opencv双目视觉三维重建代码
- 格式:docx
- 大小:37.36 KB
- 文档页数:3

reprojectimageto3d用法-回复标题:详解reprojectImageTo3D的用法在计算机视觉和三维重建领域,将二维图像转换为三维空间中的点云是一项基础且重要的任务。
OpenCV库中的reprojectImageTo3D函数就是用来实现这一功能的工具。
本文将详细解析reprojectImageTo3D的用法,以帮助读者理解和掌握这一重要工具。
首先,我们来了解一下reprojectImageTo3D函数的基本信息。
该函数位于OpenCV的calib3d模块中,其原型如下:cppvoid reprojectImageTo3D(const Mat& disparity, Mat& _3dImage, const Mat& Q, bool handleMissingValues = false, int ddepth = -1);这个函数的主要作用是将视差图(disparity)转换为三维点云(_3dImage),其中Q是一个4x4的矩阵,包含了从立体相机到世界坐标系的变换关系。
以下是一步一步使用reprojectImageTo3D函数的详细步骤:1. 准备输入数据:首先,我们需要一个视差图作为输入。
视差图通常是在进行立体匹配后得到的,它表示了左右两幅图像中对应像素之间的水平距离。
视差图通常是一个单通道的灰度图像。
2. 计算Q矩阵:Q矩阵是立体相机到世界坐标系的变换关系,它包含了相机的内参(焦距、主点等)和外参(旋转和平移)。
Q矩阵可以通过stereoRectify 函数或者自定义的方式得到。
3. 初始化输出矩阵:_3dImage是函数的输出,它将存储转换后的三维点云。
_3dImage的大小应与输入的视差图相同,每个像素对应一个三维点。
_3dImage的类型可以是CV_32FC3(每个像素由三个浮点数表示XYZ坐标)或者其他深度大于等于CV_32F的三通道格式。
4. 调用reprojectImageTo3D函数:现在我们可以调用reprojectImageTo3D函数进行转换了。

双目视觉 opencv 代码双目视觉是指利用两个摄像头来获取场景的深度信息。
在OpenCV中,可以使用双目视觉进行立体视觉的处理。
下面我将从多个角度介绍如何使用OpenCV来实现双目视觉的代码。
1. 初始化摄像头:首先,你需要初始化两个摄像头,可以使用OpenCV的VideoCapture类来实现。
你可以通过以下代码来初始化两个摄像头:cv::VideoCapture cap1(0); // 打开第一个摄像头。
cv::VideoCapture cap2(1); // 打开第二个摄像头。
2. 获取图像:接下来,你需要从两个摄像头中获取图像。
你可以使用以下代码来获取图像:cv::Mat frame1, frame2;cap1 >> frame1; // 从第一个摄像头获取图像。
cap2 >> frame2; // 从第二个摄像头获取图像。
3. 立体校正:在进行立体视觉处理之前,通常需要进行立体校正,以确保两个摄像头的图像对齐。
你可以使用OpenCV中的stereoRectify和initUndistortRectifyMap函数来实现立体校正。
4. 视差计算:一旦完成立体校正,你可以使用OpenCV中的StereoBM或StereoSGBM类来计算图像的视差。
这些类实现了不同的立体匹配算法,可以帮助你计算出图像中不同像素的视差值。
5. 三维重构:最后,你可以使用视差图和立体校正参数来进行三维重构,从而获取场景的深度信息。
你可以使用reprojectImageTo3D函数来实现三维重构。
以上是使用OpenCV实现双目视觉的基本步骤和代码示例。
