自底向上的语法分析
- 格式:ppt
- 大小:3.05 MB
- 文档页数:70

《编译原理》中LR(0)语法分析动态演示系统分析与设计1. 引言1.1 研究背景编译原理是计算机科学领域的重要基础课程,而LR(0)语法分析是编译原理中一个关键的内容。
LR(0)语法分析是一种自底向上的语法分析方法,能够准确地判断一个输入串是否是给定文法的句子,同时可以生成句子对应的语法树。
LR(0)语法分析比上下文无关文法分析更为强大,因此被广泛应用于编译器的设计和实现中。
对于学习者来说,理解和掌握LR(0)语法分析并不是一件容易的事情。
传统的教学方法往往是通过讲解和演示来进行,但存在一定的局限性,学生很难深入理解其中的逻辑和原理。
设计一个LR(0)语法分析动态演示系统是十分必要和有意义的。
这样的系统可以通过图形化的界面展示LR(0)语法分析的每个步骤和过程,帮助学生更直观地理解LR(0)语法分析的原理和实现。
1.2 研究目的研究目的是为了通过设计和实现一个LR(0)语法分析动态演示系统,帮助学生和从业者更好地理解和应用LR(0)语法分析算法。
具体来说,研究目的包括但不限于以下几点:通过分析LR(0)语法分析算法的原理和流程,深入探讨其在编译原理中的重要性和应用价值,为用户提供一个直观、动态的学习工具,帮助他们更好地理解和掌握这一算法的核心概念。
通过设计和实现一个功能齐全、易于操作的LR(0)语法分析动态演示系统,提供用户友好的界面和交互功能,使用户可以通过实际操作和观察,加深对LR(0)语法分析算法的认识,并在实践中掌握其使用方法和技巧。
通过系统测试和优化,不断改进系统性能和用户体验,确保系统稳定运行并具有良好的可用性和可靠性,为用户提供一个高质量的学习工具和应用工具。
通过这些努力,旨在提高用户对LR(0)语法分析算法的理解和应用能力,促进编译原理领域的教学和研究工作的发展。
1.3 研究意义编译原理是计算机专业的重要基础课程,而LR(0)语法分析是编译原理中一项重要的内容。
通过设计和实现一个LR(0)语法分析动态演示系统,可以帮助学生更加直观地理解和掌握LR(0)语法分析的原理和算法。


简述 slr(1)和 lr(1)文法的定义(一)简述 SLR(1) 和 LR(1) 文法SLR(1)和LR(1)是两种常见的自底向上的语法分析算法。
它们都可以用于语法分析器生成过程中,帮助开发者构建和验证语法分析器。
下面将对SLR(1)和LR(1)的相关定义进行列举,并阐述理由和书籍简介。
SLR(1)文法•定义:SLR(1)(Simple LR)文法是一种自底向上的语法分析方法,它使用LR(0)项目集作为状态,具有一定的限制,只能处理一些相对简单的文法。
SLR(1)文法通过构造LR(0)自动机,然后结合First集和Follow集来进行分析。
•理由:SLR(1)文法的优势是在实现过程中相对简单,并且可以处理一些常见的文法,例如算术表达式、条件语句等。
由于SLR(1)文法的限制较多,相比其他更复杂的LR分析方法,其文法设计要求相对低,因此更适合初学者理解和使用。
•书籍简介:《编译原理》(作者:龙书)是一本经典的编译原理教材,其中涵盖了SLR(1)文法的相关内容。
这本书详细介绍了语法分析的各种方法,从简单的自底向上方法到更复杂的自顶向下方法,包括SLR(1)文法的构造和应用。
《编译原理》对于初学者来说是一本很好的参考书,可以帮助读者理解SLR(1)文法及其在语法分析中的应用。
LR(1)文法•定义:LR(1) 文法是一种更强大的自底向上语法分析方法,通过考虑下一个输入符号的展望符号(look-ahead)来解决由于有多个项目具有相同的前缀而导致的归约冲突。
LR(1) 文法通过构造 LR(1) 项目集来构建 LR(1) 分析表。
•理由:相比 SLR(1) 文法,LR(1) 文法可以处理更复杂的文法,具有更强的表达能力。
通过展望符号的引入,LR(1)文法能够更准确地分析语法,解决冲突。
在实际的编译器设计中,LR(1) 文法更为常用,可以处理包括C、Java等语言中的大部分语法规则。
