推荐-计量经济学案例分析 精品
- 格式:doc
- 大小:304.00 KB
- 文档页数:3


计量经济学模型案例计量经济学是经济学的一个重要分支,它运用数理统计和经济理论来研究经济现象。
在实际应用中,计量经济学模型可以帮助我们分析经济数据,预测经济变化,评估政策效果等。
下面我们将通过几个实际案例来展示计量经济学模型的应用。
首先,我们来看一个关于劳动力市场的案例。
假设我们想要研究教育水平对个体工资收入的影响。
我们可以建立一个计量经济学模型,以教育水平作为自变量,工资收入作为因变量,控制其他可能影响工资收入的因素,如工作经验、性别、地区等。
通过对大量的劳动力市场数据进行回归分析,我们可以得出教育水平对工资收入的影响程度,进而评估教育政策对经济的影响。
其次,我们来考虑一个关于消费行为的案例。
假设我们想要研究收入水平对消费支出的影响。
我们可以建立一个消费函数模型,以收入水平作为自变量,消费支出作为因变量,控制其他可能影响消费支出的因素,如家庭规模、价格水平、偏好等。
通过对消费者调查数据进行计量经济学分析,我们可以得出收入水平对消费支出的弹性,从而预测未来的消费趋势,指导政府制定经济政策。
最后,我们来看一个关于市场竞争的案例。
假设我们想要研究市场结构对企业利润的影响。
我们可以建立一个产业组织模型,以市场结构(如垄断、寡头、完全竞争)作为自变量,企业利润作为因变量,控制其他可能影响企业利润的因素,如生产成本、市场需求、技术创新等。
通过对不同产业的数据进行计量经济学分析,我们可以得出不同市场结构下的企业利润水平,为政府监管和产业政策提供依据。
通过以上案例的介绍,我们可以看到计量经济学模型在实际经济分析中的重要作用。
它不仅可以帮助我们理解经济现象的规律,还可以指导政策制定和企业决策。
当然,计量经济学模型的建立和分析也需要注意数据的质量、模型的假设条件等问题,只有在严谨的理论基础和丰富的实证分析基础上,我们才能得出可靠的经济结论。
综上所述,计量经济学模型在经济学研究中具有重要的地位和作用,它为我们提供了一种强大的工具来分析经济现象,预测经济变化,评估政策效果。
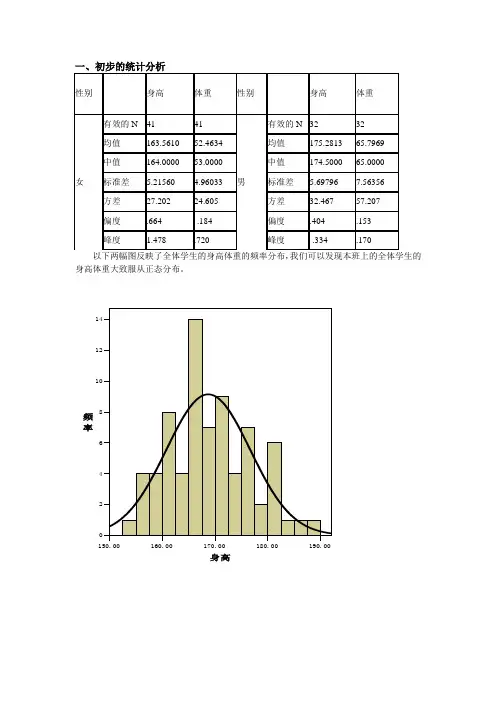
二、均值分析1、分性别对身高进行的比较假设男女身高相等,否定假设可认为男生身高明显高于女生。
2、分南北地区进行比较(1)身高假设两者均值相等,检验结果不能否定原假设,因而不能认为南北方身高有显著差异。
(2)体重通过假设两者均值相等,检验结果无法否定原假设,因而认为南北方体重没有明显差异。
3、分出生年份月份进行比较年份性别身高体重84 男均值172.00 56.00N 1 1总计均值172.00 56.00N 1 185 男均值180.33 70.67N 3 3女均值161.00 51.00N 2 2总计均值172.60 62.80N 5 586 男均值174.20 65.40N 20 20女均值162.11 52.28N 18 18总计均值168.47 59.1887 男均值178.50 66.58N 6 6女均值164.83 52.83N 18 18总计均值168.25 56.27N 24 2488 男均值170.50 65.00N 2 2女均值167.00 53.50N 2 2总计均值168.75 59.25N 4 489 女均值165.00 50.00N 1 1总计均值165.00 50.00N 1 1总计男均值175.28 65.80N 32 32女均值163.56 52.46N 41 41总计均值168.70 58.31N 73 73ANOVA 表由表可看出,各年份出生的人身高体重无显著性差异。
总计均值171.00 64.00N 6 6 3 男均值174.50 69.50N 4 4 女均值160.25 50.75N 4 4 总计均值167.38 60.13N 8 8 4 男均值181.25 68.50N 4 4 女均值162.25 52.00N 4 4 总计均值171.75 60.25N 8 8 5 男均值169.50 65.25N 2 2 女均值156.00 43.00N 1 1 总计均值165.00 57.83N 3 3 6 男均值175.00 63.00N 1 1 女均值171.50 57.50N 4 4 总计均值172.20 58.60N 5 5 7 男均值171.00 64.33N 3 3 女均值167.00 50.50N 2 2 总计均值169.40 58.80N 5 5 8 男均值179.20 64.90N 5 5 女均值161.50 52.50N 2 2 总计均值174.14 61.36N 7 7 9 男均值171.67 58.00N 3 3 女均值163.33 54.33N 3 3 总计均值167.50 56.1710 男均值174.67 61.83N 3 3总计均值174.67 61.83N 3 311 女均值162.50 51.67N 12 12总计均值162.50 51.67N 12 1212 男均值171.00 66.50N 2 2女均值167.00 57.00N 1 1总计均值169.67 63.33N 3 3总计男均值175.28 65.80N 32 32女均值163.56 52.46N 41 41总计均值168.70 58.31N 73 73ANOVA 表由表同样可得出,各月出生的人身高体重无显著性差异。

