总体均值μ的置信区间为
- 格式:ppt
- 大小:1.03 MB
- 文档页数:41

1浙江省2018年10月高等教育自学考试医药数理统计试题课程代码:10192一、填空题(本大题共10小题,每小题2分,共20分) 请在每小题的空格中填上正确答案。
错填、不填均无分。
1.设A 、B 相互独立,P (B )=0.4,P (A )≠0,则P (B|A )的值为_____________.2.设A 、B 互不容,P (A ∪B )=0.7,P (A )=0.2,则P (B )=_____________.3.在20个药丸中有4丸已失效,从中任取3丸,其中有2丸失效的概率为___________ .4.设随机变量X~N(μ,σ2),且其概率密度为6)1(261)(--=x ex f π,则有μ=____________.5.设X 的分布函数为⎪⎩⎪⎨⎧≥<≤<=1,1,10,0,0)(2x x x x x F 则X 的密度函数为_____________.6.设随机变量X的分布律为则X 的期望E(X)=_____________.7.设X 的分布律为P(X=k)=k10C 0.4k 0.610-k ,k=0,1,2,…,10,则X 的方差为_____________.8.设总体X~N(μ,σ2),X 1,X 2,…,X n 是总体X 的一个样本,X 为样本均值,S 2为样本方差,检验假设H 0∶σ=σ0,H 1∶σ≠σ0所用统计量为_____________ . 9.设随机变量U~χ2(n 1),V~χ2(n 2),且U ,V 相互独立,则称随机变量1221//n n V U n V n U F •==服从自由度为_____________的_____________分布.10.在多因素试验中,不仅各因素单独对指标起作用,有时还可能存在因素之间的联合作用,这种联合作用称为_____________.二、单项选择题(本大题共8小题,每小题3分,共24分)在每小题列出的四个备选项中只有一个是符合题目要求的,请将其代码填写在题后的括号内。

平均值的置信区间什么是置信区间?统计学家经常必须从样本数据推断总体数据的特征。
在这个过程中,一个单独的样本本身代表的是总体的一部分,因此不能仅仅依靠简单地描述样本来了解总体。
这就是置信区间的意义所在。
置信区间是总体平均值的一个估计值,因此是样本平均值的范围。
平均值的置信区间是一种用来估计某个总体参数范围的工具。
换句话说,它是一个实数区间,可能包含某个待估计参数的真实值。
例如,如果我们根据样本数据计算出来的平均值是12,那么我们可能会使用置信区间来推断总体平均值的真实值(假设总体符合正态分布)。
这个置信区间告诉我们,在一定置信度下,总体平均值可能位于某个范围内,例如11至13之间。
在置信区间的范围内,我们可以以某一个概率推测待估计参数的真实值。
但是,由于我们只能够进行样本数据的抽样,因此我们无法知道总体的真实情况,也无法肯定某个置信区间是否覆盖了总体真实值。
因此,置信区间只是一个通过样本数据估计总体数据的工具,不能对总体答案的正确性做出绝对保证。
置信区间的理论基础置信区间的关键是$t$分布。
$t$分布是概率论和统计学中的一个重要分布。
在统计推断中,为计算总体平均值的置信区间而被广泛使用。
$t$分布是由William S. Gossett发明的,是在样本量较小、总体标准差未知的情況下针对总体平均值的推断所采用的一种概率分布。
当样本容量较少时,总体标准差通常被视为不知道。
此时,如果使用普通的$z$分布进行推断,则推断的误差非常大。
而当样本容量较大时,通常可以将总体标准差视为已知。
这时,我们可以使用$z$分布进行推断。