•书籍简介:《编译原理与设计》(作者: Aho, Lam, R. Sethi, Ullman)是一本经典的编译原理教材,其中详细介绍了LR(1)文法及其相关内容。


第讲LR分析法LR分析法是一种常用的语法分析方法,可以用于生成语法树,它是自底向上的语法分析方法。
在LR分析法中,L表示“自左向右扫描输入串的方式”,R表示“反向构建和规约的方式”。
LR分析法包括以下几个步骤:1.构造LR(0)项目集规范族:LR(0)项目集是指在一些语法分析的过程中,每个项目表示对应的产生式的哪一部分已经被扫描过了,哪一部分还没有被扫描过。
根据给定的文法,构造出所有可能的项目集,并将它们进行编号,得到项目集规范族。
2.构造LR(0)项目集规范族的DFA:根据构造出的LR(0)项目集规范族,可以构造出一个DFA(确定性有限自动机)来表示LR(0)语法分析的过程。
DFA的每个状态表示一个项目集,每个转移表示在一个状态下扫描一些符号后转移到另一个状态。
3.构造LR(0)分析表:根据构造出的LR(0)项目集规范族的DFA,可以构造出一个分析表,即LR(0)分析表。
分析表的行表示当前状态,列表示当前输入符号,表格中的每个元素表示下一步应该做的动作,可以是移进一些符号,也可以是规约一些项目。
4.进行LR(0)分析:根据构造出的LR(0)分析表,可以进行LR(0)语法分析。
分析的过程是根据当前状态和输入符号,在分析表中查找对应的动作,并执行该动作。
如果遇到移进动作,就将符号加入到解析栈中,同时移动输入指针;如果遇到规约动作,就从解析栈中弹出一些符号,然后根据规约产生式将新的非终结符加入到解析栈中。
5.构造SLR(1)分析表:LR(0)分析表中存在冲突的情况,无法完全正确地进行语法分析。
为了解决这个问题,需要对LR(0)分析表进行优化,得到SLR(1)分析表。
SLR(1)分析表与LR(0)分析表的结构类似,只是在一些冲突的情况下给出更加具体的动作指令。
6.进行SLR(1)分析:根据构造出的SLR(1)分析表,可以进行SLR(1)语法分析。
与LR(0)分析类似,根据当前状态和输入符号,在分析表中查找对应的动作,并执行该动作。



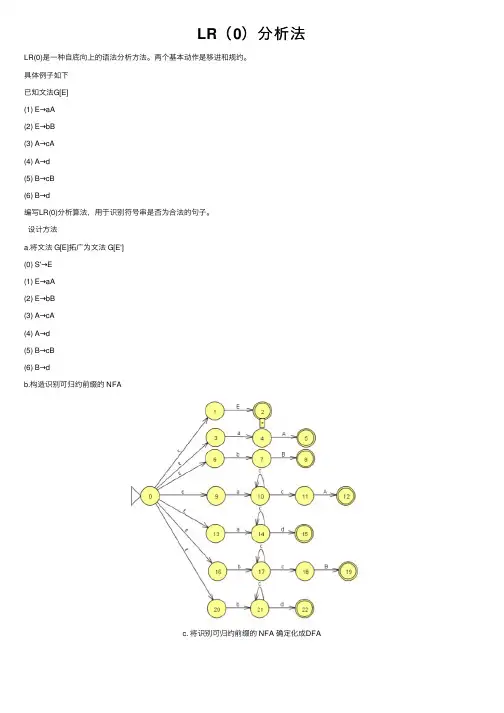
LR(0)分析法LR(0)是⼀种⾃底向上的语法分析⽅法。
两个基本动作是移进和规约。
具体例⼦如下已知⽂法G[E](1) E→aА(2) E→bB(3) A→cА(4) A→d(5) B→cB(6) B→d编写LR(0)分析算法,⽤于识别符号串是否为合法的句⼦。
设计⽅法a.将⽂法 G[E]拓⼴为⽂法 G[E'](0) S'→E(1) E→aA(2) E→bB(3) A→cA(4) A→d(5) B→cB(6) B→db.构造识别可归约前缀的 NFAc. 将识别可归约前缀的 NFA 确定化成DFAd. 根据识别可归约前缀的 DFA 构造⽂法的 LR(0)分析表表2-1 LR(0)分析表状态a b c d#E A B0S1S231S4S562S7S893acc4S4S5105r4r4r4r4r46r1r1r1r1r17S7S8118r6r6r6r6r69r2r2r2r2r210r3r3r3r3r311r5r5r5r5r5e. 设计 LR(0)分析程序⾃底向上的语法分析的两个基本动作就是,移进与规约。
分析⼀下表 2-1 中⽂法的 LR(0)分析表,可以发现这两个动作在表中都有。
进⼀步分析可知,这些移进与规约动作在表的前⾯终结符列中,因此,这部分称之为 ACTION 表。
表中不但给出了两个基本动作,还给出了规约时,弹出产⽣式右部,压⼊左部之后,应该转换到的状态。
例如,当前状态为 9,状态 9 为句柄识别态,查表得:r2,表⽰使⽤第⼆个产⽣式E→bB 进⾏规约。
规约动作分为两步:第⼀步弹出句柄 bB,从识别⽂法可归约前缀的 DFA 中可知,弹出句柄 bB后,从当前状态为 9 回到状态 0;第⼆步就是压⼊左部 E,从当前状态 0,转换到状态 3。
在表中的第 0 ⾏第 E 列中就给出状态 3。
