RegexBuddy工具的使用教程
- 格式:doc
- 大小:834.00 KB
- 文档页数:11

machinebuilder使用手册摘要:1.介绍Lua 正则表达式2.详述Lua 正则表达式结尾多个规则的匹配方法3.提供实际案例演示正文:Lua 是一种轻量级的脚本语言,广泛应用于游戏开发、Web 开发等领域。
在Lua 中,正则表达式是一种强大的文本处理工具。
本篇文章将详细介绍如何在Lua 中使用正则表达式匹配结尾多个规则。
首先简要回顾一下Lua 正则表达式的基本语法。
在Lua 中,正则表达式使用`pattern`库,可以通过`RegExp`模块进行操作。
基本的正则表达式匹配方法如下:```lualocal re = RegExp(pattern)local result = re:match(string)```其中`pattern`为正则表达式,`string`为需要匹配的文本。
`RegExp`模块提供了一系列正则表达式相关的函数,如`match`、`gmatch`、`sub`等。
在Lua 中,要匹配结尾多个规则,可以使用以下方法:1.使用量词:在正则表达式中,可以使用量词`*`、`+`、`?`等来匹配多个字符。
例如,要匹配以“abc”结尾的多个字符串,可以使用如下正则表达式:```lualocal re = RegExp(".*abc$")```这里`.*`表示匹配任意数量的任意字符,`abc$`表示匹配以“abc”结尾的字符串。
2.使用分组:在正则表达式中,可以使用圆括号`()`进行分组。
分组可以提高正则表达式的可读性,也可以用于提取匹配结果。
例如,要匹配以“abc”结尾的多个字符串,并提取前面的部分,可以使用如下正则表达式:```lualocal re = RegExp("([^abc]+)abc$")```这里`[^abc]+`表示匹配除“abc”以外的任意字符,`()`表示将这部分内容作为一个整体进行匹配。
下面通过一个实际案例演示Lua 正则表达式结尾多个规则的匹配方法:假设有一个文本列表,包含以下内容:```applebananaapple-orangebanana-grape```我们想要筛选出以“apple”和“banana”结尾的文本。

软件测试中的安全测试方法与工具推荐一、引言在当今数字化时代,软件应用广泛且日益复杂,随之而来的是安全风险的增加。
为了保障软件的安全性,软件测试中的安全测试显得尤为重要。
本文将介绍一些常用的安全测试方法,并推荐几款常用的安全测试工具。
二、安全测试方法1. 静态分析静态分析是一种通过在不运行软件的情况下,对源代码或二进制文件进行全面检查以发现潜在安全漏洞的方法。
静态分析可以帮助开发人员及时发现代码中隐藏的安全问题,并进行修复。
常用的静态分析工具有Coverity、Fortify等。
2. 动态分析动态分析是通过在运行状态下模拟各种攻击场景,检测软件对安全漏洞的防御能力。
动态分析可以模拟各种攻击行为,如SQL注入、XSS攻击等,帮助测试人员发现软件系统的弱点和薄弱环节。
常用的动态分析工具有Burp Suite、OWASP ZAP等。
3. 渗透测试渗透测试是通过模拟真实攻击者的攻击手段和技术,试图找到软件系统的安全漏洞和弱点。
渗透测试是一种主动的安全测试方法,能够全面评估软件系统在真实攻击环境下的安全性。
常用的渗透测试工具有Metasploit、Nessus等。
4. 威胁建模威胁建模是一种通过分析系统中各个组件及其之间的关系,确定系统面临的威胁和潜在攻击路径的方法。
威胁建模可以帮助测试人员有针对性地进行安全测试,并设计相应的安全对策。
常用的威胁建模工具有Microsoft Threat Modeling Tool、OWASP Threat Dragon等。
5. 正则表达式分析正则表达式分析是一种通过对软件代码中的正则表达式进行分析,发现其中的安全风险的方法。
正则表达式分析可以帮助测试人员发现代码中可能存在的正则表达式注入、拒绝服务等安全问题。
常用的正则表达式分析工具有RegexBuddy、REXPaint等。
三、安全测试工具推荐1. Burp SuiteBurp Suite是一款功能强大的渗透测试工具,提供了拦截、请求编辑、漏洞扫描等多种功能。

