统计学原理-计算公式
- 格式:doc
- 大小:258.00 KB
- 文档页数:7

一.加权算术平均数和加权调和平均数的计算加权算术平均数: ∑∑=fxf x 或 ∑∑=ffxx加权调和平均数: ∑∑∑∑==fxf x m m x频数也称次数。
在一组依大小顺序排列的测量值中,当按一定的组距将其分组时出现在各组内的测量值的数目,即落在各类别(分组)中的数据个数。
再如在3.14159265358979324中,…9‟出现的频数是3,出现的频率是3/18=16.7% 一般我们称落在不同小组中的数据个数为该组的频数,频数与总数的比为频率。
频数也称“次数”,对总数据按某种标准进行分组,统计出各个组内含个体的个数。
而频率则每个小组的频数与数据总数的比值。
在变量分配数列中,频数(频率)表明对应组标志值的作用程度。
频数(频率)数值越大表明该组标志值对于总体水平所起的作用也越大,反之,频数(频率)数值越小,表明该组标志值对于总体水平所起的作用越小。
掷硬币实验:在10次掷硬币中,有4次正面朝上,我们说这10次试验中…正面朝上‟的频数是4例题:我们经常掷硬币,在掷了一百次后,硬币有40次正面朝上,那么,硬币反面朝上的频数为____.解答,掷了硬币100次,40次朝上,则有100-40=60(次)反面朝上,所以硬币反面朝上的频数为60.一.加权算术平均数和加权调和平均数的计算加权算术平均数: ∑∑=fxf x 或 ∑∑=ffxxx 代表算术平均数;∑是总和符合;f 为标志值出现的次数。
加权算术平均数是具有不同比重的数据(或平均数)的算术平均数。
比重也称为权重,数据的权重反映了该变量在总体中的相对重要性,每种变量的权重的确定与一定的理论经验或变量在总体中的比重有关。
依据各个数据的重要性系数(即权重)进行相乘后再相加求和,就是加权和。
加权和与所有权重之和的比等于加权算术平均数。
加权平均数 = 各组(变量值 × 次数)之和 / 各组次数之和 = ∑xf / ∑f加权调和平均数: ∑∑∑∑==fxf xm m x加权算术平均数以各组单位数f 为权数,加权调和平均数以各组标志总量m 为权数但计算内容和结果都是相同的。


简答题:1.品质标志和数量标志有什么区别?统计标志通常分为品质标志和数量标志两种。
品质标志表明总体单位属性方面的特征,其标志表现只能用文字来表现,如经济类型是品质标志,标志表现则用文字具体表现为全民所有制等;数量标志表明总体单位数量方面的特征,其标志表现可以用数值表示,即标志值。
它们从不同方面体现总体单位在具体时间、地点条件运作的结果。
2.一个完整的统计调查方案包括哪些内容?(1) 调查目的:调查目的要符合客观实际,是任何一套方案首先要明确的问题,是行动的指南。
(2) 调查对象和调查单位:调查对象即总体,调查单位即总体中的个体。
(3) 调查项目:即指对调查单位所要登记的内容。
(4) 调查表:就是将调查项目按一定的顺序所排列的一种表格形式。
调查表一般有两种形式:单一表和一览表。
一览表是把许多单位的项目放在一个表格中,它适用于调查项目不多时;单一表是在一个表格中只登记一个单位的内容。
(5) 调查方式和方法:调查的方式有普查、重点调查、典型调查、抽样调查、统计报表制度等。
具体收集统计资料的调查方法有:访问法、观察法、报告法等。
(6) 调查地点和调查时间:调查地点是指确定登记资料的地点;调查时间:涉及调查标准时间和调查期限。
(7) 组织计划:是指确保实施调查的具体工作计划3.举例说明如何理解调查单位与填报单位的关系?调查单位是调查资料的直接承担着,报告单位是调查哦资料的提交者,二者有时一致,有时不一致。
如,对某市工业企业生产经营情况调查,该市所有的工业企业是调查对象,而每一工业企业是调查单位,同事又是报告单位;又如对某市工业企业职工收入状况调查,该市多有工业企业的全体职工是调查对象,每一职工是调查单位,而每一工业企业是报告单位。
4.调查对象、调查单位和填报单位有何区别?调查对象是应搜集资料的许多单位的总体。
调查单位也就是总体单位,它是调查对象的组成要素,即调查对象所包括的具体单位。
5.某地区对占该地区工业增加值三分之二的10个企业进行调查,你认为这种调查方式是重点调查还是典型调查?为什么?重点调查,重点调查是选取一部分重要样本进行调查,这些重要样本在量的方面占优势;而典型调查是有目的的选取有代表性的样本进行调查,侧重该样本的质的方面你做的时候,记住量和质的不同6.简述变量分组的种类及应用条件。


《统计学原理》复习资料(计算部分)一、 编制分配数列(次数分布表) 统计整理公式a) 组距=上限-下限 b) 组中值=(上限+下限)÷2c) 缺下限开口组组中值=上限-1/2邻组组距 d) 缺上限开口组组中值=下限+1/2邻组组距1.某班40名学生统计学考试成绩分别为:57 89 49 84 86 87 75 73 72 68 75 82 97 81 67 81 54 79 87 95 76 71 60 90 65 76 72 70 86 85 89 89 64 57 83 81 78 87 72 61要求:⑴ 根据上述资料按成绩分成以下几组:60分以下,60~70分,70~80分,80~90分,90~100分,整理编制成分配数列。
