统计学各章计算题公式及解题方法
- 格式:doc
- 大小:663.00 KB
- 文档页数:14

统计分组 1、组中值:组中值=(上限+下限)/2缺下限组的组中值=该组上限-邻组组距/2 缺上限组的组中值=该组下限+邻组组距/2 2、众数出现最多的数d ΔΔΔL M 211o ⨯++=3、中位数从小排到大,中间的那个数4、平均数5、几何平均数6、标准差例题:计算下题中的中位数、众数、平均值、标准差n πx nx n ...x 2x 1G =••=Σf f 2)x Σ(x σn 2)x Σ(x σ:标准差;(已分组资料)Σff2)x Σ(x 2σ:方差的加权式;(未分组资料)n 2)x Σ(x 2σ:方差的简单式-=-=-=-=1)△1=50-30=20 △2=50-40=10 △1+△2=30 众数=10+(20/30)*2=11.33 2)中位数∑f/2=144/2=72 S m-1=45 fm=50 ∑f/2 - Sm-1=72-45=27 Me= 10+27/50*2=11.083)平均数=∑xi*fi/∑fi=1580/144≈11 4)标准差=2.15第4章1、区间估计最后推断的公式:2、两个理论:大数定律、中心极限定理3、四种抽样组织形式:随机抽样、等距抽样、分类抽样、整群抽样第五章1、相关关系:完全正相关(值为1)、完全负相关(值为-1)、部分正相关(0,1),部分负相关(-1,0),不相关(值为0)2、相关系数:取值范围是在[-1,1]区间3、回归分析:x x p p x t X x t p t P p t μμμμ-≤≤+-≤≤+()()2222∑∑∑∑∑∑∑---=y y n x x n yx xy n γΣf f 2)x Σ(x σ-=144644=基本形式:y=a+bx4、估计标准误差的计算估计标准误差指标是用来说明回归方程代表性大小的统计分析指标,也简称为估计标准差或估计标准误差,其计算原理与标准差基本相同。
估计标准误差说明理论值(回归直线)的代表性。
若估计标准误差小,说明回归方程准确性高,代表性大;反之,估计不够准确,代表性小。

百度文库-让每个人平等地提升自我统计学各章计算题公式及解题方法第四章数据的概括性度量组距式数值型数据众数的计算:确定众数组后代入公式计算:,其中,L 为众数所在组次数与后一组次数之差,d 为众数所在组组距单变量数列的中位数:先计算各组的累积次数(或累积频率)一根据位置公式确定中位 数所在的组一对照累积次数(或累积频率)确定中位数(该公式假定中位数组的频数在 该组内均匀分布)组距式数列的中位数计算公式:1. 2.3.4. 5.6. 7. 8.9. 10. 11.12. 13. 14.下限公式:Mo 土丄+ 爲;x 氐上限公式: 叫土 “下限,U 为众数所在组上限,A 1为众数所在组次数与前一组次数之差,为众数所在组未分组数据中位数计算公式:下限公式: 叭十毛2上限公式:M e = U-■W + L ■-x ci ,其中,在组的频数, 为中位数所在组前一组的累积频数,抵咛:||为中位数所在组后一组的累积频数四分位数位置的确定:未分组数据:下四分位数:<?! = —c 帥 * I ) I 上四分位数:Qv =XX| +JTj + ... + jf nIn加权均值:- * ,-I,几何均值 (用于计算平均发展速度).工二屮1 X 引其…X 為1 - 四分位差 (用于衡量中位数的代表性)异众比率 (用于衡量众数的代表性)极差:未分组数据:R = rnax (Xl ) - ;组距分组数据:R 土 :ft 高组上阴-最-低姐下眦 平均差(离散程度):未分组数据: ,-丄一组距分组数据: 叭-总体方差:未分组数据: ;分组数据:中位数位置的确定:未分组数据为;组距分组数据为T (甞卜仇为奇数.+巴+ J 八为喝数为中位数所;组距分组数据:简单均值: 值为各组组中:Q 。
= Qu - Q L其中叫%•松1. 的估计值: 置信水平aa 2Za290%95%99%2.不同情况下总体均值的区间估计:总体分布样本量b 已知b 未知正态分布大样本(n > 30)tJX +S工土 Za-^小样本(n<30)(TX + Za —S 工 土 f41—^1捕非正态分布 大样本(n > 30)(TX + Za —S工土 ?«--其中,•查p448,查找时需查n-1的数值3. 大样本总体比例的区间估计:4. 总体方差 在.,置信水平下的置信区间为:5. 估计总体均值的样本量:门二 駕竺,其中,第八章假设检验1.总体均值的检验(已知或卜T 未知的大样本)[总体服从正态分布,不服从正态分布的用正态分布近似]假设 双侧检验左侧检验右侧检验假设形式H Q : P =他1、阿:P 工颅\/ “1 : H旳:统计量。

集中趋势测定:一、众位数L为众数组的下限,U为上限;d为众数组的组距;△1=fm-fm-1,即众数组的次数与下一组(或前一组)次数之差;△2=fm -fm+1,即众数组的次数与上一组次数之差二、中位数式中:L为中位数所在组的下限,U为上限;d为中位数所在组的组距;Sm-1 为中位数所在组以下各组(或小于中位数的各组)次数之和;Sm+1为中位数所在组以上各组(或大于中位数的各组)次数之和;fm为中位数所在组的次数。
三、算术平均数1、简单算术平均数2、加权算术平均数A、绝对权数(次数)⇒ fB、相对权数(频率或比重)⇒ f/∑f⎪⎪⎩⎪⎪⎨⎧⇒⨯+-=⇒⨯++=上限公式dΔΔΔUM下限公式dΔΔΔLM212o211o⎪⎪⎪⎩⎪⎪⎪⎨⎧→⨯+--=→⨯--+=⇒=上限公式dm f1mS2ΣfUeM下限公式dm f1mS2ΣfLeM2Σf中位四、几何平均数离散程度的测定 极差全距是数列中的最大值与最小值之差。
全距(R)=最大值—最小值平均差平均差是各数据值与其算术平均数之差绝对值的算术平均数。