RegExp(Regular Expression)是一种强大的文本处理工具,它可以用来匹配和处理字符串。
在不同的编程语言中,RegExp的使用方法有所不同,但其基本规则和语法大致相同。
在本文中,我将介绍RegExp 的基本使用规则,并通过一些实例来帮助读者更好地理解。
1.RegExp的基本概念RegExp是一种特殊的字符串,它用于描述一种字符串的模式,可以用来匹配符合该模式的字符串。
我们可以使用RegExp来匹配一个电流新箱位置区域的模式,或者匹配一个全球信息站的模式。
2.创建RegExp对象在大多数编程语言中,RegExp都是通过RegExp对象来表示的。
创建一个RegExp对象的方法通常是使用一个字符串来描述要匹配的模式。
在JavaScript中,我们可以使用以下方式来创建一个RegExp对象:```javascriptvar pattern = /ab+c/;```这里的“ab+c”就是我们想要匹配的模式,它表示一个或多个字母a后面跟着一个或多个字母b,最后跟着字母c。
3.使用RegExp匹配字符串一旦创建了一个RegExp对象,我们就可以使用它来匹配字符串了。
在大多数编程语言中,可以使用RegExp对象的test()方法或者match()方法来进行匹配。
在JavaScript中,我们可以使用test()方法来测试一个字符串是否符合指定的模式:```javascriptvar str = "abbbc";var pattern = /ab+c/;if (pattern.test(str)) {console.log("The string matches the pattern.");} else {console.log("The string does not match the pattern.");}```在上面的例子中,字符串“abbbc”符合模式“ab+c”,所以会输出"The string matches the pattern."。

regexp使用方法正则表达式(regular expression)是一种用来匹配和处理文本的强大工具。
它可以用来查找、提取、替换和验证文本中的特定模式。
无论是在编程语言中,还是在文本编辑器中,正则表达式都被广泛使用。
本文将介绍如何使用正则表达式进行文本匹配、提取和替换。
一、正则表达式的基本概念正则表达式由字符和元字符组成。
字符可以是任何字母、数字或特殊字符,而元字符则具有特殊的含义。
一些常见的元字符包括:.(点号):匹配任意字符,除了换行符。
*(星号):匹配前一个字符的零个或多个实例。
+(加号):匹配前一个字符的一个或多个实例。
(问号):匹配前一个字符的零个或一个实例。
\(反斜杠):转义字符,用于匹配特殊字符。
[ ](方括号):匹配括号内的任意一个字符。
^(脱字符):匹配行的开头。
$(美元符号):匹配行的结尾。
二、正则表达式的语法规则正则表达式的语法规则包括元字符和限定符的组合。
元字符用于匹配特定的字符,而限定符则用于指定匹配字符出现的次数。
一些常见的限定符包括:{n}:匹配前一个字符的n个实例。
{n,}:匹配前一个字符的至少n个实例。
{n,m}:匹配前一个字符的至少n个、最多m个实例。
三、使用正则表达式进行文本匹配在编程语言中,可以使用正则表达式的库函数或方法来进行文本匹配。
以下是一个示例:```pythonimport retext = "Hello, World!"pattern = r"Hello"result = re.match(pattern, text)if result:print("匹配成功")else:print("匹配失败")```在上述示例中,使用re模块的match方法进行文本匹配。
如果匹配成功,则返回匹配对象;否则返回None。
四、使用正则表达式进行文本提取正则表达式不仅可以用来匹配文本,还可以用来提取文本中的特定部分。

