SPSS软件实例应用(计量地理学课后题详解)
- 格式:pptx
- 大小:2.25 MB
- 文档页数:20

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第9章SPSS的线性回归分析1、利用第2章第9题的数据,任意选择两门课程成绩作为解释变量和被解释变量,利用SPSS提供的绘制散点图功能进行一元线性回归分析。
请绘制全部样本以及不同性别下两门课程成绩的散点图,并在图上绘制三条回归直线,其中,第一条针对全体样本,第二和第三条分别针对男生样本和女生样本,并对各回归直线的拟和效果进行评价。
选择fore和phy两门成绩体系散点图步骤:图形→旧对话框→散点图→简单散点图→定义→将fore导入Y轴,将phy导入X轴,将sex导入设置标记→确定。
接下来在SPSS输出查看器中,双击上图,打开图表编辑在图表编辑器中,选择“元素”菜单→选择总计拟合线→选择线性→应用→再选择元素菜单→点击子组拟合线→选择线性→应用。
分析:如上图所示,通过散点图,被解释变量y(即:fore)与解释变量phy有一定的线性关系。
但回归直线的拟合效果都不是很好。
2、请说明线性回归分析与相关分析的关系是怎样的?相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。
相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。
只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。
如果在没有对变量之间是否相关以及相关方向和程度做出正确判断之前,就进行回归分析,很容易造成“虚假回归”。
与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。
线性回归分析是相关性回归分析的一种,研究的是一个变量的增加或减少会不会引起另一个变量的增加或减少。
3、请说明为什么需要对线性回归方程进行统计检验?一般需要对哪些方面进行检验?检验其可信程度并找出哪些变量的影响显著、哪些不显著。

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第2章SPSS数据文件的建立和管理1、SPSS中有哪两种基本的数据组织形式?各自的特点和应用场合是什么?SPSS中两个基本的数据组织方式:原始数据的组织方式和计数数据的组织方式。
●原始数据的组织方式:待分析的数据是一些原始的调查问卷数据,或是一些基本的统计指标。
●计数数据的组织方式:所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的数据。
2、什么是SPSS的个案?什么SPSS的变量?个案:在原始数据的组织方式中,数据编辑器窗口中的一行称为一个个案或观测。
变量:数据编辑器窗口中的一列。
3、在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?默认的变量名:VAR------;默认的变量类型:数值型。
变量名标签和变量值标签可增强统计分析结果的可读性。
4、收集到以下关于两种减肥产品试用情况的调查数据,请问在SPSS中应如何组织该份资料?产品类型体重变化情况明显减轻无明显变化第一种产品27 19第二种产品20 33问:在SPSS中应如何组织该数据?数据文件如图所示:5、什么是SPSS的用户缺失值?为什么要对用户缺失值进行定义?如何在SPSS中指定用户缺失值?缺失值分为用户缺失值(User Missing Value)和系统缺失值(System MissingValue)。
用户缺失值指在问卷调查中,将无回答的一些数据以及明显失真的数据当作缺失值来处理。
用户缺失值的编码一般用研究者自己能够识别的数字来表示,如“0”、“9”、“99”等。
系统缺失值主要指计算机默认的缺失方式,如果在输入数据时空缺了某些数据或输入了非法的字符,计算机就把其界定为缺失值,这时的数据标记为一个圆点“•”。
在变量视图中定义。
6、从计量尺度角度看,变量包括哪三种主要类型?请各举出一个相应的实际数据。
《计量地理学》各章习题第一章1.在地理学研究中应用数学方法应该注意哪些问题?2.在现代地理学中,应用了哪些主要的数学方法,其主要用途是什么?3.怎样评价现代地理学中应用数学方法,在我国地理学界对数学方法应用的情况怎样?第二章1.根据1990~2003年的中国经济统计年鉴,以各省(直辖市、自治区)的GDP数据为变量,运用平均值、方差、变异系数等统计量,对全国各年经济发展的一般水平、差异情况进行计算和分析。
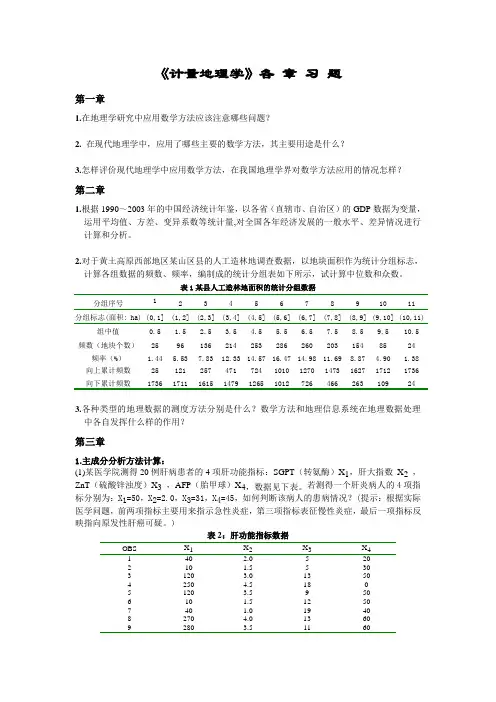
2.对于黄土高原西部地区某山区县的人工造林地调查数据,以地块面积作为统计分组标志,计算各组数据的频数、频率,编制成的统计分组表如下所示,试计算中位数和众数。
