最新多元统计分析第三章 假设检验与方差分析
- 格式:doc
- 大小:1.39 MB
- 文档页数:27


第三章 多元假设检验3.1 实例从本节开始,我们转入多元统计的实际应用。
在实际问题中,有时要同时考虑多个随机性的指标,而且这些指标之间还存在着一定的联系。
例如,检查某人的健康情况,就得检查这个人的体重、体温、血压、心脏等多项指标。
一般仅是单项指标异常还不能立即诊断是什么原因,而必须对各项指标综合分析,才能作出结论。
多元统计分析的精髓之一就是必须对p 个相关变量同时进行分析。
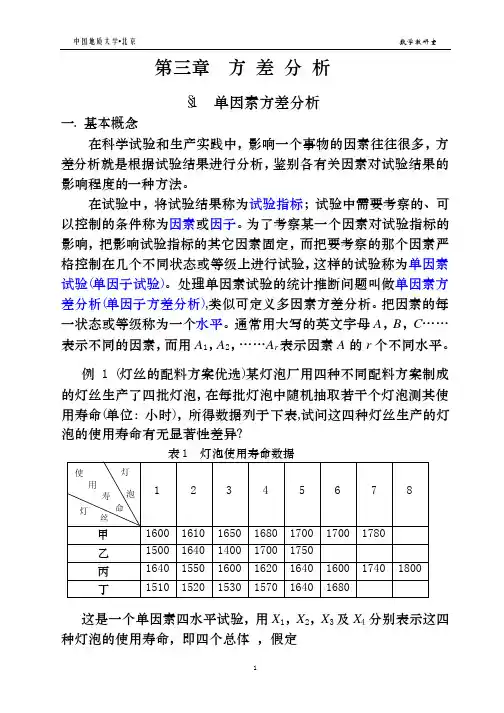
首先让我们看2个例子:例3.1测量20名健康女性排汗量1x 、钠含量2x 、钾含量3x 得表3.1。
问健康女性1x 、2x 、3x 的均值是不是4、50、10?表3.1 20名健康女性排汗量1x 、钠含量2x 、钾含量3x 数据例 3.2 为了研究日美两国在华企业对中国经营环境的评价是否存在差异,从两国在华企业对中国的政治、经济、法律、文化等环境打分,得表3.2。
试分析日美两国在华企业对中国经营环境的评价是否存在差异?表3.2这些问题涉及多个项目同时比较,例如例3.1要检验3个指标(1x )=4,E(2x )=50,E(3x )=10是否同时成立?例3.2要检验美日两国企业四个评价指标是否相同?Ey1=Ex1,Ey2=Ex2,Ey3=Ex3,Ey4=Ex4是否同时成立?本章总作多元正态假设:设)',...,(21p x x x x =服从),(∑μN 。
例3.1和例3.2即是要做复合检验⎥⎥⎦⎤⎢⎢⎣⎡=⎥⎥⎦⎤⎢⎢⎣⎡10504321μμμ和⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡43214321y y y y x x x x μμμμμμμμ 按照概率论基础知识的方法,我们可以对每个指标进行t 检验或F 检验。
例如对例1先检验E(1x )=4, 再检验E(2x )=50,然后再检验E(3x )=10。
但是可能会遇到这样的情况:单独检验E(1x )=4不否定原命题(例如接受概率P(A)=0.4),再单独检验E(2x )=50也不否定原命题(例如接受概率P(B)=0.5);而单独检验E(3x )=10也不否定原命题(例如接受概率P(C)=0.6);但是联合起来检验E(1x )=4,E(2x )=50,E(3x )=10,接受域概率P(ABC)是0与0.4间的不定数,依A 、B 、C 的关系而定:若A 、B 、C 重合,则P(ABC)=0.4;若A 和B 互斥,则P(ABC)=0。








第一章绪论§1.1 什么是多元统计分析在工业、农业、医学、气象、环境以及经济、管理等诸多领域中,常常需要同时观测多个指标。
例如,要衡量一个地区的经济发展,需要观测的指标有:总产值、利润、效益、劳动生产率、万元生产值能耗、固定资产、流动资金周转率、物价、信贷、税收等等;要了解一种岩石,需观测或化验的指标也很多,如:颜色、硬度、含碳量、含硫量等等;要了解一个国家经济发展的类型也需观测很多指标,如:人均国民收入,人均工农业产值、人均消费水平等等。
在医学诊断中,要判断某人是有病还是无病,也需要做多项指标的体检,如:血压、心脏脉搏跳动的次数、白血球、体温等等。
总之,在科研、生产和日常生活中,受多种指标共同作用和影响的现象是大量存在的,举不胜举。
