统计学第4章抽样调查
- 格式:ppt
- 大小:4.36 MB
- 文档页数:72

第四章一.思考题1、一组数据的分布特征可以从哪几个方面进行测度?答:可以从三个方面进行测度和描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布的偏态和峰态。
2、怎样理解平均数在统计学中的地位?答:平均数在统计学中具有重要的地位,它是进行统计分析和统计推断的基础。
从统计学思想上看,平均数是一组数据的重心所在,是数据误差相互抵消后的必然结果。
3、简述四分位数的计算方法。
答:四分位数是一组数据排序后处于25%和75%位子上的值。
四分位数是通过3个点将全部数据等分成4分,其中每部分包含25%的数据。
中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值和处在75%位置上的数值。
它是根据为分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数据就是四分位数。
4、对于比率数据的平均数为什么采用几何平均?答:几何平均数是适用于特殊数据的一种平均数,主要适用于计算平均比率。
当所掌握的变量值本身是比率的形式时,采用几何平均法计算平均比率更为合理。
5、简述众数、中位数、平均数的特点和应用场合。
答:众数是数据中出现次数次数最多的变量值。
主要应用于分类数据。
中位数是一组数据排序后处于中间位置的变量值,其适用于顺序数据。
平均数也称均值,它是一组数据相加后除以数据个数的结果,是集中去世的主要测量值,它适用于数值型数据。
6、简述异众比率、四分位差、方差、标准差的使用场合。
答:异众比率主要适合测度分类数据的离散程度,对于顺序数据以及数值型数据也可以计算异众比率。
四分位差主要用于测度顺序数据的离散程度。
方差和标准差适用于测度数值型数据的离散程度。
7、标准分数有哪些用途?答:首先是比较不同单位和不同质数据的位置。
其次是和正态分布结合起来,求得概率和标准分值之间的对应关系。
还有就是在假设检验和估计中应用。

第四章抽样理论与参数估计第一节抽样理论的基本知识分层抽样,又叫分层随机抽样,这种抽样方法是按照总体已有的某些特征,承认总体中已有的差异,按差异将总体分为几个不同的部分,每一部分称为一个层,在每一个层中实行简单随机抽样。
它充分利用了总体的已知信息,因而是一种非常适用的抽样方法,其样本代表性及推论的精确性一般优于简单随机抽样。
分层的原则是层与层之间的变异越大越好,各层内的变异要小。
试述分层抽样的原则和方法?分层抽样是按照总体上已有的某些特征,将总体分成几个不同部分,在分别在每一部分中随机抽样。
分层的总的原则是:各层内的变异要小,而层与层之间的变异越大越好。
在具体操作中,没有一成不变的标准,研究人员可根据研究需要依照多个分层标准,视具体情况而定。
⑷两阶段随机抽样两阶段随机抽样首先将总体分成M个部分,每一部分叫做一个"集团"(或"群"),第一步从M个集团中随机抽取m个"集团”作为第一阶段样本,第二步是分别从所选取的m个"集团”中抽取个体(g构成第二阶段样本。
一般而言,两阶段抽样相对于简单随机抽样,标准误要大些,但是,两阶段抽样简便易行,节省经草贼,因而它是大规模调查研究中常被使用的抽样方法。
例如,如果我们要了解全国城市初中二年级学生的身高,第一步我们可以从全国几百个城市中随机抽取几十个城市作为第一阶段的样本。
第二步,在第一阶段随机抽取出来的城市中再随机抽取初中二年级的学生。
(二)非旃抽样非概率抽样不是完全按随机原则选取样本,有方便抽样、判断抽样。
方便抽样是由调查人员自由、方便地选择被调查者的非随机选样。
判断抽样是通过某些条件过滤,然后选择某些被调查者参与调查的抽样法。
当采取非概率抽样的方法选取样本时,研究者要说明采用此种方取样的原因以及对研究结果可能造成的影响。
第二节抽样分布[统计量分布、基本随机变量函数的分布]总体:又称母全体、全域,指具有某种特征的一类事物的全体。
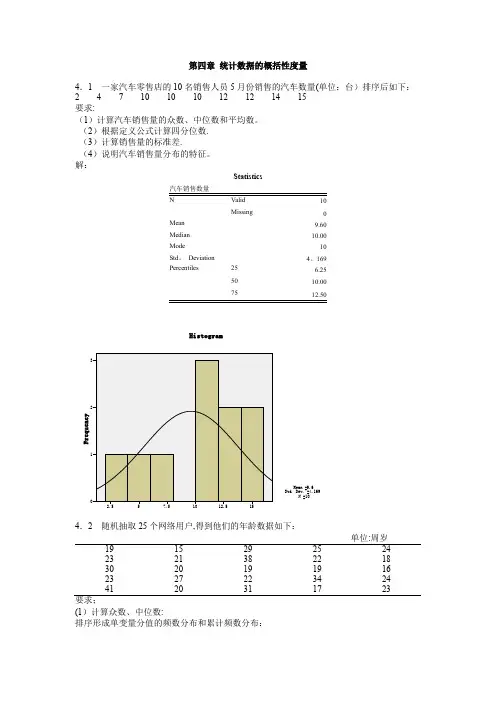
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数.(3)计算销售量的标准差.(4)说明汽车销售量分布的特征。