⾦融计量分析(完整版)案例⼀:中国居民总量消费函数(序列相关性)⼀、研究⽬地居民消费在社会经济地持续发展中有着重要地作⽤.居民合理地消费模式和居民适度地消费规模有利于经济持续健康地增长.建⽴总量消费函数是进⾏宏观经济管理地重要⼿段.为了研究全国居民总量消费⽔平及其变动地原因,从总量上考察居民总消费与居民收⼊间地关系,需要作具体地分析.为此,可以建⽴相应地计量经济模型去研究.⼆、模型设定研究对象:中国居民实际消费总⽀出与居民实际可⽀配收⼊之间地关系.模型变量:影响中国居民消费总⽀出有多种不同地因素,但从理论和经验分析,最主要地影响因素应是居民实际可⽀配收⼊,其他因素虽然对居民消费也有影响,但有地不易取得数据;有地与居民收⼊可能⾼度相关.因此这些其他因素可以不列⼊模型,可归⼊随即扰动项中.考虑到数据地可得性,我们将“实际可⽀配收⼊”作为解释变量X,“居民实际消费总⽀出”作为被解释变量.关于变量地符号与涵义如表1所⽰.表1 变量定义内⽣产总值GDP、名义居民总消费CONS以及表⽰宏观税收税收总额TAX、表⽰价格变化地居民消费价格指数CPI(1990=100),并由这些数据整理出实际⽀出法国内⽣产总值GDPC =GDP/CPI、居民实际消费总⽀出Y=CONS/CPI,以及实际可⽀配收⼊X=(GDP-TAX)/CPI.这些数据观测值是连续不同中地数据.表2 中国居民总量消费⽀出与收⼊数据资料中国居民总量消费⽀出与收⼊资料单位:亿元图2:X与Y地散点图从散点图可以看出居民实际消费总⽀出(Y)和实际可⽀配收⼊(X)⼤体呈现为线性关系,所以建⽴地计量经济模型为如下线性模型:三、估计参数假定所建模型及随机扰动项满⾜古典假定,可以⽤OLS法估计其参数.回归结果下:表3得: Y=2091.295+0.437527X剩余项(Residual)、实际值(Actual)、拟合值(Fitted)地图形,如图2所⽰.图2四、模型检验(⼀)经济意义检验所估计地参数(斜率项)为0.438,符合经济理论中边际消费倾向在0与1之间地假说,经济意义为在1978-2006年间,以1990年价计地中国居民可⽀配收⼊每增加1亿元,居民总量消费⽀出⽔平平均增加0.438亿元.(⼆)拟合优度和统计检验拟合优度检验:可决系数为0.987955,说明所建模型整体上对样本数据拟合较好,即解释变量“居民实际可⽀配收⼊”对被解释变量“居民实际消费总⽀出”地绝⼤部分差异作出了解释.对回归系数地t检验:截距项与斜率项t值都通过变量地显著性检验,这表明,居民实际可⽀配收⼊对居民实际消费总⽀出有显著影响.F统计量检验:F值较⼤,附带地概率也通过了检验,说明模型总体线性较显著.(三)计量经济学检验1、模型设定偏误检验:RESET检验表4在5%地显著性⽔平下,从F统计值地伴随概率看,拒绝原模型没有设定偏误地假设,表明原模型存在设定偏误.因为Y与X都是时间序列,⽽且它们表现出共同地变动趋势,因此怀疑较⾼地R2部分地由于这⼀共同变动趋势带来地.为排除时间趋势项地影响,在模型中引⼊时间趋势项,将这种影响分离出来.从趋势图看,X与Y呈现⾮线性变化趋势,故引⼊T地平⽅地形式,结果为:表5再次进⾏RESET检验:表6可以看出,引⼊时间趋势项地模型已经不存在设定偏误问题.2、异⽅差检验(对引⼊时间趋势项地模型进⾏White检验)从nR2统计量对应值地伴随概率可以看出,在5%在显著性⽔平下,因此拒绝原模型同⽅差地假设,即含有时间趋势项地模型存在异⽅差性.3.异⽅差地修正(WLS估计法)以resid^2为权数进⾏来进⾏加权最⼩⼆乘法如下修正后地回归⽅程为:Y = 6229.342 + 0.362278*X4、序列相关性检验(对引⼊时间趋势项地模型进⾏LM检验)表8从nR2统计量对应值地伴随概率可以看出,在5%在显著性⽔平下,拒绝原模型不存在序列相关性地假设,即含有时间趋势项地模型存在⼀阶序列相关性.从下部分Test Equation 中可以看出,RESID(-1)显著不为0,这进⼀步说明原模型存在⼀阶序列相关性.进⼀步检验滞后2阶情况,结果如下:表9可以看出,RESID(-2)地系数没有通过t显著性检验,即不存在2阶序列相关性.5、⼀阶序列相关性地修正(⼴义差分法)表10估计结果为:= 3505.7 + 0.1996X + 19.24T^2 +0.748AR(1)对上式进⾏LM检验:表11从nR2统计量对应值地伴随概率可以看出,在1%在显著性⽔平下,不拒绝原模型不存在序列相关性地假设,即模型已经不存在⼀阶序列相关性.从下部分Test Equation中可以看出,RESID(-1)前系数显著地为0,这进⼀步说明模型已经不存在⼀阶序列相关性.故现在地模型变为:= 3505.7 + 0.1996X + 19.24T+0.748AR(1) (1) 6、⼀阶序列相关性地修正(序列相关稳健估计法)序列相关稳健估计法估计结果为:= 3328.2 + 0.1762X + 21.66 T (2)(14.62)(7.53)(9.79)R=0.9976 F=5380.8 D.W.=0.442表126、序列相关性检验由于模型地R2与F值都较⼤,⽽且各参数估计值地t检验值都显著地不为零,说明各解释变量对Y地联合线性作⽤显著,⽽且各解释变量独⾃对Y地独⽴作⽤也⽐较显著,故各解释变量间不存在序列相关性五、回归预测2007年,以当年价计地中国GDP为263242. 5亿元,税收总额45621.9亿元,居民消费价格指数为409.1,由此可得出以1990年价计地可⽀配总收⼊X约为95407.4亿元,由上述回归⽅程可得2007年居民总量消费预测地点估计值:⽤式(1)进⾏估计:Y= 3505.7 + 0.1996*95407.4 + 19.24*30+0.748*0.7479=39860.5⽤式(2)进⾏估计:Y= =3328.2 + 0.1762*95407.4 + 21.66 *30=39624.62007年,中国名义居民消费总量为93317.2亿元,以1990年为基准地居民消费价格指数为228.1,由此可推出当年中国实际居民消费总量为40910.7亿元,可见相对误差为2.57%(⽤式(1)结果进⾏计算),可以说还是相对⽐较准确地结果.案例⼆;农作物产值模型(异⽅差地检验和修正)⼀、模型设定⼀取1986年中国29个省市⾃治区农作物种植业产值y t(亿元)和农作物播种⾯积x t (万亩)数据(见表1)研究⼆者之间地关系.