⑵ 根据整理后的分配数列,计算学生的平均成绩。
解:分配数列成绩(分) 学生人数(人) 频率(%) 60以下 4 10 60—70 6 15 70—80 12 30 80—90 15 37.5 90—100 3 7.5 合计 40 100平均成绩 55465675128515953307076.754040xf x f⨯+⨯+⨯+⨯+⨯====∑∑(分)或 5510%6515%7530%8537.5%957.5%76.75fx x f=⋅=⨯+⨯+⨯+⨯+⨯=∑∑(分)2.某生产车间40名工人日加工零件数(件)如下:30 26 42 41 36 44 40 37 43 35 37 25 45 29 43 31 36 49 34 47 33 43 38 42 32 25 30 46 29 34 38 46 43 39 35 40 48 33 27 28要求:⑴ 根据以上资料分成如下几组:25~30,30~35,35~40,40~45,45~50,整理编制次数分布表。
⑵ 根据整理后的次数分布表,计算工人的平均日产量。
(作业10P 1) 解:次数分布表日加工零件数(件) 工人数(人)频率(%)25—307 17.5 30—35 8 20 35—40 9 22.5 40—45 10 25 45—50 6 15 合计 40100平均日产量 27.5732.5837.5942.51047.56150037.54040xf x f⨯+⨯+⨯+⨯+⨯====∑∑ 件或 27.517.5%32.520%37.522.5%42.525%47.515%37.5fx x f=⋅=⨯+⨯+⨯+⨯+⨯=∑∑ 件二、 算术平均数和调和平均数的计算 加权算术平均数公式 xfx f=∑∑(常用) fx x f=⋅∑∑(x 代表各组标志值,f 代表各组单位数,ff∑代表各组的比重)加权调和平均数公式 m x m x=∑∑ (x 代表各组标志值,m 代表各组标志总量)分析: m x mx=总产量工人平均劳动生产率(结合题目)总工人人数从公式可以看出,“生产班组”这列资料不参与计算,是多余条件,将其删去。

统计学原理常用公式1.样本均值公式:样本均值是用来估计总体均值的一种方法,公式为:\bar{x} = \frac{{\sum_{i=1}^n x_i}}{n}\]其中,\(\bar{x}\) 是样本均值,\(x_i\) 是第 \(i\) 个观察值,\(n\) 是样本容量。
2.样本方差公式:样本方差是用来估计总体方差的一种方法,公式为:s^2 = \frac{{\sum_{i=1}^n (x_i - \bar{x})^2}}{n-1}\]其中,\(s^2\) 是样本方差,\(x_i\) 是第 \(i\) 个观察值,\(\bar{x}\) 是样本均值,\(n\) 是样本容量。
计算样本方差时使用的是无偏估计公式。
3.标准差公式:标准差是样本方差的平方根,公式为:s = \sqrt{s^2}\]其中,\(s\)是样本标准差。
4.离差平方和公式:离差平方和是指每个观察值与均值之差的平方的总和,公式为:\sum_{i=1}^n (x_i - \bar{x})^2\]5.切比雪夫不等式:切比雪夫不等式给出了随机变量与其均值之间的关系,公式为:P(,X-\mu,\geq k\sigma) \leq \frac{1}{k^2}\]其中,\(X\) 是随机变量,\(\mu\) 是均值,\(\sigma\) 是标准差,\(k\) 是大于零的常数。
6.二项分布的期望值和方差公式:二项分布用于描述在\(n\)次独立重复试验中成功的次数的概率分布。
其期望值和方差分别为:E(X) = np\]Var(X) = np(1-p)\]其中,\(X\)是二项分布随机变量,\(n\)是试验次数,\(p\)是单次试验成功的概率。
7.正态分布的概率密度函数和累积分布函数公式:正态分布描述了大部分自然现象中的连续性随机变量的分布。
f(x) = \frac{1}{{\sqrt{2\pi}\sigma}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]F(x) = \frac{1}{2}\left[1 + \text{erf}\left(\frac{x -\mu}{\sqrt{2}\sigma}\right)\right]\]其中,\(x\) 是正态分布的随机变量,\(\mu\) 是均值,\(\sigma\) 是标准差,\(\text{erf}\) 是误差函数。

统计学期末(单选、10个填空、5个判断、三个计算、一道论述)第一章导论1、统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。
分析数据:分为描述统计方法和推断统计方法两种方法。
描述统计:研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法。