解:Statistics10Missing0Mean9.60Median10.00Mode10Std。
Deviation4。
169Percentiles25 6.255010.0075单位:周岁19152925242321382218302019191623272234244120311723要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数.Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18。
75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0。
75×2=26。
5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1。
080;Kurtosis=0。
773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数: ()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 — 最小值)÷ 组数=(41—15)÷6=4。
3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图::一种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待.为比较哪种排队方式使顾客等待的时间更短.两种排队方式各随机抽取9名顾客.得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟.第二种排队方式的等待时间(单位:分钟)如下:5.5 6.6 6.7 6.8 7.1 7.3 7.4 7.8 7.8要求:(1)画出第二种排队方式等待时间的茎叶图。




第四章综合指标一.填空题:1.总量指标按其说明总体内容不同,可分为总体标志总量和总体单位总量。
2.总量指标按其反应的时间状况不同,可分为时期指标和时点指标。
3.总量指标按其采用计量单位不同,可分为实物指标. 价值指标和劳动量指标。
4.算术平均数的基本公式总体标志总量/总体单位数。
5.相对指标按其是否拥有计量单位可区分为无名数和名数。
6.某地区去年的财政总收入为250亿元。
从反映总体的时间上看,该指标是时期指标;从反映总体的内容上看,该指标是总体标志总量。
7.平均指标说明分配数列中各变量值分布的集中趋势,变异指标说明各变量值分布的离中趋势。
8. 标志变异指标是用以反映总体各单位标志值差异程度的指标。
9.强度相对指标数值大小,如果与现象的发展程度或密度成正比,则称之为正指标,反之则称为逆指标。
10.用标准差比较两个变量数列平均数的代表性的前提条件是这两个变量数列的平均数相等。
二.单项选择题:1.下列指标属于总量指标的是( D )。
A.人均粮食产量B.资金利税率C.产品合格率D.学生人数2.下列指标属于比例相对指标的是( B )。
A.工人出勤率B.农轻重的比例关系C.每百元产值利税额D.净产值占总产值的比重3.下列指标中属于时点指标的是( D )。
A.国内生产总值B.流通费用率C.人均利税额D.商店总数4.下列指标中属于时期指标的是(D )。
A.商场数量B.营业员人数C.商品价格D.商品销售量5.下列属于结构相对数的是(C )。
A.人口出生率B.产值利润率C.恩格尔系数D.人口性别比6.某地区2006年的人均粮食产量393.10公斤,人均棉花产量3.97公斤,人均国民生产总值为1558元,它们是( D )。
A.结构相对指标B.比较相对指标C、比例相对指标 D.强度相对指标7.某企业产品单位成本计划2007年比2006年降低10%,实际降低15%,则计划完成程度为( B )。
A.150%B.94.4%C.104.5%D.66.7%8.第五次全国人口普查结果,我国每10万人中具有大学程度的为3611人。