当然,双目视觉涉及到的内容非常广泛,包括摄像头标定、深度图像的可视化等等,还有很多细节需要考虑。
希望以上内容能够帮助你入门双目视觉的代码实现。

《视觉几何三维重建-openmvs源码解析》课程手册引言概述:视觉几何三维重建是计算机视觉领域中的重要研究方向,而OpenMVS是一个流行的开源库,用于实现三维重建。
本文将对OpenMVS源码进行解析,深入探讨其实现原理和关键算法。
正文内容:1. 数据输入和预处理1.1 图像序列输入:OpenMVS支持从图像序列中进行三维重建,通过读取图像序列并提取特征点和描述子,构建相机姿态和特征点的初始估计。
1.2 特征点匹配:通过特征点的匹配,建立不同视角下的相机姿态和特征点之间的对应关系,为后续的三维重建提供基础。
2. 稀疏点云重建2.1 初始点云生成:根据相机姿态和特征点的对应关系,通过三角测量的方法生成初始的稀疏点云。
2.2 点云滤波:为了去除噪声和无效点,OpenMVS采用了一系列的滤波算法,如基于距离的滤波和法线一致性滤波等。
2.3 稀疏点云增量式重建:OpenMVS采用增量式的方法进行点云重建,通过不断添加新的视角和特征点,逐步完善和扩展点云模型。
3. 稠密点云重建3.1 图像对齐:为了实现稠密点云的重建,OpenMVS需要对输入的图像进行对齐,以消除不同视角之间的误差。
3.2 深度图生成:通过图像对齐后,OpenMVS使用立体匹配算法生成每个像素点的深度图。
3.3 点云生成:根据深度图和相机参数,OpenMVS将深度图转换为稠密点云,得到更加细致和完整的三维模型。
4. 网格生成和纹理映射4.1 网格生成:OpenMVS通过点云的重建,使用表面重建算法生成三角网格模型,将点云转换为更加紧凑和可视化的网格表示。
4.2 网格优化:为了提高网格的质量和减少噪声,OpenMVS采用了一系列的网格优化算法,如顶点平滑和边缘保持等。
4.3 纹理映射:通过将输入的图像映射到生成的网格模型上,OpenMVS实现了纹理的贴图,使得三维模型更加真实和具有视觉效果。
5. 三维模型重建结果的后处理5.1 点云和网格的滤波:为了去除噪声和无效点,OpenMVS对重建结果进行滤波处理,如基于法线的滤波和基于采样的滤波等。

学习笔记:使⽤opencv做双⽬测距(相机标定+⽴体匹配+测距).最近在做双⽬测距,觉得有必要记录点东西,所以我的第⼀篇博客就这么诞⽣啦~双⽬测距属于⽴体视觉这⼀块,我觉得应该有很多⼈踩过这个坑了,但⽹上的资料依旧是云⾥雾⾥的,要么是理论讲⼀⼤堆,最后发现还不知道怎么做,要么就是直接代码⼀贴,让你懵逼。
所以今天我想做的,是尽量给⼤家⼀个明确的阐述,并且能够上⼿做出来。
⼀、标定⾸先我们要对摄像头做标定,具体的公式推导在learning opencv中有详细的解释,这⾥顺带提⼀句,这本书虽然确实⽼,但有些理论、算法类的东西⾥⾯还是讲的很不错的,必要的时候可以去看看。
Q1:为什么要做摄像头标定?A: 标定的⽬的是为了消除畸变以及得到内外参数矩阵,内参数矩阵可以理解为焦距相关,它是⼀个从平⾯到像素的转换,焦距不变它就不变,所以确定以后就可以重复使⽤,⽽外参数矩阵反映的是摄像机坐标系与世界坐标系的转换,⾄于畸变参数,⼀般也包含在内参数矩阵中。
从作⽤上来看,内参数矩阵是为了得到镜头的信息,并消除畸变,使得到的图像更为准确,外参数矩阵是为了得到相机相对于世界坐标的联系,是为了最终的测距。
ps1:关于畸变,⼤家可以看到⾃⼰摄像头的拍摄的画⾯,在看矩形物体的时候,边⾓处会有明显的畸变现象,⽽矫正的⽬的就是修复这个。
ps2:我们知道双⽬测距的时候两个相机需要平⾏放置,但事实上这个是很难做到的,所以就需要⽴体校正得到两个相机之间的旋转平移矩阵,也就是外参数矩阵。