表1某县人工造林地面积的统计分组数据分组序号 1 2 3 4 5 6 7 8 9 10 11分组标志(面积: ha) (0,1] (1,2] (2,3] (3,4] (4,5] (5,6] (6,7] (7,8] (8,9] (9,10] (10,11) 组中值0.5 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 10.5 频数(地块个数)25 96 136 214 253 286 260 203 154 85 24 频率(%) 1.44 5.53 7.83 12.33 14.57 16.47 14.98 11.69 8.87 4.90 1.38 向上累计频数25 121 257 471 724 1010 1270 1473 1627 1712 1736 向下累计频数1736 1711 1615 1479 1265 1012 726 466 263 109 243.各种类型的地理数据的测度方法分别是什么?数学方法和地理信息系统在地理数据处理中各自发挥什么样的作用?第三章1.主成分分析方法计算:(1)某医学院测得20例肝病患者的4项肝功能指标:SGPT(转氨酶)X1,肝大指数X2,ZnT(硫酸锌浊度)X3,AFP(胎甲球)X4,数据见下表。

相关分析目的:揭示地理要素之间相互关系的密切程度。
实际操作:第一步,我们应该主观列出一些影响Y的一些X,选择相关分析的方法,如果只是两个要素之间的关系,我们采用简单相关,秩相关的方法,如果要是想研究多个要素之间的关系,我们可以采用偏相关和复相关的方法。
第二步,绘制散点图判断是否线性相关,进行正态性检验(检验方法:选用SPSS中的正态性检验功能,样本数>50选用K-S,<50选用S-W,sig值<0.05非正态,>0.05正态)。
第三步,计算相关系数。
如果正态性检验通过,我们就可以进行简单相关的分析(使用SPSS计算其Person 相关系数,绝对值越接近1表示相关性越强),正态性检验没有通过,选用秩相关的方法(秩相关是将两要素的样本值按数据的大小顺序排列位次,以各要素样本值的位次代替实际数据而求得的一种统计量)(使用SPSS软件计算Spearman系数)。
第四步,对所求系数进行显著性检验。
(|r|>rα,p<α,拒绝零假设,表示他们相关性显著。
其中P在SPSS中是P值下的Sig值,小于0.05拒绝零假设,大于0.05承认零假设。
r(相关系数)在实际中可以用查表法进行检验,注意其中f=n-2,这里容易出错误!)偏相关检验方法:常使用t检验的方法。
(|t|> tα, p<α,拒绝零假设,表示他们相关性显著。
需要自己计算t=偏相关系数/根号下(1-偏相关系数的平方)*根号下(n-m-1),n是样本数,m是自变量个数。
)*复相关系数检验方法:常使用F检验的方法。
(f> fα, p<α,拒绝零假设,表示他们相关性显著。
)回归分析目的:找出影响Y的影响源X,对以后的发展进行预测。
实际操作:第一步,如果只是研究两个变量之间的相关关系,我们可以选用一元线性回归模型,绘制散点图,选择线形回归还是非线性回归,如果是非线性那么我们化为线性进行参数结算,线性直接进行计算。

统计分析与SPSS 的应用(第五版)》(薛薇)课后练习答案第 5 章SPSS 的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→ 分析→ 比较均值→ 单样本t 检验→ 相关设置→ 输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N均值标准差均值的标准误成绩1173.739.551 2.880单个样本检验检验值= 75tdf Sig.(双侧)均值差值差分的95% 置信区间下限上限成绩-.44210.668-1.273-7.69 5.14分析:指定检验值: 在test 后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean )为73.7 ,标准差(std.deviation )为9.55 ,均值标准误差均值标准误差(std errormean )为2.87. t 统计量观测值统计量观测值为-4.22 ,t 统计量观测值的双尾概率p-值(sig.(2-tailed ))为0.668 ,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较a 和p 。
T 统计量观测值的双尾概率p-值(sig.(2-tailed ))为0.66 8>a=0.05 所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内, 所以经理的话是可信的。

spss习题及其答案
SPSS习题及其答案
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学和商业研究。
它可以帮助研究人员对数据进行分析、建模和预测。
在学习和使用SPSS的过程中,习题和答案是非常重要的,可以帮助我们更好地理解和掌握SPSS的使用方法和技巧。
下面是一些常见的SPSS习题及其答案,供大家参考:
1. 问题:如何在SPSS中导入数据?
