一种新的分类器选择集成算法
- 格式:pdf
- 大小:232.44 KB
- 文档页数:3

adaboosting算法原理Adaboosting(亦称AdaBoost)是一种集成学习(ensemble learning)方法,用于提高弱分类器的准确性,并将它们组合为强分类器。
它是由Yoav Freund和Robert Schapire于1996年提出的。
Adaboost的基本思想是通过对先前分类错误的训练样本进行加权,并重新训练分类器,使其能够更好地区分这些错误的样本。
在下一轮的训练中,对先前分类正确的样本权重进行降低,以便更多地关注分类错误的样本。
这样的迭代过程将使得一些样本在最终的分类器中具有更高的权重,从而提高整体分类性能。
以下是Adaboosting算法的基本步骤:1.初始化训练样本权重:对于具有N个训练样本的训练集,初始权重都设置为相等值(通常为1/N)。
2.对于t从1到T(迭代次数):a.使用加权训练集训练一个弱分类器。
弱分类器在训练样本上的错误分类程度将决定它的权重。
b.计算弱分类器的错误率εt。
c.根据εt计算弱分类器的权重αt,其中:αt = 0.5 * ln((1-εt)/εt)d.更新训练样本的权重,使错误分类的样本权重增加,并且正确分类的样本权重减少。
更新公式为:对于正确分类的样本:wt+1(i) = wt(i) * exp(-αt * yi * hi(xi)) / Zt对于错误分类的样本:wt+1(i) = wt(i) * exp(αt * yi * hi(xi)) / Zt其中,wt(i)是第t轮迭代时样本i的权重,yi是样本i的类别(+1或-1),hi(xi)是弱分类器在样本xi上的预测输出,Zt是用于归一化权重的因子。
3. 根据所有弱分类器的权重αt和各自的预测输出hi(xi),通过加权求和的方式得到最终的强分类器:f(x) = sign(Σt=1到T (αt * hi(x)))其中,sign(是一个符号函数,将结果转换为二元分类输出(+1或-1)。
Adaboosting的主要优点在于它能够使用一系列相对简单的弱分类器构建一个准确性更高的强分类器。

利用旋转森林变换的异构多分类器集成算法毛莎莎;熊霖;焦李成;张爽;陈博【期刊名称】《西安电子科技大学学报(自然科学版)》【年(卷),期】2014(000)005【摘要】为了增强集成系统中各分类器之间的差异性,提出了一种使用旋转森林策略集成两种不同模型分类器的方法,即异构多分类器集成学习算法。
首先采用旋转森林对原始样本集进行变换划分,获得新的样本集;然后通过特定比例选择分类精度高的支撑矢量机或分类速度较快的核匹配追踪作为基本的集成个体分类器,并对新样本集进行分类,获得其预测标记;最后结合两种模型下的预测标记。
该算法通过结合两种不同分类器模型,实现了精度和速度互补,将二者混合集成后改善了集成系统泛化误差,相比单个模型集成提高了系统分类性能。
对 UCI数据集和遥感图像数据集的仿真实验结果表明,文中算法相比单一分类器集成缩短了运行时间,同时提高了系统的分类准确率。
【总页数】6页(P48-53)【作者】毛莎莎;熊霖;焦李成;张爽;陈博【作者单位】西安电子科技大学智能感知与图像理解教育部重点实验室,陕西西安 710071;西安电子科技大学智能感知与图像理解教育部重点实验室,陕西西安710071;西安电子科技大学智能感知与图像理解教育部重点实验室,陕西西安710071;西安电子科技大学智能感知与图像理解教育部重点实验室,陕西西安710071;西安电子科技大学智能感知与图像理解教育部重点实验室,陕西西安710071【正文语种】中文【中图分类】TP181【相关文献】1.基于小波变换和极限旋转森林算法的入侵检测模型 [J], 刘利群;项顺伯;王晗2.利用2 DCOS进行多组分混合气体傅里叶变换红外光谱分析中同分异构体谱峰的辨别 [J], 赵安新;汤晓君;张钟华;刘君华3.基于旋转森林的分类器集成算法研究 [J], 邵良杉;马寒4.一种利用空间和光谱信息的高光谱遥感多分类器动态集成算法 [J], 苏红军;刘浩5.利用旋转变换,提升初中生的数学思维 [J], 吉雪梅因版权原因,仅展示原文概要,查看原文内容请购买。

adaboost算法参数【原创版】目录1.AdaBoost 算法概述2.AdaBoost 算法的参数3.参数的作用及对算法性能的影响4.实际应用中的参数选择正文一、AdaBoost 算法概述AdaBoost(Adaptive Boosting)算法是一种自适应的集成学习算法,它可以将多个基本分类器(如决策树、SVM 等)组合成一个更强的集成分类器。
AdaBoost 算法的主要思想是加权训练样本和加权弱学习器,以提高分类准确率。
它具有较强的泛化能力,可以有效地解决数据不平衡和过拟合问题。
二、AdaBoost 算法的参数AdaBoost 算法有两个主要的参数:正则化参数α和迭代次数 T。
1.正则化参数α:α是一个超参数,用于控制弱学习器的权重。
它决定了每个训练样本对应的弱学习器的权重,从而影响到最终集成分类器的性能。
较小的α值会使得弱学习器更关注误分类的训练样本,提高模型的泛化能力;较大的α值则会使得弱学习器更关注分类准确的训练样本,提高模型在训练集上的准确率。
2.迭代次数 T:T 表示 AdaBoost 算法迭代训练的次数。
