32位浮点加法器设计
- 格式:doc
- 大小:501.00 KB
- 文档页数:4

《VLSI电路系统与设计》课程设计报告——32bit_32bit移位相加乘法器A 移位相加乘法器原理无符号二进制移位相加乘法器的基本原理是通过逐项移位相加来实现相乘的,从被乘数的最低为开始,若为1,则乘法左移后与上一次的和相加;若为0,左移后以全零相加,直至被乘数的最高位。
以下以4位二进制数为例进行说明:图1 移位相加乘法器原理图如图所示,就可以实现4位二进制数的相乘。
B 电路结构方案根据移位相加乘法器的基本原理,可以将整个电路划分为四个部分:32右移寄存器,32位加法器,乘1模块,64位锁存器。
原理框图如下所示:图2 移位相加乘法器原理框图在上图中,START信号的上跳沿及其高电平有两个功能,即32位寄存器清零和被乘数A[32:0]向移位寄存器SREG32B加载;它的低电平则作为乘法使能信号。
CLK为乘法时钟信号。
当被乘数被加载于32位右移寄存器SREG32B后,随着每一时钟节拍,最低位在前,由低位至高位逐位移出。
当为1时,与门ANDARITH打开,32位乘数B[32:0]在同一节拍进入32位加法器,与上一次锁存在64位锁存器REG16B中的高32位进行相加,其和在下一时钟节拍的上升沿被锁进此锁存器。
而当被乘数的移出位为0时,与门全零输出。
如此往复,直至32个时钟脉冲后,乘法运算过程中止。
此时REG64B的输出值即为最后的乘积。
此乘法器的优点是节省芯片资源,它的核心元件只是一个32位加法器,其运算速度取决于输入的时钟频率。
一、32位加法器模块的设计加法器模块是由8个四位全加器构成的,4位全加器是采用1位全加器构成的。
对于1位全加器,采用门级描述语言,使用了3个异或门和2个与门来实现的。
(1)1位加法器是采用门级描述语言,生成的库文件如图:仿真结果:图1 功能仿真图2 时序仿真(2)32位全加器32位全加器是采用8个4位全加器构成的,其电路原理图如下:图3-32位全加器原理图仿真结果:图4 功能仿真图5 时序仿真由以上的仿真结果可以看出,所设计电路在在功能上能满足要求,在时序上存在一定的时间延迟。
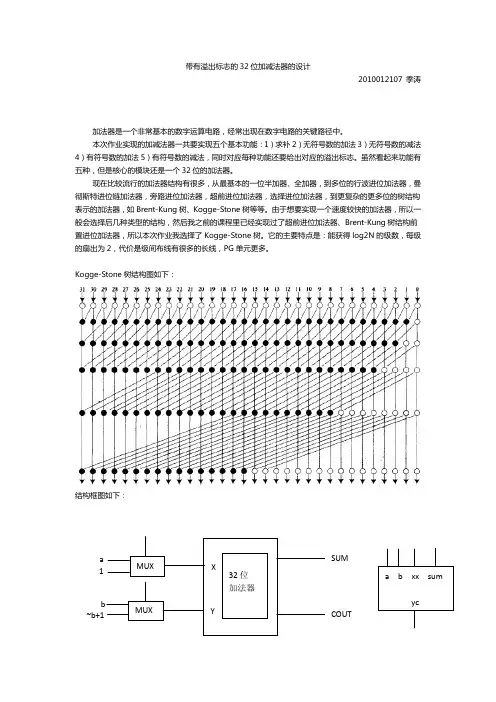
带有溢出标志的32位加减法器的设计2010012107 季涛加法器是一个非常基本的数字运算电路,经常出现在数字电路的关键路径中。
本次作业实现的加减法器一共要实现五个基本功能:1)求补2)无符号数的加法3)无符号数的减法4)有符号数的加法5)有符号数的减法,同时对应每种功能还要给出对应的溢出标志。
虽然看起来功能有五种,但是核心的模块还是一个32位的加法器。
现在比较流行的加法器结构有很多,从最基本的一位半加器、全加器,到多位的行波进位加法器,曼彻斯特进位链加法器,旁路进位加法器,超前进位加法器,选择进位加法器,到更复杂的更多位的树结构表示的加法器,如Brent-Kung树、Kogge-Stone树等等。
由于想要实现一个速度较快的加法器,所以一般会选择后几种类型的结构,然后我之前的课程里已经实现过了超前进位加法器、Brent-Kung树结构前置进位加法器,所以本次作业我选择了Kogge-Stone树。
它的主要特点是:能获得log2N的级数,每级的扇出为2,代价是级间布线有很多的长线,PG单元更多。
Kogge-Stone树结构图如下:结构框图如下:设计的思路是这样的,求补的话就是对操作数进行取反然后+1,令加法器的一个输入为1,另一个输入为~a即可;无符号数和有符号数的加法的输入是一样的;减法的时候只要对第二个操作数求补即可。
然后溢出标志的获取我是对四种功能分别考虑,无符号数的加法,只有在最高位的进位信号为1的时候表示超过了数的表示范围,溢出信号为1,其余情况都为0;无符号数的减法只有在第一个操作数比第二个操作数小的时候溢出信号为1,其余为0;有符号数的加法只有在两个操作数的符号相同而和的最高位符号与他们不同时为1.其余为0;有符号数的减法只有在两个操作数的符号位不同而差的最高位和第二个操作数符号位相同时为1,其余为0。
这样就基本实现了功能。
总结:第一次作业主要让我又回顾了modelsom、DC等软件的使用方法,时隔一年没用有些东西确实都生疏了,甚至安装modelsim软件、DC综合的过程中也产生了不少问题,好在在同学和助教姐姐的帮助下都克服了困难。

32位浮点加法器设计32位浮点加法器是一种用于计算机中的算术逻辑单元(ALU),用于执行浮点数的加法运算。
它可以将两个32位浮点数相加,并输出一个32位的结果。
设计一个高效的32位浮点加法器需要考虑多个方面,包括浮点数的表示形式、运算精度、舍入方式、运算逻辑等。
下面将详细介绍32位浮点加法器的设计。
1.浮点数的表示形式:浮点数通常采用IEEE754标准进行表示,其中32位浮点数由三个部分组成:符号位、阶码和尾数。
符号位用来表示浮点数的正负,阶码用来表示浮点数的指数,尾数用来表示浮点数的小数部分。
2.运算精度:在浮点数加法运算中,精度是一个重要的考虑因素。
通常,浮点数加法器采用单精度(32位)进行设计,可以处理较为广泛的应用需求。
如果需要更高的精度,可以考虑使用双精度(64位)浮点加法器。
3.舍入方式:浮点数加法运算中,结果通常需要进行舍入处理。
常见的舍入方式有以下几种:舍入到最近的偶数、舍入向上、舍入向下、舍入到零。
具体的舍入方式可以根据应用需求来确定。
4.运算逻辑:浮点数加法运算涉及到符号位、阶码和尾数的加法。
首先,需要判断两个浮点数的阶码大小,将较小的阶码移到较大的阶码对齐,并相应调整尾数。
然后,将尾数进行相加并进行规格化处理。
最后,根据求和结果的大小,进行溢出处理和舍入操作。
在32位浮点加法器的设计中,还需要考虑到性能和效率。
可以采用流水线技术来提高运算速度,将加法运算划分为多个阶段,并在每个阶段使用并行处理来加速运算。
此外,还可以使用硬件加速器和快速逻辑电路来优化运算过程。
总结起来,设计一个高效的32位浮点加法器需要考虑浮点数的表示形式、运算精度、舍入方式、运算逻辑以及性能和效率。
在实际设计中,还需要根据具体应用需求进行功能扩展和优化。
通过合理的设计和调优,可以实现高性能的浮点加法器,满足不同应用场景的需求。

32位浮点数加法设计仿真实验报告名字:李磊学号:10045116 班级:1004221132位浮点数的IEEE-754格式单精度格式IEEE.754标准规定了单精度浮点数共32位,由三部分组成:23位尾数f,8位偏置指数e,1位符号位s。
将这三部分由低到高连续存放在一个32位的字里,对其进行编码。
其中[22:0]位包含23位的尾数f;[30:23]位包含8位指数e;第31位包含符号s{s[31],e[30:23],f[22:0]}其中偏置指数为实际指数+偏置量,单精度浮点数的偏置量为128,双精度浮点数的偏置量为1024。
规格化的数:由符号位,偏置指数,尾数组成,实际值为1.f乘2的E-128次方非规格化的数:由符号位,非偏置指数,尾数组成,实际值为0.f乘2的E次方特殊的数:0(全为零),+无穷大(指数全为1,尾数为0,符号位为0),-无穷大(指数全为1,尾数为0,符号位为1),NAN(指数全为1,尾数为不全为0)浮点数加法器设计设计思路:1.前端处理,还原尾数2.指数处理,尾数移位,使指数相等3.尾数相加4.尾数规格化处理5.后端处理,输出浮点数具体设计:设计全文:module flowadd(ix, iy, clk, a_en, ost,oz);input ix, iy, clk, a_en;output oz, ost;wire[31:0] ix,iy;reg[31:0] oz;wire clk,ost,a_en;reg[25:0] xm, ym, zm;reg[7:0] xe, ye, ze;reg[2:0] state;parameter start = 3'b000, //设置状态机zerock = 3'b001,exequal = 3'b010,addm = 3'b011,infifl = 3'b100,over = 3'b110;assign ost = (state == over) ? 1 : 0; /*后端处理,输出浮点数*/always@(posedge ost)beginif(a_en)oz <= {zm[25],ze[7:0],zm[22:0]};endalways@(posedge clk) //状态机begincase(state)start: //前端处理,分离尾数和指数,同时还原尾数beginxe <= ix[30:23];xm <= {ix[31],1'b0,1'b1,ix[22:0]};ye <= iy[30:23];ym <= {iy[31],1'b0,1'b1,iy[22:0]};state <= zerock;endzerock:beginif(ix == 0)begin{ze, zm} <= {ye, ym};state <= over;endelseif(iy == 0)begin{ze, zm} <= {xe, xm};state <= over;endelsestate <= exequal;endexequal: //指数处理,使得指数相等beginif(xe == ye)state <= addm;elseif(xe > ye)beginye <= ye + 1;ym[24:0] <= {1'b0, ym[24:1]};if(ym == 0)beginzm <= xm;ze <= xe;state <= over;endelsestate <= exequal;endelsebeginxe <= xe + 1;xm[24:0] <= {1'b0,xm[24:1]};if(xm == 0)beginzm <= ym;ze <= ye;state <= over;endelsestate <= exequal;endendaddm: //带符号位和保留进位的尾数相加beginif ((xm[25]^ym[25])==0)beginzm[25] <= xm[25];zm[24:0] <= xm[24:0]+ym[24:0];endelseif(xm[24:0]>ym[24:0])beginzm[25] <= xm[25];zm[24:0] <=xm[24:0]-ym[24:0];endelsebeginzm[25] <= ym[25];zm[24:0] <=ym[24:0]-xm[24:0];endze <= xe;state <= infifl;endinfifl: //尾数规格化处理beginif(zm[24]==1)beginzm[24:0] <= {1'b0,zm[24:1]};ze <= ze + 1;state <= over;endelseif(zm[23]==0)beginzm[24:0] <= {zm[23:0],1'b0};ze <= ze - 1;state <= infifl;endelsestate <= over;endover:beginstate<= start;enddefault:beginstate<= start;endendcaseendendmodule设计结果仿真仿真结果为41A00000H+41080000H=41E40000H41A00000H=10D,41080000H=4.25D,41E40000H=14.25D,验证成功。

基于改进型选择进位加法器的32位浮点乘法器设计刘容;赵洪深;李晓今【期刊名称】《现代电子技术》【年(卷),期】2013(000)016【摘要】在修正型Booth算法和Wallace树结构以及选择进位加法器的基础上,提出了一种新型32位单精度浮点乘法器结构。
该新型结构通过截断选择进位加法器进位链,缩短了关键路径延时。
传统选择进位加法器每一级加法器的进位选择来自上级的进位输出。
提出的结构可以提前计算出尾数第16位的结果,它与Wallace树输出的相关位比较就可得出来自前一位的进位情况进而快速得到进位选择。
在Altera的EP2C70F896C6器件上,基于该结构实现了一个支持IEEE754浮点标准的4级流水线浮点乘法器,时序仿真表明,该方法将传统浮点乘法器结构关键路径延时由6.4 ns减小到5.9 ns。
