第六章自相关案例分析
- 格式:doc
- 大小:78.00 KB
- 文档页数:5




计量经济学第六章自相关自相关是计量经济学中一种重要的现象,它指的是一个变量与其自己在过去时间点上的相关性。
自相关在实证研究中十分常见,对经济学家来说,了解和掌握自相关性质是至关重要的。
1. 引言自相关作为计量经济学的一项基础概念,是经济学研究中不可或缺的一个重要方法。
自相关性的存在通常会引起回归结果的偏误,而忽略自相关性可能导致估计不准确的结果。
因此,探讨自相关性的性质和应对方法是计量经济学的重点之一。
2. 自相关的定义和表示自相关是指一个变量与其自身在过去时间点上的相关性。
假设我们有一个时间序列数据集,其中变量yt表示一个时间点上的观测值,t表示时间索引。
自相关系数可以通过计算观测值yt与其在过去某一时间点上的观测值yt-k(k为时间滞后期数)的相关性来得到。
数学上,自相关系数可以用公式表示为:ρ(k) = Cov(yt, yt-k) / (σ(yt) * σ(yt-k))其中,ρ(k)表示第k期的自相关系数,Cov表示协方差,σ表示标准差。
3. 自相关性的性质自相关性具有以下几个性质:3.1 一阶自相关性一阶自相关性是指变量值yt与前一期的观测值yt-1之间的相关性。
一阶自相关系数ρ(1)通常用来检验时间序列数据是否存在自相关性。
若ρ(1)大于零且显著,则表明存在正的一阶自相关性;若ρ(1)小于零且显著,则表明存在负的一阶自相关性。
3.2 高阶自相关性除了一阶自相关性,时间序列数据还可能存在高阶自相关性。
高阶自相关性是指变量值yt与过去第k期的观测值yt-k之间的相关性。
通过计算不同滞后期的自相关系数ρ(k),可以了解数据在不同时间跨度上的自相关性情况。
3.3 异方差自相关性异方差自相关性是指时间序列数据中的方差不仅与自身相关,还与过去观测值的相关性有关。
异方差自相关性可能导致在回归分析中的标准误差失效,从而产生无效的回归结果。
因此,在处理存在异方差自相关性的数据时要采取合适的修正方法。
4. 自相关性的检验方法在实证研究中,经济学家通常使用多种方法来检验数据中的自相关性,常用的方法包括:4.1 Durbin-Watson检验Durbin-Watson检验是一种常用的检验自相关性的方法,其基本思想是通过检验误差项的相关性来判断自相关是否存在。
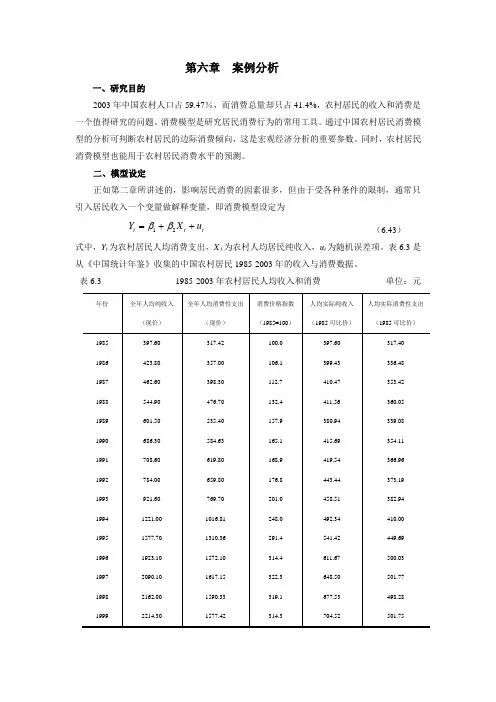
第六章 案例分析一、研究目的2003年中国农村人口占59.47%,而消费总量却只占41.4%,农村居民的收入和消费是一个值得研究的问题。
消费模型是研究居民消费行为的常用工具。
通过中国农村居民消费模型的分析可判断农村居民的边际消费倾向,这是宏观经济分析的重要参数。
同时,农村居民消费模型也能用于农村居民消费水平的预测。
二、模型设定正如第二章所讲述的,影响居民消费的因素很多,但由于受各种条件的限制,通常只引入居民收入一个变量做解释变量,即消费模型设定为t t t u X Y ++=21ββ(6.43)式中,Y t 为农村居民人均消费支出,X t 为农村人均居民纯收入,u t 为随机误差项。
表6.3是从《中国统计年鉴》收集的中国农村居民1985-2003年的收入与消费数据。
表6.3 1985-2003年农村居民人均收入和消费 单位: 元2000 2001 2002 20032253.40 2366.40 2475.60 2622.241670.00 1741.00 1834.00 1943.30314.0 316.5 315.2 320.2717.64 747.68 785.41 818.86531.85 550.08 581.85 606.81注:资料来源于《中国统计年鉴》1986-2004。
为了消除价格变动因素对农村居民收入和消费支出的影响,不宜直接采用现价人均纯收入和现价人均消费支出的数据,而需要用经消费价格指数进行调整后的1985年可比价格计的人均纯收入和人均消费支出的数据作回归分析。
根据表6.3中调整后的1985年可比价格计的人均纯收入和人均消费支出的数据,使用普通最小二乘法估计消费模型得t t X Y 0.59987528.106ˆ+=(6.44)Se = (12.2238) (0.0214)t = (8.7332)(28.3067)R 2 = 0.9788,F = 786.0548,d f = 17,DW = 0.7706该回归方程可决系数较高,回归系数均显著。




