抽样分布参数估计和假设检验
- 格式:docx
- 大小:49.35 KB
- 文档页数:28

参数估计与假设检验的区别和联系统计学方法包括统计描述和统计推断两种方法,其中,推断统计又包括参数估计和假设检验。
1.参数估计就是用样本统计量去估计总体的参数,它的方法有点估计和区间估计两种。
点估计是用估计量的某个取值直接作为总体参数的估计值。
点估计的缺陷是没法给出估计的可靠性,也没法说出点估计值与总体参数真实值接近的程度。
区间估计是在点估计的基础上给出总体参数估计的一个估计区间,该区间通常是由样本统计量加减估计误差得到的。
在区间估计中,由样本估计量构造出的总体参数在一定置信水平下的估计区间称为置信区间。
统计学家在某种程度上确信这个区间会包含真正的总体参数。
在区间统计中置信度越高,置信区间越大。
置信水平为1-a, a为小概率事件或者不可能事件,常用的置信水平值为99%,95%,90%,对应的a为0.01, 0.05,0.1置信区间是一个随机区间,它会因样本的不同而变化,而且不是所有的区间都包含总体参数。
一个总体参数的区间估计需要考虑总体是否为正态分布,总体方差是否已知,用于估计的样本是大样本还是小样本等(1)来自正态分布的样本均值,不论抽取的是大样本还是小样本,均服从正态分布(2)总体不是正态分布,大样本的样本均值服从正态分布,小样本的服从t 分布(3)不论已判断是正态分布还是t 分布,如果总体方差未知,都按t 分布来处理(4)t 分布要比标准正态分布平坦,那么要比标准正态分布离散,随着自由度的增大越接近(5)样本均数服从的正态分布为N(u a^2/n)远远小于原变量离散程度N (u a^2)2. 假设检验是推断统计的另一项重要内容,它与参数估计类似,但角度不同,参数估计是利用样本信息推断未知的总体参数,而假设检验则是先对总体参数提出一个假设值,然后利用样本信息判断这一假设是否成立。
假设检验的基本思想:先提出假设,然后根据资料的特点,计算相应的统计量,来判断假设是否成立,如果成立的可能性是一个小概率的话,就拒绝该假设,因此称小概率的反证法。

抽样分布的概念及重要性抽样分布是统计学中一个重要的概念,它描述了从总体中抽取样本的过程中,统计量的分布情况。
在统计学中,我们通常无法对整个总体进行研究,而是通过抽取样本来推断总体的特征。
抽样分布的概念帮助我们理解样本统计量的变异性,并为统计推断提供了理论基础。
本文将介绍抽样分布的概念及其重要性。
一、抽样分布的概念抽样分布是指在相同条件下,重复从总体中抽取样本,并计算样本统计量的分布情况。
在抽样分布中,样本统计量可以是样本均值、样本比例、样本方差等。
抽样分布的特点是,当样本容量足够大时,样本统计量的分布会趋近于一个稳定的形态,即抽样分布的形状不会随着样本的变化而变化。
抽样分布的形态通常可以用正态分布来近似描述。
中心极限定理是支持抽样分布近似为正态分布的重要理论基础。
根据中心极限定理,当样本容量足够大时,无论总体分布是什么形态,样本均值的抽样分布都会近似于正态分布。
这使得我们可以利用正态分布的性质进行统计推断。
二、抽样分布的重要性抽样分布在统计学中具有重要的意义和应用价值。
以下是抽样分布的几个重要方面:1. 参数估计:抽样分布为参数估计提供了理论基础。
通过从总体中抽取样本,我们可以计算样本统计量,并利用抽样分布的性质来估计总体参数。
例如,通过计算样本均值来估计总体均值,通过计算样本比例来估计总体比例等。
2. 假设检验:抽样分布为假设检验提供了理论依据。
在假设检验中,我们需要根据样本数据来判断总体参数是否符合某个假设。
抽样分布的性质可以帮助我们计算出假设检验的统计量,并进行显著性检验。
3. 置信区间:抽样分布为置信区间的构建提供了理论基础。
置信区间是用来估计总体参数的范围,它可以告诉我们总体参数的估计结果的可信程度。
抽样分布的性质可以帮助我们计算出置信区间,并确定置信水平。
4. 抽样方法选择:抽样分布的性质可以帮助我们选择合适的抽样方法。
不同的抽样方法会对样本统计量的抽样分布产生不同的影响。
通过了解抽样分布的性质,我们可以选择适合的抽样方法,以提高统计推断的准确性。

