第七章 虚拟变量
- 格式:doc
- 大小:42.50 KB
- 文档页数:5
第七章 虚拟变量和随机解释变量本章将讨论两种不同的模型:虚拟变量模型和随机解释变量模型,以及模型设定的其它问题。
第一节 虚拟变量模型在我们以前考虑的模型中,解释变量都是定量变量(如成本、价格、收入、产出等),但在经济研究中,因变量经常受到一些定性变量的影响(如性别、种族、季节、不同历史时期等),我们把这类定性变量称为虚拟变量。
习惯上用D表示虚拟变量,虚拟变量的取值通常为0和1。
0表示变量具备某种属性,1表示变量不具备某种属性。
一、包含一个虚拟变量的模型如果我们要研究的问题中解释变量只分为两类。
则需引入一个模拟变量。
例9.1建立模型研究中国妇女在工作中是否受到歧视。
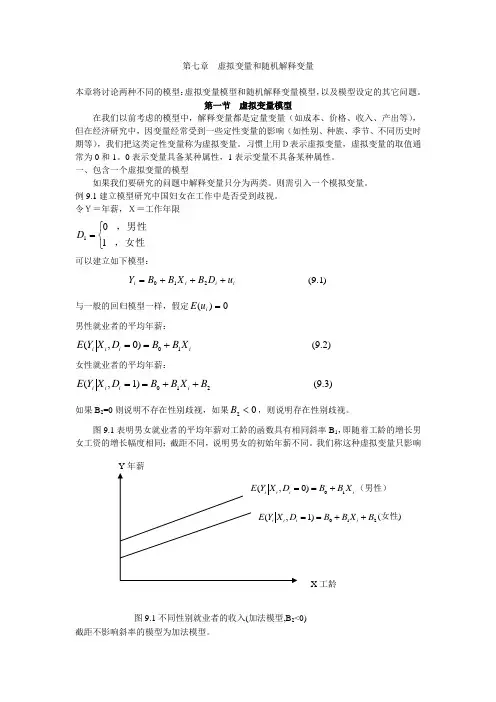
令Y=年薪,X=工作年限⎩⎨⎧=,女性,男性101D 可以建立如下模型:i i i i u D B X B B Y +++=210 )1.9( 与一般的回归模型一样,假定0)(=i u E 男性就业者的平均年薪:i i i i X B B D X Y E 10)0,(+== )2.9(女性就业者的平均年薪:210)1,(B X B B D X Y E i i i i ++== )3.9(如果B 2=0则说明不存在性别歧视,如果02<B ,则说明存在性别歧视。
图9.1表明男女就业者的平均年薪对工龄的函数具有相同斜率B 1,即随着工龄的增长男女工资的增长幅度相同;截距不同,说明男女的初始年薪不同。
我们称这种虚拟变量只影响截距不影响斜率的模型为加法模型。
图9.1不同性别就业者的收入(加法模型,B 2<0)如果随着工龄增加,男性与女性的年薪差距也发生变化,则模型(9.1)就变为i i i i i u X D B X B B Y +++=210 )4.9(图9.2描绘了男性年薪增加较快的情况。
我们称虚拟变量只影响斜率而不影响截距的模型为乘法模型如(9.4)如果男性与女性的初始年薪和年薪增加速度都有差异,我们可以将加法模型和乘法模型结合起来,得到如下模型i i i i i i u D B X D B X B B Y ++++=3210 )5.9(模型(9.5)可以用来表示截距和斜率都发生变化的模型。


第七章虚拟变量实验报告一、研究目的改革开放以来,我国经济保持了长期较快发展,与此同时,我国对外贸易规模也日益增长。
尤其是2002年中国加入世界贸易组织之后,我国对外贸易迅速扩张。
2012年,我国进出口总值38667.6亿美元,与上年同期相比增长6.2%。
至此,我国贸易总额首次超过美国,成为世界贸易规模最大的国家。
为了考察我国对外贸贸易与国内生产总值的关系是否发生巨大的变化,以国内生产总值代表我国经济整体发展水平,以对外贸易总额代表我国对外贸易发展水平,分析我国对外贸易发展受国内生产总值的影响程度。
二、模型设定为研究我国对外贸易发展规模受我国经济发展程度影响,引入国内生产总值为自变量。
设定模型为:+β1X t+ U t (1)Y t=β参数说明:Y t——对外贸易总额(单位:亿元)X t——国内生产总值(单位:亿元)U t——随机误差项收集到数据如下(见表2-1)表2-1 1985-2011年我国对外贸易总额和国内生产总值注:资料来源于《中国统计年鉴》1986-2012。
为了研究1985-2011年期间我国对外贸易总额随国内生产总值的变化规律是否有显著不同,考证对外贸易与国内生产总值随时间变化情况,如下图所示。