%On the basis of the modified Booth encoding,Wallace tree structure and carry-select adder,a new structure of 32-bit float point multiplier is proposed,which can shorten its critical path delay by cutting the carry chain. The carry selection of each level of the carry-select adder comes from the upper carry output. The new structure can produce the 16th bit of the man-tissa. By comparing it with the relative output bit of the Wallace tree,the carry which comes from the former bit can be got to achieve the carry selection. By using the new structure,a 4-stage pipeline float point multiplier supporting IEEE754 standard is implemented on Altera’s FPGA device EP2C70F896C6. Thetime-sequence simulation shows that the critical path delay of the multiplier is 5.9 ns,less than that of the traditional multiplier,which is 6.4 ns.【总页数】4页(P133-136)【作者】刘容;赵洪深;李晓今【作者单位】中国科学院光电技术研究所,四川成都 610209; 中国科学院,北京100049;中国科学院光电技术研究所,四川成都 610209; 中国科学院,北京100049;中国科学院光电技术研究所,四川成都 610209【正文语种】中文【中图分类】TN702-34【相关文献】1.基于选择进位32位加法器的硬件电路实现 [J], 高建卫2.基于改进4-2压缩结构的32位浮点乘法器设计 [J], 邵磊;李昆;张树丹;于宗光;徐睿3.基于改进4—2压缩结构的32位浮点乘法器设计 [J], 邵磊;李昆;张树丹;于宗光;徐睿4.浮点ALU中选择进位复合加法器的优化设计 [J], 王桐;李立健;王东琳5.基于FPGA的32位浮点加法器的设计 [J], 吉伟;黄巾;杨靓;黄士坦因版权原因,仅展示原文概要,查看原文内容请购买。

32位浮点乘法器的设计与仿真代码一、引言随着计算机科学和技术的不断发展,浮点乘法器在科学计算、图像处理、人工智能等领域中扮演着重要的角色。
本文将详细讨论32位浮点乘法器的设计与仿真代码,并深入探讨其原理和实现方法。
二、浮点数表示在开始设计32位浮点乘法器之前,我们首先需要了解浮点数的表示方法。
浮点数由符号位、阶码和尾数组成,其中符号位表示数的正负,阶码确定数的大小范围,尾数表示数的精度。
三、浮点乘法器的原理浮点乘法器的原理基于乘法运算的基本原理,即将两个数的尾数相乘,并将阶码相加得到结果的阶码。
同时需要考虑符号位的处理和对阶的操作。
下面是32位浮点乘法器的基本原理:1.获取输入的两个浮点数A和B,分别提取出符号位、阶码和尾数。
2.将A和B的尾数相乘,得到乘积P。
3.将A和B的阶码相加,得到结果的阶码。
4.对乘积P进行规格化,即将小数点左移或右移,使其满足规定的位数。
5.对结果的阶码进行溢出判断,若溢出则进行相应的处理。
6.将符号位与结果的阶码和尾数合并,得到最终的浮点乘积。
四、浮点乘法器的设计根据浮点乘法器的原理,我们可以开始进行浮点乘法器的设计。
设计的关键是确定乘法器中各个部件的功能和连接方式。
下面是浮点乘法器的设计要点:1.输入模块:负责接收用户输入的两个浮点数,并提取出符号位、阶码和尾数。
2.乘法模块:负责将两个浮点数的尾数相乘,得到乘积P。
3.加法模块:负责将两个浮点数的阶码相加,得到结果的阶码。
4.规格化模块:负责对乘积P进行规格化操作,使其满足规定的位数。
5.溢出判断模块:负责判断结果的阶码是否溢出,并进行相应的处理。
6.输出模块:负责将符号位、阶码和尾数合并,得到最终的浮点乘积。
五、浮点乘法器的仿真代码为了验证浮点乘法器的设计是否正确,我们需要进行仿真测试。
下面是一段简单的浮点乘法器的仿真代码:module floating_point_multiplier(input wire [31:0] a,input wire [31:0] b,output wire [31:0] result);wire [31:0] mantissa;wire [7:0] exponent;wire sign;// 提取符号位assign sign = a[31] ^ b[31];// 提取阶码assign exponent = a[30:23] + b[30:23];// 尾数相乘assign mantissa = a[22:0] * b[22:0];// 规格化assign {result[30:23], result[22:0]} = {exponent, mantissa};// 处理溢出always @(*)beginif (exponent > 255)result = 32'b0; // 结果溢出为0else if (exponent < 0)result = 32'b0; // 结果溢出为0elseresult[31] = sign;endendmodule六、浮点乘法器的应用浮点乘法器在科学计算、图像处理、人工智能等领域中有着广泛的应用。

基于与非门和D触发器的32位加法器【摘要】这次的课程设计的任务是设计一个输入范围为-(230-1)~(230-1)的加法器。
利用拨码开关输入二进制补码,再将二进制补码转化为串行信号,经过一位全加器后得到计算结果,再将计算结果转化为并行信号输出,并利用LED灯显示计算结果的二进制补码。
本次设计通过开关的闭合和断开来代表电平的高低,继而代表代表1和0来输入所要计算的十进制数的补码。
将并行输入转化为串行输出的模块和将串行输入转化为并行输出的模块是由与非门和D触发器构成的移位寄存器。
但是,这样并不能保证输出的稳定,所以我们在串入并出的移位寄存器的每个输出后面各加了一个D触发器,只有当32位补码全部并出时,D触发器才会触发,将结果显示,其余时候D触发器将保持上一个输出结果。
这样就能确保计算结果的稳定显示。
而控制并入串出信号的加载和最后结果稳定显示的控制电路是由与非门和D触发器构成的模32计数器,每次计32个时钟上升沿时便会产生一个上升沿。
用来控制移位寄存器移位动作和计数器的时钟信号,是由NE555电路产生的1KHz的脉冲信号。
【关键词】32位加法器:移位寄存器;计数器;NE555一、设计目的与要求1、设计目的1)掌握计数器、移位寄存器的电路设计与工作原理。
2)学会分析各模块之间的时延关系,并调节各个模块之间的时延关系。
3)掌握信号并入串出和串入并出的工作原理。
4)了解时钟信号的产生。
2、设计要求设计一个输入范围为-(230-1)~(230-1)的加法器。
具体要求如下:1)只能使用与非门和D触发器。
2)用两组拨码开关分别输入两个加数的二进制补码。
3)用二极管稳定显示计算结果的二进制补码。
4)利用Multisim设计仿真。
二、设计思路我们将加法器可以分为3级:第一级是并入串出模块;第二级是加法运算模块(一位全加器);第三级是串入并出模块。
第一级模块负责将拨码快关的并行输入转化为串行输出,作为第二级输入,输入到第二级加法运算模块,得到一个串行输出的计算结果,将该结果作为第三级输入,再由第三级模块转化为并行输出,最后由LED显示。
课程名称 EDA 学院电信专业电信班级三班学号姓名指导老师目录第一章、题目 (3)第二章、设计步骤 (4)第三章、设计心得 (40)第四章、参考文献 (41)第一章题目应用VHDL引用LPM库设计32位加法器。
要求在Quartus II软件,利用VHDL完成层次式电路设计,电路中的元件可以用VHDL设计也可以用库元件连线构成再封装。
借助EDA工具中的综合器,适配器,时序仿真器和编程器等工具进行相应处理。
输入方法不限制。
适配元件不限制。
要求综合出RTL电路,并进行仿真输入波形设计并分析电路输出波形。
第二章设计步骤新建工程输入设计项目并存盘:利用lpm_add_sub函数。
参数设定:引脚分配:程序清单:OPTIONS NAME_SUBSTITUTION = ON;INCLUDE "addcore";INCLUDE "look_add";INCLUDE "bypassff";INCLUDE "altshift";INCLUDE "alt_stratix_add_sub";INCLUDE "alt_mercury_add_sub";PARAMETERS(LPM_WIDTH,LPM_REPRESENTATION = "SIGNED",LPM_DIRECTION = "DEFAULT", -- controlled by add_sub portONE_INPUT_IS_CONSTANT = "NO",LPM_PIPELINE = 0,MAXIMIZE_SPEED = 5,REGISTERED_AT_END = 0,OPTIMIZE_FOR_SPEED = 5,USE_CS_BUFFERS = 1,CARRY_CHAIN = "IGNORE",CARRY_CHAIN_LENGTH = 32,DEVICE_FAMILY,USE_WYS = "OFF",STYLE = "NORMAL",CBXI_PARAMETER = "NOTHING");INCLUDE ""; % device family definitions %FUNCTION @CBXI_PARAMETER (aclr, add_sub, cin, clken, clock, dataa[LPM_WIDTH-1..0], datab[LPM_WIDTH-1.RETURNS (cout, overflow, result[LPM_WIDTH-1..0]);-- a useful macroDEFINE MIN(a, b) = a < b ? a : b;-- LPM_PIPELINE became the new name for LATENCY. Will keep LATENCY in the code.CONSTANT LATENCY = LPM_PIPELINE;-- Determine the effective speed (vs. size) optimization factor: If The local-- param is used, take it as the effective value, otherwise use the global value CONSTANT SPEED_MAX_FACTOR = USED(MAXIMIZE_SPEED) ?MAXIMIZE_SPEED : OPTIMIZE_FOR_SPEED;-- Internal and external latencyCONSTANT LAST_STAGE_INDEX = (REGISTERED_AT_END == 1) ? 1 : 0; CONSTANT INT_STAGES_NUM = LATENCY + 1 - LAST_STAGE_INDEX; CONSTANT INT_LATENCY = (LATENCY == 0) ? 1 : MIN(LPM_WIDTH, INT_STAGES_NUM);CONSTANT EXT_LATENCY = (LATENCY > LPM_WIDTH) ? (LATENCY - LPM_WIDTH) : 0;CONSTANT REG_LAST_ADDER = ((LATENCY >= LPM_WIDTH) # (REGISTERED_AT_END == 1)) ? 1 : 0;DEFINE OVFLOW_EXTRA_DEPTH() = (LPM_REPRESENTATION == "SIGNED" #LPM_REPRESENTATION == "UNSIGNED" & USED(add_sub)) ? REG_LAST_ADDER :-- Partial adders (for pipelined cases)CONSTANT RWIDTH = LPM_WIDTH MOD INT_LATENCY; -- # of adders on the right sideCONSTANT LWIDTH = INT_LATENCY - RWIDTH; -- # of adders on the left sideCONSTANT SUB_WIDTH1 = FLOOR(LPM_WIDTH DIV INT_LATENCY); -- Width of right-side addersCONSTANT SUB_WIDTH0 = SUB_WIDTH1 + 1; -- Width of left-side adders-- =====================================================-- Look-ahead adder section-- =====================================================-- Number of 8-bit adder blocks in carry-look-ahead casesCONSTANT LOOK_AHEAD_BLOCK_SIZE = 8;CONSTANT BLOCKS = CEIL(LPM_WIDTH DIV LOOK_AHEAD_BLOCK_SIZE);-- Will use the look-ahead adder?CONSTANT USE_LOOK_AHEAD = -(!((LPM_WIDTH < LOOK_AHEAD_BLOCK_SIZE) #((FAMILY_FLEX() == 1) &(USE_CARRY_CHAINS() # (!USE_CARRY_CHAINS() & SPEED_MAX_FACTOR <=(!(FAMILY_FLEX() == 1) &(STYLE == "NORMAL" & SPEED_MAX_FACTOR <= 5))));DEFINE CBX_FAMILY() = ((FAMILY_STRATIXII() == 1 #FAMILY_CYCLONEII() == 1) ? 