推断统计:是研究如何利用样本数据来推断总体特征的统计方法。
推断统计内容包含参数估计和假设检验2、统计数据的类型:(1)按照采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据与数值型数据。
注意:分类数据和顺序数据都是表现事物的品质特征,通常是用文字来表述的,其结果均表现为类别,因此可以通称为定性数据或品质数据(qualitative data)。
数值型数据说明的是现象的数量特征,通常用数值来表现,因此可以统称为定量数据或数量数据(quantitative data)。
(2)按照统计数据的收集方法,可以将统计数据分为观测数据和实验数据。
(3)按照被描述的现象与时间的关系,可以将统计数据分为截面数据、时间序列数据(和面板数据 panal data)。
3、抽样独立性问题:总体区分为有限总体和无限总体,目的是为了判别在抽样中每次抽取是否独立(类似抽小球是否放回的问题)。
在统计推断中,通常是针对无限总体的,因而通常把总体看做随机变量(random variable)。
统计上的总体通常是一组观测数据,而不是一群人或者一些物品的简单集合。
4、统计指标按其所反映的数量特点和作用不同,分为数量指标、质量指标。
样本(sample)是从总体中抽取的一部分元素的集合,构成样本的元素的数目称为样本量(sample size)。
抽样的目的是根据样本提供的信息推断总体的特征。
5、总体参数(parameter)是用来描述总体特征的概括性数字度量,是研究者想要了解的某种特征值。
样本统计量(statistic)是用来描述样本特征的概括性数字度量,是根据样本数量计算出来的一个量。


统计学原理第一章绪论统计是对客观事物的数量方面进行核算和分析,是人们对客观事物的数量表现、数量关系和数量变化进行描述和分析的一种计量活动。
统计的三层含义:统计工作、统计资料、统计学统计工作:即统计实践活动,是人们对客观事物的数据资料进行搜集、整理、分析的工作的总称,是一种社会调研活动统计资料:是统计工作的成果,包括各种统计报表、统计图形及文字资料等。
统计学:是研究大量社会现象(经济)的总体方面的方法论科学三者关系:统计学与统计实践活动的关系是理论与实践的关系,理论源于实践,理论又高于实践,反过来又指导实践。
统计工作和统计数据是工作和工作成果关系。
统计工作过程(统计工作的基本环节):1.统计设计(准备阶段)设计方案、指标体系、分类目录等2.统计调查(调查阶段)收集和占有统计资料3.统计整理(整理阶段)分布数列、次数分布等加工资料(承上启下)4.统计分析(分析阶段)绝对指标、相对指标等5.统计的表现与运用(工作总结)统计研究的基本方法:1.大量观察法2.综合指标法3.统计分组法4.归纳推理法5.统计模型社会统计学的特点1、数量性:统计研究对象是客观事物的数量方面。
2、总体性:主要是研究社会经济现象的总体数量规律3、具体性:社会经济统计的研究对象是具体事物的数量,不是抽象的量。
4、变异性:总体中各单位的数值表现存在差异5、不确定性:是在现有的统计资料基础上或样本数据基础上进行阶段性分析,所获得的结论不确定统计的职能:信息职能、咨询职能、监督职能。
第二章统计数据的搜集统计学中几个基本概念统计数据的计量尺度统计数据:是对客观社会经济现象进行计量的结果。
1.定类尺度:也称类别尺度或列名尺度,是按照现象的某种属性对其进行平行的分组或分类。
是最粗略、计量层次最低的计量尺度。
2.定序尺度:又称顺序尺度,是对现象之间的等级差或顺序差别的一种测度。
可以确定类别的优劣或顺序3.定距尺度:也称间隔尺度,是对现象类别或次序之间间距的测度。

精品文档《统计学原理》常用公式汇总及计算题目分析第一部分常用公式第三章统计整理a)组距=上限-下限b)组中值=(上限+下限)÷2c)缺下限开口组组中值=上限-1/2邻组组距d)缺上限开口组组中值=下限+1/2邻组组距第四章综合指标i.相对指标1.结构相对指标=各组(或部分)总量/总体总量2.比例相对指标=总体中某一部分数值/总体中另一部分数值3.比较相对指标=甲单位某指标值/乙单位同类指标值4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象总量指标5.计划完成程度相对指标=实际数/计划数=实际完成程度(%)/计划规定的完成程度(%)ii.平均指标精品文档.精品文档简单算术平均数:1.2.加权算术平均数或iii.变异指标1.全距=最大标志值-最小标志值 = : 简单σ加权= ;σ2.标准差 :3.标准差系数抽样估计第五章1.平均误差:重复抽样:不重复抽样:抽样极限误差2.3.重复抽样条件下:平均数抽样时必要的样本数目精品文档.精品文档成数抽样时必要的样本数目4.不重复抽样条件下:平均数抽样时必要的样本数目第七章相关分析相关系数1.y=a+bx配合回归方程2.3.估计标准误:第八章指数分数一、综合指数的计算与分析数量指标指数(1)精品文档.精品文档此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。