Q2:如何做摄像头的标定?A:这⾥可以直接⽤opencv⾥⾯的sample,在opencv/sources/sample/cpp⾥⾯,有个calibration.cpp的⽂件,这是单⽬的标定,是可以直接编译使⽤的,这⾥要注意⼏点:1.棋盘棋盘也就是标定板是要预先打印好的,你打印的棋盘的样式决定了后⾯参数的填写,具体要求也不是很严谨,清晰能⽤就⾏。
之所⽤棋盘是因为他检测⾓点很⽅便,and..你没得选。

《视觉几何三维重建-openmvs源码解析》课
程手册
引言概述:
视觉几何三维重建是计算机视觉领域的重要研究方向,其通过从多个视角的图像中恢复场景的三维结构和相机的位姿信息。
OpenMVS是一种开源的三维重建软件,其源码解析对于理解三维重建算法和实现自定义功能具有重要意义。
本文将通过对OpenMVS源码的解析,详细介绍视觉几何三维重建的基本原理和OpenMVS 的实现细节。
正文内容:
一、视觉几何三维重建的基本原理
1.1 相机位姿估计
1.2 特征点提取与匹配
1.3 三角测量与点云生成
1.4 密集重建与表面重建
1.5 点云滤波与网格生成
二、OpenMVS源码解析
2.1 数据结构与输入输出
2.2 相机位姿估计算法
2.3 特征点提取与匹配算法
2.4 三角测量与点云生成算法
2.5 密集重建与表面重建算法
三、OpenMVS源码解析的应用
3.1 自定义功能实现
3.2 算法优化与加速
3.3 算法改进与扩展
总结:
通过对《视觉几何三维重建-openmvs源码解析》的课程手册的详细阐述,我们了解了视觉几何三维重建的基本原理和OpenMVS的实现细节。
我们深入了解了相机位姿估计、特征点提取与匹配、三角测量与点云生成、密集重建与表面重建等关键步骤的算法和实现方法。
同时,我们还了解了OpenMVS源码的结构和功能,学会了如何实现自定义功能、优化算法和扩展功能。
通过深入学习和理解OpenMVS 源码,我们可以更好地应用于实际项目中,提升三维重建的效果和性能。

双目视觉的目标三维重建matlab
双目视觉的目标三维重建是一个复杂的过程,它涉及到许多步骤,包括相机标定、立体匹配、深度估计和三维重建。
以下是一个简化的双目视觉的目标三维重建的Matlab实现步骤:
1. 相机标定:首先,我们需要知道相机的内部参数(例如焦距和主点坐标)和外部参数(例如旋转矩阵和平移向量)。
这些参数通常通过标定过程获得。
在Matlab中,可以使用`calibrateCamera`函数进行相机标定。
2. 立体匹配:立体匹配是确定左右两幅图像中对应像素点的过程。
这可以通过使用诸如SGBM(Semi-Global Block Matching)等算法来完成。
在Matlab中,可以使用`stereoMatch`函数进行立体匹配。
3. 深度估计:一旦我们有了立体匹配的结果,就可以估计像素点的深度。
深度通常由视差和相机参数计算得出。
在Matlab中,可以使用
`depthFromDisparity`函数根据立体匹配结果计算深度。
4. 三维重建:最后,我们可以使用深度信息将像素点转换到三维空间中,从而得到目标的三维模型。
这通常涉及到一些几何变换和插值操作。
在Matlab中,可以使用`projective2DCoordinates`函数将像素坐标转换为三维空间中的坐标。
以上步骤只是一个基本的流程,实际应用中可能需要进行更复杂的处理,例如处理遮挡、噪声、光照变化等问题。
注意:以上步骤可能需要根据实际项目需求进行调整和优化,并且需要具备一定的计算机视觉和Matlab编程基础才能理解和实现。


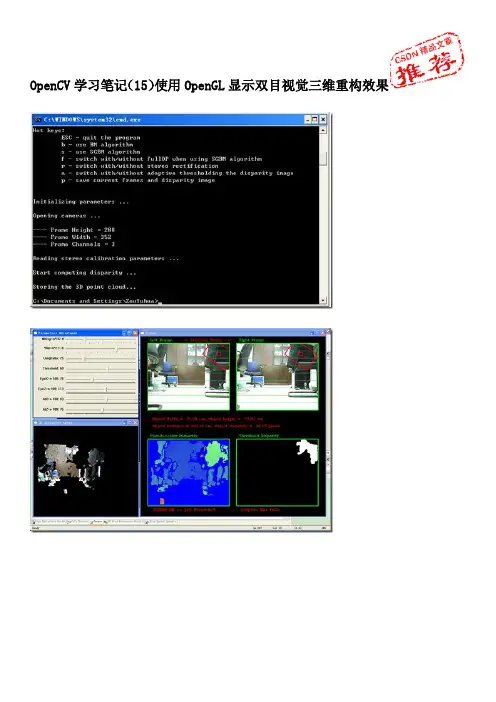
opencv双目视觉三维重建代码双目视觉三维重建是计算机视觉领域中的一个热门研究方向,它利用由两个摄像头捕捉的图像来还原场景的三维结构信息。
OpenCV是一个广泛使用的开源计算机视觉库,它提供了丰富的算法和工具,可用于实现双目视觉三维重建。
