标准萤火虫算法源码
- 格式:docx
- 大小:13.41 KB
- 文档页数:4
Jflash-s3c2410(linux 版本)源码分析最近在远峰公司买了arm9的板子,S3C2410,ARM920T ,没有Nor flash ,Nand Flash 是64M ,SDRAM 是K9f1208,本人对linux 的热情大于windows ,所以想在linux 下做开发,可是远峰公司只给我YFSJF.exe 文件,而且没有源代码,每次在linux 下编译好了后还得切换到windows 下烧录,很是麻烦,于是在网上找了很多Jflash 类似的程序,不过不同的烧录针对不同的硬件平台,Jflash 是跟硬件紧密结合的,比如有的针对Nor Flash ,有的针对Nand Flash 的,不同内核有不同的Jflash ,而且相同的内核也有不同的版本,因为Jtag 的原理图不同,就只能有相对应的Jflash ,程序中的定义要与pc 机并口与Jtag 接口的对应相一致。
在进入源码分析之前要介绍一些预备的知识,有助于理解源代码,毕竟这个程序和硬件联系很紧密的。
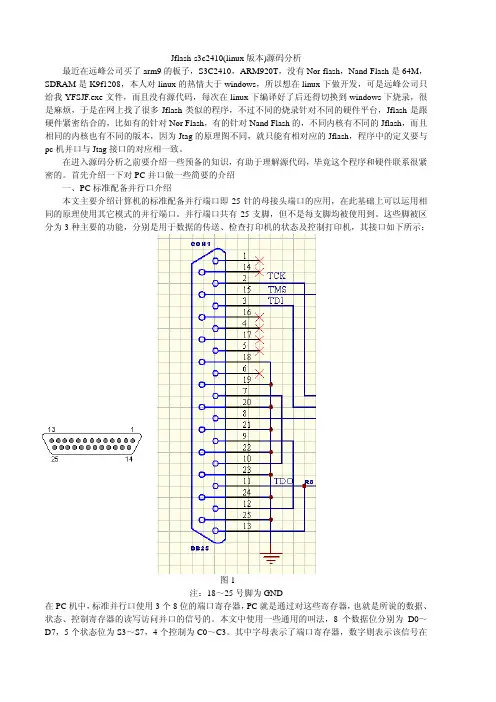
首先介绍一下对PC 并口做一些简要的介绍一、PC 标准配备并行口介绍本文主要介绍计算机的标准配备并行端口即25针的母接头端口的应用,在此基础上可以运用相同的原理使用其它模式的并行端口。
并行端口共有25支脚,但不是每支脚均被使用到。
这些脚被区图1分为3种主要的功能,分别是用于数据的传送、检查打印机的状态及控制打印机,其接口如下所示:注:18~脚为GND在PC 机中,标准并行口使用3个8位对这些寄存器,也就是所说的数据、25号的端口寄存器,PC 就是通过状态、控制寄存器的读写访问并口的信号的。
本文中使用一些通用的叫法,8个数据位分别为D0~D7,5个状态位为S3~S7,4个控制为C0~C3。
其中字母表示了端口寄存器,数字则表示该信号在寄存器中的位。
数据寄存器据端口或称数据寄存器(D0~D7)保存了写入数据输出端口的一字节信息。
数据端口可以写入数数据寄存器(即数据输出端口)可擦写、基地址数据,也可以读出数据(即可擦写);写进去的当然是我们希望从数据端口引脚输出的数据,不过读进来的也只是我们上次写进去的数据,或是原来保留在里面的数据,并不是从端口引脚输入PC 的数据。

布林彩虹线指标源码布林彩虹线指标是一种基于布林带的技术分析指标,它通过将多条布林带合并成一条彩虹线来展示价格的波动情况。
该指标源码可以用于编程交易系统中,用于生成布林彩虹线的数值,并根据这些数值进行交易决策。
以下是一个全面详细的布林彩虹线指标源码:```python# 导入必要的库import numpy as npimport pandas as pd# 定义计算布林带的函数def calculate_bollinger_bands(data, window=20, std_dev=2): # 计算均线data['MA'] = data['Close'].rolling(window=window).mean()# 计算标准差data['std'] = data['Close'].rolling(window=window).std()# 计算上轨和下轨data['Upper Band'] = data['MA'] + std_dev * data['std']data['Lower Band'] = data['MA'] - std_dev * data['std']return data# 定义计算布林彩虹线的函数def calculate_rainbow_bands(data, colors=['red', 'orange', 'yellow', 'green', 'blue', 'purple']):# 计算每个颜色对应的百分位数(20%,40%,60%,80%) percentiles = [20, 40, 60, 80]bands = []for color, percentile in zip(colors, percentiles):# 计算每个百分位数对应的价格data[color] = np.percentile(data['Close'], percentile) bands.append(color)return data, bands# 读取数据data = pd.read_csv('data.csv')# 计算布林带data = calculate_bollinger_bands(data)# 计算布林彩虹线data, bands = calculate_rainbow_bands(data)# 打印结果print("布林彩虹线指标:")print("------------------")print("日期\t\t收盘价\t\t均线\t\t上轨\t\t下轨\t\t红色(20%)\t橙色(40%)\t黄色(60%)\t绿色(80%)")print("-----------------------------------------------------------------------------------")for index, row in data.iterrows():print(f"{row['Date']}\t{row['Close']}\t{row['MA']}\t{row['Upper Band']}\t{row['Lower Band']}", end="\t")for band in bands:print(f"{row[band]}", end="\t")print("\n")```这段源码实现了计算布林彩虹线指标的功能。

捉妖神器天下妖股统统现出原形通达信指标公式源码CC为股票的绝对波动率,计算公式为:ABS((2*CLOSE+HIGH+LOW)/4-MA(CLOSE,20))/MA(CLOSE,20)。
DD为股票的动态移动平均线,计算公式为:DMA(CLOSE,CC)。
上轨为DD的1.07倍,上轨1为DD的1.05倍,下轨为DD的0.93倍,中轨为上轨和下轨的平均值。
疯狂为DD的1.14倍,用灰色点状线表示。
抄底为DD的0.86倍,用灰色点状线表示。
如果上轨大于等于前一天的上轨,则上轨为红色实线,否则为虚线。
中轨和下轨同理。
中期临界点为DMA(MA(CLOSE+REF(CLOSE,5)/CLOSE*0.098,90),VOL),用灰色圆点表示。
年为DMA(MA(CLOSE+REF(CLOSE,5)/CLOSE*0.098,250),VOL),用灰色圆点表示。
DIR2为收盘价与前10天收盘价差的绝对值,VIR2为收盘价与前一天收盘价差的绝对值的10日累和。
ER2为DIR2与VIR2的比值,CS2为ER2的加权平均值,CQ2为CS2的平方。
重新改写每段话:1.使用表示无限均线,使用DMA(CLOSE,(VOL)/(CAPITAL)) 表示 DMA 线。
同时,使用STICKLINE 函数绘制 K 线图,其中使用 COLORRED 表示上涨,使用 COLORGREEN 表示下跌。
2.使用 ZDT:=(C-REF(C,1))/REF(C,1)*100.表示涨跌幅度,并使用 STICKLINE 函数绘制 K 线图,其中使用COLORYELLOW 表示涨停,使用 COLOR00FF00 表示跌停。
3.定义涨停1 和不破价变量,使用 Z:=(L+H+C*2)/4 和EMA(Z,14)COLORBLUE,LINETHICK2 表示 Z 值和 EMA 线。
Z2:=EMA(Z,25)COLORLIBLUE,LINETHICK2;Z1B:=(Z1-REF(Z1,1))/REF(Z1,1)*100;Z2B:=(Z2-REF(Z2,1))/REF(Z2,1)*100;如果Z1B>=0且BARSLAST(CROSS(Z1B,0))>0,则考虑打击,否则不画线。
import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.File;import java.io.FileReader;import java.io.FileWriter;import java.io.IOException;import no.uib.cipr.matrix.DenseMatrix;import no.uib.cipr.matrix.DenseVector;import no.uib.cipr.matrix.Matrices;import no.uib.cipr.matrix.NotConvergedException;public class elm {private DenseMatrix train_set;private DenseMatrix test_set;private int numTrainData;private int numTestData;private DenseMatrix InputWeight;private float TrainingTime;private float TestingTime;private double TrainingAccuracy, TestingAccuracy;private int Elm_Type;private int NumberofHiddenNeurons;private int NumberofOutputNeurons;private int NumberofInputNeurons;private String func;private int []label;private DenseMatrix BiasofHiddenNeurons;private DenseMatrix OutputWeight;private DenseMatrix testP;private DenseMatrix testT;private DenseMatrix Y;private DenseMatrix T;public elm(int elm_type, int numberofHiddenNeurons, String ActivationFunction){Elm_Type = elm_type;NumberofHiddenNeurons = numberofHiddenNeurons;func = ActivationFunction;TrainingTime = 0;TestingTime = 0;TrainingAccuracy= 0;TestingAccuracy = 0;NumberofOutputNeurons = 1;}public elm(){}public DenseMatrix loadmatrix(String filename) throws IOException{BufferedReader reader = new BufferedReader(new FileReader(new File(filename)));String firstlineString = reader.readLine();String []strings = firstlineString.split(" ");int m = Integer.parseInt(strings[0]);int