但是,如果我们无法确认总体标准差,却需要进行总体平均值的推断,那么我们就可以使用$t$分布。
$t$分布与正态分布不同,它没有一个固定的标准差。
相反,它的标准差是根据样本数据中的方差估计得出的。
与正态分布相比,$t$分布的曲线更高、更平,它的尾部比正态分布更粗、更长。
在样本容量较小(小于30)时,$t$分布对总体平均值的估计要比正态分布更准确。

数理统计练习题1.设4321,,,X X X X 是总体),(2σμN 的样本,μ已知,2σ未知,则不是统计量的是〔 〕.〔A 〕415X X +; 〔B 〕41ii Xμ=-∑;〔C 〕σ-1X ; 〔D 〕∑=412i iX.解: 统计量是不依赖于任何未知参数的连续函数. ∴ 选C.2.设总体n X X X p B X ,,,),,1(~21 为来自X 的样本,则=⎪⎭⎫⎝⎛=n k X P 〔 〕. 〔A 〕p ; 〔B 〕p -1;〔C 〕k n k k n p p C --)1(; 〔D 〕k n k kn p p C --)1(.解:n X X X 21相互独立且均服从),1(p B 故 ∑=ni ip n B X1),(~即 ),(~p n B X n 则()()(1)k k n k n k P X P nX k C p p n-====- ∴ 选C.3.设n X X X ,,,21 是总体)1,0(N 的样本,X 和S 分别为样本的均值和样本标准差,则〔 〕.〔A 〕)1(~/-n t S X ; 〔B 〕)1,0(~N X ;〔C 〕)1(~)1(22--n S n χ; 〔D 〕)1(~-n t X n .解:∑==ni i X n X 110=X E ,)1,0(~112n N X n n n X D ∴== B 错 )1(~)1(222--n S n χσ)1(~)1(1)1(2222--=-∴n S n S n χ )1(~-n t n SX . ∴ A 错.∴ 选C.4.设n X X X ,,,21 是总体),(2σμN 的样本,X 是样本均值,记=21S ∑∑∑===--=-=--n i n i n i i i i X n S X X n S X X n 1112232222)(11,)(1,)(11μ,∑=-=ni i X n S 1224)(1μ,则服从自由度为1-n 的t 分布的随机变量是〔〕.〔A 〕1/1--=n S X T μ;〔B 〕1/2--=n S X T μ;〔C 〕nS X T /3μ-=;〔D 〕n S X T /4μ-=解:)1(~)(2212--∑=n X Xni iχσ)1,0(~N n X σμ-)1(~1)(1122----=∑=n t n X XnX T ni iσσμ)1(~11/)(222---=--=n t n S X n nS nX T μμ ∴选B.5.设621,,,X X X 是来自),(2σμN 的样本,2S 为其样本方差,则2DS 的值为〔〕. 〔A 〕431σ;〔B 〕451σ;〔C 〕452σ;〔D 〕.522σ 解:2126,,,~(,),6X X X N n μσ=∴)5(~5222χσS由2χ分布性质:1052522=⨯=⎪⎪⎭⎫ ⎝⎛σS D即442522510σσ==DS ∴选C.6.设总体X 的数学期望为n X X X ,,,,21 μ是来自X 的样本,则下列结论中正确的是〔〕. 〔A 〕1X 是μ的无偏估计量; 〔B 〕1X 是μ的极大似然估计量; 〔C 〕1X 是μ的一致〔相合〕估计量; 〔D 〕1X 不是μ的估计量. 解:11EX EX X μ==∴是μ的无偏估计量.∴选A.7.