答案:在SPSS中,可以通过“文件”菜单中的“打开”选项来导入数据,也可以直接拖拽数据文件到SPSS的工作区。
2. 问题:如何计算变量的描述性统计量?
答案:在SPSS中,可以使用“分析”菜单中的“描述统计”选项来计算变量的描述性统计量,包括均值、标准差、最大值、最小值等。
3. 问题:如何进行相关性分析?
答案:在SPSS中,可以使用“分析”菜单中的“相关”选项来进行相关性分析,可以计算变量之间的皮尔逊相关系数或斯皮尔曼相关系数。
4. 问题:如何进行回归分析?
答案:在SPSS中,可以使用“回归”选项来进行回归分析,可以进行简单线性回归、多元线性回归等不同类型的回归分析。
5. 问题:如何进行因子分析?
答案:在SPSS中,可以使用“因子”选项来进行因子分析,可以帮助研究人员发现变量之间的潜在结构和关联。
通过以上习题及其答案的学习和实践,我们可以更好地掌握SPSS的使用方法,提高数据分析的效率和准确性。
希望大家在学习SPSS的过程中能够多多练习,不断提升自己的数据分析能力。
SPSS习题及其答案是我们学习的好帮手,也是我们进步的动力。

《统计分析与SPSS的应用(第五版)》课后练习答案第3章SPSS数据的预处理1、利用第2章第7题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用第2章第7题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用第2章第9题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用第2章第9题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用第2章第7题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。

《统计分析与SPSS的应⽤(第五版)》课后练习答案.doc(1)《统计分析与SPSS的应⽤(第五版)》课后练习答案第⼀章练习题答案1、SPSS的中⽂全名是:社会科学统计软件包(后改名为:统计产品与服务解决⽅案)英⽂全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗⼝是数据编辑器窗⼝和结果查看器窗⼝。
数据编辑器窗⼝的主要功能是定义SPSS数据的结构、录⼊编辑和管理待分析的数据;结果查看器窗⼝的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:SPSS运⾏时可同时打开多个数据编辑器窗⼝。
每个数据编辑器窗⼝分别显⽰不同的数据集合(简称数据集)。
活动数据集:其中只有⼀个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进⾏分析。
4、SPSS的三种基本运⾏⽅式:完全窗⼝菜单⽅式、程序运⾏⽅式、混合运⾏⽅式。
完全窗⼝菜单⽅式:是指在使⽤SPSS的过程中,所有的分析操作都通过菜单、按钮、输⼊对话框等⽅式来完成,是⼀种最常见和最普遍的使⽤⽅式,最⼤优点是简洁和直观。
程序运⾏⽅式:是指在使⽤SPSS的过程中,统计分析⼈员根据⾃⼰的需要,⼿⼯编写SPSS命令程序,然后将编写好的程序⼀次性提交给计算机执⾏。
该⽅式适⽤于⼤规模的统计分析⼯作。
混合运⾏⽅式:是前两者的综合。
5、.sav是数据编辑器窗⼝中的SPSS数据⽂件的扩展名.spv是结果查看器窗⼝中的SPSS分析结果⽂件的扩展名.sps是语法窗⼝中的SPSS程序6、SPSS的数据加⼯和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按⼀定的概率以随机原则抽取样本,抽取样本时每个单位都有⼀定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。

用 SPSS 统计软件学会建立时间序列新变量方法时间序列,也叫时间数列或动态数列,是要素(变量) 的数据按照时间顺序变动排列而形成的一种数列,它反映了要素(变量) 随时间变化的发展过程。
地理过程的时间序列分析,就是通过分析地理要素(变量) 随时间变化的历史过程,揭示其发展变化规律,并对其未来状态进行预测。