上述指标,在数学上通常称为变量,由于每次观测的指标值是不能预先确定的,因此每个指标可用随机变量来表示。
如何同时对多个随机变量的观测数据进行有效的统计分析和研究呢?一种做法是把多个随机变量分开分析,一次处理一个去分析研究;另一种做法是同时进行分析研究。
显然前者做法有时是有效的,但一般来说,由于变量多,避免不了变量之间有相关性,如果分开处理不仅会丢失很多信息,往往也不容易取得好的研究结果。
而后一种做法通常可以用多元统计分析方法来解决,通过对多个随机变量观测数据的分析,来研究变量之间的相互关系以及揭示这些变量内在的变化规律,如果说一元统计分析是研究一个随机变量统计规律的学科,那么多元统计分析则是研究多个随机变量之间相互依赖关系以及内在统计规律性的一门统计学科,同时,利用多元分析中不同的方法还可以对研究对象进行分类(如指标分类或样品分类)和简化(如把相互依赖的变量变成独立的或降低复杂集合的维数等等)。
在当前科技和经济迅速发展的今天,在国民经济许多领域中特别对社会经济现象的分析,只停留在定性分析上往往是不够的。
为提高科学性、可靠性,通常需要定性与定量分析相结合。
实践证明,多元分析是实现做定量分析的有效工具。
第三章⽅差分析(11.18)第三章⽅差分析在⽣产、研究等⼯作中经常要对在不同条件下进⾏观察或试验得到的数据进⾏分析,以判断不同条件对结果有⽆影响。
这时,就需要进⾏⽅差分析。
第⼀节⽅差分析的基本问题⼀、⽅差分析研究的问题⽅差分析是检验若⼲个具有相同⽅差的正态总体的均值是否相等的⼀种假设检验⽅法。
例如,我们要研究不同化肥品种(甲种、⼄种)与某农作物的关系,测定是否不同化肥的增产效果也不同。
则通过⽐较不同品种组的平均数的差异来反映分组变量(如化肥)对因变量(如农作物产量)的影响和作⽤,这就是⽅差分析要解决的内容。
在⽅差分析中,常常⽤到以下术语:响应,是指观察指标的结果或试验结果为响应。
如农作物的产量为响应。
因⼦(因素),是指在观察中或在试验中改变其状态时对响应产⽣影响的因素,也称为因⼦。
如⽤来进⾏分组研究的变量化肥就是因素或因⼦。
⽔平,是指因⼦(因素)在观察或试验中所取的状态称为因⼦(因素)的⽔平。
如化肥的种类甲种、⼄种就是因素的⽔平。
⽅差分析主要有两种。
如果⽅差分析只针对⼀个因素进⾏,称为单因素⽅差分析。
如果同时对多个因素进⾏,称为多因素分析。
在⽅差分析中,通常假定在同⼀条件下的试验结果是来⾃正态总体的⼀个样本;不同条件下的正态总体是相互独⽴的,它们的期望可能不同,但⽅差相同。
要判断不同条件对响应有⽆影响就是要检验各个正态总体的均值是否相等。
在实际应⽤时,⼀般应近似地符合上述要求。
⼆、⽅差分析的基本思想从⽅差分析的⽬的看,是要检验各个正态总体的均值是否相等,⽽实现这个⽬的的⼿段是通过⽅差的⽐较。
我们知道,观察值之间存在着差异,差异的产⽣来⾃于两个⽅⾯,⼀⽅⾯是由因素中的不同⽔平造成的,称为系统性差异;另⼀个⽅⾯是由于抽选样本的随机性⽽产⽣的差异。
两个⽅⾯产⽣的差异可以⽤两个⽅差来计量,⼀个称为⽔平之间的⽅差,⼀个称为⽔平内部的⽅差。
前者既包括系统性因素,也包括随机性因素。
后者仅包括随机性因素。
如果不同⽔平对结果没有影响,那么在⽔平之间的⽅差中,就仅仅有随机因素的差异,⽽没有系统性差异,它与⽔平内部⽅差就应该近似,两个⽅差的⽐值就会接近于1;反之,如果不同的⽔平对结果产⽣影响,在⽔平之间的⽅差中就不仅包括了随机性差异,也包括了系统性差异。