第4章 练习题 一、单项选择题1.平均指标反映了( )①总体次数分布的集中趋势 ②总体分布的特征③总体单位的集中趋势 ④总体次数分布的离中趋势2.某单位的生产小组工人工资资料如下:90元、100元、110元、120元、128元、148元、200元,计算结果均值为128=X 元,标准差为( )①σ=33 ②σ=34 ③σ=34.23 ④σ=35 3.众数是总体中下列哪项的标志值( ) ①位置居中 ②数值最大 ③出现次数较多 ④出现次数最多4.某工厂新工人月工资400元,工资总额为200000元,老工人月工资800元,工资总额80000元,则平均工资为( )①600元 ②533.33元 ③466.67元 ④500元5.标志变异指标说明变量的( )①变动趋势 ②集中趋势 ③离中趋势 ④一般趋势 6.标准差指标数值越小,则反映变量值( )①越分散,平均数代表性越低 ②越集中,平均数代表性越高 ③越分散,平均数代表性越高 ④越集中,平均数代表性越低 7.在抽样推断中应用比较广泛的指标是( )①全距 ②平均差 ③标准差 ④标准差系数二、多项选择题1.根据标志值在总体中所处的特殊位置确定的平均指标有( ) ①算术平均数 ②调和平均数 ③几何平均数 ④众数 ⑤中位数2.影响加权算术平均数的因素有( )①总体标志总量 ②分配数列中各组标志值③各组标志值出现的次数 ④各组单位数占总体单位数比重 ⑤权数3.标志变异指标有( )①全距 ②平均差 ③标准差 ④标准差系数 ⑤相关系数 4.在组距数列的条件下,计算中位数的公式为( )①i f S fL M mm e ⋅-+=+∑12②i f S fU M m m e ⋅-=∑12--③i f S fL M mm e ⋅-+=∑12- ④i f S fU M mm e ⋅-=+∑12-⑤i f S fU M mm e ⋅-=∑12-+5.几何平均数的计算公式有( )①n n n X X X X ⋅⋅⋅121-Λ ②nX X X X nn ⋅⋅⋅121-Λ③122121-++++n X X X X nn -Λ ④∑f fIIX ⑤n IIX三、计算题1.某企业360名工人生产某种产品的资料如表1:试分别计算7、8月份平均每人日产量,并简要说明8月份平均每人日产量变化的原因。

统计学中的抽样与调查统计学是一门研究数据收集、整理、分析和解释的学科。
在统计学中,抽样和调查是非常重要的方法,用于获取和分析数据,从而得出对总体的推断和结论。
一、抽样的定义和目的抽样是从总体中选取一部分个体进行调查或研究的方法。
总体是要研究或调查的全部对象,例如,全国的人口或一种药物的副作用。
抽样的目的是通过对样本群体进行观察和测量,从而推断出总体的特征。
抽样可以帮助统计学家节约时间和资源,同时保证研究结论的准确性和可靠性。
二、抽样的方法1. 简单随机抽样:简单随机抽样是一种基本的抽样方法,每个个体都有相等的机会被选中。
使用随机数表或随机数发生器来选择样本,确保样本的代表性和无偏性。
2. 系统抽样:系统抽样是按照固定的间隔从总体中选取样本。
例如,从一个市场中每隔五个人选择一个进行调查,这样可以保证样本的分布均匀。
3. 分层抽样:分层抽样是将总体划分为几个不同的层次,然后从每个层次中进行抽样。
这样可以确保在样本中包含不同层次的特征,提高结果的代表性。
4. 整群抽样:整群抽样是将总体划分为若干个互不重叠的群体,然后从这些群体中随机选取几个进行调查。
这种方法常用于人口普查中,可以减少调查的复杂性。
三、调查的步骤和技巧1. 设计调查问卷:在进行调查之前,首先要设计调查问卷。
问卷应该简洁明了,问题要具体、明确,以确保得到准确和有用的信息。
2. 选择合适的调查方法:根据被调查者的特点和调查的目的,选择合适的调查方法,例如面对面访谈、电话调查、在线问卷等。
3. 实施调查:按照设计好的方案和计划进行调查,确保采集到充分、准确的数据。
调查人员应该专业、礼貌,并保证被调查者的隐私和权益。
4. 数据分析和解释:收集到数据后,使用统计方法对数据进行分析和解释。
常用的数据分析方法包括描述统计分析、推断统计分析等。
5. 结果报告和应用:根据数据分析的结果,撰写报告并对调查结果进行解释和应用。
报告应该简明扼要,结论准确可靠。

统计学-抽样调查的基本方法习题及答案一、选择题1. 抽样调查是指从人口中随机抽取个体作为调查对象,并通过对这些个体的调查研究来推断总体特征。