在描述实际中出现的某些问题时,一种非常有用的随机模型就是自回归模型 (Autoregression) .在该模型中,过程的当前值被表示过程的有穷线性组合在加上一个重击e t .我们用X t,X t- 1,X t-2,… ,记在等间隔时间t,t- 1,t-2,…上的过程值。
此外,用Z t,Z t- 1,Z t-2,…,记关于均值u 的偏差,即Z t=X t-u 。
则:Z t=φ1Z t- 1+φ2Z t-2+…+φp Z t-p+e t便叫做为P阶自回归(AR)过程,当P=1时,称为一阶自回归模型。
1) 定义变量,建立数据文件并输入数据,至少要有一个变量。
打开Data 菜单中的DefineDates 对话框,定义时间序列的周期。
采用Transform 菜单中的Create Time Series 的方法,建立一个时间序列的新的变量。
2) 按Analyze ⇒ Time series ⇒ Autoregression 顺序展开相应的对话框。
3) 选择一个因变量,将其移到Dependent 框。
选择一个或多个自变量移到independent(s)框。
在Media 栏中,从三种方法中选择一种预测方法。
如果在回归方程中不需要包括常数项,可不选Include constant in model 复选项。
4) 单击Save 按钮展开保存对话框,在对话框中选择计算结果存放方式。
O 在Create Variables 栏中给出今Add to file 选项,将新建变量存放在原数据文件中,是系统默认的。
今Replace existing 选项,用新建变量数据替代数据文件中原先存在的计算结果。
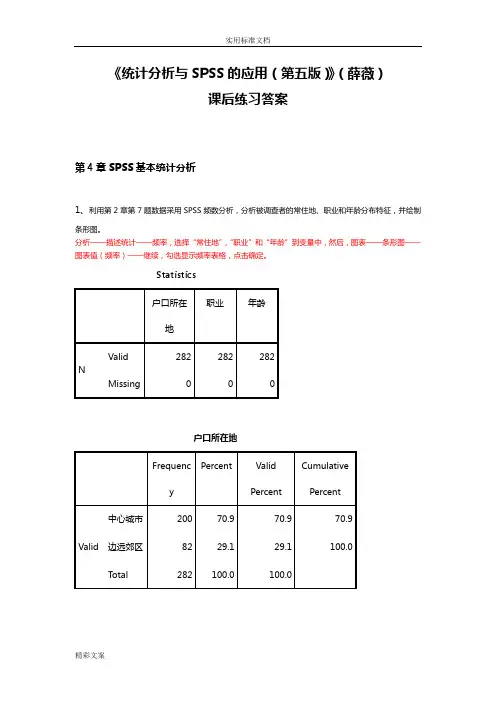
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第4章SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在地职业年龄NValid 282 282 282Missing 0 0 0户口所在地Frequency Percent ValidPercentCumulativePercentValid 中心城市200 70.9 70.9 70.9 边远郊区82 29.1 29.1 100.0 Total 282 100.0 100.0职业Frequency Percent ValidPercentCumulativePercentValid 国家机关24 8.5 8.5 8.5 商业服务业54 19.1 19.1 27.7 文教卫生18 6.4 6.4 34.0 公交建筑业15 5.3 5.3 39.4 经营性公司18 6.4 6.4 45.7 学校15 5.3 5.3 51.1 一般农户35 12.4 12.4 63.5 种粮棉专业户4 1.4 1.4 64.9 种果菜专业户10 3.5 3.5 68.4 工商运专业户34 12.1 12.1 80.5 退役人员17 6.0 6.0 86.5 金融机构35 12.4 12.4 98.9 现役军人 3 1.1 1.1 100.0 Total 282 100.0 100.0年龄Frequency Percent ValidPercentCumulativePercentValid 20岁以下4 1.4 1.4 1.4 20~35岁146 51.8 51.8 53.2 35~50岁91 32.3 32.3 85.5 50岁以上41 14.5 14.5 100.0 Total 282 100.0 100.0分析:本次调查的有效样本为282份。
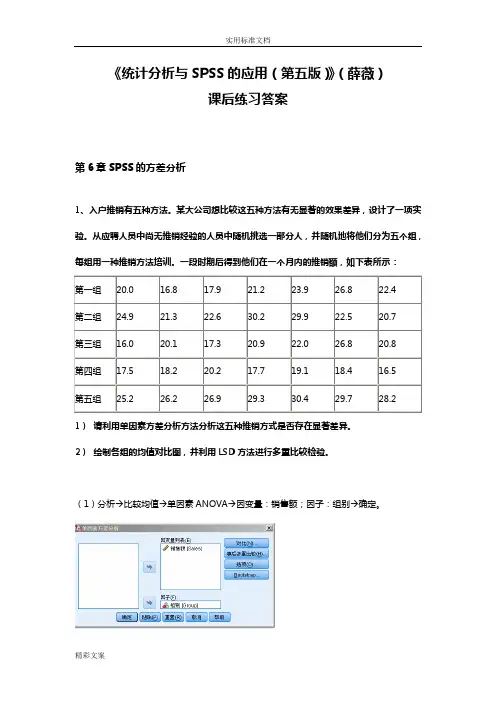
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第6章SPSS的方差分析1、入户推销有五种方法。
某大公司想比较这五种方法有无显著的效果差异,设计了一项实验。
从应聘人员中尚无推销经验的人员中随机挑选一部分人,并随机地将他们分为五个组,每组用一种推销方法培训。