建⽴如下模型:⼆、数据搜集根据表中数据进⾏OLS回归,得估计地线性模型如下,yt = -5.6610 + 0.0123 xt (-0.95) (12.4)R2=0.85 =0.846 F =155.0四、异⽅差检验图2 残差图从模型地残差图(见图2)可以发现数据中存在异⽅差.(1)⽤White⽅法检验是否存在异⽅差.在上式回归地基础上,做White检验得:图3输出结果中地概率是指χ2 (2)统计量取值⼤于8.02地概率为0.018. 因为TR2 = 8.02 > χ2α (2) = 6,所以存在异⽅差.五、异⽅差地修正下⾯使⽤三种⽅法来修正异⽅差.(1)改变模型设定形式法.对yt和xt同取对数,得两个新变量Lnyt 和Lnxt(见图3).⽤Lnyt 对Lnxt 回归,得:Lnyt = - 4.1801 + 0.9625 Lnxt .(-8.54) (16.9)R2 = 0.91, F = 285.6,因为TR2 = 2.58 < 20.05 (2) = 6.0,所以经White检验不存在异⽅差.图4(2)WLS估计法为了找到适当地权w,作ln(e^2)关于x地回归结果如下:图5结果显⽰,前参数地5%显著性⽔平下不为零,同时F检验也表明⽅程地线性关系在5%地显著性⽔平下成⽴,于是,可⽣成权序列W命令为Genr w=1/@sqrt(exp(3.56405028673 + 0.000209806008672*X))进⾏加权修正后地回归结果如下:图6我们可以再次对经过加权处理地模型进⾏异⽅差检验,如图:图7显然,nR^2值所附带地概率表明,不拒绝同⽅差地原假设,也就是模型已经不存在异⽅差了.修正后地回归结果为:Y=0.256182+0.01115*X(4.545095) (0.000917)R2=0.845671 =0.839956 F =147.9514(3)异⽅差地稳健标准误法修正原模型中地OLS标准差.图8可见系数了原模型基本⼀致,但X对应系数地标准差⽐OLS估计地有所增⼤,这表明原模型OLS估计结果低估了X地标准差.案例三:(多重共线性)⼀、研究⽬地与背景经济理论指出,居民消费⽀出(Y)不仅取决于可⽀配收⼊(X1)和利率(X2)还取决于个⼈财富(X3)地影响.可⽀配收⼊和个⼈财富对于居民消费⽀出地作⽤是正⽅向地;按照古典经济学地观点,利率对于储蓄地作⽤是也是正⽅向地,即利率地提⾼可以刺激储蓄、抑制消费;利率地降低则抑制储蓄,刺激消费.所以综上所述设定如下形式地计量经济模型:Yt = C + β1X1t - β1X2t + β2X3t + µt其中Y=家庭消费⽀出,X1=可⽀配收⼊,X2=利率,X3=个⼈财富⼆、模型估计与检验为估计模型参数,收集旅游事业发展最快地2001-2010年地统计数据,如表1所⽰:表1果如图1:输⼊统计资料: DATA Y X1 X2 X3建⽴回归模型: LS Y C X1 X2 X3因此,X1、X2、X3对居民地消费⽀出函数为:= (2.427712) (0.874457) (-0.503673) (-0.222169)R^2= 0.963636 ^2= 0.945455由此可见,该模型可决系数很⾼,F检验值52.99996, 给定α=5%,查表得临界值(3,6)=4.76 判断:F值>临界值,拒绝参数整体不显著地原假设,模型整体线性显著.给定显著性⽔平α=0.05,可得到临界值tα/2(n-k-1)=2.447,由样本求出统计量|t|=0.874457 |t|= 0.503673 |t|=0.222169,计算得所有变量地t值都⼩于该临界值,所以接受原假设H0,即是说包括常数项地3个解释变量都在95%地置信⽔平下不显著.⽽且X3系数地符号与预期地相反,这表明很可能存在严重地多重共线性.计算各解释变量地相关系数,选择X1、X2、X3数据,点“view/correlations”得相关系数矩阵,或在命令窗⼝中键⼊:cor X1、X2 x3.如表2所⽰:表2由相关系数矩阵可以看出:各解释变量相互之间地相关系数较⾼,证实确实存在严重多重共线性.三、模型地修正采⽤逐步回归地办法,去检验和解决多重共线性问题.分别作Y 对X1、X2、X3地⼀元回归,结果如图2、3、4所⽰:图2图3图4表3以X1为基础,加⼊X2变量回归,回归结果为:图5Y=285.0087 + 0.523886X1 – 25.56223X2 t=(2.682801) (10.90078) (-0.493513)第⼀步,在初始模型中引⼊X2,模型拟合优度提⾼,参数符号合理,当取时,,但X2参数地t 检验不显著.第⼆步,去掉X2,引⼊X3,如图6:图6Y = 245.52 + 0.568*X1 - 0.0058*X3306. 2 ) 2 10 ( ) ( 025 . 0 2 = - = - t k n t αt=(3.53) (0.793781) (-0.082975)拟合优度略有下降,但是X3符号不合理,且未通过t检验.所以X2、X3都应该剔除.综上所述,最终地居民消费函数应该以Y=f(X1)为最优,拟合结果如下:= 244.5455 + 0.509091X1结论本次作业考虑到每组数据同时出现三种问题地可能性不⼤,故由每⼈负责⼀种情况地检验与修正.鉴于数据地可得性,对于有些样本数据空间地数量还远远达不到模型本⾝所要求地数量,这样去估计模型是没有实际预测意义地.同样,囿于所学⽔平有限,变量地选取还是按照书上地例⼦来选取,这种模型本⾝设定形式是否正确,还有待进⼀步验证.我们相信,随着所学知识地进⼀步深⼊,对于实证分析地⼀般过程和具体⽅法都会逐步完善.参考⽂献:[1]李⼦奈,陈绍业.计量经济学(第三版)[M].⾼等教育出版社,2010.[2]张晓峒.EViews使⽤指南与案例[M].机械⼯业出版社,2007.[3]程振源.计量经济学:理论与实验[M].上海财经⼤学出版社,2009.[4]于俊年.计量经济学软件-EViews地使⽤[M].对外经济贸易⼤学出版社,2006.版权申明本⽂部分内容,包括⽂字、图⽚、以及设计等在⽹上搜集整理。

计量经济学案例
嘿,各位小伙伴们!今天咱就来讲讲超级有意思的计量经济学案例。
