2.5.6 继承和接口
- 格式:doc
- 大小:31.50 KB
- 文档页数:3

UML那些事儿:六类UML图来源:天极网作者:邱郁惠2.1 类图2.2 对象图2.3 包图2.4 活动图2.5 序列图2.6 用例图本章介绍六类UML图的主要用途,以及常见的概念及图示,以便对这六类图有一个初步的认识。
2.1 类图如果投票选最重要的UML图,我一定会把票投给类图( class diagram)。
类图是一款结构图(structure diagram),如图2-1所示,我们可以用它来表达系统内部重要的组成结构。
一个稳定且具弹性的内部结构可以同时支撑系统对外提供的各式服务,以及系统内部复杂的运作,所以我认为类图特别重要。
接下来的各小节会谈到类图中最常见的概念及图示。
2.1.1 类一群对象(object)享有相同的结构、行为、约束和语义时,称它们是同类(class)的对象。
换句话说,定义一个类就相当于描述了一群对象。
在类中,使用属性(attribute)表达对象的结构,使用操作(operation)表达对象的行为。
如图2-2所示,定义员工(worker)类之后,便可以依据此类的描述产生一群对象。
这些:Worker对象不仅可以共用类所定义的属性,拥有自己的属性值,还可以共用类所定义的操作,或者共用约束。
图2-1 类图图2-2 类与对象类采用三格的矩形图示,顶格放置类名称,中格放置属性名称,底格放置操作名称。
不过,也可以将类的属性格或操作格隐藏起来,节省空间,如图2-3所示。
大多数的UML工具都有隐藏功能。
以StarUML为例,点选任何一个类图示都可以选择是否隐藏属性或操作,如图2-4所示。
图2-3 类图示图2-4 隐藏属性或操作2.1.2 可见性对象具有封装(encapsulation)属性,可以把数据结构和行为细节封装起来,外界无法随意存取。
对应UML的类概念,我们会看到类中有属性和操作,同时可以设定这些成员是否能被外界存取的可见性(visibility)。
以图2-5为例,单笔申购(purchase)封装了一个外界无法存取的私有属性—金额(amount),以及一个外界可以调用的公开操作—计算(calculate)。
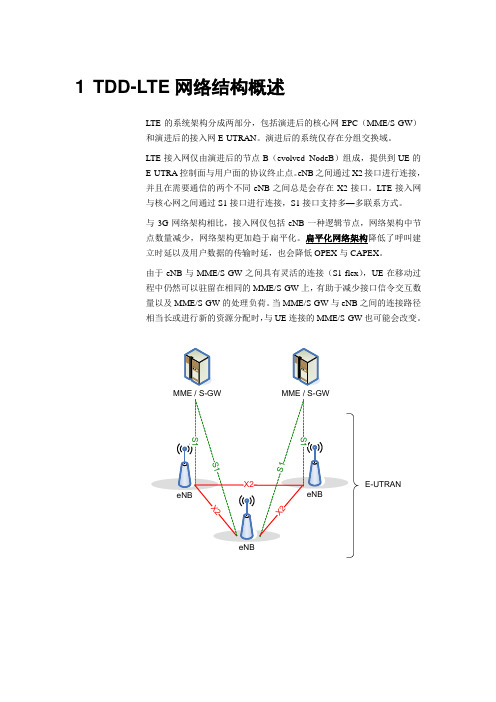
1 TDD-LTE网络结构概述LTE的系统架构分成两部分,包括演进后的核心网EPC(MME/S-GW)和演进后的接入网E-UTRAN。
演进后的系统仅存在分组交换域。
LTE接入网仅由演进后的节点B(evolved NodeB)组成,提供到UE的E-UTRA控制面与用户面的协议终止点。
eNB之间通过X2接口进行连接,并且在需要通信的两个不同eNB之间总是会存在X2接口。
LTE接入网与核心网之间通过S1接口进行连接,S1接口支持多—多联系方式。
与3G网络架构相比,接入网仅包括eNB一种逻辑节点,网络架构中节点数量减少,网络架构更加趋于扁平化。
扁平化网络架构降低了呼叫建立时延以及用户数据的传输时延,也会降低OPEX与CAPEX。
由于eNB与MME/S-GW之间具有灵活的连接(S1-flex),UE在移动过程中仍然可以驻留在相同的MME/S-GW上,有助于减少接口信令交互数量以及MME/S-GW的处理负荷。
当MME/S-GW与eNB之间的连接路径相当长或进行新的资源分配时,与UE连接的MME/S-GW也可能会改变。
整体网络结构图如下:1.1 EPC 与E-UTRAN 功能划分与3G 系统相比,由于重新定义了系统网络架构,核心网和接入网之间的功能划分也随之有所变化,需要重新明确以适应新的架构和LTE 的系统需求。
针对LTE 的系统架构,网络功能划分如下图:E-UTRANeNB功能:1)无线资源管理相关的功能,包括无线承载控制、接纳控制、连接移动性管理、上/下行动态资源分配/调度等;2)IP头压缩与用户数据流加密;3)UE附着时的MME选择;4)提供到S-GW的用户面数据的路由;5)寻呼消息的调度与传输;6)系统广播信息的调度与传输;7)测量与测量报告的配置。
MME功能:1)寻呼消息分发,MME负责将寻呼消息按照一定的原则分发到相关的eNB;2)安全控制;3)空闲状态的移动性管理;4)SAE承载控制;5)非接入层信令的加密与完整性保护。

Python 全栈工程师必备面试题300 道(2020 版)Python 面试不仅需要掌握Python 基础知识和高级语法,还会涉及网络编程、web 前端后端、数据库、网络爬虫、数据解析、数据分析和数据可视化等各方面的核心知识。