第6章自相关1. 自相关定义1)非自相关由第2节知回归模型的假定条件之一是,Cov(u i,u j )=E(u i u j) =0, (i, j∈T, i ≠ j),(1.1)即误差项u t的取值在时间上是相互无关的。
称误差项u t非自相关。
2)自相关如果Cov (u i ,u j ) ≠ 0, (i ≠ j)则称误差项u t存在自相关。
自相关又称序列相关。
原指一随机变量在时间上与其滞后项之间的相关。
这里主要是指回归模型中随机误差项u t 与其滞后项的相关关系。
自相关也是相关关系的一种。
2.自相关类型1)自相关按滞后阶数可分为两类。
(1)一阶自回归形式当误差项u t只与其滞后一期值有关时,即u t = f (u t - 1),称u t具有一阶自回归形式。
(2) 高阶自回归形式当误差项u t的本期值不仅与其前一期值有关,而且与其前若干期的值都有关系时,即u t = f (u t – 1, u t – 2 , … ), 则称u t 具有高阶自回归形式。
2)按函数形式分为线性自相关和非线性自相关 (1)线性自相关 f 为线性函数形式 (2)非线性自相关 f 为非线性函数形式 3.一阶线性自相关通常假定误差项的自相关是线性的。
因计量经济模型中自相关的最常见形式是一阶自回归形式,所以下面重点讨论误差项的线性一阶自回归形式,即 u t =1a u t -1 + v t (1.2)其中1a 是自回归系数,v t 是随机误差项。
v t 满足通常假设E(v t ) = 0, t = 1, 2 …, T, Var(v t ) = σv 2, t = 1, 2 …, T,Cov(v i , v j ) = 0, i ≠ j, i, j = 1, 2 …, T, Cov(u t-1, v t ) = 0, t = 1, 2 …, T,依据普通最小二乘法公式,模型(1.2)中 1 的估计公式是,1ˆa= ∑∑=-=-Tt t Tt t tuuu 22121 (1ˆβ=∑∑---2)())((x x x x y y t t t ) (1.3)其中T 是样本容量。


《计量经济学》实验报告实验课题:各章节案列分析姓名:茆汉成班级:会计学12-2班学号:指导老师:蒋翠侠报告日期:目录第二章简单线性回归模型案例 (1)1 问题引入 (2)2 模型设定 (2)3 估计参数 (2)4 模型检验 (2)第三章多元线性回归模型案例 (3)1 问题引入 (3)2 模型设定 (3)3 估计参数 (4)4 模型检验 (4)第四章多重线性案例 (4)1 问题引入 (4)2 模型设定 (5)3 参数估计 (5)4 对多重共线性的处理 (5)第五章异方差性案例 (6)1 问题引入 (6)2 模型设定 (6)3 参数估计 (6)4 异方差检验 (7)5 异方差性的修正 (7)第六章自相关案例 (8)1 问题引入 (8)2 模型设定 (8)3 用OLS估计 (8)4 自相关其他检验 (8)5 消除自相关 (9)第七章分布滞后模型与自回归模型案例 (9)案例1 (9)1 问题引入 (9)2 模型设定 (10)3 参数估计 (10)案例2 (10)1 问题引入 (10)2 模型设定 (10)3、回归分析 (10)4 模型检验 (11)第八章虚拟变量回归案例 (11)1 问题引入 (11)2 模型设定 (11)3 参数估计 (12)4 模型检验 (12)第二章简单线性回归模型案例1、问题引入居民消费在社会经济的持续发展中有着重要的作用。
适度的居民消费规模和合理的消费模型是人民生活水平的具体体现,有利于经济持续健康的增长。
随着社会信息化程度和居民的收入水平的提高,计算机的运用越来越普及,作为居民耐用消费品重要代表的计算机已经为众多的城镇居民家庭所拥有。
研究中国各地区城镇居民计算机拥有量与居民收入水平的数量关系。
影响居民计算机拥有量的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入水平。
从理论上说居民收入水平越高,居民计算机拥有量越多。
所以我们设定“城镇居民家庭平均每百户计算机拥有量(台)”为被解释变量,“城镇居民平均每人全年家庭总收入(元)”为解释变量。