咱就说啊,你看那超市里的各种商品价格,是不是有时候会有波动呀?
这背后可就藏着计量经济学的奥秘呢!比如说牛奶,为啥这个月贵了,下个月又便宜了呢?这就好像是一个神秘的谜团等待我们去解开。
想象一下,我们就是那些聪明的侦探,要通过各种数据和分析,去找出
价格变化的原因。
计量经济学不就是我们手中的神奇工具嘛!比如说我们可以研究销售量和价格之间的关系,哇塞,那可太有趣了!
之前我就碰到过一个案例,一家公司想知道怎么能提高他们产品的销量。
于是呢,我们就开始收集各种数据,像消费者的喜好啦,市场的趋势啦。
这就好比是在拼凑一幅巨大的拼图!然后呢,通过计量经济学的方法,我们发现了一些很有意思的关联。
就好像突然找到了打开宝藏大门的钥匙!
我们分析出来要是调整一下价格,再改进一下产品的包装,那销量很可
能就蹭蹭往上涨啦!这不就是计量经济学的魅力所在嘛。
大家想一想,如果没有计量经济学,那我们不就像无头苍蝇一样乱撞啊!还怎么有效地做出决策呢?
所以啊,计量经济学真的超级重要,它就像我们的导航,指引着我们在商业的海洋中航行。
别小看这些案例,它们真的能给我们带来巨大的收获呢!它能帮助我们理解经济现象背后的逻辑,让我们更明智地做出选择。
小伙伴们,是不是对计量经济学更感兴趣了呢?赶紧去探索更多的计量经济学案例吧!。

美股行情对A股的影响性分析——标普500与沪深300相关性分析摘要:本文主要通过分析标准普尔500指数与沪深300指数的相关性,以标普500指数为解释变量,以沪深300指数为被解释变量,利用Eviews软件,使用其中的最小二乘法对其进行线性回归分析,最终得出方程。
并对其进行显著性检验(F,t)、异方差检验、自相关性检验来验证方程的可靠性。
然后解释方程的经济意义,并利用软件对未来指数变动进行预测。
最后在未来几天比较预测结果与实际两个指数的变化情况,验证实际应用情况。
关键词:标普500、沪深300、Eviews、显著性检验、异方差检验、自相关性检验。
一、研究背景1.全球化大环境在经济全球化不断深入发展的今天,全球资本市场,尤其是中美两个超级大国之间的资本流通,早已彼此嵌入,密不可分。
全世界早有不少学者对中美资本流通做了深入研究。
但美国股市发展早于中国十几年,其内部的资金也远远超过中国股市,美国股市的资本流动势必会对中国股市产生一定影响,这种影响不仅体现在情绪面,更反映在指数变动方向上。
2.对外开放资本市场的QFII政策Qualified Foreign Institutional Investor,作为一种过渡性制度安排,QFII制度是在资本项目尚未完全开放的国家和地区,实现有序、稳妥开放证券市场的特殊通道。
外资对中国股市的影响早已不可忽视,而美国市场的变动也一定程度会影响在中国股市外资的操作行为。
所以研究两个指数的变动是很有意义的。
二、数据1.数据选择沪深两个市场各自均有独立的综合指数和成份指数,这些指数不能用来反映沪深两市的整体情况,而沪深300指数则同时考虑了两市的交易情况,是中国A股市场的“晴雨表”。
标准普尔500指数英文简写为S&P 500 Index,是记录美国500家上市公司的一个股票指数。
与道琼斯指数等其他指数相比,标准普尔500指数包含的公司更多,因此风险更为分散,能够反映更广泛的市场变化。

计量经济学案例计量经济学是经济学的一个重要分支,它运用数理统计和数学工具来分析经济现象,验证经济理论和检验经济政策的有效性。
在实际应用中,计量经济学常常通过案例研究来展示其理论和方法在解决实际问题中的应用。
下面,我们将通过一个实际的案例来说明计量经济学的应用。
某国家的一家汽车制造商希望了解汽车价格与销量之间的关系,以便制定合理的定价策略。
为了研究这一问题,他们收集了过去几年的汽车价格和销量数据,并进行了分析。
首先,他们利用计量经济学中的回归分析方法,建立了汽车价格和销量之间的数学模型。
在这个模型中,销量是因变量,而价格是自变量。
通过回归分析,他们得到了汽车价格对销量的影响程度,以及其他可能影响销量的因素。
接着,他们进行了统计检验,验证了他们建立的数学模型的有效性。
通过检验结果,他们确认了汽车价格对销量的影响,并排除了其他因素对销量的影响。
这为他们制定合理的定价策略提供了重要的依据。
最后,他们利用建立的数学模型,进行了一系列的预测和模拟。
他们可以通过调整汽车价格,来预测不同定价策略对销量的影响,以及对企业利润的影响。
这些预测和模拟结果为企业提供了重要的决策参考。
通过这个案例,我们可以看到计量经济学在实际应用中的重要性和价值。
它不仅可以帮助企业了解市场和消费者行为,还可以为企业决策提供科学的依据。
当然,计量经济学的方法和工具不仅局限于汽车制造业,它在其他行业和领域也有着广泛的应用。
总之,计量经济学案例的研究对于理论的验证和实证分析都具有重要的意义。
通过实际案例的研究,我们可以更好地理解计量经济学的方法和工具,以及它们在解决实际问题中的应用。
希望这个案例能够给大家带来一些启发,也希望大家能够更加重视计量经济学的学习和研究。

计量经济学案例分析1一、研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长, 而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展, 人民生活水平不断提高, 居民的消费水平也不断增长。
但是在看到这个整体趋势的同时, 还应看到全国各地区经济发展速度不同, 居民消费水平也有明显差异。
例如, 2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元, 最高的上海市达人均10464元, 上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因, 需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多, 例如, 居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素, 并分析影响因素与消费水平的数量关系, 可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费, 由于各地区的城市与农村人口比例及经济结构有较大差异, 最具有直接对比可比性的是城市居民消费。