多元统计分析第三章假设检验与方差分析第3章 多元正态总体的假设检验与方差分析从本章开始,我们开始转入多元统计方法和统计模型的学习。
统计学分析处理的对象是带有随机性的数据。
按照随机排列、重复、局部控制、正交等原则设计一个试验,通过试验结果形成样本信息(通常以数据的形式),再根据样本进行统计推断,是自然科学和工程技术领域常用的一种研究方法。
由于试验指标常为多个数量指标,故常设试验结果所形成的总体为多元正态总体,这是本章理论方法研究的出发点。
所谓统计推断就是根据从总体中观测到的部分数据对总体中我们感兴趣的未知部分作出推测,这种推测必然伴有某种程度的不确定性,需要用概率来表明其可靠程度。
统计推断的任务是“观察现象,提取信息,建立模型,作出推断”。
统计推断有参数估计和假设检验两大类问题,其统计推断目的不同。
参数估计问题回答诸如“未知参数θ的值有多大?”之类的问题,而假设检验回答诸如“未知参数θ的值是0θ吗?”之类的问题。
本章主要讨论多元正态总体的假设检验方法及其实际应用,我们将对一元正态总体情形作一简单回顾,然后将介绍单个总体均值的推断, 两个总体均值的比较推断,多个总体均值的比较检验和协方差阵的推断等。
3.1一元正态总体情形的回顾一、 假设检验在假设检验问题中通常有两个统计假设(简称假设),一个作为原假设(或称零假设),另一个作为备择假设(或称对立假设),分别记为0H 和1H 。
1、显著性检验为便于表述,假定考虑假设检验问题:设1X ,2X ,…,n X 来自总体),(2σμN 的样本,我们要检验假设100:,:μμμμ≠=H H (3.1)原假设0H 与备择假设1H 应相互排斥,两者有且只有一个正确。
备择假设的意思是,一旦否定原假设0H ,我们就选择已准备的假设1H 。
当2σ已知时,用统计量nX z σμ-=在原假设0H 成立下,统计量z 服从正态分布z )1,0(~N ,通过查表,查得)1,0(N 的上分位点2αz 。
对于检验问题(3.1.1),我们制定这样一个检验规则(简称检验): 当2αz z >时,拒绝0H ;当2αz z ≤时,接受0H 。
(3.2) 我们称2αz 为临界值,是)1,0(N 的上分位点,不同的临界值代表不同的检验。
称拒绝原假设0H 的统计量z 的范围为拒绝域,称接受0H 的统计量z 的范围为接受域,因此给出一个检验,就是给出一个拒绝域。
2、两类错误由于样本具有随机性,因此在根据样本进行判断时,有可能犯两种类型的错误。
一类错误是,原假设0H 本来正确,但按检验规则却作出了拒绝0H 的判断,这类错误称为第一类错误(弃真错误),其发生的概率{}αα=>2z z P 称为犯第一类错误的概率;另一类错误时,原假设0H 本来不正确,但按检验规则却作出了接收0H 的判断,这类错误称为第二类错误(存伪错误),其发生的概率称为犯第二类错误的概率,记为β。
同时控制这两类错误是困难的,当时在样本容量n 固定的条件下,要使α和β同时减小,通常是不可能的。
在假设检验的应用中,由奈曼(NEYMAN)与皮尔逊(PEARSON)提出了一个原则,即在控制犯第一类错误的概率α条件下,尽量使犯第二类错误的概率β小,这种检验问题, 称为显著性检验问题。
根据这一原则,原假设受到保护,不至于被轻易拒绝,一旦检验结果拒绝了原假设,则表明拒绝的理由是充分的,如果接受了原假设,则只是表明拒绝的理由还不充分,未必意味着原假设就是正确的。