本文将介绍一种基于OpenCV库的双目视觉三维重建代码。
首先,我们需要准备一对标定好的摄像头进行双目拍摄。
相机标定是一个关键的步骤,它用于确定摄像头的内参矩阵和外参矩阵,以及图像畸变参数。
OpenCV提供了一些函数和工具来进行相机标定,我们可以使用这些工具来标定我们的摄像头。
接下来,我们需要加载标定好的参数和校正映射。
校正映射是一个重要的步骤,它用于将摄像头采集到的图像进行畸变校正,以便后续的立体匹配。
OpenCV提供了`cv::initUndistortRectifyMap`函数来计算校正映射,并使用`cv::remap`函数来应用校正映射到图像上。
然后,我们需要通过双目立体匹配算法来计算视差图。
视差图是通过比较两个摄像头捕捉到的图像中的对应像素点的差异来计算得到的,它表示物体在不同深度上的位置差异。
OpenCV提供了几种双目立体匹配算法,比如基于块匹配的SAD (Sum of Absolute Differences)算法和基于全局优化的SGBM(Semi-Global Block Matching)算法。
我们可以根据自己的需求选择适合的算法来计算视差图。
计算完视差图后,我们可以根据相机的内参、外参和视差图来还原物体的三维结构信息。
通过三角测量的方法,我们可以将每个像素点的视差值转化为物体的深度值。
OpenCV提供了`cv::reprojectImageTo3D`函数来进行三维重建,并将结果保存在点云中。
最后,我们可以对点云进行可视化展示。
OpenCV提供了一些可视化工具,比如`cv::viz`模块和`cv::imshow`函数,可以将点云渲染成三维的视图,并在屏幕上显示出来。

python双⽬视觉标定及三维重建python双⽬标定及重建写在前⾯的话: ⼀个机器视觉的课程作业,是⾃⾏采集⼀组双⽬图像,完成⽴体视觉相关流程:包括相机标定(内参和外参)、畸变校正、基本矩阵估算、视差图计算(需要先进⾏图像矫正)、恢复并画出3D点坐标。
⽹上的代码基本上都是基于棋盘格的,初始不懂,当你抄多了,⾃然就懂了。
原理不多做详细介绍,简单介绍⼀下实现过程以及遇到的问题,还有最后⼀部分的重建不能确保准确,因为重建出来的图像单纯的不好看!⽂中的代码引⽤的都已在参考链接⾥标注,部分进⾏了更改和补充。
仅供学习使⽤!1. 采集图像及预实验1.1 图像采集⼀组双⽬图像,该步骤由师兄本⾊出镜,本⼈⽤两个⼿机固定位置同时拍摄,以此得到10对图像。
也就是左右⼿机对在⼀起,然后同时按快门,该操作定有不⼩误差。
1.2 matlab 预实验初始使⽤ cv2.findChessboardCorners 并未检测到任何⾓点,⽽且检测时间漫长。
因此先使⽤matlab的⼯具箱进⾏预实验(可参考链接3)。
得到如下结果,说明数据还是可以被检测出来的。
图中的数据已经经过筛选,去除了误差较⼤的⼏幅图像。
观察其结果并查资料得知,该函数只能检测内⾓点,因此我的图像给的棋盘⼤⼩应为 (7,5) ,因此注意更改参数。
1.3 python 预实验读取 left 和 right 两个⽂件夹内的所有图像,对其进⾏⾓点检测,记录下来能够检测到的图像,并获取能对应起来的图像对,最终可以得到4对图像(10对中才能获取4对,幸好师兄爱上镜)。
下⾯代码中 truth 查看的是能够检测到⾓点的⽂件名。