设n X X X ,,,21 是总体X 的样本,2,σμ==DX EX ,X 是样本均值,2S 是样本方差,则〔〕.〔A 〕2~,X N n σμ⎛⎫ ⎪⎝⎭;〔B 〕2S 与X 独立; 〔C 〕)1(~)1(222--n S n χσ;〔D 〕2S 是2σ的无偏估计量.解:已知总体X 不是正态总体 ∴〔A 〕〔B 〕〔C 〕都不对. ∴选D.8.设n X X X ,,,21 是总体),0(2σN 的样本,则〔 〕可以作为2σ的无偏估计量.〔A 〕∑=n i i X n 121; 〔B 〕∑=-n i i X n 1211; 〔C 〕∑=n i i X n 11; 〔D 〕∑=-ni i X n 111.解:2222)(,0σ==-==i i i i i EX EX EX DX EX22121)1(σσ=⋅=∑n nX n E n i ∴选A.9.设总体X 服从区间],[θθ-上均匀分布)0(>θ,n x x ,,1 为样本,则θ的极大似然估计为〔 〕〔A 〕},,max {1n x x ; 〔B 〕},,min{1n x x 〔C 〕|}|,|,max {|1n x x 〔D 〕|}|,|,min{|1n x x解:1[,]()20x f x θθθ⎧∈-⎪=⎨⎪⎩其它似然正数∏==ni i n x f x x L 11),();,,(θθ 1,||1,2,,(2)0,i nx i n θθ⎧≤=⎪=⎨⎪⎩其它此处似然函数作为θ函数不连续 不能解似然方程求解θ极大似然估计∴)(θL 在)(n X =θ处取得极大值|}|,|,max{|ˆ1nn X X X ==θ ∴选C.10.设总体X 的数学期望为12,,,,n X X X μ为来自X 的样本,则下列结论中正确的是〔A 〕1X 是μ的无偏估计量. 〔B 〕1X 是μ的极大似然估计量. 〔C 〕1X 是μ的相合〔一致〕估计量. 〔D 〕1X 不是μ的估计量. 〔 〕 解:1EX μ=,所以1X 是μ的无偏估计,应选〔A 〕. 11.设12,,,n x x x 为正态总体(,4)N μ的一个样本,x 表示样本均值,则μ的置信度为1α-的置信区间为 〔A 〕/2/2(x u x u αα-+ 〔B 〕1/2/2(x u x u αα--+ 〔C 〕(x u x uαα-+ 〔D 〕/2/2(x u x u αα-+ 解:因为方差已知,所以μ的置信区间为/2/2(X u X u αα-+应选D.12.设总体 X ~ N ( μ , σ2 ),其中σ2已知,则总体均值μ的置信区间长度L 与置信度1-α的关系是(a) 当1-α缩小时,L 缩短. (b) 当1-α缩小时,L 增大. (c) 当1-α缩小时,L 不变. (d) 以上说法均错.解:当σ2已知时,总体均值μ的置信区间长度为当1-α缩小时,L 将缩短,故应选〔a) 13.设总体 X ~ N ( μ1 , σ12 ), Y ~ N ( μ2 , σ22 ) ,X 和Y 相互独立,且μ1 , σ12,μ2 , σ22均未知,从X 中抽取容量为n 1 =9的样本,从Y 中抽取容量为n 2 =10的样本分别算得样本方差为 S 12 =63.86, S 22=236.8对于显著性水平α=0.10〔0< α <1〕,检验假设H 0 : σ12 = σ22; H 1 : σ12≠σ22则正确的方法和结论是[ ](a)用F 检验法,查临界值表知F 0.90(8 ,9)=0.40, F 0.10(8,9)=2.47 结论是接受H 0(b)用F 检验法,查临界值表知F 0.95(8,9)=0.31, F 0.05(8,9)=3.23 结论是拒绝H 0 (c)用t 检验法,查临界值表知t 0.05(17)=2.11结论是拒绝H 0 (d)用χ2检验法,查临界值表知χ2 0.10(17)=24.67结论是接受H 0解:这是两个正态总体均值未知时,方差的检验问题,要使用F 检验法。