1 : 0);SUBDESIGN lpm_add_sub(dataa[LPM_WIDTH-1..0] : INPUT = GND;datab[LPM_WIDTH-1..0] : INPUT = GND;cin : INPUT = GND;add_sub : INPUT = VCC;clock : INPUT = GND;aclr : INPUT = GND;clken : INPUT = VCC;result[LPM_WIDTH-1..0] : OUTPUT;cout : OUTPUT;overflow : OUTPUT;)V ARIABLEIF CBX_FAMILY() == 1 & CBXI_PARAMETER != "NOTHING" GENERATE auto_generated : @CBXI_PARAMETER WITH ( CBXI_PARAMETER = "NOTHING" );ELSE GENERATE-- Use wysiwyg implementation for mercury if USE_WYS option is turned on IF FAMILY_MERCURY() == 1 & USE_WYS == "ON" GENERATEmercury_adder : alt_mercury_add_sub WITH(LPM_WIDTH = LPM_WIDTH,LPM_REPRESENTATION = LPM_REPRESENTATION,LPM_DIRECTION = LPM_DIRECTION,ONE_INPUT_IS_CONSTANT = ONE_INPUT_IS_CONSTANT,LPM_PIPELINE = LPM_PIPELINE,MAXIMIZE_SPEED = MAXIMIZE_SPEED,REGISTERED_AT_END = REGISTERED_AT_END,OPTIMIZE_FOR_SPEED = OPTIMIZE_FOR_SPEED,USE_CS_BUFFERS = USE_CS_BUFFERS,CARRY_CHAIN_LENGTH = CARRY_CHAIN_LENGTH,STYLE = STYLE);ELSE GENERATE-- Use wysisyg implementation for stratix if USE_WYS is ON or add_sub signal is usedIF FAMILY_STRATIX() == 1 & (USE_WYS == "ON" # USED(add_sub)) & (USE_CARRY_CHAINS()) GENERATEstratix_adder : alt_stratix_add_sub WITH(LPM_WIDTH = LPM_WIDTH,LPM_REPRESENTATION = LPM_REPRESENTATION,LPM_DIRECTION = LPM_DIRECTION,ONE_INPUT_IS_CONSTANT = ONE_INPUT_IS_CONSTANT,LPM_PIPELINE = LPM_PIPELINE,MAXIMIZE_SPEED = MAXIMIZE_SPEED,REGISTERED_AT_END = REGISTERED_AT_END,OPTIMIZE_FOR_SPEED = OPTIMIZE_FOR_SPEED,USE_CS_BUFFERS = USE_CS_BUFFERS,CARRY_CHAIN_LENGTH = CARRY_CHAIN_LENGTH,STYLE = STYLE);ELSE GENERATEIF INT_LATENCY > 1 GENERATE-- carry-in nodecin_node : NODE;cout_node : NODE;unreg_cout_node : NODE;-- datab[] nodesIF (FAMILY_FLEX() == 1) GENERATEIF (USE_CARRY_CHAINS()) GENERATEIF USED(add_sub) & ONE_INPUT_IS_CONSTANT == "NO" GENERATEdatab_node[LPM_WIDTH-1..0] : LCELL;ELSE GENERATEdatab_node[LPM_WIDTH-1..0] : NODE;END GENERATE;ELSE GENERATEIF USED(add_sub) & ONE_INPUT_IS_CONSTANT == "NO" GENERATEdatab_node[LPM_WIDTH-1..0] : SOFT;ELSE GENERATEdatab_node[LPM_WIDTH-1..0] : NODE;END GENERATE;END GENERATE;ELSE GENERATEIF USED(add_sub) & ONE_INPUT_IS_CONSTANT == "NO" GENERATEdatab_node[LPM_WIDTH-1..0] : SOFT;ELSE GENERATEdatab_node[LPM_WIDTH-1..0] : SOFT;END GENERATE;END GENERATE;IF (LPM_REPRESENTATION == "UNSIGNED" & LPM_DIRECTION != "SUB") & USED(add_sub) GENERATEadd_sub_ff[INT_LATENCY-2..0] : bypassff WITH (WIDTH = 1);END GENERATE;------------------------------------------------ cases where pipeline structure is needed ------------------------------------------------IF !(FAMILY_FLEX() == 1) GENERATE------------------------------------ Non-FLEX cases------------------------------------ if a nonhomogenous adder, generate the longer (right side) addersIF RWIDTH > 0 GENERATEadder0[RWIDTH-1..0] : addcore WITH (WIDTH = SUB_WIDTH0,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);datab0_ff[INT_LATENCY-1..0][RWIDTH-1..0] : bypassffWITH (WIDTH = SUB_WIDTH0);END GENERATE;-- generate the shorter (left side) addersadder1[LWIDTH-1..0] : addcore WITH (WIDTH = SUB_WIDTH1,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);datab1_ff[INT_LATENCY-1..0][LWIDTH-1..0] : bypassff WITH (WIDTH = SUB_WIDTH1);-- dataa pipeline registersdataa_ff[INT_LATENCY-2..0] : bypassff WITH (WIDTH = LPM_WIDTH);ELSE GENERATE------------------------------------------------ FLEX cases -------------------------------------------------- if a nonhomogenous adder, generate the longer (right side) addersIF RWIDTH > 0 GENERATEadder0[RWIDTH-1..0] : addcore WITH (WIDTH = SUB_WIDTH0 + 1,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);IF RWIDTH > 1 GENERATEadder0_0[RWIDTH-1..1] : addcore WITH (WIDTH = SUB_WIDTH0 + 1,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);END GENERATE;adder1[LWIDTH-1..0] : addcore WITH (WIDTH = SUB_WIDTH1 + 1,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);adder1_0[LWIDTH-1..0] : addcore WITH (WIDTH = SUB_WIDTH1 + 1,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);datab0_ff[INT_LATENCY-1..0][RWIDTH-1..0] : bypassff WITH (WIDTH = SUB_WIDTH0+1);ELSE GENERATEadder1[LWIDTH-1..0] : addcore WITH (WIDTH = SUB_WIDTH1 + 1,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);IF LWIDTH > 1 GENERATEadder1_0[LWIDTH-1..1] : addcore WITH (WIDTH = SUB_WIDTH1 + 1,DIRECTION = "ADD",USE_CS_BUFFERS = USE_CS_BUFFERS);END GENERATE;END GENERATE;datab1_ff[INT_LATENCY-1..0][LWIDTH-1..0] : bypassff WITH (WIDTH = SUB_WIDTH1+1);IF LPM_REPRESENTATION == "SIGNED" GENERATEsign_ff[INT_LATENCY-2..0] : bypassff WITH (WIDTH = 2);END GENERATE;END GENERATE;ELSE GENERATE------------------------------------ non-pipelined adder cases -------------------------------------- Will use a look-ahead type adder for FLEX/NORMAL with SPEED_MAX_FACTOR > 5 or-- MAX/FAST cases. Will use a ripple type adder for all other cases.IF USED(clock) # (USE_LOOK_AHEAD == 0) GENERATEadder : addcore WITH (WIDTH = LPM_WIDTH, DIRECTION = LPM_DIRECTION,REPRESENTATION = LPM_REPRESENTATION,USE_CS_BUFFERS = USE_CS_BUFFERS);cout_node : NODE;oflow_node : NODE;ELSE GENERATEcin_node : NODE;cout_node : NODE;oflow_node : NODE;datab_node[LPM_WIDTH-1..0] : SOFT;adder[BLOCKS-1..0] : addcore WITH (WIDTH = 8,DIRECTION = "DEFAULT",USE_CS_BUFFERS = USE_CS_BUFFERS);look_ahead_unit : look_add WITH (WIDTH = BLOCKS);END GENERATE;END GENERATE;result_node [LPM_WIDTH-1..0] : NODE;result_ext_latency_ffs : altshift WITH (WIDTH = LPM_WIDTH,DEPTH = EXT_LATENCY);carry_ext_latency_ffs : altshift WITH (WIDTH = 1,DEPTH = EXT_LATENCY);oflow_ext_latency_ffs : altshift WITH (WIDTH = 1,DEPTH = EXT_LATENCY);END GENERATE; -- stratixEND GENERATE; --mercuryEND GENERATE; -- StratixIIBEGINASSERT REPORT "LPM_WIDTH = %" LPM_WIDTH SEVERITY DEBUG;ASSERT REPORT "LATENCY = %" LATENCY SEVERITY DEBUG;ASSERT REPORT "LWIDTH = %" LWIDTH SEVERITY DEBUG;ASSERT REPORT "RWIDTH = %" RWIDTH SEVERITY DEBUG;ASSERT REPORT "INT_LATENCY = %" INT_LATENCY SEVERITY DEBUG;ASSERT REPORT "EXT_LATENCY = %" EXT_LATENCY SEVERITY DEBUG;ASSERT REPORT "SUB_WIDTH1 = %" SUB_WIDTH1 SEVERITY DEBUG;ASSERT (LPM_REPRESENTATION == "SIGNED" # LPM_REPRESENTATION == "UNSIGNED")REPORT "Illegal value for LPM_REPRESENTATION parameter (""%"") -- value must be ""SIGNED"LPM_REPRESENTATIONSEVERITY ERRORHELP_ID LPM_ADD_SUB_REPRESENTATION;ASSERT (LPM_WIDTH > 0)REPORT "LPM_WIDTH parameter value must be greater than 0"SEVERITY ERRORHELP_ID LPM_ADD_SUB_WIDTH;ASSERT (USED(clock) ? LATENCY > 0 : LATENCY == 0)REPORT "Value of LPM_PIPELINE parameter must be greater than 0 if clock input is used andSEVERITY ERRORHELP_ID LPM_ADD_SUB_CLOCK_WITHOUT_LATENCY;ASSERT (LATENCY <= LPM_WIDTH)REPORT "Value of LPM_PIPELINE parameter (%) should be lower -- use % for best performanceSEVERITY INFOHELP_ID LPM_ADD_SUB_CLOCK_LATENCY_V ALUE;ASSERT (LPM_WIDTH > 0)REPORT "Value of LPM_WIDTH parameter must be greater than 0"SEVERITY ERRORHELP_ID LPM_ADD_SUB_WIDTH2;ASSERT (LPM_REPRESENTATION == "UNSIGNED" # LPM_REPRESENTATION == "SIGNED")REPORT "Illegal value for LPM_REPRESENTATION parameter (%) -- value must be UNSIGNED (theLPM_REPRESENTATIONSEVERITY ERRORHELP_ID LPM_ADD_SUB_REPRESENTATION2;ASSERT (ONE_INPUT_IS_CONSTANT == "YES" # ONE_INPUT_IS_CONSTANT == "NO")REPORT "Illegal value for ONE_INPUT_IS_CONSTANT parameter (%) -- value must be YES or NOONE_INPUT_IS_CONSTANTSEVERITY ERRORHELP_ID LPM_ADD_SUB_ICONSTANT;ASSERT (LPM_DIRECTION == "DEFAULT" # LPM_DIRECTION == "ADD" # LPM_DIRECTION == "SUB")REPORT "Illegal value for LPM_DIRECTION parameter (%) -- value must be ADD, SUB, or DEFAULPM_DIRECTIONSEVERITY ERRORHELP_ID LPM_ADD_SUB_DIRECTION;ASSERT (LPM_DIRECTION == "DEFAULT" # USED(add_sub) == 0)REPORT "Value of LPM_DIRECTION parameter (%) is not consistent with the use of the add_suLPM_DIRECTIONSEVERITY ERRORHELP_ID LPM_ADD_SUB_DIRECTION_ADD_SUB;-- The next assertion is not implemented because MAX+PLUS II implementation -- differs from the LPM standard. Both overflow and cout are allowed-- in MAX+PLUS II.-- ASSERT (USED(overflow) == 0 # USED(cout) == 0)-- REPORT "Can't use overflow port if cout port is used"-- SEVERITY ERROR-- HELP_ID LPM_ADD_SUB_OVERCOUT;ASSERT (FAMILY_IS_KNOWN() == 1)REPORT "Megafunction lpm_add_sub does not recognize the current device family (%) -- ensure tDEVICE_FAMILYSEVERITY WARNINGHELP_ID LPM_ADD_SUB_FAMILY_UNKNOWN;IF CBX_FAMILY() == 1 & CBXI_PARAMETER != "NOTHING" GENERATE IF USED(aclr) GENERATE= aclr;END GENERATE;IF USED(add_sub) GENERATE= add_sub;END GENERATE;IF USED(cin) GENERATE= cin;END GENERATE;IF USED(clken) GENERATE= clken;END GENERATE;IF USED(clock) GENERATE= clock;END GENERATE;IF USED(cout) GENERATEcout = ;END GENERATE;IF USED(dataa) GENERATE[] = dataa[];END GENERATE;IF USED(datab) GENERATE[] = datab[];END GENERATE;IF USED(overflow) GENERATEoverflow = ;END GENERATE;IF USED(result) GENERATEresult[] = [];END GENERATE;ELSE GENERATE------------------------------------------------------------------------ mercury wysiwyg adderIF FAMILY_MERCURY() == 1 & USE_WYS == "ON" GENERATE result[] = [];IF USED (cout) GENERATEcout = ;END GENERATE;IF USED(overflow) GENERATEoverflow = ;END GENERATE;[] = dataa[];[] = datab[];IF USED(cin) GENERATE= cin;END GENERATE;IF USED(clock) GENERATE= clock;END GENERATE;IF USED(aclr) GENERATE= aclr;END GENERATE;IF USED(clken) GENERATE= clken;END GENERATE;IF USED(add_sub) GENERATE= add_sub;END GENERATE;ELSE GENERATE-- stratix wysisyg adderIF FAMILY_STRATIX() == 1 & (USE_WYS == "ON" # USED(add_sub)) & (USE_CARRY_CHAINS()) GENERATEresult[] = [];IF USED(cout) GENERATEcout = ;END GENERATE;IF USED(overflow) GENERATEoverflow = ;END GENERATE;[] = dataa[];[] = datab[];IF USED(cin) GENERATE= cin;END GENERATE;IF USED(clock) GENERATE= clock;END GENERATE;IF USED(aclr) GENERATE= aclr;END GENERATE;IF USED(clken) GENERATE= clken;END GENERATE;IF USED(add_sub) GENERATE= add_sub;END GENERATE;ELSE GENERATE-- default addcore adderIF INT_LATENCY > 1 GENERATEIF USED(cin) GENERATEcin_node = cin;ELSE GENERATEIF LPM_DIRECTION == "SUB" GENERATEcin_node = VCC;ELSE GENERATEcin_node = !add_sub;END GENERATE;END GENERATE;IF (LPM_REPRESENTATION == "UNSIGNED" & LPM_DIRECTION != "SUB") & USED(add_sub) GENERATEadd_sub_ff[0].d[0] = add_sub;IF INT_LATENCY > 2 GENERATEadd_sub_ff[INT_LATENCY-2..1].d[0] = add_sub_ff[INT_LATENCY-3..0].q[0];END GENERATE;add_sub_ff[].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;IF LPM_DIRECTION == "SUB" GENERATEdatab_node[] = !datab[];ELSE GENERATEIF USED(add_sub) GENERATEdatab_node[] = datab[] $ !add_sub;ELSE GENERATEdatab_node[] = datab[];END GENERATE;END GENERATE;IF !(FAMILY_FLEX() == 1) GENERATE------------------------------------------------ non-FLEX cases------------------------------------------------ clock connections-- adders clock/aclr/clken/add_sub connectionsIF RWIDTH > 0 GENERATEadder0[RWIDTH-1..0].(clock, aclr, clken) = (clock, aclr, clken);IF (LWIDTH > 1) GENERATEadder1[LWIDTH-2..0].(clock, aclr, clken) = (clock, aclr, clken);END GENERATE;ELSE GENERATEIF LWIDTH > 1 GENERATEadder1[LWIDTH-2..0].(clock, aclr, clken) = (clock, aclr, clken);END GENERATE;END GENERATE;IF REG_LAST_ADDER == 1 GENERATEadder1[LWIDTH-1].(clock, aclr, clken) = (clock, aclr, clken);END GENERATE;dataa_ff[].(clk, clrn, ena) = (clock, !aclr, clken);IF RWIDTH > 0 GENERATEIF RWIDTH > 1 GENERATEdatab0_ff[0][RWIDTH-1..1].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;datab1_ff[0][LWIDTH-1..0].(clk, clrn, ena) = (clock, !aclr, clken);ELSE GENERATEdatab1_ff[0][LWIDTH-1..1].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;--carry_ff[INT_LATENCY-2..0].