)(-此差额说明由于数量指标的变动对价值量指标影响的绝对额。
质量指标指数(2)此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。
-()此差额说明由于质量指标的变动对价值量指标影响的绝对额。
=加权算术平均数指数加权调和平均数指数=复杂现象总体总量指标变动的因素分析(3) 相对数变动分析:×= 绝对值变动分析:精品文档.精品文档)×(-)= (--第九章动态数列分析一、平均发展水平的计算方法:由总量指标动态数列计算序时平均数(1)①由时期数列计算②由时点数列计算在间断时点数列的条件下计算: a.若间断的间隔相等,则采用“首末折半法”计算。
统计学原理重要公式1.样本均值公式:样本均值是样本数据的总和除以样本的大小。
它的公式是:$$ \bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i $$其中,n是样本的大小,xi是第i个观测值。
2.总体均值公式:总体均值是从总体中取得的全部样本数据的总和除以总体的大小。
它的公式是:$$ \mu = \frac{1}{N} \sum_{i=1}^{N} x_i $$其中,N是总体的大小,xi是第i个观测值。
3.样本方差公式:样本方差是样本数据与样本均值差的平方和的平均值。
它的公式是:$$ s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2 $$其中,n是样本的大小,xi是第i个观测值,$ \bar{x} $是样本均值。
4.总体方差公式:总体方差是总体数据与总体均值差的平方和的平均值。
它的公式是:$$ \sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 $$其中,N是总体的大小,xi是第i个观测值,$ \mu $是总体均值。
5.样本标准差公式:样本标准差是样本方差的平方根。
它的公式是:$$ s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2} $$其中,n是样本的大小,xi是第i个观测值,$ \bar{x} $是样本均值。
6.总体标准差公式:总体标准差是总体方差的平方根。
它的公式是:$$ \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2} $$其中,N是总体的大小,xi是第i个观测值,$ \mu $是总体均值。
7.样本比例公式:样本比例是样本中具有一些特征的观测值的比例。
$$ p = \frac{x}{n} $$其中,n是样本的大小,x是具有特征的观测值的数量。
第二章数据描述1、组距=上限—下限2、简单平均数:x=Σx/n3、加权平均数:x=Σxf/Σf4、全距: R=x max-x min5、方差和标准差:方差是将各个变量值和其均值离差平方的平均数。
其计算公式:未分组的计算公式:σ2=Σ(x-x)2/n分组的计算公式:σ2=Σ(x-x)2f/Σf样本标准差则是方差的平方根:未分组的计算公式:s=[Σ(x-x)2/(n-1)]1/2分组的计算公式:s=[Σ(x-x)2f/(Σf-1)] 1/2σ=[Σ(x-x)/n] 1/26、离散系数:总体数据的离散系数:Vσ=σ/x样本数据的离散系数:V s=s/x10、标准分数:标准分数也称标准化值或Z分数,它是变量值与其平均数的离差除以标准差后的值,用以测定某一个数据在该组数据的相对位置。
其计算公式为:Z i=(x i-x)/s标准分数的最大的用途是可以把两组数组中的两个不同均值、不同标准差的数据进行对比,以判断它们在各组中的位置。
第三章参数估计1、统计量的标准误差:(样本误差)(1)在重复抽样时;样本标准误差:σx=σ/n或σx=s/n样本的比例误差可表示为:σp=[π(1-π)/n]1/2或σp=[p(1-p)/n] 1/2(2)不重复抽样时:σ2x=σ2/n×(N-n/N-1)σ2p=p(1-p)/n×(N-n/N-1)2、估计总体均值时样本量的确定,在重复抽样的条件下:n= Z2σ2/E23、估计总体比例时样本量的确定,在重复抽样的条件下:n=Z2×p(1-p)/E24、(1)在大样本情况下,样本均值的抽样分布服从正态分布,因此采用正态分布的检验统计量,当总体方差已知时,总体均值检验统计量为:Z=(x-μ)/( σ/n)(2)当总体方差未知时,可以用样本方差来代替,此时总体均值检验的统计量为:Z=(x-μ)/( s/n)5、小样本的检验:在小样本(n<30)情况下,检验时,首先假定总体均值服从正态分布。
一、相关系数的概念相关系数用来衡量两个变量之间的线性相关程度,是统计学中常用的一种指标。
相关系数的取值范围在-1到1之间,值越接近-1或1,说明两个变量之间的线性相关程度越强,值越接近0,说明两个变量之间的线性相关程度越弱或没有线性相关关系。
二、相关系数的计算方法相关系数的计算方法有多种,其中最常用的是皮尔逊相关系数。
皮尔逊相关系数的计算步骤如下:1. 计算两个变量的均值。
