编译原理 4.2自底向上的语法分析(3)
- 格式:ppt
- 大小:1.43 MB
- 文档页数:51



自底向上语法分析器实验报告一.问题描述编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E -> E+T | E-T | TT -> T*F | T/F | FF -> id | (E) | num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
编写语法分析程序实现自底向上的分析,要求如下:(1)构造识别所有活前缀的DFA。
(2)构造LR分析表。
(3)编程实现算法4.3,构造LR分析程序。
二.算法思想1.大体步骤:(1)根据题目所给出的文法构造相应的拓广文法,并求出该文法各非终结符的FIRST、FOLLOW集合;(2).构造拓广文法的项目集规范族,并构造出识别所有前缀的DFA;(3)构造文法的LR分析表;(4)由此构造LR分析程序。
2.数据结构:1.输入缓冲区为一个字符型数组,读入输入的算术表达式并保存在此,以’$’结束;2.构建一个相对应的整型数组,将输入缓冲区中的字符转换为相应的代号并保存;3.构造一个结构体,以保存文法的某个产生式,该结构包括三个元素:整形变量,保存产生式左部非终结符代号。
整型数组,保存产生式右部字符串的代号。
整型变量,保存产生式右部长度;4.定义该结构的数组,保存文法的所有产生式;5.定义两个二维整形数组,goto和action,其值大于零代表移进操作,小于零代表规约操作,引进的状态或规约用到的产生式又绝对值表示。
等于零代表出现错误。
等于特殊值999代表acc.状态。
3.计算过程:文法对应的拓广文法为:1 S -> E2 E -> E+T3 E -> E-T4 E -> T5 T -> T*F6 T -> T/F7 T -> F8 F -> (E)9 F -> id10 F -> num求的各个非终结符的FIRST、FOLLOW集合为:FIRST(S) = { id, num, ( } FOLLOW (S) = { $ }FIRST(E) = { id, num, ( } FOLLOW (E) = { $ , + , - , ) }FIRST(T) = { id, num, ( } FOLLOW (T) = { $ , + , - , * , / , ) }FIRST(F) = { id, num, ( } FOLLOW (F) = { $ , + , - , * , / , ) }构造项目集规范族:I0= closure({S->·E}) = {S->·E, E->·E+T, E->·E-T, E->·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};从I0出发:I1 = go(I0, E) = closure({S->E·, E->E·+T, E->E·-T}) = {S->E·, E->E·+T, E->E·-T};I2 = go(I0, T) = closure({E->T·, T->T·*F, T->T·/F}) = {E->T·, T->T·*F, T->T·/F};I3 = go(I0, F) = closure({T->F·}) = {T->F·};I4 = go(I0, id) = closure({F->id·}) = {F->id·};I5= go(I0, () = closure({F->(·E)}) = {F->(·E), E->·E+T, E->·E-T, E->·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};I6 = go(I0, num) = closure({F->num·}) = {F->num·};从I1出发:I7= go(I1, +) = closure({E->E+·T}) = {E->E+·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};I8= go(I1, -) = closure({E->E-·T}) = {E->E-·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};从I2出发:I9 = go(I2, *) = closure({T->T*·F}) = {T->T*·F, F->·id, F->·(E), F->·num};I10 = go(I2, /) = closure({T->T/·F}) = {T->T/·F, F->·id, F->(E), F->·num};从I5出发:I11 = go(I5, E) = closure({F->(E·), E->E·+T, E->E·-T}) = {F->(E·), E->E·+T, E->E·-T};从I7出发:I12 = go(I7, T) = closure({E->E+T·, T->T·*F, T->T·/F}) = {E->E+T·, T->T·*F, T->T·/F};从I8出发:I13 = go(I8, T) = closure({E->E-T·, T->T·*F, T->T·/F}) = {E->E-T·, T->T·*F, T->T·/F};从I9出发:I14 = go(I9, F) = closure({T->T*F·}) = {T->T*F·};从I10出发:I15 = go(I10, F) = closure({T->T/F·}) = {T->T/F·};从I11出发:I16 = go(I11, )) = closure({F->(E)·}) = {F->(E)·};下面构造文法的LR分析表:goto[0,E] = 1; goto[0,T] = 2; goto[0,F] = 3;action[0,id] = S4; action[0,(] = S5; action[0,num] = S6;action[1,$] = ACC.; action[1,+] = S7; action[1,-] = S8;;action[2,)] = action[2,+] = action[2,-] = action[2,$] = R4;action[2,*] = S9; action[2,/] = S10;action[3,)] = action[3,+] = action[3,-] = action[3,*] = action[3,/] = action[3,$] = R7;action[4,)] = action[4,+] = action[4,-] = action[4,*] = action[4,/] = action[4,$] = R8;goto[5,E] = 11; goto[5,T] = 2; goto[5,F] = 3;action[5,id] = S4; action[5,(] = S5; action[5,num] = S6;action[6,)] = action[6,+] = action[6,-] = action[6,*] = action[6,/] = action[6,$] = R10;goto[7,T] = 12; goto[7,F] = 3;action[7,id] = S4; action[7,(] = S5; action[7,num] = S6;goto[8,T] = 13; goto[8,F] = 3;action[8,id] = S4; action[8,(] = S5; action[8,num] = S6;goto[9,F] = 14;action[9,id] = S4; action[9,(] = S5; action[9,num] = S6;goto[10,F] = 15;action[10,id] = S4; action[10,(] = S5; action[10,num] = S6;action[11,)] = S16; action[11,+] = S7; action[11,-] = S8;action[12,)] = action[12,+] = action[12,-] = action[12,$] = R2; action[12,*] = S9; action[12,/] = S10;action[13,)] = action[13,+] = action[13,-] = action[13,$] = R3; action[13,*] = S9; action[13,/] = S10;action[14,)] = action[14,+] = action[14,-] = action[14,*] = action[14,/] = action[14,$] = R5;action[15,)] = action[15,+] = action[15,-] = action[15,*] = action[15,/] = action[15,$] = R6;action[16,)] = action[16,+] = action[16,-] = action[16,*] = action[16,/] = action[16,$] = R9;4.SLR(1)分析表为:E1: 缺少运算对象。

编译原理目录一、引言。