所以,在实际问题中,为了通过样本观测值对某一猜测取得强有力的支持,通称我们把这一猜测的否定作为原假设,而把猜测本身作为备择假设。
3、关于检验的p 值下面,我们再介绍进行检验的另一种方式——p 值,我们就以(3.1.1)的检验问题为例来加以说明,对于样本,我们通过统计量,计算出nx z σμ00-=,是一确定值,这里的x 是样本观测值的均值,再由统计量z 服从正态分布z )1,0(~N ,计算}{0z z P >为检验的p 值。
由于αz z >等价于p =}{0z z P >{}αα=>≤2z z P ,所以检验规则可以表述为: 当α≤p 时,拒绝0H ;当α>p 时,接受0H 。
接受0H 。
(3.3) 上述p 值的检验规则与(3.1.2)的检验结果相比含有更丰富的信息,p 值越小,拒绝原假设的理由就充分。
通常SAS 等软件的计算机输出一般只给出p 值,由你自己给定的α值来判断检验结果二、单一变量假设检验的回顾 1、 单个正态总体均值的检验考虑假设检验问题:设1X ,2X ,…,n X 来自总体),(2σμN 的样本,我们要检验假设100:,:μμμμ≠=H H(1) 总体方差2σ已知构造统计量nX z σμ-=在原假设H 成立下, z 服从正态分布z )1,0(~N ,可得这样一个检验规则: 当2αz z >时,拒绝0H ; 当αz z ≤时,接受H 。
(2) 总体方差2σ未知构造统计量nsX t μ-=在原假设0H 成立下,t 服从自由度为1-n 的t 分布t )1(~-n t 可得这样一个检验规则:当)1(2->n t t α时,拒绝H ;当)1(-≤n t t α时,接受0H 。
(3.1.4)2、 两个正态总体均值的比较检验 考虑假设检验问题 211210:,:μμμμ≠=H H (3.1.5)设121,,,n X X X 是取自总体),(211σμN 的容量为1n 的样本,221,,,n Y Y Y 是取自),(222σμN 的容量为2n 的样本,给定显著性水平α。
(1) 两个总体方差21σ和22σ已知 构造检验统计量222121n n YX z σσ+-=(3.1.6)在原假设H 成立下, z 服从正态分布z )1,0(~N ,检验规则为:当2αz z >时,拒绝0H ; 当αz z ≤时,接受H 。
(2) 两个总体方差21σ和22σ都未知,但21σ=22σ=2σ 用样本方差s 代替σ,构造检验统计量2111n n s YX t +-=在原假设H 成立下,t 服从正态分布t )2(~21-+n n t ,检验规则为:当)2(212-+>n n t t α时,拒绝0H ;当)2(212-+≤n n t t α时,接受H 。
3、多个正态总体均值的比较检验(方差分析)设k 个正态总体分别为),(21σμN ,),(22σμN ,…, ),(2σμk N 从k 个总体取i n 个独立样本如下:)()(2)(1)1(1)1(2)1(1k nkk k n X X X X X X考虑假设检验问题,:210k H μμμ=== j i j i H μμ≠≠使至少存在,:1假设0H 成立条件下,构造检验统计量为:)/()1/(k n SSE k SSA F --=),1(~k n k F -- 这里∑=-=ki ii X Xn SSA 12)(称为组间平方和;∑∑==-=k i i i j n j X X SSE i12)(1)(称为组内平方和;∑∑==-=ki i jn j X XSST i12)(1)(称为总平方和。