2. 计算两个变量与均值的差值,并将差值相乘。
3. 将上一步的结果相加,并除以两个变量的标准差的乘积。
除了皮尔逊相关系数外,还有斯皮尔曼相关系数、肯德尔相关系数等其他计算方法。
不同的计算方法适用于不同类型的变量和数据分布。
三、相关系数的应用领域相关系数在各个领域都有着广泛的应用,特别是在自然科学、社会科学和工程技术领域。
以下是一些相关系数在实际中的应用案例:1. 医学研究中,可以使用相关系数来衡量药物与疾病之间的相关性,以及疾病发展的趋势。
2. 金融领域中,相关系数可以帮助分析不同资产之间的相关程度,从而进行风险管理和资产配置。
3. 市场营销中,相关系数可以用来分析产品销售量与广告投入之间的相关性,为市场策略提供依据。
四、相关系数的局限性尽管相关系数在许多情况下都是一种有效的分析工具,但它也有一些局限性。
以下是一些相关系数的局限性:1. 相关系数只能反映两个变量之间的线性相关程度,而不能反映非线性关系或者其他类型的关系。
2. 相关系数不能用于说明因果关系,即使两个变量之间存在很强的相关性,也不能说明其中一个变量是另一个变量的原因。
在使用相关系数进行分析时,需要结合具体的问题和实际情况进行综合考虑,不能过分依赖相关系数的结果进行决策。
五、结语相关系数作为统计学中重要的工具之一,对于研究变量之间的关系具有重要意义。
在实际应用中,需要根据具体情况选择合适的相关系数计算方法,并结合其他分析方法进行综合分析,以获得更为全面和准确的结论。
统计学原理知识点统计学是一门研究数据收集、分析、解释和呈现的学科,它在各个领域都有着重要的应用。
无论是社会科学、自然科学还是工程技术领域,统计学都扮演着至关重要的角色。
在统计学的学习过程中,我们需要掌握一些基本的知识点,这些知识点对于理解统计学的基本原理和方法至关重要。
首先,我们需要了解统计学的基本概念。
统计学是一门研究如何收集、整理、分析和解释数据的学科。
它包括描述统计和推断统计两个方面。
描述统计是对已有数据进行整理和总结,包括数据的集中趋势和离散程度的度量;推断统计则是根据样本数据对总体进行推断,包括参数估计和假设检验等内容。
其次,我们需要了解统计学中的数据类型。
在统计学中,数据可以分为定量数据和定性数据两种类型。
定量数据是可以用数字表示的数据,包括连续型数据和离散型数据;定性数据则是用文字描述的数据,通常表示某种特征或属性。
另外,我们还需要了解统计学中的概率理论。
概率是统计学的重要基础,它用来描述随机现象发生的可能性。
概率理论包括基本概率、条件概率、贝叶斯定理等内容,它们在统计推断和决策分析中有着重要的应用。
此外,统计学中的抽样技术也是我们需要掌握的重要知识点。
抽样技术是指从总体中抽取样本的方法,它包括简单随机抽样、分层抽样、整群抽样等多种抽样方法,对于保证样本的代表性和可靠性至关重要。
最后,我们还需要了解统计学中的统计推断方法。
统计推断是根据样本数据对总体进行推断的方法,包括参数估计和假设检验两种方法。
参数估计是利用样本数据对总体参数进行估计,包括点估计和区间估计两种方法;假设检验则是根据样本数据对总体参数进行假设检验,判断总体参数是否符合某种假设。
总的来说,统计学原理知识点涉及到了统计学的基本概念、数据类型、概率理论、抽样技术和统计推断方法等内容。
掌握这些知识点对于理解统计学的基本原理和方法至关重要,它们不仅对于学习统计学课程有着重要的意义,也对于日常生活和各个领域的应用有着重要的指导作用。
《统计学原理》公式大全一、统计整理1.组距=上限 - 下限 2.组中值(1)闭口组2下限上限组中值+= (2)开口组组中值①2相邻组组距上限值缺下限的开口组的组中-= ②2相邻组组距下限值缺上限的开口组的组中+= 二、综合指标1.计划完成相对数 =计划任务数实际完成数2.计划执行进度 =计划期计划任务累计数数一时间的实际完成累计自计划执行之日起至某3.结构相对数 =总体总量总体中某部分数值4.总体中另一部分数值总体中某部分数值比例相对数=5.值另一总体的同类指标数某总体的某指标数值比较相对数=6.的总量指标数值另一性质不同但有联系某一总量指标数值强度相对数=7.基期指标数值报告期指标数值动态相对数=8.总体单位总量总体标志总量算术平均数=9.简单算术平均数 x —=nxn x x x n ∑=+++ 21 10.加权算术平均数 x —=∑∑=∑+++f xf f f x f x f x n n 2211 11.简单调和平均数 ∑=-xN x H 112.加权调和平均数 ∑∑=-mxmx H 113.极差(R )= 最大标志值 — 最小标志值14.简单平均差 D A ⋅=nx x∑-—15.加权平均差 D A ⋅=∑-fx x —16.简单标准差 nx x ∑-=)(—2σ17.加权标准差 ∑∑-=ffx x )(—2σ三、抽样推断1.重复抽样条件下的抽样平均数的抽样平均误差 nx σμ2=2.重复抽样条件下的抽样成数的抽样平均误差 nP P p )1(-=μ 3.不重复抽样条件下的抽样平均数的抽样平均误差 )1(2N nn x -=σμ4.