常用“M ·D ”表示(一)根据未分组资料计算(简单算术平均差)(二)根据分组资料计算(加权算术平均差)方差和标准差⎩⎨⎧⇔⇔⇔⇔=的代表性越大x 数据越集中R越小的代表性越小x 数据越分散R越大x x 当21nxx ΣD M -=⋅⎩⎨⎧→→→→→→=的代表性越大x 数据越整齐平均离差越小A.D越小的代表性越小x 数据越分散平均离差越大A.D越大x x 21Σff2)x Σ(x σn2)x Σ(x σ:标准差;(已分组资料)Σff2)x Σ(x 2σ:方差的加权式;(未分组资料)n2)x Σ(x 2σ:方差的简单式-=-=-=-=抽样平均误差计算总体平均数的抽样平均误差 (1)不重置抽样条件下(2)重置抽样条件下总体成数的抽样平均误差 (1) 不重置抽样条件下(2)重置抽样条件下抽样极限误差计算:1. 总体平均数的抽样极限误差2.总体成数的抽样极限误差100%xσV :标准差系数100%xM.DV :平均差系数σA.D ⨯=⨯=)1N n N (n σ2μx --=nσμx=)1N nN (n p)p(1μp ---=np)p(1μp -=μxxt=∆μppt=∆1、 总体平均数的区间估计:2、总体成数的区间估计:样本容量的确定总体平均数估计的样本容量的确定 重置抽样:不重置抽样 :总体成数估计的样本容量的确定 重置抽样:不重置抽样 :∆∆+-xx x x ,∆∆+-pp p p ,相关系数 判定标准:• 0.3以下,微弱线性相关 • 0.3~0.5,低度线性相关 • 0.5~0.8,显著线性相关 • 0.8以上,高度线性相关 计算公式:⎪⎩⎪⎨⎧→→→=y的标准差x,y σx σy的协方差x,xy σ为x与y的相关系数y σx σxyσ2r 2)y Σ(y 2)x Σ(x )y )(y x Σ(x n2)y Σ(y n2)x Σ(x n )y )(y x Σ(x r ----=----=yyxx xy L L L =2)y Σ(y 2)x Σ(x )y )(y x Σ(x yσx σxy σr ----==n2(Σy)2Σy n2(Σx)2Σx n ΣxΣy Σxy ---=2(Σy)2nΣy 2(Σx)2nΣx ΣxΣynΣxy ---=n2(Σy)2Σy n2(Σx)2Σxn )n ΣxΣy n(Σxy ---=2y 2y 2x 2x y x xy --⋅-=yσx σy x xy ⋅-=回归分析的方法 一元线性回归分析 方程式: 线性回归模型参数估计值计算公式:估计标准误差 计算: 平均发展水平间隔不等的时点数列Σf )f a (a 21Σa 公式i1i i ++=→平均发展水平计算bxa y +=n 2(Σx)2ΣxnΣxΣy Σxy b--=2(Σx)2nΣx ΣxΣy nΣxy --=xb y nΣx b nΣy a -=⋅-=n-2xyy-b a y2s ∑∑∑-=nΣa a :计算公式=⇒nΣa a 时期数列=→⎪⎪⎪⎪⎪⎩⎪⎪⎪⎪⎪⎨⎧⎪⎪⎪⎩⎪⎪⎪⎨⎧⎩⎨⎧++=→-+++=→=Σfi)f 1i a i Σ(a 21a 间隔不等1n n a 212a 1a 21a 间隔相等时点数列nΣa a 连续时点数列时点数列(1)∏环比发展速度=定基发展速度。
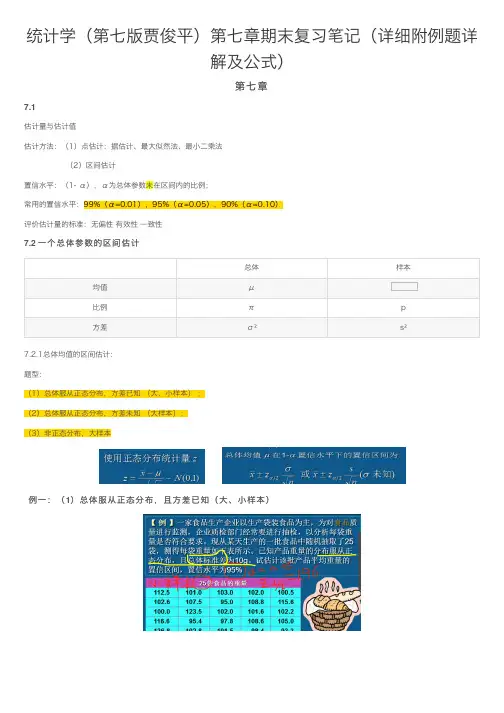
统计学(第七版贾俊平)第七章期末复习笔记(详细附例题详解及公式)第七章7.1估计量与估计值估计⽅法:(1)点估计:据估计、最⼤似然法、最⼩⼆乘法(2)区间估计置信⽔平:(1- α),α为总体参数未在区间内的⽐例;常⽤的置信⽔平:99%(α=0.01),95%(α=0.05),90%(α=0.10)评价估计量的标准:⽆偏性 有效性 ⼀致性7.2 ⼀个总体参数的区间估计7.2.1总体均值的区间估计:题型:(1)总体服从正态分布,⽅差已知 (⼤、⼩样本) ;(2)总体服从正态分布,⽅差未知 (⼤样本);(3)⾮正态分布,⼤样本例⼀:(1)总体服从正态分布,且⽅差已知(⼤、⼩样本)例⼆:(3)⾮正态分布,⼤样本(n>=30)题型:(4)总体服从正态分布 ,但⽅差未知,⼩样本(n<30)例三:(4)总体服从正态分布 ,但⽅差未知,⼩样本(n<30)总结:7.2.2 总体⽐例的区间估计题型:总体服从⼆项分布,可由正态分布来近似(只讨论⼤样本)例四:7.2.3 总体⽅差的区间估计题型:估计⼀个总体的⽅差或标准差(只讨论正态总体)例五:⼩结:7.3 两个总体参数的区间估计7.3.1 两个总体均值之差的区间估计(2)⾮正态分布,但两个总体都是⼤样本;例⼀:(3)例⼀:(1)例⼆: (2)题型:(1)两个匹配的⼤样本;(2)两个匹配的⼩样本例⼀:(2)7.3.2 两个总体⽐例之差的区间估计题型:两个总体服从⼆项分布,样本独⽴例⼀:7.3.3 两个总体⽅差⽐的区间估计题型:求两个总体的⽅差⽐例⼀:7.4 样本量的确定7.4.1 估计总体均值时的样本量的确定例⼀:7.4.2 估计总体⽐例时的样本量的确定例⼀:。

平均数基本公式: 一、总体单位总量总体标志总量算术平均数=(调和平均数)简单算术平均: nx x ∑=加权算术平均: ∑∑=fxf x 或 ∑∑=ffxx二、调和平均数: 简单调和平均: ∑=xn H 1 加权调和平均: ∑∑=xm m H三、几何平均数: 简单:nx G ∏= 加权: ∑∏=ff x G四、众数:下限: d L M O 211∆+∆∆+= 上限:d U M O 212∆+∆∆-=五、中位数:下限: d f S fL M mm e 12--+=∑ 上限:d f S fU M mm e 12+--=∑中位数的位次: M e 2∑=f标志变异指标:标准差: 简单: nx x ∑-=2)(σ 加权:∑∑-=ffx x 2)(σ方差: 简单: nx x ∑-=22)(σ加权: ∑∑-=ffx x 22)(σ成数: N N p 1=NN q 0= 1=+p q交替标志: 平均数:p x = 标准差: )1(p p p -=σ标准差系数: %100⨯=xV σσ分析计算题:1、星河公司2009年四个季度的销售利润率分别是12%、11%、13%和10%,同期的销售额分别是1000万元、1200万元、1250万元和1000万元。
