【习题答案】第05章 自底向上的语法分析
- 格式:pdf
- 大小:1.12 MB
- 文档页数:6



第五章第5章自顶向下语法分析方法练习(P99)1.文法S->a|^|(T)T->T,S|S(1) 对(a,(a,a)和(((a,a),^,(a)),a)的最左推导。
(3)经改写后的文法是否为LL(1)的?给出它的预测分析表。
(4)给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
(1) 对(a,(a,a)的最左推导为:S=>(T)=>(T,S) =>(S,S) =>(a,S) =>(a,(T)) =>(a,(T,S)) =>(a,(S,S))=>(a,(a,S)) =>(a,(a,a))对(((a,a),^,(a)),a) 的最左推导为:S=>(T) =>(T,S) =>(S,S) =>((T),S) =>((T,S),S) =>((T,S,S),S)=>((S,S,S),S) =>(((T),S,S),S) =>(((T,S),S,S),S) =>(((S,S),S,S),S)=>(((a,S),S,S),S) =>(((a,a),S,S),S) =>(((a,a),^,S),S) =>(((a,a),^,(T)),S) =>(((a,a),^,(S)),S) =>(((a,a),^,(a)),S) =>(((a,a),^,(a)),a)(3)改写文法为:0) S->a1) S->^2) S->( T )3) T->S N4) N->, S N5) N->ε对左部为N2的产生式可知:FIRST (->, S N2)={,}FIRST (->ε)={ε}FOLLOW (N2)={)}{,}∩ { )}=Ø所以文法是LL(1)的。
也可由预测分析表中无多重入口判定文法是LL(1)的。

编译原理复习题及答案一、选择题1.一个正规语言只能对应(B)A一个正规文法B一个最小有限状态自动机2.文法G[A]:A→εA→aBB→AbB→a是(A)A正规文法B二型文法3.下面说法正确的是(A)A一个SLR(1)文法一定也是LALR(1)文法B一个LR(1)文法一定也是LALR(1)文法4.一个上下文无关文法消除了左递归,提取了左公共因子后是满足LL(1)文法的(A)A必要条件B充分必要条件5.下面说法正确的是(B)A一个正规式只能对应一个确定的有限状态自动机B一个正规语言可能对应多个正规文法6.算符优先分析与规范归约相比的优点是(A)A归约速度快B对文法限制少7.一个LR(1)文法合并同心集后若不是LALR(1)文法(B)A则可能存在移进/归约冲突B则可能存在归约/归约冲突C则可能存在移进/归约冲突和归约/归约冲突8.下面说法正确的是(A)ALe某是一个词法分析器的生成器BYacc是一个语法分析器9.下面说法正确的是(A)A一个正规文法也一定是二型文法B一个二型文法也一定能有一个等价的正规文法10.编译原理是对(C)。
A、机器语言的执行B、汇编语言的翻译C、高级语言的翻译D、高级语言程序的解释执行C.FORTRAND.PASCAL11.(A)是一种典型的解释型语言。
A.BASICB.C12.把汇编语言程序翻译成机器可执行的目标程序的工作是由(B)完成的。
A.编译器B.汇编器C.解释器D.预处理器13.用高级语言编写的程序经编译后产生的程序叫(B)A.源程序B.目标程序C.连接程序14.(C)不是编译程序的组成部分。
A.词法分析程序B.代码生成程序D.解释程序D.语法分析程序C.设备管理程序15.通常一个编译程序中,不仅包含词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成等六个部分,还应包括(C)。
A.模拟执行器B.解释器C.表格处理和出错处理D.符号执行器16.编译程序绝大多数时间花在(D)上。