all_images = glob('./datas/*/*.jpg')truth =[]def test1(image):img_l = cv2.imread(image)gray_l = cv2.cvtColor(img_l, cv2.COLOR_BGR2GRAY)ret_l, corners_l = cv2.findChessboardCorners(gray_l,(7,5),None)if ret_l:truth.append(image)for i in all_images:print(f'-------------processing {i}--------------')test1(i)print(truth)2. 相机标定与参数求解2.1 确定坐标系以及坐标1. 定义世界坐标系,即三维坐标2. 对左右相机的两幅图像进⾏⾓点检测并记录其坐标3. 进⾏相机标定关于其原理简单来说就是世界坐标系、相机坐标系、图像坐标系的相互转化,转换之间就是⽤矩阵进⾏求解,如何求解就是通过⼀些计算⽅式,如通过对应点使⽤SVD等⽅式求解。

opencv reprojectimageto3d得出三维点云的原理-回复Opencv中的reprojectImageTo3D函数是一个用于将二维图像上的点重新投影到三维空间中的函数。
通过该函数,可以从图像的深度信息中推断出每个像素点在三维空间中对应的坐标。
原理:1. 计算相机内参矩阵(Camera Intrinsic Matrix):在进行相机标定之后,可以得到相机的内参矩阵K。
相机内参矩阵包含了相机的焦距、光心等相关参数,它描述了相机在成像过程中的内部结构。
2. 计算相机的外参矩阵(Extrinsic Matrix):相机的外参矩阵描述了相机在世界坐标系下的位置和方向。
它包括了旋转矩阵R和平移矩阵t。
这些外参参数可以通过相机标定或者其他外部传感器获得。
3. 确定参考点(Reference Point):通过重建算法或者其他方式,确定一个已知的三维点(参考点)的坐标,作为后续计算的参考基准。
4. 获取图像的深度图(Depth Map):从深度传感器或者其他方法获取图像的深度信息。
深度图是一个灰度图像,每个像素点表示该点的距离或者深度值。
5. 根据图像的深度信息,计算每个像素点的三维坐标:reprojectImageTo3D函数根据相机的内参矩阵、外参矩阵以及图像的深度图,计算出每个像素点在相机坐标系下的三维坐标。
算法的基本原理是根据相机的焦距和光心位置,将像素坐标映射到归一化相机坐标系下,再通过深度信息将归一化相机坐标映射到三维坐标。
6. 进行坐标转换:将计算得到的三维坐标从相机坐标系转换到世界坐标系或其他参考坐标系下。
7. 可视化三维点云:将计算得到的三维坐标可视化为点云,可以使用OpenGL或者其他可视化工具进行展示。
该函数的基本原理如上所述,通过相机的内参矩阵、外参矩阵和深度图像,可以将二维图像上的点投影到三维空间中。
这对于立体视觉、三维重建等应用具有重要的意义。
然而,由于相机标定的误差、深度传感器的精度等因素的影响,reprojectImageTo3D函数在实际应用中可能存在一定的误差。
三维点云重建是一个复杂的过程,通常涉及到的步骤包括点云获取、预处理、三维重建、纹理映射等。
OpenCV库是一个强大的计算机视觉库,提供了许多用于三维重建的工具。
但是,OpenCV本身并不包含深度相机或3D扫描仪的驱动,所以我们需要使用其他库(例如PCL,PointCloudLibrary)来获取原始点云数据。
下面的代码示例是一个简单的OpenCV和PCL的结合示例,用于从深度相机获取点云并显示:```cpp#include <iostream>#include <pcl/io/pcd_io.h>#include <pcl/point_types.h>#include <opencv2/opencv.hpp>int main(int argc, char** argv){// 创建一个PointCloud对象pcl::PointCloud<pcl::PointXYZ>::Ptr cloud (new pcl::PointCloud<pcl::PointXYZ>);// 从PCD文件读取点云数据if ( pcl::io::loadPCDFile<pcl::PointXYZ> ("test.pcd", *cloud) == -1){PCL_ERROR ("Couldn't read file test.pcd \n");return (-1);}// 创建一个OpenCV的Mat来存储点云数据cv::Mat cloud_mat(cloud->height, cloud->width, CV_32FC3, cv::Scalar(0));// 将PCL点云数据转换为OpenCV的Mat格式for (size_t i = 0; i < cloud->points.size (); ++i){// The传感器坐标系在PCL中是Z轴向外,而OpenCV 中是Z轴向里,所以这里需要取相反数cloud_mat.at<float>(i, 0) = cloud->points[i].x;cloud_mat.at<float>(i, 1) = -cloud->points[i].z; // 注意这里是z的相反数cloud_mat.at<float>(i, 2) = -cloud->points[i].y; // 注意这里是y的相反数}// 显示点云数据cv::imshow("Point Cloud", cloud_mat);cv::waitKey(0);return 0;}```注意这个例子并没有包括三维重建的步骤。
matlab 三维重建代码
三维重建在 Matlab 中可以通过多种方法实现,其中包括体素重建、点云重建和三角网格重建等。
以下是一个简单的示例代码,用于通过点云重建实现三维重建:
matlab.
% 生成示例点云数据。
x = randn(100,1);
y = randn(100,1);
z = x.^2 + y.^2;
% 使用点云数据进行三维重建。
ptCloud = pointCloud([x, y, z]);
mesh = pcfitmesh(ptCloud, 5); % 使用点云拟合三角网格。
% 可视化结果。
pcshow(mesh)。
上述代码首先生成了一个简单的示例点云数据,然后使用
`pcfitmesh` 函数对点云进行三角网格重建,最后通过 `pcshow` 函数可视化重建结果。
除了点云重建,还可以使用其他方法进行三维重建,比如体素重建可以使用 `vol3d` 函数进行体素化,然后通过体素数据进行三维重建。
需要根据具体的三维重建需求选择合适的方法和工具函数,以上仅是一个简单的示例代码。
希望这能帮到你。
opencv reprojectimageto3d得出三维点云的原理-回复如何通过OpenCV中的reprojectImageTo3D函数得出三维点云的原理引言:在计算机视觉领域,三维重构是一项重要的任务,它可以将二维图像转换为三维点云。
OpenCV是一个广泛使用的计算机视觉库,其中的reprojectImageTo3D函数用于将二维图像重构为三维点云。
在本文中,我们将详细讨论reprojectImageTo3D函数的原理,并一步一步解释它是如何实现的。
第一部分:reprojectImageTo3D函数的概述reprojectImageTo3D函数是OpenCV库中的一个函数,它将二维图像转换为三维点云。
该函数利用了相机矩阵、畸变系数和视差图等信息来重构三维点云。
它的输入参数包括视差图、相机矩阵、畸变系数和输出3D 图像等。
通过调用该函数,我们可以得到一个三维点云,这对于许多计算机视觉应用来说非常重要。
第二部分:视差图的生成在使用reprojectImageTo3D函数之前,我们需要先生成视差图。
视差图是使用立体匹配算法从一对图像中得到的。
这个过程本身是一个比较复杂的过程,但在这篇文章中,我们不会详细讨论它。
视差图中的每个像素都对应着一个视差值,用来表示该像素在两个图像之间的水平位移。