友谊公司同期的销售利润率分别是13%、11%、10%和12%,利润额分别是130万元、132万元、120万元和144万元,试通过计算比较两家公司2009年全年销售利润率的高低。
2、课本 P 93 17题动态分析指标:一、平均发展水平: 总量指标时间数列:1、时期数列:na a ∑=2、时点数列:连续型: 等间隔:na a ∑= 不等间隔:∑∑=ffa a不连续型: 等间隔: na a a a a n n 22110++⋅⋅⋅++=-不等间隔: 12111232121222---+⋅⋅⋅++++⋅⋅⋅++++=n n n n f f f f a a f a a f a a a相对指标时间数列: ba c =平均指标时间数列: 同上二、增长量: 逐期增长量: 01a a -12a a - 23a a -… 1--n n a a 累计增长量: 01a a -02a a -03a a -…0a a n -平均增长量1)1()()()(011201-+-=-+⋅⋅⋅+-+-=-n a a n a a a a a a n n n三、发展速度: 环比发展速度:01a a 12a a 23a a …1-n n a a 定基发展速度:1a a2a a3a a …a a n两者之间关系: 1、112010-⨯⨯⨯=n n n a a a a a a a a 2、110--=n n n na a a a a a平均发展速度: n x x ∏=nn a a x 0= n R x =长期趋势测定方法:(时间数列变动分析)方程法:根据时间数列的数据特征,建立一个合适的趋势方程来描述时间数列的趋势变动,推算或预测个时期的趋势值。

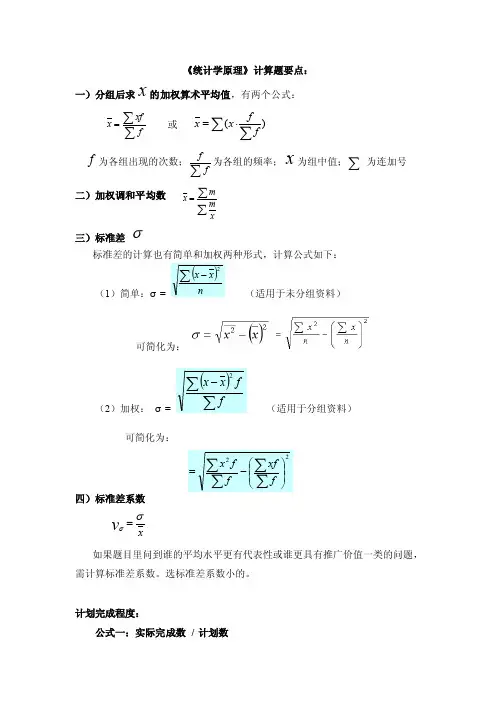
《统计学原理》计算题要点:一)分组后求x 的加权算术平均值,有两个公式:∑∑=fxf x 或 )(∑∑⋅=ffx xf为各组出现的次数;∑ff为各组的频率;x 为组中值;∑为连加号二)加权调和平均数 ∑∑=xm m x 三)标准差σ标准差的计算也有简单和加权两种形式,计算公式如下:(1)简单:σ=(适用于未分组资料)可简化为:(2)加权: σ= (适用于分组资料)可简化为:四)标准差系数x v σσ=如果题目里问到谁的平均水平更有代表性或谁更具有推广价值一类的问题,需计算标准差系数。
选标准差系数小的。
计划完成程度:公式一:实际完成数 / 计划数公式二: 实际完成的上期百分数 / 计划的上期百分数五)总体参数的两种区间估计方法 (以平均数X的估计为例。
若是估计成数P ,则只有σ的计算公式改为)1(p p -,其他公式和方法是相同的。
)(一)给定抽样误差范围(即极限误差)x ∆,求置信区间和置信度。
(1)计算样本均值x ;(2)计算样本标准差σ(3)求抽样平均误差:重复抽样: nx σμ=不重复抽样:)1(2--=N nN n x σμ当N很大时可近似为:)1(2N nn x -=σμ(4)置信区间为:),(x x x x ∆+∆-(5)概率度为:xxz μ∆=,查表得)(Z F 的值,置信度为)(Z F(二)给定置信度,求置信区间和抽样极限误差的可能范围。
(1)计算样本均值x ;(2)计算样本标准差σ(3)求抽样平均误差:重复抽样: nx σμ=不重复抽样:)1(2--=N nN n x σμ当N很大时可近似为:)1(2N n n x -=σμ(4)由已知的置信度)(Z F ,得对应的概率度Z抽样极限误差为x x Z μ⋅=∆ (5)置信区间为:),(x x x x ∆+∆-六)样本单位数的计算方法:抽样平均数 抽样成数重复抽样:七)相关系数r0.8 ~ 1, 高度相关; 0.5 ~ 0.8 显著相关八) 线性回归方程式为:yc =a+bx注: (1)(2)回归系数b 的涵义是:当自变量x每增加一个单位时,因变量y的平均增加值。
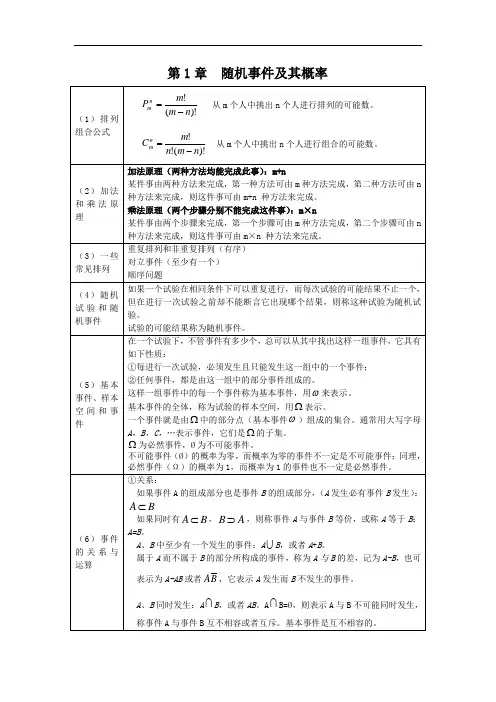


一、基本概率公式及分布1、概率常用公式:P(A+B)=P(A)+P(B)-P(AB);P(A-B)=P(A)-P(AB);如A 、B 独立,则P(AB)=P(A)P(B);P(A )=1-P(A);B 发生的前提下A 发生的概率==条件概率:P(A|B)=P(AB)P(B);或记:P(AB)=P(A|B)*P(B);2、随机变量分布律、分布函数、概率密度分布律:离散型X 的取值是x k (k=1,2,3...),事件X=x k 的概率为:P{X=x k }=P k ,k=1,2,3...;---既X 的分布律;X X1X2....xn PkP1P2...pnX 的分布律也可以是上面的表格形式,二者都可以。
分布函数:F(x)=P{X ≤x},-∞ t ∞;是概率的累积!P(x1<X<x2)=F(x2)-F(x1);P{X>a}=1-P{X<a}离散型rv X;F(x)=P{X ≤x}=x k tp k ;(把X<x 的概率累加)连续型rvX ;F(x)=−∞xf x dx ,f(x)称密度函数;既分布函数F(X)是密度函数f(x)和X 轴上的(-∞,x)围成的面积!性质:F(∞)=1;F(−∞)=0;二、常用概率分布:①离散:二项分布:事件发生的概率为p,重复实验n次,发生k 次的概率(如打靶、投篮等),记为B(n,p)P{X=k}=n k p k(1−p)n−k,k=0,1,2,...n;E(X)=np,D(X)=np(1-p);②离散:泊松分布:X~Π(λ)P{X=k}=λk e−λk!,k=0,1,2,...;E(X)=λ,D(X)=λ;③连续型:均匀分布:X在(a,b)上均匀分布,X~U(a,b),则:密度函数:f(x)=1b−a,a t0,其它=0,x x−a b−a1,x≥b,a t分布函数F(x)=−∞x f x dx④连续型:指数分布,参数为θ,f(x)=1θe−xθ,0 t0,其它F(x)=1−e−xθ0,x 0;⑤连续型:正态分布:X~N(μ,σ2),most importment!密度函数f(x),表达式不用记!一定要记住对称轴x=µ,E(X)=µ,方差D(X)=σ2;当µ=0,σ2=1时,N(0,1)称标准正态,图形为:分布函数F(x)为密度函数f(x)从(-∞,x)围成的面积。