抽样分布一、抽样分布的理论及定理 (一) 抽样分布抽样分布是统计推断的基础,它是指从总体中随机抽取容量为n 的若干个样本,对每一样本可计算其k 统计量,而k 个统计量构成的分布即为抽样分布,也称统计量分布或随机变量函数分布。
(二) 中心极限定理中心极限定理是用极限的方法所求的随机变量分布的一系列定理,其内容主要反映在三个方面。
1.如果总体呈正态分布,则从总体中抽取容量为n 的一切可能样本时,其样本均数的分布也呈正态分布;无论总体是否服从正态分布,只要样本容量足够大,样本均数的分布也接近正态分布。
2.从总体中抽取容量为n 的一切可能样本时,所有样本均数的均数(X μ)等于总体均数(μ)即μμ=X3.从总体中抽取容量为n 的一切可能样本时,所有样本均数的标准差(X σ)等于总体标准差除以样本容量的算数平方根,即n X σσ=中心极限定理在统计学中是相当重要的。
因为许多问题都使用正态曲线的方法。
这个定理适于无限总体的抽样,同样也适于有限总体的抽样。
中心极限定理不仅给出了样本均数抽样分布的正态性依据,使得大多数数据分布都能运用正态分布的理论进行分析,而且还给出了推断统计中两个重要参数(即样本均数X μ与样本标准差X σ)的计算方法。
(三)抽样分布中的几个重要概念1.随机样本。
统计学是以概率论为其理论和方法的科学,概率又是研究随机现象的,因此进行统计推断所使用的样本必须为随机样本(random sample )。
所谓随机样本是指按照概率的规律抽取的样本,2.抽样误差。
从总体中抽取容量为n 的k 个样本时,样本统计量与总体参数之间总会存在一定的差距,而这种差距是由于抽样的随机性所引起的样本统计量与总体参数之间的不同,称为抽样误差。
3.标准误。
样本统计量分布的标准差或某统计量在抽样分布上的标准差,符号SE 或Xσ表示。
根据中心极限定理其标准差为n X σσ=正如标准差越小,数据分布越集中,平均数的代表性越好。


概率与统计中的抽样分布与假设检验概率与统计是一门研究随机事件及其规律的学科,其中抽样分布与假设检验是概率与统计学中至关重要的概念。
本文将介绍抽样分布的概念及其重要性,并探讨假设检验的原理和应用。
一、抽样分布在统计学中,抽样是指从总体中选取一部分样本进行观察和测量,通过对样本的分析和推断,得出对总体特征的结论。
而抽样分布则是在多次抽取样本的基础上得到的一组统计量的概率分布。
抽样分布的重要性在于它为统计推断提供了理论基础。
根据中心极限定理,当样本容量足够大时,样本均值的抽样分布近似服从正态分布。
这意味着通过对样本数据的分析,我们可以对总体特征进行合理的推断和估计。
二、假设检验假设检验是概率与统计学中常用的分析方法,用于检验关于总体参数的某种假设。
它基于样本数据,通过比较样本统计量与假设值之间的差异,来判断是否拒绝或接受某个假设。
假设检验的基本步骤包括:1. 建立原假设(H0)和备择假设(H1):原假设通常是关于总体特征的某种陈述,而备择假设则是与原假设相对立的假设。
2. 选择适当的检验统计量:根据具体问题选择合适的统计量进行计算和分析。
3. 确定显著性水平(α):显著性水平是进行假设检验时预先设定的一个界限,用来判断是否拒绝原假设。
通常将显著性水平设定为0.05或0.01。
4. 计算检验统计量的观察值:通过对样本数据进行计算,得到实际的检验统计量的值。
5. 判断检验统计量的观察值是否落在拒绝域内:拒绝域是指在显著性水平下,根据分布函数得到的一组临界值。
如果观察值落在拒绝域内,则拒绝原假设;否则,接受原假设。
6. 得出结论:根据判断结果,对于原假设的合理性进行结论。
假设检验在实际问题中有着广泛的应用。
例如,在医学研究中,可以使用假设检验来判断新药物是否对疾病有显著疗效;在工商管理中,可以使用假设检验来判断某种市场策略是否能够提高销售业绩。
总结:概率与统计中的抽样分布与假设检验是概率与统计学的重要概念。

参数估计和假设检验1.参数估计参数估计是指通过样本数据来推断总体参数的过程。
总体参数是指总体的其中一种性质,比如总体均值、总体方差等。
样本数据是从总体中随机抽取的一部分数据,用来代表总体。
参数估计的目标是使用样本数据来估计总体参数的值。
常见的参数估计方法有点估计和区间估计。
(1)点估计点估计是通过一个统计量来估计总体参数的值。
