数据分析与数据挖掘--实验六 聚类分析实验(2)
- 格式:doc
- 大小:63.00 KB
- 文档页数:3

实验设计过程及分析:1、通过通信企业数据(USER_INFO_M.csv),使用K-means算法实现运营商客户价值分析,并制定相应的营销策略。
(预处理,构建5个特征后确定K 值,构建模型并评价)代码:setwd("D:\\Mi\\数据挖掘\\")datafile<-read.csv("USER_INFO_M.csv")zscoredFile<- na.omit(datafile)set.seed(123) # 设置随机种子result <- kmeans(zscoredFile[,c(9,10,14,19,20)], 4) # 建立模型,找聚类中心为4round(result$centers, 3) # 查看聚类中心table(result$cluster) # 统计不同类别样本的数目# 画出分析雷达图par(cex=0.8)library(fmsb)max <- apply(result$centers, 2, max)min <- apply(result$centers, 2, min)df <- data.frame(rbind(max, min, result$centers))radarchart(df = df, seg =5, plty = c(1:4), vlcex = 1, plwd = 2)# 给雷达图加图例L <- 1for(i in 1:4){legend(1.3, L, legend = paste("VIP_LVL", i), lty = i, lwd = 3, col = i, bty = "n")L <- L - 0.2}运行结果:2、根据企业在2016.01-2016.03客户的短信、流量、通话、消费的使用情况及客户基本信息的数据,构建决策树模型,实现对流失客户的预测,F1值。

第1篇一、实验背景聚类分析是数据挖掘中的一种重要技术,它将数据集划分成若干个类或簇,使得同一簇内的数据点具有较高的相似度,而不同簇之间的数据点则具有较低相似度。
本实验旨在通过实际操作,了解并掌握聚类分析的基本原理,并对比分析不同聚类算法的性能。
二、实验环境1. 操作系统:Windows 102. 软件环境:Python3.8、NumPy 1.19、Matplotlib 3.3.4、Scikit-learn0.24.03. 数据集:Iris数据集三、实验内容本实验主要对比分析以下聚类算法:1. K-means算法2. 聚类层次算法(Agglomerative Clustering)3. DBSCAN算法四、实验步骤1. K-means算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的KMeans类进行聚类,设置聚类数为3。
(3)计算聚类中心,并计算每个样本到聚类中心的距离。
(4)绘制聚类结果图。
2. 聚类层次算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的AgglomerativeClustering类进行聚类,设置链接方法为'ward'。
(3)计算聚类结果,并绘制树状图。
3. DBSCAN算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的DBSCAN类进行聚类,设置邻域半径为0.5,最小样本数为5。
(3)计算聚类结果,并绘制聚类结果图。
五、实验结果与分析1. K-means算法实验结果显示,K-means算法将Iris数据集划分为3个簇,每个簇包含3个样本。
从聚类结果图可以看出,K-means算法能够较好地将Iris数据集划分为3个簇,但存在一些噪声点。
2. 聚类层次算法聚类层次算法将Iris数据集划分为3个簇,与K-means算法的结果相同。
从树状图可以看出,聚类层次算法在聚类过程中形成了多个分支,说明该算法能够较好地处理不同簇之间的相似度。

第1篇一、实验背景与目的随着大数据时代的到来,数据量呈爆炸式增长,如何有效地对海量数据进行聚类分析,提取有价值的信息,成为数据挖掘领域的重要课题。
动态聚类分析作为一种新兴的聚类方法,能够在数据不断变化的情况下,自动调整聚类结果,具有较强的适应性和实用性。
本次实验旨在通过动态聚类分析,对一组数据进行聚类,并验证其有效性和可靠性。
二、实验数据与工具1. 实验数据本次实验数据来源于某电商平台用户购买行为数据,包括用户ID、购买时间、商品类别、购买金额等字段。
数据量约为10万条,具有一定的代表性。
2. 实验工具本次实验采用Python编程语言,利用sklearn库中的KMeans、DBSCAN等动态聚类算法进行实验。