精品文档《统计学原理》常用公式汇总及计算题目分析第一部分常用公式第三章统计整理a)组距=上限-下限b)组中值=(上限+下限)÷2c)缺下限开口组组中值=上限-1/2邻组组距d)缺上限开口组组中值=下限+1/2邻组组距第四章综合指标i.相对指标1.结构相对指标=各组(或部分)总量/总体总量2.比例相对指标=总体中某一部分数值/总体中另一部分数值3.比较相对指标=甲单位某指标值/乙单位同类指标值4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象总量指标5.计划完成程度相对指标=实际数/计划数=实际完成程度(%)/计划规定的完成程度(%)ii.平均指标精品文档.精品文档简单算术平均数:1.2.加权算术平均数或iii.变异指标1.全距=最大标志值-最小标志值 = : 简单σ加权= ;σ2.标准差 :3.标准差系数抽样估计第五章1.平均误差:重复抽样:不重复抽样:抽样极限误差2.3.重复抽样条件下:平均数抽样时必要的样本数目精品文档.精品文档成数抽样时必要的样本数目4.不重复抽样条件下:平均数抽样时必要的样本数目第七章相关分析相关系数1.y=a+bx配合回归方程2.3.估计标准误:第八章指数分数一、综合指数的计算与分析数量指标指数(1)精品文档.精品文档此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。
)(-此差额说明由于数量指标的变动对价值量指标影响的绝对额。
质量指标指数(2)此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。
-()此差额说明由于质量指标的变动对价值量指标影响的绝对额。
=加权算术平均数指数加权调和平均数指数=复杂现象总体总量指标变动的因素分析(3) 相对数变动分析:×= 绝对值变动分析:精品文档.精品文档)×(-)= (--第九章动态数列分析一、平均发展水平的计算方法:由总量指标动态数列计算序时平均数(1)①由时期数列计算②由时点数列计算在间断时点数列的条件下计算: a.若间断的间隔相等,则采用“首末折半法”计算。
回归方程统计指数参数估计示例详解一、组限和组中值1 当两组间的相邻组限重合时:组距=本组上限—本组下限 组中值=(上限+下限)/ 2或=下限+组距 / 2 或=上限—组距 / 22当两组间的相邻组限不重合时:组距=下组下限—本组下限或=本组上限—上组上限组中值=(本组下限+下组下限)/ 2或=本组下限+组距 / 2 或=下组下限—组距 / 23 组距式分组中的“开口”情况:组中值=上限—邻组组距 / 2或=下限+邻组组距 / 2一、相对指标的种类和计算方法(一)计划完成相对数1计划完成相对数的基本计算公式: 计划完成相对数=计划完成数实际完成数* 100%例:某公司计划20XX 年销售收入500万元,实际的销售收入552万元。
则:计划完成相对数=500552* 100% = 110.4%2计划完成相对数的派生公式:(1)对于产量、产值增长百分数: 计划完成相对数=%%100%%100计划增长实际增长++ * 100%(2)对于产品成本降低百分数: 计划完成相对数=%%100%%100计划增长实际增长—— * 100%例:某企业20XX 年规定产值计划比上年增长8%,计划生产成本比上年降低5%,产值实际比上年提高10%,生产成本实际比上年降低6%,试求该企业产值和成本计划完成相对数。
解:产值计划完成相对数=%8%100%10%100++ * 100% = 101.85%成本计划完成相对数=%5%100%6%100—— * 100% = 98.95%(3)计划执行进度相对数的计算方法: 计划执行进度=本期计划数成数计划期内某月止累计完 * 100%例:某公司20XX 年计划完成商品销售额1500万元,1—9月累计实际完成1125万元。
则:1—9月计划执行进度=15001125* 100% = 75%(二)结构相对数 结构相对数=总体数值总体某部分数值* 100%例:某地区20XX 年国内生产总值为1841.61亿元,其中第一产业增加值为88.88亿元,则: 第一产业增加值所占比重=1.618418.888 * 100% =4.83%(三)比例相对数 比例相对数=同一总体另一部分数值总体中某一部分数值* 100%例:某地区20XX 年国内生产总值为2106.96亿元,其中轻工业产值为1397.31亿元,重工业产值为709.65亿元,则:轻重工业比例=1397.31:709.65=1.97:1(四)比较相对数 比较相对数=标数值乙地区(单位)同一指数值甲地区(单位)某指标 * 100%(五)动态相对数 动态相对数=基期数值报告期数值* 100%例:某地区国内生产总值20XX 年为2097.77亿元,20XX 年为2383.07亿元。