每次迭代都会根据当前弱学习器的预测错误率来生成一个新的训练样本分布,使得后续的弱学习器更加关注误分类的训练样本。
增加迭代次数 T 可以提高模型的准确率,但也会增加计算复杂度。
三、参数的作用及对算法性能的影响AdaBoost 算法的参数对模型的性能具有重要影响。
合适的参数设置可以使得模型在训练集和测试集上都取得较好的性能,而过度调参则可能导致模型过拟合或欠拟合。
正则化参数α的取值影响着弱学习器的权重分配,从而影响到模型的泛化能力。
较小的α值会使得弱学习器更关注误分类的训练样本,提高模型的泛化能力;较大的α值则会使得弱学习器更关注分类准确的训练样本,提高模型在训练集上的准确率。
迭代次数 T 的取值影响着模型的训练过程。
增加迭代次数可以使得模型更加关注误分类的训练样本,提高模型的准确率;但过多的迭代次数会增加计算复杂度,可能导致模型过拟合。

分类算法数据挖掘中有很多领域,分类就是其中之一,什么是分类,分类就是把一些新得数据项映射到给定类别的中的某一个类别,比如说当我们发表一篇文章的时候,就可以自动的把这篇文章划分到某一个文章类别,一般的过程是根据样本数据利用一定的分类算法得到分类规则,新的数据过来就依据该规则进行类别的划分.分类在数据挖掘中是一项非常重要的任务,有很多用途,比如说预测,即从历史的样本数据推算出未来数据的趋向,有一个比较著名的预测的例子就是大豆学习。
再比如说分析用户行为,我们常称之为受众分析,通过这种分类,我们可以得知某一商品的用户群,对销售来说有很大的帮助。
分类器的构造方法有统计方法,机器学习方法,神经网络方法等等。
常见的统计方法有knn算法,基于事例的学习方法。
机器学习方法包括决策树法和归纳法,上面讲到的受众分析可以使用决策树方法来实现.神经网络方法主要是bp算法,这个俺也不太了解。
文本分类,所谓的文本分类就是把文本进行归类,不同的文章根据文章的内容应该属于不同的类别,文本分类离不开分词,要将一个文本进行分类,首先需要对该文本进行分词,利用分词之后的的项向量作为计算因子,再使用一定的算法和样本中的词汇进行计算,从而可以得出正确的分类结果.在这个例子中,我将使用庖丁分词器对文本进行分词。
目前看到的比较全面的分类算法,总结的还不错。
2。
4.1 主要分类方法介绍解决分类问题的方法很多[40—42] ,单一的分类方法主要包括:决策树、贝叶斯、人工神经网络、K-近邻、支持向量机和基于关联规则的分类等;另外还有用于组合单一分类方法的集成学习算法,如Bagging和Boosting等。
(1)决策树决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则.构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。
它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论.主要的决策树算法有ID3、C4.5(C5.0)、CART、PUBLIC、SLIQ和SPRINT算法等.它们在选择测试属性采用的技术、生成的决策树的结构、剪枝的方法以及时刻,能否处理大数据集等方面都有各自的不同之处. (2)贝叶斯贝叶斯(Bayes)分类算法是一类利用概率统计知识进行分类的算法,如朴素贝叶斯(Naive Bayes)算法.这些算法主要利用Bayes定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。

随机森林的原理随机森林是一种集成学习算法,通过组合多个决策树来进行分类和回归任务。
它的原理基于决策树和随机抽样的思想,具有一定的鲁棒性和预测能力。
本文将详细介绍随机森林的原理和应用,并探讨其优缺点及改进方法。
一、随机森林的原理随机森林由多个决策树组成,每个决策树都是一个分类器。
在随机森林中,每个决策树的生成过程都是独立的,首先从样本集中通过有放回抽样(bootstrap)的方式抽取出n个样本,然后对每个样本随机选择k个特征,构建决策树。
这里的k是一个常数,通常取总特征数的平方根。
每个决策树都对应着一个子样本集和一个特征子集,通过递归地选择最优特征进行划分,直到满足某个停止条件(如节点样本数小于阈值或深度达到预定值)。
在决策树的生成过程中,每个节点通过计算一个评价指标(如信息增益或基尼指数)来选择最优特征进行划分。
决策树的划分过程会不断减少样本的纯度,直到达到叶节点。
叶节点的类别由该节点中样本的多数类确定。
每个决策树都会对新样本进行分类,最终通过投票的方式确定随机森林的预测结果。
二、随机森林的优点1. 随机森林能够处理高维数据和大规模数据集,具有较强的泛化能力。
2. 随机森林能够处理缺失值和不平衡数据集,并且对异常值具有较好的鲁棒性。
3. 随机森林能够评估特征的重要性,可以用于特征选择和特征工程。
4. 随机森林可以并行计算,提高了训练速度。
三、随机森林的应用1. 随机森林广泛应用于分类问题,如垃圾邮件过滤、疾病诊断等。
通过训练多个决策树,随机森林可以提高分类的准确度和鲁棒性。
2. 随机森林可以用于回归问题,如房价预测、股票走势预测等。
通过训练多个决策树,随机森林可以提供更加准确的预测结果。
3. 随机森林还可以用于异常检测、聚类分析等领域。