计量经济学第六章自相关在计量经济学的学习中,自相关是一个重要且颇具挑战性的概念。
自相关,简单来说,就是指在时间序列或横截面数据中,观测值之间存在的某种相关性。
想象一下,我们在研究某个经济变量随时间的变化情况,比如一家公司的销售额。
如果在不同的时间段,销售额的变化不是相互独立的,而是存在一定的关联,这就可能出现了自相关现象。
自相关产生的原因多种多样。
其中一个常见的原因是经济变量的惯性。
例如,消费者的消费习惯往往具有一定的延续性,不会突然发生巨大的改变。
这就导致消费数据在不同时期可能存在相关性。
另一个可能的原因是模型设定的不准确。
如果我们在构建计量经济模型时,遗漏了某些重要的解释变量,那么残差项就可能包含这些被遗漏变量的影响,从而导致自相关。
自相关的存在会给我们的计量经济分析带来一系列问题。
首先,它会影响参数估计的有效性。
在存在自相关的情况下,传统的最小二乘法(OLS)估计得到的参数估计值不再是最优的,估计的方差也会被低估,这可能导致我们对参数的显著性做出错误的判断。
其次,自相关会使我们对模型的假设检验失效。
假设检验是基于一定的统计分布进行的,如果存在自相关,这些分布就不再适用,从而导致检验结果的不可靠。
那么,如何检测自相关呢?常用的方法有图形法、杜宾瓦特森(DurbinWatson)检验等。
图形法是通过绘制残差的序列图来直观地观察是否存在自相关。
如果残差呈现出某种周期性或趋势性,那么就可能存在自相关。
杜宾瓦特森检验则是一种基于统计量的检验方法。
它通过计算一个特定的统计量,并与临界值进行比较来判断是否存在自相关。
如果经过检测发现存在自相关,我们就需要采取相应的方法来处理。
一种常见的方法是广义最小二乘法(GLS)。
GLS通过对原模型进行变换,使得变换后的模型不存在自相关,从而得到更有效的参数估计。
另外,还可以使用一阶差分法。
这种方法将原变量的一阶差分作为新的变量进行回归分析,从而消除可能存在的自相关。
第六章 自相关性本章教学要求:本章是违背古典假定情况下线性回归描写的参数估计的又一问题。
通过本章的学习应达到:掌握自相关的基本概念,产生自相关的背景;自相关出现对模型影响的后果;诊断自相关存在的方法和修正自相关的方法。
能够运用本章的知识独立解决模型中的自相关问题。
经过第四、五、六章的学习,要求自行选择一个实际经济问题,建立模型,并判断和解决上述可能存在的问题。
第一节 自相关性的概念一、一个例子研究中国城镇居民消费函数,其中选取了两个变量,城镇家庭商品性支出(现价)和城镇家庭可支配收入(现价),分别记为CSJTZC 和CSJTSR ,时间从1978年到1997年,n=20。
但为了剔除物价的影响,分别对CSJTZC 和CSJTSR 除以物价(用CPI 表示),这里CPI 为城镇居民消费物价指数(以1990年为100%),经过扣除价格因素以后,记CPICSJTSRX CPICSJTZCY ==即如下表回归以后得到的残差为Dependent Variable: YMethod: Least SquaresDate: 10/27/04 Time: 09:39Sample: 1978 1997Included observations: 20Std. Error t-Statistic Prob.Variable CoefficientC-103.369278.80739-1.3116690.2061X0.9235510.01603357.603880.00003939.341 R-squared0.994605Mean dependentvarAdjusted R-squared0.994305S.D. dependent var2124.467S.E. of regression160.3247Akaike info criterion13.08692Sum squared resid462671.9Schwarz criterion13.18649Log likelihood -128.8692 F-statistic 3318.207 Durbin-Watson stat1.208037 Prob(F-statistic)0.000000二、什么是自相关性在引出自相关性的概念之前,根据建立中国城镇居民储蓄函数,经用最小二乘法估计出参数后,得到残差序列,由此画出残差图(残差序列自身的关系),从图形上看存在t e 对1 t e 的线性关系,残差的这种现象说明了什么?下面给出序列自相关的定义。
