一元线性回归中的假设检验和预测
- 格式:ppt
- 大小:197.00 KB
- 文档页数:11


《应用回归分析》实验指导书倪伟才编二00四年十一月《应用回归分析》实验指导书一、实验教学简介《应用回归分析》是统计专业的必修课程,同时也是核心课程。
该课程教学是以数学分析、线性代数、概率统计为预备知识,同时为计量经济学课程的教学奠定基础。
本课程在系统介绍回归分析基本理论和方法的同时,结合社会、经济、医学等领域的实际例子,把回归分析方法和实际应用相结合,注意定性分析和定量分析的紧密结合。
实验教学是该课程必不可少的、重要的组成部分。
本实验课程的案例中的数据处理主要运用我国已较流行的SPSS统计软件来实现,再结合SAS与Excel。
通过本课程的学习,使学生能够熟练地运用SPSS 统计软件进行回归分析,利用回归的方法解决一些实际问题,同时介绍SPSS使用中的一些小技巧。
实验教学的主要内容有:一元线性回归模型的估计、回归系数的检验、回归方程的检验、预测;多元线性回归模型的估计、回归系数的检验、回归方程的检验、预测;异方差的检验(多种检验方法);加权最小二乘估计;自相关性的诊断及差分法;逐步回归法;多重共线性的诊断;岭回归;多项式回归;曲线回归等。
二、实验教学目的与任务通过对本课程的实验教学,不仅使学生掌握回归分析的基本概念、基本原理、基本方法,而且能够熟练地运用SPSS统计软件进行回归分析,利用回归的方法解决一些实际问题,同时掌握SPSS使用中的一些小技巧。
强调定性分析与定量分析的有机结合,注重理论水平和实际操作的有机结合。
三、实验教学数据的存放本实验指导书涉及到的数据均以SPSS格式或Excel格式给出,并放在班级的服务器上,学生完全可以共享。
为了保持实验指导书的完整性,所有的数据也附在每一个实验的题目后面。
四、实验内容实验一:一元线性回归模型的估计、回归系数和回归方程的检验、预测(验证性实验2课时)实验题目:一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。
经过10周时间,收集了每周加班工作时间的数据及签发的新保单数目,x为每周签发的新保单数目,y为每周加班工作时间(小时),数据如下:1:画散点图;3:用最小二乘法估计回归方程;4:求回归标准误;5:求回归系数的置信度为95%的区间估计;6:计算x与y的决定系数;7:对回归方程做方差分析;8:做回归系数β1的显著性检验;9:做相关系数的显著性检验;10:该公司预测下一周签发新保单x0=1000,需要的加班时间是多少?11:分别给出置信水平为95%的均值与个体预测区间;12:请在散点图的基础上画出回归线,均值的预测区间图,个体的预测区间图。


一元线性回归分析摘要:一元线性回归分析是一种常用的预测和建模技术,广泛应用于各个领域,如经济学、统计学、金融学等。
本文将详细介绍一元线性回归分析的基本概念、模型建立、参数估计和模型检验等方面内容,并通过一个具体的案例来说明如何应用一元线性回归分析进行数据分析和预测。
1. 引言1.1 背景一元线性回归分析是通过建立一个线性模型,来描述自变量和因变量之间的关系。
通过分析模型的拟合程度和参数估计值,我们可以了解自变量对因变量的影响,并进行预测和决策。
1.2 目的本文的目的是介绍一元线性回归分析的基本原理、建模过程和应用方法,帮助读者了解和应用这一常用的数据分析技术。
2. 一元线性回归模型2.1 模型表达式一元线性回归模型的基本形式为:Y = β0 + β1X + ε其中,Y是因变量,X是自变量,β0和β1是回归系数,ε是误差项。
2.2 模型假设一元线性回归模型的基本假设包括:- 线性关系假设:自变量X与因变量Y之间存在线性关系。
- 独立性假设:每个观测值之间相互独立。
- 正态性假设:误差项ε服从正态分布。
- 同方差性假设:每个自变量取值下的误差项具有相同的方差。
3. 一元线性回归分析步骤3.1 数据收集和整理在进行一元线性回归分析之前,需要收集相关的自变量和因变量数据,并对数据进行整理和清洗,以保证数据的准确性和可用性。
3.2 模型建立通过将数据代入一元线性回归模型的表达式,可以得到回归方程的具体形式。
根据实际需求和数据特点,选择适当的变量和函数形式,建立最优的回归模型。