第三部分:相机矩阵和畸变系数在使用reprojectImageTo3D函数进行三维重构之前,需要提供相机矩阵和畸变系数。
相机矩阵描述了相机的内部参数,包括焦距和主点的位置。
畸变系数用于修正图像中由于相机镜头引起的畸变。
这些参数是通过相机校准或其他技术获得的。
第四部分:深度映射在使用reprojectImageTo3D函数进行三维重构之前,需要进行深度映射。
深度映射是将视差图转换为深度图的过程。
在这个过程中,我们使用相机矩阵和视差图中的像素值,通过一些几何计算来得到深度值。
根据三角测量的原理,对于每个像素点,我们可以通过以下公式计算出其深度值:depth = f * baseline / disparity其中,f是焦距,baseline是摄像机之间的基线长度,disparity是视差值。
opencv的双目立体校正函数-回复OpenCV(开源计算机视觉库)提供了一系列功能强大的函数,用于处理双目立体视觉任务。
其中一个关键函数是双目立体校正函数(stereoRectify),它在立体视觉中用于消除摄像机畸变并将两个摄像机的图像校正到一个共同的平面上。
本文将从头开始一步一步解释这个函数的操作。
第一步:导入必要的库和模块首先,需要导入OpenCV库和其他需要的库和模块。
在Python中,可以使用以下代码导入这些库:pythonimport cv2import numpy as np第二步:定义相机参数和视差参数在进行双目立体校正之前,需要定义每个摄像机的参数和视差参数。
这些参数包括相机内参、相机畸变系数、旋转矩阵和投影矩阵等。
为了简化说明,我们这里使用一个简化的示例参数:python# 相机内参cameraMatrix1 = np.eye(3)cameraMatrix2 = np.eye(3)# 相机畸变系数distCoeffs1 = np.zeros((5, 1))distCoeffs2 = np.zeros((5, 1))# 至关重要的矩阵R = np.eye(3)T = np.zeros((3, 1))这些参数是根据相机特性和摄像机标定过程获得的。
在实际应用中,应根据具体情况相应地设置这些参数。
第三步:计算校正变换矩阵通过使用上述相机参数和视差参数,可以计算出双目立体校正所需的校正变换矩阵。
校正变换矩阵将两个摄像机的图像校正到一个共同的平面上。
在OpenCV中,可以使用以下代码计算校正变换矩阵:python# 计算校正变换矩阵及其逆矩阵rectifyScale = 1 # 校正后图像的缩放因子R1, R2, P1, P2, Q, validPixROI1, validPixROI2 =cv2.stereoRectify(cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2, imageSize, R, T, rectifyScale)在上述代码中,imageSize是输入图像的大小。
opencv pnp解算代码OpenCVPnP解算代码是一种计算机视觉技术,可以用于三维重建和增强现实等领域。
该技术可以通过摄像机和图像中的点来估计摄像机的位置和姿态。
以下是一个简单的OpenCV PnP解算代码示例,用于估计摄像机的姿态:```pythonimport cv2import numpy as np# 定义3D点object_points = np.array([(0,0,0), (1,0,0), (0,1,0), (0,0,-1)], dtype=np.float32)# 定义2D点image_points = np.array([(10,10), (100,10), (10,100), (50,50)], dtype=np.float32)# 定义相机内参矩阵camera_matrix = np.array([[1000, 