《编译原理》第3章 词法分析与有穷自动机
- 格式:ppt
- 大小:2.23 MB
- 文档页数:120



第三章词法分析本章要点1.词法分析器设计,2.正规表达式与有限自动机,3.词法分析器自动生成。
本章目标:1.理解对词法分析器的任务,掌握词法分析器的设计;2.掌握正规表达式与有限自动机;3.掌握词法分析器的自动产生。
本章重点:1.词法分析器的作用和接口,用高级语言编写词法分析器等内容,它们与词法分析器的实现有关。
应重点掌握词法分析器的任务与设计,状态转换图等内容。
2.掌握下面涉及的一些概念,它们之间转换的技巧、方法或算法。
(1)非形式描述的语言↔正规式(2)正规式→ NFA(非确定的有限自动机)(3)NFA→ DFA(确定的有限自动机)(4)DFA→最简DFA本章难点(1)非形式描述的语言↔正规式(2)正规式→ NFA(非确定的有限自动机)(3)NFA→ DFA(确定的有限自动机)(4)DFA→最简DFA作业题一、单项选择题(按照组卷方案,至少15道)1. 程序语言下面的单词符号中,一般不需要超前搜索a. 关键字b. 标识符c. 常数d. 算符和界符2. 在状态转换图的实现中,一般对应一个循环语句a. 不含回路的分叉结点b. 含回路的状态结点c. 终态结点d. 都不是3. 用了表示字母,d表示数字, ={l,d},则定义标识符的正则表达式可以是:。
(a)ld*(b)ll*(c)l(l | d)*(d)ll* | d*4. 正规表达式(ε|a|b)2表示的集合是(a){ε,ab,ba,aa,bb} (b){ab,ba,aa,bb}(c){a,b,ab,aa,ba,bb} (d){ε,a,b,aa,bb,ab,ba}5. 有限状态自动机可用五元组(V T,Q,δ,q0,Q f)来描述,设有一有限状态自动机M的定义如下:V T={0,1},Q={q0,q1,q2},Q f={q2},δ的定义为:δ(q0,0)=q1δ(q1,0)=q2δ(q2,1)=q2δ(q2,0)=q2M所对应的状态转换图为。
6. 有限状态自动机可用五元组(V T,Q,δ,q0,Q f)来描述,设有一有限状态自动机M的定义如下:V T={0,1},Q={q0,q1,q2},Q f={q2},δ的定义为:δ(q0,0)=q1δ(q1,0)=q2δ(q2,1)=q2δ(q2,0)=q2M所能接受的语言可以用正则表达式表示为。
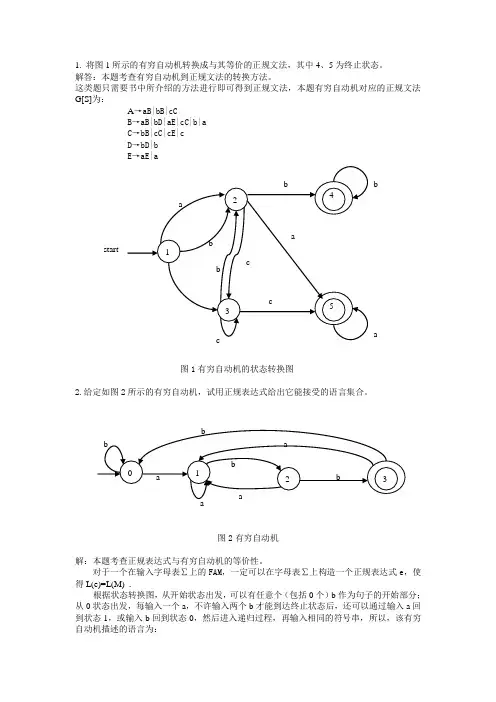
1. 将图1所示的有穷自动机转换成与其等价的正规文法,其中4、5为终止状态。
解答:本题考查有穷自动机到正规文法的转换方法。
这类题只需要书中所介绍的方法进行即可得到正规文法,本题有穷自动机对应的正规文法G[S]为:A →aB|bB|cCB →aB|bD|aE|cC|b|aC →bB|cC|cE|cD →bD|bE →aE|a图1有穷自动机的状态转换图2.给定如图2所示的有穷自动机,试用正规表达式给出它能接受的语言集合。
图2有穷自动机解:本题考查正规表达式与有穷自动机的等价性。