n = Integer.parseInt(strings[1]);if(strings.length > 2)NumberofOutputNeurons = Integer.parseInt(strings[2]);DenseMatrix matrix = new DenseMatrix(m, n);firstlineString = reader.readLine();int i = 0;while (i<m) {String []datatrings = firstlineString.split(" ");for (int j = 0; j < n; j++) {matrix.set(i, j,Double.parseDouble(datatrings[j]));}i++;firstlineString = reader.readLine();}return matrix;}public void train(String TrainingData_File) throws NotConvergedException{try {train_set = loadmatrix(TrainingData_File);} catch (IOException e) {e.printStackTrace();}train();}public void train(double [][]traindata) throws NotConvergedException{//classification require a the number of classtrain_set = new DenseMatrix(traindata);int m = train_set.numRows();if(Elm_Type == 1){double maxtag = traindata[0][0];for (int i = 0; i < m; i++) {if(traindata[i][0] > maxtag)maxtag = traindata[i][0];}NumberofOutputNeurons = (int)maxtag+1;}train();}private void train() throws NotConvergedException{numTrainData = train_set.numRows();NumberofInputNeurons = train_set.numColumns() - 1;InputWeight = (DenseMatrix)Matrices.random(NumberofHiddenNeurons, NumberofInputNeurons);DenseMatrix transT = new DenseMatrix(numTrainData, 1);DenseMatrix transP = new DenseMatrix(numTrainData, NumberofInputNeurons);for (int i = 0; i < numTrainData; i++) {transT.set(i, 0, train_set.get(i, 0));for (int j = 1; j <= NumberofInputNeurons; j++)transP.set(i, j-1, train_set.get(i, j));}T = new DenseMatrix(1,numTrainData);DenseMatrix P = newDenseMatrix(NumberofInputNeurons,numTrainData);transT.transpose(T);transP.transpose(P);if(Elm_Type != 0) //CLASSIFIER{label = new int[NumberofOutputNeurons];for (int i = 0; i < NumberofOutputNeurons; i++) {label[i] = i; }DenseMatrix tempT = newDenseMatrix(NumberofOutputNeurons,numTrainData);tempT.zero();for (int i = 0; i < numTrainData; i++){int j = 0;for (j = 0; j < NumberofOutputNeurons; j++){if (label[j] == T.get(0, i))break;}tempT.set(j, i, 1);}T = newDenseMatrix(NumberofOutputNeurons,numTrainData); //T=temp_T*2-1;for (int i = 0; i < NumberofOutputNeurons; i++){for (int j = 0; j < numTrainData; j++)T.set(i, j, tempT.get(i, j)*2-1);}transT = newDenseMatrix(numTrainData,NumberofOutputNeurons);T.transpose(transT);}long start_time_train = System.currentTimeMillis();BiasofHiddenNeurons = (DenseMatrix)Matrices.random(NumberofHiddenNeurons, 1);DenseMatrix tempH = newDenseMatrix(NumberofHiddenNeurons, numTrainData);InputWeight.mult(P, tempH);//DenseMatrix ind = new DenseMatrix(1, numTrainData);DenseMatrix BiasMatrix = newDenseMatrix(NumberofHiddenNeurons, numTrainData);for (int j = 0; j < numTrainData; j++) {for (int i = 0; i < NumberofHiddenNeurons; i++) {BiasMatrix.set(i, j, BiasofHiddenNeurons.get(i, 0));}}tempH.add(BiasMatrix);DenseMatrix H = new DenseMatrix(NumberofHiddenNeurons, numTrainData);if(func.startsWith("sig")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTrainData; i++) {double temp = tempH.get(j, i);temp = 1.0f/ (1 + Math.exp(-temp));H.set(j, i, temp);}}}else if(func.startsWith("sin")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTrainData; i++) {double temp = tempH.get(j, i);temp = Math.sin(temp);H.set(j, i, temp);}}}else if(func.startsWith("hardlim")){}else if(func.startsWith("tribas")){}else if(func.startsWith("radbas")){}DenseMatrix Ht = newDenseMatrix(numTrainData,NumberofHiddenNeurons);H.transpose(Ht);Inverse invers = new Inverse(Ht);DenseMatrix pinvHt = invers.getMPInverse();OutputWeight = new DenseMatrix(NumberofHiddenNeurons, NumberofOutputNeurons);pinvHt.mult(transT, OutputWeight);long end_time_train = System.currentTimeMillis();TrainingTime = (end_time_train -start_time_train)* 1.0f/1000;DenseMatrix Yt = newDenseMatrix(numTrainData,NumberofOutputNeurons);Ht.mult(OutputWeight,Yt);Y = new DenseMatrix(NumberofOutputNeurons,numTrainData);Yt.transpose(Y);if(Elm_Type == 0){double MSE = 0;for (int i = 0; i < numTrainData; i++) {MSE += (Yt.get(i, 0) - transT.get(i, 0))*(Yt.get(i, 0) - transT.get(i, 0));}TrainingAccuracy = Math.sqrt(MSE/numTrainData);}else if(Elm_Type == 1){float MissClassificationRate_Training=0;for (int i = 0; i < numTrainData; i++) {double maxtag1 = Y.get(0, i);int tag1 = 0;double maxtag2 = T.get(0, i);int tag2 = 0;for (int j = 1; j < NumberofOutputNeurons; j++) {if(Y.get(j, i) > maxtag1){maxtag1 = Y.get(j, i);tag1 = j;}if(T.get(j, i) > maxtag2){maxtag2 = T.get(j, i);tag2 = j;}}if(tag1 != tag2)MissClassificationRate_Training ++;}TrainingAccuracy = 1 -MissClassificationRate_Training* 1.0f/numTrainData;}}public void test(String TestingData_File){try {test_set = loadmatrix(TestingData_File);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}numTestData = test_set.numRows();DenseMatrix ttestT = new DenseMatrix(numTestData, 1);DenseMatrix ttestP = new DenseMatrix(numTestData, NumberofInputNeurons);for (int i = 0; i < numTestData; i++) {ttestT.set(i, 0, test_set.get(i, 0));for (int j = 1; j <= NumberofInputNeurons; j++)ttestP.set(i, j-1, test_set.get(i, j));}testT = new DenseMatrix(1,numTestData);testP = newDenseMatrix(NumberofInputNeurons,numTestData);ttestT.transpose(testT);ttestP.transpose(testP);long start_time_test = System.currentTimeMillis();DenseMatrix tempH_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);InputWeight.mult(testP, tempH_test);DenseMatrix BiasMatrix2 = newDenseMatrix(NumberofHiddenNeurons, numTestData);for (int j = 0; j < numTestData; j++) {for (int i = 0; i < NumberofHiddenNeurons; i++) {BiasMatrix2.set(i, j, BiasofHiddenNeurons.get(i, 0));}tempH_test.add(BiasMatrix2);DenseMatrix H_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);if(func.startsWith("sig")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = 1.0f/ (1 + Math.exp(-temp));H_test.set(j, i, temp);}}}else if(func.startsWith("sin")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = Math.sin(temp);H_test.set(j, i, temp);}}}else if(func.startsWith("hardlim")){}else if(func.startsWith("tribas")){}else if(func.startsWith("radbas")){}DenseMatrix transH_test = newDenseMatrix(numTestData,NumberofHiddenNeurons);H_test.transpose(transH_test);DenseMatrix Yout = newDenseMatrix(numTestData,NumberofOutputNeurons);transH_test.mult(OutputWeight,Yout);DenseMatrix testY = newDenseMatrix(NumberofOutputNeurons,numTestData);Yout.transpose(testY);long end_time_test = System.currentTimeMillis();TestingTime = (end_time_test -start_time_test)* 1.0f/1000;//REGRESSIONif(Elm_Type == 0){double MSE = 0;for (int i = 0; i < numTestData; i++) {MSE += (Yout.get(i, 0) -testT.get(0,i))*(Yout.get(i, 0) - testT.get(0,i));}TestingAccuracy = Math.sqrt(MSE/numTestData);}//CLASSIFIERelse if(Elm_Type == 1){DenseMatrix temptestT = newDenseMatrix(NumberofOutputNeurons,numTestData);for (int i = 0; i < numTestData; i++){int j = 0;for (j = 0; j < NumberofOutputNeurons; j++){if (label[j] == testT.get(0, i))break;}temptestT.set(j, i, 1);}testT = newDenseMatrix(NumberofOutputNeurons,numTestData);for (int i = 0; i < NumberofOutputNeurons; i++){for (int j = 0; j < numTestData; j++)testT.set(i, j, temptestT.get(i, j)*2-1);}float MissClassificationRate_Testing=0;for (int i = 0; i < numTestData; i++) {double maxtag1 = testY.get(0, i);int tag1 = 0;double maxtag2 = testT.get(0, i);int tag2 = 0;for (int j = 1; j < NumberofOutputNeurons; j++) { if(testY.get(j, i) > maxtag1){maxtag1 = testY.get(j, i);tag1 = j;}if(testT.get(j, i) > maxtag2){maxtag2 = testT.get(j, i);tag2 = j;}}if(tag1 != tag2)MissClassificationRate_Testing ++;}TestingAccuracy = 1 -MissClassificationRate_Testing* 1.0f/numTestData;}}public double[] testOut(double[][] inpt){test_set = new DenseMatrix(inpt);return testOut();}public double[] testOut(double[] inpt){test_set = new DenseMatrix(new DenseVector(inpt));return testOut();}//Output numTestData*NumberofOutputNeuronsprivate double[] testOut(){numTestData = test_set.numRows();NumberofInputNeurons = test_set.numColumns()-1;DenseMatrix ttestT = new DenseMatrix(numTestData, 1);DenseMatrix ttestP = new DenseMatrix(numTestData, NumberofInputNeurons);for (int i = 0; i < numTestData; i++) {ttestT.set(i, 0, test_set.get(i, 0));for (int j = 1; j <= NumberofInputNeurons; j++)ttestP.set(i, j-1, test_set.get(i, j));}testT = new DenseMatrix(1,numTestData);testP = newDenseMatrix(NumberofInputNeurons,numTestData);ttestT.transpose(testT);ttestP.transpose(testP);DenseMatrix tempH_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);InputWeight.mult(testP, tempH_test);DenseMatrix BiasMatrix2 = newDenseMatrix(NumberofHiddenNeurons, numTestData);for (int j = 0; j < numTestData; j++) {for (int i = 0; i < NumberofHiddenNeurons; i++) {BiasMatrix2.set(i, j, BiasofHiddenNeurons.get(i, 0));}}tempH_test.add(BiasMatrix2);DenseMatrix H_test = newDenseMatrix(NumberofHiddenNeurons, numTestData);if(func.startsWith("sig")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = 1.0f/ (1 + Math.exp(-temp));H_test.set(j, i, temp);}}}else if(func.startsWith("sin")){for (int j = 0; j < NumberofHiddenNeurons; j++) { for (int i = 0; i < numTestData; i++) {double temp = tempH_test.get(j, i);temp = Math.sin(temp);H_test.set(j, i, temp);}}}else if(func.startsWith("hardlim")){}else if(func.startsWith("tribas")){}else if(func.startsWith("radbas")){}DenseMatrix transH_test = newDenseMatrix(numTestData,NumberofHiddenNeurons);H_test.transpose(transH_test);DenseMatrix Yout = newDenseMatrix(numTestData,NumberofOutputNeurons);transH_test.mult(OutputWeight,Yout);double[] result = new double[numTestData];if(Elm_Type == 0){for (int i = 0; i < numTestData; i++)result[i] = Yout.get(i, 0);}else if(Elm_Type == 1){for (int i = 0; i < numTestData; i++) {int tagmax = 0;double tagvalue = Yout.get(i, 0);for (int j = 