第3.3节 minimax估计
- 格式:ppt
- 大小:1.02 MB
- 文档页数:21

第三章 多元线性回归与最小二乘估计3.1 假定条件、最小二乘估计量和高斯—马尔可夫定理1、多元线性回归模型:y t = β0 +β1x t 1 + β2x t 2 +…+ βk - 1x t k -1 + u t (3.1) 其中y t 是被解释变量(因变量),x t j 是解释变量(自变量),u t 是随机误差项,βi , i = 0, 1, … , k - 1是回归参数(通常未知)。
对经济问题的实际意义:y t 与x t j 存在线性关系,x t j , j = 0, 1, … , k - 1, 是y t 的重要解释变量。
u t 代表众多影响y t 变化的微小因素。
使y t 的变化偏离了E( y t ) = β0 +β1x t 1 + β2x t 2 +…+ βk - 1x t k -1 决定的k 维空间平面。
当给定一个样本(y t , x t 1, x t 2 ,…, x t k -1), t = 1, 2, …, T 时, 上述模型表示为 y 1 = β0 +β1x 11 + β2x 12 +…+ βk - 1x 1 k -1 + u 1,y 2 = β0 +β1x 21 + β2x 22 +…+ βk - 1x 2 k -1 + u 2, (3.2) ………..y T = β0 +β1x T 1 + β2x T 2 +…+ βk - 1x T k -1 + u T经济意义:x t j 是y t 的重要解释变量。
代数意义:y t 与x t j 存在线性关系。
几何意义:y t 表示一个多维平面。
此时y t 与x t i 已知,βj 与 u t 未知。
)1(21)1(110)(111222111111)1(21111⨯⨯-⨯---⨯⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡+⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡T T k k k T k T TjT k j k jT T u u u x x x x x x x x x y y yβββ (3.3) Y = X β + u (3.4)2假定条件为保证得到最优估计量,回归模型(3.4)应满足如下假定条件。


有约束的多元模型的Minimax估计及多元正态分布熵的估计的开题报告一、课题背景多元统计分析中,多元模型的参数估计是重要的研究内容之一。
在多元模型中,有时需要对参数进行估计,在这种情况下,最小二乘估计可能不是最优的选择,因为它可能受到数据中的异常值影响。
因此,Minimax估计就被提出,它是一种对参数进行估计的方法,可以抵抗异常值的影响,从而提高了估计的准确性。
另外,多元正态分布的熵也是多元统计分析中非常重要的内容之一。
正如单变量分布的熵可以衡量随机变量的不确定性一样,多元正态分布的熵可以衡量多元随机变量的不确定性。
在一些实际问题中,我们需要估计多元正态分布的熵以了解它的基本特征或计算其他与熵相关的统计量。
因此,本文将重点探讨有约束的多元模型的Minimax估计和多元正态分布熵的估计。
二、研究目的与意义在实际研究中,数据中常常存在异常值等噪声因素,这些因素会对估计参数的精度造成负面影响,因此如何提高参数估计的鲁棒性是很有意义的研究方向。
Minimax 估计是一种抵抗异常值影响的估计方法,能够准确地估计参数,因此具有很高的应用价值。
另一方面,多元正态分布的熵是描述多元随机变量不确定性的重要指标,它不仅可以用于统计分析,还可以应用于工程、经济学、计算机科学等多个领域。
因此,研究多元正态分布熵的估计方法有助于更好地理解多元随机变量的统计特性,为相关应用提供更可靠的基础数据。