本人结合自己多年的开发经验,同时汲取网络中的精华,本着打造全网最全面最深入的面试题集,分类归纳总结了Python 面试中的核心知识点,这篇文章不论是从深度还是广度上来讲,都已经囊括了非常多的知识点了,读者可以根据自己的需要强化升级自己某方面的知识点,文中所有案例在Python3.6 环境下都已通过运行。
本文章是作者呕心沥血,耗时两个月潜心完成。
通过阅读本文章,可以在最短的时间内获取Python 技术栈最核心的知识点,同时更全面更深入的了解与Python 相关的各项技术。
1. Python 基础知识1.1 语言特征及编码规范1.1.1 Python 的解释器有哪些?1.1.2 列举至少 5 条Python 3 和Python 2 的区别?1.1.3 Python 中新式类和经典类的区别是什么?1.1.4 Python 之禅是什么,Python 中如何获取Python 之禅?1.1.5 python中的DocStrings(解释文档)有什么作用?1.1.6 Python 3 中的类型注解有什么好处?如何使用?1.1.7 Python 语言中的命名规范有哪些?1.1.8 Python 中各种下划线的作用?1.1.9 单引号、双引号、三引号有什么区别?1.2 文件I/O 操作1.2.1 Python 中打开文件有哪些模式?1.2.2 Python 中read 、readline 和readlines 的区别?1.2.3 大文件只需读取部分内容,或者避免读取时候内存不足的解决方法?1.2.4 什么是上下文?with 上下文管理器原理?1.2.5 什么是全缓冲、行缓冲和无缓冲?1.2.6 什么是序列化和反序列化?JSON 序列化时常用的四个函数是什么?1.2.7 JSON 中dumps 转换数据时候如何保持中文编码?1.3 数据类型1.3.1 Python 中的可变和不可变数据类型是什么?1.3.2 is 和== 有什么区别?1.3.3 Python 中的单词大小写转换和字母统计?1.3.4 字符串,列表,元组如何反转?反转函数reverse 和reversed 的区别?1.3.5 Python 中的字符串格式化的方法有哪些?f-string 格式化知道吗?1.3.6 含有多种符号的字符串分割方法?1.3.7 嵌套列表转换为列表,字符串转换为列表的方法1.3.8 列表合并的常用方法?1.3.9 列表如何去除重复的元素,还是保持之前的排序?1.3.10 列表数据如何筛选,筛选出符合要求的数据?1.3.11 字典中元素的如何排序?sorted 排序函数的使用详解? 1.3.12 字典如何合并?字典解包是什么?1.3.13 字典推导式使用方法?字典推导式如何格式化cookie 值?1.3.14 zip 打包函数的使用?元组或者列表中元素生成字典?1.3.15 字典的键可以是哪些类型的数据?1.3.16 变量的作用域是怎么决定的?1.4 常用内置函数1.4.1 如何统计一篇文章中出现频率最高的 5 个单词?1.4.2 map 映射函数按规律生成列表或集合?1.4.3 filter 过滤函数如何使用?如何过滤奇数偶数平方根数?1.4.4 sort 和sorted 排序函数的用法区别?1.4.5 enumerate 为元素添加下标索引?1.4.6 lambda 匿名函数如何使用?1.4.7 type 和help 函数有什么作用?2. Python 高级语法2.1 类和元类2.1.1 类class 和元类metaclass 的有什么区别?2.1.2 类实例化时候,__init__ 和__new__ 方法有什么作用?2.1.3 实例方法、类方法和静态方法有什么不同?2.1.4 类有哪些常用的魔法属性以及它们的作用是什么?2.1.5 类中的property 属性有什么作用?2.1.6 描述一下抽象类和接口类的区别和联系?2.1.7 类中的私有化属性如何访问?2.1.8 类如何才能支持比较操作?2.1.9 hasattr()、getattr()、setattr()、delattr()分别有什么作用?2.2 高级用法(装饰器、闭包、迭代器、生成器)2.2.1 编写函数的四个原则是什么?2.2.2 函数调用参数的传递方式是值传递还是引用传递?2.2.3 Python 中pass 语句的作用是什么?2.2.4 闭包函数的用途和注意事项?2.2.5 *args 和**kwargs 的区别?2.2.6 位置参数、关键字参数、包裹位置参数、包裹关键字参数执行顺序及使用注意?2.2.7 如何进行参数拆包?2.2.8 装饰器函数有什么作用?装饰器函数和普通函数有什么区别?2.2.9 带固定参数和不定参数的装饰器有什么区别?2.2.10 描述一下一个装饰器的函数和多个装饰器的函数的执行步骤? 