其中=i X ∑=nj i jiXn 1)(1,=X ∑∑==k i n j i j X n 11)(1 k n n n n ++=21给定检验水平α,查F 分布表,使{}αα=>F F P ,可确定出临界值αF ,再利用样本值计算出F 值,若>F αF ,则拒绝0H ,否则不能拒绝0H 。
附注:多元假设检验与SAS 过程本章的主要内容是多元假设检验和方差分析,其中的计算一般都很复杂,可用国际上著名的专业软件——SAS 软件计算。
SAS 中有GLM ,ANOVA 和NESTED 等过程可用方差分析。
其中GLM 过程最常用。
SAS 的GLM 过程采用了一般线性模型: ε++++=m m x b x b b y (110)在方差分析问题中,变量 m x x ...1是示性变量,即只取0或1的变量。
GLM 过程对每一因子的每一水平,通过CLASS 语句产生1个示性变量,也称分类变量。
GLM 过程主要有四个语句:PROC GLM ,CLASS ,MODEL 和LSMEANS 语句。
PROC GLM 语句 用以调用GLM 过程,有许多选项,一般形式是: Proc glm [data=数据集名称] [outstat=输出的统计量][order=formatted|freq|data|internal];CLASS 语句 说明哪些变量是分类变量。
方差分析中的因素都是分类变量,如:Class V1 V2 V3;此语句指示计算机把因子V1,V2 ,V3作为分类变量,可以是字符型变量或数字型变量。
如果是字符型变量,长度限于10个字符以内。
MODEL 语句 语句中等号前是响应变量,如: Model Y=A ; 单因子ANOVA Model Y=A B C ; 主效应模型Model Y=A B A*B ; 含交互效应的因子模型 Model Y1 Y2=A B ; 多因子方差模型MANOVA LSMEANS 语句 用以求待估参数的最小二乘估计。
Lsmeans A B A*B ;MANOVA 语句 用以说明是做多元方差分析。
3.2 均值等于常数向量的检验在经济生产、管理决策中的很多实际问题,通常要选取多个指标进行考察,根据历史数据,将p 项指标的历史平均水平记作0 ,考虑新的p 项指标平均值是否与历史数据记载的平均值有明显差异?若有差异,进一步分析差异主要在哪些指标上,先看下面的实例:例3.1测量20名健康女性排汗量1x 、钠含量2x 、钾含量3x 得表3.1。
问健康女性1x 、2x 、3x 的均值是不是4、50、10?表3-1 20名健康女性排汗量1x 、钠含量2x 、钾含量3x 数据例3.1的数学模型就是:)',,(321x x x x =服从),(∑μN 要根据20个样品做复合检验:⎥⎥⎦⎤⎢⎢⎣⎡≠⎥⎥⎦⎤⎢⎢⎣⎡⎥⎥⎦⎤⎢⎢⎣⎡=⎥⎥⎦⎤⎢⎢⎣⎡10504:,10504:32113210μμμμμμH H一般的,我们考虑p 维正态分布均值等于常数的检验问题:n X X X ,,,21 为取自p 维正态总体),(1∑μp N 的一个样本,要检验:0100:;:μμμμ≠=H H , (3.4)其中0μ为已知p 维向量。
对于这样一个检验问题,分为以下两种情形: 一、协方差阵∑已知条件下,均值μ的检验作出假设后,需要构造一个合适的统计量。
要检验的假设在形式上同一维情形是一样的。
0100:;:μμμμ≠=H H在一维时构造的统计量为n X U 0σμ-=且在0H 成立时,U 服从正态分布)1,0(N 。