3.3 参数估计利用最小二乘法或最大似然法等统计方法,估计回归模型中的参数。
通过最小化观测值与回归模型预测值之间的差异,找到最优的参数估计值。
3.4 模型检验通过对回归模型的拟合程度进行检验,评估模型的准确性和可靠性。
常用的检验方法包括:残差分析、显著性检验、回归系数的显著性检验等。
4. 一元线性回归分析实例为了更好地理解一元线性回归分析的应用,我们以房价和房屋面积之间的关系为例进行分析。

竭诚为您提供优质文档/双击可除一元回归及检验实验报告篇一:一元线性回归模型的参数估计实验报告山西大学实验报告实验报告题目:计量经济学实验报告学院:专业:课程名称:计量经济学学号:学生姓名:教师名称:崔海燕上课时间:一、实验目的:掌握一元线性回归模型的参数估计方法以及对模型的检验和预测的方法。
二、实验原理:1、运用普通最小二乘法进行参数估计;2、对模型进行拟合优度的检验;3、对变量进行显著性检验;4、通过模型对数据进行预测。
三、实验步骤:(一)建立模型1、新建工作文件并保存打开eviews软件,在主菜单栏点击File\new\workfile,输入startdate1978和enddate20XX并点击确认,点击save 键,输入文件名进行保存。
2输入并编辑数据在主菜单栏点击Quick键,选择empty\group新建空数据栏,先输入被解释变量名称y,表示中国居民总量消费,后输入解释变量x,表示可支配收入,最后对应各年分别输入数据。
点击name键进行命名,选择默认名称group01,保存文件。
得到中国居民总量消费支出与收入资料:xY年份19786678.83806.719797551.64273.219807944.24605.5198 184385063.919829235.25482.4198310074.65983.21984115 656745.7198511601.77729.2198613036.58210.9198714627 .788401988157949560.5198915035.59085.5199016525.994 50.9199118939.610375.8199222056.511815.3199325897.3 13004.7199428783.413944.2199531175.415467.919963385 3.717092.5199735956.218080.6199838140.919364.119994 027720989.3200042964.622863.920XX20XX20XX20XX20XX20XX46385.45127457408.164623.17 4580.485623.124370.126243.22803530306.233214.436811 .2注:y表示中国居民总量消费x表示可支配收入3、画散点图,判断被解释变量与解释变量之间是否为线性关系在主菜单栏点击Quick\graph出现对话框,输入“xy”,点击确定。

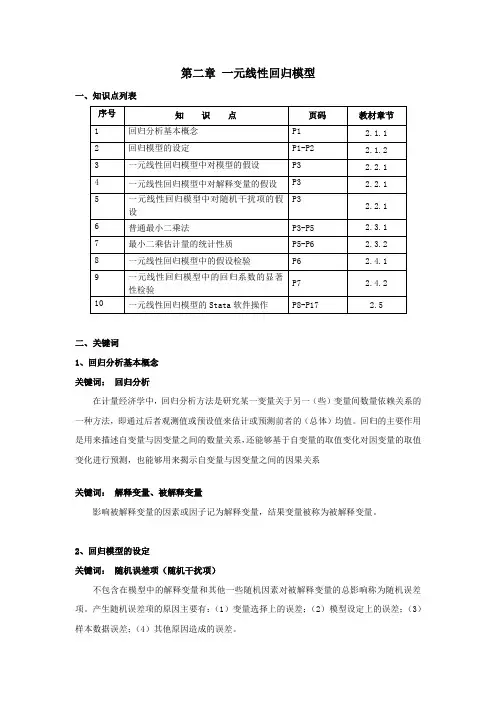
第二章一元线性回归模型一、知识点列表二、关键词1、回归分析基本概念关键词:回归分析在计量经济学中,回归分析方法是研究某一变量关于另一(些)变量间数量依赖关系的一种方法,即通过后者观测值或预设值来估计或预测前者的(总体)均值。
回归的主要作用是用来描述自变量与因变量之间的数量关系,还能够基于自变量的取值变化对因变量的取值变化进行预测,也能够用来揭示自变量与因变量之间的因果关系关键词:解释变量、被解释变量影响被解释变量的因素或因子记为解释变量,结果变量被称为被解释变量。
2、回归模型的设定关键词:随机误差项(随机干扰项)不包含在模型中的解释变量和其他一些随机因素对被解释变量的总影响称为随机误差项。
产生随机误差项的原因主要有:(1)变量选择上的误差;(2)模型设定上的误差;(3)样本数据误差;(4)其他原因造成的误差。
关键词:残差项(residual )通过样本数据对回归模型中参数估计后,得到样本回归模型。
通过样本回归模型计算得到的样本估计值与样本实际值之差,称为残差项。
也可以认为残差项是随机误差项的估计值。