图2.1 对外贸易总额(Y)与国内生产总值(X)随时间变化趋势图从图2.1中,可以看出对外贸易总额明显表现出了阶段特征:在2002年、2007年和2009年有明显的转折点。
为了分析对外贸易总额在2002年前后、2007年前后及2009年前后几个阶段的数量关系,引入虚拟变量D1、D2、D3。
这三个年度对应的GDP分别为120332.69亿元、265810.31亿元和340902.81亿元。
据此,设定以下以加法和乘法两种方式同时引入虚拟变量的模型:Y t=β0+β1Xt+β2(Xt-120332.69)D1+β3(Xt-265810.31)D2+β4(Xt-340902.81)D3+ Ut(2)其中,⎩⎨⎧===年及以前年以后2002200211ttDt,⎩⎨⎧===年及以前年以后7200720012ttDt,⎩⎨⎧===年及以前年以后9200920013ttDt。








第七章虚拟变量第七章虚拟变量第一节虚拟变量的引入一、什么是虚拟变量前面几章介绍的解释变量都是可以直接度量的,称为定量变量。
如收入、支出、价格、资金等等。
但在现实经济生活中,影响应变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些无法定量的解释变量的影响,如性别、民族、国籍、职业、文化程度、政府经济政策变动等因素,他们只表示某种特征的存在与不存在,所以称为属性变量或定性变量。
属性变量:不能精确计量的说明某种属性或状态的定性变量。
在计量经济模型中,应当包含属性变量对应变量的影响作用。
那怎么才能把定性变量包括在模型中呢?属性变量通常是非数值变量,直接纳入回归方程中进行回归,显然是很困难的。
为此,人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与定量变量一样在回归模型中得以应用。
由于定性变量通常是表明某种特征或属性是否存在,如性别变量中以男性为分析基础的话,那就只有男性、非男性;政策变动变量中以政策不变为基准,则有政策不变,和政策变动;至于有两种以上的状态的话,比如学历分高中,本科,本科以上等等,我们又怎么办呢?把疑问留到后面去解决。
既然定性变量只有存在或不存在两种状态,所以量化的一般方法是取值为0或1。
称为虚拟变量。
虚拟变量:人工构造的取值为0或1的作为属性变量代表的变量。
一般常用D表示。
D=0,表示某种属性或状态不存在D=1,表示某种属性或状态存在比如前面说的性别变量,以男性为基准,则当样本为男性时,虚拟变量取0,当样本为女性时,则虚拟变量取1。
当虚拟变量作为解释变量引入计量经济模型时,对其回归系数的估计和统计检验方法都与定量解释变量相同。
二、虚拟变量的作用1、作为属性因素的代表,如,性别、种族等2、作为某些非精确计量的数量因素的代表,如:受教育程度、年龄段等;3、作为某些偶然因素或政策因素的代表,如战争、911等。
4、时间序列分析中作为季节(月份)的代表(比如对某些明显有淡季、旺季之分的产品)5、分段回归,研究斜率、截距的变动;6、比较两个回归模型;7、虚拟应变量概率模型,应变量本身是定性变量(比如你研究某产品的购买率,应变量本身就是买或不买)三、虚拟变量的设置规则1、虚拟变量D取值为0,还是取值为1,要根据研究的目的决定。
第七章虚拟变量第一节虚拟变量的引入一、什么是虚拟变量前面几章介绍的解释变量都是可以直接度量的,称为定量变量。
如收入、支出、价格、资金等等。