对于一个在输入字母表∑上的FAM ,一定可以在字母表∑上构造一个正规表达式e ,使得L(e)=L(M) .根据状态转换图,从开始状态出发,可以有任意个(包括0个)b 作为句子的开始部分;从0状态出发,每输入一个a ,不许输入两个b 才能到达终止状态后,还可以通过输入a 回到状态1,或输入b 回到状态0,然后进入递归过程,再输入相同的符号串,所以,该有穷自动机描述的语言为:startab(b*(aa*b)*b)*3. 构造下述正规表达式的DFA。
Xy*|yx*y|xyx解:本题考查由正规表达式构造有穷自动机的方法,本题可按照由正规表达式构造等价的NFA,NFA确定化,DFA最小化3步进行求解。
(1)根据题中所给的正规表达式得到相应的DFA如图3所示。
图3正规表达式Xy*|yx*y|xyx的DFA。
(2)依据该NFA采用子集法构造确定DFA其过程如表1(已换名)所示。
以所有包含NFA的终止状态Z的DFA状态作为终止状态,得到DFA相应的状态转换图如图4所示图4 DFA的状态转换图(3)对DFA进行最小化,过程如下:已知K={0,1,2,3,4,5,6}。
首先将K分成两个子集K1={0,2,3} (非终态集)K2={1,3,4,6} (终态集)在状态集合K1={0,2,3}中,因为{0}x={1}⊂K2{2,4}x={4}⊂K1所以状态0与状态2,4不等价,故K1可分割为K11={0} K12={2,4}在状态集合K12={2,4}中,因为有{2,4}x={4} {2,4}y={5}⊂K2所以,状态2和状态4等价。


第三章有限自动机与词法分析器3.1词法分析3.1.1词法分析器的功能在第二章里我们已介绍了词法分析的基本问题。
计算机存储是二进制式的,因此,任何一种程序和数据在计算机内部均被表示为二进制表示。
实际上,当程序员每按键盘中的一个键时,自动往计算机里输入一个相应的八位二进制码,称这种码为ASCII码。
当程序员敲完程序时将它保存到自己事先起好名的文件中,因此,程序在计算机文件中的表示是ASCII码序列(末尾有文件结束码)。
编译器总是要用某种程序设计语言来写,而任何一种语言的程序其操作对象必须是该语言所规定的数据。
编译器的操作对象是程序中的各种语法单位,如<常量声明>,<类型声明>,<变量声明>,<过程声明>,<表达式>,<语句>,<变量>等等,因此,必须把它们都表示成某种数据结构形式,而它们的最小单位是所谓的单词,故首当其充的是要把每个单词转换成一种数据形式,通常称它们为TOKEN。
词法分析器的任务就是,从源程序的ASC码(用高级语言的术语来说是字符串)序列逐个地拼出单词,并将构造相应TOKEN数据表示。
词法分析器可有两种,一种是它作为语法分析的一个子程序,一种是它作为编译器的独立一遍。
前一种情形,词法分析器不断地被语法分析器所调用,每调用一次词法分析器将从源程序的字符序列拼出一个单词,并将其TOKEN值返回给语法分析器。
后一种情形则不同,即不是被别的部分不断地调用,而是完成编译器的独立一遍任务,具体说将整个源程序的字符序列转换成TOKEN序列,并将其交给语法/语义分析器。
实际的编译器一般都采用子程序方式,但是为了独立地介绍词法分析、语法分析和语义分析的概念和技术,我们将词法分析部分分离出来即作为独立一遍的词法处理器来介绍。
从实际的角度来说,这种方法有以下缺点:一是因为它要生成TOKEN列,自然多占用空间;二是因为要保存所有的TOKEN,需要耗费更多的时间。