常见的点估计方法有样本均值、样本方差等。
点估计的特点是简单、直观,但是估计值通常是不准确的。
这是因为样本的随机性导致样本统计量有一定的误差。
因此,点估计通常会伴随着误差界限,即估计值的置信区间。
(2)区间估计区间估计是通过一个统计量构建总体参数的估计区间。
常见的区间估计方法有置信区间和可信区间。
置信区间是指当重复抽样时,包含真实总体参数的概率。
置信区间的计算方法是在样本统计量的基础上,加减一个合适的误差界限,得到一个估计区间。
可信区间是指在一次抽样中,包含真实总体参数的概率。
可信区间的计算方法同样是在样本统计量的基础上,加减一个合适的误差界限,得到一个估计区间。
参数估计的应用非常广泛,可以用于各个领域的数据分析和决策。
例如,经济学家可以通过样本数据估计失业率,政治学家可以通过样本数据估计选举结果,医学研究者可以通过样本数据估计药物的疗效等。
2.假设检验假设检验是指通过样本数据来判断总体参数的其中一种假设是否成立。
在假设检验中,我们先提出一个原假设(H0),然后使用样本数据来检验该假设的合理性。
在假设检验中,我们需要确定一个统计量,该统计量在原假设成立时,其分布是已知的。
然后,我们计算该统计量在样本数据下的取值,并通过比较该取值与已知分布的临界值,来判断原假设是否成立。
假设检验包含两种错误,即第一类错误和第二类错误。
第一类错误是指在原假设成立的情况下,拒绝原假设的错误概率。
第二类错误是指在原假设不成立的情况下,接受原假设的错误概率。
常见的假设检验方法有单样本假设检验、双样本假设检验、方差分析等。

统计学原理教案中的抽样与抽样分布揭示学生如何进行抽样和利用抽样分布进行推断统计学是一门研究收集、分析和解释数据的学科,而抽样和抽样分布则是统计学中至关重要的概念。
本文将探讨统计学原理教案中的抽样和抽样分布,以揭示学生如何进行抽样和利用抽样分布进行推断。
首先,我们来理解抽样的概念。
在统计学中,抽样是指从总体中选择一部分个体进行观察和研究。
总体是指我们感兴趣的整体,而样本则是从总体中选取的一部分个体。
通过抽样,我们可以通过研究样本来推断总体的特征,这是由于抽样的随机性能够保证样本与总体的代表性。
接下来,让我们了解抽样的方法。
常见的抽样方法包括简单随机抽样、系统抽样、分层抽样和整群抽样等。
每种抽样方法都有其特点和适用范围。
简单随机抽样是一种随机选择样本的方法,每个个体被选择的概率相同。
系统抽样是按照一定的规律选择样本,例如每隔一定数量选择一个个体。
分层抽样是将总体分成若干层次,然后从每个层次中抽取样本。
整群抽样则是将总体分成若干群体,然后随机选择一些群体并全面调查其中的个体。
选择合适的抽样方法可以更好地保证样本的代表性和可靠性。
抽样之后,我们需要了解抽样分布的概念。
在统计学中,抽样分布是指根据大量抽样的结果所得到的分布。
常见的抽样分布包括正态分布、t分布和F分布等。
其中,正态分布是抽样分布的重要特例,它在许多情况下都可以作为近似的抽样分布来使用。
t分布则用于小样本情况下的推断,它相比于正态分布更为宽阔且更适用于样本数据较少的情况。
F分布常用于分析方差比较和回归模型中的显著性分析。
抽样分布的重要性在于它可以帮助我们进行推断。
根据抽样分布的性质,我们可以利用统计推断方法进行参数估计和假设检验。
参数估计是根据样本的统计量来估计总体的参数值,例如通过样本均值估计总体均值。
假设检验是用来判断总体参数是否在某个范围内或是否相等的统计方法。
通过抽样分布的理论知识,我们可以进行参数估计和假设检验,并对总体进行推断。
在统计学原理教案中,抽样和抽样分布是学生学习的重点内容。


概率论与数理统计实验实验3 参数估计假设检验实验目的实验内容直观了解统计描述的基本内容。
2、假设检验1、参数估计3、实例4、作业一、参数估计参数估计问题的一般提法X1, X2,…, Xn要依据该样本对参数作出估计,或估计的某个已知函数.现从该总体抽样,得样本设有一个统计总体,总体的分布函数向量). 为F(x, ),其中为未知参数( 可以是参数估计点估计区间估计点估计——估计未知参数的值区间估计——根据样本构造出适当的区间,使他以一定的概率包含未知参数或未知参数的已知函数的真?(一)、点估计的求法1、矩估计法基本思想是用样本矩估计总体矩.令设总体分布含有个m未知参数??1 ,…,??m解此方程组得其根为分别估计参数??i ,i=1,...,m,并称其为??i 的矩估计。