但在现实经济生活中,影响应变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些无法定量的解释变量的影响,如性别、民族、国籍、职业、文化程度、政府经济政策变动等因素,他们只表示某种特征的存在与不存在,所以称为属性变量或定性变量。
属性变量:不能精确计量的说明某种属性或状态的定性变量。
在计量经济模型中,应当包含属性变量对应变量的影响作用。
那怎么才能把定性变量包括在模型中呢?属性变量通常是非数值变量,直接纳入回归方程中进行回归,显然是很困难的。
为此,人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与定量变量一样在回归模型中得以应用。
由于定性变量通常是表明某种特征或属性是否存在,如性别变量中以男性为分析基础的话,那就只有男性、非男性;政策变动变量中以政策不变为基准,则有政策不变,和政策变动;至于有两种以上的状态的话,比如学历分高中,本科,本科以上等等,我们又怎么办呢?把疑问留到后面去解决。
既然定性变量只有存在或不存在两种状态,所以量化的一般方法是取值为0或1。
称为虚拟变量。
虚拟变量:人工构造的取值为0或1的作为属性变量代表的变量。
一般常用D表示。
D=0,表示某种属性或状态不存在D=1,表示某种属性或状态存在比如前面说的性别变量,以男性为基准,则当样本为男性时,虚拟变量取0,当样本为女性时,则虚拟变量取1。
当虚拟变量作为解释变量引入计量经济模型时,对其回归系数的估计和统计检验方法都与定量解释变量相同。
二、虚拟变量的作用1、作为属性因素的代表,如,性别、种族等2、作为某些非精确计量的数量因素的代表,如:受教育程度、年龄段等;3、作为某些偶然因素或政策因素的代表,如战争、911等。
4、时间序列分析中作为季节(月份)的代表(比如对某些明显有淡季、旺季之分的产品)5、分段回归,研究斜率、截距的变动;6、比较两个回归模型;7、虚拟应变量概率模型,应变量本身是定性变量(比如你研究某产品的购买率,应变量本身就是买或不买)三、虚拟变量的设置规则1、虚拟变量D取值为0,还是取值为1,要根据研究的目的决定。
D取值为0的类型,是基础类型,是比较的基准。
不如前面说的性别变量,如果你研究是以男性为研究基准,则样本为男性,D取值为0,2、避免落入“虚拟变量陷阱”。
当一个定性变量含有m个相互排斥的类型时,应向模型引入m—1个虚拟变量。
比如“性别”含男性和女性两个类别,所以当性别作为解释变量时,应向模型引入一个虚拟变量。
取值方式是:D=1(男性)、D=0(女性)或D=0(男性)、D=1(女性)而当“学历”含有四个类别时,即大学、中学、小学、无学历。
当“学历”作为解释变量时,应向模型引入三个虚拟变量。
一种取值方式是:1 (大学)1(中学)1(小学)D1= 0 (非大学)D2 = 0(非中学)D3= 0(非小学)所谓的“虚拟变量陷阱”就是当一个定性变量含有m个类别时,模型引入m个虚拟变量,造成了虚拟变量之间产生完全多重共线性,无法估计回归参数。
在m-1个虚拟变量中,虚拟变量可以同时取值为0,但不能全部取值为1。
3、当定性变量含有m个类别时,不能把虚拟变量的值设为D=0(第一类)D=1(二类)D=2(三类)等等。
1、回归模型中可以只有虚拟变量作解释变量,也可以用定量变量和虚拟变量一起作解释变量。
另外,虚拟变量还可以作被解释变量。
第二节虚拟解释变量的回归虚拟变量的引入,可以影响模型的截距,也可以影响斜率,还可以同时影响截距和斜率。
