标准差公式
- 格式:doc
- 大小:80.00 KB
- 文档页数:5

标准差(Standard Deviation ) ,也称均方差(mean square error ),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S (σ)表示。
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
标准差也被称为标准偏差,或者实验标准差,公式如下两式:()1n x x S n 1i 2i --=∑= 或 1n n x x S 2n 1i i n 1i 2i -⎪⎭⎫ ⎝⎛-=∑∑==即: ()1n x x 1n n x x S n 1i 2i 2n 1i i n 1i 2i --=-⎪⎭⎫ ⎝⎛-=∑∑∑===如是总体,标准差公式根号内除以n 如是样本,标准差公式根号内除以(n-1)因为我们大量接触的是样本,所以普遍使用根号内除以(n-1)公式意义所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一),再把所得值开根号,所得之数就是这组数据的标准差。
标准差越高,表示实验数据越离散,也就是说越不精确;反之,标准差越低,代表实验的数据越精确简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。

标准差Standard Deviation ,也称均方差mean square error,是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S σ表示;标准差是方差的算术平方根;标准差能反映一个数据集的离散程度;平均数相同的,标准差未必相同;标准差也被称为标准偏差,或者实验标准差,公式如下两式: ()1n x x S n 1i 2i --=∑= 或 1n n x x S 2n 1i i n 1i 2i -⎪⎭⎫ ⎝⎛-=∑∑==即: 如是总体,标准差公式根号内除以n如是样本,标准差公式根号内除以n-1因为我们大量接触的是样本,所以普遍使用根号内除以n-1公式意义所有数减去其平均值的平方和,所得结果除以该组数之个数或个数减一,再把所得值开根号,所得之数就是这组数据的标准差;标准差越高,表示实验数据越离散,也就是说越不精确;反之,标准差越低,代表实验的数据越精确简单来说,标准差是一组数据平均值分散程度的一种度量;一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值;例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二个集合具有较小的标准差;标准差可以当作不确定性的一种测量;例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度;当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远同时与标准差数值做比较,则认为测量值与预测值互相矛盾;这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确;标准差应用于投资上,可作为量度回报稳定性的指标;标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高;相反,标准差数值越细,代表回报较为稳定,风险亦较小;例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67;这两组的平均数都是70,但A组的标准差为17.07分,B组的标准差为2.37分此数据时在R统计软件中运行获得,说明A组学生之间的差距要比B组学生之间的差距大得多;求证下列公式:由题意可知,求证下列式子即可:假设x i=错误!+a i,既有x i-错误!=a i,即求证下列式子即可:因为:所以:所以:所以:()()∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑================-++=-++=⎪⎭⎫⎝⎛+-++=⎪⎭⎫⎝⎛+-++=⎪⎭⎫⎝⎛+-+=⎪⎭⎫⎝⎛-n1i22n1i222n1i2n1ii22n1i2in1iin1i2n1i2n1in1ii2ii2n1i2n1iin1i2i2n1iin 1 i2iiiiax nax nx nn1aax2x nxn1aa x2xaxn1aa x2xnaxaxnxx)()()()()(设X是一个随机变量,若E{X-EX^2}存在,则称E{X-EX^2}为X的方差,记为DX或DX; 即DX=E{X-EX^2}称为方差,而σX=DX^0.5与X有相同的量纲称为标准差或均方差;即用来衡量一组数据的离散程度的统计量;方差刻画了随机变量的取值对于其数学期望的离散程度; 若X的取值比较集中,则方差DX较小;若X的取值比较分散,则方差DX较大; 因此,DX是刻画X取值分散程度的一个量,它是衡量X取值分散程度的一个尺度;方差的计算由定义知,方差是随机变量 X 的函数gX=X-EX^2 的数学期望;即:由方差的定义可以得到以下常用计算公式:DX=EX^2-EX^2证明:DX=EX-EX^2 =E{X^2-2XEX+EX^2} =EX^2-2EX^2+EX^2 =EX^2-EX^2 方差其实就是标准差的平方;方差的几个重要性质1设c是常数,则Dc=0; 2设X是随机变量,c是常数,则有DcX=c^2DX; 3设 X 与 Y 是两个随机变量,则DX+Y= DX+DY+2E{X-EXY-EY} 特别的,当X,Y是两个相互独立的随机变量,上式中右边第三项为0常见协方差, 则DX+Y=DX+DY;此性质可以推广到有限多个相互独立的随机变量之和的情况. 