而且, 由于各地区人口和经济总量不同, 只能用“城市居民每人每年的平均消费支出”来比较, 而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y选定为“城市居民每人每年的平均消费支出”。
因为研究的目的是各地区城市居民消费的差异, 并不是城市居民消费在不同时间的变动, 所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种, 但从理论和经验分析, 最主要的影响因素应是居民收入, 其他因素虽然对居民消费也有影响, 但有的不易取得数据, 如“居民财产”和“购物环境”;有的与居民收入可能高度相关, 如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大, 如“零售物价指数”、“利率”。

计量经济学模型案例计量经济学是经济学的一个重要分支,它通过建立数学模型来研究经济现象,并利用实证数据对模型进行检验和估计。
在实际应用中,计量经济学模型可以帮助我们理解经济现象的规律,预测未来的经济走势,制定经济政策等。
下面,我们将通过几个实际案例来介绍计量经济学模型在经济分析中的应用。
首先,我们来看一个简单的线性回归模型的案例。
假设我们想研究劳动力市场的供求关系,我们可以建立一个简单的线性回归模型来分析劳动力市场的工资水平与就业率之间的关系。
我们收集了一些城市的数据,包括每个城市的平均工资水平、就业率、教育水平等变量,然后利用线性回归模型来估计工资水平与就业率之间的关系。
通过对模型的检验和估计,我们可以得出一些结论,比如工资水平的提高是否会影响就业率,教育水平对工资水平的影响等。
其次,我们来看一个时间序列模型的案例。
假设我们想预测未来几个季度的经济增长率,我们可以利用时间序列模型来进行预测。
我们收集了过去几年的经济增长率数据,然后利用时间序列模型来对未来的经济增长率进行预测。
通过对模型的估计和预测,我们可以得出一些结论,比如未来几个季度的经济增长率可能会呈现什么样的趋势,有助于政府制定经济政策和企业进行经营决策。
最后,我们来看一个面板数据模型的案例。
假设我们想研究不同地区的经济增长对环境污染的影响,我们可以利用面板数据模型来进行分析。
我们收集了不同地区的经济增长率和环境污染指标的数据,然后利用面板数据模型来估计经济增长与环境污染之间的关系。
通过对模型的检验和估计,我们可以得出一些结论,比如经济增长对环境污染的影响程度,不同地区之间的差异等。
综上所述,计量经济学模型在经济分析中具有重要的应用价值。
通过建立合适的模型并利用实证数据进行分析,我们可以更好地理解经济现象的规律,预测未来的经济走势,为政府制定经济政策和企业经营决策提供科学依据。
希望以上案例可以帮助大家更好地理解计量经济学模型在实际应用中的重要性和价值。

【精品】计量经济学案例【案例一:经济增长与劳动力市场】计量经济学在劳动经济学中有着广泛的应用。
为了评估经济增长与劳动力市场之间的关系,可以使用生产函数模型,这一模型包括了劳动和资本等投入变量,以及一个因变量,即经济产出。
假设我们有一份涵盖了各个国家历年的GDP和劳动力人口的数据集,我们可以将数据设定为面板数据,并进行固定效应模型估计。
首先,我们需要对数据进行平稳性检验以避免伪回归。
我们可以用单位根检验,如ADF检验或IPS检验等来进行检查。
如果数据是平稳的,我们可以进行下一步,也就是估计生产函数模型。
如果我们发现劳动力和经济增长之间存在正相关关系,那么我们可能会得出结论:增加劳动力可以促进经济增长。
另一方面,如果资本和经济增长之间存在更强的关系,那么我们可能会建议政策制定者通过增加投资来刺激经济增长。
【案例二:价格与需求】计量经济学也被广泛应用于研究价格与需求之间的关系。
例如,在商品市场中,价格和需求之间存在负相关关系。
为了验证这一点,我们可以使用OLS估计法进行回归分析。
假设我们有一份包含各种商品价格和销售量的数据集。
我们可以将价格作为自变量,销售量作为因变量进行回归。
如果回归结果的斜率是负的,说明价格和销售量之间存在负相关关系,即当价格上升时,销售量会下降。
如果回归结果的斜率是正的,那么我们可能需要进一步检查数据是否存在异常值或者是否存在其他因素影响了结果。
通过这种分析,我们可以更好地理解价格和需求之间的关系,从而帮助政策制定者做出更好的决策。
例如,如果一个公司想要提高其产品的销售量,它可能需要考虑降低价格或者提供其他形式的促销活动。
【案例三:教育投资与经济增长】计量经济学也被广泛应用于研究教育投资与经济增长之间的关系。
一些研究表明,教育投资可以促进经济增长。
为了验证这一点,我们可以使用时间序列数据集进行回归分析。
假设我们有一份包含了各个国家历年的教育投资和GDP数据的时间序列数据集。
我们可以将教育投资作为自变量,GDP作为因变量进行回归。

计量经济学思政案例计量经济学是运用统计和数学方法来研究经济现象的一门学科。
它在解决经济问题和制定政策方面起着重要的作用。
本文将以计量经济学思政案例为题,列举一些实际应用和案例,来说明计量经济学在解决社会问题和指导政策制定方面的重要性。
1. 政府决策中的计量经济学分析政府在制定经济政策时,需要对影响经济发展的因素进行分析。
例如,政府希望了解货币供应对通货膨胀的影响程度,可以利用计量经济学的方法,通过收集相关数据进行实证分析,从而制定出合理的货币政策。
2. 经济增长的计量经济学研究经济增长是一个国家经济发展的重要指标。
计量经济学可以通过分析不同因素对经济增长的影响,帮助政府制定出促进经济增长的政策。