三、实验方法与步骤1. 数据预处理(1)数据清洗:删除缺失值、异常值等无效数据;(2)数据标准化:将不同量纲的数据进行标准化处理,消除数据之间的量纲差异;(3)特征选择:根据业务需求,选取对聚类结果影响较大的特征。
2. 动态聚类分析(1)KMeans聚类:设置聚类数量k,初始化聚类中心,计算每个样本与聚类中心的距离,将样本分配到最近的聚类中心所在的簇;迭代更新聚类中心和簇成员,直至满足停止条件;(2)DBSCAN聚类:设置邻域半径ε和最小样本数min_samples,遍历每个样本,计算其邻域内的样本数量,根据样本密度进行聚类;(3)动态聚类分析:设置时间窗口,以时间窗口内的数据为样本,重复上述聚类过程,观察聚类结果随时间的变化趋势。
四、实验结果与分析1. KMeans聚类结果通过KMeans聚类,将用户分为若干个簇,每个簇代表一组具有相似购买行为的用户。
从聚类结果来看,大部分簇的用户购买行为较为集中,具有一定的区分度。
2. DBSCAN聚类结果DBSCAN聚类结果与KMeans聚类结果相似,大部分簇的用户购买行为较为集中。
同时,DBSCAN聚类能够发现一些KMeans聚类无法发现的潜在簇,例如小众用户群体。

数据挖掘6个实验实验报告中南民族⼤学计算机科学学院《数据挖掘与知识发现》综合实验报告姓名年级专业软件⼯程指导教师学号序号实验类型综合型2016年12 ⽉10 ⽇⼀、使⽤Weka建⽴决策树模型1、准备数据:在记事本程序中编制ColdType-training.arff,ColdType-test.arff。
2、加载和预处理数据。
3、建⽴分类模型。
(选择C4.5决策树算法)4、分类未知实例⼆、使⽤Weka进⾏聚类1、准备数据:使⽤ColdType.csv⽂件作为数据集。
2、加载和预处理数据。
3、聚类(⽤简单K -均值算法)4、解释和评估聚类结果三、完成感冒类型的相关操作及相应处理结果1.加载了ColdType-training.arff⽂件后的Weka Explorer界⾯:2.感冒类型诊断分类模型输出结果:Sore-throat = Yes| Cooling-effect = Good: Viral (2.0)4.感冒类型诊断聚类结果:Cluster centroids:Cluster#Attribute Full Data 0 1(10) (5) (5) ================================================= Increased-lym Yes Yes No Leukocytosis Yes No Yes Fever Yes Yes Yes Acute-onset Yes Yes No Sore-throat Yes No Yes Cooling-effect Good Good Notgood Group Yes Yes NoTime taken to build model (full training data) : 0 seconds=== Model and evaluation on training set ===Clustered Instances0 5 ( 50%)1 5 ( 50%)Class attribute: Cold-typeClasses to Clusters:0 1 <-- assigned to cluster5 1 | Viral0 4 | BacterialCluster 0 <-- ViralCluster 1 <-- BacterialIncorrectly clustered instances : 1.010 %分析:由诊断聚类结果图可知,聚类中有两个簇Cluster0和Cluster1,分别对应Viral类和Bacterial类,但有⼀个实例被聚类到错误的簇,聚类错误率为10%。

数据挖掘实验报告(三)聚类分析姓名:李圣杰班级:计算机1304学号:1311610602一、实验目的1、掌握k-means 聚类方法;2、通过自行编程,对三维空间内的点用k-means 方法聚类。
二、实验设备PC 一台,dev-c++5.11三、实验内容1.问题描述:立体空间三维点的聚类.说明:数据放在数据文件中(不得放在程序中),第一行是数据的个数,以后各行是各个点的x,y,z 坐标。
2.设计要求读取文本文件数据,并用K-means 方法输出聚类中心 3. 需求分析k-means 算法接受输入量k ;然后将n 个数据对象划分为 k 个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
k-means 算法的工作过程说明如下:首先从n 个数据对象任意选择k 个对象作为初始聚类中心,而对于所剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类。