三、研究内容本文拟就有约束的多元模型的Minimax估计和多元正态分布熵的估计展开研究,具体内容如下:1. 有约束的多元模型的Minimax估计(1) 介绍Minimax估计的基本概念和原理,并分析Minimax估计的优缺点;(2) 探讨有约束的多元模型中的Minimax估计,包括有限制条件下的Minimax 估计和先验信息下的Minimax估计;(3) 针对具体问题,利用实例进行实证分析,验证Minimax估计的优越性。
2. 多元正态分布熵的估计(1) 简述多元正态分布的概念和特性,重点介绍其熵的计算方法和性质;(2) 探究多元正态分布熵的估计方法,包括直接估计和间接估计两种方法,比较其优缺点;(3) 针对具体问题,利用实例进行实证分析,评估各种多元正态分布熵的估计方法的表现。

Minimax算法及实例分析发表于2015/5/11 15:20:32 2419人阅读分类: AI算法计算机科学中最有趣的事情之一就是编写一个人机博弈的程序。
有大量的例子,最出名的是编写一个国际象棋的博弈机器。
但不管是什么游戏,程序趋向于遵循一个被称为Minimax算法,伴随着各种各样的子算法在一块。
Minimax算法又名极小化极大算法,是一种找出失败的最大可能性中的最小值的算法。
Minimax算法常用于棋类等由两方较量的游戏和程序,这类程序由两个游戏者轮流,每次执行一个步骤。
我们众所周知的五子棋、象棋等都属于这类程序,所以说Minimax算法是基于搜索的博弈算法的基础。
该算法是一种零总和算法,即一方要在可选的选项中选择将其优势最大化的选择,而另一方则选择令对手优势最小化的方法。
1. Minimax是一种悲观算法,即假设对手每一步都会将我方引入从当前看理论上价值最小的格局方向,即对手具有完美决策能力。
因此我方的策略应该是选择那些对方所能达到的让我方最差情况中最好的,也就是让对方在完美决策下所对我造成的损失最小。
1. Minimax不找理论最优解,因为理论最优解往往依赖于对手是否足够愚蠢,Minimax中我方完全掌握主动,如果对方每一步决策都是完美的,则我方可以达到预计的最小损失格局,如果对方没有走出完美决策,则我方可能达到比预计的最悲观情况更好的结局。
总之我方就是要在最坏情况中选择最好的。
实例分析:现在考虑这样一个游戏:有三个盘子A、B和C,每个盘子分别放有三张纸币。
A放的是1、20、50;B放的是5、10、100;C放的是1、5、20。
单位均为“元”。
有甲、乙两人,两人均对三个盘子和上面放置的纸币有可以任意查看。
游戏分三步:1. 甲从三个盘子中选取一个。
2. 乙从甲选取的盘子中拿出两张纸币交给甲。
3. 甲从乙所给的两张纸币中选取一张,拿走。
其中甲的目标是最后拿到的纸币面值尽量大,乙的目标是让甲最后拿到的纸币面值尽量小。
Minimax极⼤极⼩算法、Alpha-BetaPruning剪枝算法这篇博客分为两部分。
⾸先我会先讲极⼤极⼩算法,然后在此基础上进⾏改进给出进阶版的Alpha-Beta剪枝算法以及代码实现。
⽂中配备b站讲解的视频,感兴趣的可以看⼀下视频讲解,然后复习的时候拿着⽂章当作参考。
Minimax算法(极⼤极⼩算法)概念是⼀种找出最⼩失败的可能的算法。
意思就是两个⼈下棋,A和B下棋,A想要⾃⼰的利益最⼤化(失败的可能性最⼩),B想要A的利益最⼩化(B想要A输)。
这个算法以及接下来的Alpha-Beta剪枝都是⼀种对抗性搜索算法(两个⼈互相对抗着下棋,俩⼈都想赢),是⼀种⼈⼯智能搜索的算法。
掌握此算法后可以⽤来写井字棋、五⼦棋等⼈⼯智能⼈机对抗下棋程序。
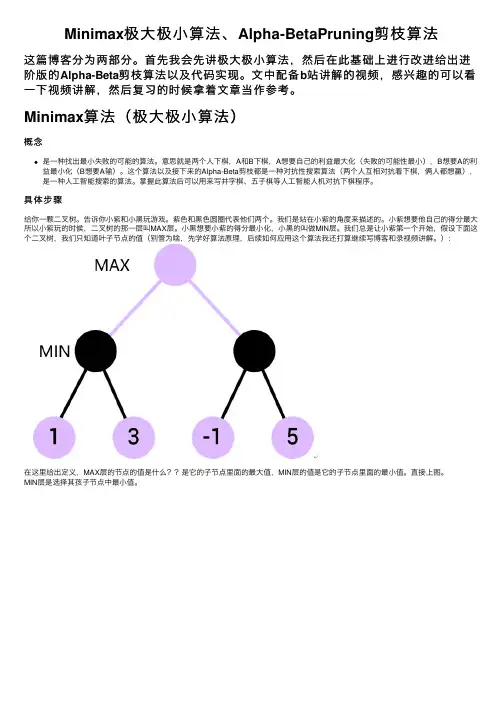
具体步骤给你⼀颗⼆叉树。
告诉你⼩紫和⼩⿊玩游戏。
紫⾊和⿊⾊圆圈代表他们两个。
我们是站在⼩紫的⾓度来描述的。
⼩紫想要他⾃⼰的得分最⼤所以⼩紫玩的时候,⼆叉树的那⼀层叫MAX层。
⼩⿊想要⼩紫的得分最⼩化,⼩⿊的叫做MIN层。
我们总是让⼩紫第⼀个开始,假设下⾯这个⼆叉树,我们只知道叶⼦节点的值(别管为啥,先学好算法原理,后续如何应⽤这个算法我还打算继续写博客和录视频讲解。
):在这⾥给出定义,MAX层的节点的值是什么??是它的⼦节点⾥⾯的最⼤值,MIN层的值是它的⼦节点⾥⾯的最⼩值。