抽样成数的抽样平均误差 )1()1(Nnn P P p --=μ 5.抽样平均数的抽样极限误差 =∆xμ-⋅x t 6.抽样成数的抽样极限误差=∆pμp t ⋅7.概率度 t =μxx ∆ t = μpp ∆8.总体均值的区间估计 x __±∆x9.总体比例的区间估计 p ±∆P四、统计指数1.个体价格指数 p pk p 01=2.个体产量指数 q q k q 01=3.个体成本指数 z z k z 01=4.数量指标综合指数 ∑∑=p q p q k q 00015.质量指标综合指数 ∑∑=p q p q k p 01116.加权算术平均数指数 ∑∑⋅=p q p q k k q q 0007.加权调和平均数指数 ∑⋅∑=p q k p q k pp 111118.可变构成指数 ∑∑∑∑⋅⋅==)()(00011101_________f x f f x x x k 可变9.固定构成指数 ∑∑∑∑⋅⋅=)()(110111___f f x f x k 固定10.结构影响指数 ∑∑∑∑⋅⋅=)()(00110___f x f f x k 结构11.指数体系相对数形式 k k k p q qp ⨯= 即∑∑⨯∑∑=∑∑p q p q p q p q p q p q 011100010011 绝对数形式:)()(011100010011∑∑-+∑∑-∑∑=-p q p q p q p q p q p q五、动态数列1.根据时期数列计算平均发展水平 n a na a a a n ∑=+++=21—2.根据间隔相等的连续时点数列计算平均发展水平n a na a a a n ∑=+++=21—3.根据间隔不等的连续时点数列计算平均发展水平∑∑=ffa a —4.根据间隔相等的间断时点数列计算平均发展水平1221222132113221—-++++=-++++++=--n n a a a a a a a a a a a a nn nn5.根据间隔不等的间断时点数列计算平均发展水平f f f f aa f a a f a a a n n n n 12111232121—222---+++++++++= 6.根据相对数动态数列或平均数动态数列计算平均发展水平ba c ———=7.增长量 = 报告期水平 一 基期水平 8.逐期增长量=报告期水平一前一期水平,用符号表示为:a a ,,a a ,a a ,a a n n 1231201----- 9.累计增长量 = 报告期水平一某一固定基期水平用符号表示为:a a ,,a a ,a a ,a a n 0030201---- 10.各期的逐期增长量之和等于最后一个时期的累计增长量,用公式表示为: a a a a a a a a a a n n n 01231201)()()()(-=-++-+-+--11.相邻两个时期的累计增长量之差等于相应时期的逐期增长量,用公式表示为: a a a a a a n n n n 1010)()(---=---12.年距增长量 = 本期发展水平 - 去年同期发展水平 13.1-==时间数列的项数累计增长量逐期增长量的个数逐期增长量之和平均增长量14.基期水平报告期水平发展速度=15.前一期水平报告期水平环比发展速度=用符号表示为:a a a a a a a a n n 1231201,,,,- 16.某一固定基期水平报告期水平定基发展速度=用符号表示为:a a a a a a a a no o 03201,,,,17.定基发展速度等于相应时期内的各环比发展速度的连乘积,用符号可表示为:a a a a a a a a n n 1231201-⨯⨯⨯⨯ =aa n 018.相邻两个定基发展速度之比等于相应时期的环比发展速度,用符号可表示为:a a a a a a n nn n 1010--=÷19.去年同期发展水平本期发展水平年距发展速度=20.11-=-=-==发展速度基期水平报告期水平基期水平基期水平报告期水平基期水平报告期增长量增长速度21.1-=-==环比发展速度前一期水平前一期水平报告期水平前一期水平逐期增长量环比增长速度 22.1-=-==定基发展速度某一固定基期水平某一固定基期水平报告期水平某一固定基期水平累计增长量定基增长速度23.()1-==年距发展速度月或季去年同期发展水平年距增长量年距增长速度24.平均发展速度的计算公式为:ninnx x x x x x ∏=⋅⋅⋅⋅= 321—由于环比发展速度的连乘积等于相应定基发展速度,因此平均发展速度的公式可写成:non a a x =—25.平均增长速度 = 平均发展速度 一1 26.100100100%1前一期水平前一期水平期增长量逐期增长量环比增长速度逐期增长量的绝对值增长=⨯=⨯=。
位值平均数计算公式1、众数:是一组数据中出现次数最多的变量值 组距式分组下限公式:002110m m d L M ⋅∆+∆∆+= 0m L :代表众数组下限; 1100--=∆m m f f :代表众数组频数—众数组前一组频数 0m d :代表组距; 1200+-=∆m m f f :代表众数组频数—众数组后一组频数2、中位数:是一组数据按顺序排序后,处于中间位置上的变量值。