通过利用随机森林的特征选择和异常检测能力,可以有效地发现异常样本或聚类相似样本。
四、随机森林的改进方法尽管随机森林具有很多优点,但也存在一些缺点。
比如,随机森林在处理高维数据时容易过拟合,而且对噪声数据敏感。

'classifier' is deprecated -回复“classifier is deprecated(分类器已被弃用)”这句话意味着分类器算法的某个版本已经不再被推荐使用。
在计算机科学和机器学习领域,分类器是一种有监督学习算法,其目标是将数据集中的样本分配到不同的类别中。
然而,由于算法和技术的不断发展,某些算法可能会变得过时并被更高效或更准确的算法取代。
这篇文章将一步一步回答关于分类器被弃用的问题,探讨其原因以及可能的替代方法。
第一步:了解分类器算法在讨论分类器被弃用的问题之前,我们先来了解一下分类器算法的基本原理。
分类器算法是机器学习中最常用和最基础的方法之一。
它通过学习输入数据的模式和特征,根据这些信息将新的未知样本分配到预定义的不同类别中。
种类最多的任务是二类或多类分类,但也有一些分类器可以进行回归和聚类任务。
第二步:了解分类器被弃用的原因分类器算法被弃用往往是因为以下几个原因:1.效果不佳:某个算法在特定问题上的表现不佳,无法达到预期的准确性或效率。
这可能是因为数据集的特点不适合这个算法,或者算法本身的局限性。
2.技术过时:分类器算法是一个不断发展和演变的领域。
随着时间的推移,研究人员会提出新的算法来解决现有算法的问题,或者开发更高效和准确的替代方案。
因此,某个算法可能会被认为是过时的,且不再推荐使用。
3.缺乏支持和更新:开发者可能停止支持某个算法的更新和维护,导致其在未来无法继续使用。
这可能是因为开发者转向其他研究方向,或者无法继续投入资源来维护该算法。
第三步:探究分类器替代方法既然我们已经了解了分类器被弃用的原因,接下来我们将探讨可能的替代方法。
每个分类器算法都有其独特的特点和适用范围,所以具体的替代方法将取决于特定的应用情况。
下面是一些常见的分类器替代方法:1.支持向量机(Support Vector Machines,SVM):SVM是一种二类分类器,它通过将数据映射到高维空间,找到一个最优超平面来进行分类。
ROC及AUC计算⽅法及原理1.⾮均衡分类问题在⼤多数情况下不同类别的分类代价并不相等,即将样本分类为正例或反例的代价是不能相提并论的。
例如在垃圾邮件过滤中,我们希望重要的邮件永远不要被误判为垃圾邮件,还有在癌症检测中,宁愿误判也不漏判。
在这种情况下,仅仅使⽤分类错误率来度量是不充分的,这样的度量错误掩盖了样例如何被错分的事实。
所以,在分类中,当某个类别的重要性⾼于其他类别时,可以使⽤Precison和Recall多个⽐分类错误率更好的新指标。
Precison(查准率):预测为正例的样本中真正正例的⽐例。
Recall(召回率):真正为正例的样本有多少被预测出来。
可见,我们可以根据我们最终的⽬标来选择度量指标。
例如,在癌症检测中,我们希望选择Recall较⾼的模型(有病为正例)。
⽽在垃圾邮件过滤中,我们希望选择Precison较⾼的模型。
但是我们很容易构造⼀个⾼查准率或⾼召回率的分类器,但是很难保证两者同时成⽴。
构建⼀个同时使两者很⼤的分类器是具有挑战性的。
2.ROC曲线ROC是⼀个⽤于度量分类中的⾮均衡性的⼯具,ROC曲线及AUC常被⽤来评价⼀个⼆值分类器的优劣。
既然已经有了这么多的评价指标,为什么还要使⽤ROC与AUC呢?因为ROC曲线有⼀个很好的特征:在实际的数据集中经常会出现类别不平衡现象,即负样本⽐正样本多很多(或者相反),⽽且测试数据中的正负样本的分布也可能随着时间⽽变化。
⽽在这种情况下,ROC曲线能够保持不变。
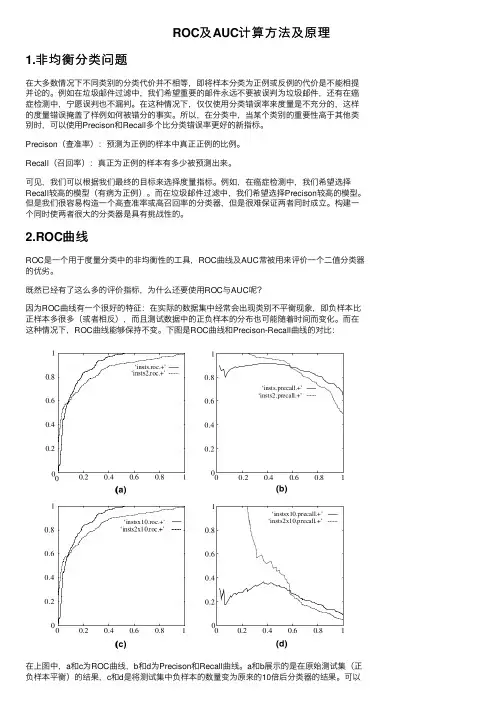
下图是ROC曲线和Precison-Recall曲线的对⽐:在上图中,a和c为ROC曲线,b和d为Precison和Recall曲线。
a和b展⽰的是在原始测试集(正负样本平衡)的结果,c和d是将测试集中负样本的数量变为原来的10倍后分类器的结果。
可以看出,曲线基本保持不变,⽽Precison和Recall变化较⼤。
2.2 ROC曲线的定义(Receiver Operating Characteristic)ROC可以⽤来⽐较不同分类器的相关性能。


一种改进的RAKEL多标签分类算法金永贤;张微微;周恩波【摘要】RAKEL(random k-labelsets)算法是一种集成技术,能有效解决多标签分类问题.它将原始标签集随机选用一小部分标签子集构成的数据集来训练每个分类器,但由于RAKEL算法构造标签空间的随机性,并未充分考察到样本多个标签之间的相关性,从而造成分类精度不高,泛化性能受到一定影响.为此,提出了改进的LC-RAKEL算法.首先,通过标签聚类将原始标签集划分成标签簇,再从每个标签簇中各选择一个标签构成标签集,以此发现标签空间中重要且不频繁的映射关系;然后,利用出现次数较少的标签集合组成新的训练数据,训练相应的分类器.实验证明,改进的算法性能优于其他常用多标签分类算法.