第2章2.1 解:()1 这种抽样方法是等概率的。
在每次抽取样本单元时,尚未被抽中的编号为1~64的这些单元中每一个单元被抽到的概率都是1100。
()2这种抽样方法不是等概率的。
利用这种方法,在每次抽取样本单元时,尚未被抽中的编号为1~35以及编号为64的这36个单元中每个单元的入样概率都是2100,而尚未被抽中的编号为36~63的每个单元的入样概率都是1100。
()3这种抽样方法是等概率的。
在每次抽取样本单元时,尚未被抽中的编号为20 000~21 000中的每个单元的入样概率都是11000,所以这种抽样是等概率的。
2.3 解:首先估计该市居民日用电量的95%的置信区间。
根据中心极限定理可知,在大_y E y y -=近似服从标准正态分布, _Y 的195%α-=的置信区间为y z y z y y αα⎡⎡-+=-+⎣⎣。
而()21f V y S n-=中总体的方差2S 是未知的,用样本方差2s 来代替,置信区间为,y y ⎡⎤-+⎢⎥⎣⎦。
由题意知道,_29.5,206y s ==,而且样本量为300,50000n N ==,代入可以求得 _21130050000()2060.6825300f v y s n --==⨯=。
将它们代入上面的式子可得该市居民日用电量的95%置信区间为7.8808,11.1192⎡⎤⎣⎦。
下一步计算样本量。
绝对误差限d 和相对误差限r 的关系为_d rY =。
根据置信区间的求解方法可知____11P y Y r Y P αα⎫⎪⎧⎫-≤≥-⇒≤≥-⎨⎬⎩⎭根据正态分布的分位数可以知道1P Z αα⎫⎪⎪≤≥-⎬⎪⎪⎭,所以()2_2rY V y z α⎛⎫⎪= ⎪⎝⎭。
也就是2_2_222/221111r Y r Y S n N z S n N z αα⎡⎤⎛⎫⎢⎥⎛⎫⎪⎛⎫⎝⎭⎪⎢⎥-=⇒=+ ⎪ ⎪⎢⎥⎝⎭⎝⎭⎢⎥⎣⎦。
把_29.5,206,10%,50000y s r N ====代入上式可得,861.75862n =≈。


生物统计学知到章节测试答案智慧树2023年最新烟台大学绪论单元测试1.概率论是研究随机现象数量规律的数学分支。
参考答案:对2.在18世纪概率论引进之后,统计才逐渐发展成为一门成熟的学科。
参考答案:对3.同质基础上的变异是随机现象的基本属性。
参考答案:对4.同质性是总体的基本特征。
参考答案:对5.抽样研究的目的是用有限的样本信息推断总体特征。
参考答案:对6.变异是导致抽样误差的根本原因。
参考答案:对7.参数是描述样本特征的指标。
参考答案:错8.数理统计以概率论为基础,通过对随机现象观察数据的收集整理和分析推断来研究其统计规律。
参考答案:对9.统计方法体系的主体内容是参考答案:推断10.统计学的主要研究内容包括参考答案:数据分析;数据整理;数据解释;数据收集第一章测试1.各样本观察值均加同一常数c后参考答案:样本均值改变,样本标准差不变2.关于样本标准差,以下叙述错误的是参考答案:不会小于样本均值3.表示定性数据整理结果的统计图有条形图、圆形图。
参考答案:对4.直方图、频数折线图、茎叶图、箱图是专用于表示定量数据的特征和规律的统计图。
参考答案:对5.描述数据离散程度的常用统计量主要有极差、方差、标准差、变异系数等,其中最重要的是方差、标准差。
参考答案:对6.统计数据可以分为定类数据、定序数据和数值数据等三类,其中定类数据、定序数据属于定性数据。
参考答案:对7.描述数据集中趋势的常用统计量主要有均值、众数和中位数等,其中最重要的是均值。