分析表可知,表中的⾮终结符列填⼊的是某⼀规约动作,压⼊产⽣式左部(⾮终结符)之后,转换到的状态。
因此,这部分称之为 GOTO 表。

语法分析实验报告语法分析实验报告引言语法分析是自然语言处理中的一项重要任务,它旨在根据给定的语法规则和输入句子,确定句子的结构和语法成分,并进行语义解析。
本实验旨在探索语法分析的基本原理和方法,并通过实际操作来加深对其理解。
实验目标本实验的主要目标是实现一个简单的自底向上的语法分析器,即基于短语结构文法的分析器。
具体而言,我们将使用Python编程语言来实现一个基于CYK 算法的语法分析器,并对其进行评估和分析。
实验过程1. 语法规则的定义在开始实验之前,我们首先需要定义一个适当的语法规则集。
为了简化实验过程,我们选择了一个简单的文法,用于分析包含名词短语和动词短语的句子。
例如,我们定义了以下语法规则:S -> NP VPNP -> Det NVP -> V NP2. 实现CYK算法CYK算法是一种自底向上的语法分析算法,它基于动态规划的思想。
我们将使用Python编程语言来实现CYK算法,并根据定义的语法规则进行分析。
具体而言,我们将根据输入的句子和语法规则,构建一个二维的表格,用于存储句子中各个子串的语法成分。
通过填充表格并进行推导,我们可以确定句子的结构和语法成分。
3. 实验结果与分析我们使用几个示例句子来测试我们实现的语法分析器,并对其结果进行分析。
例如,对于句子"the cat eats fish",我们的语法分析器可以正确地识别出该句子的结构,并给出相应的语法成分。
具体而言,我们的分析器可以识别出句子的主语是"the cat",谓语是"eats",宾语是"fish"。
通过对多个句子的测试,我们可以发现我们实现的语法分析器在大多数情况下都能正确地分析句子的结构和语法成分。
然而,在一些复杂的句子中,我们的分析器可能会出现一些错误。
这可能是由于语法规则的不完备性或者算法的限制所致。
结论与展望通过本实验,我们深入了解了语法分析的基本原理和方法,并实现了一个简单的自底向上的语法分析器。

编译原理LR分析法编译原理中的LR分析法是一种自底向上的语法分析方法,用于构建LR语法分析器。
LR分析法将构建一个识别句子的分析树,并且在分析过程中动态构建并操作一种非常重要的数据结构,称为句柄(stack)。
本文将详细介绍LR分析法的原理、算法以及在实际应用中的一些技巧。
1.LR分析法的原理LR分析法是从右向左(Right to Left)扫描输入串,同时把已处理的输入串的右侧部分作为输入串的前缀进行分析的。
它的核心思想是利用句柄来识别输入串中的语法结构,从而构建分析树。
为了实现LR分析法,需要识别和操作两种基本的语法结构:可规约项和可移近项。
可规约项指的是已经识别出的产生式右部,可以用产生式左部进行规约。
可移近项指的是当前正在处理的输入符号以及已处理的输入串的右侧部分。
2.LR分析法的算法LR分析法的算法包括以下几个步骤:步骤1: 构建LR分析表,LR分析表用于指导分析器在每个步骤中的动作。
LR分析表包括两个部分:动作(Action)表和状态(Goto)表。
步骤2: 初始化分析栈(stack),将初始状态压入栈中。
步骤3:从输入串中读取一个输入符号,并根据该符号和当前状态查找LR分析表中的对应条目。
步骤4:分析表中的条目可能有以下几种情况:- 移进(shift):将输入符号移入栈中,并将新的状态压入栈中。
- 规约(reduce):将栈中符合产生式右部的项规约为产生式左部,并将新的状态压入栈中。
- 接受(accept):分析成功,结束分析过程。
- 错误(error):分析失败,报告错误。
步骤5:重复步骤3和步骤4,直到接受或报错。
3.LR分析法的应用技巧在实际应用中,为了提高LR分析法的效率和准确性,一般会采用以下几种技巧:-使用LR分析表的压缩表示:分析表中的大部分条目具有相同的默认动作(通常是移进操作),因此可以通过压缩表示来减小分析表的大小。
-使用语法冲突消解策略:当分析表中存在冲突时,可以使用优先级和结合性规则来消解冲突,以确定应该选择的操作。