【期刊名称】《浙江师范大学学报(自然科学版)》【年(卷),期】2016(039)004【总页数】6页(P386-391)【关键词】多标签分类;RAKEL;标签空间;随机;不频繁的映射【作者】金永贤;张微微;周恩波【作者单位】浙江师范大学数理与信息工程学院,浙江金华321004;浙江师范大学数理与信息工程学院,浙江金华321004;浙江师范大学数理与信息工程学院,浙江金华321004【正文语种】中文【中图分类】TP181多标签学习问题在现实世界中广泛存在.例如,在图像分类[1]中,一张图片往往可以对应多个主题,如“海滩”和“落日”.在文档分类[2]中,一篇文档可以属于多个主题,如“世界杯”和“足球”.可以看出,每个样例都与一个标签集合相对应.多标签学习主要研究当样本同时具有多个类别标记时,如何构建分类器准确预测未知样本的标签集合.传统的二分类和多类分类问题,都可以看作多标签学习问题的特例.目前,研究者已提出多种解决多标签学习问题的方法,这些方法主要分为算法适应法和问题转换法两类[3].由于问题转换法具有简化性及在大多数数据集上应用良好性的特点,因此,本文主要讨论问题转换法.问题转化法中最基本、最常用的2个方法:Binary Relevance(BR,即二值相关)方法和Label Powset(LP,即标记集合)方法.其中,BR 法学习多个二类分类器,每个分类器只针对某一个标签进行分类.这种方法简便易行,但忽略了标签之间的相互关系,预测结果往往难以令人满意.在BR的基础上,文献[4]提出Classifier Chain(CC)算法,构造多个链式结构的分类器.所谓链式结构,即将之前分类器的类属性加入到训练集的特征属性中,建立新的训练集,后面的分类器则是在新的训练集上构建,这样就能有效地利用标记之间的依赖关系,但构建分类器链的顺序会影响分类器的性能.文献[5]提出的Tree-Based Classifier Chain(TCC)算法是在分类器链算法的基础上改进的,它按照一定的顺序建立分类器链.LP 方法是通过将多标签数据集中每一个唯一的标签集合看成一个类别,将多标签分类问题分解为多类单标签问题.对于给出的一个测试实例,多类LP 分类器可以预测出最可能的类别,然后被转换成一个标签集合.与简单的BR方法相比,LP方法一定程度上考虑标签的相关性.然而,随着标签数目和训练样本实例的增加,可能的类别也相应地成比例增加,使得计算开销变大;另一方面,个别类别训练样本过少,使得学习变难.而且LP 仅能预测训练集中出现的标签组合.为此,文献[6]提出了Pruned Problem Transformation(PPT)算法,它保留出现次数大于阈值的标记集合,并对出现次数较少的标记集合进行划分,对划分后的子集建立LP分类器,然而在实例预测时只能得到在训练集中出现过的标记集合.文献[7]提出了Random k-labelsets(RAKEL)算法,从标签的原始集中每次随机选择一部分标签子集,使用LP方法训练相应的分类器,最后由多个LP分类器通过投票的方式集成预测.这种方法通过集成方式解决LP产生数据倾斜的不足,同时通过随机构造标签子集考虑标签之间的相关性.值得注意的是,也正是由于随机选择的特点,标签之间的相关关系并没有被充分利用,从而造成分类精度不高,泛化性能会受到一定影响.在实际应用中,标签与标签之间是有一定联系的.例如,图片分类中,一张图片包含“黑色”和“月亮”2个标签,那么其属于“夜晚”的可能性就很大.又如,包含“裙子”、“长发”标签的图片,属于“男性”标签的可能性会很小.因此,是否能充分利用标签之间的相关性,将直接影响算法的预测性能.为此,本文结合Hierarchy of Multilabel Classifiers(HOMER)算法[8]中balanced k-means(平衡k-means)聚类标签的方法对RAKEL算法进行了改进.首先,利用balanced k-means将标签聚类为k簇;然后,从每簇中各选择一个构成新的标签子集.以此发现训练集中出现次数较少的标签集合,提高出现次数较少标签组合的利用率,充分利用标签之间的联系,以提高算法的预测性能.Tsoumakas 等[7]提出的RAKEL算法是通过将原始的大标签集分成一定数目的小标签集,然后使用LP训练相应的分类器,最后集成预测结果.在训练过程中,RAKEL迭代构建m(大小为2倍的标签个数)个LP分类器,每次迭代中,从所有不同的标签组合(大小为k)中随机选择一个标签组合Yi,然后学习一个LP分类模型hi.在预测分类时,对于一个未知实例x,每个模型hi对在自己相应的Yi中的每一个标签λj给出一个二值的预测结果(0或1),通过RAKE算法计算L(标签集合)中每一个标签λj的一个平均得票率,如果平均得票率大于给定的阈值t,那么λj就属于x.一般阈值为0.5.RAKEL算法是通过集成学习来获得最后的结果,而集成学习的有效性在于分类器的差异性和精确度.由于该算法从标签集合L中随机选择标签子集,所以当L较小时,预先设置好的子分类器数量可以较好地体现出标签的相关关系,同时也保证了子分类器的差异性和精确度.但对于大标签数据集,随机选取的一定数量的标签子集构成的子模型就不能充分体现出相关性,从而对集成预测的准确度造成较大的影响.本文从该角度出发,在标签子集选取过程中,重视发现训练集出现次数稀少的标签组合,使构造的子模型更具有代表性.首先,通过基于HOMER算法中balanced k-means(平衡k-means)聚类的方法,从标签集合L中随机选择k个标签作为标签聚类中心,将与每个标签中心的欧式距离最近的其他标签加入到相应的标签集合中,每次聚类后都要重新计算标签聚类中心.