下面哪种抽样方法是最常用的?- A. 简单随机抽样- B. 系统抽样- C. 分层抽样- D. 整群抽样选择答案:A2. 如果我们希望对某个地区的顾客群体进行调查,首先将地区划分为多个不同的区域,然后从每个区域中随机选取一些顾客进行调查,这种抽样方法称为:- A. 简单随机抽样- B. 系统抽样- C. 分层抽样- D. 整群抽样选择答案:C3. 在统计调查中,"样本容量"是指:- A. 做出判断的人数- B. 地区划分数- C. 调查问卷的页数- D. 参与调查的个体数量选择答案:D二、填空题1. 抽样误差是指抽出的样本与总体之间的差异。
为了减小抽样误差,可以增加样本的<div style="">容量</div>。
2. "抽样分布"是指在相同的总体中,根据不同的抽样数据得出的统计量的<div style="">分布</div>。
3. "简单随机抽样"是一种可能的抽样方法,其中每个个体都有相同的<div style="">机会</div>被选中。
三、问答题1. 请简要说明简单随机抽样的基本步骤。
答案:简单随机抽样的基本步骤包括:- 确定总体和样本的定义;- 根据总体的特征确定抽样目标;- 设定样本容量;- 使用随机数生成器或其他随机选择方法,从总体中随机选取样本;- 进行调查或实验,收集样本数据;- 对样本数据进行统计分析,得出结论,并推断总体特征。
2. 请详细描述分层抽样的原理和适用场景。
答案:分层抽样是根据总体的特征将总体划分为多个层级,然后从每个层级中随机选取样本。

统计学习题(抽样分布、参数估计)练习题第1章绪论(略)第2章统计数据的描述2.1某家商场为了解前来该商场购物的顾客的学历分布情况,随机抽取了100名顾客。
其学历表示为:1.初中;2.高中/中专;3.大专;4.本科及以上学历。
调查结果如下:4222434414 2244432422 3121441424 2332134344 3312424324 2322212244 2123333334 2343313232 4313434214 2242334121(1)制作一张频数分布表。
(2)绘制一张条形图,反映学历分布。
2.2为了解某电信客户对该电信公司的服务的满意度情况,某调查公司分别对两个地区的电信用户在以下五个方面对受访用户的满意情况进行了问卷调查得到的数据如下(表中数据为平均满意度打分,从1分到10分满意度依次递增):地区企业形象客户期望质量感知价值感知客户总体满意度A 8.269504 7.51773 9.2624117.9148948.411348B 7.447368 8.3684218.9736848.1052637.394737试用条形图反映将两地区的满意度情况。
2.3下面是一个班50个学生的经济学考试成绩:88569179699088718279 988534744810075956092 83646569996445766369 6874948167818453912484628183698429667594(1)对这50名学生的经济学考试成绩进行分组并将其整理成频数分布表,绘制直方图。
(2)用茎叶图将原始数据表现出来。
2.4如下数据反映的是某大学近视度数的情况,共120名受访同学,男女同学各60名。
男149 161761821310 80 951081414 0 144145151515161681882121 0 21211052121211116817521 0 356462121212121312121 0 2121212121375375383838 8 45566065120 30120 7521女120 3334537437538700 90700 60141516212121211517170 0 0 0 0 0 0 0 5 521 0 1752121214043451217517 8 181818518519195196202021 0 21212121212121333335 0 3636363840474865055(1)按近视度数分别对男女学生进行分组。
六.计算题部分1、对一批成品按重复抽样方法抽选100件,其中废品4件,当概率为95.45%(t=2)时,可否认为这批产品的废品率不超过6%?答案:解:2%,41004,100====t p n 0196.0100)04.01(04.0)1(=-=-=n p p p μ039.00196.02=⨯==∆p p t μ p p p P p ∆+≤≤∆-039.004.0039.004.0+≤≤-P0.1%------7.9% ∴废品率不超过6%2、某乡有5000农户,按随机原则重复抽取100户调查,得平均每户年纯收入12000元,标准差2000元。
