总体均值的区间估计
- 格式:ppt
- 大小:2.94 MB
- 文档页数:32



估计理论估计理论提供了从样本统计量估计未知总体参数的方法。
样本统计量是某些测量值样本特征的经验性数值量度,不能将样本的经验抽样分布与样本理论抽样分布及总体概率分布混淆。
(回顾:通俗解释“大数据”及推断性统计学:抽样分布)两个概念估计量:指任何一个对总体参数给出估计值的样本统计量,例如样本均值。
估计值:指从某一样本计算得到的估计量的一个具体数值。
点估计对于来自一个测量总体的任何随机样本,如果对随机量(例如:样本的均值、方差或标准差)算得一个具体的数值(某个样本的均值、方差或标准差),用以估计总体的参数(例如:总体的均值、方差或标准差),则该数值称为总体参数(例如:总体的均值、方差或标准差)的一个点估计。
用点估计反映总体参数时,应该给出尽可能多的附加信息,使得便于评价估计值的准确度和精度。
准确度受度量方法和抽样设计影响;精度则由固定容量n的样本标准差决定,标准差越小越精确。
尽管有点估计及其准确度和精度的一些信息,但是仍然未能从样本跳跃到总体,即未能把点估计与待估总体参数联系起来,给出估计对参数的接近程度或确定在估计值中存在多大的可能误差,为了从样本信息推断总体参数,需要用到区间估计。
区间估计区间估计是一个从样本到总体的推断,区间估计将总体参数置于一个实区间上。
区间的边界值由三个因素决定:1、样本点估计值;2、联系总体参数和样本点估计的样本统计量(如Z统计量,做正态变换得到);3、该统计量的抽样分布(例如,样本均值的理论抽样分布服从正态分布,则Z统计量的抽样分布是标准正态分布);总体均值的区间估计公式推导上述推导给出了总体均值的区间估计的概率形式,基于要求:容量为n的单样本来自无限大且标准差已知的正态分布总体。
置信水平在进行数据分析时,经常需要输入置信水平,大多数情况选择95%的置信水平,当然也可以选择其他的置信水平。
什么是置信水平呢?通过上面的公式推导,得到了总体均值区间估计的概率表示:其中的1-α称为置信系数,它的百分数表示形式(1-α)100%称为置信水平。


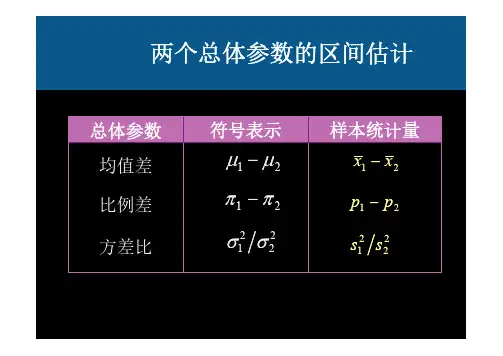
双正态总体参数的区间估计双正态总体参数的区间估计是统计学中的一种方法,用于估计由两个正态分布组成的总体的参数。
这种方法适用于当我们需要估计两个总体的平均值或比例时,且这两个总体可以被假定为来自两个不同的正态分布。
下面我们将详细介绍双正态总体参数的区间估计的原理和步骤。
双正态总体参数的区间估计可以分为两种情况:一种是当我们需要估计两个总体的平均值,另一种是当我们需要估计两个总体的比例。
首先,假设我们需要估计两个总体的平均值。
我们可以用样本平均值来估计总体平均值,并通过计算标准误差来构建置信区间。
如果我们假设两个总体的方差相等,则可以使用统计学中的配对t检验方法来进行推断。
具体步骤如下:1.收集样本数据。
从每个总体中随机抽取一定数量的样本,并记录下每个样本的观测值。
2.计算样本平均值。
对于每个总体,计算对应样本的平均值。
3.计算差值。
对于每个配对样本,计算它们的差值。
如果我们关注的是总体平均值的差异,则用两个总体对应样本的平均值之差来作为差值。
4.计算标准差。
计算差值样本的标准差,用来估计差值的标准误差。
5.确定置信水平。
选择一个置信水平,通常为95%。
这意味着我们希望有95%的置信度认为估计的区间包含真实的总体差异。
6.计算临界值。
确定配对t检验的自由度,并使用自由度和置信水平来查找相应的t临界值。
7.构建置信区间。
使用差值平均值±t临界值*标准误差来构建置信区间,这个区间将包含真实的总体差异。
另一种情况是当我们需要估计两个总体的比例。
在这种情况下,我们可以使用两个样本中的比例差异来估计总体的比例差异。
具体步骤如下:1.收集样本数据。
从每个总体中随机抽取一定数量的样本,并记录下每个样本中的成功次数和总次数。
2.计算样本比例。
