第三章-语音信号的特征分析讲解讲解学习
- 格式:ppt
- 大小:3.93 MB
- 文档页数:17


语音信号的特征提取与分类研究语音信号是一种常见的信号,它传递了人类的语言信息,是人类进行交流的重要媒介之一。
但是,要对语音信号进行处理以便于机器学习或实现其他应用,需要提取出语音信号中的特征,并对其进行分类。
本文将重点探讨语音信号的特征提取与分类研究。
一、语音信号的特征提取语音信号是一种时域信号,包含了大量的声音信息。
在对语音信号进行处理前,需要将其转化为数字信号,并从中提取出有用的特征。
下面介绍几种经典的语音信号特征提取方法。
1. 短时能量和短时平均幅值短时能量和短时平均幅值是语音信号最基本的特征之一。
它们可以反映语音信号的音量大小和能量密度分布。
具体方法是将语音信号分成若干小段,在每一小段内求出能量和幅值的平均值。
这种方法简单易行,但是对于含有大量噪声的语音信号效果不佳。
2. 过零率语音信号中能量与过零率相关联,因此,过零率可以反映信号中的频率成分。
过零率表示的是语音信号穿过0的次数。
在计算过零率时,需要将语音信号分成若干小段,计算每一小段内0的穿过次数,并求出平均值。
过零率在识别某些语音词汇时具有一定的作用。
3. 短时倒谱系数短时倒谱系数是一种基于滤波器的语音信号特征提取方法。
它的原理是将语音信号输入到一个数字滤波器中,输出的结果就是短时倒谱系数。
这种方法比较复杂,需要涉及数字滤波器的设计和使用,但是效果很好。
4. 线性预测系数线性预测系数是一种基于自回归模型的语音信号特征提取方法。
它的原理是将语音信号视为一个自回归信号,通过线性预测模型估计自回归系数。
这种方法需要对语音信号进行复杂的数学运算,但是可以提取出语音信号的主要频率成分。
二、语音信号的分类研究经过特征提取后,语音信号就可以被机器进行分类了。
分类的目的是通过对语音信号的特征进行分析,将语音信号划分到不同的类别中,以便于机器进行语音识别或其他应用。
1. 基于深度学习的语音信号分类深度学习是近年来非常流行的一种机器学习方法,其在语音识别领域中也取得了一定的成果。

语音信号的识别与分析技术语音信号是我们日常交流中最为普遍和基础的通信手段,随着科技的不断发展,越来越多的人工智能设备和人机交互系统也采用语音作为信息输入和输出的方式,语音信号的识别与分析技术也越来越成为了一个重要的研究领域。
语音信号的识别可以分为语音识别和说话人识别两种。
语音识别是指将说话人说的语音信号转化为文本或命令等符号组合的技术,它是现代人机交互和自然语言处理的基础;而说话人识别是指通过对语音信号中的说话人身份进行识别,从而实现区分不同说话人的功能。
语音信号的分析则是指对说话人语音信号的声学和语言特征进行分析,以提取有效信息的技术。
从声学角度来说,语音信号的分析可以分别在时域和频域上进行。
在时域上,可以利用数字信号处理技术对语音信号进行连续采样,并对其物理特性(如频率、振幅、波形等)进行分析;在频域上,可以将语音信号转化为频域信号,并利用现代声学理论对其进行分析。
在语言学角度来说,语音信号分析的主要任务是对语音信号中的语言信息进行抽取和处理。
语音信号中的语言信息包括音位、音节、单词和语调等。
而对于这些语言信息的抽取和处理,则需要运用到语言学理论、音韵学和自然语言处理等相关技术。
除了语音识别和说话人识别以外,语音信号的识别和分析技术还能够应用于很多其他领域。
例如,通过语音识别技术的应用,可以实现智能家居、手写识别、虚拟助手等人工智能设备的语音交互功能;通过说话人识别技术的应用,可以实现声纹识别、安全认证等方面的应用;而通过语音分析技术的应用,则可以实现情感分析、语音合成等应用。
尽管语音信号的识别和分析技术在很多领域得到了广泛的应用,但是在实际应用中仍然存在一些困难和挑战。
例如,现有的语音识别技术在语音噪声和口音干扰比较大的情况下准确率较低,而现有的说话人识别技术在多说话人同时发言的情况下也容易出现识别困难;而对于语音信号的分析,则由于人类语言的复杂性和多样性,其分析也面临着很大的挑战。
总体来说,语音信号的识别与分析技术已经逐渐成为了计算机科学和人工智能领域中的研究重点之一,随着机器学习和深度学习等技术的不断进步和应用,我们期待这一领域在未来的进一步发展。







第2篇语音信号分析第3章时域分析3.1 概述语音信号处理包括语音通信、语音合成、语音识别、说话人识别和语音增强等方面,但其前提和基础是对语音信号的分析。
只有将语音信号分析成表示其本质特性的参数,才有可能利用这些参数进行高效的语音通信,才能建立用于语音合成的语音库,也才可能建立用于识别的模板或知识库。
而且,语音合成的音质好坏、语音识别率的高低,都取决于对语音信号分析的准确性和精度。
语音信号是非平稳、时变、离散性大、信息量大的复杂信号,处理难度很大。
语音信号携带着各种信息。
在不同应用场合下,人们感兴趣的信息是不同的。
那些与应用目的的不相干或影响不大的信息,应当去掉;而需要的信息不仅应当提取出来,有时还需要加强。
这涉及到语音信号中各种信息如何表示的问题。
语音信息表示方法的选择原则是使之最方便和最有效。
语音信号可以用语音的抽样波形来描述,也可以用一些语音信号的特征来描述。
提取少量的参数有效地描述语音信号,即语音信号的参数表示,是语音处理领域共用性的关键技术之一。
根据所分析的参数不同,语音信号分析可分为时域、频域、倒谱域等方法。
时域分析具有简单、运算量小、物理意义明确等优点;但更为有效的分析多是围绕频域进行的,因为语音中最重要的感知特性反映在其功率谱中,而相位变化只起着很小的作用。
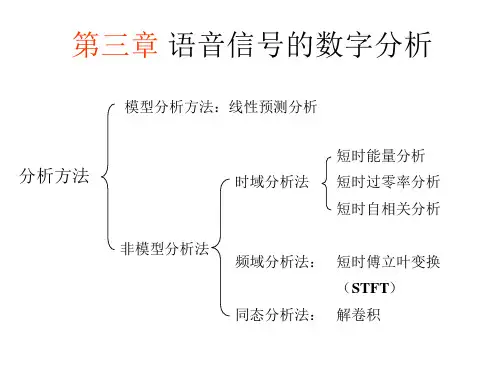
另一方面,按照语音学观点,可将语音的特征表示和提取方法分为模型分析法和非模型分析法两种。
其中模型分析法是指依据语音产生的数学模型,来分析和提取表征这些模型的特征参数;共振峰模型分析及声管模型(即线性预测模型)分析即属于这种分析方法。
而不进行模型化分析的其他方法都属于非模型分析法,包括上面提到的时域分析法、频域分析法及同态分析法等。
基于语音产生模型的多种参数表示法已在语音识别、合成、编码和说话人识别研究的大量实践中证明是十分有效的。
贯穿于语音分析全过程的是“短时分析技术”。
语音信号特性是随时间而变化的,是一个非平稳的随机过程。
但是,从另一方面看,虽然语音信号具有时变特性,但在一个短时间范围内其特性基本保持不变。