在自底向上的语法一、什么是自底向上的语法自底向上的语法(Bottom-Up Parsing)是一种常用的语法分析方法,用于将一个字符串根据给定语法规则转化为语法分析树。
与之相对的是自顶向下的语法分析方法,自顶向下的语法分析从根节点开始,逐步将输入的字符串分解为非终结符和终结符,直到得到语法分析树。
而自底向上的语法分析则相反,它从叶子节点开始,逐步合并成非终结符,直到得到语法分析树。
自底向上的语法分析方法通常采用的是操作符优先分析法(Operator Precedence Parsing),也称为算符优先文法。
这种分析方法可以通过构造一个算符优先关系表来进行分析,从而判断字符串是否符合给定的语法规则。
自底向上的语法分析方法适用于各种类型的语言和文法,包括正则文法、上下文无关文法等。
这种方法具有较高的灵活性和适应性,并且能够处理大型复杂的文法和语言。
二、自底向上的语法分析步骤自底向上的语法分析过程可以分为以下步骤:1. 词法分析首先,将输入的字符串进行词法分析,将其划分为一个个单词或记号(Token)。
每个单词或记号都具有一个特定的含义,表示了输入字符串中的一个基本语义单元。
2. 初始化构建一个栈(Stack)用于保存已识别的单词或记号,并初始化一个语法分析表(Parsing Table)用于记录语法规则和操作符的优先级关系。
3. 移入操作从输入的字符串中读取一个未处理的单词或记号,并将其压入栈中。
4. 归约操作不断检查栈中的记号序列是否满足某一语法规则,如果满足,则将该记号序列替换为相应的非终结符,并执行相应的语义动作。
重复这个过程,直到不能再进行归约操作。
5. 接受或错误处理如果最终栈中只剩下一个元素,且该元素为起始符号,则语法分析成功,接受输入的字符串。
如果栈中无法进行归约操作,或者最终栈中还有多余的元素,或者无法匹配到输入字符串的所有部分,则语法分析失败,进行错误处理。
三、算符优先文法算符优先文法是自底向上分析方法的代表,它以操作符的优先级和关联性为基础,构造一个优先关系表来进行分析。
语法分析器的设计与实现一、设计概述1.定义语法规则:根据所设计的编程语言,确定其语法规则。
可以使用文法或者EBNF(扩展巴科斯-诺尔范式)来定义语法规则。
2. 设计语法分析算法:选择适合的语法分析算法,常见的有自顶向下(Top-Down)和自底向上(Bottom-Up)两种。
自顶向下算法从语法规则的起始符号开始,逐步向下匹配源代码,构建语法树。
自底向上算法则通过逐步将输入的源代码规约为语法规则的右侧,最终得到语法树。
3.实现语法分析器:根据所选择的语法分析算法,实现相应的算法,根据文法定义和源代码进行语法分析。
二、自顶向下语法分析自顶向下语法分析是一种递归的、自上而下构造语法树的方法。
它以文法的起始符号为目标,通过不断向下匹配文法规则,构造出整个语法树。
自顶向下语法分析的步骤如下:1.设计非终结符的产生规则:根据文法的非终结符定义产生规则。
非终结符表示语法规则的左侧。
2.设计终结符的匹配规则:根据文法的终结符定义匹配规则。
终结符表示具体的代码元素,如标识符、关键字等。
3.设计递归下降分析算法:根据文法的产生规则,设计递归下降分析算法。
算法的入口是文法的起始符号,通过递归调用不同的产生规则,不断向下匹配源代码,构造语法树。
三、自底向上语法分析自底向上语法分析是一种逆推的、以产生规则的右侧为目标的方法。
它通过逐步将源代码的串规约为文法规则的右侧,最终得到语法树。
自底向上语法分析的步骤如下:1.设计终结符的匹配规则:根据文法的终结符定义匹配规则。
2.设计产生规则的规约动作:根据文法的产生规则,为每个规则设计规约动作。
规约动作通常是将产生规则的右侧转化为左侧的非终结符。
3.设计移进-规约分析算法:根据终结符的匹配规则和产生规则的规约动作,实现移进-规约分析算法。
算法通过逐步将输入的源代码进行移进和规约操作,直到得到语法树。
四、错误处理在语法分析的过程中,可能会出现各种错误,如语法错误、缺失分号、括号不匹配等。