因此,加入虚拟解释变量的途径有两种基本类型:一是加法类型,二是乘法类型。
不同的引入途径对计量经济模型有不同的影响。
一、加法类型:改变模型的截距所谓的加法类型引入虚拟变量,就是虚拟变量与其他解释变量在设定模型中是相加关系。
在所设定的计量经济模型中,根据所研究问题中定量变量的影响作用,按照虚拟变量的设置规则,直接在所设定的计量经济模型中加入适当的虚拟解释变量。
比如:Y=a0+a1D1+a2D2+βX+u 就是以加法形式引入的虚拟变量。
加法形式引入虚拟解释变量,其作用是改变了设定模型的截距水平。
定性因素所包含的属性类别m的多少,决定了引入虚拟解释变量个数的多少,同时也决定了所设模型的不同性质。
下面分三种主要情形对加法形式引入虚拟变量的情形进行讨论。
1、解释变量包含一个分为两种属性类型的定性变量的回归如Y=a0+a1D+βX+u D=0 (基础类型)D=1(其他类型)则基础类型:E(Y)=a0+βX 比较类型:E(Y)=(a0+a1)+βXa1就是截距的差异系数。
对a1的显著性检验,就是判别两条回归线的截距项是否存在显著性差异,或者说,检验定性因素对截距是否有显著影响。
注意:u应服从基本假定;这里一个定性变量有两种类型,只使用了一个虚拟变量。
比如:我们分析是否读大学对年工资的影响。
见资料。
另P2192、解释变量中包含一个两种属性以上的定性解释变量的回归Y=a0+a1D1+a2D2+βX+u 例如研究收入、学历(中学以下、中学、中学以上)对书报费支出的影响。
D1=1(中学)=0(其他)D2=1 (中学以上)=0 (其他)则基础类型:(中学以下)E(Y|D1=0、D2=0)=a0+βX比较类型(中学)E(Y|D1=1,D2=0)=(a0+a1)+βX(中学以上)E(Y|D1=0,D2=1)=(a0+a2)+βX这表明,三种不同的属性类型,其对应变量的影响都是不同的,原因在于三者的起点水平即截距不同。
同样,a2、a3表示的是截距差异系数,对他们的显著性检验,说明了不同的属性是否对戒惧6具有显著性影响。
注意:u应服从基本假定;一个定性变量有m种属性,使用了m-1个虚拟变量,D1、D2代表的是同一定性变量的两种不同属性。
两个差异截距系数a1、a2表示的都是与基础类型的差异;一个定性变量多种属性时,虚拟变量可以同时取0(基础类型),但不能同时取值为1,因为同一定性变量的各类型间是相互排斥,“非此即彼”的。
3、解释变量包含两个定性变量的回归模型Y=a0+a1D1+a2D2+βX+u 这里的D1、D2代表的是两个不同的定性变量。
例如研究卷烟需求与收入、性别、居住地区的关系。
D1=1(城镇居民)=0(其他)D2=1男性=0 女性基础类型:农村女性居民:E(Y|D1=0、D2=0)=a0+βX比较类型:农村男性居民:E(Y|D1=0、D2=1)=(a0+a2)+βX城镇女性居民:E(Y|D1=1、D2=0)=(a0+a1)+βX城镇男性居民:E(Y|D1=1、D2=1)=(a0+a1+a2)+βX这个结果表明,不同的定性变量以及他们各自不同的属性都对应变量产生不同的影响。
a1、a2的显著性检验,可验证这两个定性变量对截距是否有影响。
注意:u应服从基本假定‘两个定性变量和一个有三种属性类型的定性变量都用了两个虚拟变量,但其性质是不同的;K个定性变量可选用K个虚拟变量去表示,这不会出现“虚拟变量陷阱”;代表不同定性变量的虚拟变量,可以同时为0,也可以同时为1,因为不同的定性变量间没有非此即彼的关系。