2.2.11 知道通用装饰器和类装饰器吗?2.2.12 浅拷⻉和深拷⻉的区别?2.2.13 元组的拷⻉要注意什么?2.2.14 全局变量是否一定要使用global 进行声明?2.2.15 可迭代对象和迭代器对象有什么区别?2.2.16 描述一下for 循环执行的步骤?2.2.17 迭代器就是生成器,生成器一定是迭代器,这句话对吗?2.2.18 yield 关键字有什么好处?2.2.19 yield 和return 关键字的关系和区别?2.2.20 简单描述一下yield 生成器函数的执行步骤?2.2.21 生成器函数访问方式有哪几种?生成器函数中的send() 有什么作用?2.2.22 Python 中递归的最大次数?2.2.23 递归函数停止的条件是什么?2.4 模块2.4.1 如何查看模块所在的位置?2.4.2 import 导入模块时候,搜索文件的路径顺序?2.4.3 多模块导入共享变量的问题?2.4.4 Python 常用内置模块有哪些?2.4.5 Python 中常⻉的异常有哪些?2.4.6 如何捕获异常?万能异常捕获是什么?2.4.7 Python 异常相关的关键字主要有哪些?2.4.8 异常的完整写法是什么?2.4.9 包中的__init__.py 文件有什么作用?2.4.10 模块内部的__name__ 有什么作用?2.5 面向对象2.5.1 面向过程和面向对象编程的区别?各自的优缺点和应用场景?2.5.2 面向对象设计的三大特征是什么?2.5.3 面向对象中有哪些常用概念?2.5.4 多继承函数有那几种书写方式?2.5.5 多继承函数执行的顺序(MRO)?2.5.6 面向对象的接口如何实现?2.6 设计模式2.6.1 什么是设计模式?2.6.2 面向对象中设计模式的六大原则是什么?2.6.3 列举几个常⻉的设计模式?2.6.4 Mixin 设计模式是什么?它的特点和优点?2.6.5 什么是单例模式?单例模式的作用?2.6.7 单例模式的应用场景有那些?2.7 内存管理2.7.1 Python 的内存管理机制是什么?2.7.2 Python 的内寸管理的优化方法?2.7.3 Python 中内存泄漏有哪几种?2.7.4 Python 中如何避免内存泄漏?2.7.5 内存溢出的原因有哪些?2.7.6 Python 退出时是否释放所有内存分配?3. 系统编程3.1 多进程、多线程、协程、并行、并发、锁3.1.1 并发与并行的区别和联系?3.1.2 程序中的同步和异步与现实中一样吗?3.1.3 进程、线程、协程的区别和联系?3.1.4 多进程和多线程的区别?3.1.5 协程的优势是什么?3.1.6 多线程和多进程分别用于哪些场景?3.1.7 全局解释器锁(GIL)是什么?如何解决GIL 问题?3.1.8 Python 中有哪些锁(LOCK)?它们分别有什么作用?3.1.9 Python 中如何实现多线程和多进程?3.1.10 守护线程和非守护线程是什么?3.1.11 多线程的执行顺序是什么样的?3.1.12 多线程非安全是什么意思?3.1.13 互斥锁是什么?有什么好处和坏处?3.1.14 什么是僵尸进程和孤儿进程?3.1.15 多线程和多进程如何实现通信?3.1.16 Python 3 中multiprocessing.Queue() 和queue.Queue() 的区别?3.1.17 如何使用多协程并发请求网⻉?3.1.18 简单描述一下asyncio 模块实现异步的原理?4. 网络编程4.1 TCP UDP HTTP SEO WSGI 等4.1.1 UDP 和TCP 有什么区别以及各自的优缺点?4.1.2 IP 地址是什么?有哪几类?4.1.3 举例描述一下端口有什作用?4.1.4 不同电脑上的进程如何实现通信的?4.1.5 列举一下常用网络通信名词?4.1.6 描述一下请求一个网⻉的步骤(浏览器访问服务器的步骤)?4.1.7 HTTP 与HTTPS 协议有什么区别?4.1.8 TCP 中的三次握手和四次挥手是什么?4.1.9 TCP 短连接和⻉连接的优缺点?各自的应用场景?4.1.10 TCP 第四次挥手为什么要等待2MSL?4.1.11 HTTP 最常⻉的请求方法有哪些?4.1.12 GET 请求和POST 请求有什么区别?4.1.13 cookie 和session 的有什么区别?4.1.14 七层模型和五层模型是什么?4.1.15 HTTP 协议常⻉状态码及其含义?4.1.16 HTTP 报文基本结构?列举常用的头部信息?4.1.17 SEO 是什么?4.1.18 伪静态URL、静态URL 和动态URL 的区别? 4.1.19 浏览器镜头请求和动态请求过程的区别?4.1.20 WSGI 接口有什么好处?4.1.21 简单描述浏览器通过WSGI 接口请求动态资源的过程?5. 