一段时期后得到他们在一个月内的推销额,如下表所示:第一组20.0 16.8 17.9 21.2 23.9 26.8 22.4第二组24.9 21.3 22.6 30.2 29.9 22.5 20.7第三组16.0 20.1 17.3 20.9 22.0 26.8 20.8第四组17.5 18.2 20.2 17.7 19.1 18.4 16.5第五组25.2 26.2 26.9 29.3 30.4 29.7 28.21)请利用单因素方差分析方法分析这五种推销方式是否存在显著差异。
2)绘制各组的均值对比图,并利用LSD方法进行多重比较检验。
(1)分析→比较均值→单因素ANOVA→因变量:销售额;因子:组别→确定。
ANOVA销售额平方和df 均方 F 显著性组之间405.534 4 101.384 11.276 .000组内269.737 30 8.991总计675.271 34概率P-值接近于0,应拒绝原假设,认为5种推销方法有显著差异。
(2)均值图:在上面步骤基础上,点选项→均值图;事后多重比较→LSD多重比较因变量: 销售额LSD(L)(I) 组别(J) 组别平均差(I-J) 标准错误显著性95% 置信区间下限值上限第一组第二组-3.30000* 1.60279 .048 -6.5733 -.0267第三组.72857 1.60279 .653 -2.5448 4.0019第四组 3.05714 1.60279 .066 -.2162 6.3305第五组-6.70000* 1.60279 .000 -9.9733 -3.4267第二组第一组 3.30000* 1.60279 .048 .0267 6.5733第三组 4.02857* 1.60279 .018 .7552 7.3019第四组 6.35714* 1.60279 .000 3.0838 9.6305第五组-3.40000* 1.60279 .042 -6.6733 -.1267第三组第一组-.72857 1.60279 .653 -4.0019 2.5448第二组-4.02857* 1.60279 .018 -7.3019 -.7552第四组 2.32857 1.60279 .157 -.9448 5.6019第五组-7.42857* 1.60279 .000 -10.7019 -4.1552第四组第一组-3.05714 1.60279 .066 -6.3305 .2162第二组-6.35714* 1.60279 .000 -9.6305 -3.0838第三组-2.32857 1.60279 .157 -5.6019 .9448第五组-9.75714* 1.60279 .000 -13.0305 -6.4838第五组第一组 6.70000* 1.60279 .000 3.4267 9.9733第二组 3.40000* 1.60279 .042 .1267 6.6733第三组7.42857* 1.60279 .000 4.1552 10.7019第四组9.75714* 1.60279 .000 6.4838 13.0305*. 均值差的显著性水平为0.05。
SPSS FOR WINDOWS 在计量地理学中的应用二○○八年六月闽江学院地理科学系目录第一章SPSS概述 (3)第一节SPSS简介 (3)第二节SPSS的主界面 (3)第二章SPSS的数据管理 (5)第一节定义变量 (5)第二节数据的输入与编辑 (7)第三节数据转换 (8)第三章摘要性分析 (11)第一节Frequencies过程 (11)3.1.1 主要功能 (11)3.1.2 实例操作 (11)第二节Descriptives过程 (16)3.2.1 主要功能 (16)3.2.2 实例操作 (16)第四章相关分析 (19)第一节Bivariate过程 (19)4.1.1 主要功能 (19)4.1.2 实例操作 (19)第二节Partial过程 (22)4.2.1 主要功能 (22)4.2.2 实例操作 (22)第三节Distances过程 ........................................................................................ 错误!未定义书签。