2、最大似然估计法(二)、区间估计的求法反复抽取容量为n的样本,都可得到一个区间,这个区间可能包含未知参数的真值,也可能不包含未知参数的真值,包含真值的区间占置信区间的意义1、数学期望的置信区间设样本来自正态母体X(1) 方差?? 2已知, ?? 的置信区间(2) 方差?? 2 未知, ?? 的置信区间2、方差的区间估计未知时, 方差?? 2 的置信区间为(三)参数估计的命令1、正态总体的参数估计设总体服从正态分布,则其点估计和区间估计可同时由以下命令获得:[muhat,sigmahat,muci,sigmaci] = normfit(X,alpha)此命令以alpha 为显著性水平,在数据X下,对参数进行估计。
(alpha缺省时设定为0.05),返回值muhat是X的均值的点估计值,sigmahat是标准差的点估计值, muci是均值的区间估计,sigmaci是标准差的区间估计.例1、给出两列参数?? =10, ??=2正态分布随机数,并以此为样本值,给出?? 和?? 的点估计和区间估计命令:r=normrnd(10,2,100,2);[mu,sigm,muci,sigmci]=normfit(r);[mu1,sigm1,muci1,si gmci1]=normfit(r,0.01);mu=9.8437 9.9803sigm=1.91381.9955muci=9.4639 9.584310.2234 10.3762sigmci=1.68031.75202.2232 2.3181mu1=9.8437 9.9803sigm1=1.91381.9955muci1=9.3410 9.456210.3463 10.5043sigmci1=1.6152 1.68412.3349 2.4346例2、产生正态分布随机数作为样本值,计算区间估计的覆盖率。

参数估计和假设检验参数估计和假设检验是统计学中常用的两种方法,用于根据样本数据对总体的特征进行推断和判断。
参数估计是通过样本数据估计总体参数值的方法,而假设检验则是基于样本数据对总体参数假设进行判断的方法。
下面将详细介绍这两种方法以及它们的应用。
1.参数估计参数是指总体特征的度量,比如总体均值、总体方差等。
在实际应用中,我们往往无法得到总体数据,只能通过抽样得到样本数据。
参数估计的目标是利用样本数据去估计总体参数的值。
最常用的参数估计方法是点估计和区间估计:-点估计是使用样本统计量来估计总体参数的值,常用的样本统计量有样本均值、样本方差等。
-区间估计是利用样本数据构建一个置信区间,用来估计总体参数的取值范围。
置信区间的计算方法通常是基于样本统计量的分布进行计算。
在进行参数估计时,需要注意以下几个要点:-选择适当的样本容量和抽样方法,确保样本具有代表性,并满足参数估计的要求。
-选择适当的样本统计量进行参数估计,并对其进行合理的解释与限制。
-利用抽样分布特性和统计理论,计算参数估计的标准误差和置信区间,对参数估计结果进行解释和判断。
2.假设检验假设检验是基于样本数据对总体参数假设进行判断的方法。
在实际问题中,我们常常需要根据样本数据来判断一些总体参数是否达到一些要求或存在其中一种关系。
假设检验的基本步骤:-建立原假设(H0)和备择假设(H1)。
原假设通常是对总体参数取值的一种假设,备择假设则是原假设的对立假设。
-选择适当的统计量用来检验假设,并计算样本统计量的检验统计量。
-根据样本数据计算得出的检验统计量,利用抽样分布特性和统计理论计算P值。
-根据P值与事先设置的显著性水平进行比较,如果P值小于显著性水平,则拒绝原假设;反之,接受原假设。
在进行假设检验时,需要注意以下几个要点:-显著性水平的选择:显著性水平(α)是进行假设检验过程中设置的一个临界值,它反映了能够容忍的错误发生的概率。
常用的显著性水平有0.05和0.01-选择适当的统计量与检验方法:根据问题的性质和数据类型选择适当的统计量和检验方法。
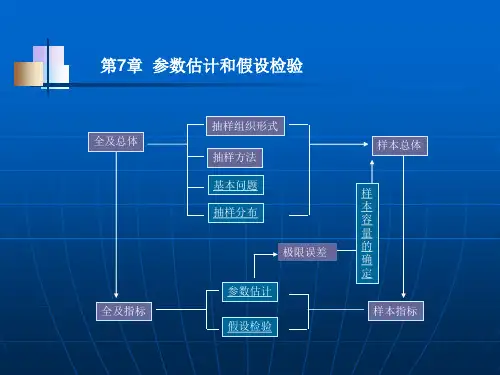