数据库5.1 MySQL5.1.1 NoSQL 和SQL 数据库的比较?5.1.2 了解MySQL 的事物吗?事物的四大特性是什么?5.1.3 关系型数据库的三范式是什么?5.1.4 关系型数据库的核心元素是什么?5.1.5 简单描述一下Python 访问MySQL 的步骤?5.1.6 写一个Python 连接操作MySQL 数据库实例?5.1.7 SQL 语句主要有哪些?分别有什么作用?5.1.8 MySQL 有哪些常用的字段约束?5.1.9 什么是视图?视图有什么作用?5.1.10 什么是索引?索引的优缺点是什么?5.1.11 NULL 是什么意思?它和空字符串一样吗?5.1.12 主键、外键和索引的区别?5.1.13 char 和varchar 的区别?5.1.14 SQL 注入是什么?如何避免SQL 注入?5.1.15 存储引擎MyISAM 和InnoDB 有什么区别?5.1.16 MySQL 中有哪些锁?5.1.17 三种删除操作drop、truncate、delete 的区别? 5.1.18 MySQL 中的存储过程是什么?有什么优点?5.1.19 MySQL 数据库的有哪些种类的索引?5.1.20 MySQL 的事务隔离级别?5.1.21 MySQL 中的锁如何进行优化?5.1.22 解释MySQL 外连接、内连接与自连接的区别?5.1.23 如何进行SQL 优化?5.1.24 什么是MySQL 主从?主从同步有什么好处?5.1.25 MySQL 主从与MongoDB 副本集有什么区别?5.1.26 MySQL 账户权限怎么分类的?5.1.27 如何使用Python 面向对象操作MySQL 数据库?5.2 Redis5.2.1 Redis 是什么?常⻉的应用场景?5.2.2 Redis 常⻉数据类型有哪些?各自有什么应用场景?5.2.3 非关系型数据库Redis 和MongoDB 数据库的结构有什么区别?5.2.4 Redis 和MongoDB 数据库的键(key)和值(value)的区别?5.2.5 Redis 持久化机制是什么?有哪几种方式?5.2.6 Redis 的事务是什么?5.2.7 为什么要使用Redis 作为缓存?5.2.8 Redis 和Memcached 的区别?5.2.9 Redis 如何设置过期时间和删除过期数据?5.2.10 Redis 有哪几种数据淘汰策略?5.2.11 Redis 为什么是单线程的?5.2.12 单线程的Redis 为什么这么快?5.2.13 缓存雪崩和缓存穿透是什么?如何预防解决?5.2.14 布隆过滤器是什么?5.2.15 简单描述一下什么是缓存预热、缓存更新和缓存降级?5.2.16 如何解决Redis 的并发竞争Key 的问题?5.2.17 写一个Python 连接操作Redis 数据库实例?5.2.18 什么是分布式锁?5.2.19 Python 如何实现一个Redis 分布式锁?5.2.20 如何保证缓存与数据库双写时的数据一致性?5.2.21 集群是什么?Redis 有哪些集群方案?5.2.22 Redis 常⻉性能问题和解决方案?5.2.23 了解Redis 的同步机制么?5.2.24 如果有大量的key 需要设置同一时间过期,一般需要注意什么?5.2.25 如何使用Redis 实现异步队列?5.2.26 列举一些常用的数据库可视化工具?5.3 MongoDB5.3.1 NoSQL 数据库主要分为哪几种?分别是什么?5.3.2 MongoDB 的主要特点及适用于哪些场合?5.3.3 MongoDB 中的文档有哪些特性?5.3.4 MongoDB 中的key 命名要注意什么?5.3.5 MongoDB 数据库使用时要注意的问题?5.3.6 常用的查询条件操作符有哪些?5.3.7 MongoDB 常用的管理命令有哪些?5.3.8 MongoDB 为何使用GridFS 来存储文件?5.3.9 如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?5.3.10 分析器在MongoDB 中的作用是什么?5.3.11 MongoDB 中的名字空间(namespace)是什么?5.3.12 更新操作会立刻fsync 到磁盘吗?5.3.13 什么是master 或primary?什么是secondary 或slave?5.3.14 必须调用getLastError 来确保写操作生效了么?5.3.15 MongoDB 副本集原理及同步过程?5.3.16 MongoDB 中的分片是什么意思?5.3.17 “ObjectID”有哪些部分组成?5.3.18 在MongoDB 中什么是索引?5.3.19 什么是聚合?5.3.20 写一个Python 连接操作MongoDB 数据库实例?6. 