4.3.1 主要功能............................................................................................. 错误!未定义书签。
4.3.2 实例操作............................................................................................. 错误!未定义书签。
第五章回归分析.. (26)第一节Linear过程 (26)5.1.1 主要功能 (26)5.1.2 实例操作 (26)第二节Curve Estimation过程............................................................................ 错误!未定义书签。
计量地理课后题问题详解SANY标准化小组 #QS8QHH-HHGX8Q8-GNHHJ8-HHMHGN#徐建华版计量地理学第二章答案1.地理数据有哪几种类型,各种类型地理数据之间的区别和联系是什么答:地理数据就是用一定的测度方式描述和衡量地理对象的有关量化指标。
按类型可分为:1)空间数据:点数据,线数据,面数据;2)属性数据:数量标志数据,品质标志数据地理数据之间的区别与联系:数据包括空间数据和属性数据,空间数据的表达可以采用栅格和矢量两种形式。
空间数据表现了地理空间实体的位置、大小、形状、方向以及几何拓扑关系。
属性数据表现了空间实体的空间属性以外的其他属性特征,属性数据主要是对空间数据的说明。
如一个城市点,它的属性数据有人口,GDP,绿化率等等描述指标。
它们有密切的关系,两者互相结合才能将一个地理试题表达清楚。
2. 各种类型的地理数据的测度方法分别是什么地理数据主要包括空间数据和属性数据:空间数据——对于空间数据的表达,可以将其归纳为点、线、面三种几何实体以及描述它们之间空间联系的拓扑关系;属性数据——对于属性数据的表达,需要从数量标志数据和品质标志数据两方面进行描述。
其测度方法主要有:(1) 数量标志数据①间隔尺度(Interval Scale)数据: 以有量纲的数据形式表示测度对象在某种单位(量纲)下的绝对量。
②比例尺度(Ratio Scale)数据: 以无量纲的数据形式表示测度对象的相对量。
这种数据要求事先规定一个基点,然后将其它同类数据与基点数据相比较,换算为基点数据的比例。
(2) 品质标志数据①有序(Ordinal)数据。
当测度标准不是连续的量,而是只表示其顺序关系的数据,这种数据并不表示量的多少,而只是给出一个等级或次序。
②二元数据。
即用0、1 两个数据表示地理事物、地理现象或地理事件的是非判断问题。
③名义尺度(Nominal Scale)数据。
即用数字表示地理实体、地理要素、地理现象或地理事件的状态类型。
第1章统计分析与SPSS软件概述习题与思考题(一)填空题1.定性数据,定序数据,定距数据,定比数据2.主成分分析,因子分析,聚类分析,判别分析,对应分析等3.数据清理,数据转换,缺失数据插补,数据的合并汇总拆分4.完全窗口菜单运行方式,程序运行方式5.SPSS Base(二)选择BADAD(三)判断√√×√×(四)简答题1.目前常用的统计分析工具或软件有哪些?你使用过哪些?它们之间的区别在哪里?解:常用的统计分析工具有SPSS、SAS、STATA、Python等。
2.试检查自己的SPSS软件共有几个模块,其中包括了哪些基本功能,并思考平时的统计分析需要哪些模块才能满足需要。
解:SPSS软件共有11个模块,分别是SPSS Base、SPSS Advance、SPSS Categories、SPSS Complex Sample、SPSS Conjoint、SPSS Exact Test、SPSS Maps、SPSS Missing Value Analysis、SPSS Regression、SPSS Tables和SPSS Trends。
其中SPSS Base是必需的,SPSS的整体框架、基本数据的获取、数据准备和整理等基本功能都集中在这一模块上,其他模块必须在该模块的基础上才能工作。
3.阐述定性、定序、定距、定比数据,并各举1例。
解:定性变量又称为名义变量。
这是一种测量精度最低、最粗略的基于“质”因素的变量,它的取值只代表观测对象的不同类别,如“班级”。