3、一元线性回归模型中对随机干扰项的假设 关键词:线性回归模型经典假设线性回归模型经典假设有5个,分别为:(1)回归模型的正确设立;(2)解释变量是确定性变量,并能够从样本中重复抽样取得;(3)解释变量的抽取随着样本容量的无限增加,其样本方差趋于非零有限常数;(4)给定被解释变量,随机误差项具有零均值,同方差和无序列相关性。
(5)随机误差项服从零均值、同方差的正态分布。
前四个假设也称为高斯马尔科夫假设。
4、最小二乘估计量的统计性质关键词:普通最小二乘法(Ordinary Least Squares ,OLS )普通最小二乘法是通过构造合适的样本回归函数,从而使得样本回归线上的点与真实的样本观测值点的“总体误差”最小,即:被解释变量的估计值与实际观测值之差的平方和最小。
ββ==---∑∑∑nn n222i i 01ii=111ˆˆmin =min ()=min ()i i i i u y y y x关键词:无偏性由于未知参数的估计量是一个随机变量,对于不同的样本有不同的估计量。



一元线性回归方程回归系数的假设检验方法
一元线性回归方程是一种统计学方法,用于研究两个变量之间的关系。
它可以
用来预测一个变量(被解释变量)的值,另一个变量(解释变量)的值已知。
回归系数是一元线性回归方程的重要参数,它可以用来衡量解释变量对被解释变量的影响程度。
回归系数的假设检验是一种统计学方法,用于检验回归系数是否具有统计学意义。
它的基本思想是,如果回归系数的值不是0,则表明解释变量对被解释变量有
显著的影响,反之则表明解释变量对被解释变量没有显著的影响。
回归系数的假设检验一般采用t检验或F检验。
t检验是检验单个回归系数是
否具有统计学意义的方法,而F检验是检验多个回归系数是否具有统计学意义的方法。
在进行回归系数的假设检验时,首先要确定检验的显著性水平,一般为0.05
或0.01。
然后,根据检验的类型,计算t值或F值,并与检验的显著性水平比较,如果t值或F值大于显著性水平,则拒绝原假设,即认为回归系数具有统计学意义;反之,则接受原假设,即认为回归系数没有统计学意义。
回归系数的假设检验是一种重要的统计学方法,它可以用来检验回归系数是否
具有统计学意义,从而更好地理解解释变量对被解释变量的影响程度。

§2.5 一元线性回归模型的置信区间与预测多元线性回归模型的置信区间问题包括参数估计量的置信区间和被解释变量预测值的置信区间两个方面,在数理统计学中属于区间估计问题。
所谓区间估计是研究用未知参数的点估计值(从一组样本观测值算得的)作为近似值的精确程度和误差范围,是一个必须回答的重要问题。
一、参数估计量的置信区间在前面的课程中,我们已经知道,线性回归模型的参数估计量^β是随机变量i y 的函数,即:i i y k ∑=1ˆβ,所以它也是随机变量。
在多次重复抽样中,每次的样本观测值不可能完全相同,所以得到的点估计值也不可能相同。
现在我们用参数估计量的一个点估计值近似代表参数值,那么,二者的接近程度如何?以多大的概率达到该接近程度?这就要构造参数的一个区间,以点估计值为中心的一个区间(称为置信区间),该区间以一定的概率(称为置信水平)包含该参数。
即回答1β以何种置信水平位于()a a +-11ˆ,ˆββ之中,以及如何求得a 。
在变量的显著性检验中已经知道)1(~^^---=k n t s t iii βββ (2.5.1)这就是说,如果给定置信水平α-1,从t 分布表中查得自由度为(n-k-1)的临界值2αt ,那么t 值处在()22,ααt t -的概率是α-1。
表示为ααα-=<<-1)(22t t t P即αββαβα-=<-<-1)(2^2^t s t P iiiαββββαβα-=⨯+<<⨯-1)(^^2^2^iis t s t P i i i于是得到:在(α-1)的置信水平下i β的置信区间是)(^^2^2^iis t s t i i βαβαββ⨯+⨯-,i=0,1 (2.5.3)在某例子中,如果给定01.0=α,查表得012.3)13()1(005.02==--t k n t α 从回归计算中得到01.0,15,21.0ˆ,3.102ˆ1ˆˆ10====ββββS S 根据(2.5.2)计算得到10,ββ的置信区间分别为()48.147,12.57和(0.1799,0.2401) 显然,参数1β的置信区间要小。