二、乘法类型——引起模型中斜率系数的差异。
加法方式引入虚拟解释变量,暗含着一个基本的假定:定性解释变量对于应变量的影响作用,仅体现在回归模型的截距项,即仅影响平均水平,而不会影响不同属性模型的相对变化。
表现在图上,就是回归线的斜率不变,只会上下平移。
但在现实经济中,这种假定条件通常难以满足。
例如,居住地区(城市或乡村)不仅会使消费总体支出上升,而且消费的结构也会发生很大的变化。
乘法类型引入虚拟解释变量,是在所设定的计量经济模型中,将虚拟变量与其他解释变量相乘作为新的解释变量出现在模型中,以达到其调整设定模型斜率系数的目的。
例如:Y=a0+a1X1+a2X2D+u乘法形式引入虚拟解释变量的主要作用在于:1、关于两个回归模型的比较;2、因素间的交互影响分析;3、提高模型对现实经济现象的描述精度。
下面分别对上述作用进行讨论。
(一)回归模型的比较——结构变化检验比如我们比较我国改革开放前后的储蓄——收入关系的变化时,就存在着经济结构变化而导致设定模型斜率发生变化的问题。
这类问题可归结为两个回归模型的比较。
例如:Y=a0+a1D+β1X+β2(DX)+u 其中D=1(改革开放前)=0(改革开放后) Y储蓄总额 X收入总额基础类型:改革开放后E(Y|D=0)=a0+β1X比较类型改革前:E(Y|D=0)=(a0+a1)+(β1+β2)X对上式的估计等同于对两个储蓄函数进行估计。
在式中,a1被称为截距差异系数,β2为斜率差异系数,分别代表改革开放前后储蓄函数截距与斜率所存在的差异。
因此,当以乘法形式引入虚拟解释变量时,其作用在于区别改革开放前后储蓄关于收入的相对变化情况,即区别两个时期模型斜率系数的变化情况,而加法形式引入虚拟变量则是区别不同时期的储蓄起点。
显著性检验的意义,也在于说明引入的虚拟变量对斜率影响的显著性,也就是检验这两个回归的结构是否有差异。
优点:用一个回归替代了多个回归,简化了分析过程;合并回归增加了自由度,提高参数估计的精确性。
(二)交互效应分析我们前面的模型,不管引入多少个定性变量,都暗含着一种假定:两个定性变量是分别独立影响应变量的。
但在实际情况中,两个定性变量之间存在着交互影响,而且这种交互影响对应变量产生了作用。
比如,我们引入性别和学历两个定性变量解释对服装支出费用的影响,用上面的模型我们只能得出性别对服装支出的影响而与学历无关,以及学历对服装支出的影响而与性别无关,没有一个解释变量是表征女性本科比女性高中的支出有没有差异,也就是说,性别和学历这两个定性变量之间存在着交互影响,且对应变量产生作用。
因此,为了描述这种交互作用,把两个虚拟变量的乘积以加法形式引入模型。
例如上面所说的服装支出与收入、性别、学历的关系:Y=a0+a1D1+a2D2+a3(D1D2)+βX+U其中的D1D2描述的就是二者交互效应的虚拟变量。
假设D1=1 女性 =0 男性,D2=1 本科及本科以上,=0 其他。
则a1=女性服装年平均支出的截距差异系数;a2=高教育水平人群年平均服装支出的截距差异系数;a3=高教育水平女性服装支出的截距差异系数,又称为本科女性的交互效应系数。
可以通过对对交互效应虚拟变量系数的显著性检验,判断交互效应是否存在(三)分段线性回归有的社会经济现象的变动,会在解释变量达到某个临界值时发生突变,比如公司对销售人员的奖励政策就经常是这样设计的:按销售额提,当销售额在某一目标水平以上或以下,提奖励的方法不同。
当销售额X《X*时,与X》X*的线段更平缓。