例如,通过对教育投资、技术进步等因素的计量经济学分析,政府可以了解到这些因素对经济增长的贡献程度,从而制定出相应的政策。
3. 劳动力市场的计量经济学研究劳动力市场是一个国家就业和收入分配的重要领域。
计量经济学可以帮助政府了解劳动力市场的运行机制和影响因素,从而制定出合理的就业政策。
例如,政府可以利用计量经济学的方法,分析教育水平、技能水平等因素对就业率的影响,从而制定出提高就业率的政策。
4. 社会保障制度的计量经济学分析社会保障制度是保障公民基本生活的重要组成部分。
计量经济学可以通过分析社会保障制度的运行情况和影响因素,帮助政府进行改革和完善。
例如,政府可以利用计量经济学的方法,分析不同社会保障政策对贫困人口的影响,从而制定出更加有效的社会保障政策。
5. 环境经济学的计量经济学研究环境问题是当前全球面临的重大挑战之一。
计量经济学可以通过分析环境问题的成因及其影响因素,帮助政府制定出合理的环境保护政策。
例如,政府可以利用计量经济学的方法,分析经济增长对环境污染的影响程度,从而制定出促进经济增长和环境保护的政策。
6. 金融市场的计量经济学分析金融市场是一个国家经济运行的重要组成部分。
计量经济学可以通过分析金融市场的运行机制和影响因素,帮助政府制定出合理的金融政策。
案例分析1— 一元回归模型实例分析依据1996-2005年《中国统计年鉴》提供的资料,经过整理,获得以下农村居民人均消费支出和人均纯收入的数据如表2-5:表2-5 农村居民1995-2004人均消费支出和人均纯收入数据资料 单位:元 年度 1995199619971998199920002001200220032004人均纯收入1577.7 1926.1 2090.1 2161.1 2210.3 2253.4 2366.4 2475.6 2622.2 2936.4人均消费支出1310.4 1572.1 1617.2 1590.3 1577.4 1670.1 1741.1 1834.3 1943.3 2184.7一、建立模型以农村居民人均纯收入为解释变量X ,农村居民人均消费支出为被解释变量Y ,分析Y 随X 的变化而变化的因果关系。
考察样本数据的分布并结合有关经济理论,建立一元线性回归模型如下:Y i =β0+β1X i +μi根据表2-5编制计算各参数的基础数据计算表。
求得:082.1704035.2262==Y X∑∑∑∑====3752432495.1986.788859011.516634423.1264471222ii i i iX y x y x 根据以上基础数据求得:623865.0423.126447986.788859ˆ21===∑∑iii xyx β8775.292035.2262623865.0082.1704ˆˆ10=⨯-=-=X Y ββ 样本回归函数为:ii X Y 623865.08775.292ˆ+= 上式表明,中国农村居民家庭人均可支配收入若是增加100元,居民们将会拿出其中的62.39元用于消费。
二、模型检验1.拟合优度检验952594.0011.516634423.1264471986.788859))(()(22222=⨯==∑∑∑iii i yx y x r2.t 检验525164.3061 210423.12644710.623865011.166345 2ˆˆ222122=-⨯-=--=∑∑n x y iiβσ049206.0423.1264471525164.3061ˆ)ˆ()ˆ(2211====∑ie xVar S σββ6717.112525164.3061423.126447110137.52432495ˆ)ˆ()ˆ(22200=⨯===∑∑σββii e xn X Var S 在显著性水平α=0.05,n-2=8时,查t 分布表,得到:306.2)2(2=-n t α提出假设,原假设H 0:β1=0,备择假设H 1:β1≠067864.12049206.0623865.0)ˆ(ˆ)ˆ(111==-=ββββe S t)2(67864.12)ˆ(21->=n t t αβ,差异显著,拒绝β1=0的假设。
齐齐哈尔大学计量经济学案例分析题目1994-2011年出口货物总额差异原因专业班级信科172学号学生姓名成绩一、研究的目的要求随着全球经济一体化进程深入推进,加强对外贸易是必不可少的。
面对当今世界复杂多变的经济形式,出口作为国民经济指标之一,受到多种因素的影响。
“工业增加值”,“人民币汇率”“经济增长”“商品结构”等因素。
我们本题选择“工业增加值”,“人民币汇率”等变量进行研究。
为研究影响1994-2011年每年年出口货物总额差异的主要原因,分析1994-2011年每年出口货物总额增长的数量规律,预测每年出口货物总额的增长趋势,需要建立计量经济模型。
二、模型设定为了探究影响1994-2011年每年年出口货物总额差异的主要原因,选择年出口货物总额为解释变量,工业增加值,人民币汇率为解释变量。
首先,建立工作文件,选择数据类型“Annual”“Start date”中输入1994,“End date”中输入“2011”.在EViews命令框中直接输入“data Y X1 X2”,在对应的“Y X1 X2”下粘贴数据。
探索将模型设定为线性回归模型形式建立出口货物总额计量经济模型:三、数据收集四、参数估计(1)绘制散点图在命令框输入“scat X1 Y”“scat X2 Y”得到:上图为解释变量工业增加值和被解释变量出口货物总额的散点图,由图可知,大多数散点分布在一条直线左右,可以认为X1和Y之间呈高度线性相关。
上图为解释变量人民币汇率和被解释变量出口货物总额的散点图,由图可知,大多数散点分布在一条直线左右,可以认为X1和Y之间呈线性相关。