(clk, clrn, ena) = (clock, !aclr, clken);-- dataa connections as we have intermediate subaddersdataa_ff[0].d[] = dataa[];IF INT_LATENCY > 2 GENERATEdataa_ff[INT_LATENCY-2..1].d[] = dataa_ff[INT_LATENCY-3..0].q[];END GENERATE;-- datab input connectionsIF RWIDTH > 0 GENERATEIF RWIDTH > 1 GENERATEFOR I IN 1 TO RWIDTH-1 GENERATEdatab0_ff[0][I].d[] = datab_node[(I+1)*SUB_WIDTH0-1..I*SUB_WIDTH0];END GENERATE;END GENERATE;FOR I IN 0 TO LWIDTH-1 GENERATEdatab1_ff[0][I].d[] = datab_node[(I+1)*SUB_WIDTH1+RWIDTH*SUB_WIDTH0-1..I*SUB_WIDTH1+RWIDTH*SUB_WIDTH0];END GENERATE;ELSE GENERATEIF LWIDTH > 1 GENERATEFOR I IN 1 TO LWIDTH-1 GENERATEdatab1_ff[0][I].d[] = datab_node[(I+1)*SUB_WIDTH1-1..I*SUB_WIDTH1];END GENERATE;END GENERATE;END GENERATE;-- some adder connectionsIF RWIDTH > 0 GENERATE-- The nonhomogeneous adder case. Note that with RWIDTH > 0,-- INT_LATENCY must have been > 1.-- longer (right hand side) adder(s) connection(s)-- the upper right-most adder is connected to the input nodesadder0[0].dataa[] = dataa[SUB_WIDTH0-1..0];adder0[0].datab[] = datab_node[SUB_WIDTH0-1..0];adder0[0].cin = cin_node;-- if more than one right-side adder, make the input and carry connectionsIF RWIDTH > 1 GENERATEFOR I IN 1 TO RWIDTH-1 GENERATEadder0[I].dataa[] = dataa_ff[I-1].q[(I+1)*SUB_WIDTH0-1..I*SUB_WIDTH0];adder0[I].datab[] = datab0_ff[I-1][I].q[];adder0[I].cin = adder0[I-1].cout;END GENERATE;END GENERATE;-- first left-hand-side adder connectionsadder1[0].dataa[] = dataa_ff[RWIDTH-1].q[SUB_WIDTH1+RWIDTH*SUB_WIDTH0-1..RWIDTH*SU adder1[0].datab[] = datab1_ff[RWIDTH-1][0].q[];adder1[0].cin = adder0[RWIDTH-1].cout;ELSE GENERATE-- case with homogeneous addersadder1[0].dataa[] = dataa[SUB_WIDTH1-1..0];adder1[0].datab[] = datab_node[SUB_WIDTH1-1..0];adder1[0].cin = cin_node;END GENERATE;-- more connections if more than 1 left-hand-side adders existIF LWIDTH > 1 GENERATEFOR I IN 1 TO LWIDTH-1 GENERATEadder1[I].dataa[] = dataa_ff[I+RWIDTH-1].q[(I+1)*SUB_WIDTH1+RWIDTH*SUB_WIDTH0-1..I*SUB_WIDTH1+RWIDTH*SUB_WIDTH0];adder1[I].datab[] = datab1_ff[I+RWIDTH-1][I].q[];END GENERATE;adder1[LWIDTH-1..1].cin = adder1[LWIDTH-2..0].cout;END GENERATE;IF USED(cout) # USED(overflow) GENERATEcout_node = adder1[LWIDTH-1].cout;unreg_cout_node = adder1[LWIDTH-1].unreg_cout;ELSE GENERATEcout_node = GND;unreg_cout_node = GND;END GENERATE;ELSE GENERATE------------------------------------------------ FLEX cases -------------------------------------------------- adders clock/aclr/clken/add_sub connectionsIF RWIDTH > 0 GENERATEadder0[RWIDTH-1..0].(clock, aclr, clken) = (clock, aclr, clken);IF RWIDTH > 1 GENERATEadder0_0[RWIDTH-1..1].(clock, aclr, clken) = (clock, aclr, clken);END GENERATE;IF (LWIDTH > 1) GENERATEadder1[LWIDTH-2..0].(clock, aclr, clken) = (clock, aclr, clken);END GENERATE;adder1_0[LWIDTH-1..0].(clock, aclr, clken) = (clock, aclr, clken);ELSE GENERATEIF LWIDTH > 1 GENERATEadder1[LWIDTH-2..0].(clock, aclr, clken) = (clock, aclr, clken);adder1_0[LWIDTH-1..1].(clock, aclr, clken) = (clock, aclr, clken);END GENERATE;END GENERATE;IF REG_LAST_ADDER == 1 GENERATEadder1[LWIDTH-1].(clock, aclr, clken) = (clock, aclr, clken);END GENERATE;IF LPM_REPRESENTATION == "SIGNED" GENERATEsign_ff[INT_LATENCY-2..0].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;-- dataa & datab input connectionsIF RWIDTH > 0 GENERATEIF RWIDTH > 1 GENERATEFOR I IN 1 TO RWIDTH-1 GENERATEadder0_0[I].dataa[SUB_WIDTH0-1..0] = dataa[(I+1)*SUB_WIDTH0-1..I*SUB_WIDTH0];adder0_0[I].datab[SUB_WIDTH0-1..0] = datab_node[(I+1)*SUB_WIDTH0-1..I*SUB_WIDdatab0_ff[0][I].d[] = adder0_0[I].result[];END GENERATE;END GENERATE;FOR I IN 0 TO LWIDTH-1 GENERATEadder1_0[I].dataa[SUB_WIDTH1-1..0] = dataa[(I+1)*SUB_WIDTH1+RWIDTH*SUB_WIDTH0-1..I*SUB_WIDTH1+RWIDTH*SUB_WIDTH0];adder1_0[I].datab[SUB_WIDTH1-1..0] = datab_node[(I+1)*SUB_WIDTH1+RWIDTH*SUB_WIDTHI*SUB_WIDTH1+RWIDTH*SUB_WIDTH0];datab1_ff[0][I].d[] = adder1_0[I].result[];END GENERATE;ELSE GENERATEIF LWIDTH > 1 GENERATEFOR I IN 1 TO LWIDTH-1 GENERATEadder1_0[I].dataa[SUB_WIDTH1-1..0] = dataa[(I+1)*SUB_WIDTH1-1..I*SUB_WIDTH1];adder1_0[I].datab[SUB_WIDTH1-1..0] = datab_node[(I+1)*SUB_WIDTH1-1..I*SUB_WIDdatab1_ff[0][I].d[] = adder1_0[I].result[];END GENERATE;END GENERATE;END GENERATE;-- adder and bypass nodes connectionsIF RWIDTH > 0 GENERATE-- The nonhomogeneous adder case. Note that with RWIDTH > 0,-- INT_LATENCY must have been > 1.-- longer (right hand side) adder(s) connection(s)-- the upper right-most adder is connected to the input nodesadder0[0].dataa[SUB_WIDTH0-1..0] = dataa[SUB_WIDTH0-1..0];adder0[0].datab[SUB_WIDTH0-1..0] = datab_node[SUB_WIDTH0-1..0];adder0[0].cin = cin_node;-- if more than one right-side adder, make the input and carry connectionsIF RWIDTH > 1 GENERATEFOR I IN 1 TO RWIDTH-1 GENERATEadder0[I].dataa[0] = adder0[I-1].result[SUB_WIDTH0];adder0[I].datab[] = datab0_ff[I-1][I].q[];END GENERATE;END GENERATE;-- first left-hand-side adder connectionsadder1[0].dataa[0] = adder0[RWIDTH-1].result[SUB_WIDTH0];adder1[0].datab[] = datab1_ff[RWIDTH-1][0].q[];ELSE GENERATE-- case with homogeneous addersadder1[0].dataa[SUB_WIDTH1-1..0] = dataa[SUB_WIDTH1-1..0];adder1[0].datab[SUB_WIDTH1-1..0] = datab_node[SUB_WIDTH1-1..0];adder1[0].cin = cin_node;END GENERATE;-- more connections if more than 1 left-hand-side adders existIF LWIDTH > 1 GENERATEFOR I IN 1 TO LWIDTH-1 GENERATEadder1[I].dataa[0] = adder1[I-1].result[SUB_WIDTH1];adder1[I].datab[] = datab1_ff[I+RWIDTH-1][I].q[];END GENERATE;END GENERATE;IF LPM_REPRESENTATION == "SIGNED" GENERATEsign_ff[0].d[] = (dataa[LPM_WIDTH-1], datab_node[LPM_WIDTH-1]);IF INT_LATENCY > 2 GENERATEFOR I IN 1 TO INT_LATENCY-2 GENERATEsign_ff[I].d[] = sign_ff[I-1].q[];END GENERATE;END GENERATE;END GENERATE;IF USED(cout) # USED(overflow) GENERATEcout_node = adder1[LWIDTH-1].result[SUB_WIDTH1];unreg_cout_node = adder1[LWIDTH-1].unreg_result[SUB_WIDTH1];ELSE GENERATEcout_node = GND;unreg_cout_node = GND;END GENERATE;END GENERATE;---------------------------- datab_ff connections ----------------------------IF RWIDTH > 0 GENERATE-- first quadrant connectionsFOR I IN 0 TO RWIDTH-1 GENERATEdatab0_ff[I][I].d[] = adder0[I].result[];END GENERATE;IF RWIDTH > 1 GENERATEIF RWIDTH > 2 GENERATEFOR I IN 1 TO RWIDTH-2 GENERATEdatab0_ff[I][RWIDTH-1..