中位数位置21+=n 分组向上累计公式:e e e e m m m m e d f S f L M ⋅-∑+=-12 e m L 代表中位数组下限; 1-e m S :代表中位数所在组之前各组的累计频数;e mf 代表中位数组频数; e m d 代表组距3、四分位数:也称四分位点,它是通过三个点将全部数据等分为四部分,其中每部分包含25%,处在25%和75%分位点上的数值就是四分位数。
其公式为:411+=n Q 212+=n Q (中位数) 4)1(33+=n Q 实例数据总量: 7, 15, 36, 39, 40, 41一共6项Q1 的位置=(6+1)/4=1.75 Q2 的位置=(6+1)/2=3.5 Q3的位置=3(6+1)/4=5.25 Q1 = 7+(15-7)×(1.75-1)=13,Q2 = 36+(39-36)×(3.5-3)=37.5,Q3 = 40+(41-40)×(5.25-5)=40.25数值平均数计算公式1、简单算术平均数:是将总体单位的某一数量标志值之和除以总体单位。
其公式为:n x n x x x X n ∑=⋯⋯++=212、加权算术平均数:受各组组中值及各组变量值出现的频数(即权数f )大小的影响,其公式为:fxf f f f f x f x f x X i i i ∑∑=⋯⋯++⋯⋯++=2122113、加权算术平均数的频率: 其公式为:f f X f f X f f X f f X X n ∑⋅∑=∑∑⋯⋯+∑+∑=22114、调和平均数:由于只掌握每组某个标志的数值总和(M )而缺少总体单位数(f )的资料,不能直接采用加权算术平均数法计算平均数,则应采用加权调和平均数。
其公式为:x m m H ∑∑=5、简单几何平均数:就是n 个变量值(Xn )连乘积的n 次方根: 其公式为:n n n X X X X X G ∏=⋯⋯⋅⋅=3216、加权几何平均数:如果变量值较多,其出现的次数不同,则应采用加权几何平均数, 其公式为:f ff f f f n f f X X X X G n n ∑⋯⋯++∏=⋯⋯⋅=212121标志变异绝对指标及成数计算公式一、标志变异绝对指标:1、异众比率(又称离异比率或变差比,它是指非众数组的频数占总频数的比率): 公式即,im i m i r f f f f f V ∑-=∑-∑=1 2、极差(也称全距,它是一组数据的最大值与最小值这差公式即:min max X X R -=3、平均差(总体各单位标志值对算数平均数的绝对离差的算术平均数,平均差是反映各标志值对平均数的平均距离,平均差越大,说明总体各标志值越分散,平均差越小,说明各标志值越集中),公式即为:(未分组情况)n xx D A -∑=. (分组情况):f fx x D A ∑-∑=·.4、方差和标准差:方差(是各变量值与其均值离差平方的平均数),公式即为:(未分组情况)n x x 22)(-∑=σ (分组情况):f f x x ∑-∑=·)(22σ标准差(方差的平方根),公式即为:(未分组情况)n x x 2)(-∑=σ (分组情况):f f x x ∑-∑=·)(2σ 方差的数学性质:变量的方差等于变量平方的平均数减去变量平均数的平方。
方差的简便算法:方差=平方的平均数-平均数的平方 平方的平均数表示为:n x 2∑ 平均数的平方表示为:2⎪⎭⎫ ⎝⎛∑n x 方差简便算法的公式即为:222)(x x -=σ 二、是非标志的平均数、方差、标准差:是非标志:将总体分成具有某种性质和不具有某种性质的两部分,我们所关心的标志表现称为“是”,另一标志标现称为“非”。
例如:产品分为合格与不合格品。
成数:总体中,是非标志只有两种表现,我们把具有某种表现和不具有某种表现的单位占全部总体单位的比重称为成数。
具有某种性质的成数用(p )表示,不具有某种性质的用(q )表示。
p+q=1。
[成数的平均数(均值)就是成数本身]成数方差:)1(2p p -=σ 成数标准差:p p -=1(σ抽样平均误差、极限误差计算公式1、抽样平均误差:反映所有的样本平均数与总体平均数的平均误差,用x σ表示。
平均数公式: 重置抽样公式为:nM x x σμσ=-∑=2)( 其中σ表示总体标准差,n 表示样本容量,M 为样本个数。
不重抽样公式为:1·)(2--=-∑=N n N n M x x σμσ 其中N 为总体单位数。
成数公式:重置抽样公式为:n P P P )1(-=σ 不重置抽样公式为:1)1(--⋅-=N n N n P P P σ 2、极限误差:样本统计量与被估计的总体参数的离差的绝对值所容许的最大值,又称边际误差,用∆来表示。
x X x ∆≤- p P p ∆≤- x z σ∆=,用文字表述为:概度率=抽样极限误差÷抽样平均误差。
概率保证程度用()z F 表示,又叫置信度或置信水平,它是z 的函数。