把类似的标签聚成k个标签簇,通过控制每个标签簇大小的上限,使每个聚类标签簇的大小平衡.然后,在模型训练过程中依次从不同标签簇内随机取出一个标签,组成k-labelsets标签子集.根据训练集的数据集迭代构建m个LP分类器模型.由于在训练集中,以这种方式组成的k-labelsets标签子集对应的样本较少,从而使得训练出的子分类器预测输出的标签组合更倾向于负例(这种标签组合的可能性很小),进而得到分类精度更高的子分类器.最后,预测分类时,每个分类器都会得到未知实例的标签预测结果,通过综合计算每一个标签的平均得票率,预测未知实例的所属标签.为了更好地描述算法,首先引入一些相关定义:D={(xi,Yi),i=1,2,…,n}表示一个多标签训练样本集.其中:xi代表的是特征向量;Yi表示第i个样本的标签集合;L={λi},i=1,2,…,|L|,表示多标签数据学习任务中所包含的全部标签所组成的集合;Y⊆L且|Y|=k表示k-labelsets;Lk表示L中所有不同的k-labelsets的集合,且它的大小为二项式系数.标签聚类过程描述如下:输入:聚类的数目k,全部标签集合L,循环次数p输出:k个平衡标签聚类簇for i←1 to k doCi←Ø;//初始化标签聚类集合Ci,赋为空集ci←random member of L;//初始化聚类中心ci,从L中随机取一个标签赋给ci while p>0 dofor each λ∈L dofor i←1 to k dodλi←distance(λ,ci)//利用欧式距离公式计算2个标签间的距离dλifinished←false;v←λ;//将标签λ赋给标签将距离λ最近的聚类中心标签编号赋给jinsert sort(v,dvj) to sorted list Cj;//将标签λ及最短距离添加到标签聚类集合Cj 中if |Cj|>「|L/k|⎤ thenv←remove last element of Cj;//控制Cj的大小大致相等,若大小超过上限,则将 //Cj的最后一个元素移除并插入到下一个最接近的集合中dvj←∞;elsefinished←true;recalculate centers;//重新计算聚类标签中心p←p-1return C1,C2,…,Ck.模型训练过程如下:输入:模型个数m,labelsets(标签子集)大小k,全部标签集合L,训练样本集D输出:LP分类器的组合及相应的k-labelsets YiR←Lk;//将所有的标签子集赋给Rfor i=1 to min(m,|Lk|) doYi←Ø;//清空标签集Yifor j←1 t o k doYi←Yi+randomly member select from Cjendtrain an LP classifier hi:X→P(Yi) on D;R←R\{Yi};//从R中去掉Yi这种标签组合end预测分类过程如下:输入:未知实例x,LP分类器hi的组合,相应的k-labelsets Yi,全部标签集合L,阈值t输出:多标签分类结果向量Tfor j←1 to |L| doSj←0;//Sj统计第j个标签的预测结果Vj←0;//Vj统计含有第j个标签的训练模型数量for i←1 to m dofor all labels λj∈Yi doSj←Sj+hi(x,λj);Vj←Vj+1;for j←1 to |L| doAj←Sj/Vj;//Aj计算对未知实例x的标签λi平均得票率if Aj>t thenTj←1;else Tj←0;//若平均得票率大于阈值,则对应标签的预测为1,反之为0为了验证算法的有效性,在一些多标记数据集上进行了实验.3.1 实验数据本文实验数据采用emotions[9],scene[10],birds[11],medical[12],genbase[13] 5个数据集.表1给出了详细的统计信息.3.2 实验结果及分析针对LC-RAKEL算法,本文采用5-fold交叉验证方法来评价其性能.为了验证该算法的有效性,选择了BR算法、RAKEL算法、CC算法及基于kNN的ML-KNN[14]算法作为对比,并采用分类准确率(Subset Accuracy)、准确率(Accuracy)、召回率(Recall)、F值(F-measure)、微平均(micro F1)、宏平均(macro F1)[15-16] 6个评价指标进行比较.其中:对于BR算法、CC算法及RAKEL 算法采用的基础分类器算法为支持向量机分类算法,RAKEL算法中标签子集大小设为3,模型个数设为标签数量的2倍,阈值设为0.5.ML-KNN算法中的k设为10,smoothing取值为1.所有实验均在Mulan[17]开源库中用Java实现.表2~表7给出了本文算法与其他算法的对比实验结果,表中标注星号的数据表示最优结果.从实验结果发现:LC-RAKEL算法的性能有明显提升,5个数据集中的绝大部分指标都达到了1%的提升,有些甚至有2%的性能提升;在emotions,birds和genbase 3个数据集上的全部指标都达到最优;在scene数据集上除了分类准确率这个指标之外都达到最优.因为数据集本身具有数据分布的复杂性及标签之间相关关系强弱程度,所以在medical数据集上的表现略逊于CC算法,但较改进前的算法仍有很大的提升.