然后,再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值),不断重复这一过程直到标准测度函数开始收敛为止。
一般都采用均方差作为标准测度函数,具体定义如下:21∑∑=∈-=ki iiE C p m p (1)其中E 为数据库中所有对象的均方差之和,p 为代表对象的空间中的一个点,m i 为聚类C i 的均值(p 和m i 均是多维的)。
公式(1)所示的聚类标准,旨在使所获得的k 个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
四、实验步骤Step 1.读取数据组,从N 个数据对象任意选择k 个对象作为初始聚类中心; Step 2.循环Step 3到Step 4直到每个聚类不再发生变化为止; Step 3.根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分;Step 4.重新计算每个(有变化)聚类的均值(中心对象)。
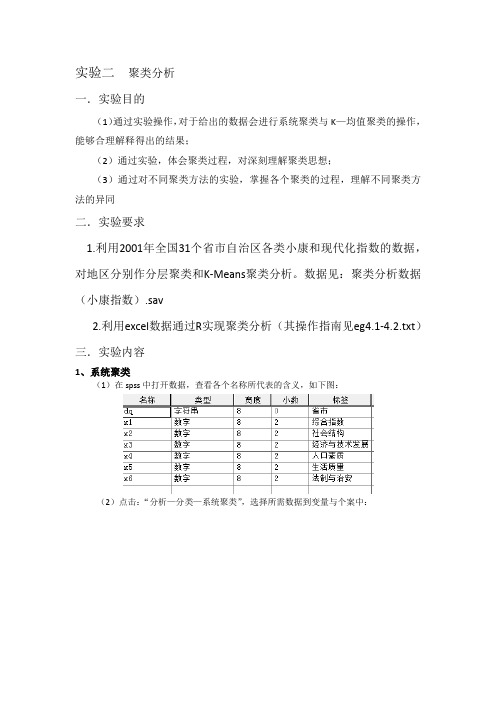
实验二聚类分析一.实验目的(1)通过实验操作,对于给出的数据会进行系统聚类与K—均值聚类的操作,能够合理解释得出的结果;(2)通过实验,体会聚类过程,对深刻理解聚类思想;(3)通过对不同聚类方法的实验,掌握各个聚类的过程,理解不同聚类方法的异同二.实验要求1.利用2001年全国31个省市自治区各类小康和现代化指数的数据,对地区分别作分层聚类和K-Means聚类分析。
数据见:聚类分析数据(小康指数).sav2.利用excel数据通过R实现聚类分析(其操作指南见eg4.1-4.2.txt)三.实验内容1、系统聚类(1)在spss中打开数据,查看各个名称所代表的含义,如下图:(2)点击:“分析—分类—系统聚类”,选择所需数据到变量与个案中:(3)在上图“统计量”中:(4)在“图”中,选中树状图:(5)在“方法”中:说明:上表中,聚类方法包括很多种,教材内介绍的有8种,即以何种方法聚类,在“度量——区间”中,也包括多种方法可选择,即在聚类时,彼此之间的距离的计算方法,如下图:spss得出的结果:对结果的简单说明:在上表、图中,聚类表表示的是聚类的动态过程,每一个步骤中,一个类别将哪些数据聚类在一块,在第几步聚类时,将某一个数据聚类到已经分为一个类的中,例如第一行数据,26表示甘肃,28表示江西,第一步将26、28聚在一起,然后是下一阶7,表示将26、28这个类用26表示,和30聚在一起,然后是15,即26、28、30这个类用26表示,和20聚在一起,这一以此类推,就将所有数据聚类。
上图中,就是哪些先聚在一块,然后又是哪些类聚在一块,要分为几类,就以轴为横轴,画纵轴,将下面的部分分为几部分,就是聚为几类,相比较聚类表更直观,也是聚类表的直观表现。
2、K—均值聚类(1)点击“分析——分类——K-均值聚类”,选择所需数据到变量与标注个案中,如下图:说明:聚类数表示所要做的聚类聚为几类,可以是3、4、等,按需求所做(2)在上图“迭代”中,选择所需要做的最大迭代次数,默认值为10,如下图:(3)在“保存”中,将聚类成员和聚类中心的距离都选中,最后在原始数据中能够显示这俩个值:(4)在“选项”中,选择统计量ANOVA表,即方差分析表,可以进行大致检验分类效果如何,如下图:在spss中得到的结果,如下图:在spss原始数据中多出的俩行数据,即为在第三步中所选中的聚类成员和与聚类中心的距离,如下图:3.练习3.1对第一个实验系统聚类的练习:在以上实验中提到聚类方法可以选择不同种,此时聚类法方选择“质心聚类法”,“区间”选择余弦,如下图:在spss中得到的结果如下:对结果的简单分析:将这次得出的结果同上面的结果进行比较,可以发现基本聚类结果相同,聚类表和聚类图的解释也基本一样,但需注意,在聚类图中,聚类类别对应的标尺的长度不同。
第1篇一、实验目的本次实验旨在通过路径聚类分析,深入理解聚类分析的基本原理和应用,掌握路径聚类算法的实现过程,并学会如何使用聚类分析解决实际问题。
通过实验,我们希望能够提高对数据挖掘和模式识别方法的理解,以及提高在实际应用中处理复杂数据的能力。
二、实验背景聚类分析是数据挖掘中的一个重要技术,它将相似的数据对象归为一类,从而发现数据中的隐藏模式和结构。
路径聚类分析是聚类分析的一种,它主要针对序列数据,如时间序列、空间轨迹等,通过分析数据对象之间的顺序关系来进行聚类。
三、实验内容1. 实验环境与工具- 操作系统:Windows 10- 数据库:MySQL- 聚类分析工具:Python(使用Scikit-learn库)2. 数据准备本次实验采用的数据集为某城市居民出行轨迹数据,包含居民出行的时间、地点、出行方式等信息。