《统计学原理》常用公式汇总及计算题目分析第一部分常用公式第三章统计整理a)组距=上限-下限b)组中值=(上限+下限)÷2c)缺下限开口组组中值=上限-1/2邻组组距d)缺上限开口组组中值=下限+1/2邻组组距第四章综合指标i.相对指标1.结构相对指标=各组(或部分)总量/总体总量2.比例相对指标=总体中某一部分数值/总体中另一部分数值3.比较相对指标=甲单位某指标值/乙单位同类指标值4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象总量指标5.计划完成程度相对指标=实际数/计划数=实际完成程度(%)/计划规定的完成程度(%)ii.平均指标1.简单算术平均数:2.加权算术平均数或iii.变异指标1.全距=最大标志值-最小标志值2.标准差: 简单σ= ;加权σ=3.标准差系数:第五章抽样估计1.平均误差:重复抽样:不重复抽样:2.抽样极限误差3.重复抽样条件下:平均数抽样时必要的样本数目成数抽样时必要的样本数目4.不重复抽样条件下:平均数抽样时必要的样本数目第七章相关分析1.相关系数2.配合回归方程y=a+bx3.估计标准误:第八章指数分数一、综合指数的计算与分析(1)数量指标指数此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。
(-)此差额说明由于数量指标的变动对价值量指标影响的绝对额。
(2)质量指标指数此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。
(-)此差额说明由于质量指标的变动对价值量指标影响的绝对额。
加权算术平均数指数=加权调和平均数指数=(3)复杂现象总体总量指标变动的因素分析相对数变动分析:= ×绝对值变动分析:-= (-)×(-)第九章动态数列分析一、平均发展水平的计算方法:(1)由总量指标动态数列计算序时平均数①由时期数列计算②由时点数列计算在间断时点数列的条件下计算:a.若间断的间隔相等,则采用“首末折半法”计算。
位值平均数计算公式1、众数:是一组数据中出现次数最多的变量值组距式分组下限公式:2110m m d L M ⋅∆+∆∆+= 0m L :代表众数组下限; 1100--=∆m m f f :代表众数组频数-众数组前一组频数0m d :代表组距; 1200+-=∆m m f f :代表众数组频数—众数组后一组频数2、中位数:是一组数据按顺序排序后,处于中间位置上的变量值.中位数位置21+=n 分组向上累计公式:e ee em m m m e d f S fL M ⋅-∑+=-12e m L 代表中位数组下限;1-e m S :代表中位数所在组之前各组的累计频数;e mf 代表中位数组频数; em d 代表组距3、四分位数:也称四分位点,它是通过三个点将全部数据等分为四部分,其中每部分包含25%,处在25%和75%分位点上的数值就是四分位数。
其公式为:411+=n Q 212+=n Q (中位数) 4)1(33+=n Q实例数据总量: 7, 15, 36, 39, 40, 41 一共6项Q1 的位置=(6+1)/4=1.75 Q2 的位置=(6+1)/2=3。
5 Q3的位置=3(6+1)/4=5。
25Q1 = 7+(15-7)×(1.75-1)=13,Q2 = 36+(39-36)×(3。
5-3)=37。
5,Q3 = 40+(41-40)×(5。
25—5)=40.25数值平均数计算公式1、简单算术平均数:是将总体单位的某一数量标志值之和除以总体单位。
其公式为:n x n x x x X n ∑=⋯⋯++=212、加权算术平均数:受各组组中值及各组变量值出现的频数(即权数f)大小的影响,其公式为:fxf f f f f x f x f x X i i i ∑∑=⋯⋯++⋯⋯++=2122113、加权算术平均数的频率:其公式为:ffX f f X f f X f f X X n ∑⋅∑=∑∑⋯⋯+∑+∑=22114、调和平均数:由于只掌握每组某个标志的数值总和(M )而缺少总体单位数(f)的资料,不能直接采用加权算术平均数法计算平均数,则应采用加权调和平均数.其公式为:xm m H ∑∑=5、简单几何平均数:就是n 个变量值(Xn)连乘积的n 次方根:其公式为:n n nX X X X X G ∏=⋯⋯⋅⋅=3216、加权几何平均数:如果变量值较多,其出现的次数不同,则应采用加权几何平均数,其公式为:fff f f f nf f XX X X G nn∑⋯⋯++∏=⋯⋯⋅=212121标志变异绝对指标及成数计算公式一、标志变异绝对指标:1、异众比率(又称离异比率或变差比,它是指非众数组的频数占总频数的比率):公式即,imi m i r f f f f f V ∑-=∑-∑=12、极差(也称全距,它是一组数据的最大值与最小值这差公式即:min max X X R-=3、平均差(总体各单位标志值对算数平均数的绝对离差的算术平均数,平均差是反映各标志值对平均数的平均距离,平均差越大,说明总体各标志值越分散,平均差越小,说明各标志值越集中),公式即为:(未分组情况)nx x DA -∑=. (分组情况):ff x x DA ∑-∑=·.4、方差和标准差:方差(是各变量值与其均值离差平方的平均数),公式即为:(未分组情况)nx x 22)(-∑=σ (分组情况):ff x x ∑-∑=·)(22σ标准差(方差的平方根),公式即为:(未分组情况)n x x 2)(-∑=σ (分组情况):ffx x ∑-∑=·)(2σ方差的数学性质:变量的方差等于变量平方的平均数减去变量平均数的平方。