(I+1)].d[] = datab0_ff[I-1][RWIDTH-1..(I+1)].q[];datab0_ff[I][RWIDTH-1..(I+1)].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;END GENERATE;FOR I IN 1 TO RWIDTH-1 GENERATEdatab0_ff[I][I-1..0].d[] = datab0_ff[I-1][I-1..0].q[];datab0_ff[I][I-1..0].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;END GENERATE;-- fourth quadrant connectionsFOR I IN RWIDTH TO INT_LATENCY-1 GENERATEdatab0_ff[I][RWIDTH-1..0].d[] = datab0_ff[I-1][RWIDTH-1..0].q[];END GENERATE;IF (INT_LATENCY - RWIDTH) > 1 GENERATEFOR I IN RWIDTH TO INT_LATENCY-2 GENERATEdatab0_ff[I][RWIDTH-1..0].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;END GENERATE;IF REG_LAST_ADDER == 1 GENERATEdatab0_ff[INT_LATENCY-1][].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;-- second quadrant connectionsIF RWIDTH > 1 GENERATEFOR I IN 1 TO RWIDTH-1 GENERATEdatab1_ff[I][LWIDTH-1..0].d[] = datab1_ff[I-1][LWIDTH-1..0].q[];datab1_ff[I][LWIDTH-1..0].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;END GENERATE;-- datab1_ff interface between second and third quadrantsIF LWIDTH >1 GENERATEdatab1_ff[RWIDTH][LWIDTH-1..1].d[] = datab1_ff[RWIDTH-1][LWIDTH-1..1].q[];datab1_ff[RWIDTH][LWIDTH-1..1].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;END GENERATE;-- third quadrant connectionsFOR I IN 0 TO LWIDTH-1 GENERATEdatab1_ff[I+RWIDTH][I].d[] = adder1[I].result[];END GENERATE;IF LWIDTH > 1 GENERATEFOR I IN 1 TO LWIDTH-1 GENERATEdatab1_ff[I+RWIDTH][I-1..0].d[] = datab1_ff[I+RWIDTH-1][I-1..0].q[];END GENERATE;IF LWIDTH > 2 GENERATEFOR I IN 1 TO LWIDTH-2 GENERATEdatab1_ff[I+RWIDTH][I-1..0].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;FOR I IN 1 TO LWIDTH-2 GENERATEdatab1_ff[I+RWIDTH][LWIDTH-1..I+1].d[] =datab1_ff[I+RWIDTH-1][LWIDTH-1..I+1].q[]datab1_ff[I+RWIDTH][LWIDTH-1..I+1].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;END GENERATE;IF REG_LAST_ADDER == 1 GENERATEdatab1_ff[INT_LATENCY-1][LWIDTH-2..0].(clk, clrn, ena) = (clock, !aclr, clken);END GENERATE;END GENERATE;-- connections of last row to output nodes-- right sectionIF RWIDTH > 0 GENERATEFOR J IN 0 TO RWIDTH-1 GENERATEresult_node[(J+1)*SUB_WIDTH0-1..J*SUB_WIDTH0] = datab0_ff[INT_LATENCY-1][J].q[SUB_WIDTH0-1..0];END GENERATE;END GENERATE;-- left sectionFOR J IN 0 TO LWIDTH-1 GENERATEresult_node[(J+1)*SUB_WIDTH1+RWIDTH*SUB_WIDTH0-1..J*SUB_WIDT H1+RWIDTH*SUB_WIDTH0] =datab1_ff[INT_LATENCY-1][J].q[SUB_WIDTH1-1..0];END GENERATE;-- overflow detectionIF LPM_REPRESENTATION == "SIGNED" GENERATEIF !(FAMILY_FLEX() == 1) GENERATE[] = (datab1_ff[INT_LATENCY-2][LWIDTH-1].q[SUB_WIDTH1-1] !$dataa_ff[INT_LATENCY-2].q[LPM_WIDTH-1]) &(dataa_ff[INT_LATENCY-2].q[LPM_WIDTH-1] $adder1[LWIDTH-1].unreg_result[SUB_WIDTH1-1]);ELSE GENERATE[] = !(sign_ff[INT_LATENCY-2].q[0] $ sign_ff[INT_LATENCY-2]&(sign_ff[INT_LATENCY-2].q[0] $ adder1[LWIDTH-1].unrEND GENERATE;ELSE GENERATEIF LPM_DIRECTION == "SUB" GENERATE[] = !cout_node;ELSE GENERATEIF USED(add_sub) GENERATE[] = !add_sub_ff[INT_LATENCY-2].q[0] $ unreg_cout_node;ELSE GENERATE[] = cout_node;END GENERATE;END GENERATE;END GENERATE;ELSE GENERATE------------------------------------ non-pipelined adder cases ------------------------------------IF USED(clock) # (USE_LOOK_AHEAD == 0) GENERATE--------------------------------------------------- connections for a ripple carry adder-------------------------------------------------[] = dataa[];[] = datab[];result_node[] = [];IF USED(cin) GENERATE= cin;END GENERATE;IF USED(add_sub) GENERATE= add_sub;END GENERATE;IF USED(cout) GENERATEcout_node = ;ELSE GENERATEcout_node = GND;END GENERATE;IF USED(overflow) GENERATEoflow_node = ;ELSE GENERATEoflow_node = GND;。

1、12进位选择加法器原理图32位进位选择加法器原理图仅仅是将12位进位选择加法器原理图中虚线框内的模块再向后重复5次,这就构成了32位进位选择加法器原理图。
2、Verilog模块根据上图可以将进位选择加法器在结构上分为四个模块:①四位先行进位加法器adder_4bits②四位数据选择器mux_2to1③高四位选择加法器(虚线框内部分)adder_high_4bits④顶层设计32位进位选择加法器adder_32_bits3、Verilog代码# 四位先行进位加法器module adder_4bits(a,b,s,ci,co);parameter N=4;input[N-1:0] a;input[N-1:0] b;input ci;output[N-1:0] s;output co;wire [N-1:0] c;wire [N-1:0] g;wire [N-1:0] p;assign g=a&b;assign p=a|b;assign c[0]=g[0]||(p[0]&&ci);assign c[1]=g[1]||(p[1]&&g[0])||(p[1]&&p[0]&&ci);assign c[2]=g[2]||(p[2]&&g[1])||(p[2]&&p[1]&&g[0])||(p[2]&&p[1]&&p[0]&&ci);assignc[3]=g[3]||(p[3]&&g[2])||(p[3]&&p[2]&&g[1])||(p[3]&&p[2]&&p[1]&&g[0])||(p[3]&&p[2]&&p[1]&&p[0]&&ci);assign s[0]=p[0]&~g[0]^ci;assign s[1]=p[1]&~g[1]^c[0];assign s[2]=p[2]&~g[2]^c[1];assign s[3]=p[3]&~g[3]^c[2];assign co=c[3];endmodule# 四位数据选择器module mux_2to1 (out,in0,in1,sel);parameter N=4;output[N:1] out;input[N:1] in0,in1;input sel;assign out=sel?in1:in0;endmodule# 高四位选择加法器module adder_high_4bits(a,b,ci,co,s);parameter N=4;input[N-1:0] a;input[N-1:0] b;input ci;output[N-1:0] s;output co;wire [N-1:0] sum1,sum0;wire co1,co0,cand;adder_4bits #(4) adder_1(.a(a),.b(b),.s(sum1),.ci(1'b1),.co(co1)); adder_4bits #(4) adder_2(.a(a),.b(b),.s(sum0),.ci(1'b0),.co(co0)); mux_2to1 #(4) mux1(.in0(sum0),.in1(sum1),.sel(ci),.out(s)); and G1(cand,ci,co1);or G2(co,cand,co0);endmodule# 顶层设计32位进位选择加法器module adder_32bits(a,b,s,ci,co);parameter N=32;input [N-1:0] a;input [N-1:0] b;input ci;output [N-1:0] s;output co;wire co1,co2,co3,co4,co5,co6,co7;adder_4bits #(4) adder1(.a(a[3:0]),.b(b[3:0]),.ci(ci),.s(s[3:0]),.co(co1));adder_high_4bits #(4) adder2(.a(a[7:4]),.b(b[7:4]),.ci(co1),.s(s[7:4]),.co(co2));adder_high_4bits #(4) adder3(.a(a[11:8]),.b(b[11:8]),.ci(co2),.s(s[11:8]),.co(co3));adder_high_4bits #(4) adder4(.a(a[15:12]),.b(b[15:12]),.ci(co3),.s(s[15:12]),.co(co4));adder_high_4bits #(4) adder5(.a(a[19:16]),.b(b[19:16]),.ci(co4),.s(s[19:16]),.co(co5));adder_high_4bits #(4) adder6(.a(a[23:20]),.b(b[23:20]),.ci(co5),.s(s[23:20]),.co(co6));adder_high_4bits #(4) adder7(.a(a[27:24]),.b(b[27:24]),.ci(co6),.s(s[27:24]),.co(co7));adder_high_4bits #(4) adder8(.a(a[31:28]),.b(b[31:28]),.ci(co7),.s(s[31:28]),.co(co)); endmodule4、仿真结果①四位先行进位加法器进行仿真,结果如下如图所示,a=0101,b=1010,ci=1;sum=0000,cout=1;仿真正确。