第六章 案例分析
一、研究目的
2003年中国农村人口占59.47%,而消费总量却只占41.4%,农村居民的收入和消费是一个值得研究的问题。
消费模型是研究居民消费行为的常用工具。
通过中国农村居民消费模型的分析可判断农村居民的边际消费倾向,这是宏观经济分析的重要参数。
同时,农村居民消费模型也能用于农村居民消费水平的预测。
二、模型设定
正如第二章所讲述的,影响居民消费的因素很多,但由于受各种条件的限制,通常只引入居民收入一个变量做解释变量,即消费模型设定为
t t t u X Y ++=21ββ
(6.43)
式中,Y t 为农村居民人均消费支出,X t 为农村人均居民纯收入,u t 为随机误差项。
表6.3是从《中国统计年鉴》收集的中国农村居民1985-2003年的收入与消费数据。
表6.3 1985-2003年农村居民人均收入和消费 单位: 元
2000 2001 2002 2003
2253.40 2366.40 2475.60 2622.24
1670.00 1741.00 1834.00 1943.30
314.0 316.5 315.2 320.2
717.64 747.68 785.41 818.86
531.85 550.08 581.85 606.81
注:资料来源于《中国统计年鉴》1986-2004。
为了消除价格变动因素对农村居民收入和消费支出的影响,不宜直接采用现价人均纯收入和现价人均消费支出的数据,而需要用经消费价格指数进行调整后的1985年可比价格计的人均纯收入和人均消费支出的数据作回归分析。
根据表6.3中调整后的1985年可比价格计的人均纯收入和人均消费支出的数据,使用普通最小二乘法估计消费模型得
t t X Y 0.59987528.106ˆ+=
(6.44)
Se = (12.2238) (0.0214)
t = (8.7332)
(28.3067)
R 2 = 0.9788,F = 786.0548,d f = 17,DW = 0.7706
该回归方程可决系数较高,回归系数均显著。
对样本量为19、一个解释变量的模型、5%显著水平,查DW 统计表可知,d L =1.18,d U = 1.40,模型中DW<d L ,显然消费模型中有自相关。
这一点残差图中也可从看出,点击EViews 方程输出窗口的按钮Resids 可得到残差图,如图6.6所示。
图6.6
残差图
图6.6残差图中,残差的变动有系统模式,连续为正和连续为负,表明残差项存在一阶正自相关,模型中t 统计量和F 统计量的结论不可信,需采取补救措施。
三、自相关问题的处理
为解决自相关问题,选用科克伦—奥克特迭代法。
由模型(6.44)可得残差序列e t ,在EViews 中,每次回归的残差存放在resid 序列中,为了对残差进行回归分析,需生成命名为
e 的残差序列。
在主菜单选择Quick/Generate Series 或点击工作文件窗口工具栏中的Procs/ Generate Series ,在弹出的对话框中输入e = resid ,点击OK 得到残差序列e t 。
使用e t 进行滞后一期的自回归,在EViews 命今栏中输入ls e e (-1)可得回归方程
e t = 0.4960 e t-1
(6.45)
由式(6.45)可知ρ
ˆ=0.4960,对原模型进行广义差分,得到广义差分方程 t t t t t u X X Y Y +-+-=---)4960.0()4960.01(4960.01211ββ
(6.46)
对式(6.46)的广义差分方程进行回归,在EViews 命令栏中输入ls Y -0.4960*Y (-1) c
X -0.4960*X (-1),回车后可得方程输出结果如表6.4。
表6.4 广义差分方程输出结果 Dependent Variable: Y-0.496014*Y(-1) Method: Least Squares Date: 03/26/05 Time: 12:32 Sample(adjusted): 1986 2003
Included observations: 18 after adjusting endpoints
