计量经济学-案例分析-第六章
- 格式:doc
- 大小:78.00 KB
- 文档页数:5

第六章课后答案6.1(1)收入—消费模型为Se = (2.5043) (0.0075)t = (-3.7650) (125.3411)R2 = 0.9978,F = 15710.39,d f = 34,DW = 0.5234(2)对样本量为36、一个解释变量的模型、5%显著水平,查DW统计表可知,d L=1.411,d U= 1.525,模型中DW<d L,显然消费模型中有自相关。
(3)采用广义差分法查5%显著水平的DW统计表可知d L = 1.402,d U = 1.519,模型中DW= 2.0972>d U,说明广义差分模型中已无自相关。
同时,判定系数R2、t、F统计量均达到理想水平。
由差分方程式可以得出:所以最终的消费模型为:6.2(1)给定n=16, ,在的显著水平下,查DW统计表可知,。
模型中,所以可以判断模型中存在正自相关。
给定n=16, ,在的显著水平下,查DW统计表可知,。
模型中,所以可以判断模型中不存在自相关。
(2)自相关可能由于模型6.1的误设,因为它排除了趋势的平方项。
(3)虚假自相关是由于模型的误设造成的,因此就要求对可能的函数形式有先验知识。
真正的自相关是可以通过广义差分法等方法来修正。
6.3(1)收入—消费模型为(2)DW=0.575,取,查DW上下界,说明误差项存在正自相关。
(3)采用广义差分法使用普通最小二乘法估计的估计值,得DW=1.830,已知,模型中因此,在广义差分模型中已无自相关。
由差分方程式可以得出:因此,修正后的回归模型应为6.4(1)回归结果如下:(2)模型检验:从回归结果可以看出,参数均显著,模型拟和较好。
异方差的检验:通过white检验可以得知模型不存在异方差。
DW检验:给定n=25, ,在的显著水平下,查DW统计表可知,。
模型中,所以可以判断模型中存在正自相关。
(3)采用广义差分法修正模型中存在的自相关问题:给定n=24,,在的显著水平下,查DW统计表可知,。

计量经济学第六章自相关自相关是计量经济学中一种重要的现象,它指的是一个变量与其自己在过去时间点上的相关性。
自相关在实证研究中十分常见,对经济学家来说,了解和掌握自相关性质是至关重要的。
1. 引言自相关作为计量经济学的一项基础概念,是经济学研究中不可或缺的一个重要方法。
自相关性的存在通常会引起回归结果的偏误,而忽略自相关性可能导致估计不准确的结果。
因此,探讨自相关性的性质和应对方法是计量经济学的重点之一。
2. 自相关的定义和表示自相关是指一个变量与其自身在过去时间点上的相关性。
假设我们有一个时间序列数据集,其中变量yt表示一个时间点上的观测值,t表示时间索引。
自相关系数可以通过计算观测值yt与其在过去某一时间点上的观测值yt-k(k为时间滞后期数)的相关性来得到。
数学上,自相关系数可以用公式表示为:ρ(k) = Cov(yt, yt-k) / (σ(yt) * σ(yt-k))其中,ρ(k)表示第k期的自相关系数,Cov表示协方差,σ表示标准差。
3. 自相关性的性质自相关性具有以下几个性质:3.1 一阶自相关性一阶自相关性是指变量值yt与前一期的观测值yt-1之间的相关性。
一阶自相关系数ρ(1)通常用来检验时间序列数据是否存在自相关性。
若ρ(1)大于零且显著,则表明存在正的一阶自相关性;若ρ(1)小于零且显著,则表明存在负的一阶自相关性。
3.2 高阶自相关性除了一阶自相关性,时间序列数据还可能存在高阶自相关性。
高阶自相关性是指变量值yt与过去第k期的观测值yt-k之间的相关性。
通过计算不同滞后期的自相关系数ρ(k),可以了解数据在不同时间跨度上的自相关性情况。
3.3 异方差自相关性异方差自相关性是指时间序列数据中的方差不仅与自身相关,还与过去观测值的相关性有关。
异方差自相关性可能导致在回归分析中的标准误差失效,从而产生无效的回归结果。
因此,在处理存在异方差自相关性的数据时要采取合适的修正方法。
4. 自相关性的检验方法在实证研究中,经济学家通常使用多种方法来检验数据中的自相关性,常用的方法包括:4.1 Durbin-Watson检验Durbin-Watson检验是一种常用的检验自相关性的方法,其基本思想是通过检验误差项的相关性来判断自相关是否存在。


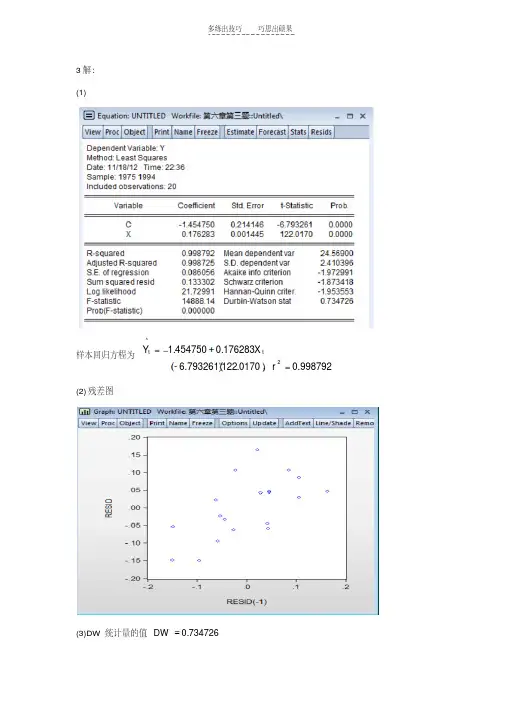