一、填空题1、在半导体生产中常用的薄膜可以分为、、三大类。
2、集成电路金属互连工艺中AlCu合金常用作解决铝互连中的问题。
3、集成电路传统的铝互连线结构中常采用TiN / Ti作为金属阻挡层,这种工艺的主要目的是为了解决问题。
4、在半导体生产中,绝缘介质薄膜常见的主要有等材料。
5、在半导体生产中,半导体薄膜常见的主要有等材料。
6、在半导体生产中,金属导电薄膜常见的主要有等材料。
7、绝缘介质材料的特性中,介电常数主要用来表征绝缘材料的性能,介电强度用来表示绝缘材料的性能。
8、二氧化硅作为杂质选择扩散的掩蔽层,所需要满足的条件为:。
二、简答题1、简述二氧化硅薄膜在半导体生产中的主要作用?2、金属导电膜在半导体生产中的主要作用?3、什么是铝的电迁移?产生的原因?解决的方法?4、什么是铝尖刺现象?产生的原因和解决的方法?一、课程性质《编译原理》是高等工科院校“计算机科学与技术”、“软件工程”、“信息安全”等专业的一门重要的必修专业基础课。
所含内容涉及学科抽象、理论、设计三个形态。
在学习编译原理所涉及的知识的同时,掌握问题求解的典型思路和方法,帮助学生从系统层面重新认识程序和算法。
二、课程目标本课程的教学目标是:通过学习该课程,使学生了解形式语言基本概念和术语、掌握词法分析、语法分析、语义分析及中间代码生成、代码优化、符号表管理、存储组织和分配及代码优化的基本原理和实现方法。
通过学习编译程序的构造原理和技术,将有助于深刻理解和正确使用程序设计语言。
除此以外,编译原理课程介绍的一些原理、方法和算法并不局限于编译器的构造,也广泛地应用于其他软件的设计与开发。
本课程具有思想素质、知识技能以及能力培养三个层面的通用课程目标:(一)思想、素质教育目标目标1.1 在教学过程中,激发学生自豪感与爱国情怀,鼓励学生通过努力学习掌握先进科学技术,服务国家,回馈社会。
目标1.2 在教学过程中,通过课程内容与中国传统文化思想相结合,提升学生的学习兴趣、人文关怀和道德情操,真正做到“传道、授业和解惑”。

第六章自底向上优先分析方法•教学要求:了解简单优先分折法,掌握算符优先分析法的关系表的构造以及分析过程。
•教学重点:算符优先表构造及算符优先分析法。
1自底向上分析法的基本思想•从输入串开始,朝着文法的开始符号进行最左归约,直到到达文法的开始符号为止。
•工作方式:“移进-归约”方式。
2分析程序模型1)初态时栈内仅有栈底符“#”,读头指针在最左单词符号上。
2)语法分析程序执行的动作:a)移进读入一个单词并压入栈内,读头后移;b)归约检查栈顶若干个符号能否进行归约,若能,就以产生式左部替代该符号串,同时输出产生式编号;c)识别成功移进-归约的结局是栈内只剩下栈底符号和文法开始符号,读头也指向语句的结束符;d)识别失败语法分析程序语法表a+b……#输出带#3例如:有文法如下(1)S→aAcBe(2)A→b(3)A→Ab(4)B→d问:语句abbcde是不是该文法的合法语句?4•例:设文法G(S):(1) S aAcBe(2) A b(3) A Ab(4) B d 试对abbcde进行“移进-归约”分析。
bbcde bbcde b cde de deabbcde eB cA a SB A a 5成功11接受2,3,4,1##S 10归约##aAcBe 9移进2,3,4e ##aAcB 8归约e ##aAc d 7移进de ##aAc 6移进2,3cde ##aA 5归约cde ##a Ab 4移进2bcde ##aA 3归约bcde ##a b 2移进bbcde ##a 1移进abbcde ##0动作输出带输入串栈步骤移进归约的分析过程G[S]:(1)S →aAcBe(2)A →b(3)A →Ab(4)B →d 6遇到的问题:(1)如何找出进行直接归约的简单短语?(2)找出的简单短语应直接归约到哪一个非终结符?关键:确定句柄.常用的分析方法:(1)优先分析法(2)LR分析法7b db ac eSA B A d b a c e S A B A d a c eSA B a c e A B S 没有语法树如何确定句柄?86.1 自底向上优先分析法概述•基本思想:利用文法符号中相邻符号之间的优先关系(谁先规约的优先关系)找出句柄。