1; j < NumberofOutputNeurons; j++) {if(Yout.get(i, j) > tagvalue){tagvalue = Yout.get(i, j);tagmax = j;}}result[i] = tagmax;}}return result;}public float getTrainingTime() {return TrainingTime;}public double getTrainingAccuracy() {return TrainingAccuracy;public float getTestingTime() {return TestingTime;}public double getTestingAccuracy() {return TestingAccuracy;}public int getNumberofInputNeurons() {return NumberofInputNeurons;}public int getNumberofHiddenNeurons() {return NumberofHiddenNeurons;}public int getNumberofOutputNeurons() {return NumberofOutputNeurons;}public DenseMatrix getInputWeight() {return InputWeight;}public DenseMatrix getBiasofHiddenNeurons() {return BiasofHiddenNeurons;}public DenseMatrix getOutputWeight() {return OutputWeight;}//for predicting a data file based on a trained model.public void testgetoutput(String filename) throws IOException {try {test_set = loadmatrix(filename);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}numTestData = test_set.numRows();NumberofInputNeurons = test_set.numColumns() - 1;double rsum = 0;double []actual = new double[numTestData];double [][]data = newdouble[numTestData][NumberofInputNeurons];for (int i = 0; i < numTestData; i++) {actual[i] = test_set.get(i, 0);for (int j = 0; j < NumberofInputNeurons; j++) data[i][j] = test_set.get(i, j+1);}double[] output = testOut(data);BufferedWriter writer = new BufferedWriter(new FileWriter(new File("Output")));for (int i = 0; i < numTestData; i++) {writer.write(String.valueOf(output[i]));writer.newLine();if(Elm_Type == 0){rsum += (output[i] - actual[i])*(output[i] - actual[i]);}if(Elm_Type == 1){if(output[i] == actual[i])rsum ++;}}writer.flush();writer.close();if(Elm_Type == 0)System.out.println("Regression GetOutPut RMSE: "+Math.sqrt(rsum* 1.0f/numTestData));else if(Elm_Type == 1)System.out.println("Classfy GetOutPut Right:"+rsum*1.0f/numTestData);}}。
![[转载]自用的观察筹码移动分布的指标(源码)(附图)](https://uimg.taocdn.com/16905feb760bf78a6529647d27284b73f2423695.webp)
[转载]⾃⽤的观察筹码移动分布的指标(源码)(附图)称帝:(COST(99)+COST(93)+COST(85))/3,COLORYELLOW,DOTLINE,LINETHICK1;汉界:(COST(84)+COST(67)+COST(50))/3,COLORGREEN,DOTLINE,LINETHICK1;楚河:(COST(16)+COST(34)+COST(49))/3,COLORRED,DOTLINE,LINETHICK1;⾃刎:(COST(1)+COST(7)+COST(15))/3,COLORMAGENTA,DOTLINE,LINETHICK1;汉界飘移:(汉界-REF(汉界,3))/REF(汉界,3)*100,COLORGREEN,NODRAW;楚河飘移:(楚河-REF(楚河,3))/REF(楚河,3)*100,COLORRED,NODRAW;****************************************************************************************有同学说线没办法测试通过,可能是版本的问题吧,把线型和颜⾊换个位置或去掉试试,来个纯净版的称帝:(COST(99)+COST(93)+COST(85))/3,LINETHICK1;汉界:(COST(84)+COST(67)+COST(50))/3,LINETHICK1;楚河:(COST(16)+COST(34)+COST(49))/3,LINETHICK1;⾃刎:(COST(1)+COST(7)+COST(15))/3,LINETHICK1;汉界飘移:(汉界-REF(汉界,3))/REF(汉界,3)*100,NODRAW;楚河飘移:(楚河-REF(楚河,3))/REF(楚河,3)*100,NODRAW;****************************************************************************************先来解释⼀下每段代码的含意:帝王:(COST(99)+COST(93)+COST(85))/3,COLORYELLOW,DOTLINE,LINETHICK1;{输出称帝:(获利盘为99%的成本分布+获利盘为93%的成本分布+获利盘为85%的成本分布)/3,画黄⾊,也就是获利盘为99%、93%、85%三个区域的平均成本}汉界:(COST(84)+COST(67)+COST(50))/3,COLORGREEN,DOTLINE,LINETHICK1;{输出汉界:(获利盘为84%的成本分布+获利盘为67%的成本分布+获利盘为50%的成本分布)/3,画绿⾊,也就是获利盘为84%、67%、50%三个区域的平均成本}楚河:(COST(16)+COST(34)+COST(49))/3,COLORRED,DOTLINE,LINETHICK1;{输出楚河:(获利盘为16%的成本分布+获利盘为34%的成本分布+获利盘为49%的成本分布)/3,画红⾊,也就是获利盘为49%、34%、16%三个区域的平均成本}⾃刎:(COST(1)+COST(7)+COST(15))/3,COLORMAGENTA,DOTLINE,LINETHICK1;{输出⾃刎:(获利盘为1%的成本分布+获利盘为7%的成本分布+获利盘为15%的成本分布)/3,画洋红⾊,也就是获利盘为15%、7%、1%三个区域的平均成本}汉界飘移:(汉界-REF(汉界,3))/REF(汉界,3)*100,COLORGREEN,NODRAW;楚河飘移:(楚河-REF(楚河,3))/REF(楚河,3)*100,COLORRED,NODRAW;这两直接输出数值,没有划线,主要⽤来查看这汉界和楚河这两条线上⾏或下⾏的速度,值越⼤,说明筹码移动的速度越快,正在激烈的动作,变盘概率越⾼⽐如正值突然变⼤(⼤于5以上),分别对应的线就会表现为⼤⾓度向上拐,说明底部锁仓筹码正在快速上移派发如果负数绝对值突然变⼤(低于-5以下),分别对应的线就会表现为⼤⾓度向下拐,说明顶部套牢筹码正在快速下移割⾁这个指标的⼏条线,可以从⼏个⽅⾯看⼀⽅⾯可以直观的反应出该股的筹码分布情况:每条线分别代表某获利区间的平均价格,如上⾯对代码的解释,分别对应着⼏个区间获利盘对应的价位如上图所⽰,参照上⾯的解释,当前的四条线分别代表四个获利区间的价格,⼀⽬了然,如果把⿏标指定固定的某⼀天K线,上⾯的值也会变为相对应的当天的数值另⼀⽅⾯,可以直观的看到该股当前的筹码获利状况:当股价运⾏于帝王线附近时,证明市场上绝⼤部份的持股⼈是获利的当股价运⾏于汉界线附近时,说明该股有少量的套牢筹码当股价运⾏于楚河线附近时,说明该股有⼤量的套牢筹码当股价运⾏于⾃刎线附近时,说明该股⼤部份的筹码是套牢的如上图中吉林森⼯当前运⾏于帝王线附近,说明场内⼤部份资⾦(将近90%)是获利的再⼀个最主要的⽅⾯,是可以直观的看到随着股价的变化,各部份筹码的移动情况,这也就是我们研究筹码分布时最关⼼的,筹码是上移了,还是下移了,是在相对顶部集中了,还是在相对底部集中了,股价拉升或挖坑的过程中,上⽅和下⽅筹码的变化情况等等。

Cascadeclassifier源码详解一、前言在计算机视觉和图像处理领域,Cascadeclassifier是一种常用的目标检测算法。
它可以用于人脸识别、物体检测等任务,被广泛应用于人工智能、安防监控、互联网等领域。
Cascadeclassifier引入了Haar-like特征和Adaboost算法,通过级联多个弱分类器构成的强分类器,来实现对目标的高效检测。
本文将对Cascadeclassifier源码进行详细解读,包括算法原理、代码结构、实现细节、优化技巧等方面的内容。
二、算法原理1. Haar-like特征Haar-like特征是Cascadeclassifier算法中的基础。
它通过对图像进行特征提取,将图像转换成一组特征值,用于表示图像中的区域。
Haar-like特征包括直方图、水平/垂直直线特征等,这些特征可以对目标的不同形状、纹理、边缘等进行描述。
2. Adaboost算法Adaboost算法是Cascadeclassifier的核心。
它通过训练一系列弱分类器,然后将这些弱分类器进行级联,构成一个强分类器。
Adaboost 算法的关键在于对训练样本进行加权,使得错误分类的样本在下一轮训练中得到更多重视,从而不断改进弱分类器的准确率。
3. 级联分类器级联分类器是Cascadeclassifier的特点之一。
它将多个弱分类器进行级联,当一个样本通过了第一个弱分类器,才会继续传递给下一个弱分类器。
这种级联结构能够在保证高检测率的大大减少了计算量,提高了算法的效率。