3解:(1)样本回归方程为998792.00170.1226.793261-176283.0454750.12^t r X Y t,(2)残差图(3)DW 统计量的值734726.0DW(4)BG LM 自相关检验辅助回归式估计结果是t t t tX e e 000420.0060923.0638831.01因为84.3998223.7,84.31205.0LM ,所以LM 检验量也说明样本回归方程的误差项存在一阶正自相关。
首先估计自相关系数^,得632637.02734726.0121^DW 对原变量做广义差分变换。
令1t 632637.0t t Y Y GDY ,1t 632637.0t t X X GDX 以年1994~1975,,t t GDX GDY 为样本再次回归,得tGDX GDY 173740.0391490.0t 回归方程拟合的效果仍然比较好,651914.1DW 对于给定05.0,查表得,。
43.1,24.1U L d d 因为75.243.11651914.1DW ,依据判别规则,误差项已消除自相关。
由391490.0^*0,得06568.1632637.01/391490.01/^^*0^0则原模型的广义最小二乘估计结果是t X Y 173470.006568.1^t 。
4解:(1)样本回归方程为tGDP Y 694454.0674.2816^t(2)残差图(3)3397.0DW(4)BG LM 自相关检验辅助回归式估计结果是t t t tGDP e e 029062.07871.334985257.01因为84.309615.30,84.31205.0LM ,所以LM 检验量也说明样本回归方程的误差项存在一阶正自相关。
首先估计自相关系数^,得83015.023397.0121^DW对原变量做广义差分变换。
令1t 83015.0t t Y Y GDY ,183015.0t t tGDGDP GDP GDGDP ,以年1994~1975,,t t GDGDP GDY 为样本再次回归,得。
第六章自相关二、问答题1、那些原因可以造成自相关;2、存在自相关时,参数的OLS估计具有哪些性质;3、如何检验是否存在自相关;4、当存在自相关时,如何利用广义差分法进行参数估计;5、当存在自相关时,如何利用广义最小平方估计法进行参数估计;6、异方差与自相关有什么异同;三、计算题1、证明:当样本个数较大时,)d。
≈-1(2ρα2、通过D-W检验,判断下列模型中是否存在自相关,显著性水平%5=(1)样本大小:20;解释变量个数(包括常数项):2;d=0.73;(2)样本大小:35;解释变量个数(包括常数项):3;d=3.56;(3)样本大小:50;解释变量个数(包括常数项):3;d=1.87;(4)样本大小:80;解释变量个数(包括常数项):6;d=1.62;(5)样本大小:100;解释变量个数(包括常数项):5;d=2.41;3、假定存在下表所示的时间序列数据:请回答下列问题:(1)利用表中数据估计模型:t t t x y εββ++=10;(2)利用D-W 检验是否存在自相关?如果存在请用d 值计算估计自相关系数ρ;(3)利用广义差分法重新估计模型:'''1011(1)()t t tt t y y x x ρβρβρε---=-+-+。
第三部分 参考答案二、问答题1、那些原因可以造成自相关?答:造成自相关的原因大致包括以下六个方面:(1)经济变量的变化具有一定的倾向性。
在实际的经济现象中,许多经济变量的现值依赖于他的前期值。
也就是说,许多经济时间序列都有一个明显的相依性特点,这种现象称作经济变量所具有的惯性。
(2)缺乏应有变量的设定偏差。
(3)不正确的函数形式的设定错误。
(4)蛛网现象和滞后效应。
(5)随机误差项的特征。
(6)数据拟合方法造成的影响。
2、存在自相关时,参数的OLS 估计具有哪些性质?答:当存在自相关,即I D ≠ΩΩ=,)(2σε时,OLS 估计的性质有:(1)βˆ是观察值Y 和X 的线性函数;(2)βˆ是β的无偏估计;(3)βˆ的协方差矩阵为112)()()ˆ(--'Ω''=X X X X X X D σβ;(4)βˆ不是β的最小方差线性无偏估计;(5)如果nX X n Ω'∞→lim存在,那么βˆ是β的一致估计;(6)2σ 不是2σ的无偏估计;(7)2σ不是2σ的一致估计。