3、计算题步骤:第一套:()z F 求∆1、抽样 计算 区间估计⇒x()x x S σ⇒2、根据:()z F 查表z 3、计算:x z σ⋅=∆,写出x :()∆+∆-x ,x 4、成数计算步骤: 第一套:()z F 求∆ 1、抽样 计算 区间估计⇒P ()p x S σ⇒ 2、根据:()z F 查表z 3、计算:p pz σ⋅=∆写出(P p ,P P ∆+∆-) 样本容量、相关系数、估计标准误差一、样本容量的确定1、平均数:重复抽样下样本容量222∆=σz n ;不重复抽样下样本容量22222)1(σσz N Nz n +∆-= 2、成数:重复抽样下样本容量22)1(p p p z n ∆-⋅=;不重复抽样下样本容量)1()1()1(222p p z N p p Nz n p -⋅+∆--⋅=二、相关系数:在线性条件下说明两个变量之间相关关系密切程度的统计分析指标。
公式1:2222)()())(()()())((y y x x y y x x y y x x y y x x r -∑⋅-∑--∑=-∑⋅-∑--∑= 公式2:()()2222y y n x x n y x xy n r ∑-∑⋅∑-∑∑⋅∑-∑= 公式3:yx y x xy r σσ⋅⋅-= 三、一元线性回归分析:只涉及一个自变量时称为一元回归。
1、估计回归方程可表示为:x b b y 10+=,其中0b 是估计的回归直线在y 轴上的截距,是当x =0时的期望值;1b 是直线的斜率,称为第二套:∆求()z F 1、抽样 计算 区间估计⇒x ()x x S σ⇒ 2、根据:x z σ∆= 查表 ()z F 3、由x 和∆,写出()∆+∆-x ,x第二套:∆求()z F1、抽样 计算 区间估计⇒P()p x S σ⇒2、根据:P P z σ∆= 查表 ()z F3、由P 和p ∆,写出(P p ,P P ∆+∆-)回归系数,表示当x 每变动一个单位时y 的值平均变动。
2、最小二乘法(残差平方和最小)221)())((x x n y x xy n b ∑-∑∑∑-∑= x b y b 10-= 2221)()())((x x n y x xy n x x y y x x b ∑-∑∑⋅∑-∑=-∑--∑= n x b n y b ∑-∑=10三、回归直线的似合程度1、判定系数(可决系数):等于相关系数的平方。
2222212)()(y y n x x n b r ∑-∑∑-∑⋅=2、估计标准误差:实际观察值与回归估计值离差平方和的均方根反映实际观察值在回归直线周围的分散状况从另一个角度说明了回归直线的拟合程度 计算公式为22)ˆ(1022-∑-∑-∑=--∑=n xy b y b y n y y S y 四、利用回归方程式进行估计1、点估计:对于自变量 x 的一个给定值x 0 ,根据回归方程得到因变量 y 的一个估计值根据回归方程:x b b y 10+=得出y 的估计值。
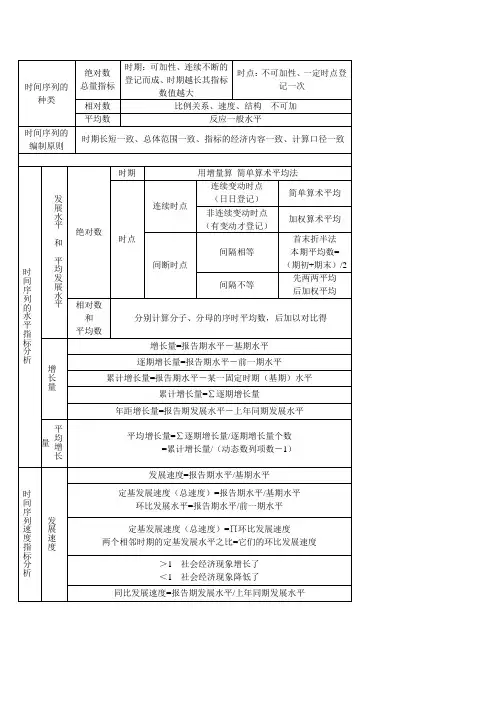
时间序列的分析指标1、绝对数时间序列的计算:(用算术平均数计算) ①、时期序列的序时平均数:n y y y y yn /21∑=⋯⋯++= ②、时点序列的序时平均数: 连续时点:连续每天资料不同:n y y /∑= 持续天内资料不变:t yt y ∑∑=/间断时点:间隔时间相等序时平均数的计算(首末折半):12121121-++⋯⋯++=-n y y y y y n n间断时点:间隔不相等序时平均数的计算:tt y y t y y t y y y n n n ∑++⋯⋯++++=--11232121)2()2()2( 2、绝对数或平均数时间序列的序时平均数:应先分别求出构成相对数或平均数的分子和分母的平均数,而后再进行对比(先平均,再对比):b a y /=3、增长量:增长量=报告期水平-基期水平。
逐期增长量:是报告期水平与前一期水平之差,表示本期比前一期增长的绝对数量累积增长量:是报告期水平与某一固定时期水平之差,说明报告期与某一固定期增长的绝 逐期增长量与累积增长量之间存在一定的关系:各逐期增长量的和等于相应时期的累积增长量;两相邻时期累积增长量之差等相应时期的逐期增长量。
4、平均增长量: n y y n y y y n i i 01)(-=-∑=∆-(n 为逐期增长量个数,它是观察数量的个数减1)平均增长量=逐期增长量之和/逐期增长量个数=累积增长量/观察期数。
5、发展速度:发展速度=报告期水平/基期水平环比发展速度:是报告期发展水平与前一水平之比,说明现象逐期发展变化的程度定基发展速度:是报告期发展水平与某一固定时期水平之比,说明现象整个观察期内总的发展变化程度。
以上两种发展速度之间存在着一定的数量:各个环比发展速度的连乘积等于最末期的定基发展速度;两个相邻的定基发展速度之比等于相应的各期环比发展速度。
6、增长速度:增长速度=增长量/基期水平=报告期水平-基期水平/基期水平=发展速度-1 环比增长速度:1//111-=-=---i i i i i i y y y y y G (i=1,2…n )定基增长速度:1//000-=-=y y y y y G i i i (i=1,2…n )环比增长速度与定基增长速度之间没有直接关系:若由环比增长速度推算定基增长速度,可先将各环比增长速度加1后连乘,再将结果减1,即得定期增长速度。