三、代码结构1. 源文件组织Cascadeclassifier的源码通常组织如下:- haarcascade_frontalface_alt.xml:前置摄像头人脸检测模型- haarcascade_frontalface_default.xml:默认人脸检测模型- haarcascade_eye.xml:眼部检测模型- haarcascade_upperbody.xml:上半身检测模型- haarcascade_licence_plate_rus_16stages.xml:车牌检测模型- haarcascade_smile.xml:微笑检测模型- haarcascade_fullbody.xml:全身检测模型2. 源码分析Cascadeclassifier的源码通常包括以下几个部分:- 加载模型:通过读取xml文件,加载预训练的级联分类器模型- 图像预处理:对输入图像进行灰度转换、归一化等预处理操作- 特征提取:利用Haar-like特征对图像进行特征提取- Adaboost分类:通过Adaboost算法对特征进行分类,得到分类结果- 级联分类:对多个弱分类器进行级联,得到较为精确的目标检测结果- 检测输出:将检测结果输出到图像上,或者返回目标的位置坐标四、实现细节1. Haar-like特征提取在Cascadeclassifier的源码中,Haar-like特征提取是一个关键的步骤。

pinbar指标源码以下是一个简单的pinbar指标的python源码,解释了该指标的计算方式和使用方法。
代码中使用了pandas和numpy库来处理数据和进行计算。
```pythonimport pandas as pdimport numpy as npdef calculate_pinbar(data):#计算每根K线的上引线、实体长度和下引线data['upper_wick'] = np.where(data['high'] > data['close'], data['high'] - data['close'], 0)data['lower_wick'] = np.where(data['open'] > data['close'], data['open'] - data['close'], 0)data['body'] = abs(data['close'] - data['open'])#计算每根K线的总长度data['total_range'] = data['high'] - data['low']# 判断pinbar条件data['is_pinbar'] = np.where(data['upper_wick'] >= 2 * data['body']) & # 上引线至少是实体长度的两倍(data['lower_wick'] >= 2 * data['body']) & # 下引线至少是实体长度的两倍(data['body'] > 0) & # 实体长度大于0,即非十字星(data['body'] / data['total_range'] > 0.4), # 实体长度占总长度的比例大于0.4True, False)return data['is_pinbar']#使用示例#创建示例数据data = pd.DataFrame'open': [10, 12, 15, 8, 12],'high': [14, 15, 16, 9, 13],'low': [8, 11, 14, 5, 10],'close': [12, 14, 11, 7, 11]})# 计算pinbar指标pins = calculate_pinbar(data)#打印结果print(pins)```以上代码实现了一个简单的pinbar指标计算函数`calculate_pinbar`,其中传入的参数`data`是一个包含K线数据的pandas DataFrame。

博易大师指标公式汇总以及源代码集成博易大师(Bollinger Bands)指标是一种常用的股票交易技术分析工具,由约翰·波林格(John Bollinger)在1980年代提出。
该指标通过计算标准差来衡量股票价格的波动性,并结合移动平均线来提供买入和卖出的参考。
以下是博易大师指标的公式和一些常见的源代码集成示例。
1.计算移动平均线(MA)MA=(收盘价1+收盘价2+...+收盘价n)/n2.计算标准差(SD)SD = sqrt(((收盘价1 - MA)^2 + (收盘价2 - MA)^2 + ... + (收盘价n - MA)^2) / n)3. 计算上轨线(Upper Band)Upper Band = MA + k * SD4. 计算下轨线(Lower Band)Lower Band = MA - k * SD其中,n为计算移动平均线和标准差的周期数,k为标准差的倍数。
以下是一些常用编程语言的源代码集成示例:Python:```pythonimport numpy as npdef bollinger_bands(data, n, k):ma = np.mean(data)sd = np.std(data)upper_band = ma + k * sdlower_band = ma - k * sdreturn upper_band, lower_band#示例用法closing_prices = [10, 12, 14, 16, 18, 20, 22, 24, 26, 28]n=10k=2upper_band, lower_band = bollinger_bands(closing_prices, n, k)print("Upper Band:", upper_band)print("Lower Band:", lower_band)```R:```rbollinger_bands <- function(data, n, k)ma <- mean(data)sd <- sd(data)upper_band <- ma + k * sdlower_band <- ma - k * sdreturn(c(upper_band, lower_band))#示例用法closing_prices <- c(10, 12, 14, 16, 18, 20, 22, 24, 26, 28) n<-10k<-2bands <- bollinger_bands(closing_prices, n, k)cat("Upper Band:", bands[1], "\n")cat("Lower Band:", bands[2], "\n")```以上是博易大师指标公式的汇总以及在Python和R编程语言中的源代码集成示例。

bevdepth源码解读bevdepth是一个开源项目,旨在实现高精度的Bird'sEyeView(BEV)深度估计。
BEV深度估计在自动驾驶和机器人技术中有着广泛的应用,因为它可以帮助我们理解周围环境的三维结构。
源码解读是一个相对复杂的任务,因此在这里,我将尽量简洁地概述bevdepth的源码结构和主要功能。
1、文件结构:bevdepth的源码主要包含以下几个部分:(1)数据处理:这部分代码主要负责从原始数据中提取有用的信息,并进行预处理,以便于后续的深度估计。
(2)深度估计:这是核心部分,包含了各种深度估计算法的实现。
(3)后处理:对深度估计结果进行进一步的处理,如滤波、校正等。
(4)工具和辅助函数:提供了一些实用的工具函数和辅助类。
2、主要功能:bevdepth通过以下几个步骤来实现BEV深度估计:(1)数据预处理:读取传感器数据(如激光雷达、摄像头等),并进行必要的预处理,如滤波、去噪等。
(2)特征提取:从预处理后的数据中提取与深度估计相关的特征,如点云、边缘、纹理等。
(3)深度估计:使用各种机器学习或深度学习算法,基于提取的特征进行深度估计。
这可能是最核心的部分,因为bevdepth提供了多种不同的深度估计方法供用户选择。
(4)后处理:对深度估计结果进行必要的校正和优化,以确保最终输出的准确性和可靠性。
3、算法实现:bevdepth在深度估计方面采用了多种算法,包括但不限于:基于几何的方法、基于机器学习的方法以及基于深度学习的方法。
这些算法的选择和使用,旨在为用户提供更多的灵活性和可定制性。
为了深入理解bevdepth的源码,需要对计算机视觉、机器学习和深度学习等领域有一定的了解。
此外,阅读和理解源码还需要耐心和细心,因为源码中可能包含许多细节和潜在的逻辑。

三种SPWM算法源码.txt再过几十年,我们来相会,送到火葬场,全部烧成灰,你一堆,我一堆,谁也不认识谁,全部送到农村做化肥。
头文件 spwm.h/***************普通SPWM程序************************/#ifndef _NORMAL_SPWM_H#define _NORMAL_SPWM_H//SPWM 表结构体三项公用一个表typedef struct _SPWM_table{Uint16 TableSize; //表大小即表中所有数据Uint16 SpwmSize; //SPWM表大小volatile Uint16 *p_SPWM_A; //A相指针volatile Uint16 *p_SPWM_B; //B相指针volatile Uint16 *p_SPWM_C; //C相指针Uint16 *p_HeadTable; //表头指针指向SPWM表}SPWM_TABLE;extern SPWM_TABLE g_SPWM_Table; //全局SPWM表void InitSpwm(void);void StartSpwm(void);interrupt void ISR_T1UFINT_NORMAL_FUNC(void);void CalcSpwmWithSym(float32 a/*调制比*/,float32 w_Hz/*调制频率*/,float32 z_Hz/*载波频率*/);void CalcSpwmWithImSym(float32 a/*调制比*/,Uint16 w_Hz/*调制频率*/,Uint32 z_Hz/*载波频率*/);void CalcSpwmWithArea(float32 a/*调制比*/,Uint16 w_Hz/*调制频率*/,Uint32 z_Hz/*载波频率*/);#endif源文件#include "DSP281x.h"#include "SPWM.h"#include "float.h"#include "math.h"#define MAX_BUF 400#define PI 3.1415926Uint16 g_spwm_data[MAX_BUF]; //表的数据存储SPWM_TABLE g_SPWM_Table; //全局SPWM表//SPWM初始化程序void InitSpwm(void){g_SPWM_Table.p_HeadTable = g_spwm_data ; //指向数据表g_SPWM_Table.TableSize = MAX_BUF; //存储表的大小EALLOW;PieVectTable.T1UFINT=&ISR_T1UFINT_NORMAL_FUNC;EDIS;IER|=M_INT2; //开中断2PieCtrlRegs.PIEIER2.bit.INTx6=1; //开下益中断EvaRegs.EVAIFRA.bit.T1UFINT=1; //清楚中断标志PieCtrlRegs.PIEACK.bit.ACK2 = 1; //响应同组中断}void StartSpwm(void){EvaRegs.EVAIMRA.bit.T1UFINT = 1; //打开下益中断}//对称规则采样法void CalcSpwmWithSym(float32 a/*调制比*/,float32 w_Hz/*调制频率*/,float32 z_Hz/*载波频率*/){Uint16 tmp_PR; //T1周期值volatile Uint16 i,n,*p;float32 m;m = z_Hz/w_Hz ; //求出载波比g_SPWM_Table.SpwmSize =(Uint16)m;tmp_PR = g_T1_Clk /(2*z_Hz); //计算出其周期值p=g_SPWM_Table.p_HeadTable; //得到数据表头指针for(i=0;i<(Uint16)m;i++){n=tmp_PR*(0.5-0.5*a*sin((i+0.75)*2*PI/m));*p=n;p++;}}//不对称规则采样法void CalcSpwmWithImSym(float32 a/*调制比*/,Uint16 w_Hz/*调制频率*/,Uint32 z_Hz/*载波频率*/){Uint16 tmp_PR; //T1周期值volatile Uint16 i,n,*p;float32 m;m = z_Hz/w_Hz ; //求出载波比g_SPWM_Table.SpwmSize =(Uint16)m;tmp_PR = g_T1_Clk /(2*z_Hz); //计算出其周期值p=g_SPWM_Table.p_HeadTable; //得到数据表头指针for(i=0;i<(Uint16)m;i++){n=tmp_PR*(0.5-0.25*a*(sin((i+0.25)*2*PI/m)+sin((i+0.75)*2*PI/m)));*p=n;p++;}}//面积法void CalcSpwmWithArea(float32 a/*调制比*/,Uint16 w_Hz/*调制频率*/,Uint32 z_Hz/*载波频率*/){//Uint16 tmp_PR; //T1周期值volatile Uint16 i,n,*p;float32 m,n1,n2;m = z_Hz/w_Hz ; //求出载波比g_SPWM_Table.SpwmSize =(Uint16)m;//tmp_PR = g_T1_Clk /(2*z_Hz); //计算出其周期值p=g_SPWM_Table.p_HeadTable; //得到数据表头指针n=m;m/=2; //除去一半计算半波n1=(float32)g_T1_Clk/(8.0*m*w_Hz); // 计算首相n2=(float32)g_T2_Clk/(8.0*PI*w_Hz)*a;for(i=0;i<n;i++){*p=n1-n2*(cos(i*PI/m)-cos((i+1)*PI/m));p++;}}//中断程序interrupt void ISR_T1UFINT_NORMAL_FUNC(void) {static Uint16 cnt=0 ; //计数EvaRegs.CMPR1 = g_spwm_data[cnt];cnt++;if(cnt>=g_SPWM_Table.SpwmSize)cnt = 0;EvaRegs.EVAIFRA.bit.T1UFINT=1;PieCtrlRegs.PIEACK.bit.ACK2 = 1;EINT;}。

短线乘风指标源码【短线乘风指标源码解读】短线乘风指标是一种技术分析工具,其基本原理是通过计算股票价格的震荡幅度来预测未来的趋势,并给出买入和卖出股票的建议。
本文将介绍短线乘风指标的计算公式和源码解析,帮助略有编程基础的投资者学习该技术分析工具。
一、短线乘风指标的计算公式短线乘风指标的计算公式非常简单,其基本思路是通过计算价格的标准差比上移动平均线的值来获得相对波动性。
具体而言,该指标的计算公式如下所示:```MF=(CLOSE-MA(CLOSE,10))/(0.1*STDEV(CLOSE,10));```其中,MF代表短线乘风指标,CLOSE代表股票的收盘价,MA(CLOSE,10)代表股票收盘价的10日移动平均线,STDEV(CLOSE,10)代表股票收盘价的10日标准差。
如果MF的数值大于0,则表示股票价格处于一个较为稳定的上升期,反之则表示处于下降期。
当MF的数值在正数和负数之间波动,表示股票处于一个相对波动性较大的震荡期。
二、短线乘风指标的源码解析下面是基于Python语言的短线乘风指标源码:```pythonimport tushare as tsimport numpy as npdef MF(close, n=10, m=0.1):ma = np.mean(close[-n:]) # 计算收盘价的10日移动平均线 std = np.std(close[-n:], ddof=1) # 计算收盘价的10日标准差 mf = (close[-1] - ma) / (m * std) # 计算短线乘风指标的值return mf```源码解析:1. 导入必要的Python库,其中tushare库用于获取股票历史资料,numpy库用于计算股票数据的标准差和移动平均线等指标。
2. 定义MF函数,其中close参数代表股票的收盘价,n参数代表计算移动平均线和标准差的天数,m参数代表用于计算相对波动性的常数。
益盟操盘手经典指标源码及使用方法(全部)ABJB按部就班N(1,100,5)现价:C;顶部: cost(95) ,colorffff33;卖出: cost(75) ,colorgreen;买入: cost(30) ,colorred;底部: cost(5) ,colorteal;^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^LTSH龙腾四海N(1,100,8)坐标线:0;20;50;80;100;100-100*(HHV(HIGH,5*N)-CLOSE)/(HHV(HIGH,5*N)-LLV(LOW,5*N));海面:20,COLORGREEN;海天分界线:50,COLORYELLOW;天际:80,COLORRED;————————————————————————QSDD趋势顶底80,COLOR996699;20,COLORGREEN;10,COLORCC6633,LINETHICK2;90,COLOR9966FF,LINETHICK2;{50,COLORRED;FILLRGN(1,20,80),color222222;FILLRGN(1,90,100),color000068;FILLRGN(1,79,90),color663366;FILLRGN(1,10,20),color666600;FILLRGN(1, 0,10),color663300;}A:=MA(-100*(HHV(HIGH,34)-CLOSE)/(HHV(HIGH,34)-LLV(LOW,34)),19),COLORRED;B:=-100*(HHV(HIGH,14)-CLOSE)/(HHV(HIGH,14)-LLV(LOW,14));d:=EMA(-100*(HHV(HIGH,34)-CLOSE)/(HHV(HIGH,34)-LLV(LOW,34)),4),linethick2;长期线:A+100,color9900FF;短期线:B+100,color888888;中期线:d+100,coloryellow,linethick2;{见顶:(长期线>85 or ref(长期线,1)>85 ) and (cross(中期线,短期线) or cross(ref(中期线,1),ref(短期线,1)) )and cross(长期线,短期线);} 见顶:(ref(中期线,1)>85 and ref(短期线,1)>85 and ref(长期线,1)>65) and cross(长期线,短期线) ;顶部区域:(中期线80) and (ref(短期线,1)>95 or ref(短期线,2)>95 ) and 长期线>60 and 短期线<83.5 and 短期线<中期线and 短期线<长期线+4;顶部:=filter(顶部区域,4);{DRAWICON( 见顶, 108, 2 );}底部区域:(长期线<12 and 中期线<8 and (短期线<7.2 or ref(短期线,1)<5) and (中期线>ref(中期线,1) or 短期线>ref(短期线,1))) or (长期线<8 and 中期线<7and 短期线<15 and 短期线>ref(短期线,1)) or (长期线<10 and 中期线<7 and 短期线<1) ;stickline( {见顶 or} 顶部,99,103,20,1 ),colorred,linethick2;stickline( 底部区域,-4,0,22,0 ),colorgreen;低位金叉:长期线<15 and ref(长期线,1)<15 and 中期线<18 and 短期线>ref(短期线,1) and cross(短期线,长期线) and 短期线>中期线and (ref(短期线,1)<5 orref(短期线,2)<5 ) and (中期线>=长期线 or ref( 短期线,1)<1 );stickline( 低位金叉,0,5,11,0 ),colorred;^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^^^^^^^^BDWQ波段无敌P1:=0;P2:= IF (CLOSE>MA(CLOSE,5),P1+10,P1-10);P3:= IF (CLOSE>MA(CLOSE,10),P2+10,P2-10);P4:= IF (CLOSE>MA(CLOSE,10),P3+10,P3-10);P5:= IF (MA(CLOSE,5)>MA(CLOSE,10),P4+10,P4-10);P6:= IF (MA(CLOSE,10)>MA(CLOSE,20),P5+10,P5-10);BD:P6;STICKLINE(BD>=-50,-50,BD,3,0),COLORGREEN;STICKLINE(BD>=-30,-30,BD,3,0),COLORFFFF00;STICKLINE(BD>=0,0,BD,3,0),COLORYELLOW;STICKLINE(BD<=50 AND BD>=30,30,BD,3,0),COLORRED;{STICKLINE(BD<=50 OR