要求:(1)以95%的概率(t=1.96)估计全乡平均每户年纯收入的区间。
(2)以同样概率估计全乡农户年纯收入总额的区间范围。
答案: 解: 2001002000===n x σμ 39220096.1=⨯==∆x x t μ x x x X x ∆+≤≤∆- 3921200039212000+≤≤-X11608-----12392(元) 5000×11608------5000×12392(元)3、某企业生产一种新的电子元件,用简单随机重复抽样方法抽取100只作耐用时间试验,测试结果,平均寿命6000小时,标准差300小时,试在95.45%(t=2)概率保证下,估计这种新电子元件平均寿命区间。
答案:解:2,300,6000,100====t x n σ (小时)30100300===n x σμ (小时)60302=⨯==∆x x t μ x x x X x ∆+≤≤∆- 606000606000+≤≤-X 5940-----6060(小时)4、 从某年级学生中按简单随机抽样方式抽取50名学生,对邓小平理论课的考试成绩进行检查,得知其平均分数为75.6分,样本标准差10分,试以95.45%(99.73%t=3、68.27%t=1)的概率保证程度推断全年级学生考试成绩的区间范围。
第四章抽样估计一、判断题1.抽样估计的目的是用以说明总体特征。
2.抽样分布就是样本分布。
3.既定总体在当抽样方法、抽样组织形式和样本容量确定时,样本均值的分布惟一确定。
4.样本容量就是样本个数。
5.在抽样中,样本容量是越大越好。
6.抽样的目的是判断样本估计值是否处于以总体指标为中心的某规定区域范围内。
7.当估计量有偏时,人们应该弃之不用。
8.对于一个确定的抽样分布,其方差是确定的,因而抽样标准误也是确定的。
9.抽样极限误差越大,用以包含总体参数的区间就越大,估计的把握程度也就越大,因此极限误差越大越好。
10.非抽样误差会随着样本容量的扩大而下降。
二、单项选择题1.想了解学生的眼睛视力状况,准备抽取若干学校、若干班级的学生进行测试,则()。
A.观测单位是学校B.观测单位是班级C.观测单位是学生D.观测单位可以是学校、也可班级或学生2.下列误差中属于非一致性的有()。
A.估计量偏差B.偶然性误差C.抽样标准误D.非抽样误差3.抽样估计中最常用的分布理论是()。
A.t分布理论B.二项分布理论C.正态分布理论D.超几何分布理论4.抽样标准误大小与下列哪个因素无关?()A.样本容量B.抽样方式、方法C.概率保证程度D.估计量5.下列关于抽样标准误的叙述哪个是错误的?()A.抽样标准误是抽样分布的标准差B.抽样标准误的理论值是惟一的,与所抽样本无关C.抽样标准误比抽样极限误差小D.抽样标准误只能衡量抽样中的偶然性误差的大小三、计算分析题1. 某小组5个工人的每周工资分别为520、540、560、580、600元,现从中用简单随机抽样形式(不重复抽样)随机抽取2个工人周工资构成样本。
要求:(1)计算总体平均工资的标准差;(2)列出全部可能的样本平均工资;(3)计算样本平均工资的平均数,并检验其是否等于总体平均工资;(4)计算样本平均工资的标准差;(5)用抽样平均误差的公式计算并验证是否等于(4)的结果。
2.从某大型企业中随机抽取100名职工,调查他们的工资。
抽样调查,习题答案篇一:《抽样技术》第四版习题答案第2章2.1 解:?1? 这种抽样方法是等概率的。
在每次抽取样本单元时,尚未被抽中的编号为1~64的这些单元中每一个单元被抽到的概率都是1。
100?2?这种抽样方法不是等概率的。
利用这种方法,在每次抽取样本单元时,尚未被抽中的编号为1~35以及编号为64的这36个单元中每个单元的入样概率都是抽中的编号为36~63的每个单元的入样概率都是2,而尚未被1001。
100?3?这种抽样方法是等概率的。
在每次抽取样本单元时,尚未被抽中的编号为20 000~21 000中的每个单元的入样概率都是1,所以这种抽样是等概率的。