数据解析提取6.1 正则表达式6.1.1 match、search 和findall 有什么区别?6.1.2 正则表达式的()、[]、{} 分别代表什么意思?6.1.3 正则表达式中的.* 、.+ 、.*? 、.+? 有什么区别?6.1.4 .*? 贪婪匹配的一种特殊情况?当* 和? 中间有一个字符会怎么样?6.1.5 \s 和\S 是什么意思?re.S 是什么意思?6.1.6 写一个表达式匹配座机或者手机号码?6.1.7 正则表达式检查Python 中使用的变量名是否合法?6.1.8 正则表达式检查邮箱地址是否符合要求?6.1.9 如何使用分组匹配HTML 中的标签元素?6.1.10 如何使用re.sub 去掉“028-******** # 这是一个电话号码”# 和后面的注释内容?6.1.11 re.sub 替换如何支持函数调用?举例说明?6.1.12 如何只匹配中文字符?6.1.13 如何过滤评论中的表情?6.1.14 Python 中的反斜杠\ 如何使用正则表达式匹配?6.1.15 如何提取出下列网址中的域名?6.1.16 去掉'ab;cd%e\tfg,,jklioha;hp,vrww\tyz' 中的符号,拼接为一个字符串?6.1.17 str.replace 和re.sub 替换有什么区别?6.1.18 如何使用重命名分组修改日期格式?6.1.19 (?:x) a(?=x) a(?!=x) (?<=x)a (?<!x)a 有什么区别?6.2 XPath6.2.1 XML 是什么?XML 有什么用途?6.2.2 XML 和HTML 之间有什么不同?6.2.3 描述一下XML lxml XPath 之间有什么关系?6.2.4 介绍一下XPath 的节点?6.2.5 XPath 中有哪些类型的运算符?6.2.6 XPath 中的/// 、./ 、../ 、.// 别有什么区别?6.2.7 XPath 中如何同时选取多个路径?6.2.8 XPath 中的* 和@* 分别表示什么含义?6.2.9 如何使用位置属性选取节点中的元素?6.2.10 XPath 中如何多条件查找?6.2.11 Scrapy 和lxml 中的XPath 用法有什么不同?6.2.12 用过哪些常用的XPath 开发者工具?6.3 BeautifulSoup46.3.1 BeautifulSoup4 是什么?有什么特点?6.3.2 三种解析工具:正则表达式lxml BeautifulSoup4 各自有什么优缺点?6.3.3 etree.parse()、etree.HTML() 和etree.tostring() 有什么区别?6.3.4 BeautifulSoup4 支持的解析器以及它们的优缺点?6.3.5 BeautifulSoup4 中的四大对象是什么?6.3.6 BeautifulSoup4 中如何格式化HTML 代码?6.3.7 BeautifulSoup4 中find 和find_all 方法的区别?6.3.8 string、strings 和stripped_strings 有什么区别?6.3.9 BeautifulSoup4 输出文档的编码格式是什么?7. 网络爬虫7.1 网络爬虫是什么?它有什么特征?7.2 Python 中常用的爬虫模块和框架有哪些?它们有什么优缺点? 7.3 搜索引擎中的ROBOTS 协议是什么?7.4 urlib 和requests 库请求网⻉有什么区别?7.5 网⻉中的ASCII Unicode UTF-8 编码之间的关系?7.6 urllib 如何检测网⻉编码?7.7 urllib 中如何使用代理访问网⻉?7.8 如果遇到不信任的SSL 证书,如何继续访问?7.9 如何提取和使用本地已有的cookie 信息?7.10 requests 请求中出现乱码如何解决?7.11 requests 库中response.text 和response.content 的区别?7.12 实际开发中用过哪些框架?7.13 Scrapy 和PySpider 框架主要有哪些区别?7.14 Scrapy 的主要部件及各自有什么功能?7.15 描述一下Scrapy 爬取一个网站的工作流程?7.16 Scrapy 中的中间件有什么作用?7.17 Scrapy 项目中命名时候要注意什么?7.18 Scrapy 项目中的常用命令有哪些?7.19 scrapy.Request() 中的meta 参数有什么作用?7.20 Python 中的协程阻塞问题如何解决?7.21 Scrapy 中常用的数据解析提取工具有哪些?7.22 描述一下Scrapy 中数据提取的机制?7.23 Scrapy 是如何实现去重的?