java日志解析正则
Java日志解析正则表达式是一种强大的工具,可以帮助开发人员在日
志文件中快速定位错误、问题和异常。
正则表达式是一种强大的文本
处理工具,可以帮助开发人员轻松地在大量文本数据中查找和解析信息。
Java日志通常是以文本文件的形式记录的,其格式可以是任何一种。
例如,可以使用普通文本文件、XML文件或JSON格式的日志文件。
不管使用何种格式,使用正则表达式都能够帮助开发人员快速、准确
地解析日志文件,找到所需的信息。
在Java中,正则表达式是通过java.util.regex包中的类来处理的。
这个包提供了多个类和方法,可以快速、简便地创建和处理正则表达式。
其中,使用Pattern和Matcher两个类是最常见、最常用的方法之一。
在使用正则表达式解析Java日志时,开发人员首先需要了解日志文件的格式和结构,以便能够正确地编写正则表达式。
其次,开发人员需
要使用正则表达式解析工具,例如RegexBuddy、Regexplorer或在
线工具等。
最后,开发人员需要学会测试和调试正则表达式,以确保它们能够正
确地解析日志文件,并且能够在发现问题时进行修改和优化。
总之,Java日志解析正则表达式是一种非常有用的技术,可以帮助开发人员快速、准确地解析日志文件,发现隐藏的问题和异常。
使用正则表达式的好处不仅可以提高代码的效率和可维护性,也可以有效地减少错误和异常的出现。
因此,学习和使用正则表达式是每个Java开发人员都应该掌握的一项技能。

Java的regexHelper.trick方法简介在编程中,正则表达式是一种强大且广泛应用于字符串处理的工具。
J a va作为一种常用的编程语言,提供了丰富的正则表达式处理方法。
其中,re ge xH el pe r.t r ic k方法是一种非常实用的方法,它可以帮助开发者快速解决一些常见的正则表达式问题。
使用方式r e ge xH el pe r.tr ick方法是Ja va中reg e xH el pe r类库提供的一个方法,可以通过该方法来进行正则表达式的匹配和替换操作。
使用该方法时,我们需要先创建一个re ge xH el pe r对象,然后调用其tr i ck方法来进行操作。
```j av aR e ge xH el pe rr eg ex=n ew Re ge xH el pe r();S t ri ng re su lt=r ege x.t ri ck(p at te rn,i np ut);```在上述代码中,p att e rn表示要匹配的正则表达式模式,in p ut表示待匹配的字符串。
调用t ri c k方法后,将返回匹配结果的字符串。
功能特点1.快速匹配r e ge xH el pe r.tr ick方法可以通过传入正则表达式模式和待匹配的字符串,快速匹配出符合要求的字符串。
它支持常见的正则表达式语法,并且对于较复杂的匹配需求也能提供灵活的解决方案。
```j av aS t ri ng in pu t="H ell o Wo rl d";S t ri ng pa tt er n="He l lo\\s\\w+";R e ge xH el pe rr eg ex=n ew Re ge xH el pe r();S t ri ng re su lt=r ege x.t ri ck(p at te rn,i np ut);```在上述代码中,p att e rn使用了"\s"来匹配空格,"\w+"来匹配一个或多个字母、数字或下划线。