BD>=30,30,BD,3,0),COLORRED;}………………………………………………………………………………BHLCT冰火两重天P1(1,100,16)能量:=SQRT(vol)*(((C-(H+L)/2))/((H+L)/2));平滑能量:=EMA(能量,P1);能量惯性:EMA(平滑能量,P1) ;STICKLINE(能量惯性>=0,(能量惯性-能量惯性*0.05),(能量惯性-能量惯性*0.15),3,0), COLOR0000CC;STICKLINE(能量惯性>=0,(能量惯性-能量惯性*0.2),(能量惯性-能量惯性*0.35),3,0), COLOR0066FF;STICKLINE(能量惯性>=0,(能量惯性-能量惯性*0.4),(能量惯性-能量惯性*0.55),3,0),COLOR0099FF;STICKLINE(能量惯性>=0,(能量惯性-能量惯性*0.6),(能量惯性-能量惯性*0.75),3,0), COLOR00CCFF;STICKLINE(能量惯性>=0,(能量惯性-能量惯性*0.8),(能量惯性-能量惯性*0.95),3,0), COLOR00FFFF;STICKLINE(能量惯性<0,(能量惯性-能量惯性*0.05),(能量惯性-能量惯性*0.15),3,0), COLORFF3300;STICKLINE(能量惯性<0,(能量惯性-能量惯性*0.2),(能量惯性-能量惯性*0.35),3,0), COLORFF6600;STICKLINE(能量惯性<0,(能量惯性-能量惯性*0.4),(能量惯性-能量惯性*0.55),3,0), COLORFF9900;STICKLINE(能量惯性<0,(能量惯性-能量惯性*0.6),(能量惯性-能量惯性*0.75),3,0), COLORFFCC00;STICKLINE(能量惯性<0,(能量惯性-能量惯性*0.8),(能量惯性-能量惯性*0.95),3,0), COLORFFFF00;------------------------------------cmfx筹码分析HSL:=EMA(VOL/CAPITAL,3);ZDL:HHV(HSL,240);ZXL:LLV(HSL,240);XS:=MA(C,33);锁定筹码:EMA((HSL-ZXL)/ZXL*XS,13);浮动筹码:EMA((ZDL-HSL)/HSL*XS,13);力量对比:锁定筹码-浮动筹码 ,COLORSTICK;------------dkby多空博弈VAR1:=(HHV(HIGH,21)-C)/(HHV(HIGH,21)-LLV(LOW,21))*100-10;VAR2:=(C-LLV(LOW,21))/(HHV(HIGH,21)-LLV(LOW,21))*100;VAR3:=SMA(VAR2,13,8);高位:90;低位:0;多方: SMA(VAR3,13,8),COLORRED;空方: SMA(VAR1,21,8),COLORGREEN;中轴:45;-----------------mmpp买卖频谱买线:EMA(C,3);卖线:EMA(SLOPE(C,21)*20+C,55);买卖差:=买线-卖线;STICKLINE(买卖差>=0,(买线-买卖差*0.05),(买线-买卖差*0.15),5,0) ,COLOR00FFFF;STICKLINE(买卖差>=0,(买线-买卖差*0.2),(买线-买卖差*0.35),5,0) ,COLOR00CCFF;STICKLINE(买卖差>=0,(买线-买卖差*0.4),(买线-买卖差*0.55),5,0) ,COLOR0099FF;STICKLINE(买卖差>=0,(买线-买卖差*0.6),(买线-买卖差*0.75),5,0) ,COLOR0066FF;STICKLINE(买卖差>=0,(买线-买卖差*0.8),(买线-买卖差*0.95),5,0) ,COLOR0000CC;STICKLINE(买卖差<0,(卖线+买卖差*0.05),(卖线+买卖差*0.15),5,0) ,COLOR006600;STICKLINE(买卖差<0,(卖线+买卖差*0.2),(卖线+买卖差*0.35),5,0) ,COLOR009900;STICKLINE(买卖差<0,(卖线+买卖差*0.4),(卖线+买卖差*0.55),5,0) ,COLOR00CC00;STICKLINE(买卖差<0,(卖线+买卖差*0.6),(卖线+买卖差*0.75),5,0) ,COLOR00FF00;STICKLINE(买卖差<0,(卖线+买卖差*0.8),(卖线+买卖差*0.95),5,0) ,COLOR66FF00;------------zljc主力进出MAV:=(C*2+H+L)/4;SK:= EMA(MAV,13) - EMA(MAV,34);SD := EMA(SK,5);中轴:0;空方主力 : (-2*(SK-SD))*3.8,COLORGREEN;多方主力 : (2*(SK-SD))*3.8,COLORRED;--------------------------------------成本均线P1 (0, 10000, 5, 1);P2 (0, 10000, 13, 1);P3 (0, 10000, 34, 1);cb1:ema(AMOUNT,P1)/EMA(VOL,P1)*10;cb2:ema(amount,P2)/ema(vol,P2)*10;cb3:ema(amount,P3)/ema(vol,P3)*10;∞:DMA(C,V/CAPITAL);(这行重要)--------------------------------------资金博弈jgV:=(BIGORDER(1,3)-BIGORDER(2,3));dhV:=(BIGORDER(1,2)-BIGORDER(2,2)-BIGORDER(1,3)+BIGORDER(2,3));zhV:=(BIGORDER(1,1)-BIGORDER(2,1)-BIGORDER(1,2)+BIGORDER(2,2));shV:=(BIGORDER(2,1)-BIGORDER(1,1));A1:=MIN((COUNT(ORDER(2),0)),60);超级资金:EMA(jgV,A1)*A1,COLORMAGENTA;大户资金:EMA(dhV,A1)*A1,color3399FF ;中户资金:EMA(zhV,A1)*A1,colorcyan;散户资金:EMA(shV,A1)*A1,colorgreen;0,color333333,PRECIS0,layer7;超级资金A1:=MIN((COUNT(ORDER(2),0)),60);超户:(BIGORDER(1,3)-BIGORDER(2,3)),COLOR3D ;累计:EMA(超户,A1)*A1,COLORMAGENTA;均值:MA(累计,10),colorwhite;大户资金A1:=MIN((COUNT(ORDER(2),0)),60);大户:(BIGORDER(1,2)-BIGORDER(2,2)-BIGORDER(1,3)+BIGORDER(2,3)),COLOR3D ;累计:EMA(大户,A1)*A1,color3399FF;均值:MA(累计,10),colorwhite;中户资金A1:=MIN((COUNT(ORDER(2),0)),60);中户:(BIGORDER(1,1)-BIGORDER(2,1)-BIGORDER(1,2)+BIGORDER(2,2)),COLOR3D ;累计:EMA(中户,A1)*A1,colorcyan;均值:MA(累计,10),colorwhite;散户资金A1:=MIN((COUNT(ORDER(2),0)),60);散户:(BIGORDER(2,1)-BIGORDER(1,1))*vol/capital,COLOR3D ;累计:EMA(散户,A1)*A1,colorgreen;均值:MA(累计,10),colorwhite;^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^。
好看的c语言程序烟花源代码烟花是人们新年、庆祝等节日最喜爱的庆祝道具之一,而用C语言编写的烟花程序更是酷炫、有趣,甚至具有一定的指导意义。
本程序采用的是Win32 API图形和多线程,实现了屏幕上多个烟花同时绽放、炫彩夺目的效果。
以下是程序代码:```include <stdio.h>include <windows.h>include <stdlib.h>include <time.h>define MAX_FIREWORKS 10define MAX_PARTICLES 100struct ParticleStruct {float x, y;float vx, vy;float brightness;};struct FireworkStruct {int x, y;int color;int particlesLeft;bool exploded;ParticleStruct particles[MAX_PARTICLES];};FireworkStruct fireworks[MAX_FIREWORKS];int screenHeight, screenWidth;HDC hDCMem;HBITMAP hBitmap;HBITMAP hOldBitmap;void InitializeFirework(int index) {fireworks[index].x = rand() % screenWidth;fireworks[index].y = screenHeight - 1;fireworks[index].color = RGB(rand() % 256, rand() % 256, rand() % 256);fireworks[index].particlesLeft = rand() % 101 + 100;for (int i = 0; i < MAX_PARTICLES; i++) {fireworks[index].particles[i].x =fireworks[index].x;fireworks[index].particles[i].y =fireworks[index].y;fireworks[index].particles[i].vx = (rand() % 11 - 5) / 10.0;fireworks[index].particles[i].vy = (rand() % 11 - 10) / 10.0;fireworks[index].particles[i].brightness = 1.0;}}void InitializeFireworks() {for (int i = 0; i < MAX_FIREWORKS; i++)InitializeFirework(i);}bool UpdateFirework(int index) {fireworks[index].y -= rand() % 6 + 3;if (fireworks[index].y < screenHeight / 4) { fireworks[index].exploded = true;for (int i = 0; i < MAX_PARTICLES; i++) { fireworks[index].particles[i].vx = 0; fireworks[index].particles[i].vy = 0; }}return true;}else {bool particleExists = false;for (int i = 0; i < MAX_PARTICLES; i++){fireworks[index].particles[i].vx *= 0.95; fireworks[index].particles[i].vy *= 0.95;fireworks[index].particles[i].x +=fireworks[index].particles[i].vx;fireworks[index].particles[i].y +=fireworks[index].particles[i].vy;fireworks[index].particles[i].brightness *=0.975;if (fireworks[index].particles[i].brightness > 0.0)particleExists = true;}fireworks[index].particlesLeft--;if (fireworks[index].particlesLeft == 0|| !particleExists) {InitializeFirework(index);return false;}return true;}}void UpdateFireworks() {for (int i = 0; i < MAX_FIREWORKS; i++)UpdateFirework(i);}void DrawFireworks() {HBRUSH hBrush;for (int i = 0; i < MAX_FIREWORKS; i++) {if (!fireworks[i].exploded) {hBrush = CreateSolidBrush(fireworks[i].color);SelectObject(hDCMem, hBrush);Ellipse(hDCMem, fireworks[i].x - 5,fireworks[i].y - 5, fireworks[i].x + 5, fireworks[i].y + 5);DeleteObject(hBrush);}else {for (int j = 0; j < MAX_PARTICLES; j++) {hBrush = CreateSolidBrush(RGB(255, 255, 255)/*fireworks[i].color*/);SelectObject(hDCMem, hBrush);SetPixel(hDCMem,fireworks[i].particles[j].x, fireworks[i].particles[j].y, fireworks[i].color*fireworks[i].particles[j].brightness);DeleteObject(hBrush);}}}}DWORD WINAPI UpdateThread(LPVOID lpParam) {while (true) {UpdateFireworks();Sleep(10);}return 0;}int main() {HWND hWnd = GetDesktopWindow();HDC hDC = GetDC(hWnd);screenHeight = GetSystemMetrics(SM_CYSCREEN);screenWidth = GetSystemMetrics(SM_CXSCREEN);hDCMem = CreateCompatibleDC(hDC);hBitmap = CreateCompatibleBitmap(hDC, screenWidth, screenHeight);hOldBitmap = (HBITMAP)SelectObject(hDCMem, hBitmap);InitializeFireworks();CreateThread(NULL, 0, &UpdateThread, NULL, 0, NULL);MSG msg;BOOL bRet;while ((bRet = GetMessage(&msg, NULL, 0, 0)) != 0) { if (bRet == -1)break;else {TranslateMessage(&msg);DispatchMessage(&msg);DrawFireworks();BitBlt(hDC, 0, 0, screenWidth, screenHeight, hDCMem, 0, 0, SRCCOPY);}}SelectObject(hDCMem, hOldBitmap);DeleteObject(hBitmap);DeleteDC(hDCMem);ReleaseDC(hWnd, hDC);return 0;}```本程序实现了多个烟花同时在屏幕上绽放和消失,其中每个烟花的颜色和位置随机生成。
捉牛分时公式源码
下面是捉牛分时公式的源码,代码均用中文书写:
//定义捉牛分时函数
function 捉牛分时(开始时间,结束时间,目标时间){
var 总时间 = 结束时间 - 开始时间; //总时间为结束时间减去开始时间
var 剩余时间 = 目标时间 - 开始时间; //剩余时间为目标时间减去开始时间
var 进度 = 剩余时间 / 总时间; //进度为剩余时间占总时间的比例
return 进度; //返回进度
}
//使用示例
var 开始时间 = new Date("2022/05/01 00:00"); //设置开始时间为2022年5月1日零点
var 结束时间 = new Date("2022/05/07 23:59"); //设置结束时间为2022年5月7日23点59分
var 目标时间 = new Date("2022/05/03 12:00"); //设置目标时间为2022年5月3日12点
var 进度 = 捉牛分时(开始时间,结束时间,目标时间); //获取捉牛分时的进度
console.log("目标时间的捉牛分时进度为:" + (进度 * 100) + "%"); //输出捉牛分时进度。
function fa_ndim
para=[20 500 0.5 0.2 1];
help fa_dim.m
% 定义问题维度
d=15;
Lb=zeros(1,d);
Ub=2*ones(1,d);
u0=Lb+(Ub-Lb).*rand(1,d);
[u,fval,NumEval]=ffa_mincon(@cost,u0,Lb,Ub,para);
%Display results
bestsolution=u;
bestojb=fval;
total_number_of_function_eveluation=NumEval;
%目标函数
function z=cost(x)
%准确的结果应该是(1,1,1...1)
z=sum((x-1).^2);
%开始执行萤火虫算法
function[nbest,fbest,NumEval]=ffa_mincon(fhandle,u0,Lb,Ub,para)
if nargin<5,para=[20 500 0.25 0.20 1];
end
if nargin<4,Ub=[];
end
if nargin<3,Lb=[];
end
if nargin<2,
disp('Usuage:FA_mincon(@cost,u0,Lb,Ub,para)');
end
n=para(1);
MaxGeneration=para(2);
alpha=para(3);
betamin=para(4);
gamma=para(5);
%函数运算次数
NumEval=n*MaxGeneration;
%检查是否越过上限
if length(Lb)~=length(Ub);
disp('Simple bounds/limits are improper! ');
return
end
%计算维度
d=length(u0);
%初始化向量
zn=ones(n,1)*10^100;
%生成萤火虫位置
[ns,Lightn]=init_ffa(n,d,Lb,Ub,u0);
for k=1:MaxGeneration, %开始迭代
alpha=alpha_new(alpha,MaxGeneration);
%评估新解
for i=1:n,
zn(i)=fhandle(ns(i,:));
Lightn(i)=zn(i);
end
%根据亮度强弱排列萤火虫
[Lightn,Index]=sort(zn);
ns_tmp=ns;
for i=1:n,
ns(i,:)=ns_tmp(Index(i),:);
end
%找到当前最优
nso=ns;
Lighto=Lightn;
nbest=ns(1,:);
Lightbest=Lightn(1);
fbest=Lightbest;
%所有的萤火虫飞向最亮的萤火虫
[ns]=ffa_move(n,d,ns,Lightn,nso,Lighto,nbest,Lightbest,alpha,betamin,ga
mma,Lb,Ub);
end %迭代结束
%*******子函数***************
%萤火虫位置初始化
function[ns,Lightn]=init_ffa(n,d,Lb,Ub,u0)
if length(Lb)>0,
for i=1:n,
ns(i,:)=Lb+(Ub-Lb).*rand(1,d);
end
else
for i=1:n,
ns(i,:)=u0+randn(1,d);
end
end
%初始化亮度
Lightn=ones(n,1)*10^100;
%所有的萤火虫飞向最亮的萤火虫
function[ns]=ffa_move(n,d,ns,Lightn,nso,Lighto,nbest,Lightbest,alpha,be
tamin,gamma,Lb,Ub)
scale=abs(Ub-Lb);
for i=1:n,
for j=1:n,
r=sqrt(sum((ns(i,:)-ns(j,:)).^2));
if Lightn(i)>Lighto(j), %Brighter and more attractive
beta0=1;
beta=(beta0-betamin)*exp(- gamma*r.^2)+betamin;
tmpf=alpha.*(rand(1,d)-0.5).*scale;
ns(i,:)=ns(i,:).*(1-beta)+nso(j,:).*beta+tmpf;
end
end
end
%检查更新的解是否在限制范围内
[ns]=findlimits(n,ns,Lb,Ub);
% This function is optional,as it is not in the original FA
% The idea to reduce randomness is to increase the convergence,
% however,if you reduce randomness too quickly,then premature
% convergence can occr.So use with care.
function alpha=alpha_new(alpha,NGen)
delta=1-(10^(-4)/0.9)^(1/NGen);
alpha=(1-delta)*alpha;
%确保萤火虫在限制范围内移动
function[ns]=findlimits(n,ns,Lb,Ub)
for i=1:n,
%下限
ns_tmp=ns(i,:);
I=ns_tmp
%上限
J=ns_tmp>Ub;
ns_tmp(J)=Ub(J);
%更新运动
ns(i,:)=ns_tmp;
end