八爪鱼采集器正则表达式入门教程
- 格式:docx
- 大小:29.99 KB
- 文档页数:4


xpath入门教程以及定位元素实例本文用来讲解xpath的入门基础,本教材是xpath入门2,建议大家从入门1教程开始学习Xpath的教程适合对八爪鱼已经有一些基础的用户来学习。
示例地址/tutorial?type=0&page=0&tag=%E8%BF%9B%E9%98%B6&version=otherXpath:是一种路径查询语言,简单的说就是利用一个路径表达式找到我们需要的数据位置。
Html:超文本标记语言,是用来描述网页的一种语言。
主要用于控制数据的显示和外观。
HTML文档也被称为网页。
Xpath专用于xml中沿着路径查找数据用的,但是八爪鱼采集器内部有一套针对Html的Xpath引擎,使得直接用Xpath就能精准的查找定位网页里面的数据。
xpath入门2-图1例如下图通过火狐的firebug、firepath查看网页源码。
查看方法参考“xpath入门1”教程xpath入门2-图2完整的HTML文件至少包括<HTML>标签、<HEAD>标签、<TITLE>标签和<BODY>标签,并且这些标签都是成对出现的,开头标签为<>,结束标签为</>,在这两个标签之间添加内容。
通过这些标签中的相关属性可以设置页面的背景色、背景图像等。
Html标签作为开始和结束的标记由尖括号包围的关键词,比如 <html>标签对中,第一个标签是开始标签,第二个标签是结束标签元素HTML的网页内容是由元素组成的,从开始标签到结束标签的所有代码。
元素的开始和结束都使用标签作为开始和结束的标记节点所有事物都是节点整个文档是一个文档节点每个 HTML 元素是元素节点HTML元素内的文本是文本节点每个 HTML 属性是属性节点注释是注释节点Html常见标签<a></a> 定义超链接,用于从一张页面链接到另一张页面<h1></h1> 文本标题标签,最大的标签。

八爪鱼数据采集月成交笔数教程
八爪鱼是一款数据采集工具,可以用于自动化地采集网站上的各种数据。
下面是使用八爪鱼进行月成交笔数数据采集的教程:
步骤1:打开八爪鱼软件,并点击新建任务来创建一个新的数据采集任务。
步骤2:在任务设置页面,填写任务的基本信息,例如任务名称和网站的URL 地址。
步骤3:在页面内容设置页面,选择需要采集的数据所在的页面,并使用八爪鱼提供的选择器工具来选择数据所在的HTML元素。
步骤4:在数据字段设置页面,给数据字段命名并设置字段的提取规则。
例如,要提取月成交笔数,可以使用正则表达式或者XPath规则来匹配对应的数据。
步骤5:在数据导出设置页面,选择导出数据的格式和保存路径。
八爪鱼支持导出为Excel、CSV等格式。
步骤6:点击保存并运行任务,等待八爪鱼自动采集数据。
可以选择定时运行任务或者手动运行任务。
通过以上步骤,就可以使用八爪鱼进行月成交笔数数据采集。
根据实际情况,可
能需要进行一些调试和优化,以确保能够正确地采集到目标数据。
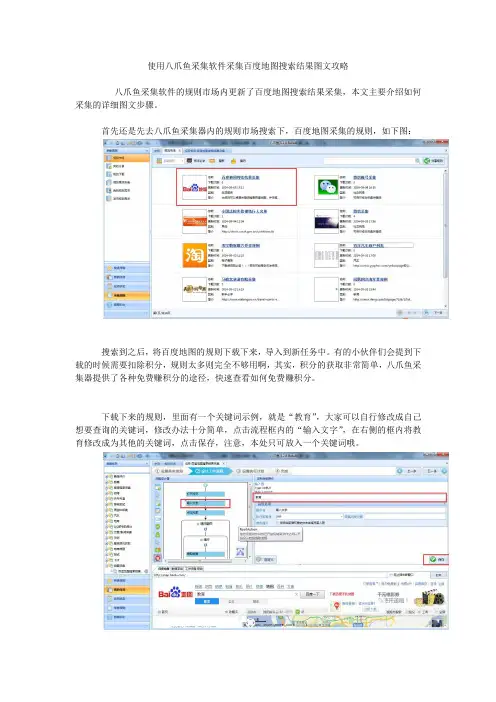
使用八爪鱼采集软件采集百度地图搜索结果图文攻略
八爪鱼采集软件的规则市场内更新了百度地图搜索结果采集,本文主要介绍如何采集的详细图文步骤。
首先还是先去八爪鱼采集器内的规则市场搜索下,百度地图采集的规则,如下图:
搜索到之后,将百度地图的规则下载下来,导入到新任务中。
有的小伙伴们会提到下载的时候需要扣除积分,规则太多则完全不够用啊,其实,积分的获取非常简单,八爪鱼采集器提供了各种免费赚积分的途径,快速查看如何免费赚积分。
下载下来的规则,里面有一个关键词示例,就是“教育”,大家可以自行修改成自己想要查询的关键词,修改办法十分简单,点击流程框内的“输入文字”,在右侧的框内将教育修改成为其他的关键词,点击保存,注意,本处只可放入一个关键词哦。