整体上,LC-RAKEL算法优于其他算法.基于RAKEL算法在处理存在大量标签的数据集时,由于随机选择标签的特点,使得构建的子分类器分类精度降低.为此,首先通过平衡k-means算法找到相关度高的标签集合,然后从每一类中随机选择标签构成子标签集合进行模型训练,以此找到分类精度高的模型.实验证明,LC-RAKEL算法处理多标记学习问题优于其他4种算法.【相关文献】[1]刘鹏,叶志鹏,赵巍,等.一种多层次抽象语义决策图像分类方法[J].自动化学报,2015,41(5):960-969.[2]张晶,李德玉,王素格,等.基于稳健模糊粗糙集模型的多标记文本分类[J].计算机科学,2015,42(7):270-275.[3]李思男,李宁,李战怀.多标签数据挖掘技术:研究综述[J].计算机科学,2013,40(4):14-21.[4]Read J,Pfahringer B,Holmes G,et al.Classifier chains for multi-labelclassification[J].Machine Learning,2011,85(3):254-269.[5]付彬,王志海.基于树型依赖结构的多标记分类算法[J].模式识别与人工智能,2012,25(4):573-580.[6]Read J.A pruned problem transformation method for multi-labelclassification[C]//Proceeding of New Zealand Computer Science Research Student Conference.Christchurch:Canterbury University,2008:143-150.[7]Tsoumakas G,Katakis I,Vlahavas I.Random k-labelsets for multilabel classification[J].IEEE Transactions on Knowledge and Data Engineering,2011,23(7):1079-1089.[8]Tsoumakas G,Angelis L,Vlahavas I.Selective fusion of heterogeneousclassifiers[J].Intelligent Data Analysis,2005,9(6):511-525.[9]Trohidis K,Tsoumakas G,Kalliris G,et al.Multi-label classification of music into emotions[J].Eurasip Journal on Audio Speech & Music Processing,2008,11(1):325-330. [10]Boutell M R,Luo J,Shen X,et al.Learning multi-label scene classification[J].Pattern Recognition,2004,37(4):1757-1771.[11]Briggs F,Lakshminarayanan B,Neal L,et al.Acoustic classification of multiple simultaneous bird species:A multi-instance multi-label approach[J].Journal of the Acoustical Society of America,2012,131(6):4640-4650.[12]Kajdanowicz T,Kazienko P.Multi-label classification using error correcting output codes[J].International Journal of Applied Mathematics & ComputerScience,2012,22(4):829-840.[13]Tsoumakas G,Katakis I.Multi-label classification:An overview[J].International Journal of Data Warehousing and Mining,2007,3(3):1-13.[14]Zhang M L,Zhou Z H.ML-KNN:A lazy learning approach to multi-labellearning[J].Pattern Recognition,2007,40(7):2038-2048.[15]Schapire R E,Singer Y.Boostexter:A boosting-based system for textcategorization[J].Machine Learning,2000,39(2):135-168.[16]Godbole S,Sarawagi S.Discriminative methods for multi-labeledclassification[J].Lecture Notes in Computer Science,2004,30(56):22-30.[17]Tsoumakas G,Spyromitros-Xioufis E,Vlahavas I P,et al.MULAN:A Java library for multi-label learning[J].Journal of Machine Learning Research,2011,12(7):2411-2414.。