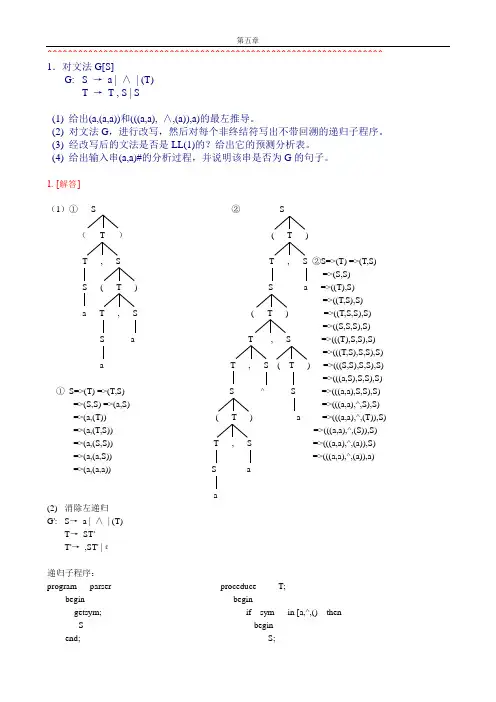
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 1.对文法G[S]G: S →a | ∧| (T)T →T , S | S(1) 给出(a,(a,a))和(((a,a), ∧,(a)),a)的最左推导。
(2) 对文法G,进行改写,然后对每个非终结符写出不带回溯的递归子程序。
(3) 经改写后的文法是否是LL(1)的?给出它的预测分析表。
(4) 给出输入串(a,a)#的分析过程,并说明该串是否为G的句子。
1. [解答](1)①S ②S(T )( T )T , S T , S ②S=>(T) =>(T,S)=>(S,S) S ( T ) S a =>((T),S)=>((T,S),S)a T , S ( T ) =>((T,S,S),S)=>((S,S,S),S) S a T , S =>(((T),S,S),S)=>(((T,S),S,S),S)a T , S ( T ) =>(((S,S),S,S),S)=>(((a,S),S,S),S)①S=>(T) =>(T,S) S ^ S =>(((a,a),S,S),S)=>(S,S) =>(a,S) =>(((a,a),^,S),S) =>(a,(T)) ( T ) a =>(((a,a),^,(T)),S) =>(a,(T,S)) =>(((a,a),^,(S)),S)=>(a,(S,S)) T , S =>(((a,a),^,(a)),S)=>(a,(a,S)) =>(((a,a),^,(a)),a)=>(a,(a,a)) S aa(2) 消除左递归G': S→a | ∧| (T)T→ST'T'→,ST' |ε递归子程序:program parser proceduce T;begin begingetsym; if sym in [a,^,() thenS beginend; S;proceduce S; T;begin end;if sym=’a’ or sym=’^’ then elsegetsym error;elseif sym=’(‘ end;begin getsym; proceduce T’;T; beginIf sym=’)’ then if sym=’,’ thenGetsym; beginElse getsym;Error; S;End; T;Else end;Error; elseEnd; if sym=’)’ thenelseerror;end;LL(1)文法!(4) 分析栈余留串所用产生式或动作1 #S (a,a)# S—>(T)2 #)T( (a,a)# (匹配3 #)T a,a)# T—>ST’4 #)T’S a,a)# S—>a5 #)T’a a,a)# a匹配6 #)T’ ,a)# T’ —>,ST’7 #)T’S, ,a)# ,匹配8 #)T’S a)# S—>a9 #)T’a a)# a匹配10 #)T’ )# T’—>ε11 #) )# )匹配12 # # 接受因为(a,a)#分析成功所以(a,a)为文法的句子步骤分析栈余留串所用产生式或动作1 #S (a,a# S→(T)2 #)T( (a,a# ( 匹配3 #)T a,a# T→ST’4 #)T’S a,a# S→a5 #)T’a a,a# a 匹配6 #)T’,a# T’→,ST’7 #)T’S, ,a# , 匹配8 #)T’S a# S→a9 #)T’a a# a 匹配10 #)T’# 出错^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 2. G: E →TE'E' →+E |εT →FT'T' →T |εF →PF'F' →*F' |εP →(E) | a | b |∧预测分析表^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ 3.