由于这个地图页面有防采集措施,所以大家就一个关键词一个关键词的采集比较好,建议使用云采集会更有效的突破防采集哦!如果要多个关键词一起修改,则可按下图设置关键词循环。
最后,我们就来一起看下采集的成果吧!采集完毕后可以根据自己的需要将数据保存为EXCEL、TXT、HTML、数据库等多种格式哦。
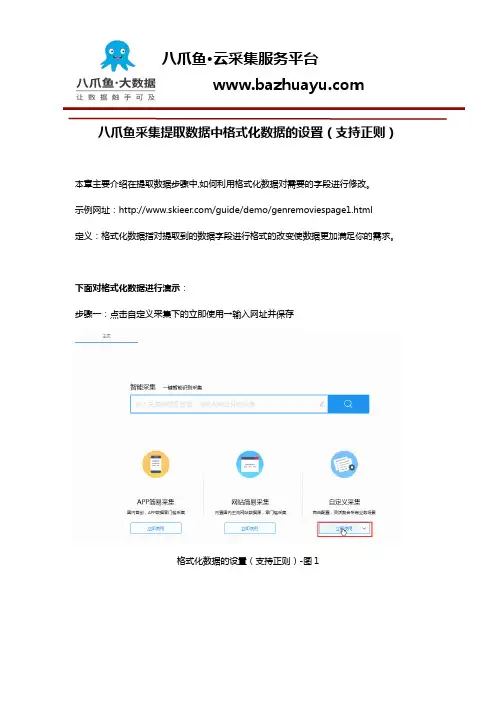
八爪鱼采集提取数据中格式化数据的设置(支持正则)本章主要介绍在提取数据步骤中,如何利用格式化数据对需要的字段进行修改。
示例网址:/guide/demo/genremoviespage1.html定义:格式化数据指对提取到的数据字段进行格式的改变使数据更加满足你的需求。
下面对格式化数据进行演示:步骤一:点击自定义采集下的立即使用→输入网址并保存格式化数据的设置(支持正则)-图1格式化数据的设置(支持正则)-图2步骤二:点击采集位置→循环采集元素→补充并修改提取元素步骤格式化数据的设置(支持正则)-图3格式化数据的设置(支持正则)-图4说明:循环采集元素会采集所有信息,。
我们在补充并修改提取元素步骤,进行了删除第一个字段操作,同时添加了我们需要的正确字段。
步骤三:格式化数据选中要修改的字段→点击高级选项中自定义数据字段(如下图)→格式化数据→添加步骤格式化数据的设置(支持正则)-图5格式化数据的设置(支持正则)-图6格式化数据的设置(支持正则)-图7使用格式化数据的统一步骤,打开格式化数据并点击添加步骤后,可以看到有多个选项,下面我们分别对其进行讲述。
格式化数据的设置(支持正则)-图8(1)替换格式化数据的设置(支持正则)-图9格式化数据的设置(支持正则)-图10说明:替换是将字段替换为其他字段的步骤,例如示例中将肖申克的救赎中的救赎替换为月亮,在替换下输入需要替换的内容,在为下输入需要替换的内容,即将XX替换为XX。
设置完成可以点击下方的计算验证是否替换。
除了文字、数字、符号外,替换还可以替换空格、换行符等内容,假如只输入替换内容不输入替换为的内容,则形成替换的删除作用,将替换中的内容进行删除。
(2)正则表达式替换格式化数据的设置(支持正则)-图11格式化数据的设置(支持正则)-图12格式化数据的设置(支持正则)-图13格式化数据的设置(支持正则)-图14格式化数据的设置(支持正则)-图15说明:正则表达式替换是利用正则表达式匹配字段并进行替换。


xpath入门学习(以提取网页中公司名和地址为例)本文用来讲解xpath的入门基础,适合对八爪鱼已经有一些基础的用户来学习。
文中示例地址为:/qiye2309554//qiye2275810/提取两个网页中的公司名称和地址字段。
Xml和Html之间既有相似之处,又有很大区别。
Xml包含数据和对数据的描述,主要用来交换数据。
Html也包含了数据和对数据的描述,但只是针对描述网页这种用途,Html结构看起来和Xml类似,但并不严格遵循Xml标准,可以看做不标准的Xml。
Xpath是专门针对Xml设计的,在复杂结构化数据中查找信息的语言,而我们的网页实质上是Html的文档,那如何对网页执行Xpath查询呢?八爪鱼采集器内部有一套针对Html 的Xpath引擎,使得直接用Xpath就能精准的查找定位网页里面的数据。
给大家介绍一个类似的工具,就是火狐浏览器里面firebug和firepath插件。
首先在电脑上先安装火狐浏览器,然后打开火狐浏览器右上角的打开菜单按钮,选择添加组件。
Xpath入门1-图1:附件组件在弹出的对话框中搜索firebug组件,搜索出来之后选择安装。
Xpath入门1-图2:安装firebug安装成功之后同样的方式搜索firepath进行安装。