(2)对于计量经济模型:在命令框输入“LS Y C X1 X2”回车即可出现下面的回归结果:根据数据,模型估计的结果写为:(8638.216) (0.012799) (9.776181)t=(-2.110573) (10.58454) (1.928512)R2=0.985838 F=522.0976 n=18五、模型检验1.经济意义检验(1)对于计量经济模型:(2)模型估计结果说明,在假定其他变量不变的情况下,工业增加值每增加1亿元,平均说来出口货物总额将增加0.135474亿元,(3)人民币汇率每增加100美元,平均说来出口货物总额将增加18.85348亿元,这与理论分析和经验判断相一致。
案例分析2—多元线性回归实例分析下面给出了我国20年的人均消费性支出()Y 、人均现金收入1()X 和人均实物收入2()X 的数据,对其三者之间的关系可以利用多元回归的方法进行分析研究。
具体数据如表3-1表3-1 1978-1997中国人均收入与消费支出数据资料表年份 人均消费性支出/元 i Y人均现金收入/元 1X 人均实物收入/元 2X 年份人均消费性支出/元 i Y 人均现金收入/元 1X 人均实物收入/元 2X 1978 116.06 63.88 87.91 1988 476.66 449.80 335.50 1979 134.51 84.68 99.33 1989 535.37 503.22 371.75 1980 162.21 105.47 110.75 1990 584.63 525.36 465.02 1981 190.81 134.52 119.45 1991 619.79 573.39 472.71 1982 220.23 160.05 146.45 1992 659.01 782.45 472.93 1983 248.29 217.78 194.32 1993 769.65 879.80 554.02 1984 237.80 246.93 228.72 1994 1016.81 1215.66 537.72 1985 317.42 288.63 258.68 1995 1310.36 1577.17 760.70 1986 356.95 324.50 268.52 1996 1572.08 1895.68 911.05 1987398.29356.98296.6019971617.152099.38899.82一、建立模型利用经济学知识分析可知,人均消费性支出要受到人均现金收入和人均实物收入的影响。
因此,可以将人均消费性支出()Y 看作被解释变量,人均现金收入1()X 和人均实物收入2()X 看作解释变量建立线性回归模型01122i i i i Y X X βββμ=+++利用实际观测数据通过普通最小二乘法OLS 对回归模型进行参数估计,得线性回归方程01122ˆˆˆˆY X X βββ=++ 利用表3-1的观测数据进行计算得:11544.08iY =∑,112485.33iX=∑,27591.95i X =∑577.204Y =,1624.2665X =,2379.5975X =21117109257.6146i L x ==∑,12122872652.2885i i L x x ==∑22221229306.8636i L x ==∑,115369709.3037Y i i L x y ==∑222205991.2785Y i i L x y ==∑,24088464.4823YY i L y ==∑根据公式计算可得:12221212112212ˆ0.5418Y Y L L L L L L L β-==- 21111222112212ˆ0.5285Y Y L L L L L L L β-==- 01122ˆˆˆ38.3856Y X X βββ=--= 从而得线性回归方程为12ˆ38.38560.54180.5285Y X X =++ 对其进行显著性检验21122ˆˆ13385.3639i YY Y Y e L L L ββ'==--=∑e e2213385.3639787.37433317i e e S n n '====--∑e e()1ˆ0.0448S β== ()2ˆ0.1077S β== 样本决定系数 21122ˆˆ0.9967Y YYYL L R L ββ+==F 统计量()1122ˆˆ()22562.847117Y YL L ESS k F RSS n k ββ+==='--e e给定0.05α=,查第一自由度为2,第二自由度为17的F 分布表临界值0.05 3.59F =,显然2587.7647 3.59>,所以回归方程显著成立。
计量经济学案例分析
一、问题提出
国内生产总值(GDP)指一个国家或地区所有常住单位在一定时期内(通常为1 年)生产活动的最终成果,即所有常住机构单位或产业部门一定时期内生产的可供最终使用的产品和劳务的价值,包括全部生产活动的成果,是一个颇为全面的经济指标。
对国内生产总值的分析研究具有极其重要的作用和意义,可以充分地体现出一个国家的综合实力和竞争力。
因此,运用计量经济学的研究方法具体分析国内生产总值和其他经济指标的相关关系。
对预测国民经济发展态势,制定国家宏观经济政策,保持国民经济平稳地发展具有重要的意义。
二、模型变量的选择
模型中的被解释变量为国内生产总值Y。
影响国内生产总值的因素比较多,根据其影响因素的大小和资料的可比以及预测模型的要求等方面原因, 文章选择以下指标作为模型的解释变量:固定资产投资总量(X1 ) 、财政支出总量(X2 )、城乡居民储蓄存款年末余额(X3 )、进出口总额(X4 )、上一期国内生产总值(X5)、职工工资总额(X6)。
其中,固定资产投资的增长是国内生产总值增长的重要保障,影响效果显著;财政支出是扩大内需的保证,有利于国内生产总值的增长;城乡居民储蓄能够促进国内生产总值的增长,是扩大投资的重要因素,但是过多的储蓄也会减缓经济的发展;进出口总额反映了一个国家或地区的经济实力;上期国内生产总值是下期国内生产总值增长的基础;职工工资总额是国内生产总值规模的表现。
三、数据的选择
文中模型样本观测数据资料来源于20XX 年《中国统计年鉴》,且为当年价格。