参考答案:对8.己知某城市居民家庭月人均支出(元)<200,200-500,500-800,800-1000和>1000五个档次的家户庭数占总户数比例(%)分别为1.5,18.2,46.8,25.3,8.2。
则根据上述统计数据计算该市平均每户月人均支出的均值为687.3。
参考答案:对9.己知某城市居民家庭月人均支出(元)<200,200-500,500-800,800-1000和>1000五个档次的家户庭数占总户数比例(%)分别为1.5,18.2,46.8,25.3,8.2。

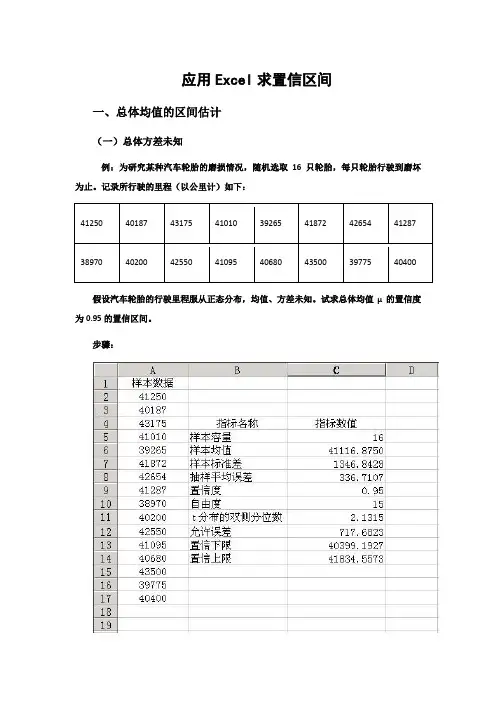
应用Excel求置信区间一、总体均值的区间估计(一)总体方差未知例:为研究某种汽车轮胎的磨损情况,随机选取16只轮胎,每只轮胎行驶到磨坏为止。
记录所行驶的里程(以公里计)如下:41250 40187 43175 41010 39265 41872 42654 41287 38970 40200 42550 41095 40680 43500 39775 40400假设汽车轮胎的行驶里程服从正态分布,均值、方差未知。
试求总体均值μ的置信度为0.95的置信区间。
步骤:1.在单元格A1中输入“样本数据”,在单元格B4中输入“指标名称”,在单元格C4中输入“指标数值”,并在单元格A2:A17中输入样本数据。
2.在单元格B5中输入“样本容量”,在单元格C5中输入“16”。
3.计算样本平均行驶里程。
在单元格B6中输入“样本均值”,在单元格C6中输入公式:“=AVERAGE(A2,A17)”,回车后得到的结果为41116.875。
4.计算样本标准差。
在单元格B7中输入“样本标准差”,在单元格C7中输入公式:“=STDEV(A2,A17)”,回车后得到的结果为1346.842771。
5.计算抽样平均误差。
在单元格B8中输入“抽样平均误差”,在单元格C8中输入公式:“=C7/SQRT(C5)” ,回车后得到的结果为336.7106928。
6.在单元格B9中输入“置信度”,在单元格C9中输入“0.95”。
7.在单元格B10中输入“自由度”,在单元格C10中输入“15”。
8.在单元格B11中输入“t分布的双侧分位数”,在单元格C11中输入公式:“ =TINV(1-C9,C10)”,回车后得到α=0.05的t分布的双侧分位数t=2.1315。
9.计算允许误差。
在单元格B12中输入“允许误差”,在单元格C12中输入公式:“=C11*C8”,回车后得到的结果为717.6822943。
10.计算置信区间下限。
在单元格B13中输入“置信下限”,在单元格C13中输入置信区间下限公式:“=C6-C12”,回车后得到的结果为40399.19271。

二)组距分组次数分布表(重点。
简单应用)若观测变量的取值变动均匀,则应采用等距分组。
分组的组数不宜太少,也不宜过多。
1.确定组数:记变量值的个数为N,组数为m,则斯特吉斯公式为:m=1+3.322lgNlg20=lg2+1=1.3010lg60=lg2+lg3+1=0.3010+0.4771+1=1.7781lg50=1.6989lg2=0.3010lg3=0.4771lg5=0.6990lg7=0.8451 这几个是应该记住的。
非常实用等距分组的组距为w,则由下式可计算出w的最低值为:W=【max(xi)-min(xi)】/m(一)算术平均数算术平均数又称均值,它是一组变量值的总和与其变量值的个数总和的比值,是测度变量分布中心最常用的指标。
1.简单算术平均数=(x1+x2+…+x n)/n2.加权算术平均数=Σx i f i/Σf i=Σx i*(f i/Σf i)式中f i/Σf i为各组的频率。