指纹去重是什么?7.24 Item Pipeline 有哪些应用?7.25 Scrapy 中常用的调试技术有哪些?7.26 Scrapy 中有哪些常⻉异常以及含义?7.27 Spider、CrawlSpider、XMLFeedSpider 和RedisSpider 有什么区别?7.28 scrapy-redis 是什么?相比Scrapy 有什么优点?7.29 使用scrapy-redis 分布式爬虫,需要修改哪些常用的配置?7.30 常⻉的反爬虫措施有哪些?如何应对?7.31 BloomFitler 是什么?它的原理是什么?7.32 为什么会用到代理?代码展现如何使用代理?7.33 爬取的淘宝某个人的历史消费信息(登陆需要账号、密码、验证码),你会如何操作?7.34 网站中的验证码是如何解决的?7.35 动态⻉面如何有效的抓取?7.36 如何使用MondoDB 和Flask 实现一个IP 代理池?8. 数据分析及可视化8.1 Python 数据分析通常使用的环境、工具和库都有哪些?库功能是什么?8.2 常用的数据可视化工具有哪些?各自有什么优点?8.3 数据分析的一般流程是什么?8.4 数据分析中常⻉的统计学概念有哪些?8.5 归一化方法有什么作用?8.6 常⻉数据分析方法论?8.7 如何理解欠拟合和过拟合?8.8 为什么说朴素⻉叶斯是“朴素”的?8.9 Matplotlib 绘图中如何显示中文?8.10 Matplotlib 中如何在一张图上面画多张图?8.11 使用直方图展示多部电影 3 天的票房情况?8.12 描述一下NumPy array 对比Python list 的优势?8.13 数据清洗有哪些方法?。


编码规范版本:1.0目录1. 简介 (4)1.1目的 (4)1.2范围 (4)1.3对象 (4)2. C#编程风格 (4)2.1格式 (4)2.1.1 空白 (4)2.1.2 花括号 (5)2.1.3 类的组织 (5)2.2命名 (5)2.2.1 一般原则 (5)2.2.2 缩略形式 (6)2.2.3 预处理器符号 (6)2.2.4 类型和常量 (6)2.2.5 枚举 (7)2.2.6 接口 (7)2.2.7 属性 (8)2.2.8 方法 (8)2.2.9 变量和参数 (9)2.2.10 特性 (10)2.2.11 命名空间 (10)2.2.12 事件处理 (10)2.2.13 异常 (10)2.3文档 (11)2.3.1 一般原则 (11)2.3.2 API (11)2.3.3 内部代码 (12)2.4设计 (13)2.4.1 工程 (13)2.4.2 类的设计 (13)2.4.3 线程安全和并发 (14)2.4.4 效率 (14)2.5编程 (14)2.5.1 类型 (14)2.5.2 语句和表达式 (16)2.5.3 控制流程 (16)2.5.4 类 (16)2.5.5 生命周期 (17)2.5.6 字段和属性 (17)2.5.7 方法 (18)2.5.8 特性 (18)2.5.9 泛型 (18)2.5.10 枚举 (18)2.5.11 类型安全、强制转换与转换 (18)1. 简介1.1 目的编程语言的语法告诉你可以写什么样的代码――机器可以理解的代码。
而风格则告诉你应该编写怎样的代码――阅读代码的人可以理解的代码。
采用一致、简单风格编写的代码可维护、健壮、更少缺陷。
而不顾及一致的代码包含更多缺陷,最好是推翻重写而不是维护。
团队开发时,留心代码风格尤其重要。
一致的代码风格有助于沟通,因为它让团队成员更容易阅读和理解他人的代码。
一个团队要想有成效,每个人都必须能阅读并理解其他人的代码。
拥有一致的风格约定将是个良好的开始!1.2 范围适用于C#.NET……1.3 对象团队中所有C#程序员。

构件图1.概述构件图(Component Diagram)是一种描述系统静态结构的图,它描述了构件的内部结构,以及构件与构件之间的关系。
一个典型的构件图如图1所示,它描述了一个包含Order,Customer,Product等其他构件的Store构件。
图1. 构件图2.基本表示符号构件图的基本元素有构件、接口、端口以及表示内部结构的部件和连接器等。
2.1 构件(Component)UML2.0规范把构件定义为:系统的一类模块,隐藏了细节,并且可以被其它实现了该功能的其它模块替换。
在UML中,构件用带有« component »关键字的矩形表示。
作为可选项,图标可以添加到该矩形的右上角。
构件的图形表示如图2所示:图2. 构件2.2 接口(Interface)接口是一种类元,它定义了一组操作,以及一些公共属性。