直接上图。
MIN层是选择其孩⼦节点中最⼩值。
MAX层选择其孩⼦节点中的最⼤值。
算法概念就是这个样⼦。
算法的输⼊是构造的这⼀棵满⼆叉树,输出是最上层MAX节点的值。
代码实现class Node{ //结点类public:const int value;Node *left;Node *right;Node(int v,Node* l,Node* r):value(v),left(l),right(r) {};};为了遍历这棵树,⾸先我们得创建出来这棵树对吧?但是你的代码⾥没有创建⼆叉树这⼀部分啊。

第3章 最小二乘法和最小二乘估计Chapter 3 Least Squares线性模型中的参数估计有多种方法,其中最小二乘法是最为著名的。
即使已经发现其他方法比较优越,但是最小二乘法仍然是线性模型估计的基础方法,最小二乘估计的性质已经得到了广泛应用。
§3.1 最小二乘回归(least squares regression)随机线性关系i i i y ε+'=βx 中的未知系数是我们考虑的重点,也是我们进行估计的主要目标。
这时我们有必要区分母体变量(例如β和i ε)和它们的样本估计,对应地表示为b 和i e 。
母体回归方程可以表示为:βx x i i i y E '=]|[它的估计表示为:b x i i y '=ˆ (3.1) 与第i 个数据点相关的扰动项可以表示为:βx i i i y '-=ε (3.2) 如果获得了回归系数的估计,则可以利用回归方程的残差来估计随机扰动项,即b x i i i y e '-= (3.3) 根据这些定义和表示,可以得到:i i i i i e y +'=+'=b x βx ε (3.4)母体量β是每个i y 的概率分布中的未知系数,我们希望利用样本数据),(i i y x 来估计这些参数。
虽然这是一个统计推断问题,但是我们仍然可以直观地认为应该选取向量b ,使得拟合直线b x i '尽量地靠近数据点。
如果描述这种靠近性,需要一定的拟合准则,其中最为广泛使用的是最小二乘法。
§3.1.1 最小二乘系数向量可以通过极小化下述残差平方和来获得最小二乘系数向量。
∑∑=='-=n i i n i i y e120120)(b x (3.5) 其中0b 表示系数向量的选择。
利用矩阵形式表示上述残差平方和:)()()(Minminze 000000Xb y Xb y e e b b -'-='=S (3.6) 将上述目标函数展开得到(注意利用标量的转置不变的性质):0000002)(Xb X b Xb y y y e e b ''+'-'='=S (3.7)极小化的一阶条件为(相当于对向量求导数,要么利用向量展开,要么利用向量求导公式):022)(000='+'-=∂∂Xb X y X b b S (3.8) 假设b 是最小二乘的解,则它必须满足最小二乘正规方程(least square normal equations): y X Xb X '=' (3.9) 如果解释变量矩阵的满秩条件满足,则有:K rank rank K n K K =='⨯⨯)()(X X X这说明矩阵K K ⨯')(X X 是可逆矩阵,因此正规方程的唯一解为:y X X X b ''=-1)( (3.10) 注意到上述条件只是极小化问题的必要条件,为了判断充分性,我们需要求出目标函数的Hessian 矩阵:X X bb b '='∂∂∂2)(2S (3.11) 如果这个Hessian 矩阵是正定的,则可以判断所得到的解是唯一的最小二乘解。