对于每个总体,计算对应样本的比例,即成功次数除以总次数。
3.计算差异。
对于每个配对样本,计算它们的比例之差。
4.计算标准误差。
计算比例差异样本的标准误差,用来估计比例差异的标准误差。


与点估计相比区间估计的主要优点是一、点估计:1、优点:简单易懂,能够提供总体参数的估计值。
2、缺点:用抽样指标直接代替全体指标,不可避免的会有误差。
二、区间估计:1、优点:可以在一定的概率水平上来判断估计值的取值范围自,从而认识样本序列的聚集程度和离散程度2、缺点:受异常值影响可能导致估计的区间不准确,同时知由于是在一定概率陈水平上道的推断,忽略了小概率事件可能产生的影响。
点估计目的是依据样本X=(X1、X2…Xi)估计总体分布所含的未知参数θ或θ的函数g(θ)。
一般θ或g(θ)是总体的某个特征值,如数学期望、方差、相关系数等。
点估计的常用方法有矩估计法、顺序统计量法、最大似然法、最小二乘法等。
与点估计不同,进行区间估计时,根据样本统计量的抽样分布可以对样本统计量与总体参数的接近程度给出一个概率度量。
区间估计(interval estimate)是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减估计误差得到。
与点估计不同,进行区间估计时,根据样本统计量的抽样分布可以对样本统计量与总体参数的接近程度给出一个概率度量。
下面将以总体均值的区间估计为例来说明区间估计的基本原理。
区间估计,是参数估计的一种形式。
1934年,由统计学家J.奈曼所创立的一种严格的区间估计理论。
置信系数是这个理论中最为基本的概念。
通过从总体中抽取的样本,根据一定的正确度与精确度的要求,构造出适当的区间,以作为总体的分布参数(或参数的函数)的真值所在范围的估计。
用数轴上的一段距离或一个数据区间,表示总体参数的可能范围.这一段距离或数据区间称为区间估计的置信区间。
区间估计(interval estimation)是从点估计值和抽样标准误差出发,按给定的概率值建立包含待估计参数的区间.其中这个给定的概率值称为置信度或置信水平(confidence level),这个建立起来的包含待估计参数的区间称为置信区间(confidence interval),指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。

均值置信区间
均值置信区间是统计学中常用的一种方法,用于估计总体均值的范
围。在实际应用中,我们往往只能通过样本来推断总体的特征,而
均值置信区间就是一种基于样本的估计方法。
均值置信区间的计算方法比较简单,首先需要确定置信水平,通常
取95%或99%。然后根据样本的均值、标准差和样本量,计算出置
信区间的上下限。例如,对于一个样本均值为x,标准差为s,样本
量为n,置信水平为95%,则置信区间的上下限为x±1.96s/√n。
均值置信区间的意义在于,我们可以通过样本均值的范围来估计总
体均值的范围。例如,如果我们对某个产品的质量进行抽样检验,
得到的样本均值为90分,置信水平为95%,则可以认为总体均值
的范围在87.2分到92.8分之间。这个范围是基于样本的统计推断,
具有一定的不确定性,但是可以提供一定的参考价值。
均值置信区间的应用范围非常广泛,例如在医学研究中,可以通过
抽样检验来估计某种药物的疗效;在市场调研中,可以通过抽样调
查来估计某种产品的市场占有率;在质量控制中,可以通过抽样检
验来估计产品的平均质量水平等等。
需要注意的是,均值置信区间只是一种估计方法,其结果具有一定
的不确定性。因此,在实际应用中,需要根据具体情况来确定置信
水平和样本量,以提高估计的准确性和可靠性。同时,还需要注意
样本的选取和抽样方法,以避免样本偏差对估计结果的影响。
均值置信区间是一种常用的统计方法,可以用于估计总体均值的范
围。在实际应用中,需要根据具体情况来确定置信水平和样本量,
以提高估计的准确性和可靠性。
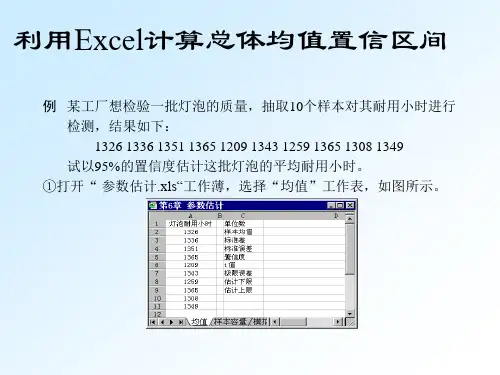