10002.3 解:首先估计该市居民日用电量的95%的置信区间。
根据中心极限定理可知,在大间为??z?_E近似服从标准正态分布,Y的195%的置信区_z。
1而V1?f2S中总体的方差S2是未知的,用样本方差s2来代替,置信区间n为,?_2。
?由题意知道,y?9.5,s?206,而且样本量为n?300,N?50000,代入可以求得v(y)?_1?f21?50000s??206?0.6825。
将它们代入上面的式子可得该市居民n300 日用电量的95%置信区间为??7.8808,11.1192??。
下一步计算样本量。
绝对误差限d和相对误差限r的关系为d?rY。
根据置信区间的求解方法可知____PyYrY1P1_2_rY根据正态分布的分位数可以知道P。
?Z1??,所以Vz?2?_rY??11?也就是S2nnNz??2?_222_rY1?。
22Nz/2S把y?9.5,s?206,r?10%,N?50000代入上式可得,n?86以总体比例P的195%的置信区间n?1可以写为pzp?z?,将p?0.35,n?200,N?10000代入可得置信区间为??0.2844,0.4156??。
2.5 解:利用得到的样本,计算得到样本均值为?2890/20?144.5,从而估计小区的平均文化支出为144.5元。
第四章 抽样分布与参数估计3.某地区粮食播种面积5000亩,按不重复抽样方法随机抽取了100亩进行实测,调查结果,平均亩产450公斤,亩产量标准差为52公斤。
试以95%的置信度估计该地区粮食平均亩产量和总产量的置信区间。
解:已知X =450公斤,n =100(大样本),n/N=1/50,11≈-Nn,不考虑抽样方式的影响,用重复抽样计算。
s =52公斤,1-α=95%,α=5%。
这时查标准正态分布表,可得临界值:96.1025.02/==z z α该地区粮食平均亩产量的置信区间是:1005296.14502⨯±=±nsz x α=[439.808,460.192] (公斤) 总产量的置信区间是:[439.808⨯5000,460.192⨯5000] (公斤) =[2199040,2300960](公斤)4.已知某种电子管使用寿命服从正态分布。
从一批电子管中随机抽取16只,检测结果,样本平均寿命为1490小时,标准差为24.77小时。
试以95%的置信度估计这批电子管的平均寿命的置信区间。
解:(1)已知X =1490小时,n =16,s =24.77小时,1-α=95%,α=5%。
这时查t 分布表,可得 2.13145)1(2/=-n t α该批电子管的平均寿命的置信区间是:1677.2413145.214902⨯±=±nst x α=[ 1476.801,1503.199](小时)因此,这批电子管的平均寿命的置信区间在1476.801小时与1503.199小时之间。
6.采用简单随机重复抽样的方法,从2 000件产品中抽查200件,其中合格品190件。
要求:(1)计算合格品率及其抽样平均误差。
(2)以95.45%的置信度,对合格品率和合格品数量进行区间估计。
(3)如果极限误差为2.31%,则其置信度是多少? 解:(1)合格品率:P=190/200⨯100%=95% 抽样平均误差:np p p )1()(-=σ=0.015(2)%3%95%100015.02%95)(22/02275.02/±=⨯⨯±=±==p Z P Z Z σαα]19601840[]2000%982000%92[(%]98%92[,,的置信区为:件合格品数量,:合格品率的置信区间为=⨯⨯)(3)%64.87)(8764.01,54.1%31.2%100015.0%31.2)(2/2/2/==-==⨯⨯==∆z F Z Z p Z ασααα查表得7.从某企业工人中随机抽选部分进行调查,所得工资分布数列如下:试求:(1)以95.45%的置信度估计该企业工人平均工资的置信区间,以及该企业工人中工资不少于800元的工人所占比重的置信区间;(2)如果要求估计平均工资的允许误差范围不超过30元,估计工资不少于800元的工人所占比重的允许误差范围不超过10%,置信度仍为95.45%,试问至少应抽多少工人? 解(1)通过EXCEL 计算可得: X =816元,n =50人,s =113.77元。