parameters of uncertain objects. Finally it gets satisfactory optimization results.Keywords: Proportion-Integral – Derivative Controller,Genetic Algorithm,Uncertainty System,MINIMAX Optimization,Hybrid Genetic Algorithm; Robustness目录摘要 (I)Abstract (II)目录 (IV)第一章绪论 (1)1.1 引言 (1)1.2 PID 控制器简介 (2)1.2.1 PID 控制器的结构和原理 (2)1.2.2 控制参数对 PID 控制的影响 (3)1.3 遗传算法简介 (4)1.3.1 遗传算法的特点 (4)1.3.2 遗传算法在控制工程中的应用 (5)1.4 国内外研究现状 (5)1.5 本文的研究内容及结构 (6)1.5.1 论文的研究内容 (6)1.5.2 论文的组织结构 (7)第二章不确定性优化问题的描述 (8)2.1 不确定优化命题的表达 (8)2.2 不确定优化命题的研究现状 (8)2.3 不确定优化问题的讨论 (10)2.3.1 不确定优化问题的提出与讨论 (10)2.3.2 参数不确定系统的优化命题 (11)2.4 参数不确定系统的优化解 (12)2.4.1 区间数运算 (12)2.4.2 优化解 (14)2.5 本章小结 (15)第三章基于全局 MINIMAX 优化问题的改进混合遗传算法 (16)3.1 全局 MINIMAX 优化问题 (16)3.1.1 全局 MINIMAX 优化问题的描述 (16)3.1.2 MINIMAX 优化命题研究的意义 (18)3.1.3 MINIMAX 的理论基础 (19)3.2 用 SGA 求解 MINIMAX 优化问题的算法 (20)3.2.1 简单遗传算法基础操作 (20)3.2.2 运用 SGA 解 MINIMAX 优化问题的算法描述 (21)3.2.3 运用 SGA 求解出现的困难 (22)3.3 改进的混合遗传算法求解 MINIMAX 优化问题 (23)3.3.1 改进遗传算法 (23)3.3.2 单纯形法的引入 (25)3.3.3 算法描述 (26)1.5.3 matlab 仿真实例计算 (27)1.5.4 本章小结 (28)第四章基于 HGA-I 的不确定对象 PID 优化 (30)2.6 PID 控制器参数的传统整定方法简介 (30)4.1.1 Ziegler-Nichols 整定方法 (30)4.1.2 遗传算法 PID 参数整定方法 (31)4.2 PID 控制性能指标 (33)4.2.1 动态指标 (33)4.2.2 综合指标 (34)4.3 HGA-I 整定不确定对象的 PID 参数的思想 (35)4.3.1 PID 控制器的选取 (35)4.3.2 不确定对象的描述 (36)4.3.3 参数的编码方案 (38)4.3.4 最优指标的选取 (38)4.3.5 适应度函数的选取 (40)4.3.6 参数整定的思想 (41)4.4 不确定对像的 PID 优化的参数整定算法 (42)4.5 matlab 实例仿真及结果分析 (44)4.6 本章小结 (47)第五章结论及展望 (48)参考文献 (49)致谢 (54)第一章绪论1.6引言常规比例积分微分(PID)控制是到现在为止最早发展起来的最通用最基本的控制器之一。

经典参数估计方法:普通最小二乘(OLS)、最大似然(ML)和矩估计(MM)普通最小二乘估计(Ordinary least squares,OLS)1801年,意大利天文学家朱赛普.皮亚齐发现了第一颗小行星谷神星。
经过40天的跟踪观测后,由于谷神星运行至太阳背后,使得皮亚齐失去了谷神星的位置。
随后全世界的科学家利用皮亚齐的观测数据开始寻找谷神星,但是根据大多数人计算的结果来寻找谷神星都没有结果。
时年24岁的高斯也计算了谷神星的轨道。
奥地利天文学家海因里希.奥尔伯斯根据高斯计算出来的轨道重新发现了谷神星。
高斯使用的最小二乘法的方法发表于1809年他的著作《天体运动论》中。
法国科学家勒让德于1806年独立发现“最小二乘法”,但因不为世人所知而默默无闻。
勒让德曾与高斯为谁最早创立最小二乘法原理发生争执。
1829年,高斯提供了最小二乘法的优化效果强于其他方法的证明,因此被称为高斯-莫卡夫定理。