(2)组距数列算术平均数的计算方法。
组中值=(上限+下限)/2缺下限组的组中值=上限-邻组组距/2 缺上限组的组中值=下限+邻组组距/23.应用算术平均数应注意的几个问题(1)算术平均数容易受极端变量值的影响。
2)权数对算术平均数大小起着权衡轻重的作用,但不取决于它的绝对值的大小,而是取决于它的比重。
(3)根据组距数列求加权算术平均时,需用组中值作为各组变量值的代表。
5.算术平均数的变形——调和平均数令xf=m(3)数学期望的性质:1)设c为常数,则E(c)=c。
2)设X为随机变量,a为常数,则E(aX)=aE(X)。
3)设X、Y是两个随机变量,则E(X士Y)=E(X)+E(Y)。
4)设X、Y是相互独立的随机变量,下限公式:m0=L+△1/(△1+△2)*d上限公式:m0=U-△1/(△1+△2)*d式中:m0代表众数;L和U分别代表众数组的下限和上限;d代表众数组的组距;△1代表众数组的次数与前一组次数之差;△2代表众数组的次数与后一组次数之差。

《抽样调查》复习题概述1.1 结合以下所列情况讨论哪些适合用全面调查,哪些适合用抽样调查,并说明理由;1.研究居住在某城市所有居民的食品消费结构;抽样调查2.调查一个县各村的粮食播种面积和全县生猪的存栏头数;全面调查3.为进行治疗,调查一地区小学生中患沙眼的人数;全面调查4.估计一个水库中草鱼的数量;抽样调查5.某企业想了解其产品在市场的占有率;抽样调查6.调查一个县中小学教师月平均工资。
全面调查1.2 结合习题1.1的讨论,你能否概括在什么场合作全面调查,什么场合适合做抽样调查。
答:全面调查:是一种有策划、有方法、有程序的活动,调查的结果一般表现为搜集的数据。
抽样调查:为某一特定目的而对部分考查对象进行的调查1.3某刊物对其读者进行调查,调查表随刊物送到读者手中,对寄回的调查表进行分析。
试问这是不是一项抽样调查?样本抽取是不是属于概率抽样?为什么?答:属于抽样调查,属于概率抽样,每一个样本单元被选中入样的概率是已知的。
1.5 结合习题1.3的讨论,根据你的理解什么是概率抽样?什么是非概率抽样?它们各有什么优点?答:非概率抽样:优点:操作简单,调查数据的处理较容易,省时,省费用。
概率抽样:根据随机原则,按照事先设计的程序,从总体抽取部分单元的抽样方法(要求每一个样本单元被选中入样的概率是已知的)优点:1.6抽样调查的特点。
答:1、节约费用 2、时效性强 3、完成全面调查不能胜任的项目 4、有助于提高数据质量抽样调查基本原理2.1 试说明以下术语或概念之间的关系与区别;1.总体、样本与个体;总体:是指所要研究对象的全体,它由研究对象中所有性质相同的个体组成,组成总体的各个个体称为总体单元或单位。
抽样总体:是指从中抽取样本的总体。
2.总体与抽样框;总体与抽样框应保持一致抽样框:是一份包含所有抽样单元的名单,给每一个抽样单元编上一个号码,就可以按照一定的随机化程序进行抽样。
抽样总体的具体表现是抽样框。

置信区间公式表 在统计学中,置信区间是用来估计一个参数或者变量真实值的范围。
置信区间公式表则是用来计算这些置信区间的具体公式的总结。
本文将介绍常见的统计参数和对应的置信区间计算公式,以及实际举例说明,帮助读者更好地理解和运用这些公式。
一、均值的置信区间公式1.总体均值的置信区间公式(大样本)当总体标准差已知时,总体均值的置信区间公式为: 置信区间 = 样本均值 ± Z分数 *(总体标准差 / 根号下样本容量)2.总体均值的置信区间公式(小样本)当总体标准差未知时,总体均值的置信区间公式为: 置信区间 = 样本均值 ± t分数 *(样本标准差 / 根号下样本容量) 举例说明:假设某地的成年人平均身高是170厘米,现在随机抽取了50名成年人,测得的样本平均身高是168厘米,样本标准差为3厘米。