小贴士:安装成功之后,浏览器需要重启一下才能完全安装成功。
重新打开浏览器中,可以看到多了一个昆虫按钮,代表安装成功。
在浏览器中打开一个网页,再点击浏览器中的firebug按钮,就弹出了可以用xpath的firepath工具。
Xpath入门1-图3:firepath工具按照下面的操作可以找到数据的精确位置。
点击firepath工具中“查看页面中的元素”按钮→选择网页中要提取的字段→可以看到firepath工具中显示出了xpath路径 Xpath入门1-图4:“查看页面中的元素”按钮Xpath入门1-图5:字段与其对应的xpath路径这种定位方式在八爪鱼采集器里面也是通用的,例如:步骤1 点击新建任务→自定义采集,进入到任务配置页面:然后输入要采集的两个网址→保存网址,系统会进入到流程设计页面并自动打开前面输入的网址。

octopus 在线正则表达式Octopus是一种在线正则表达式工具,它提供了强大的功能和便捷的操作界面,用于处理文本匹配和替换的需求。
在这篇文章中,我们将探讨Octopus的特点、使用方法以及一些实用的技巧。
Octopus的主要特点之一是它的在线操作性。
无需下载或安装任何软件,用户可以直接在网页上使用Octopus进行正则表达式的编写和测试。
这对于初学者来说非常方便,也节省了学习和使用的成本。
在使用Octopus时,我们首先需要了解正则表达式的基本语法和规则。
正则表达式是一种用于描述文本模式的工具,可以用来查找、匹配和替换符合特定规则的字符串。
它由一系列字符和特殊符号组成,用于定义匹配规则。
在Octopus中,我们可以使用各种元字符和操作符来构建正则表达式。
元字符是一些特殊的字符,代表某种特定的意义。
例如,"."代表匹配任意字符,"\d"代表匹配任意数字。
操作符则用于组合元字符,形成更复杂的匹配规则。
除了基本的元字符和操作符外,Octopus还提供了一些高级的功能,如捕获组、反向引用和零宽断言等。
这些功能可以帮助我们更精确地匹配和提取文本。
例如,我们可以使用捕获组来提取网页中的链接,或使用反向引用来查找重复出现的单词。
在实际应用中,Octopus可以帮助我们解决许多常见的文本处理问题。
例如,我们可以使用正则表达式在一篇文章中查找特定的关键词,并将其替换为其他词汇。
我们也可以使用正则表达式来验证用户输入的邮箱地址或电话号码是否合法。
在使用Octopus时,我们需要注意一些常见的问题和注意事项。
首先,正则表达式是区分大小写的,所以在编写表达式时需要注意大小写的一致性。
其次,正则表达式的性能可能会受到文本长度和复杂度的影响,所以在处理大量文本时需要注意效率的问题。
Octopus还提供了一些实用的技巧和工具,可以帮助我们更好地使用正则表达式。
例如,我们可以使用预定义的字符类来匹配特定的字符类型,如数字、字母或空格。

使用八爪鱼的数据采集流程1. 简介八爪鱼是一款强大的数据采集工具,可以帮助用户自动化获取网页上的信息,并将其保存为结构化的数据。
用户只需设置好采集规则,八爪鱼就能自动按照规则从网页中提取所需数据,并保存到指定的文件或数据库中。
2. 安装八爪鱼要使用八爪鱼进行数据采集,首先需要将其安装到您的电脑上。
八爪鱼提供了Windows和Mac版本的安装包,您可以根据自己的操作系统下载对应的安装包,并按照提示完成安装。
3. 创建新的采集项目在安装完成并启动八爪鱼后,您可以看到一个简洁的用户界面。
点击左上角的“新建项目”按钮,输入项目名称并选择适当的项目分类。
4. 设置采集规则在创建新的项目后,您需要设置采集规则来告诉八爪鱼从哪些网页上抓取数据以及如何提取这些数据。
八爪鱼提供了多种方式来设置采集规则,包括手动选择页面元素、选择页面区域、使用正则表达式等。