4DX=0的充分必要条件是X以概率为1取常数值c,即P{X=c}=1,其中EX=c;常见随机变量的期望和方差设随机变量X; X服从0—1分布,则EX=p DX=p1-p X服从泊松分布,即X~ πλ,则EX= λ,DX= λ X服从均匀分布,即X~Ua,b,则EX=a+b/2, DX=b-a^2/12 X服从指数分布,即X~eλ, EX= λ^-1,DX= λ^-2 X服从二项分布,即X~Bn,p,则Ex=np, DX=np1-p X 服从正态分布,即X~Nμ,σ^2, 则Ex=μ, DX=σ^2 X 服从标准正态分布,即X~N0,1, 则Ex=0, DX=1。
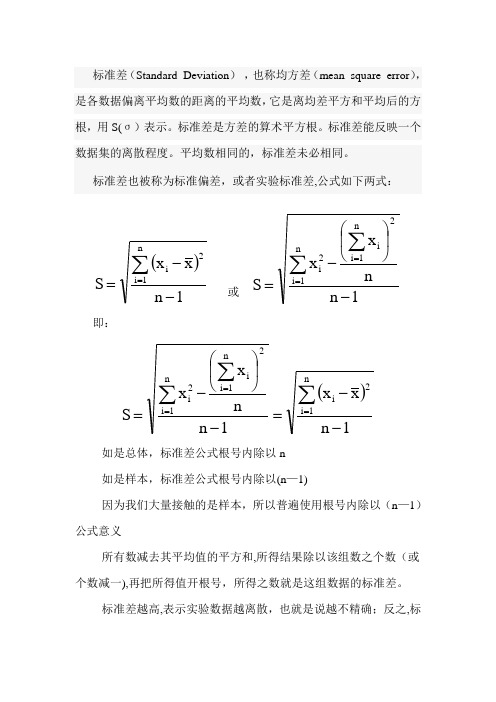
标准差(Standard Deviation ) ,也称均方差(mean square error ),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S(σ)表示。
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
标准差也被称为标准偏差,或者实验标准差,公式如下两式:()1n x xS n1i 2i--=∑= 或1n n x x S 2n1i i n1i 2i-⎪⎭⎫⎝⎛-=∑∑==即:()1n x x1n n x x S n1i 2i2n1i i n1i 2i--=-⎪⎭⎫ ⎝⎛-=∑∑∑===如是总体,标准差公式根号内除以n如是样本,标准差公式根号内除以(n —1)因为我们大量接触的是样本,所以普遍使用根号内除以(n —1) 公式意义所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一),再把所得值开根号,所得之数就是这组数据的标准差。
标准差越高,表示实验数据越离散,也就是说越不精确;反之,标准差越低,代表实验的数据越精确简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合{0,5,9,14} 和{5,6, 8,9} 其平均值都是7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量.例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。

标准差的计算公式引言在统计学中,标准差是一种常用的测量数据分散程度的指标。
它用于衡量一组数据的离散程度,即数据点在平均值附近的分布情况。
标准差计算公式是标准差的基础,它描述了如何计算标准差的数学公式。
本文将介绍标准差的计算公式及其应用。
标准差的定义标准差是方差的平方根,方差是一组数据与其平均值的差值平方的平均值。
标准差是对方差的一种衡量,它与平均数之间的差异较大时,标准差较大;差异较小时,标准差较小。
标准差的计算公式如下所示:标准差 = 平方根(∑(xi - x̄)^2 / n)其中,xi 是每个数据点,x̄是所有数据点的平均值,∑ 代表求和,n 是数据点的数量。
标准差计算公式的步骤计算标准差的步骤如下:1.计算每个数据点与平均值之差的平方:(xi - x̄)^22.将这些平方差值相加:∑(xi - x̄)^23.将这个总和除以数据点的数量:∑(xi - x̄)^2 / n4.取这个结果的平方根,即可得到标准差:标准差 = 平方根(∑(xi - x̄)^2/ n)例子为了更好地理解标准差的计算过程,下面举一个简单的例子。
假设我们有一组数据:[3, 6, 9, 12, 15],我们需要计算这组数据的标准差。
首先,计算平均值:平均值x̄ = (3 + 6 + 9 + 12 + 15) / 5 = 9然后,计算每个数据点与平均值之差的平方:(3 - 9)^2 = 36(6 - 9)^2 = 9(9 - 9)^2 = 0(12 - 9)^2 = 9(15 - 9)^2 = 36接着,将这些平方差值相加:∑(xi - x̄)^2 = 36 + 9 + 0 + 9 + 36 = 90将这个总和除以数据点的数量:∑(xi - x̄)^2 / n = 90 / 5 = 18最后,取这个结果的平方根,即可得到标准差:标准差 = 平方根(18) ≈ 4.2426因此,这组数据的标准差约为4.2426。
标准差的应用标准差在实际应用中有着广泛的应用,它可以帮助我们理解数据的离散程度。

标准差(Standard Deviation ) ,也称均方差(mean square e rror ),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S (σ)表示。
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
标准差也被称为标准偏差,或者实验标准差,公式如下两式:()1n x x S n 1i 2i --=∑= 或 1n n x x S 2n 1i i n 1i 2i -⎪⎭⎫ ⎝⎛-=∑∑==即: ()1n x x 1n n x x S n 1i 2i 2n 1i i n 1i 2i --=-⎪⎭⎫ ⎝⎛-=∑∑∑===如是总体,标准差公式根号内除以n 如是样本,标准差公式根号内除以(n-1)因为我们大量接触的是样本,所以普遍使用根号内除以(n-1) 公式意义所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一),再把所得值开根号,所得之数就是这组数据的标准差。