接口内部的所有操作都没有任何实现,它描述了一种契约,任何继承并实现该接口的类元都必须保证执行该契约。
接口有供给接口(Provided Interface)和需求接口(Required Interface)两种,如图3所示。
由构件(或类)实现的接口称为供给接口,构件(或类)需要的接口称为需求接口。
图3. 供给接口和需求接口不同构件的供给接口和需求接口之间的关系,既可以通过“依赖”来表示,如图4所示:图4. 接口之间的“依赖”也可通过“装配连接器”(见2.6部分)表示,如图5所示:图5. 接口之间通过“连接器”连接端口是构件与外部系统进行交互的纽带。
在UML中,端口符号表示为一个小长方形,端口的名字是可选的,如图6所示:.图6. 端口端口可以具有多重性,多重性显示在矩形内部,端口名称和类型名称之后。
多重性表示该类元实例可以具有的端口的数目。
端口的多重性如图7所示:图7. 端口的多重性2.4 构件内部结构(Internal Structure)构件可以具有内部结构,可以在构件内部展现其部件,或者通过依赖关系把部件从外部系统连接到该构件,如图8所示:图8. 构件的内部结构部件是类元的结构化成员,它描述了一个实例在该类元实例内部所扮演的角色。
**市国土资源局“一张图”及综合管理平台建设技术要求1.建设目标与任务**市国土资源局“一张图”数据库及数据管理应用平台是指基于统一的地理空间框架,建设全市国土资源“一张图”数据库和国土资源综合管理平台。
系统集成土地资源、矿产资源、地质灾害和卫片执法监察等多源数据集的**市国土资源“一张图”本底数据库,建设数据管理应用平台。
实现国土资源利用管理“批、供、用、补、查”全面监管,及时、准确地掌握国土资源真实现状,为国土资源业务应用系统提供统一的数据应用服务,同时为各级政府部门、企事业单位和个人提供多用途、多功能的数据共享和信息服务。
1.1.建设目标(1)通过**市国土资源“一张图”建设,形成国土资源核心数据库及数据管理系统,并使其成为国土资源政务信息系统、资源监管平台的数据支持环境,为国土资源审批、资源监管提供统一的数据和技术保障。
(2)建设完善的市本级和四个县(市、区)数据库“一张图”数据整合、入库管理和应用,建立数据交换、数据服务及其发布标准。
(3)将国土资源核心数据库建成支撑国土资源信息共享和社会化服务的数据支持环境,通过“历史库”、“现势库”、“中间库”三者不同状态下的写入输出,为实现国土资源数据最大限度地社会化服务提供数据和技术保障。
(4)通过综合管理平台建设,整合全市国土资源行政审批及其业务办理、行政办公业务流程,实现“批、供、用、补、查”在应用系统中的全面实现和全市国土资源管理及利用的动态监管。
1.2.建设任务(1)制定数据库入库标准、业务数据交换标准、数据应用和服务技术标准、数据整合技术标准、数据更新技术标准。
(2)建设集成土地资源、矿产资源、地质灾害和执法监察等多源数据集的**市国土资源“一张图”本底数据库。
依据相关数据建设标准、规范,对多源、海量、异构数据进行转换、整理等,按照统一建库标准进行数据库入库。
海量数据库建设做到性能优化,满足海量数据浏览和显示、后期数据维护和更新需求。
MII (Media Independent Interface(介质无关接口);或称为媒体独立接口,它是IEEE-802.3定义的以太网行业标准。
它包括一个数据接口,以及一个MAC和PHY之间的管理接口。
数据接口包括分别用于发送器和接收器的两条独立信道。
每条信道都有自己的数据、时钟和控制信号。
MII数据接口总共需要16个信号。
管理接口是个双信号接口:一个是时钟信号,另一个是数据信号。
通过管理接口,上层能监视和控制PHY。
MII (Management interface)只有两条信号线。
目录展开编辑本段概述MII标准接口用于连快Fast Ethernet MAC-block与PHY。
"介质无关"表明在不对MAC硬件重新设计或替换的情况下,任何类型的PHY设备都可以正常工作。
在其他速率下工作的与 MII等效的接口有:AUI(10M 以太网)、GMII(Gigabit 以太网)和XAUI(10-Gigabit 以太网)。
编辑本段MIICPU1997年,Cyrix被称作MII的新一代微处理器已正式推出.MII是在Cyrix在大规模投放市场的6X86的基础上将其第一级高速缓冲内存由原有的16K扩大到64K,大大地增加了运算速度,同时在流行的X86指令集中加入了MMX的功能。
MII传承了6X86出色的运行32位软件的功能并具有MMX功能。