Variable Coefficient Std. Error t-Statistic Prob. C
60.44431 8.964957 6.742287 0.0000 X-0.496014*X(-1) 0.583287
0.029410
19.83325
0.0000
R-squared
0.960914 Mean dependent var 231.9218 Adjusted R-squared 0.958472 S.D. dependent var 49.34525 S.E. of regression 10.05584 Akaike info criterion 7.558623 Sum squared resid 1617.919 Schwarz criterion 7.657554 Log likelihood -66.02761 F-statistic 393.3577 Durbin-Watson stat
1.397928 Prob(F-statistic)
0.000000
**5833.04443.60ˆt t X Y +=
(6.47)
)9650.8(=Se (0.0294)
t = (6.7423)
(19.8333)
R 2 = 0.9609 F = 393.3577 d f = 16 DW = 1.3979
式中,1*4960.0ˆ--=t t t Y Y Y ,
1*4960.0--=t t t X X X 。
由于使用了广义差分数据,样本容量减少了1个,为18个。
查5%显著水平的DW 统
计表可知d L = 1.16,d U = 1.39,模型中DW = 1.3979> d U ,说明广义差分模型中已无自相关,不必再进行迭代。
同时可见,可决系数R 2
、t 、F 统计量也均达到理想水平。
对比模型(6.44)和(6.47),很明显普通最小二乘法低估了回归系数2ˆ
β的标准误差。
[原模型中Se (2ˆβ)= 0.0214,广义差分模型中为Se (2ˆ
β)= 0.0294。
经广义差分后样本容量会减少1个,为了保证样本数不减少,可以使用普莱斯—温斯
腾变换补充第一个观测值,方法是21*11ρ-=X X 和21*11ρ-=Y Y 。
在本例中即为
210.49601-X 和210.49601-Y 。
由于要补充因差分而损失的第一个观测值,所以在
EViews 中就不能采用前述方法直接在命令栏输入Y 和X 的广义差分函数表达式,而是要生成X 和Y 的差分序列X *和Y *。
在主菜单选择Quick/Generate Series 或点击工作文件窗口工具栏中的Procs/Generate Series ,在弹出的对话框中输入Y *= Y -0.4960*Y (-1),点击OK 得到广义差分序列Y *,同样的方法得到广义差分序列X *。
此时的X *和Y *都缺少第一个观测值,
需计算后补充进去,计算得*1X =345.236,*
1Y =275.598,双击工作文件窗口的X * 打开序列
显示窗口,点击Edit +/-按钮,将*
1X =345.236补充到1985年对应的栏目中,得到X *的19个观测值的序列。
同样的方法可得到Y *的19个观测值序列。
在命令栏中输入Ls Y * c X*得到普莱斯—温斯腾变换的广义差分模型为
**5833.04443.60t t X Y +=
(6.48)
)1298.9(=Se (0.0297)
t = (6.5178)
(19.8079)
R 2 = 0.9585 F = 392.3519 d f = 19 DW = 1.3459
对比模型(6.47)和(6.48)可发现,两者的参数估计值和各检验统计量的差别很微小,说明在本例中使用普莱斯—温斯腾变换与直接使用科克伦—奥克特两步法的估计结果无显著差异,这是因为本例中的样本还不算太小。
如果实际应用中样本较小,则两者的差异会较大。
通常对于小样本,应采用普莱斯—温斯腾变换补充第一个观测值。
由差分方程(6.46)有
9292
.1194960.014443
.60ˆ1
=-=β
(6.49)
由此,我们得到最终的中国农村居民消费模型为 Y t = 119.9292+0.5833 X t
(6.50)
由(6.50)的中国农村居民消费模型可知,中国农村居民的边际消费倾向为0.5833,即中国农民每增加收入1元,将增加消费支出0.5833元。