标准差越高,表示实验数据越离散,也就是说越不精确;反之,标准差越低,代表实验的数据越精确简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。

统计中的标准差公式
标准差是用以度量离散程度的一种统计量。
它在科学、经济学和计量经济学中
被广泛使用,有助于确定一组数据整体离散程度或尺度的大小。
它同样也是用以分析任意样本的一般程度,与数据的平均值、分位数有着密切的关系。
标准差的计算公式为:σ =√(1/N * Σ(Xi - μ)2),其中,N表示样本数,
Xi表示相应样本取值,μ表示所求样本均值。
Σ代表对所有样本取值后的结果求和,√代表开方。
由此可见,标准差的计算结果决定于被考察的样本的数量和每个样本数据相对
于平均数的偏移量。
当样本取值分布极度不均衡时,离散程度也就会出现较大偏差,从而使得标准差变得非常大;而如果样本取值分布比较均匀,那么标准差就会变小。
标准差是离散程度的一种有效衡量指标,它是基于每一个样本取值与样本均值
的偏移量来计算的,其中非常着重于变异程度的描述,使得标准差成为统计学上最重要的参数之一。
它不仅对分析每一个样本的实际分布状态有重要问疚,更是选择最合适的数据拟合模型的普遍依据。
标准差的计算公式实例标准差公式是一种数学公式。
标准差也被称为标准偏差,或者实验标准差,公式如下所示:标准差=方差的算术平方根=s=sqrt(((x1-x)^2 +(x2-x)^2 +......(xn-x)^2)/n)。
单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。
一个较大的标准差,代表大部分的数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合{0, 5, 9, 14} 和{5, 6, 8, 9} 其平均值都是7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
相反,标准差数值越小,代表回报较为稳定,风险亦较小。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。
这两组的平均数都是70,但A组的标准差为17.078分,B组的标准差为2.160分(此数据时在R统计软件中运行获得,使用的是样本标准差),说明A组学生之间的差距要比B组学生之间的差距大得多。
如是总体,标准差公式根号内除以n如是样本,标准差公式根号内除以(n-1)。
因为我们大量接触的是样本,所以普遍使用根号内除以(n-1)。
公式意义所有数减去平均值,它的平方和除以数的个数(或个数减一),再把所得值开根号,就是1/2次方,得到的数就是这组数的标准差。
标准差公式是什么标准差是统计学中常用的一种测量数据离散程度的方法,它可以帮助我们了解数据集中的数据点与平均值的偏离程度。
标准差的计算方法相对复杂,但是掌握了标准差的计算方法,我们就能更好地理解数据的分布规律,从而更准确地分析和解释数据。
标准差的计算公式如下:标准差= sqrt(Σ(xi μ)² / N)。
其中,Σ代表求和,xi代表每个数据点,μ代表数据的平均值,N代表数据点的个数。
这个公式看起来可能有些抽象,下面我们通过一个具体的例子来说明标准差的计算过程。
假设我们有一个数据集,3, 5, 7, 9, 11。
首先,我们需要计算这组数据的平均值。
平均值的计算方法是将所有数据点相加,然后除以数据点的个数。
在这个例子中,数据的平均值为(3+5+7+9+11)/5 = 7。
接下来,我们需要计算每个数据点与平均值的偏离程度。
偏离程度的计算方法是将每个数据点与平均值的差值求平方。
然后,将所有偏离程度的平方相加。
在这个例子中,偏离程度的平方之和为(3-7)² + (5-7)² + (7-7)² + (9-7)² + (11-7)² = 20。
最后,我们需要将偏离程度的平方之和除以数据点的个数,然后取平方根即可得到标准差。
在这个例子中,标准差的计算过程为sqrt(20/5) = sqrt(4) = 2。
因此,这组数据的标准差为2。
这意味着这组数据的每个数据点与平均值的偏离程度约为2。
标准差越大,数据的离散程度就越大;标准差越小,数据的离散程度就越小。
除了上述的样本标准差计算方法,还有总体标准差的计算方法。
总体标准差与样本标准差的区别在于,总体标准差的分母是总体数据点的个数,而样本标准差的分母是总体数据点的个数减1。
总体标准差的计算公式为:总体标准差= sqrt(Σ(xi μ)² / N)。
其中,Σ代表求和,xi代表每个数据点,μ代表数据的平均值,N代表总体数据点的个数。
标准差(Standard Deviation ) ,也称均方差(mean square error ),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S (σ)表示。
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
标准差也被称为标准偏差,或者实验标准差,公式如下两式:()1n x x S n 1i 2i --=∑= 或 1n n x x S 2n 1i i n 1i 2i -⎪⎭⎫ ⎝⎛-=∑∑==即: 如是总体,标准差公式根号内除以n如是样本,标准差公式根号内除以(n-1)因为我们大量接触的是样本,所以普遍使用根号内除以(n-1)公式意义所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一),再把所得值开根号,所得之数就是这组数据的标准差。