所谓MMX是指一套加在流行的X86指令集的附加指令,它包括57条为加速多媒体单元设计的新指令,包括音频处理、视频解压和图形处理等。
Cyrix新的MII处理器依然是为用户提供一种简单的升级方法,以使他们的计算机拥有MMX技术。
相比INTEL和AMD的同时期CPU,MII的优势仍然在整数运算,其浮点运算仍然为人们所诟病.时至今日,Cyrix被威盛所收购,早已不复存在,这款处理器成为人们心中的回忆.作为Cyrix公司独自研发的最后一款微处理器,Cyrix MII于1998年3月开始量产。
2.4实例和类成员
2.4.5 对象和类
你可能会注意到对象和类看起来很相似。
在现实世界中,类和对象之间的区别经常是让程序员困惑的源泉。
在现实世界中,很明显,类不能是它们描述的对象本身。
然而,在软件中很困难来区分类和对象。
有部分原因是软件对象只是现实世界中的电子模型或者是抽象概念。
但是也因为对象通常有时是指类和实例。
2.5什么是继承
一个类可以从它的父类继承状态和行为。
继承为组织和构造软件程序提供了一个强大的和自然的机理。
总得说来,对象是以类得形式来定义得。
你可能现在已经可以从它类知道许多对象了。
即使你如知道,如果我告诉你它是一辆自行车,你就会知道它有两个轮子和脚踏板等等。
面向对象系统就更深入一些了,它允许类在其它类中定义。
比如,山地自行车、赛车以及串座双人自行车都是各种各样的自行车。
在面向对象技术中,山地自行车、赛车以及串座双人自行车都是自行车类的子类。
同样地,自行车类是山地自行车、赛车以及串座双人自行车的父类。
这个父子关系可以如图9所示:
(图9)
每一个子例从父类中继承了状态。
山地自行车、赛车以及串座双人自行车共享了这些状态:速度等。
同样,每一个子类继承类从父类的方法,山地自行车、赛车以及串座双人自行车共享了这些行为:刹车、改变脚踏速度等等。
2.5什么是继承
然而,子类不能受到父类提供的状态和行为的限制。
子类可以增加变量和方法到从父类继承而来的变量和方法。
比如,串座双人自行车有两个座位,这是它的父类没有的。
子类同样可以重载继承的方法并且为这些方法提供特殊执行方法。
比如,如果你有一个山地自行车有额外的齿轮设置,你就可以重载改变齿轮方法来使骑车者可以使用这些新的齿轮。
你也不能受限于继承的一个层次。
继承树或者类的分级结构可以是很深。
方法和变量是逐级继承的。
总的来说,在分级结构的越下方,就有越多的行为。
如果对象类处于分级结构的顶端,那么每个类都是它的后代(直接地或者是间接地)。
一种类型的对象保留任何对象的一个引用,比如类或者数组的一个实例。
对象提供了行为,这些行为是运行在JAVA虚拟机所需要的。
比如,所有类继承了对象的toString方法,它返回了代表对象的字符串。
下面说说我们为什么要使用继承,它到底有哪些好处呢?好处是有的:
1.子类提供了特殊的行为,这是在父类中所没有的。
通过使用继承,程序员
可以多次重新使用在父类中的代码。
2.程序员可以执行父类(称为抽象类)来定义总的行为。
这个抽象的父类可
以定义并且部分执行行为,但是绝大多数的父类是未定义和未执行的。
其它的部分由程序员来实现特殊的子类。
2.6什么是接口
接口是一个收集方法和常数表单的契约。
当类执行一个接口,它就许诺声明在那个接口中执行所有的方法。
接口是一个设备或者一个系统,它是用于交互的无关的实体。
根据这个定义,远程控制是一个在你和电视的接口;而英语是两个人之间的接口;强制在军事中的行为协议是不同等价人之间的接口。
在JAVA语言中,接口是一个设备,它是用来与其它对象交互的设备。
一个接口可能对一个协议是类似的。
实际上,其它面向对象语言有接口的功能,但它们调用它们的接口协议。
自行车类和它的类分级结构定义了什么是自行车。
但是自行车在其它方面与现实世界交互作用,例如,仓库中的自行车可以由一个存货程序来管理。
一个存货程序不关心管理项目的哪一类只要项目提供某一信息,比如价格和跟踪数字。
取代强迫类与其它无关项的关系,存货程序建立了通讯的协议。
这个协议是由包含在接口中的常数和方法定义组成的。
这个存货清单接口将要定义(但不执行)方法来设置和得到零售价格,指定跟踪数字等等。
为了在存货清单程序中操作,自行车类必须在执行接口的时候遵守这个协议。
当一个了执行一个接口的时候,类遵守定义在接口中的所有方法。
因此,自行车将为这些设置和获得零售价格并指定跟踪数值等等的方法提供执行。
你可以使用接口来定义一个行为的协议,这个行为可以有在类分级结构中任何类来执行。
接口的主要好处有一下几点:
1.不用人工强迫类关系在无关类中截获相似处。
2.声明想执行的一个或者更多类的方法。
3.在不暴露对象的类的前提下,暴露对象的编程接口。