应用Excel求置信区间一、总体均值的区间估计(一)总体方差未知例:为研究某种汽车轮胎的磨损情况,随机选取16只轮胎,每只轮胎行驶到磨坏为止。
记录所行驶的里程(以公里计)如下:41250 40187 43175 41010 39265 41872 42654 41287 38970 40200 42550 41095 40680 43500 39775 40400假设汽车轮胎的行驶里程服从正态分布,均值、方差未知。
试求总体均值μ的置信度为0.95的置信区间。
步骤:1.在单元格A1中输入“样本数据”,在单元格B4中输入“指标名称”,在单元格C4中输入“指标数值”,并在单元格A2:A17中输入样本数据。
2.在单元格B5中输入“样本容量”,在单元格C5中输入“16”。
3.计算样本平均行驶里程。
在单元格B6中输入“样本均值”,在单元格C6中输入公式:“=AVERAGE(A2,A17)”,回车后得到的结果为41116.875。
4.计算样本标准差。
在单元格B7中输入“样本标准差”,在单元格C7中输入公式:“=STDEV(A2,A17)”,回车后得到的结果为1346.842771。
5.计算抽样平均误差。
在单元格B8中输入“抽样平均误差”,在单元格C8中输入公式:“=C7/SQRT(C5)” ,回车后得到的结果为336.7106928。
6.在单元格B9中输入“置信度”,在单元格C9中输入“0.95”。
7.在单元格B10中输入“自由度”,在单元格C10中输入“15”。
8.在单元格B11中输入“t分布的双侧分位数”,在单元格C11中输入公式:“ =TINV(1-C9,C10)”,回车后得到α=0.05的t分布的双侧分位数t=2.1315。
9.计算允许误差。
在单元格B12中输入“允许误差”,在单元格C12中输入公式:“=C11*C8”,回车后得到的结果为717.6822943。
10.计算置信区间下限。
在单元格B13中输入“置信下限”,在单元格C13中输入置信区间下限公式:“=C6-C12”,回车后得到的结果为40399.19271。
第19讲 正态总体参数的区间估计教学目的:理解区间估计的概念,掌握各种条件下对一个正态总体的均值和方差进行区间估计的方法。
教学重点:置信区间的确定。
教学难点:对置信区间的理解。
教学时数: 2学时。
教学过程:第六章 参数估计§6.3正态总体参数的区间估计1. 区间估计的概念我们已经讨论了参数的点估计,但是对于一个估计量,人们在测量或计算时,常不以得到近似值为满足,还需估计误差,即要求知道近似值的精确程度。
因此,对于未知参数θ,除了求出它的点估计ˆθ外,我们还希望估计出一个范围,并希望知道这个范围包含参数θ真值的可信程度。
设ˆθ为未知参数θ的估计量,其误差小于某个正数ε的概率为1(01)αα-<<,即ˆ{||}1P θθεα-<=-或αεθθεθ-=+<<-1)ˆˆ(P这表明,随机区间)ˆ,ˆ(εθεθ+-包含参数θ真值的概率(可信程度)为1α-,则这个区间)ˆ,ˆ(εθεθ+-就称为置信区间,1α-称为置信水平。
定义 设总体X 的分布中含有一个未知参数θ。
若对于给定的概率1(01)αα-<<,存在两个统计量1112(,,,)n X X X θθ= 与2212(,,,)n X X X θθ= ,使得12{}1P θθθα<<=-则随机区间12(,)θθ称为参数θ的置信水平为1α-的置信区间,1θ称为置信下限,2θ称为置信上限,1α-称为置信水平。
注(1)置信区间的含义:若反复抽样多次(各次的样本容量相等,均为n ),每一组样本值确定一个区间12(,)θθ,每个这样的区间要么包含θ的真值,要么不包含θ的真值。
按伯努利大数定理,在这么多的区间中,包含θ真值的约占100(1)%α-,不包含θ真值的约仅占100%α。
例如:若0.01α=,反复抽样1000次,则得到的1000个区间中,不包含θ真值的约为10个。
(2)置信区间的长度表示估计结果的精确性,而置信水平表示估计结果的可靠性。