1.1 编译原理概述。
1.2 编译器的作用和原理。
二、词法分析。
2.1 词法分析的任务和原理。
2.2 正规表达式和有限自动机。
2.3 词法分析器的实现。
三、语法分析。
3.1 语法分析的任务和原理。
3.2 自顶向下分析和自底向上分析。
3.3 语法分析器的实现。
四、语义分析。
4.1 语义分析的任务和原理。
4.2 语义动作和语法制导翻译。
4.3 语义分析器的实现。
五、中间代码生成。
5.1 中间代码的作用和原理。
5.2 三地址码和四元式。
5.3 中间代码生成器的实现。
六、代码优化。
6.1 代码优化的目标和原理。
6.2 基本块和流图。
6.3 代码优化器的实现。
七、目标代码生成。
7.1 目标代码生成的任务和原理。
7.2 寄存器分配和指令选择。
7.3 目标代码生成器的实现。
八、汇编与链接。
8.1 汇编的作用和原理。
8.2 静态链接和动态链接。
8.3 汇编器和链接器的实现。
九、实践与应用。
9.1 编译原理在实际开发中的应用。
9.2 前端与后端的协同工作。
9.3 实践案例分析。
十、总结与展望。
10.1 编译原理的发展历程。
10.2 未来编译原理的发展趋势。
10.3 结语。
在编译原理的学习过程中,我们将深入了解编译器的工作原理和实现方法。
从词法分析到目标代码生成,每个环节都承担着特定的任务,而它们又相互协作,共同完成将源代码翻译成目标代码的过程。
通过本文档的学习,读者将能够全面了解编译原理的核心概念和具体实现,为日后的编译器开发和优化工作打下坚实的基础。

《编译原理》常见题型一、填空题1.编译程序的工作过程一般可以划分为词法分析,语法分析,中间代码生成,代码优化(可省) ,目标代码生成等几个基本阶段。
2.若源程序是用高级语言编写的,目标程序是机器语言程序或汇编程序,则其翻译程序称为编译程序.3.编译方式与解释方式的根本区别在于是否生成目标代码 .5.对编译程序而言,输入数据是源程序,输出结果是目标程序 .7.若源程序是用高级语言编写的,目标程序是机器语言程序或汇编程序,则其翻译程序称为编译程序。
8.一个典型的编译程序中,不仅包括词法分析、语法分析、中间代码生成、代码优化、目标代码生成等五个部分,还应包括表格处理和出错处理。
其中,词法分析器用于识别单词。
10.一个上下文无关文法所含四个组成部分是一组终结符号、一组非终结符号、一个开始符号、一组产生式。
12.产生式是用于定义语法成分的一种书写规则。
13.设G[S]是给定文法,则由文法G所定义的语言L(G)可描述为:L(G)={x│S=>*x,x∈VT*} 。
14.设G是一个给定的文法,S是文法的开始符号,如果S*⇒x(其中x∈V*),则称x是文法的一个句型。
15.设G是一个给定的文法,S是文法的开始符号,如果S*⇒x(其中x∈V T*),则称x是文法的一个句子。
16.扫描器的任务是从源程序中识别出一个个单词符号。
17.语法分析最常用的两类方法是自上而下和自下而上分析法。
18.语法分析的任务是识别给定的终结符串是否为给定文法的句子。
19.递归下降法不允许任一非终结符是直接左递归的。
20.自顶向下的语法分析方法的关键是如何选择候选式的问题。
21.递归下降分析法是自顶向下分析方法。
22.自顶向下的语法分析方法的基本思想是:从文法的开始符号开始,根据给定的输入串并按照文法的产生式一步一步的向下进行直接推导,试图推导出文法的句子,使之与给定的输入串匹配。
23.自底向上的语法分析方法的基本思想是:从给定的终结符串开始,根据文法的规则一步一步的向上进行直接归约,试图归约到文法的开始符号。

编译原理课后答案问题一计算机程序的执行是一个多阶段的过程,其中编译是其中的一环。
请问编译的三个主要阶段分别是什么?答:编译过程一般可以分为三个主要阶段,分别是词法分析、语法分析和代码生成。
下面分别对这三个阶段进行介绍。
1. 词法分析词法分析是编译过程的第一步,也是最基础的一步。
它的任务是将源代码中的字符序列分解成一个个具有独立含义的单词,这些单词被称为“记号”或“词法单元”。
词法分析器根据程序中每一个字符的组合规则,将其转化为一个个词法单元,并记录下词法单元的类型标记。
词法分析器的工作一般通过有限状态自动机来实现,它根据一定的词法规则进行扫描和分析。
2. 语法分析语法分析是编译过程的第二步,它接收词法分析器生成的词法单元流,根据语法规则进行分析,并生成一棵语法树。
语法分析的主要任务是确定输入程序的结构,检查程序的语法正确性,并生成用于后续处理的输入形式。
语法分析器一般采用的是自顶向下或自底向上的分析方法,常用的方法有递归下降法和LR(1)分析法。