最大似然估计(Maximum likelihood,ML)最大似然法,也称最大或然法、极大似然法,最早由高斯提出,后由英国遗传及统计学家费歇于1912年重新提出,并证明了该方法的一些性质,名称“最大似然估计”也是费歇给出的。
该方法是不同于最小二乘法的另一种参数估计方法,是从最大似然原理出发发展起来的其他估计方法的基础。
虽然其应用没有最小二乘法普遍,但在计量经济学理论上占据很重要的地位,因为最大似然原理比最小二乘原理更本质地揭示了通过样本估计总体的内在机理。
计量经济学的发展,更多地是以最大似然原理为基础的,对于一些特殊的计量经济学模型,最大似然法才是成功的估计方法。
对于最小二乘法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得模型能最好地拟合样本数据;而对于最大似然法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该是使得从模型中抽取该n组样本观测值的概率最大。
从总体中经过n次随机抽取得到的样本容量为n的样本观测值,在任一次随机抽取中,样本观测值都以一定的概率出现。


M-矩阵(张量)最小特征值估计及其相关问题研究1.引言M-矩阵(张量)最小特征值估计及其相关问题是数值线性代数和数值计算中的重要研究方向。
M-矩阵是一类特殊的稀疏矩阵,具有广泛的应用背景,如有限元方法、图像处理、机器学习等。
M-矩阵的最小特征值估计是求解线性方程组和特征值问题中的关键步骤,对于提高算法效率、减少计算量具有重要意义。
2.M-矩阵及其性质2.1 M-矩阵定义M-矩阵是指一类具有特殊形式的稀疏实对称正定矩阵。
对于一个n×n的实对称正定矩阵A,如果存在一个正实数p,使得A中每个元素a_ij(i≠j)满足|a_ij|≤p*min(a_ii,a_jj),则称A为一个M-matrix。
2.2 M-矩阵性质M-矩阵具有许多重要性质。
首先,M-矩阵的主对角元素都是非负的,即a_ii≥0,对于所有的i。
其次,M-矩阵的非主对角元素满足a_ij≤0,对于所有的i≠j。
第三,M-矩阵是正定的,即对于所有的x≠0,x^T A x>0。
最后,M-矩阵是可被分解的,即存在正定矩阵D和上三角矩阵U,使得A=D-U。
3.M-矩阵最小特征值估计方法3.1幂迭代法幂迭代法是最简单且最常用的M-矩阵最小特征值估计方法之一。
它的基本思想是通过迭代得到一个向量序列,使得向量序列的极限向量为M-矩阵的最小特征值对应的特征向量。
幂迭代法通过不断迭代计算A与一个初始向量之间的乘积,使得初始向量逐渐趋近于M-矩阵A的最小特征值对应的特征向量。
3.2反幂迭代法反幂迭代法是一种用于估计M-矩阵逆矩阵最大特征值的方法,通过将幂迭代法应用于矩阵的逆来实现。
反幂迭代法的基本思想是通过迭代计算矩阵逆与一个初始向量之间的乘积,使得初始向量逐渐趋近于M-矩阵逆矩阵的最大特征值对应的特征向量。
3.3 Rayleigh商迭代法Rayleigh商迭代法是一种基于Rayleigh商的特征值估计方法。
Rayleigh商是一个用于估计对称矩阵特征值和特征向量近似值的重要工具。

中山大学硕士学位论文基于概率的混合mini-max搜索算法姓名:梁彬申请学位级别:硕士专业:信息计算科学指导教师:冯国灿20060526第五章算法的实例化与算法的程序实现图5.2搜索树的节点复用6)招法生成嚣本系统招法的生成是通过查表实现的。
系统中内置一份“招法表”;其记录了各种类型的棋子可能的行走方式。
整个表采用c_+STI。
标准库中的vector对象进行组织。
招法生成器通过保留在每个节点中的整型下标在常时问(constanttime)内索引招法表以获得下一步可能的招法以及相应的棋盘局势。
7)招法验证器招法验证器由招法生成器进行驱动,为其生成的每一个招式进行合法性第六章实验、比较、及结论实验结果:我们得到了图6.2。
图6.2“帅四平五”关键招的出招概率变化统计图根据实验数据,PTP在第6局对奔时,走出了“帅五平四”的招法,并赢得了比赛的胜利,经过强化学习,WPRP将对这一招的加强十分明显,这从上图中第6局的跳跃可以看出来。