《计量经济学》实验报告实验课题:各章节案列分析姓名:茆汉成班级:会计学12-2班学号:指导老师:蒋翠侠报告日期:目录第二章简单线性回归模型案例 (1)1 问题引入 (1)2 模型设定 (1)3 估计参数 (3)4 模型检验 (3)第三章多元线性回归模型案例 (5)1 问题引入 (5)2 模型设定 (5)3 估计参数 (6)4 模型检验 (6)第四章多重线性案例 (8)1 问题引入 (8)2 模型设定 (8)3 参数估计 (8)4 对多重共线性的处理 (9)第五章异方差性案例 (10)1 问题引入 (11)2 模型设定 (11)3 参数估计 (11)4 异方差检验 (11)5 异方差性的修正 (14)第六章自相关案例 (14)1 问题引入 (15)2 模型设定 (15)3 用OLS估计 (15)4 自相关其他检验 (15)5 消除自相关 (16)第七章分布滞后模型与自回归模型案例 (18) (19)1 问题引入 (19)2 模型设定 (19)3 参数估计 (19) (20)1 问题引入 (21)2 模型设定 (21)3、回归分析 (21)4模型检验 (23)第八章虚拟变量回归案例 (23)1 问题引入 (24)2 模型设定 (24)3 参数估计 (26)4 模型检验 (27)第二章简单线性回归模型案例1、问题引入居民消费在社会经济的持续发展中有着重要的作用。
适度的居民消费规模和合理的消费模型是人民生活水平的具体体现,有利于经济持续健康的增长。
随着社会信息化程度和居民的收入水平的提高,计算机的运用越来越普及,作为居民耐用消费品重要代表的计算机已经为众多的城镇居民家庭所拥有。
研究中国各地区城镇居民计算机拥有量与居民收入水平的数量关系。
影响居民计算机拥有量的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入水平。
从理论上说居民收入水平越高,居民计算机拥有量越多。
所以我们设定“城镇居民家庭平均每百户计算机拥有量(台)”为被解释变量,“城镇居民平均每人全年家庭总收入(元)”为解释变量。

第六章 案例分析一、研究目的2003年中国农村人口占59.47%,而消费总量却只占41.4%,农村居民的收入和消费是一个值得研究的问题。
消费模型是研究居民消费行为的常用工具。
通过中国农村居民消费模型的分析可判断农村居民的边际消费倾向,这是宏观经济分析的重要参数。
同时,农村居民消费模型也能用于农村居民消费水平的预测。
二、模型设定正如第二章所讲述的,影响居民消费的因素很多,但由于受各种条件的限制,通常只引入居民收入一个变量做解释变量,即消费模型设定为t t t u X Y ++=21ββ(6.43)式中,Y t 为农村居民人均消费支出,X t 为农村人均居民纯收入,u t 为随机误差项。
表6.3是从《中国统计年鉴》收集的中国农村居民1985-2003年的收入与消费数据。
表6.3 1985-2003年农村居民人均收入和消费 单位: 元2000 2001 2002 20032253.40 2366.40 2475.60 2622.241670.00 1741.00 1834.00 1943.30314.0 316.5 315.2 320.2717.64 747.68 785.41 818.86531.85 550.08 581.85 606.81为了消除价格变动因素对农村居民收入和消费支出的影响,不宜直接采用现价人均纯收入和现价人均消费支出的数据,而需要用经消费价格指数进行调整后的1985年可比价格计的人均纯收入和人均消费支出的数据作回归分析。
根据表6.3中调整后的1985年可比价格计的人均纯收入和人均消费支出的数据,使用普通最小二乘法估计消费模型得t t X Y 0.59987528.106ˆ+=(6.44)Se = (12.2238) (0.0214)t = (8.7332)(28.3067)R 2 = 0.9788,F = 786.0548,d f = 17,DW = 0.7706该回归方程可决系数较高,回归系数均显著。
《计量经济学》各章数据第6章多重共线性例6.3.1分析我国居民家庭电力消耗量与可支配收入及居住面积的关系,以预测居民家庭对电力的需求量(具体数据见表6.3.1)。
表6.3.1 我国居民家庭电力消耗量与可支配收入及居住面积统计资料例6.4.2根据表6.4.2,建立我国进口需求与GNP和消费价格指数之间的关系模型。
表6.4.2 我国进口支出与GNP和消费价格指数(单位:亿元人民币)6.5 案例分析——我国旅游市场收入函数根据理论和经验分析,影响国内旅游市场收入Y 的主要因素,除了国内旅游人数和旅游支出以外,还可能与相关基础设施有关。
为此,考虑的影响因素主要有国内旅游人数X 1,城镇居民人均旅游支出X 2,农村居民入均旅游支出X 3,并以公路里程X 4和铁路里程X 5作为相关基础设施的代表。
统计数据如表6.5.1所示。
试估计以下形式的计量经济模型:t t t t t t t u X b X b X b X b X b b Y ++++++=55443322110其中,Y 为全国旅游收入(亿元);X 1为国内旅游人数(万人/次);X 2为城镇居民人均旅游支出(元);X 3为农村居民人均旅游支出(元);X 4为公路里程(万km);X 5为铁路里程(万km)。