位可控加减法器设计32位算术逻辑运算单元标题:深入探讨位可控加减法器设计中的32位算术逻辑运算单元一、引言在计算机系统中,算术逻辑运算单元(ALU)是至关重要的部件,用于执行数字运算和逻辑运算。
而在ALU中,位可控加减法器设计是其中的重要部分,尤其在32位算术逻辑运算单元中更是不可或缺。
本文将深入探讨位可控加减法器设计在32位算术逻辑运算单元中的重要性,结构特点以及个人观点和理解。
二、位可控加减法器设计的重要性位可控加减法器是ALU中的重要组成部分,它具有对加法和减法操作进行控制的能力,可以根据输入信号来实现不同的运算操作。
在32位算术逻辑运算单元中,位可控加减法器的设计要考虑到对每一位进行并行操作,并且要保证高速、低功耗和稳定性。
位可控加减法器设计在32位算术逻辑运算单元中具有非常重要的意义。
三、位可控加减法器设计的结构特点在32位算术逻辑运算单元中,位可控加减法器的设计需要考虑到以下几个结构特点:1. 并行运算:位可控加减法器需要能够实现对32位数据的并行运算,以提高运算速度。
2. 控制信号:设计需要合理的控制信号输入,来实现不同的运算模式和操作类型。
3. 进位传递:保证进位信号能够正确传递和计算,以确保运算的准确性。
4. 低功耗:设计需要考虑到低功耗的特点,以满足现代计算机系统对能源的需求。
四、个人观点和理解在我看来,位可控加减法器设计在32位算术逻辑运算单元中扮演着十分重要的角色。
它不仅需要具备高速、稳定和精确的运算能力,还需要考虑到功耗和控制信号的合理设计。
只有兼具这些特点,才能更好地满足现代计算机系统对于高效、可靠和低功耗的需求。
五、总结和回顾通过本文对位可控加减法器设计在32位算术逻辑运算单元中的深入探讨,我们可以看到它在计算机系统中的重要性和结构特点。
而个人观点也表明了它需要具备高速、低功耗和稳定性等特点,才能更好地满足现代计算机系统的需求。
在写作过程中,我对位可控加减法器设计在32位算术逻辑运算单元中的重要性和结构特点进行了深入探讨,并分享了个人观点和理解。

32位浮点加法器设计一、基本原理浮点数加法运算是在指数和尾数两个部分进行的。
浮点数一般采用IEEE754标准表示,其中尾数部分采用规格化表示。
浮点加法的基本原理是将两个浮点数的尾数对齐并进行加法运算,再进行规格化处理。
在加法运算过程中,还需考虑符号位、指数溢出、尾数对齐等特殊情况。
二、设计方案1. 硬件实现方案:采用组合逻辑电路实现浮点加法器,以保证运算速度和实时性。
采用Kogge-Stone并行加法器、冒泡排序等技术,提高运算效率。
2.数据输入:设计32位浮点加法器,需要提供两个浮点数的输入端口,包括符号位、指数位和尾数位。
3.数据输出:设计32位浮点加法器的输出端口,输出相加后的结果,包括符号位、指数位和尾数位。
4.控制信号:设计合适的控制信号,用于实现指数对齐、尾数对齐、规格化等操作。
5.流程控制:设计合理的流程控制,对各个部分进行并行和串行处理,提高加法器的效率。
三、关键技术1. Kogge-Stone并行加法器:采用Kogge-Stone并行加法器可以实现多位数的并行加法运算,提高运算效率。
2.浮点数尾数对齐:设计浮点加法器需要考虑浮点数尾数的对齐问题,根据指数大小进行右移或左移操作。
3.溢出判断和处理:浮点加法器需要判断浮点数的指数是否溢出,若溢出需要进行调整和规格化。
4.符号位处理:设计浮点加法器需要考虑符号位的处理,确定加法结果的符号。
四、性能评价性能评价是衡量浮点加法器设计好坏的重要指标。
主要从以下几个方面进行评价:1.精度:通过与软件仿真结果进行比较,评估加法器的运算精度,误差较小的加法器意味着更高的性能。
2.速度:评估加法器的运行速度,主要考虑延迟和吞吐量。
延迟越低,意味着加法器能够更快地输出结果;吞吐量越高,意味着加法器能够更快地处理多个浮点加法运算。
3.功耗:评估加法器的功耗情况,低功耗设计有助于提高整个系统的能效。
4.面积:评估加法器的硬件资源占用情况,面积越小意味着设计更紧凑,可用于片上集成、嵌入式系统等场景。
32位浮点加法器设计摘要:浮点数具有数值范围大,表示格式不受限制的特点,因此浮点数的应用是非常广泛的。
浮点数加法运算比较复杂,算法很多,但是为了提高运算速度,大部分均是基于流水线的设计结构。
本文介绍了基于IEE754标准的用Verilog语言设计的32位浮点加法器,能够实现32位浮点数的加法运算。
虽然未采用流水线的设计结构但是仍然对流水线结构做了比较详细的介绍。
关键字:浮点数,流水线,32位浮点数加法运算,Verilog语言设计32-bit floating point adder designCao Chi,Shen Jia- qi,Zheng Yun-jia[(School of Mechatronic Engineering and Automation, Shanghai University, Shanghai ,China)words:float; Assembly line; 32-bit floating-point adder浮点数的应用非常广泛,无论是在计算机还是微处理器中都离不开浮点数。
但是浮点数的加法运算规则比较复杂不易理解掌握,而且按照传统的运算方法,运算速度较慢。
因此,浮点加法器的设计采用了流水线的设计方法。
32位浮点数运算的摄入处理采用了IEE754标准的“0舍1入”法。
1.浮点数的介绍在处理器中,数据不仅有符号,而且经常含有小数,即既有整数部分又有小数部分。
根据小数点位置是否固定,数的表示方法分为定点表示和浮点表示。
浮点数就是用浮点表示法表示的实数。
浮点数扩大了数的表示范围和精度。
浮点数由阶符、阶码E、数符、尾数N构成。
任意一个二进制数N总可以表示成如下形式:N=±M×2±E。
通常规定:二进制浮点数,其尾数数字部分原码的最高位为1,叫作规格化表示法。
因此,扩大数的表示范围,就增加阶码的位数,要提高精度,就增加尾数的位数。
浮点数表示二进制数的优势显而易见。
【位可控加减法器设计32位算术逻辑运算单元】1. 引言位可控加减法器是现代计算机中十分重要的组成部分,它可以在逻辑电路中实现对算术运算的功能。
其中,32位算术逻辑运算单元是计算机中非常常见的一个部件,它可以用来进行32位数据的加法、减法和逻辑运算。
本文将就位可控加减法器的设计和32位算术逻辑运算单元进行全面评估,并给出深度和广度兼具的解析。
2. 什么是位可控加减法器位可控加减法器是一种灵活的算术逻辑电路,它可以根据控制信号来选择进行加法运算或减法运算。
这种设计可以大大提高电路的灵活性和适用性,使得算术运算单元可以在不同的情况下实现不同的运算需求。
3. 32位算术逻辑运算单元的设计原理32位算术逻辑运算单元是计算机中进行32位数据运算的核心部件,它通常包括加法器、减法器、逻辑门等组件。
在设计中,需要考虑到加法器和减法器的位宽、进位和溢出等问题,同时还需要考虑逻辑门的多功能性和灵活性。
通过合理的组合和控制,可以实现对32位数据进行高效的算术逻辑运算。
4. 位可控加减法器设计在32位算术逻辑运算单元中的运用位可控加减法器的设计可以很好地应用在32位算术逻辑运算单元中,通过控制信号来选择进行加法或减法运算,从而满足不同情况下对数据的处理需求。
这种设计不仅能简化电路结构和控制逻辑,还能提高算术逻辑运算单元的灵活性和效率,使其更适用于不同的场景和运算需求。
5. 个人观点和理解从我个人的理解来看,位可控加减法器设计在32位算术逻辑运算单元中的应用,可以很好地提高计算机的运算效率和灵活性。
通过合理的设计和控制,可以使得算术逻辑运算单元在不同的情况下具有不同的功能,从而更好地满足计算机对于数据处理的需求。
这种设计也为计算机的设计和优化提供了很好的思路和方法。
6. 总结通过本文的评估和解析,我们对于位可控加减法器的设计以及在32位算术逻辑运算单元中的应用有了更深入的理解。
通过灵活的控制信号,可以实现算术逻辑运算单元在不同情况下对数据进行不同的处理,从而提高了计算机的运算效率和灵活性。
基于RISC指令系统的32位浮点加减法运算器设计摘要:浮点运算部件一直是限制微处理器性能的一个关键因素。
在分析了浮点运算器的结构和算法,提出了一种支持IEEE-754标准的浮点加减法运算器的实现方案,并详细介绍了该运算器的结构和算法。
方案采用了四级流水线的结构,即:0操作数检查、对阶、尾数运算、结果规格化及舍入处理。
每个步骤可以单独作为一个模块,在每个模块之间增加了寄存器,利用这些寄存器可以为下一个操作准备正确的数据。
关键词:流水线,IEEE-754标准,警戒位,舍入法32 bit Floating-Point Addition and Subtraction ALU Design Based onRISC StructureABSTRACT:Floating-Point arithmetic unit is always key factor of restricting microprocessor performance.This paper analyses structure and algorithm of Floating-Point ALU and brings forward a scenario about Floating-Point addition and subtraction ALU which supports IEEE-754 standard. The scenario adopts 4-Level pipelining structure: 0 operation numbers check、match exponent、fraction arithmetic、result normalization and rounding. Each step can be act as a single module. Among these modules, there are some registers which can prepare correct data for next operation.Keywords: pipelining, IEEE-754 Standard, Guard Digit, Rounding Method1 引言随着SOC技术、IP技术以及集成电路技术的发展,RISC软核处理器的研究与开发设计开始受到了人们的重视。
文章编号:1001-893X(2003)06-0073205基于FPG A的32位浮点FFT处理器的设计3Ξ赵忠武,陈 禾,韩月秋(北京理工大学电子工程系,北京100081)摘 要:介绍了一种基于FPG A的1024点32位浮点FFT处理器的设计。
采用改进的蝶形运算单元,减小了系统的硬件消耗,改善了系统的性能。
详细讨论了32位浮点加法器/减法器、乘法器的分级流水技术,提高了系统性能。
浮点算法的采用使得系统具有较高的处理精度。
关键词:数字信号处理;快速傅里叶变换;浮点加法器/减法器;浮点乘法器;分级流水;可编程门阵列;设计中图分类号:T N91117 文献标识码:AFPGA-based Design of a32Bit Floating-pointFFT ProcessorZH AO Zhong-wu,CHEN He,H AN Yue-qiu(Department of Electronic Engineering,Beijing Institute of T echnology,Beijing100081,China)Abstract:An FPG A-based design of a32bit floating-point FFT process or used to com pute1024points FFT is presented.Because of the utilization of im proved butterfly process or,hardware consum ption is reduced and the performance is im proved.The pipelining technique of32bit floating-point adder/subtracter and multiplier is introduced in detail,which can enhance the performance of the FFT process or.High precision is achieved due to the inherence of the floating-point alg orithm.K ey w ords:Digital signal processing;FFT;Floating-point adder/subtracter;Floating-point multiplier;Pipelining;FPG A;Design一、引 言1965年快速傅里叶变换(FFT)的提出,根本地改变了傅里叶变换的地位。
16位快速加法器32位快速加法器(运算器设计)快速加法器的设计基于全加器和半加器的组合。
全加器可以实现对两个二进制位的相加,并且可以处理进位。