数据集共有1000条记录,每条记录包含5个特征。
3. 实验步骤(1)数据预处理:对数据进行清洗、去重、缺失值处理等操作,确保数据质量。
(2)特征工程:对原始特征进行转换和提取,如将时间转换为时间戳、计算出行距离等。
(3)路径聚类分析:使用Scikit-learn库中的KMeans聚类算法对数据进行路径聚类分析。
(4)结果分析与可视化:对聚类结果进行分析,绘制聚类效果图,并评估聚类效果。
四、实验结果与分析1. 数据预处理经过数据预处理,数据集共包含1000条记录,每条记录包含5个特征。
预处理后的数据满足实验要求,为后续聚类分析提供了可靠的数据基础。
2. 特征工程通过特征工程,我们将时间转换为时间戳,并计算出行距离。
这样,特征维度从5个增加到7个,有助于提高聚类效果。
3. 路径聚类分析使用Scikit-learn库中的KMeans聚类算法对数据进行路径聚类分析,设置聚类数为5。
聚类过程耗时约1分钟。
4. 结果分析与可视化(1)聚类效果图通过聚类效果图可以看出,聚类效果较好,不同聚类之间存在明显的界限。
对数据进行聚类分析实验报告数据聚类分析实验报告摘要:本实验旨在通过对数据进行聚类分析,探索数据点之间的关系。
首先介绍了聚类分析的基本概念和方法,然后详细解释了实验设计和实施过程。
最后,给出了实验结果和结论,并提供了改进方法的建议。
1. 引言数据聚类分析是一种将相似的数据点自动分组的方法。
它在数据挖掘、模式识别、市场分析等领域有广泛应用。
本实验旨在通过对实际数据进行聚类分析,揭示数据中的隐藏模式和规律。
2. 实验设计与方法2.1 数据收集首先,我们收集了一份包含5000条数据的样本。
这些数据涵盖了顾客的消费金额、购买频率、地理位置等信息。
样本数据经过清洗和预处理,确保了数据的准确性和一致性。
2.2 聚类分析方法本实验采用了K-Means聚类算法进行数据分析。
K-Means算法是一种迭代的数据分组算法,通过计算数据点到聚类中心的距离,将数据点划分到K个不同的簇中。
2.3 实验步骤(1)数据预处理:对数据进行归一化和标准化处理,确保每个特征的权重相等。
(2)确定聚类数K:通过执行不同的聚类数,比较聚类结果的稳定性,选择合适的K值。
(3)初始化聚类中心:随机选取K个数据点作为初始聚类中心。
(4)迭代计算:计算数据点与聚类中心之间的距离,将数据点划分到距离最近的聚类中心所在的簇中。
更新聚类中心的位置。
(5)重复步骤(4),直到聚类过程收敛或达到最大迭代次数。
3. 实验结果与分析3.1 聚类数选择我们分别执行了K-Means算法的聚类过程,将聚类数从2增加到10,比较了每个聚类数对应的聚类结果。
通过对比样本内离差平方和(Within-Cluster Sum of Squares, WCSS)和轮廓系数(Silhouette Coefficient),我们选择了最合适的聚类数。
结果表明,当聚类数为4时,WCSS值达到最小,轮廓系数达到最大。
3.2 聚类结果展示根据选择的聚类数4,我们将数据点划分为四个不同的簇。
第1篇一、实验背景随着大数据时代的到来,数据挖掘技术逐渐成为各个行业的重要工具。
数据挖掘是指从大量数据中提取有价值的信息和知识的过程。
本实验旨在通过数据挖掘技术,对某个具体领域的数据进行挖掘,分析数据中的规律和趋势,为相关决策提供支持。
二、实验目标1. 熟悉数据挖掘的基本流程,包括数据预处理、特征选择、模型选择、模型训练和模型评估等步骤。
2. 掌握常用的数据挖掘算法,如决策树、支持向量机、聚类、关联规则等。
3. 应用数据挖掘技术解决实际问题,提高数据分析和处理能力。
4. 实验结束后,提交一份完整的实验报告,包括实验过程、结果分析及总结。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 数据挖掘库:pandas、numpy、scikit-learn、matplotlib四、实验数据本实验选取了某电商平台用户购买行为数据作为实验数据。
数据包括用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业等。
五、实验步骤1. 数据预处理(1)数据清洗:剔除缺失值、异常值等无效数据。
(2)数据转换:将分类变量转换为数值变量,如年龄、性别等。
(3)数据归一化:将不同特征的范围统一到相同的尺度,便于模型训练。
2. 特征选择(1)相关性分析:计算特征之间的相关系数,剔除冗余特征。
(2)信息增益:根据特征的信息增益选择特征。
3. 模型选择(1)决策树:采用CART决策树算法。
(2)支持向量机:采用线性核函数。
(3)聚类:采用K-Means算法。