已知文法G: S →MH | aH →LSo |εK →dML |εL →eHfM →K | bLM判断G是否是LL(1)文法,如果时,构造LL(1)分析表。

在自底向上的语法一、什么是自底向上的语法自底向上的语法(Bottom-Up Parsing)是一种常用的语法分析方法,用于将一个字符串根据给定语法规则转化为语法分析树。
与之相对的是自顶向下的语法分析方法,自顶向下的语法分析从根节点开始,逐步将输入的字符串分解为非终结符和终结符,直到得到语法分析树。
而自底向上的语法分析则相反,它从叶子节点开始,逐步合并成非终结符,直到得到语法分析树。
自底向上的语法分析方法通常采用的是操作符优先分析法(Operator Precedence Parsing),也称为算符优先文法。
这种分析方法可以通过构造一个算符优先关系表来进行分析,从而判断字符串是否符合给定的语法规则。
自底向上的语法分析方法适用于各种类型的语言和文法,包括正则文法、上下文无关文法等。
这种方法具有较高的灵活性和适应性,并且能够处理大型复杂的文法和语言。
二、自底向上的语法分析步骤自底向上的语法分析过程可以分为以下步骤:1. 词法分析首先,将输入的字符串进行词法分析,将其划分为一个个单词或记号(Token)。
每个单词或记号都具有一个特定的含义,表示了输入字符串中的一个基本语义单元。
2. 初始化构建一个栈(Stack)用于保存已识别的单词或记号,并初始化一个语法分析表(Parsing Table)用于记录语法规则和操作符的优先级关系。
3. 移入操作从输入的字符串中读取一个未处理的单词或记号,并将其压入栈中。
4. 归约操作不断检查栈中的记号序列是否满足某一语法规则,如果满足,则将该记号序列替换为相应的非终结符,并执行相应的语义动作。
重复这个过程,直到不能再进行归约操作。
5. 接受或错误处理如果最终栈中只剩下一个元素,且该元素为起始符号,则语法分析成功,接受输入的字符串。
如果栈中无法进行归约操作,或者最终栈中还有多余的元素,或者无法匹配到输入字符串的所有部分,则语法分析失败,进行错误处理。
三、算符优先文法算符优先文法是自底向上分析方法的代表,它以操作符的优先级和关联性为基础,构造一个优先关系表来进行分析。

第五章语法分析—自下而上分析本章要点1. 自下而上语法分析法的基本概念:2. 算符优先分析法;3. LR分析法分析过程;4. 语法分析器自动产生工具Y ACC;5. LR分析过程中的出错处理。
本章目标掌握和理解自下而上分析的基本问题、算符优先分析、LR分析法及语法分析器的自动产生工具YACC等内容。
本章重点1.自下而上语法分析的基本概念:归约、句柄、最左素短语;2.算符优先分析方法:FirstVT, LastVT集的计算,算符优先表的构造,工作原理;3.LR分析器:(1)LR(0)项目集族,LR(1)项目集簇;(2)LR(0)、SLR、LR(1)和LALR(1)分析表的构造;(3)LR分析的基本原理,分析过程;4.LR方法如何用于二义文法;本章难点1. 句柄的概念;2. 算符优先分析法;3. LR分析器基本;作业题一、单项选择题:1. LR语法分析栈中存放的状态是识别________的DFA状态。
a. 前缀;b. 可归前缀;c. 项目;d. 句柄;2. 算符优先分析法每次都是对________进行归约:(a)句柄(b)最左素短语(c)素短语(d)简单短语3. 有文法G=({S},{a},{S→SaS,S→ε},S),该文法是________。