您可以根据具体的需求选择合适的方式进行设置。
5. 测试采集规则在设置完采集规则后,您可以通过点击右上角的“测试规则”按钮来测试采集规则是否正确。
八爪鱼会自动打开一个内置浏览器,并加载您指定的测试网页。
您可以在浏览器中查看提取到的数据,并验证数据的准确性。
6. 开始数据采集当您确认采集规则设置无误后,点击界面底部的“开始采集”按钮,八爪鱼就会自动按照规则开始抓取数据。
您可以观察采集任务的进度和状态,并在任务完成后查看采集到的数据。
7. 导出数据八爪鱼支持将采集到的数据导出为多种格式,包括Excel、CSV、JSON、MySQL 等。
您可以根据需要选择合适的导出格式,并设置相应的选项,然后点击“导出”按钮即可将数据保存到指定的文件或数据库中。
8. 自动化采集除了手动运行采集任务,八爪鱼还提供了自动化采集的功能。
您可以根据自己的需求,设置定时任务来自动运行采集任务,八爪鱼会根据您设定的时间间隔自动抓取数据,并保存到指定的文件或数据库中。
9. 其他功能除了基本的数据采集功能,八爪鱼还提供了一些其他强大的功能,如验证码识别、登录支持、动态网页采集等。

八爪鱼爬虫采集方法网页爬虫是一个比较热门的网络词,因为大数据时代,各行各业的从业人员都需要大量的数据信息,通过分析这类数据来优化升级自己的产品,从而满足所有消费者的需求,从而更好地抢占市场。
目前市面上比较好用的爬虫工具首推八爪鱼采集器,所以今天就教大家八爪鱼爬虫工具的使用方法,让你轻松get网络爬虫。
文章内示例网址为:/guide/demo/genremoviespage1.html自定义模式采集步骤:步骤1:首先打开八爪鱼采集器→找到自定义采集→点击立即使用自定义模式-图1步骤2:输入网址→设置翻页循环→设置字段提取→修改字段名→对规则进行手动检查→选择采集类型启动采集自定义模式-图2:输入网址自定义模式-图3:设置翻页循环自定义模式-图4:创建循环列表自定义模式-图5:提取字段自定义模式-图6:修改字段名注意点:1.设置翻页循环:观察网页底部有没有翻页图标,如果有并且需要翻页则点击翻页图标,操作提示中循环点击下一页表示循环翻页,可以在循环中设置翻页次数,设置几次则采集网页最新内容几页。
采集该链接的文本选项则会出现提取数据步骤,提取下一页对应的文本;点击采集该链接地址步骤选项会出现提取数据步骤,提取当前字段对应的链接地址。
点击该链接则会出现点击元素步骤,点击该元素一次。
2.设置字段提取:先对网页内容进行分区块,思路为循环各区块,再从循环到的区块中提取每个字段内容,所以设置时先点击2-3各区块,八爪鱼会自动选中剩余所有区块,点击采集以下元素文本会出现循环提取数据步骤,实现对区块的循环采集,但是此时每个区块循环时只会将区块内文字合并为一条提取,此时我们删除该字段并手动添加需要提取的所有字段;点击循环点击每个元素则会出现循环点击元素步骤,对每个区块进行一次点击,该示例中区块点击没有效果,所以该示例中循环点击不存在效果。
如果选择错误,或者出现的内容列表不是你需要的,可以在操作提示中点击区块后的垃圾桶图标进行删除操作,或者点击取消选择,重新设置。
如何利用八爪鱼爬虫抓取数据很多人都听说过八爪鱼采集器,知道它强大的网页数据采集功能,以及简单的操作步骤。
但是有的同学担心不懂代码,不会使用八爪鱼爬虫做抓取。
作为同样技术水平为0的文科生小编,看了教程后使用起来666,友好又高效,向你保证不会技术也可以轻松采集。
要系统的学习八爪鱼,完成从入门到采集大神的历练,需要经过以下几个阶段:一、理解八爪鱼工作的核心原理二、了解八爪鱼入门词汇(有一个初步印象)三、采集基本流程教程(明白整体架构)四、细致学习功能点教程+实战案例教程(开始实际操作)一、理解八爪鱼工作的核心原理八爪鱼采集的核心原理是:模拟人浏览网页,复制数据的行为,通过记录和模拟人的一系列上网行为,代替人眼浏览网页,代替人手工复制网页数据,从而实现自动化从网页采集数据,然后通过不断重复一系列设定的动作流程,实现全自动采集大量数据。