定序变量又称为有序变量、顺序变量,它取值的大小能够表示观测对象的某种顺序关系(等级、方位或大小等),也是基于“质”因素的变量,如“满意度”。
定距变量又称为间隔变量,它的取值之间可以比较大小,可以用加减法计算出差异的大小,如“重量”。
定比变量又称为比率变量,它与定距变量意义相近,差别在于定距变量中的“0”值只表示某一取值,定比数据变量表示“没有”,如“年龄”。
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第5 章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79,77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→分析→比较均值→单样本t 检验→相关设置→输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N 均值标准差均值的标准误成绩11 73.73 9.551 2.880单个样本检验检验值= 75差分的95% 置信区间t df Sig.( 双侧) 均值差值下限上限成绩-.442 10 .668 -1.273 -7.69 5.14分析:指定检验值:在test 后的框中输入检验值(填75),最后ok!分析:N=11 人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean) 为2.87.t 统计量观测值为-4.22,t 统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较 a 和p。
T 统计量观测值的双尾概率p-值(sig.(2-tailed) )为0.668>a=0.05 所以不能拒绝原假设;且总体均值的95% 的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35 名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时):(1)请利用SPSS 对上表数据进行描述统计,并绘制相关的图形。
统计分析与spss的应用(第三版)第10章课后习题详细答案1、(1)聚类分析的第1步,1号样本(广西瑶族)和3号样本(广西侗族)聚为一小类,它们的个体距离(欧氏距离)是3.722,这个小类将在下面第2步用到。
聚类分析的第2步,8号个体(贵州苗族)与第1步聚成的小类(1号和3号聚成的小类)又聚成一小类,它们的距离(个体与小类的距离,采用组间平均链锁距离)是9.970,这个小类将在下面第4步用到。
聚类分析的第3步,5号样本和7号样本聚成小类,它们的距离(个体与个体的距离)是11.556,这个小类将在第5步用到。
聚类分析的第4步,6号与第2步形成的小类(1号3号8号聚成的小类)聚为小类,它们的距离(个体与小类的距离)为18.607,这个小类将在第6步用到。
聚类分析的第5步,4号样本与第3步聚成的小类聚为小类,它们的距离(个体与小类的距离)为20.337,这个小类将在第6步用到。
聚类分析的第6步,第4步聚成的小类与第5步聚成的小类聚成小类,它们的距离(小类与小类的距离,采用组间平均链锁距离)是22.262,这个小类将在下面第7步中用到。
聚类分析的第7步,2号样本与第6步中聚成的小类聚成小类。
它们的距离(个体与小类的距离)是31.020。
经过7步,8个样本最后聚成了一大类。
(2)(3) 广西瑶族与广西侗族、贵州苗族、基诺族为一类,土家族与崩龙族、白族为一类,湖南侗族自成一类2、(1)凝聚状态表随着类数目不断减少,类间距离在逐渐增大。
3类后,聚间距离迅速增大,形成极为平坦的碎石路。
所以考虑聚成3类。
(2)北京自成一类,江苏广东上海湖南湖北聚为一类,剩余的聚省为一类。
(3)(4)通过该表可以看出,,对应P值-小于0.005,所以各指数的均值在3类中的差异是显著的。
3、答:聚类分析是以各种距离来度量个体间的“亲疏”程度的。
从各种距离的定义来看,数量级将对距离产生较大的影响,并影响最终的聚类结果。
进行层次聚类分析时,为了避免上述问题,聚类分析之前应首先消除数量级对聚类的影响,对数据进行标准化就是最常用的方法。