线性回归模型的经典假定及检验、修正一、线性回归模型的基本假定1、一元线性回归模型一元线性回归模型是最简单的计量经济学模型,在模型中只有一个解释变量,其一般形式是Y =β0+β1X 1+μ其中,Y 为被解释变量,X 为解释变量,β0与β1为待估参数,μ为随机干扰项。
回归分析的主要目的是要通过样本回归函数(模型)尽可能准确地估计总体回归函数(模型)。
为保证函数估计量具有良好的性质,通常对模型提出若干基本假设。
假设1:回归模型是正确设定的。
模型的正确设定主要包括两个方面的内容:(1)模型选择了正确的变量,即未遗漏重要变量,也不含无关变量;(2)模型选择了正确的函数形式,即当被解释变量与解释变量间呈现某种函数形式时,我们所设定的总体回归方程恰为该函数形式。
假设2:解释变量X 是确定性变量,而不是随机变量,在重复抽样中取固定值。
这里假定解释变量为非随机的,可以简化对参数估计性质的讨论。
假设3:解释变量X 在所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X 的样本方差趋于一个非零的有限常数,即∑(X i −X ̅)2n i=1n→Q,n →∞ 在以因果关系为基础的回归分析中,往往就是通过解释变量X 的变化来解释被解释变量Y 的变化的,因此,解释变量X 要有足够的变异性。
对其样本方差的极限为非零有限常数的假设,旨在排除时间序列数据出现持续上升或下降的变量作为解释变量,因为这类数据不仅使大样本统计推断变得无效,而且往往产生伪回归问题。
假设4:随机误差项μ具有给定X 条件下的零均值、同方差以及无序列相关性,即E(μi|X i)=0Var(μi|X i)=σ2Cov(μi,μj|X i,X j)=0, i≠j随机误差项μ的条件零均值假设意味着μ的期望不依赖于X的变化而变化,且总为常数零。
该假设表明μ与X不存在任何形式的相关性,因此该假设成立时也往往称X为外生性解释变量随机误差项μ的条件同方差假设意味着μ的方差不依赖于X的变化而变化,且总为常数σ2。
§4.2 一元线性回归模型及其假设条件1.理论模型y=a+bx+εX 是解释变量,又称为自变量,它是确定性变量,是可以控制的。
是已知的。
Y 是被解释变量,又称因变量,它是一个随机性变量。
是已知的。
A,b 是待定的参数。
是未知的。
2.实际中应用的模型x b a yˆˆˆ+= ,bˆ,x 是已知的,y ˆ是未知的。
回归预测方程:x b a y += a ,b 称为回归系数。
若已知自变量x 的值,则通过预测方程可以预测出因变量y 的值,并给出预测值的置信区间。
3.假设条件满足条件:(1)E (ε)=0;(2)D (εi )=σ2;(3)Cov (εi ,εj )=0,i ≠j ; (4) Cov (εi ,εj )=0 。
条件(1)表示平均干扰为0;条件(2)表示随机干扰项等方差;条件(3)表示随机干扰项不存在序列相关;条件(4)表示干扰项与解释变量无关。
在假定条件(4)成立的情况下,随机变量y ~N (a+bx ,σ2)。
一般情况下,ε~N (0,σ2)。
4.需要得到的结果a ˆ,b ˆ,σ2§4.3 模型参数的估计1.估计原理回归系数的精确求估方法有最小二乘法、最大似然法等多种,我们这里介绍最小二乘法。
估计误差或残差:y y e i i i -=,x b a y i +=,e e y y ii i i x b a ++=+= (5.3—1)误差e i 的大小,是衡量a 、b 好坏的重要标志,换句话讲,模型拟合是否成功,就看残差是否达到要求。
可以看出,同一组数据,对于不同的a 、b 有不同的e i ,所以,我们的问题是如何选取a 、b 使所有的e i 都尽可能地小,通常用总误差来衡量。
衡量总误差的准则有:最大绝对误差最小、绝对误差的总和最小、误差的平方和最小等。
我们的准则取:误差的平方和最小。
最小二乘法:令 ()()∑∑---∑======n i ni n i i x b a y y y e i i i i Q 112212 (5.3—2)使Q 达到最小以估计出a 、b的方法称为最小二乘法。