根据上述公式,我们可以计算出给定置信水平下(例如95%),这个样本的置信区间为166.4厘米至169.6厘米。
二、比例的置信区间公式总体比例的置信区间公式为: 置信区间 = 样本比例 ± Z分数 * 根号下((样本比例 *(1 - 样本比例))/ 样本容量) 举例说明:某商品在一个网上商城上的购买成功率为0.65。
现在随机抽取了300个订单,其中成功购买的数量为200个。
根据上述公式,我们可以计算出给定置信水平下(例如90%),这个样本的置信区间为0.616至0.684。
三、方差的置信区间公式总体方差的置信区间公式为: 置信区间 = ((n - 1) * 样本方差) / X^2分数(α/2,n - 1)至((n - 1) * 样本方差) / X^2分数(1 - α/2,n - 1) 举例说明:假设某批产品的重量服从正态分布,我们随机抽取了12个产品,测得的样本方差为9。
根据上述公式,我们可以计算出给定置信水平下(例如99%),这个样本的置信区间为5.77至27.44。
置信区间公式表是统计学中一个重要的工具,可以帮助我们了解样本估计值的真实范围。
置信区间计算方法(一)置信区间计算什么是置信区间?•置信区间是统计学中常用的概念,用于估计一个总体参数的范围。
•置信区间的计算依赖于样本数据,可以帮助我们对总体参数进行推断。
置信区间的计算方法1. 正态分布情况下的置信区间•对于大样本(样本量大于30)且总体近似服从正态分布的情况,常用的计算方法为Z分数方法。
•Z分数方法:假设总体均值为μ,样本均值为x̄,样本标准差为s,置信水平为1-α,置信区间为[x̄ - Z * , x̄ + Z * ],其中Z为标准正态分布的分位数。
2. 小样本或总体非正态分布情况下的置信区间•对于小样本(样本量小于30)或总体分布未知的情况,可以使用t分布进行置信区间的计算。
•t分布方法:假设总体均值为μ,样本均值为x̄,样本标准差为s,自由度为n-1,置信水平为1-α,置信区间为[x̄ - t_{} * , x̄ + t_{} * ],其中t为t分布的分位数。
3. 样本比例的置信区间•当我们想要估计一个总体比例时,可以使用二项分布进行置信区间的计算。
•二项分布方法:假设总体比例为p,样本比例为p̄,样本个数为n,置信水平为1-α,置信区间为[p̄ - Z * , p̄ + Z * ],其中Z为标准正态分布的分位数。
置信区间的应用•置信区间可以帮助我们对总体参数进行估计,例如总体均值、总体比例等。
•置信区间还可以用于比较不同样本之间的差异,例如两个样本均值的差异、两个样本比例的差异等。
•置信区间在市场调研、医学研究等领域都有重要的应用,在决策和推断中起到了至关重要的作用。
置信区间计算的注意事项•置信区间的计算结果是对总体参数范围的估计,并不是总体参数的准确值。
•置信区间的宽度受样本量和置信水平的影响,样本量越大、置信水平越高,置信区间越窄。
•在使用置信区间时,需要明确置信水平和适用的分布假设,否则可能得到不准确的结果。
以上就是置信区间计算的各种方法。
置信区间是统计学中常用的工具,可以帮助我们对总体参数进行推断和估计,具有广泛的应用价值。
中级统计师相关公式统计学是一门研究收集、分析、解释和呈现数据的学科。
在统计学中,方差是一种衡量数据分散程度的指标。
未分组数据的方差计算公式为:$\sigma^2 = \frac{\sum(x-x)^2}{n}$,而分组数据的方差计算公式为:$\sigma^2 = \frac{\sum(x-x)^2f}{\sum f}$。