理解核心原理是十分必要的,只有理解了工作原理,再结合实际操作仔细体会,才会取得事半功倍的效果。
二、了解八爪鱼入门词汇(有一个初步印象)要掌握的入门词汇主要有:积分、规则、云加速、云优先、URL、单机采集、云采集、定时采集、URL循环、自动导出、COOKIE、XPATH、HTML八爪鱼入门词汇详细资料,请点击以下链接查看:/doc-wf三、了解采集基本流程教程(明白整体架构)八爪鱼在配置规则、采集数据的时候,主要会经过以下几个步骤:打开网页、点击元素、输入文本、提取数据、循环、下翻下拉列表、条件分支、鼠标悬停。
针对这些步骤,八爪鱼内置了很多高级选项。
在针对具体网页的采集过程中,网页结构、网页情况是不一样的。
我们需要观察网页结构,相应地在八爪鱼中进行高级选项的设置。
那么,了解八爪鱼采集基本流程,是十分必要的。
八爪鱼采集基本流程详解,请点击以下链接查看:/doc-wf四、细致学习功能点教程+实战案例教程(开始实际操作)经过前两步,我们掌握了入门词汇,知道经常出现在八爪鱼中的积分、规则、云加速、云优先、URL、COOKIE、XPATH等词是什么意思;我们对八爪鱼的基本采集步骤有了清晰的把控,明白有8大步骤和若干高级选项需要设置。
数据分析实战(8-10)-数据采集简介⼋⽖鱼采集⼯具python爬⾍08 数据采集:如何⾃动化采集数据?重点介绍爬⾍做抓取1.Python 爬⾍1)使⽤ Requests 爬取内容。
我们可以使⽤ Requests 库来抓取⽹页信息。
Requests 库可以说是 Python 爬⾍的利器,也就是 Python 的HTTP 库,通过这个库爬取⽹页中的数据,⾮常⽅便,可以帮我们节约⼤量的时间。
2)使⽤ XPath 解析内容。
XPath 是 XML Path 的缩写,也就是 XML 路径语⾔。
它是⼀种⽤来确定 XML ⽂档中某部分位置的语⾔,在开发中经常⽤来当作⼩型查询语⾔。
XPath 可以通过元素和属性进⾏位置索引。
3)使⽤ Pandas 保存数据。
Pandas 是让数据分析⼯作变得更加简单的⾼级数据结构,我们可以⽤ Pandas 保存爬取的数据。
最后通过Pandas 再写⼊到 XLS 或者 MySQL 等数据库中。
Requests、XPath、Pandas 是 Python 的三个利器。
当然做 Python 爬⾍还有很多利器,⽐如 Selenium,PhantomJS,或者⽤ Puppeteer 这种⽆头模式。
##这⾥可以实践⼀下2.抓取⼯具1)2)3)集搜客09 数据采集:如何⽤⼋⽖鱼采集微博上的“D&G”评论⼋⽖鱼傻⽠软件,操作⾮常⽅便,⽐python爬⾍更容易上⼿⽤10 Python爬⾍:如何⾃动化下载王祖贤海报?python爬⾍笔记中介绍了⽤urlretrieve可以下载xpath的⾮结构化数据,参考:这篇教程是从JSON和Xpath来介绍补充如何使⽤ JSON 数据⾃动下载王祖贤的海报{"images":[{"src": …, "author": …, "url":…, "id": …, "title": …, "width":…, "height":…},…{"src": …, "author": …, "url":…, "id": …, "title": …, "width":…, "height":…}],"total":26069,"limit":20,"more":true}不如先⽤第⼀个页⾯上⼿来个下载⼩例⼦:# -*- coding: utf-8 -*import requestsimport