1.组数:一般为5-152.确定组距:组距(Class Width)是一个组的上限与下限之差,可根据全部数据的最大值和最小值及所分的组数来确定,即组距=( 最大值 - 最小值)÷ 组数 3.统计出各组的频数并整理成频数分布表 下限(lower limit) :一个组的最小值 2. 上限(upper limit) :一个组的最大值 3. 组距(class width) :上限与下限之差4. 组中值(class midpoint) :下限与上限之间的中点值封闭式组距数列: a) 组距=上限-下限b) 组中值=(上限+下限)/2c) 缺下限开口组组中值=上限-1/2邻组组距 d) 缺上限开口组组中值=下限+1/2邻组组距样本平均数nf Mx ki ii∑==1总体用µ总体方差(标准差),记为s2(s);根据样本数据计算的,称为样本方差(标准差),记为s2(s)方差未分组1)(122--=∑=n x x s ni i分组 1)(122--=∑=n f x Ms ki ii经验法则表明:当一组数据对称分布时约有68%的数据在平均数加减1个标准差的范围之内约有95%的数据在平均数加减2个标准差的范围之内约有99%的数据在平均数加减3个标准差的范围之内切比雪夫不等式1.如果一组数据不是对称分布,经验法则就不再适用,这时可使用切比雪夫不等式,它对任何分布形状的数据都适用2.切比雪夫不等式提供的是“下界”,也就是“所占比例至少是多少”3.对于任意分布形态的数据,根据切比雪夫不等式,至少有1-1/k2的数据落在平均数加减k 个标准差之内。
其中k 是大于1的任意值,但不一定是整数 对于k=2,3,4,该不等式的含义是1.至少有75%的数据落在平均数加减2个标准差的范围之内2.至少有89%的数据落在平均数加减3个标准差的范围之内3.至少有94%的数据落在平均数加减4个标准差的范围之内离散系数 标准差与其相应的均值之比 计算公式为x s v s =统计量设X1,X2,…,Xn 是从总体X 中抽取的容量为n 的一个样本,如果由此样本构造一个函数T(X1,X2,…,Xn),不依赖于任何未知参数,则称函数T(X1,X2,…,Xn)是一个统计量样本均值、)1(~--=n t ns x t μ样本比例、样本方差等都是统计量 统计量是样本的一个函数统计量的分布称为抽样分布。
第三章 平均指标 题型1.计算平均指标(算术、调和、几何平均数)2.比较平均数代表性大小3、计算变异指标(主要是平均差、标准差, 变异系数的计算)ff iff nf f n n n i n x xx xG x x x x G ∑∑∏=⋅⋅⋅=∏=⋅⋅⋅= 212121::加权几何平均数简单几何平均数第四章 抽样估计1.区间估计(总体均值、总体成数区间估计以及总体总量指标的区间估计)2.样本容量的确定重复抽样的抽样平均误差 1.抽样平均数的平均误差 2.抽样成数的平均误差不重复抽样的平均误差 1.抽样平均数的平均误差:22xx -=σx AD n n x σσσ==2)(nP P p )1()(-=σ)1()(2Nnn x -=σσ2.抽样成数的平均误差:重复抽样 不重复抽样估计总体平均数估计总体成数或第七章相关和回归1.相关分析(相关系数的计算)2.一元线性回归模型的建立3.r 、b 含义及关系回归)1()1()(Nnn P P p --=σ)(2x Z x σα=∆p p x x p P p x X x ∆+≤≤∆-∆+≤≤∆-2220x t n ∆=σ22222σσt N Nt n x +∆=220)1(pp p t n ∆-=)1()1(222p p t N p p Nt n p -+∆-=N n n n 001+=2222)()(y y x x y x xy r -⋅--=⎪⎩⎪⎨⎧-=--=∑∑∑∑∑xb y a x x n y x xy n b 22)(xxxyL L x x n y x xy n b =--=∑∑∑∑∑22)(xyrb σσ=Np PN N p N x N X N x p p x x )()()()(∆+≤≤∆-∆+≤≤∆-)(2p Z p σα=∆第八章 时间数列 1.序时平均数的计算 2.长期趋势的测定3.水平指标和速度指标的结合(增长量、平均增长量、平均发展水平、发展速度、增长速度、平均发展速度、平均增长速度、增长1%的绝对值)间隔相等的时点数列 间隔不相等的时点数列相对数或平均数时间数列一般方法 N简捷法N第九章 指数1.综合指数计算和因素分析2.平均数指数计算和因素分析n a a ∑=→时期数列12111232121222---+++++++=n n n n f f f f a a f a f a ∑∑=1011qp q p K p ∑∑=01pq p q K q )(0010000001∑∑∑∑=⋅=q p q p q p q p q q K q )(101111111∑∑∑∑=⋅=qp q p pp q p qp K p。
1.组数:一般为5-152.确定组距:组距(Class Width)是一个组的上限与下限之差,可根据全部数据的最大值和最小值及所分的组数来确定,即组距=( 最大值 - 最小值)÷ 组数 3.统计出各组的频数并整理成频数分布表 下限(lower limit) :一个组的最小值 2. 上限(upper limit) :一个组的最大值 3. 组距(class width) :上限与下限之差4. 组中值(class midpoint) :下限与上限之间的中点值封闭式组距数列: a) 组距=上限-下限b) 组中值=(上限+下限)/2c) 缺下限开口组组中值=上限-1/2邻组组距 d) 缺上限开口组组中值=下限+1/2邻组组距样本平均数nf Mx ki ii∑==1总体用µ总体方差(标准差),记为s2(s);根据样本数据计算的,称为样本方差(标准差),记为s2(s)方差未分组1)(122--=∑=n x x s ni i分组 1)(122--=∑=n f x Ms ki ii经验法则表明:当一组数据对称分布时约有68%的数据在平均数加减1个标准差的范围之内约有95%的数据在平均数加减2个标准差的范围之内约有99%的数据在平均数加减3个标准差的范围之内切比雪夫不等式1.如果一组数据不是对称分布,经验法则就不再适用,这时可使用切比雪夫不等式,它对任何分布形状的数据都适用2.切比雪夫不等式提供的是“下界”,也就是“所占比例至少是多少”3.对于任意分布形态的数据,根据切比雪夫不等式,至少有1-1/k2的数据落在平均数加减k 个标准差之内。