标准差是方差的平方根,未分组数据的标准差计算公式为:$s = \sqrt{\frac{\sum(x-x)^2}{n-1}}$,而分组数据的标准差计算公式为:$s = \sqrt{\frac{\sum(x-x)^2f}{\sumf-1}}$。
离散系数是衡量数据离散程度的指标,总体数据的离散系数为$\frac{\sigma}{x}$,而样本数据的离散系数为$\frac{s}{x}$。
标准分数是将原始数据转换为标准化值的过程,标准化值公式为$Z=\frac{x_i-x}{s}$。
在重置抽样时,样本均值的方差为$\frac{\sigma^2}{n}$,而在不重置抽样时,样本均值的方差为$\frac{\sigma^2N-n}{xn(N-1)}$。
在重置抽样时,比例的方差为$\frac{\pi(1-\pi)}{n}$,而在不重置抽样时,比例的方差为$\frac{\pi(1-\pi)}{N-n}\frac{n}{N-1}$。
样本均值的标准误为$\frac{\sigma}{\sqrt{n}}$,而样本比例的标准误为$\sqrt{\frac{\pi(1-\pi)}{n}}$。
标准正态分布是一种特殊的正态分布,其均值为0,标准差为1.将观测值转换为标准正态分布的公式为$Z=\frac{x-\mu}{\sigma/n}$。
置信区间是对总体参数的估计,其置信水平为1-α。
置信区间的一般表达式为$(x-分为数值*x的标准误差,x+分为数值*x的标准误差)$。
在大样本中,总体均值的区间估计公式为$(x-z_{\alpha/2}\frac{\sigma}{\sqrt{n}},x+z_{\alpha/2}\frac{\sigma} {\sqrt{n}})$,而在小样本中,总体均值的区间估计公式为$(x-t_{\alpha/2}\frac{s}{\sqrt{n}},x+t_{\alpha/2}\frac{s}{\sqrt{n}})$。
总体参数的区间估计公式摘要:1.总体参数的区间估计概述2.区间估计公式的推导3.区间估计在统计学中的应用正文:一、总体参数的区间估计概述总体参数的区间估计是统计学中一种重要的参数估计方法。
在实际问题中,我们通常需要对总体的某个未知参数进行估计,例如均值、方差等。
由于样本数据的随机性,我们需要通过一定的方法来估计总体参数的真实值,区间估计就是其中一种常用的方法。
区间估计的核心思想是利用样本数据计算出一个区间,该区间内包含总体参数真实值的概率在一定范围内。
这个概率范围通常用置信水平来表示,置信水平越高,所估计的区间范围就越宽,包含总体参数真实值的可能性就越大。
二、区间估计公式的推导设总体X 的概率密度函数为f(x),样本容量为n,样本均值为x,样本标准差为s,我们要估计总体均值μ。
根据中心极限定理,当n 充分大时,样本均值的分布近似于正态分布,即:x ~ N(μ, σ/n)其中,σ为总体方差。
为了估计总体均值μ,我们可以构造一个置信区间。
设α为置信水平,对应的Z 值为Zα,那么:μ的置信区间为:x ± Zα * s / √n其中,s / √n 为样本标准差除以√n,它实际上是总体标准差σ的估计。
三、区间估计在统计学中的应用区间估计在统计学中有广泛的应用,主要包括以下几个方面:1.对总体参数的单个估计:通过构造置信区间,我们可以估计总体参数的单个值,如均值、方差等。
2.对总体参数的统计推断:通过比较不同置信水平下的置信区间,我们可以对总体参数进行统计推断,如判断总体参数是否等于某个值等。
3.对样本容量的估计:在实际问题中,我们通常需要根据样本数据来估计总体参数,而样本容量的大小直接影响到估计的准确性。
通过构造置信区间,我们可以估计合适的样本容量。