表6.5.1 1994~2003年中国旅游收入及相关数据思考与练习8.考虑表1样本数据: 表1 样本数据现假定你想用对和作一多元线性回归模型:t t t t u x +22110。
请回答下列问题:(1)你能估计出这一模型的参数吗?为什么?(2)如果不能,你能估计哪一参数或参数组合?9.表2给出了一组消费支出(y ),周收入(x1)和财富(x2)的假设数据。
表2 消费支出、周收入和财富数据(单位:美元)(1)估计模型: t t t t u x b x b b y +++=22110 (2)解释变量之间存在多重共线性吗?为什么?(3)估计模型:t t t u x b b y ++=110,t t t u x b b y ++=210。
第六章 案例分析
一、研究目的
2003年中国农村人口占59.47%,而消费总量却只占41.4%,农村居民的收入和消费是一个值得研究的问题。
消费模型是研究居民消费行为的常用工具。
通过中国农村居民消费模型的分析可判断农村居民的边际消费倾向,这是宏观经济分析的重要参数。
同时,农村居民消费模型也能用于农村居民消费水平的预测。
二、模型设定
正如第二章所讲述的,影响居民消费的因素很多,但由于受各种条件的限制,通常只引入居民收入一个变量做解释变量,即消费模型设定为
t t t u X Y ++=21ββ
(6.43)
式中,Y t 为农村居民人均消费支出,X t 为农村人均居民纯收入,u t 为随机误差项。
表6.3是从《中国统计年鉴》收集的中国农村居民1985-2003年的收入与消费数据。
表6.3 1985-2003年农村居民人均收入和消费 单位: 元
2000 2001 2002 2003
2253.40 2366.40 2475.60 2622.24
1670.00 1741.00 1834.00 1943.30
314.0 316.5 315.2 320.2
717.64 747.68 785.41 818.86
531.85 550.08 581.85 606.81
为了消除价格变动因素对农村居民收入和消费支出的影响,不宜直接采用现价人均纯收入和现价人均消费支出的数据,而需要用经消费价格指数进行调整后的1985年可比价格计的人均纯收入和人均消费支出的数据作回归分析。
根据表6.3中调整后的1985年可比价格计的人均纯收入和人均消费支出的数据,使用普通最小二乘法估计消费模型得
t t X Y 0.59987528.106ˆ+=
(6.44)
Se = (12.2238) (0.0214)
t = (8.7332)
(28.3067)
R 2 = 0.9788,F = 786.0548,d f = 17,DW = 0.7706
该回归方程可决系数较高,回归系数均显著。
对样本量为19、一个解释变量的模型、5%显著水平,查DW 统计表可知,d L =1.18,d U = 1.40,模型中DW<d L ,显然消费模型中有自相关。
这一点残差图中也可从看出,点击EViews 方程输出窗口的按钮Resids 可得到残差图,如图6.6所示。
图6.6
残差图
图6.6残差图中,残差的变动有系统模式,连续为正和连续为负,表明残差项存在一阶正自相关,模型中t 统计量和F 统计量的结论不可信,需采取补救措施。
三、自相关问题的处理
为解决自相关问题,选用科克伦—奥克特迭代法。
由模型(6.44)可得残差序列e t ,在EViews 中,每次回归的残差存放在resid 序列中,为了对残差进行回归分析,需生成命名为
e 的残差序列。
在主菜单选择Quick/Generate Series 或点击工作文件窗口工具栏中的Procs/ Generate Series ,在弹出的对话框中输入e = resid ,点击OK 得到残差序列e t 。
使用e t 进行滞后一期的自回归,在EViews 命今栏中输入ls e e (-1)可得回归方程
e t = 0.4960 e t-1
(6.45)
由式(6.45)可知ρ
ˆ=0.4960,对原模型进行广义差分,得到广义差分方程 t t t t t u X X Y Y +-+-=---)4960.0()4960.01(4960.01211ββ
(6.46)
对式(6.46)的广义差分方程进行回归,在EViews 命令栏中输入ls Y -0.4960*Y (-1) c
X -0.4960*X (-1),回车后可得方程输出结果如表6.4。