3. 代码生成代码生成是编译过程的最后一步,它将语法分析生成的语法树转化为目标机器的可执行代码。
代码生成器通过遍历语法树,将每个语法树节点转化为相应的目标机器代码。
代码生成过程中需要考虑到目标机器的特性和限制,以及优化代码的效率和性能。
问题二请解释一下编译原理中的词法规则是什么?答:编译原理中的词法规则指的是一组规定词法单元模式的规则。
它描述了如何将输入字符序列转换为词法单元,并为每个词法单元定义了一个标记。
词法规则一般使用正则表达式来描述词法单元的模式。
编译器根据词法规则构建词法分析器,用于将源代码分割成一系列的词法单元。
词法规则的灵活性和准确性对编译过程的性能和结果都有较大的影响。
一个完整的词法规则一般包含以下几个部分:1.正则表达式:描述了词法单元的模式,使用特定的正则表达式语法来表示。
2.动作:描述了当词法单元匹配到模式时,需要执行的动作或处理过程。


在自底向上的语法一、什么是自底向上的语法自底向上的语法(Bottom-Up Parsing)是一种常用的语法分析方法,用于将一个字符串根据给定语法规则转化为语法分析树。
与之相对的是自顶向下的语法分析方法,自顶向下的语法分析从根节点开始,逐步将输入的字符串分解为非终结符和终结符,直到得到语法分析树。
而自底向上的语法分析则相反,它从叶子节点开始,逐步合并成非终结符,直到得到语法分析树。
自底向上的语法分析方法通常采用的是操作符优先分析法(Operator Precedence Parsing),也称为算符优先文法。
这种分析方法可以通过构造一个算符优先关系表来进行分析,从而判断字符串是否符合给定的语法规则。
自底向上的语法分析方法适用于各种类型的语言和文法,包括正则文法、上下文无关文法等。
这种方法具有较高的灵活性和适应性,并且能够处理大型复杂的文法和语言。
二、自底向上的语法分析步骤自底向上的语法分析过程可以分为以下步骤:1. 词法分析首先,将输入的字符串进行词法分析,将其划分为一个个单词或记号(Token)。
每个单词或记号都具有一个特定的含义,表示了输入字符串中的一个基本语义单元。
2. 初始化构建一个栈(Stack)用于保存已识别的单词或记号,并初始化一个语法分析表(Parsing Table)用于记录语法规则和操作符的优先级关系。
3. 移入操作从输入的字符串中读取一个未处理的单词或记号,并将其压入栈中。
4. 归约操作不断检查栈中的记号序列是否满足某一语法规则,如果满足,则将该记号序列替换为相应的非终结符,并执行相应的语义动作。
重复这个过程,直到不能再进行归约操作。
5. 接受或错误处理如果最终栈中只剩下一个元素,且该元素为起始符号,则语法分析成功,接受输入的字符串。
如果栈中无法进行归约操作,或者最终栈中还有多余的元素,或者无法匹配到输入字符串的所有部分,则语法分析失败,进行错误处理。
三、算符优先文法算符优先文法是自底向上分析方法的代表,它以操作符的优先级和关联性为基础,构造一个优先关系表来进行分析。

《编译原理》常见题型一、填空题1.编译程序的工作过程一般可以划分为词法分析,语法分析,中间代码生成,代码优化(可省) ,目标代码生成等几个基本阶段。
2.若源程序是用高级语言编写的,目标程序是机器语言程序或汇编程序,则其翻译程序称为编译程序.3.编译方式与解释方式的根本区别在于是否生成目标代码.5.对编译程序而言,输入数据是源程序,输出结果是目标程序.7.若源程序是用高级语言编写的,目标程序是机器语言程序或汇编程序,则其翻译程序称为编译程序。
8.一个典型的编译程序中,不仅包括词法分析、语法分析、中间代码生成、代码优化、目标代码生成等五个部分,还应包括表格处理和出错处理。
其中,词法分析器用于识别单词。
10.一个上下文无关文法所含四个组成部分是一组终结符号、一组非终结符号、一个开始符号、一组产生式。
12.产生式是用于定义语法成分的一种书写规则。
(13.设G[S]是给定文法,则由文法G所定义的语言L(G)可描述为:L(G)={x│S=>*x,x∈VT*} 。
14.设G是一个给定的文法,S是文法的开始符号,如果S*⇒x(其中x∈V*),则称x是文法的一个句型。
15.设G是一个给定的文法,S是文法的开始符号,如果S*⇒x(其中x∈V T*),则称x是文法的一个句子。
16.扫描器的任务是从源程序中识别出一个个单词符号。
17.语法分析最常用的两类方法是自上而下和自下而上分析法。
18.语法分析的任务是识别给定的终结符串是否为给定文法的句子。
19.递归下降法不允许任一非终结符是直接左递归的。
20.自顶向下的语法分析方法的关键是如何选择候选式的问题。
21.递归下降分析法是自顶向下分析方法。