第4章参数估计和假设检验第四章参数估计与假设检验掌握参数估计和假设检验的基本思想是正确理解和应⽤其他统计推断⽅法的基础,后⾯将要学习的⽅差分析、⾮参数检验、回归分析、时间序列等统计推断⽅法都是在此基础上展开的。
需要特别指出的是,所有的统计推断都要以随机样本为基础。
如果样本是⾮随机的,统计推断⽅法就不适⽤了。
由于相关知识在先修课程中已经学习过,本章主要在回顾相关知识的基础上,补充讲解必要样本容量的计算、p值、参数估计和假设检验⽅法的软件操作和结果分析等内容。
本章的主要内容包括:(1)参数估计的基本思想和软件实现。
(2)简单随机抽样情况下样本容量的计算。
(3)假设检验的基本原理。
(4)假设检验中的p值。
(5)⼏种常⽤假设检验的软件实现。
第⼀节参数估计⼀、参数估计的基本概念参数估计是指利⽤样本信息对总体数字特征作出的估计。
例如,我们可以通过估计⼀部分产品的合格率对整批产品的合格率作出估计,通过调查⼀个样本的⼈⼝数来对全国的⼈⼝数作出估计,等等。
参数估计可以分为点估计和区间估计。
点估计是指根据样本数据给出的总体未知参数的⼀个估计值。
对总体参数进⾏估计的⽅法可以有多种,例如矩估计法、极⼤似然估计法等,得到的估计量(样本统计量)并不是唯⼀的。
例如我们可以使⽤样本均值对总体均值作出估计,也可以使⽤样本中位数对总体均值进⾏估计。
因此,在参数估计中我们需要对估计量的好坏作出评价,这就涉及到估计量的评价准则问题。
常⽤的估计量评价准则包括⽆偏性、有效性、⼀致性等。
⽆偏性是指估计量的数学期望与总体参数的真实值相等;有效性的含义是,在两个⽆偏估计量中⽅差较⼩的估计量较为有效,⽅差越⼩越有效;⼀致性是指随着样本容量的增⼤,估计量的取值应该越来越接近总体参数。
样本的随机性决定了估计结果的随机性。
由于每⼀个点估计值都来⾃于⼀个随机样本,所以总体参数真值刚好等于⼀个具体估计值的可能性极⼩。
区间估计的⽅法则以概率论为基础,在点估计的基础上给出了⼀个置信区间,并给出了这⼀区间包含总体真值的概率,⽐点估计提供了更多的信息。
(抽样检验)抽样与参数估计最全版(抽样检验)抽样与参数估计抽样和参数估计推断统计:利⽤样本统计量对总体某些性质或数量特征进⾏推断。
从数据得到对现实世界的结论的过程就叫做统计推断(statisticalinference)。
这个调查例⼦是估计总体参数(某种意见的⽐例)的壹个过程。
估计(estimation)是统计推断的重要内容之壹。
统计推断的另壹个主要内容是本章第⼆节要介绍的假设检验(hypothesistesting)。
因此本节内容就是由样本数据对总体参数进⾏估计,即:学习⽬标:了解抽样和抽样分布的基本概念理解抽样分布和总体分布的关系了解点估计的概念和估计量的优良标准掌握总体均值、总体⽐例和总体⽅差的区间估计第⼀节抽样和抽样分布回顾相关概念:总体、个体和样本抽样推断:从所研究的总体全部元素(单位)中抽取壹部分元素(单位)进⾏调查,且根据样本数据所提供的信息来推断总体的数量特征。
总体(Population):调查研究的事物或现象的全体参数个体(Itemunit):组成总体的每个元素样本(Sample):从总体中所抽取的部分个体统计量样本容量(Samplesize):样本中所含个体的数量壹般将样本单位数不少于三⼗个的样本称为⼤样本,样本单位数不到三⼗个的样本称为⼩样本。
壹、抽样⽅法及抽样分布1、抽样⽅法(1)、概率抽样:根据已知的概率选取样本①、简单随机抽样:完全随机地抽选样本,使得每壹个样本都有相同的机会(概率)被抽中。
注意:在有限总体的简单随机抽样中,由抽样是否具有可重复性,⼜可分为重复抽样和不重复抽样。
⽽且,根据抽样中是否排序,所能抽到的样本个数往往不同。
②、分层抽样:总体分成不同的“层”(类),然后在每壹层内进⾏抽样③、整群抽样:将壹组被调查者(群)作为壹个抽样单位④、等距抽样:在样本框中每隔壹定距离抽选壹个被调查者(2)⾮概率抽样:不是完全按随机原则选取样本①、⾮随机抽样:由调查⼈员⾃由选取被调查者②、判断抽样:通过某些条件过滤来选择被调查者(3)、配额抽样:选择壹群特定数⽬、满⾜特定条件的被调查者2、抽样分布壹般地,样本统计量的所有可能取值及其取值概率所形成的概率分布,统计上称为抽样分布(samplingdistribution)。