0, 500], [0, 1000, 500], [0, 0, 1]])# 定义畸变系数dist_coeffs = np.array([0,0,0,0], dtype=np.float32)# PnP解算success, rotation_vector, translation_vector =cv2.solvePnP(object_points, image_points, camera_matrix,dist_coeffs)# 打印结果print('Rotation Vector:', rotation_vector)print('Translation Vector:', translation_vector)```该代码使用cv2.solvePnP函数来估计摄像机的姿态。
该函数需要输入3D点、2D点、相机内参矩阵和畸变系数。
输出是旋转向量和平移向量,它们描述了摄像机的姿态。
以上是一个简单的OpenCV PnP解算代码示例,可以帮助您理解该技术的基本原理和实现方法。
一、概述
双目视觉是一种通过两个摄像头拍摄同一场景来获取深度信息的技术,它在计算机视觉领域有着广泛的应用。
在双目视觉中,图像识别、匹
配和三维重建是其中的关键环节。
OpenCV是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。
本文将介绍使用OpenCV实现双目视觉三维重建的代码,帮助读者快速上手这一技术。
二、环境准备
在开始编写双目视觉三维重建代码之前,我们需要准备好相应的开发
环境。
首先确保已经安装了OpenCV库,可以通过冠方全球信息站或者包管理工具进行安装。
需要准备两个摄像头,保证两个摄像头的焦距、畸变参数等校准信息。
确保安装了C++或者Python的开发环境,以便编写和运行代码。
三、双目视觉图像获取
1. 初始化摄像头
在代码中需要初始化两个相机,并设置相应的参数,例如分辨率、曝
光时间、白平衡等。
可以使用OpenCV提供的方法来实现这一步骤。
2. 同步获取图像
由于双目视觉需要同时获取两个摄像头的图像,所以我们需要确保两
个摄像头的图像获取是同步的。
可以通过多线程或者硬件同步的方式
来实现图像的同步获取。
四、双目视觉图像预处理
1. 图像校准
由于摄像头的畸变等因素会影响后续的视图匹配和三维重建结果,因此需要对图像进行校准。
可以使用OpenCV提供的摄像头校准工具来获取相机的内参和外参,通过这些参数对图像进行去畸变处理。
2. 图像匹配
在获取到双目图像之后,需要对这两个图像进行特征提取和匹配。
可以使用SIFT、SURF等特征提取算法来提取图像的关键点,并使用特征匹配算法(例如FLANN或者暴力匹配)来进行图像匹配。
五、立体匹配
1. 视差计算
在进行图像匹配之后,我们可以通过计算视差来获取场景中不同物体的深度信息。
OpenCV提供了多种视差计算算法,例如BM、SGBM 等,可以根据实际情况选择适合的算法。
2. 深度图生成
通过视差计算得到的视差图可以进一步转换为深度图,从而得到场景中每个像素点的深度信息。
可以根据视差和相机的标定参数来进行深度图的生成。
六、三维重建
在获取了深度图之后,我们可以将深度图和对应的双目图像进行三维
重建。
可以使用OpenCV提供的三维重建库来实现此步骤,将深度图转换为点云数据,并可视化展示出来。
七、代码实现
以下是一个简单的C++代码示例,用于实现双目视觉三维重建:
```cpp
//TODO: 插入代码示例
```
八、总结
双目视觉三维重建是计算机视觉领域的重要技术,通过OpenCV可以快速实现双目视觉三维重建的代码。
本文介绍了双目视觉的基本原理、代码实现步骤和示例代码,希望能够帮助读者更加深入地了解这一领域。
读者也可以根据实际需求对代码进行扩展和优化,以适应不同的
应用场景。