表6.4 广义差分方程输出结果 Dependent Variable: Y-0.496014*Y(-1) Method: Least Squares Date: 03/26/05 Time: 12:32 Sample(adjusted): 1986 2003
Included observations: 18 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob. C
60.44431 8.964957 6.742287 0.0000 X-0.496014*X(-1) 0.583287
0.029410
19.83325
0.0000
R-squared
0.960914 Mean dependent var 231.9218 Adjusted R-squared 0.958472 S.D. dependent var 49.34525 S.E. of regression 10.05584 Akaike info criterion 7.558623 Sum squared resid 1617.919 Schwarz criterion 7.657554 Log likelihood -66.02761 F-statistic 393.3577 Durbin-Watson stat
1.397928 Prob(F-statistic)
0.000000
**5833.04443.60ˆt t X Y +=
(6.47)
)9650.8(=Se (0.0294)
t = (6.7423)
(19.8333)
R 2 = 0.9609 F = 393.3577 d f = 16 DW = 1.3979
式中,1*4960.0ˆ--=t t t Y Y Y ,
1*4960.0--=t t t X X X 。
由于使用了广义差分数据,样本容量减少了1个,为18个。
查5%显著水平的DW 统
计表可知d L = 1.16,d U = 1.39,模型中DW = 1.3979> d U ,说明广义差分模型中已无自相关,不必再进行迭代。
同时可见,可决系数R 2
、t 、F 统计量也均达到理想水平。
对比模型(6.44)和(6.47),很明显普通最小二乘法低估了回归系数2ˆ
β的标准误差。
[原模型中Se (2ˆβ)= 0.0214,广义差分模型中为Se (2ˆ
β)= 0.0294。
经广义差分后样本容量会减少1个,为了保证样本数不减少,可以使用普莱斯—温斯
腾变换补充第一个观测值,方法是21*11ρ-=X X 和21*11ρ-=Y Y 。
在本例中即为
210.49601-X 和210.49601-Y 。
由于要补充因差分而损失的第一个观测值,所以在
EViews 中就不能采用前述方法直接在命令栏输入Y 和X 的广义差分函数表达式,而是要生成X 和Y 的差分序列X *和Y *。
在主菜单选择Quick/Generate Series 或点击工作文件窗口工具栏中的Procs/Generate Series ,在弹出的对话框中输入Y *= Y -0.4960*Y (-1),点击OK 得到广义差分序列Y *,同样的方法得到广义差分序列X *。
此时的X *和Y *都缺少第一个观测值,
需计算后补充进去,计算得*1X =345.236,*
1Y =275.598,双击工作文件窗口的X * 打开序列
显示窗口,点击Edit +/-按钮,将*
1X =345.236补充到1985年对应的栏目中,得到X *的19个观测值的序列。
同样的方法可得到Y *的19个观测值序列。
在命令栏中输入Ls Y * c X*得到普莱斯—温斯腾变换的广义差分模型为
**5833.04443.60t t X Y +=
(6.48)
)1298.9(=Se (0.0297)
t = (6.5178)
(19.8079)
R 2 = 0.9585 F = 392.3519 d f = 19 DW = 1.3459
对比模型(6.47)和(6.48)可发现,两者的参数估计值和各检验统计量的差别很微小,说明在本例中使用普莱斯—温斯腾变换与直接使用科克伦—奥克特两步法的估计结果无显著差异,这是因为本例中的样本还不算太小。
如果实际应用中样本较小,则两者的差异会较大。
通常对于小样本,应采用普莱斯—温斯腾变换补充第一个观测值。
由差分方程(6.46)有
9292
.1194960.014443
.60ˆ1
=-=β
(6.49)
由此,我们得到最终的中国农村居民消费模型为 Y t = 119.9292+0.5833 X t
(6.50)
由(6.50)的中国农村居民消费模型可知,中国农村居民的边际消费倾向为0.5833,即中国农民每增加收入1元,将增加消费支出0.5833元。