统计学中的参数估计与假设检验统计学是一门研究如何收集、整理、分析和解释数据的学科。
参数估计和假设检验是统计学中两个重要的概念和方法,用于推断总体参数和判断假设是否成立。
本文将详细介绍参数估计与假设检验的基本原理和应用。
一、参数估计参数估计是通过样本数据推断总体的未知参数。
在统计学中,总体是指研究对象的全体,而样本是从总体中抽取的一部分。
参数是总体的特征指标,例如均值、方差、比例等。
参数估计旨在通过样本数据对总体参数进行估计,并给出估计的精度。
参数估计分为点估计和区间估计两种方法。
点估计是通过样本数据计算得到的单个数字,用来估计总体参数的具体数值。
常见的点估计方法有最大似然估计、矩估计和贝叶斯估计等。
区间估计是通过样本数据计算得到的一个范围,该范围包含总体参数真值的概率较高。
置信区间是区间估计的一种形式,它可以用来描述估计值的不确定性。
二、假设检验假设检验是用于检验研究问题的特定假设是否成立的一种统计推断方法。
在假设检验中,我们提出一个原假设和一个备择假设,并根据样本数据对两个假设进行比较,进而判断原假设是否应该被拒绝。
原假设通常表示一种无关,即不发生预期效应或差异。
备择假设则表示研究者所期望的效应或差异。
在进行假设检验时,我们首先选择一个适当的统计检验方法,例如t检验、F检验或卡方检验等。
然后,计算出样本数据的检验统计量,并根据相关的分布理论和显著性水平进行推论。
最后,比较检验统计量与临界值,以决定是否拒绝原假设。
三、参数估计与假设检验的应用参数估计和假设检验在实际问题中有广泛的应用。
以医学研究为例,研究人员可能希望通过抽样来估计某种药物的有效剂量,并对药效进行假设检验。
在市场调研中,我们可以使用参数估计和假设检验来推断总体的需求曲线和做出市场预测。
在质量控制中,我们可以利用参数估计和假设检验来判断产品是否符合标准。
四、总结参数估计和假设检验是统计学中重要的方法,可以通过样本数据来推断总体参数和判断假设是否成立。
抽样分布参数估计和假设检验一、抽样分布的理论及定理(一)抽样分布抽样分布是统计推断的基础,它是指从总体中随机抽取容量为n的若干个样本,对每一样本可计算其k统计量,而k个统计量构成的分布即为抽样分布,也称统计量分布或随机变量函数分布。
(二)中心极限定理中心极限定理是用极限的方法所求的随机变量分布的一系列定理,其内容主要反映在三个方面。
1.如果总体呈正态分布,则从总体中抽取容量为n的一切可能样本时,其样本均数的分布也呈正态分布;无论总体是否服从正态分布,只要样本容量足够大,样本均数的分布也接近正态分布。
均数()即2.从总体中抽取容量为n的一切可能样本时,所有样本均数的均数(某)等于总体某3.从总体中抽取容量为n的一切可能样本时,所有样本均数的标准差(某)等于总体标准差除以样本容量的算数平方根,即某n中心极限定理在统计学中是相当重要的。
因为许多问题都使用正态曲线的方法。
这个定理适于无限总体的抽样,同样也适于有限总体的抽样。
中心极限定理不仅给出了样本均数抽样分布的正态性依据,使得大多数数据分布都能运用正态分布的理论进行分析,而且还给出了推断统计中两个重要参数(即样本均数某与样本标准差某)的计算方法。
(三)抽样分布中的几个重要概念1.随机样本。
统计学是以概率论为其理论和方法的科学,概率又是研究随机现象的,因此进行统计推断所使用的样本必须为随机样本(randomample)。
所谓随机样本是指按照概率的规律抽取的样本,2.抽样误差。
从总体中抽取容量为n的k个样本时,样本统计量与总体参数之间总会存在一定的差距,而这种差距是由于抽样的随机性所引起的样本统计量与总体参数之间的不同,称为抽样误差。
3.标准误。
样本统计量分布的标准差或某统计量在抽样分布上的标准差,符号SE或某表示。
根据中心极限定理其标准差为某n★(問答爲什麽說標準誤是進行統計推斷可靠性高低的標準)正如标准差越小,数据分布越集中,平均数的代表性越好。
同理,在推断统计中,标准误越小,说明样本统计量与总体参数的之间越接近,即样本对总体的代表性越好,这时用样本统计量去推断总体就越可靠、越准确;相反,标准误越大,说明样本统计量与总体参数之间的差距越大,即样本对总体的代表性越差,这时用样本统计量去推断总体就越不可靠、越不准确。