boosting算法Boosting算法是一种集成学习方法,通过将若干个弱分类器(即分类准确率略高于随机猜测的分类器)进行适当的加权组合,形成一个强分类器,以提高整体分类性能。
在机器学习领域,Boosting算法具有广泛的应用,尤其在解决分类问题上表现出色。
Boosting算法的核心思想是通过迭代的方式,不断调整数据的权重分布,使得前一个弱分类器分错的样本在后续模型中得到更多的关注,从而使得整体模型能够更好地对这些困难样本进行分类。
具体而言,Boosting算法通常包含以下几个步骤:1.初始化样本权重:将所有样本的权重初始化为相等值,表示初始时每个样本的重要性相同。
2.迭代训练弱分类器:对于每一轮迭代,根据当前样本权重分布训练一个弱分类器。
弱分类器的训练过程可以使用各种机器学习算法,如决策树、支持向量机等。
3.更新样本权重:根据当前弱分类器的分类结果,调整样本的权重分布。
被错误分类的样本的权重会得到增加,而被正确分类的样本的权重会减少。
4.计算弱分类器权重:根据弱分类器的分类准确率,计算其在最终分类器中的权重。
分类准确率越高的弱分类器权重越大。
5.组合弱分类器:通过加权组合所有弱分类器,形成一个强分类器。
弱分类器的权重决定了其对最终分类器的影响程度。
Boosting算法的关键在于不断调整样本的权重分布,使得模型能够更加关注分类错误的样本。
这样做的目的是为了解决传统分类算法容易受到噪声样本和异常样本影响的问题。
通过集成多个弱分类器,Boosting 算法可以有效地提高整体的分类性能。
常见的Boosting算法包括AdaBoost、Gradient Boosting和XGBoost等。
AdaBoost是最早提出的Boosting算法,它通过调整样本权重和弱分类器权重来训练模型。
Gradient Boosting是一种迭代的Boosting算法,每一轮迭代都通过梯度下降的方式优化损失函数。
XGBoost是一种改进的Gradient Boosting算法,通过引入正则化项和树剪枝等技术,进一步提高了模型的性能。
集成学习算法总结----Boosting和Bagging集成学习基本思想:如果单个分类器表现的很好,那么为什么不适⽤多个分类器呢?通过集成学习可以提⾼整体的泛化能⼒,但是这种提⾼是有条件的:(1)分类器之间应该有差异性;(2)每个分类器的精度必须⼤于0.5;如果使⽤的分类器没有差异,那么集成起来的分类结果是没有变化的。
如下图所⽰,分类器的精度p<0.5,随着集成规模的增加,分类精度不断下降;如果精度⼤于p>0.5,那么最终分类精度可以趋向于1。
接下来需要解决的问题是如何获取多个独⽴的分类器呢?我们⾸先想到的是⽤不同的机器学习算法训练模型,⽐如决策树、k-NN、神经⽹络、梯度下降、贝叶斯等等,但是这些分类器并不是独⽴的,它们会犯相同的错误,因为许多分类器是线性模型,它们最终的投票(voting)不会改进模型的预测结果。
既然不同的分类器不适⽤,那么可以尝试将数据分成⼏部分,每个部分的数据训练⼀个模型。
这样做的优点是不容易出现过拟合,缺点是数据量不⾜导致训练出来的模型泛化能⼒较差。
下⾯介绍两种⽐较实⽤的⽅法Bagging和Boosting。
Bagging(Bootstrap Aggregating)算法Bagging是通过组合随机⽣成的训练集⽽改进分类的集成算法。
Bagging每次训练数据时只使⽤训练集中的某个⼦集作为当前训练集(有放回随机抽样),每⼀个训练样本在某个训练集中可以多次或不出现,经过T次训练后,可得到T个不同的分类器。
对⼀个测试样例进⾏分类时,分别调⽤这T个分类器,得到T个分类结果。
最后把这T个分类结果中出现次数多的类赋予测试样例。
这种抽样的⽅法叫做,就是利⽤有限的样本资料经由多次重复抽样,重新建⽴起⾜以代表原始样本分布之新样本。
Bagging算法基本步骤:因为是随机抽样,那这样的抽样只有63%的样本是原始数据集的。
Bagging的优势在于当原始样本中有噪声数据时,通过bagging抽样,那么就有1/3的噪声样本不会被训练。
朴素贝叶斯算法的稀疏数据处理方法朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,它被广泛应用于文本分类、垃圾邮件过滤等领域。
然而,当面对稀疏数据时,传统的朴素贝叶斯算法存在一些问题,比如参数估计不准确,分类效果不佳等。
因此,如何处理稀疏数据成为了朴素贝叶斯算法的一个重要研究方向。
稀疏数据处理方法一:平滑技术在传统的朴素贝叶斯算法中,当某个特征在训练集中没有出现时,其条件概率会被设为0,这样就会导致整个样本的概率为0。
为了解决这个问题,可以采用平滑技术。
平滑技术是通过给概率加上一个很小的数值来解决零概率的问题,常用的平滑技术包括拉普拉斯平滑、Lidstone平滑等。
这些方法可以有效地处理稀疏数据,提高了朴素贝叶斯算法的分类准确率。