a. LL(1)文法;b.二义性文法;c.算符优先文法;d.SLR(1)文法;4. 在编译程序中,语法分析分为自顶向下分析和自底向上分析两类,和LL(1)分析法属于自顶向下分析;a. 深度分析法b. 宽度优先分析法c. 算符优先分析法d. 递归下降子程序分析法5. 自底向上语法分析采用分析法,常用的是自底向上语法分析有算符优先分析法和LR分析法。
a. 递归b. 回溯c. 枚举d. 移进-归约6. 一个LR(k)文法,无论k取多大,。
a. 都是无二义性的;b. 都是二义性的;c. 一部分是二义性的;d. 无法判定二义性;7. 在编译程序中,语法分析分为自顶向下分析和自底向上分析两类,和LR分析法属于自底向上分析。
课后练习参考答案
第05章 自底向上的语法分析
1. S→aS|bS|a
(1) 构造该文法的LR(0)项目集规范族。
(2) 构造识别该文法所产生的活前缀的DFA 。
(3) 构造其SLR 分析表,并判断该文法是否是SLR(1)文法。
【解】 构造LR(0)项目集规范族,有两种方法:一种是利用有限自动机来构造,另一种是利用函数CLOSURE 和GO 来构造。
本题采取第2种方法,通过计算函数CLOSURE 和GO 得到文法的LR(0)项目集规范族,而GO 函数则把LR(0)项目集规范族连成一个识别该文法所产生的活前缀的DFA 。
(1) 将文法G(S)拓广为G(S’):
(0)S’→S
(1)S→aS
(2)S→bS (3)S→a
构造该文法的LR(0)项目集规范族:
I 0=CLOSURE({S →·S})={S’ →·S, S→·aS, S→·bS, S→·a}
I 1=GO( I 0 , a)=CLOSURE({S→a·S , S→a·})={S→a·S , S→a· , S→·aS, S→·bS, S→·a } I 2=GO(I 0 , b)=CLOSURE({S→b·S })={ S→b·S, S→·aS, S→·bS, S→·a } I 3=GO(I 0 , S)=CLOSURE({S’ →S·})={ S’ →S·} GO(I 1, a)=CLOSURE({S→a·S , S→a·})=I 1 GO(I 2, b)=CLOSURE({S→b·S})=I 2
I 4=GO(I 1, S)=CLOSURE({S→aS·})={S→aS·} GO(I 2, a)= CLOSURE({S→a·S , S→a·})=I 1 GO(I 2, b)= CLOSURE({S→b·S})=I 2
I 5=GO(I 2, S)=CLOSURE({S→bS·})={ S→bS·}
所以,项目集I 0,I 1,I 2,I 3,I 4和I 5构成了该文法的LR(0)项目集规范族。
(2) 我们用GO 函数把LR(0)项目集规范族连成一个识别该文法所产生的活前缀的DFA 如下图所示。
(3) 构造其SLR 分析表。
SLR 分析表 ACTION
GOTO 状态 a b #
S 0 S1 S2 3 1 S1 S2 r3 4 2 S1 S2 5 3 acc 4 r1 5
r2
注意到状态I 1存在“移进-归纳”冲突,计算S 的FOLLOW 集合:FOLLOW(S) = {#} 可以采用SLR 冲突消解法,得到上表所列的SLR 分析表。
从分析表可以看出,表中没有冲突项,所以该文法是SLR(1)文法。
2. 构造识别下列文法的所有活前缀的DFA
S →A|B A →aAc A →a B →bBd B →b
【解】
(1) 构造拓广文法
0) S’ →S 1) S →A 2) S →B 3) A →aAc 4) A →a 5) B →bBd 6) B →b
(2) 识别该拓广文法的所有规范句型活前缀的DFA 项目集规范族
C={I0,I1,I2,I3,I4,I5,I6,I7,I8,I9}