半加器只能处理两个二进制位的相加,但不能处理进位。
快速加法器通过使用多个全加器和半加器的级联来实现对多个二进制位的相加,并处理进位。
一个16位快速加法器通常由16个全加器组成,每个全加器对应一个二进制位的相加。
输入端包括两个16位的二进制数A和B,以及一个进位输入Cin。
输出端包括一个16位的二进制数S和一个进位输出Cout。
快速加法器的设计中还考虑了进位的传递问题。
通常情况下,每个全加器的进位输入都连接到前一个全加器的进位输出。
这样,在相加的过程中,进位会从低位传递到高位。
为了提高运算器的效率,可以采用并行运算的方式。
32位快速加法器可以通过将两个16位快速加法器并联来实现。
其中,一个加法器负责处理前16位,另一个加法器负责处理后16位。
这样可以同时进行两个16位数的相加,大大提高了加法操作的速度。
快速加法器的工作原理如下:1.将输入的两个16位二进制数A和B送入第一个全加器,通过16个全加器的级联实现对各位的相加,并处理进位。
2.每个全加器的输出与相应的进位输入连线,以实现进位的传递。
3.得到的16位二进制数S作为输出。
对于32位快速加法器,它由两个16位快速加法器组成,其中第一个加法器处理低16位,第二个加法器处理高16位。
输入的两个32位二进制数A和B被拆分为两个16位数,并分别送入两个加法器进行相加。
最后,两个相加的结果通过一个与门来判断是否有进位,进一步得到32位的二进制数S和进位输出Cout。
快速加法器是计算机中常用的运算器,它在高速计算和数据处理方面具有重要的作用。
通过合理的设计和优化,可以实现更高效的加法操作,提高计算机的性能。
同时,快速加法器的设计还需要考虑功耗和面积等因素,以实现更好的综合性能。
module floatingpoint32(en,A,B,C);input en;input[31:0] A,B;output[31:0] C;reg[31:0] C;reg[7:0] AE,BE,CE,DE;reg AS,BS,CS,DS;reg[24:0] AF,BF,CF;reg[7:0] index;integer in;integer tem;always @(A or B)//上升沿触发beginif(en==1)beginAE=A[30:23]; // 阶码8位用的是移码表示+127 01111111AF={2'b01,A[22:0]};//把缺省的1给补上同时考虑做加法时有可能产生进位所以补齐23+1+1 共25位AS=A[31]; // 最高位即符号位BE=B[30:23];BF={2'b01,B[22:0]};BS=B[31];//如果某一方阶码大,则符号位一定是在大的一方if (A[30:0]==0) //如果A是0,则结果就是B了beginCS=BS;CE=BE;CF=BF;endelse if(B[30:0]==0) //如果B是0,则结果就是A了beginCS=AS;CE=AE;CF=AF;endelse //A、B都不为0的情况下beginif(AE>BE) //A的阶码大于B的阶码beginCE=AE; //对阶DE=AE-BE; //阶码做差BF=(BF>>DE); //右移if (AS==BS) //如果A、B符号位相同,就做加法beginCS=AS;CF=AF+BF;endelse if (AS!=BS) //如果A、B的符号位不相同,就做减法beginCS=AS;CF=AF-BF;endendelse if(AE<BE) //A的阶码小于B的阶码beginCE=BE; //对阶DE=BE-AE; //阶码做差AF=(AF>>DE); //右移if (AS==BS) //如果A、B符号位相同,就做加法beginCS=AS;CF=AF+BF;endelse if (AS!=BS) //如果A、B的符号位不相同,就做减法beginCS=BS;CF=BF-AF;endendelse if(AE==BE) //A的阶码等于B阶码beginCE=AE; //首先确定结果的阶码if (AS==BS) // 如果A、B符号位相同,就做加法beginCS=AS;CF=AF+BF;endelse //如果A、B的符号位不相同,就做减法beginCS=BS;CF=BF-AF;endend//归一化,寻找CF第一个1,并将其前移in=24;tem=0;while(tem==0&&in>=0)beginif(CF[in]!=0)//如果尾数最高位CF[24]即尾数第25位不为0,则可以进行尾数规一化。
32位浮点加法器设计
苦行僧宫城
摘要:运算器的浮点数能够提供较大的表示精度和较大的动态表示范围,浮点运算已成为现代计算程序中不可缺少的部分。
浮点加法运算是浮点运算中使用频率最高的运算。
因此,浮点加法器的性能影响着整个CPU的浮点处理能力。
文中基于浮点加法的原理,采用Verilog硬件描述语言设计32位单精度浮点数加法器,并用modelsim对浮点加法器进行仿真分析,从而验证设计的正确性和可行性。
关键词:浮点运算浮点加法器 Verilog硬件描述语言
Studying on Relation of Technology and Civilization
苦行僧宫城
(School of Mechatronic Engineering and Automation, Shanghai University, Shanghai , China) Abstract: The floating-point arithmetic provides greater precision and greater dynamic representation indication range, with floating point calculations have become an indispensable part of the program. Floating-point adder is the most frequently used floating point arithmetic. Therefore, the performance of floating point adder affecting the entire CPU floating point processing capabilities. In this paper the principle-based floating-point addition, Verilog hardware description language design 32-bit single-precision floating-point adder and floating-point adder using modelsim simulation analysis in order to verify the correctness and feasibility of the desig
小组成员及任务分配:
1浮点数和浮点运算
1.1浮点数
浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。
具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学记数法。
1.2浮点格式
常用的浮点格式为IEEE 754 标准,IEEE 754 标准有单精度浮点数、双精度浮点数和扩展双精度浮点数3 种,单精度为32 位,双精度为64 位,扩展双精度为80 位以上,位数越多精度越高,表示范围也越大。
在通常的数字信号处理应用中,单精度浮点数已经足够用了,本文将以它为例来设计快速浮点加法器。
单精度浮点数如图1所示。
其中s为符号位,s为1 时表示负数,s为0时表示正数;e为指数,取值范围为[1,254],0和255表示特殊值;f有22位,再加上小数点左边一位隐含的1总共23位构成尾数部分。
1.3 浮点运算
浮点加法运算由一些单独的操作组成。
在规格化的表示中,对于基为2的尾数的第1个非0位的1是隐含的,因此,可以通过不存储这一位而使表示数的数目增加。
但在进行运算时不能忽略。
浮点加法一般要用以下步骤完成:
a) 指数相减:将2个指数化为相同值,通过比较2个指数的大小求出指数差的绝对值ΔE。
b) 对阶移位: 将指数较小的操作数的尾数右移ΔE位。
c) 尾数加减:对完成对阶移位后的操作数进行加减运算。
d) 转换:当尾数相加的结果是负数时,要进行求补操作,将其转换为符号2尾数的表示方式。
e) 前导1 和前导0 的判定:判定由于减法结果产生的左移数量或由于加法结果产生的右移数量。
f) 规格化移位:对尾数加减结果进行移位,消除尾数的非有效位,使其最高位为1。
g) 舍入:有限精度浮点表示需要将规格化后的尾数舍入到固定结果。
由以上基本算法可见,它包含2 个全长的移位即对阶移位和规格化移位,还要包括3 个全长的有效加法,即步骤c 、d、g。
由此可见,基本算法将会有很大的时延。
232位浮点加法器设计与实现
基于上述浮点数的加法运算规则,我们小组主要的设计思路是:
1.前端处理,还原尾数
2.指数处理,尾数位移使指数相等
3.尾数相加
4.尾数规格化处理
5.后端处理,输出浮点数
设计代码如下:
仿真结果如下:
3 3 Verilog 实验报告总结
此次实验,从国庆过后开始,28日结束,在小组三个人的共同努力下,克服多次失败过后,终于把波形调了出来。
实验过程中遇到了许多在之前没有遇过过的问题,其中文件关联尤为突出,还有一些Verilog的语法问题,通过这次实验,学到了许多实际编程有用的东西,特别是对Top_dowm和bottom-up的设计思路,有了更为深刻的理解。
1.设计过程总结
本次实验采用Top_down的设计思路,在弄清楚了浮点数加法的基本规则过后,即清楚输入输出,从而拟定几个基本的输入,ia,ib,ena,reset和clk,即用于计算的两个浮点数ia和ib 根据要求,其位宽定为32位,之后就是一个重置端reset,和脉冲信号clk,最后就是使能端ena,当然,有输入肯定有输出了,综合浮点数的两个标准,尾数和指数,即ze和zm,应浮点数的一般大小,暂时把ze设为8位,zm设定为24位,即暂定为两个输出端口,但是,作为一个完整的输出结果,在输入信号的综合完成后,明显只有一个输出数是不完整的,因此我们增加了一个辅助输出,即driver。
输入输出结束过后,就是对一些寄存器的定义了,显然,在对输入的锁存状态有一些特别的考虑,即ia和ib暂时锁存在一个状态中,然后通过浮点加法规则,对寄存器取值计算,最后输出结果,具体加法器算法参考网络。
完整的加法器大概框架构建出来过后,剩下的除了用适当的verilog代码进行填充之外,还要做一个完整的TB来进行测试,关于TB,我们初拟定两个固定的32位二进制数ia和ib,即32'h41A00000和32'H41080000,最后通过检测通过加法器运算的结果和理论值,来判断所设计的加法器是否满足要求。
综上,即为本次实验的大概设计思路。
2.代码编写过程总结
在拟定了实验大概构架过后,我们查询了相关verilog的语法规则,在对网络给出的代码进行详细解读和分析过后,在小组三人的共同努力下,对写出的代码作出了细致的解释,特别是对寄存器和相关网络借口的注释更为详尽。
当然,参考代码毕竟不是抄袭,在保留自
己大概思想的前提下,对几个错误之处,进行对应修改。
3.仿真过程总结
仿真,即在软件上面modisim上面仿真了。
仿真之前,针对加法器的具体仿真要求,我们编出了相对的测试tb,但是一般第一次仿真都是以失败告终的,我们也不出意外,在对两个文件编译成功过后,我们对两个文件进行关联,可是就是关联不上,如下图:
图一
然后我们又把两个代码拿出来进行对比,终于在两个文件的模块接口处找到了问题,接口如图:
图二
图三
即发现加法器中多了一个端口,但是在TB当中又找不到ze和zm两个端口,很明显,第一个错误是由于马虎造成,后面通过对TB的修改,添加了新的寄存器ze和zm,因此在加法器的接入端口上面将zo端口用这两个新增的端口代替,再进行仿真。
后面波形是出来了,但还是不对,即只有tb中输入的波形,没有输出的波形,仿真波形如下:
图四
最后检查还是端口接法不对,修改,仿真,得到如下波形:
图五
进检验,满足要求。
仿真过程结束。
4.实验结果分析总结
整个实验过程就是一个提成方案,描述方案,找到问题,解决问题的过程,并且通过这个过程来找到实验的意义。
通过这次实验,主要是对浮点数的运算用verilog代码来描述有了更加深刻的认识,同时也为其他的数据算法用verilog描述有了进一步的心得。
为用verilog
构建复杂的数据模块奠定基础,对今后的数字电路设计有深刻的影响。
5.小组成员分工及总结
此次实验,小组分工是十分明确的,整个实验任务主要分为两块,实验和论文的书写,实验由三个人共同负责,一起讨论,一起对代码进行修改和仿真。
然后,论文的书写就主要分为三块,前面的对浮点加法器的介绍主要由***负责,中间部分的实验描述,框图及其说明由**负责,最后的实验总结及整个写好后的论文修改由***负责。
整个过程分工明确,协调进行,配合清楚。
6.心得体会
实验过后,终于长长的舒了一口气,这个课程的任务终于要完成了,当然,实验,仅仅是检验学习的一种途径,在后面,更应该多多练习,熟悉并掌握这门实用的数字电路工具。
贯穿整个实验,小组成员之间紧密配合,在团队合作,共同进步的思想下,收获了很多个体与团队间的经验,但更多的,还是对课程知识的运用和总结,总得说来,这次实验让大家受益匪浅。
参考文献:
/view/339796.htm
快速浮点加法器的优化设计王颖林正浩同济大学微电子中心。