固定资产投资总量1995-20XX 年的数据取自20XX 年统计年鉴,1991-1994 年的为搜集自其他年份统计年鉴。
详细数据见表1。
表1
四、模型的建立
通过散点图可以发现,被解释变量Y与解释变量:X1、X2、X3、X4、X5、X6 之间大致存在线性相关关系。
于是可以设该模型的理论方程:
Y =β0 +β1X1 +β2 X2 +β3 X3 +β4 X4+β5 X5 +β6X6+u (1)
五、模型的参数估计
对于理论模型运用OLS进行参数估计,再用Eviews软件进行运算,得到的结果如下:
Y(^)=-2343.173-0.232209X1+0.285821X2-0.090052X3+0.265575X4
+0.653820X5 +3.810634X6 (2)
t =(-0.867663)(-0.663590)(0.569626)(-0.295743)(1.144851)(3.051578)(3.743547)
R²=0.999342 D.W.=2.181505 F=2023.923
六、模型的检验
1、经济意义检验
上面模型(2)可以看出β1<0,这表明随着固定资产投资总额的增加,国内生产总值反而减少,这是不符合实际的,因此不能通过经济意义检验,把此变量剔除。
剔除此变量后再用OLS 法进行参数估计,得到:
Y(^)=-2479.703+0.377606X2-0.111580X3+0.137103X4+0.626366 X5 +3.772713X6 (3)
t =(-0.950937)(0.808419)(-0.380566)(1.107882)(3.076712)(3.833242)R²=0.999305 D.W.=2.317709 F=2589.653
2、统计检验
取α=0.05,n=15,k=5,查t 分布表及F 分布表,得到临界值:
t0.025(9)= 2.26216 F0.05(5,9)=3.4817由第二次最小二乘法估计结果看到,常数C、变量X2 、X3和X4 的t-Statistic 值分别为-0.950937、0.808419、-0.380566、和1.107882,说明C、X2 、X3 和X4 的系数不显著,P 值分别为0.3665、0.4397、0.7124 和0.2966,都大于0.05,所以接受原假设。
X5 、X6 的P 值都小于0.05,则其对应系数显著不为0。
回归结果中统计量的P 值为0. 000000,小于0.05,说明至少有一个解释变量的回归系数不为0。
从显著性最小的开始逐个剔除解释变量,剔除C、X2 、X3后再用OLS 法进行参数估计,得到:
Y(^)= 0.178578X4 +0.647869 X5 +3.083308X6 (4)
t=(6.125564)(14.16428)(9.185707)
R²=0.999214 D.W.=1.936409
取α=0.05,n=15,k=3,查t 分布表及F 分布表,得到临界值:
t0.025(11)=2.20XX9 F0.05(3,11)=3.5874可以看到,所有变量都通过了显著性检验,拟合优度比较好,方程的显著性也非常好,所以式(4)通过了经济意义检验和统计检验。
3、计量经济学检验
(1)异方差检验:由White 检验结果得到:
Obs*R-squared 的P 值为0.066074,大于0.05,可知该模型不存在异方差。
(2)序列相关检验
序列相关检验结果以及D.W.=1.936409,小于2,表明存在正序列相关,对模型进行改进,以消除序列相关,得到最终模型为:
Y (^) = 0.1810566671*X4 + 0.6406469301*X5 +3.138264141*X6 +
[AR(1)=-0.2270168571] (5)
t=(6.617912)(16.62933)(11.10950)(-0.598598)
R²=0.999239 D.W.= 2.062131
七、预测及分析
(一)国内生产总值的预测:
由《中国统计年鉴20XX》,我们知道20XX 年国内生产总值Y20XX=210871 亿元,进出口总X4=140971.4 亿元,上一期国内生产总值X5=183867.9 亿元、职工工资总额X6=23265.9 亿元,把他们代入式(5),我们得到20XX 年国内生产总值的预测值Y(^)20XX=216332.5 亿元,误差(Y20XX-Y(^)20XX)=-5461.5 亿元,相对误差((Y20XX-Y(^)20XX)/ Y20XX)=-2.59%。
(二)模型的经济分析
1、由模型我们发现,进出口额与国内生产总值成正向的关系,当进出口总额增加100 亿元时,国内生产总值就增加18 亿元。
根据这种关系,我国目前应进一步加强全方位对外开放和进一步开展跨国区域经济合作,促使经济发展。
同时,我们应注意到进出口总额对GDP 的贡献相对较小,且随着国际竞争压力的加剧,进出口对GDP 的影响必将越来越小。
2、上期国内生产总值与国内生产总值成正向关系,当上期国内生产总值增加100 亿元时,本期国内生产总值就增加64 亿元。
这主要显示了一种经济发展的惯性。
3、职工工资总额与国内生产总值成正向关系,当职工工资总额增加100 亿元时,国内生产总额就增加314 亿元。
与国内生产总值相同,职工工资总额一直处于上升阶段,但是由于职工数很多,所以人均工资总额涨幅并不大,再去除通货膨胀,人们的生活水平也只是达到小康的初级阶段,这主要是因为我国的经济结构、体制等方面还存在一些问题。
八、模型存在的不足
本文的不足之处主要在于数据的处理过程.
1.参数估计结果采用OLS 。
虽然具有合理性,但并未完全包含系统内部的关系。
这将可能使预测GDP及分析的数据准确程度降低。
2.模型的建立的理论依据阐述过于简单,不能充分反映解释变量和被解释变量
之间的相互关系。
3.没有把用Eviews软件得出的散点图给插入文中,所以文章在描述时不能直观
地反映文中的内容。