其中k 是大于1的任意值,但不一定是整数 对于k=2,3,4,该不等式的含义是1.至少有75%的数据落在平均数加减2个标准差的范围之内2.至少有89%的数据落在平均数加减3个标准差的范围之内3.至少有94%的数据落在平均数加减4个标准差的范围之内离散系数 标准差与其相应的均值之比 计算公式为x s v s =统计量设X1,X2,…,Xn 是从总体X 中抽取的容量为n 的一个样本,如果由此样本构造一个函数T(X1,X2,…,Xn),不依赖于任何未知参数,则称函数T(X1,X2,…,Xn)是一个统计量样本均值、)1(~--=n t ns x t μ样本比例、样本方差等都是统计量 统计量是样本的一个函数统计量的分布称为抽样分布。
统计学各章计算题公式及解题方法第四章数据的概括性度量1.组距式数值型数据众数的计算:确定众数组后代入公式计算:下限公式:;上限公式:,其中,L为众数所在组下限,U为众数所在组上限,为众数所在组次数与前一组次数之差,为众数所在组次数与后一组次数之差,d为众数所在组组距2.中位数位置的确定:未分组数据为;组距分组数据为3.未分组数据中位数计算公式:4.单变量数列的中位数:先计算各组的累积次数(或累积频率)—根据位置公式确定中位数所在的组—对照累积次数(或累积频率)确定中位数(该公式假定中位数组的频数在该组内均匀分布)5.组距式数列的中位数计算公式:下限公式:;上限公式:,其中,为中位数所在组的频数,为中位数所在组前一组的累积频数,为中位数所在组后一组的累积频数6.四分位数位置的确定:未分组数据:;组距分组数据:7.简单均值:8.加权均值:,其中,为各组组中值9.几何均值(用于计算平均发展速度):10.四分位差(用于衡量中位数的代表性):11.异众比率(用于衡量众数的代表性):统计学各章计算题公式及解题方法:12.极差:未分组数据:;组距分组数据13.平均差(离散程度):未分组数据:;组距分组数据:14.总体方差:未分组数据:;分组数据:15.总体标准差:未分组数据:;分组数据:16.样本方差:未分组数据:;分组数据:17.样本标准差:未分组数据:;分组数据:18.标准分数:19.离散系数:第七章参数估计1.的估计值:置信水平α90% 0.1 0.05 1.65495% 0.05 0.025 1.9699% 0.01 0.005 2.582.不同情况下总体均值的区间估计:总体分布样本量σ已知σ未知大样本(n≥30)正态分布小样本(n<30)统计学各章计算题公式及解题方法非正态分布大样本(n≥30)其中,查p448 ,查找时需查n-1的数值3.大样本总体比例的区间估计:4.总体方差在置信水平下的置信区间为:5.估计总体均值的样本量:,其中,E为估计误差6.重复抽样或无限总体抽样条件下的样本量:,其中π为总体比例第八章假设检验1.总体均值的检验(已知或未知的大样本)[总体服从正态分布,不服从正态分布的用正态分布近似]假设双侧检验左侧检验右侧检验假设形式统计量已知未知拒绝域值决策,拒绝2.总体均值检验(未知,小样本,总体正态分布)假设双侧检验左侧检验右侧检验假设形式统计学各章计算题公式及解题方法统计量已知未知拒绝域值决策,拒绝注:已知的拒绝域同大样本3.一个总体比例的检验(两类结果,总体服从二项分布,可用正态分布近似)(其中为假设的总体比例)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝4.总体方差的检验(检验)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝统计学各章计算题公式及解题方法5.统计量的参考数值0.1 0.05 0.01双侧检验 1.65 1.96 2.58单侧检验 1.28 2.65 2.33第九章列联分析1.期望频数的分布(假定行变量和列变量是独立的)一个实际频数的期望频数,是总频数的个数乘以该实际频数落入第行和第j列的概率,即:2.统计量(用于检验列联表中变量间拟合优度和独立性;用于测定两个分类变量之间的相关程度,为列联表中第i行第j 列的实际频数,为列联表中第i行第j列的期望频数1)检验多个比例是否相等检验的步骤提出假设H0:π1 = π2= … = πj;H1:π1,π2,…,πj不全相等;计算检验的统计量;进行决策:根据显著性水平和自由度(r-1)(c-1)查出临界值,若2>,拒绝H0;若2<,不拒绝H2)利用样本数据检验总体比例是否等于某个数值检验的步骤提出假设H0:π1 = ,π2 = ,… ;H1:原假设的等式中至少有一个不成立;计算检验的统计量;进行决:根据显著性水平和自由度(r-1)(c-1)查出临界值2;若2>,拒绝H0;若2<,不拒绝H3)检验列联表中的行变量与列变量之间是否独立检验的步骤提出假设H0:行变量与列变量独立;H1:行变量与列变量不独立;计算检验的统计量;进行决策:根据显著性水平和自由度(r-1)(c-1)查出临界值,若2,拒绝H0;若2<,不拒绝H03.ϕ相关系数:测度2⨯2列联表中数据相关程度;对于2⨯2 列联表,ϕ系数的值在0~1之间统计学各章计算题公式及解题方法,其中,n为实际频数总个数,即样本容量4.列联相关系数(C系数)用于测度大于2 2列联表中数据的相关程度,其中,C的取值范围是 0C<1;C= 0表明列联表中的两个变量独立;C的数值大小取决于列联表的行数和列数,并随行数和列数的增大而增大;根据不同行和列的列联表计算的列联系数不便于比较5.V相关系数,其中,V 的取值范围是 0≤V≤1; V = 0表明列联表中的两个变量独立;V=1表明列联表中的两个变量完全相关;不同行和列的列联表计算的列联系数不便于比较;当列联表中有一维为2,min[(r-1),(c-1)]=1,此时V=第十章方差分析1.