但遗憾的是,由于经验权值参数a仅为0.2,WPRP在做出决策时,还不能充分注意到这一招。
其问出现了不少平局。
从而使这一关键枝的遍历概率变小,直至PTP再次以此招获胜,该枝再次得到加强。
随着训练的深入,WPRP的遍历概率稳步提高(中问也会因平局而稍微下降),这也说明wPRP充分注意到了这一招,并且将之强化和运用,从而提高获胜的机会。
这从下面的对弈结果图(图6.3)看出来。
在出招结果统计表中,我们将双方每一招的结果进行纪录并绘制于该散点图之上。
如图所示,纵坐标值代表了结果(一1:PTP获胜;O:平局;1:WPRP获胜),横坐标代表了出招的编号(编号贯穿于整个批处理训练)。
可以看到,在前170招之内,仅有PTP有获胜纪录。
之后,随着经验权值参数a被增大为0.5,WPRP开始在做mini-max决策时更关注于枝遍历概率,并且开始在其作红方的时候走出“帅五平四”而取得胜利。
可以看到,在300招之后,双方获胜的频率已经非常接近了。
第3章 最小二乘法和最小二乘估计Chapter 3 Least Squares线性模型中的参数估计有多种方法,其中最小二乘法是最为著名的。
即使已经发现其他方法比较优越,但是最小二乘法仍然是线性模型估计的基础方法,最小二乘估计的性质已经得到了广泛应用。
§3.1 最小二乘回归(least squares regression)随机线性关系i i i y ε+'=βx 中的未知系数是我们考虑的重点,也是我们进行估计的主要目标。
这时我们有必要区分母体变量(例如β和i ε)和它们的样本估计,对应地表示为b 和i e 。
母体回归方程可以表示为:βx x i i i y E '=]|[它的估计表示为:b x i i y '=ˆ (3.1) 与第i 个数据点相关的扰动项可以表示为:βx i i i y '-=ε (3.2) 如果获得了回归系数的估计,则可以利用回归方程的残差来估计随机扰动项,即 b x i i i y e '-= (3.3) 根据这些定义和表示,可以得到:i i i i i e y +'=+'=b x βx ε (3.4)母体量β是每个i y 的概率分布中的未知系数,我们希望利用样本数据),(i i y x 来估计这些参数。
虽然这是一个统计推断问题,但是我们仍然可以直观地认为应该选取向量b ,使得拟合直线b x i '尽量地靠近数据点。
如果描述这种靠近性,需要一定的拟合准则,其中最为广泛使用的是最小二乘法。
§3.1.1 最小二乘系数向量可以通过极小化下述残差平方和来获得最小二乘系数向量。
∑∑=='-=n i i n i i y e120120)(b x (3.5) 其中0b 表示系数向量的选择。
利用矩阵形式表示上述残差平方和:)()()(Minminze 000000Xb y Xb y e e b b -'-='=S (3.6) 将上述目标函数展开得到(注意利用标量的转置不变的性质):0000002)(Xb X b Xb y y y e e b ''+'-'='=S (3.7)极小化的一阶条件为(相当于对向量求导数,要么利用向量展开,要么利用向量求导公式):022)(000='+'-=∂∂Xb X y X b b S (3.8) 假设b 是最小二乘的解,则它必须满足最小二乘正规方程(least square normal equations): y X Xb X '=' (3.9) 如果解释变量矩阵的满秩条件满足,则有:K rank rank K n K K =='⨯⨯)()(X X X这说明矩阵K K ⨯')(X X 是可逆矩阵,因此正规方程的唯一解为:y X X X b ''=-1)( (3.10) 注意到上述条件只是极小化问题的必要条件,为了判断充分性,我们需要求出目标函数的Hessian 矩阵:X X bb b '='∂∂∂2)(2S (3.11) 如果这个Hessian 矩阵是正定的,则可以判断所得到的解是唯一的最小二乘解。