22.自顶向下的语法分析方法的基本思想是:从文法的开始符号开始,根据给定的输入串并按照文法的产生式一步一步的向下进行直接推导,试图推导出文法的句子,使之与给定的输入串匹配。
…23.自底向上的语法分析方法的基本思想是:从给定的终结符串开始,根据文法的规则一步一步的向上进行直接归约,试图归约到文法的开始符号。

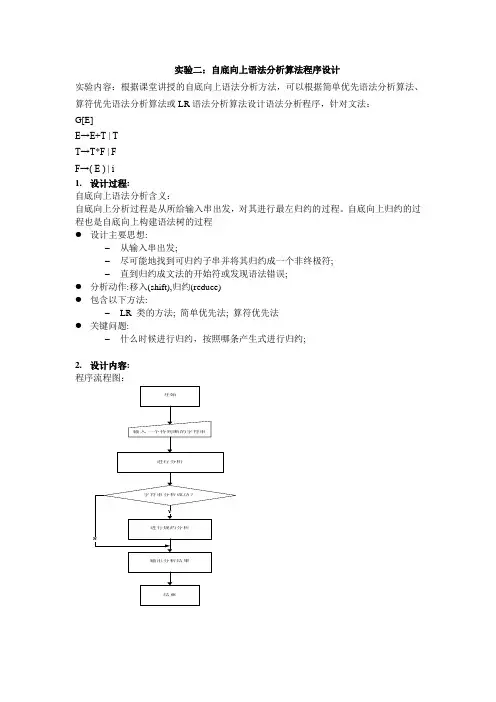
实验二:自底向上语法分析算法程序设计实验内容:根据课堂讲授的自底向上语法分析方法,可以根据简单优先语法分析算法、算符优先语法分析算法或LR语法分析算法设计语法分析程序,针对文法:G[E]E→E+T | TT→T*F | FF→( E ) | i1.设计过程:自底向上语法分析含义:自底向上分析过程是从所给输入串出发,对其进行最左归约的过程。
自底向上归约的过程也是自底向上构建语法树的过程●设计主要思想:–从输入串出发;–尽可能地找到可归约子串并将其归约成一个非终极符;–直到归约成文法的开始符或发现语法错误;●分析动作:移入(shift),归约(reduce)●包含以下方法:–LR 类的方法; 简单优先法; 算符优先法●关键问题:–什么时候进行归约,按照哪条产生式进行归约;2.设计内容:程序流程图:3. 程序关键代码:#include <stdio.h>int flag;//初始化变量char m[20]={'+','*','^','i','(',')','#'};chart[20][20]={{'>','<','<','<','<','>','>'},{'>','>','<', '<','<','>','>'},{'>','>','<','<','<','>','>'},{'>','>',' >','n','n','>','>'},{'<','<','<','<','<','=','n'},{'>','>' ,'>','n','n','>','>'},{'<','<','<','<','<','n','='}};int termin(char arr[20],char c); //函数:判断是否终结符char compare(char xarr[20][20],char c1,char c2); //函数:比较两个终结符之间的优先关系void error();main (){printf("请输入字符串并以#结束\n:");char str[50];char a,q;char s[50];int k,j,n;scanf("%s",str);s[0]='n';flag=0;n=0;k=1;s[k]='#';do //读取输入的字符串到#号结束{a=str[n];if (termin(m,a)>=0)n++;else{error();return(0);}if (termin(m,s[k])>=0)j=k;elsej=k-1;while (compare(t,s[j],a)=='>'){do{q=s[j];if ((j-1)<=0){error();return(0);}if (termin(m,s[j-1])>=0){j=j-1;}elsej=j-2;}while (compare(t,s[j],q)!='<');k=j+1;s[k]='N';}if((compare(t,s[j],a)=='<')||(compare(t,s[j],a)= ='=')){k=k+1;s[k]=a;}elseerror();}while (a!='#');if (!flag)printf("The sentence is legal!\n");}int termin(char arr[20],char c){int i=0;int l=0;while (arr[i]!='\0'){if (arr[i]==c){l=1;break;}i=i+1;}if (l==1)return(i);elsereturn(-1);}char compare(char xarr[20][20],char c1,char c2)//比较两个终结符之间的优先关系{int i,j;char r;i=termin(m,c1);j=termin(m,c2);r=xarr[i][j];return(r);}void error() //通过flag来判断字符串是否非法{flag=1;printf("The sentence is not legal\n!");}4.实验结果:上图输入的字符串虽符合要求,但是进行运行分析是发现不能进行规约,结果错误非法.5.实验总结:通过实验知道了采用自底向上分析方法对输入的字符串进行语法分析,进一步掌握最左归约的过程.。