标准差越高,表示实验数据越离散,也就是说越不精确;反之,标准差越低,代表实验的数据越精确简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
相反,标准差数值越细,代表回报较为稳定,风险亦较小。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。
标准差(Standard Deviation ) ,也称均方差(mean square e rror ),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S (σ)表示。
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
标准差也被称为标准偏差,或者实验标准差,公式如下两式:()1n x x S n 1i 2i --=∑= 或 1n n x x S 2n 1i i n 1i 2i -⎪⎭⎫ ⎝⎛-=∑∑==即: ()1n x x 1n n x x S n 1i 2i 2n 1i i n 1i 2i --=-⎪⎭⎫ ⎝⎛-=∑∑∑===如是总体,标准差公式根号内除以n 如是样本,标准差公式根号内除以(n-1)因为我们大量接触的是样本,所以普遍使用根号内除以(n-1) 公式意义所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一),再把所得值开根号,所得之数就是这组数据的标准差。
标准差越高,表示实验数据越离散,也就是说越不精确;反之,标准差越低,代表实验的数据越精确简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
标准差(Standard Deviation ) ,也称均方差(mean square e rror ),是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用S (σ)表示。
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
标准差也被称为标准偏差,或者实验标准差,公式如下两式:
()1n x x S n 1i 2i --=
∑= 或 1n n x x S 2n 1i i n 1i 2i -⎪⎭⎫ ⎝⎛-=∑∑==
即: ()1n x x 1
n n x x S n 1i 2i 2n 1i i n 1i 2i --=-⎪⎭⎫ ⎝⎛-=∑∑∑===
如是总体,标准差公式根号内除以n 如是样本,标准差公式根号内除以(n-1)
因为我们大量接触的是样本,所以普遍使用根号内除以(n-1) 公式意义
所有数减去其平均值的平方和,所得结果除以该组数之个数(或个数减一),再把所得值开根号,所得之数就是这组数据的标准差。
标准差越高,表示实验数据越离散,也就是说越不精确;反之,标
准差越低,代表实验的数据越精确
简单来说,标准差是一组数据平均值分散程度的一种度量。
一个较大的标准差,代表大部分数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
例如,两组数的集合 {0, 5, 9, 14} 和 {5, 6, 8, 9} 其平均值都是 7 ,但第二个集合具有较小的标准差。
标准差可以当作不确定性的一种测量。
例如在物理科学中,做重复性测量时,测量数值集合的标准差代表这些测量的精确度。
当要决定测量值是否符合预测值,测量值的标准差占有决定性重要角色:如果测量平均值与预测值相差太远(同时与标准差数值做比较),则认为测量值与预测值互相矛盾。
这很容易理解,因为如果测量值都落在一定数值范围之外,可以合理推论预测值是否正确。
标准差应用于投资上,可作为量度回报稳定性的指标。
标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。
相反,标准差数值越细,代表回报较为稳定,风险亦较小。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B组的分数为73、72、71、69、68、67。
这两组的平均数都是70,但A组的标准差为17.07分,B组的标准差为2.37分(此数据时在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。
求证下列公式: ()1n x x 1n n x x n 1i 2i 2n 1i i n 1
i 2i --=-⎪⎭⎫ ⎝⎛-∑∑∑===
由题意可知,求证下列式子即可:
()∑∑∑===-=⎪⎭⎫ ⎝⎛-n 1
i 2i 2
n 1i i n 1i 2i x x n x x 假设x i =x _+a i ,既有x i -x _=a i ,
即求证下列式子即可: ()∑∑===-n 1i 2n 1i 2i i a x x
因为:
n
x ......x x x n x x n 321n 1i i ++++==∑= 所以: 0x n a ......a a a (x n )
a x (......)a x ()a x ()a x (x ......x x x x n n 321n 321n
321+=+++++=++++++++=++++=)
所以:
∑=
=
+
+
+
+
=
n
1 i
n
3
2
1
i
a
......