稀疏数据处理方法二:特征选择在处理稀疏数据时,特征选择是一种常用的方法。
特征选择是指从原始特征中选择出最具代表性的特征,从而降低维度、减少计算复杂度、提高分类准确率。
在朴素贝叶斯算法中,特征选择可以通过计算每个特征的信息增益、信息增益比等指标来实现。
通过特征选择,可以剔除一些无用的特征,保留对分类有用的特征,从而提高算法的性能。
稀疏数据处理方法三:集成学习集成学习是一种将多个分类器集成在一起的方法,它通过结合多个分类器的预测结果来得到最终的分类结果。
在处理稀疏数据时,朴素贝叶斯算法可以与其他分类器进行集成,比如决策树、支持向量机等。
通过集成学习,可以弥补朴素贝叶斯算法在处理稀疏数据时的不足,提高分类准确率。
稀疏数据处理方法四:特征转换特征转换是一种将原始特征映射到一个新的特征空间的方法,它可以通过一些数学变换来减小特征的维度,从而降低模型的复杂度。
在处理稀疏数据时,可以采用特征转换的方法,比如主成分分析(PCA)、奇异值分解(SVD)等。
通过特征转换,可以减小原始特征的维度,提高算法的计算效率,同时保持原特征的信息。
结语在处理稀疏数据时,朴素贝叶斯算法可以采用平滑技术、特征选择、集成学习、特征转换等方法来提高分类准确率。
基于集成学习算法的图像分类研究 随着互联网时代的到来,数字图像处理技术逐渐成为计算机技术中一个不可或缺的领域。图像分类作为数字图像处理技术的一种重要应用,已经被广泛应用于人们的生活中。例如,人们可以通过对数字图像进行分类,来帮助审阅照片,检索网上图片,甚至用于医学图像的诊断等等。因此,能够实现高效准确的图像分类算法变得至关重要。本文就基于集成学习算法来进行图像分类的研究进行探讨。
一、图像分类简介 图像分类指的是将输入的图像划分为事先定义好的若干类别之中的一个或多个类别的过程。在图像分类中涉及了诸多复杂的数学算法,例如模式识别、特征提取、分类器训练等等。通常,图像分类任务可以分为两个阶段:特征学习和分类器学习,其中特征学习可以通过人工设计来完成,也可以利用机器学习自动学习提取。而分类器学习则可以采用各种各样的分类算法,这些算法包括传统的决策树、支持向量机、朴素贝叶斯等算法与神经网络、深度学习等算法。
二、集成学习算法概述 集成学习算法是一种基于多个弱分类器构建出一个强分类器的算法。它利用多个分类器的集合来解决单一的分类器处理不了的问题。主要包括两种集成学习算法:boosting 和 bagging 。
1、Boosting Boosting 算法通过重复对同一个训练数据进行学习,来加强对数据的学习能力。它不断地调整分类器对于样本的难易程度来更好地分类样本。在重复的学习过程中,Boosting 采用了一种分层的方法,将错误率相对较低的分类器赋予更高的权重,并且将错误率高的分类器赋予较低的权重,以此来提高整个分类器的准确率。
2、Bagging Bagging 算法是一种通过随机抽样的方法来减小预测误差的集成学习方法。它不同于 Boosting 算法,Bagging 算法训练多个相互独立的分类器,每个分类器只使用部分数据来进行模型的训练,然后将这些分类器组成一个强分类器。在 Bagging 算法中,分类器可以选择不同的参数、不同的特征,而这些参数和特征的选取是随机的,并且每个分类器在训练的过程中使用不同的样本集来进行训练。
foil算法介绍FOIL算法是一种用于特征选择和特征组合的机器学习算法。
它是一种基于规则的算法,通过组合不同的特征,生成新的特征来增加分类器的准确性。
本文将详细介绍FOIL算法的原理、步骤和应用。
一、算法原理FOIL算法的全称是First Order Inductive Learner,即一阶归纳学习器。
它基于归纳逻辑编程(ILP)的思想,通过逐步构建规则来进行学习和推理。
FOIL算法主要分为两个步骤:正例泛化和负例特殊化。
正例泛化是指通过对正例进行泛化操作,生成新的规则。
在这一步骤中,算法会根据已有的正例样本,尝试不同的特征组合,并根据这些组合生成新的规则。
通过这种方式,算法可以不断扩展规则的覆盖范围,提高分类器的准确性。
负例特殊化是指通过对负例进行特殊化操作,生成新的规则。
在这一步骤中,算法会根据已有的负例样本,尝试剔除对负例进行错误分类的规则。
通过这种方式,算法可以不断优化分类器的性能,减少错误分类的情况。
二、算法步骤FOIL算法的具体步骤如下:1. 初始化规则集合为空。
2. 选择一个正例样本作为种子规则。
3. 根据种子规则和已有规则,生成新的规则。
4. 通过正例泛化和负例特殊化,不断优化规则集合。
5. 如果规则集合不再变化,则停止算法;否则,返回第3步。
三、算法应用FOIL算法在特征选择和特征组合方面具有广泛的应用。
它可以用于数据挖掘、文本分类、图像识别等领域。
在数据挖掘中,FOIL算法可以帮助我们找到最具有代表性的特征,并将其用于分类和预测。
通过特征选择,我们可以减少特征空间的维度,提高分类器的效率和准确性。
在文本分类中,FOIL算法可以帮助我们从大量的文本数据中提取关键特征,并用于文本分类和情感分析。
通过特征组合,我们可以将多个特征进行组合,生成新的特征,从而提高分类器的性能。
在图像识别中,FOIL算法可以帮助我们从图像中提取关键特征,并用于物体识别和人脸识别。
通过特征选择和特征组合,我们可以提高图像识别的准确性和鲁棒性。