(4)关联规则:采用Apriori算法。
4. 模型训练使用训练集对各个模型进行训练。
5. 模型评估使用测试集对各个模型进行评估,比较不同模型的性能。
六、实验结果与分析1. 数据预处理经过数据清洗,剔除缺失值和异常值后,剩余数据量为10000条。
2. 特征选择通过相关性分析和信息增益,选取以下特征:用户ID、商品ID、购买时间、价格、商品类别、用户年龄、性别、职业。
甘肃政法学院本科生实验报告(2)姓名:学院:计算机科学学院专业:信息管理与信息系统班级:实验课程名称:数据挖掘实验日期:指导教师及职称:实验成绩:开课时间:2013—2014 学年一学期甘肃政法学院实验管理中心印制二.实验环境Win 7环境下的Eclipse三、实验内容在WEKA中实现K均值的算法,观察实验结果并进行分析。
四、实验过程与分析一、实验过程1、添加数据文件打开Weka的Explore,使用Open file点击打开本次实验所要使用的raff格式数据文件“auto93.raff”2、选择算法类型点击Cluster中的Choose,选择本次实验所要使用的算法类型“SimpleKMeans”3、得出实验结果选中“Cluster Mode”的“Use training set”,点击“Start”按钮,观察右边“Clusterer output”给出的聚类结果如下:=== Run information ===Scheme: weka.clusterers.SimpleKMeans -N 2 -S 10Relation: sInstances: 93Attributes: 23ManufacturerTypeCity_MPGHighway_MPGAir_Bags_standardDrive_train_typeNumber_of_cylindersEngine_sizeHorsepowerRPMEngine_revolutions_per_mile5528.8462 2622.3077 1 15.1346 4.7115 174.8654 100.2692 67.0385 36.8462 26.891 12.6069 2722.3077 0 16.4019Std Devs: N/A N/A 6.0746 5.7467 N/A N/A 0.7301 0.5047 40.8149 484.7019 377.1753 N/A 3.0204 0.848 11.2599 5.5735 2.4968 2.338 2.7753 2.3975 492.4971 N/A 7.9863Clustered Instances0 41 ( 44%)52 ( 56%)4、修改Seed值5、得出修改Seed值后的实验结果=== Run information ===Scheme: weka.clusterers.SimpleKMeans -N 2 -S 8Relation: sInstances: 93Attributes: 23ManufacturerTypeCity_MPGHighway_MPG二、实验分析本次实验采用的数据文件是“1993NewCarData ”。
实验报告封面
课程名称:数据分析与数据挖掘课程代码:
任课老师:周化实验指导老师: 周化
实验报告名称:聚类分析(2)——K均值
与K—最近邻方法
学生姓名:
学号:
教学班:
递交日期:
签收人:
我申明,本报告内的实验已按要求完成,报告完全是由我个人完成,并没有抄袭行为。
我已经保留了这份实验报告的副本。
申明人(签名):
实验报告评语与评分:
评阅老师签名:
一、实验名称:聚类分析(K均值、K中心点)
二、实验日期:2017年10月12日
三、实验目的:
(1)熟悉和巩固数据分析中的聚类划分的方法;
(2)能够通过距离相似度计算理解聚类分析中的K-均值算法和K-最近邻算法;
(3)能够通过聚类工具,对数据样本完成聚类后讨论类别划分的特征
四、实验用的仪器和材料:
硬件:PC电脑一台;
配置:内存,2G及以上硬盘250G及以上
软件环境:操作系统windows server 2003
数据库环境:Microsoft SQL SERVER 2005
五、实验内容:
1)熟练掌握课件PPT中的K均值和K最近邻实例的推演过程。
2)完成课本P217 第14题。
3)完成课本P217第20题。
(4)假设空间中的五个点{A、B、C、D、E},如下图所示。
各点之间的距离关系如下表所示,根据所给的数据对其运行k-medoids算法实现划分聚类(设k=2)。
样本点A B C D E
A01223
B10243
C22015
D24103
E33530
初始近邻点定为 A、B
(5)采用数据挖掘工具平台的聚类分析功能,完成一个任意样本的聚类,并根据所学评价该聚类的特征和优劣。
(参考书本P215)聚类验证。