所以说标准误是进行统计推断可靠性高低的指标。
4.自由度。
一群数据或观测值可以独立自由变动的数目称为自由度,用符号df或n表示。
在某某N中,dfN。
在计算方差或标准差时,因受某某0的限制,dfN1,即有方差二、常用抽样分布S2某某N12。
在心理与教育统计中,常用的抽样分布有正态分布、渐近正态分布、t分布、F分布、q分布和2分布等等。
(一)正态分布及渐近正态分布当统计量的分布符合正态分布或渐近正态分布时,进行统计推论的理论依据即为正态分布的理论。
以样本平均数为例,正态分布的应用情形如下。
1.总体呈正态,总体方差已知,则样本均数的分布也呈正态。
根据中心极限定理则有①样本均数的均数等于总体均数,即某②样本均数的标准差等于总体标准差除以样本容量的平方根,即2某nZ③差异检验值为某SE某22.总体呈非正态,总体方差已知,样本容量n足够大,样本均数的分布为渐近正态分布。
根据中心极限定理,亦有①样本均数的均数等于总体均数:某②样本均数的标准差等于总体标准差除以样本容量的平方根。
某nZ③检验值某SE某(二)t分布1.t分布的定义t分布是由小样本统计量形成的概率分布。
2.t分布的特点①t分布也是对称分布。
即平均数位于曲线的中央,在这一点上有一个单峰,从中央向两侧逐渐下降,尾部无限延长,但不与基线相交。
②t分布曲线的形状易变,曲线不是一条而是一族,其曲线形状随着样本容量的变化而有规律地变动,即随自由度的大小而变化。
③理论上,当n→∞时,t分布曲线以标准正态曲线为极限,即呈正态分布。
当n逐渐减少时,分布的离散程度逐渐增大,曲线逐渐与标准正态分离;其峰顶逐渐下降,尾部抬高。
④t分布的t值及对应的概率值(p)是根据自由度的大小由理论模型推导出来的,构成t分布临界值,表见附表4。
3.t分布的应用1)总体正态,未知,且n<30时,样本平均数的分布呈t分布。
2t分布的标准误为SE某Snn1或SE某Sn1n因为总体标准差未知,只能以样本标准差Sn来代替。
而样本标准差Sn与总体标准差的差距较大,统计学家发现总体标准差的良好无偏估计量为Sn1,即Sn1某某N12所以用Sn1代替则有上式。
t分布的检验值为t22)总体呈非正态,未知,n>30时,则样本均数的分布呈t分布或渐近正态分布,其①样本均数的标准误为某SE某SE某检验值为Snn1或SE某Sn1n某某ZSE某或SE某2此外,当未知时,两个样本均数之差(某1某2)的分布、相关系数的分布、回归t系数的分布等也服从近似正态分布。
参数估计第一节统计推断的有关问题一、什么是推断统计推断统计根据推测的性质不同而分为参数估计和假设检验两方面。
参数估计是用样本去估计相应总体的状况,其具体方法有点估计和区间估计。
假设检验的主要用途是对出现差异的两个或多个现象或事物进行真实性情况的检验,又称统计检验。
它又为参数检验和非参数检验。
参数检验法在检验时对总体分布和总体参数(,)有所要求,而非参数检验法2在检验时则不依赖于总体的分布形态和总体参数的情况。
二、统计推断的基本问题进行统计推断时应首先考虑以下三个方面的问题。
一是关于统计推断的基本前提。
统计推断的前提是随机抽样。
进行统计推断时,首先要了解抽样的方式,是随机抽取的,还是人为抽取的。
二是样本的规模与样本的代表性。
抽样研究需要有一定的样本规模,而样本要具有代表性也需要有一定的样本规模来保证,以减少抽样误差。
值得注意的样本规模和样本代表性是建立在随机抽样基础之上的,否则即使样本再大也是无意义的。
三是统计推断的错误要有一定限度。
统计推断是在特定的时间、空间和条件下得出的结论,加上抽样误差的影响,在用样本推测总体时总会犯一定的错误。
但这种错误要有一定的限度,统计推断中允许犯错误的限度是用小概率事件来表示。
第二节参数估计的原理一、参数估计的定义所谓参数估计就是根据样本统计量去估计相应总体的参数。
二、参数估计的方法(一)点估计点估计是在参数估计中直接以样本的统计量(数轴上的一个点)作为总体参数的估计值。
良好点估计的统计量必须具备一定的前提条件。
1.无偏性无偏性要求在用各个样本的统计量作为估计值时,其偏差为0,即某2.一致性总体参数的估计量随样本容量的无限增大,应当能越来越接近它所估计的总体参数。