a
a
a
a
所以:
()
()
∑∑
∑
∑
∑
∑
∑
∑∑∑
∑
∑
∑
∑
∑
=
=
=
=
=
=
=
===
=
=
=
=
=
=
-
+
+
=
-
+
+
=
⎪
⎭
⎫
⎝
⎛
+
-
+
+
=
⎪
⎭
⎫
⎝
⎛
+
-
+
+
=
⎪
⎭
⎫
⎝
⎛
+
-
+
=
⎪
⎭
⎫
⎝
⎛
-
n
1
i
2
2
n
1
i
2
2
2
n
1
i
2
n
1
i
i
2
2
n
1
i
2
i
n
1
i
i
n
1
i
2
n
1
i
2
n
1
i
n
1
i
i
2
i
i
2
n
1
i
2
n
1
i
i
n
1
i
2
i
2
n
1
i
i
n 1 i
2
i
i
i
i
a
x n
a
x n
x n
n
1
a
a
x2
x n
x
n
1
a
a x2
x
a
x
n
1
a
a x2
x
n
a
x
a
x
n
x
x
)
(
)
(
)
(
)
(
)
(
设X是一个随机变量,若E{[X-E(X)]^2}存在,则称E{[X-E(X)]^2}为X的方差,记为D(X)或DX。
即D(X)=E{[X-E(X)]^2}称为方差,而σ(X)=D(X)^0.5(与X有相同的量纲)称为标准差(或均方差)。
即用来衡量一组数据的离散程度的统计量。
方差刻画了随机变量的取值对于其数学期望的离散程度。
若X的取值比较集中,则方差D(X)较小;若X的取值比较分散,则方差D(X)较大。
因此,D(X)是刻画X取值分散程度的一个量,它是衡量X取值分散程度的一个尺度。
方差的计算
由定义知,方差是随机变量 X 的函数g(X)=[X-E(X)]^2 的数学期望。
即:
由方差的定义可以得到以下常用计算公式:D(X)=E(X^2)-[E(X)]^2证明:D(X)=E[X-E(X)]^2 =E{X^2-2XE(X)+[E(X)]^2} =E(X^2)-2[E(X)]^2+[E(X)]^2 =E(X^2)-[E(X)]^2 方差其实就是标准差的平方。
方差的几个重要性质
(1)设c是常数,则D(c)=0。
(2)设X是随机变量,c是常数,则有D(cX)=(c^2)D(X)。
(3)设 X 与 Y 是两个随机变量,则D(X+Y)= D(X)+D(Y)+2E{[X-E(X)][Y-E(Y)]} 特别的,当X,Y是两个相互独立的随机变量,上式中右边第三项为0(常见协方差),则D(X+Y)=D(X)+D(Y)。
此性质可以推广到有限多个相互独立的随机变量之和的情况. (4)D(X)=0的充分必要条件是X以概率为1取常数值c,即P{X=c}=1,其中E(X)=c。
常见随机变量的期望和方差
设随机变量X。
X服从(0—1)分布,则E(X)=p D(X)=p(1-p) X服从泊松分布,即X~ π(λ),则 E(X)= λ,D(X)= λX服从均匀分布,即X~U(a,b),则E(X)=(a+b)/2, D(X)=(b-a)^2/12 X服从指数分布,即X~e(λ), E(X)= λ^(-1),D(X)= λ^(-2) X 服从二项分布,即X~B(n,p),则E(x)=np, D(X)=np(1-p) X 服从正态分布,即
X~N(μ,σ^2), 则E(x)=μ, D(X)=σ^2 X 服从标准正态分布,即X~N(0,1), 则E(x)=0, D(X)=1。