单因素方差分析的要点:1)建立假设的表述方法:,自变量对因变量没有显著影响不全相等,自变量对因变量有显著影响2)决策:i.根据给定的显著性水平,在F分布表中查找与第一自由度、第二自由相应的临界值ii.若F>,则拒绝原假设,表明均值之间的差异是显著的,所检验的因素对观察值有显著影响iii.若F<,则不拒绝原假设,不能认为所检验的因素对观察值有显著影响3)单因素方差分析表的结构:2.方差分析中的多重比较(步骤):采用Fisher提出的最小显著差异方法,简写为LSD统计学各章计算题公式及解题方法1)提出假设:(第个总体的均值等于第个总体的均值)(第个总体的均值不等于第个总体的均值)2)计算检验统计量:3)计算LSD:4)决策:若,则拒绝;若,则不拒绝3.双因素方差分析:1)无交互作用的双因素方差分析表结构:2)有交互作用的双因素方差分析表结构:4.关系强度测量:变量间关系的强度用自变量平方和(SSA)及残差平方和(SSE)占总平方和(SST)的比例大小来反映,根据平方根R进行判断第十一章一元线性回归1.样本的相关系数:统计学各章计算题公式及解题方法2.相关系数的显著性检验步骤:1)提出假设:2)计算检验统计量:3)确定并决策:,拒绝;,不拒绝3.一元回归模型:4.一元线性回归方程形式:,其中是直线方程在y轴上的截距,是当=0时,y的期望值;是直线的斜率,称为回归系数,表示当每变动一个单位时y的平均变动值5.一元线性回归中,估计的回归方程:,其中是估计的回归直线在y轴上的截距,是直线的斜率,它表示对于一个给定的的值,是y的估计值,表示当每变动一个单位时y的平均变动值6.根据最小二乘法求以及的公式:7.误差平方和之间的关系:,即:8.判定系数(回归平方和占离差平方和的比例):9.估计标准误差(实际观察值与回归估计值离差平方和的均方根):10.线性关系的显著性检验:1)提出假设:,线性关系不显著;,有线性关系2)计算检验统计量:3)确定显著性水平,并根据分子自由度1和分母自由度n-2找出临界值统计学各章计算题公式及解题方法4)决策:若,拒绝;,不拒绝11.回归系数的显著性检验:1)提出假设:,线性关系不显著;,有线性关系2)计算检验统计量:3)确定显著性水平并决策:若;12.置信区间估计:在置信水平下的置信区间:其中,为估计标准误差,为的自由度13.预测区间估计:在置信水平下的预测区间:14.回归分析表的结构:15.几点说明:1)判定系数测度了回归直线对观测数据的拟合程度,若所有观测点都落在直线上,残差平方和SSE=0,=1,拟合是完全的2)在一元线性回归中,相关系数r实际上是判定系数的平方根统计学各章计算题公式及解题方法3)相关系数r与回归系数是同号的第十三章时间序列预测和分析1.环比增长率:报告期增长率与前一期水平之比减1:2.定基增长率:报告期水平与某一固定时期水平之比减1,其中,表示用于对比的固定基期的观察值3.平均增长率:序列中各逐期环比值(也称环比发展速度) 的几何平均数减1后的结果(描述现象在整个观察期内平均增长变化的程度)1)当时间序列中的观察值出现0或负数时,不宜计算增长率2)在有些情况下,不宜单纯就增长率论增长率,要注意增长率与绝对水平的结合分析4.时间序列预测的步骤:1)确定时间序列所包含的成分,也就是确定时间序列的类型2)找出适合此类时间序列的预测方法3)对可能的预测方法进行评估,以确定最佳预测方案4)利用最佳预测方案进行预测5.均方误差:通过平方消去正负号后计算的平均误差,用MSE表示6.简单平均法:根据过去已有的t期观察值来预测下一期数值。
设时间序列已有的其观察值为则期的预测值为:有了的实际值,则预测误差为:期的预测值为:7.简单移动平均法:将最近k期的数据加以平均,作为下一期的预测值设移动间隔为k(1<k<t),则t期的移动平均值为:期的预测值为:预测误差用均方误差表示:8.指数平滑法(一次):以一段时期的预测值与观察值的线性组合作为t+1的预测值,其预测模型为:,其中为平滑系数,在开始计算时,没有第1个时期的预测值,通常可以设等于1期的实际观察值,即9.线性趋势预测:1)一般形式:,为时间序列趋势值,为时间标号,为趋势线在Y 轴上的截距,为趋势线的斜率,表示时间变动一个单位时观察值的平均变动数量2)由最小二乘法求得:如令,则3)预测误差可用估计标准误差来衡量:m为趋势方程中未知常数的个数10.指数曲线:用于描述以几何级数递增或递减的现象1)一般形式:,a、b为未知常数,若b>1,增长率随着时间t的增加而增加,若b<1,增长率随着时间t的增加而降低,若a>0,b<1,趋势值逐渐降低到以0为极限2)将一般形式转换为对数直线形式,由最小二乘法求得:3)求出及,取反对数11.修正指数曲线:描述初期增长迅速,随后增长率逐渐降低,最终则K为增长极限现象1)一般形式:,K、a、b 为未知常数,K>0,a≠0,0<b≠12)趋势值K无法事先确定时采用;将时间序列观察值等分为三个部分,每部分有m个时期;令趋势值的三个局部总和分别等于原序列观察值的三个局部总和i.设观察值的三个局部总和分别为:,;;ii.根据三和法求得:12.Gompertz曲线:描述初期增长缓慢,以后逐渐加快,当达到一定程度后,增长率又逐渐下降,最后接近一条水平线现象1)一般形式:,K、a、b为未知常数;K>0,0<a≠1,0<b≠12)求解系数方法:i.将其改写为对数形式:ii.仿照修正指数曲线的常数确定方法,求出、、b;取和的反对数求得和令:,,则有:第十四章指数1.简单综合指数:(误差太大)(质量指标);(数量指标)2.加权综合指数:1)拉氏数量指标指数(同度量因素固定在基期):2)帕氏质量指标指数(同度量因素固定在报告期):3.指数体系:式中为报告期总量指标,为基期总量指标,q为数量指标,p为质量指标因素影响差额之间的关系:4.居民消费价格指数:,式中代表规格品个体指数或各层的类指数,为相应的消费支出比重5.股票价格指数:P。