I0={ S’→.S , S→.A, S→.B, A→.aAc, A→.a, B→.bBd, B→.b } I1={ S’→S. } I2={S→A.} I3={S→B.} I4={ A→a.Ac, A→a., A→.aAc A→.a} I5={B→b.Bd, B→b., B→.bBd, B→.b}
I6={A→aA.c} I7={B→bB.d} I8={A→aAc.} I9={B→bBd.}
(3) 识别该拓广文法的所有规范句型活前缀的DFA
→.B A →.aAc A →.a B →.bBd B →.b
3. 给定文法G: S → (L | a L → S, L | )
(1) 构造拓广文法及拓广文法的LR(0)项目集规范族(状态集合)。
(2) 构造这个文法的SLR (1)分析表。
【解】
(1) 构造拓广文法
0) S’ →S 1) S → (L
2) S → a 3) L → S, L
4) L → )
拓广文法的LR(0)项目集规范族(状态集合)
I0={S’ →.S, S →. (L, S →. a} I1={ S’ →S. }
I2={ S →(.L, L → .S, L , L →. ), S → .(L , S → .a } I3={ S →(L. }
I4={ S →S., L }
I5={ L →).} I6={ S → a.}
I7={ L → S, .L , L → .S, L , L → .)} I8={ L → S, L.}
其DFA 如下:
(2) 求各非终结符的 FISRT 集和 FOLLOW 集: FIRST(S) = { (, a } FIRST(L) = { ) } FIRST(S) = { (, ), a } FOLLOW(S) = { , , # }
FOLLOW(L) = FOLLOW(S) ={ , , # }
G 的SLR(1) 分析表:
( a , ) # S L
0 s2 s6 1
1 acc
2 s2 s6 s5 4
3 3 r1 r1
4 s7
5 r4 r4
6 r2 r2
7 s2 s6 s5 4
8 8
r3
r3
4. 证明AdBd 是文法G[S]的活前缀。
说明活前缀在LR 分析中的作用。
给出串dbdb#的LR
分析过程。
G[S]: (1) S→AdB
(2)A→a (3) A→ε (4) B→b (5)B→Bdb (6)B→ε
【解】 所谓活前缀是指规范句型的一个前缀,这种前缀不是句柄之后的任何符号。
根据此定义,直接证明AdBd 是文法G(S)的活前缀。
存在下面的规范推导:S => AdB => AdBdb ,可见AdBdb 是文法G 的规范句型,AdBd 是该规范句型的前缀。
另外,在该规范句型中Bdb 是句柄,前缀是AdBd 不含句柄Bdb 之后的任何符号,所以AdBd 是文法G(S)的活前缀。
在LR 分析工作过程中的任何时候,栈里的方法符号(自栈底而上)X 1X 2…X m 应该构成活前缀,把输入串的剩余部分配上之后即应成为规范句型(如果整个输入串确实构成一个句子)。
因此,只要输入串的已扫描部分保持可归约成一个活前缀,那就意味着所扫描过的部分没有错误。
识别活前缀的DFA 如下:
构造文法G 的LR 分析表如下:
ACTION GOTO a d b # S A B 0 s3 r3 1 2 1 acc 2 s4 3 r2 4 r6 s5 r6 6 5 r4 r4 6 s7 r1 7 s8 8 r5 r5
串dbdb#的LR 分析过程如下:
步骤 状态 符号 输入串 0 0 # dbdb# 1 02 #A dbdb# 2 024 #Ad bdb# 3 0245 #Adb db# 4 0246 #AdB db# 5 02467 #AdBd b# 6 024678 #AdBdb # 9 0246 #AdB #
10 01 #S # acc。