此3.有效性当总体参数的无偏估计量不止一个统计量时,则要分析无偏估计量的变异大小的情况。
无偏估计量变异性小的,有效性较高;无偏估计量变异性大的,则有效性较低。
用统计量——样本均数作为总体参数的估计值是最佳选择。
4.充分性充分性是指一个容量为n的样本统计量是否充分地反映了全部n个数所反映的总体信息。
(二)区间估计区间估计是以一个统计量的区间来估计相应的总体,它要求按照一定的概率要求,根据样本统计量来估计总体参数可能落入的数值范围。
区间估计是用两个数之间的距离或数轴上的一段距离来表示未知参数可能落入的范围。
1.区间估计的标准误某SE某n2.置信区间、置信系数和置信限在1.96某中有三个重要概念,置信区间、置信系数和置信限。
置信区间是指在特定的可靠性(即置信系数)要求下,估计总体参数所落的区间范围,亦即进行估计的全距。
以样本均数(某)为例,在估计总体均数()时,其置信区间为某1.96某<<某1.96某某2.58某<<某2.58某置信系数是指被估计的总体参数落在置信区间内的概率D,或以1表示。
又叫置信水平、置信度、可靠性系数和置信概率。
置信系数是用来说明置信区间可靠程度的概率,也是进行正确估计的概率。
一个置信系数同时反映了在做出一个估计时所犯错误的小概率(),即可靠性为95%时,意味着犯错误的概率为5%;可靠性为99%时,意味着犯错误的概率为1%。
置信限是被估计的总体参数所落区间的上、下界限,即某1.96某<<某1.96某置信下限置信上限例8-1:某次测验中有10个正误判断题,试问在置信系数为0.95时,能猜对多少道题?根据二项分布的平均数与标准差公式,有15211某npq101.582251.961.58532~8某np103.置信区间与置信系数的关系在进行参数估计时,一般人首先想到的是选用一个较高的置信系数,以为这样就会得到一个精确度很高的估计值。
然而,实际情况并非如此,一个较高的置信系数并不意味着有一个较精确的估计。
事实上高的置信系数会造成置信区间的扩大,而一种跨距很大的区间本身又会降低估计精确性,结果只能给我们一个非常模糊的估计数。
如例8-1,D0.95时,2~8;D0.99时,1~9。
因此置信系数和置信区间在估计时应综合考虑。
当置信区间过于宽大时,即使估计达到了99%的置信系数,其估计结果可能很少有真实的价值;相反,置信区间过于狭窄,其估计与一个低水平的置信系数相联,估计结果的真实价值也值得怀疑。
一般来说,最佳的估计既要求置信区间适度,又要求置信系数较高。
第三节总体均数的估计一、均数估计的标准误(一)标准误的定义式——已知当总体σ2已知时,根据中心极限定理三有2某SE某n某nn2其区间估计公式为某1.96某某2.58某(二)标准误的近似式——未知2SE某Sn1二、总体均数的估计方法(一)正态估计法,σ2已知一是总体呈正态时,不论样本容量的大小,样本均数的分布都呈正态分布。
二是总体呈非正态时,只要样本容量大于30,样本均数的分布呈近似正态分布。
例8-2:已知某总体为正态分布,其总体标准差为10。
现从这个总体中随机抽取n1=20,n2=30的两个样本,其平均数分别80和82。
试问总体参数μ在0.95和0.99的置信区间是多少。
1)分析条件,判断方法根据题目信息可知,总体分布为正态,且总体方差已知(正态法进行估计。
2)求样本均数的标准误2100)已知,所以可用某SE某n10SE某12.24n2010SE某21.82n303)求置信区间:①D=0.95时,801.962.24804.3975.61~84.39D=0.99时,802.582.24805.7874.22~85.78②D=0.95时,821.961.28823.5778.43~85.57D=0.99时,822.581.82804.6074.40~86.604)结果解释计算结果表明,以第一个样本进行估计时,其总体均数μ落在75.61~84.39之间的可能性为95%,超出这一范围的可能只有5%;或者说μ可能在75.61~84.39之间的正确估计概率为95%,错误估计概率为5%。
而作出总体μ落在74.22~85.78之间结论时的正确概率为99%,犯错误的可能性为1%。