jsonquery = '王祖贤'url = 'https:///j/search_photo?q=' + 'query' + '&limit=20&start=0'headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/69.0.3497.81 Safari/537.36 Maxthon/5.3.8.2000 "}html = requests.get(url, headers=headers).text # 得到返回结果,是⼀个json格式response = json.loads(html, encoding='utf-8') # 将 JSON 格式转换成 Python 对象i=0for image in response['images']:print(i)img_src = image['src'] #image是⼀个dictpic = requests.get(img_src, timeout=10) #这时候image其实是动态页⾯ XHR 数据。
八爪鱼采集器正则表达式入门教程
正则表达式(Regular Expression),按英文直译是“规范化表达”,其作用是将复杂模糊的源数据通过正则表达式转化为简单直观的目标数据。
例如:
“150ABCD”
“一百五ABCD”
“One hundred and fiftyABCD”
分析思考过程:
以上字符串中,我们的源数据数据分别为:““150ABCD”、“一百五ABCD”、“One hundred and fiftyABCD”
假设我们要提取目标数据为:字符串中以数字开头的数据
那么我们约束条件为:只取字符串中以数字开头的源数据
将此约束条件转化为正则表达式为:[0-9](.+)\b
其中,[0-9]的语义为开头1位为0-9开头,中间间隔以通配符“.”代替,(.+)语义为字符串长度不做限定,\b的语义为,匹配一个边界。
正则后的目标数据:“150ABCD”
通过这个简单例子,我们大致了解到了为什么要用正则与正则所能实现的效果,讲通俗点就是,正则只是将我们的意愿(提取字符串中以数字开头的数据)以表达式的形式展现出来([0-9](.+)\b),并最终通过表达式匹配到所需要的目标数据(“150ABCD”),所以灵活运用正则,可以通过简单的方法实现强大的功能。
为什么要在八爪鱼中使用正则?
在八爪鱼采集数据过程中,受限于网页HTML结构的原因,部分目标数据并不能单独提取出来,这时需要简单的搜索与替换操作来提取与预期搜索结果匹配的确切文本,除此之外,对数据要求精准规范的用户,还能通过正则表达式测试所提取数据字符串的模式、替换文本、基于匹配模式从字符串中提取子字符串等操作。
例如:
匹配字符串内模式:
1.查看字符串是否出现电话号码模式
2.查看字符串是否出现网址URL模式
替换文本:
1.用正则表达式识别字符中特定文本
2.用正则表达式完全删除该文本或用其他文本替换它
基于匹配模式从字符串中提取子串
1.用于查找字符串文本内特定文本
相关采集教程:
八爪鱼数据爬取入门基础操作
/tutorial/xsksrm/rmjccz
八爪鱼网站抓取入门功能介绍
/tutorial/xsksrm/rmgnjs
八爪鱼爬虫软件功能使用教程/tutorial/gnd 循环翻页爬取网页数据/tutorial/gnd/xunhuan ajax网页数据抓取/tutorial/gnd/ajaxlabel
特殊翻页操作/tutorial/gnd/teshufanye
模拟登录并识别验证码抓取数据
/tutorial/gnd/dlyzm
八爪鱼——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。