c语言regex用法正则表达式是计算机科学领域中常用的一种文本匹配工具。
在C语言中,通过使用regex库,我们可以轻松地进行正则表达式的匹配和处理。
要使用regex库,首先需要在代码中引入相应的头文件,如下所示:```c#include <stdio.h>#include <regex.h>```接下来,我们可以通过regex_t结构体类型来创建一个正则表达式对象。
这个对象将用于存储编译后的正则表达式。
```cregex_t regex;```在使用正则表达式之前,我们需要将正则表达式字符串编译成可供使用的格式。
编译正则表达式的函数为regcomp,其原型如下:```cint regcomp(regex_t *restrict preg, const char *restrict pattern, int cflags);```其中,preg是正则表达式对象,pattern是待编译的正则表达式字符串,cflags是编译选项。
编译成功后,我们可以使用正则表达式进行匹配。
匹配函数为regexec,其原型如下:```cint regexec(const regex_t *restrict preg, const char *restrict string, size_t nmatch, regmatch_t pmatch[], int eflags);```其中,preg是编译后的正则表达式对象,string是待匹配的字符串,nmatch是匹配结果的最大数量,pmatch是用于存储匹配结果的数组,eflags是匹配选项。
正则表达式匹配完成后,我们可以通过遍历pmatch数组来获取匹配到的字符串及其在原始字符串中的位置。
最后,使用完正则表达式后,需要使用regfree函数释放正则表达式对象的内存。
以上是在C语言中使用regex库进行正则表达式匹配的基本步骤。
通过这些函数的灵活组合,我们可以实现各种复杂的文本匹配操作。
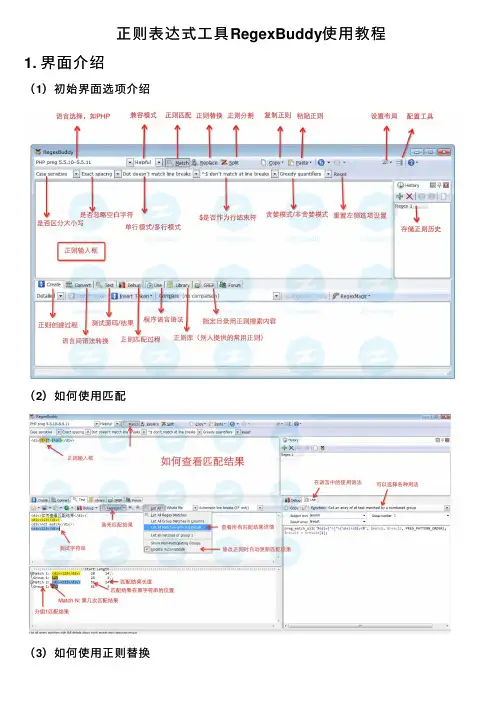
正则表达式⼯具RegexBuddy使⽤教程1. 界⾯介绍(1)初始界⾯选项介绍(2)如何使⽤匹配(3)如何使⽤正则替换(4)如何使⽤Debug2.界⾯菜单翻译Case sensitivity 区分⼤⼩写Case insensitive: Differences between uppercase and lowercase characters are ignored. cat matches CAT, Cat, or cAt or any other capitalization in addition to cat.不区分⼤⼩写:忽略⼤⼩写字符之间的差异。
cat匹配CAT, Cat,cAt或cat的其他任何⼤写字母.Case sensitive: Differences between uppercase and lowercase characters are significant. cat matches only cat.区分⼤⼩写:⼤⼩写字符之间的差异是显著的。
cat只匹配cat。
Free-spacing mode ⾃由间距模式Free-spacing: Unescaped spaces and line breaks in the regex are ignored so you can use them to format your regex to make it more readable. In most applications this mode also makes # the start of a comment that runs until the end of the line.⾃由间距:regex中未转义的空格和换⾏符被忽略,因此可以使⽤它们格式化正则表达式,使其更可读。
在⼤多数应⽤程序中,此模式还使#成为注释的开头,直到⾏的结尾。
Exact spacing: Unescaped spaces, line breaks, and # characters in the regex are treated as literal characters that the regex must match. 精确间距:正则表达式中未转义的空格、换⾏符和#字符被视为正则表达式必须匹配的⽂字字符。

c语言regex用法摘要:1.C 语言正则表达式简介2.C 语言中的regex 函数库3.使用regex 函数库进行正则表达式操作的步骤4.C 语言regex 示例正文:C 语言正则表达式是一种非常强大的文本处理工具,它可以让你在C 语言程序中进行复杂的文本匹配和替换操作。
C 语言中的正则表达式函数库是regex.h,你需要包含这个头文件才能在你的程序中使用正则表达式。
使用regex 函数库进行正则表达式操作的步骤一般包括以下几个步骤:1.包含头文件<regex.h>2.声明regex_t 变量3.初始化regex_t 变量4.使用regexec 函数进行匹配操作5.使用regfree 函数释放资源下面是一个简单的C 语言regex 示例,它演示了如何使用regex 函数库进行文本匹配和替换操作:```c#include <stdio.h>#include <regex.h>int main() {char text[] = "Hello, world!";regex_t regex;int ret;// 初始化regex_t 变量ret = regex_compile(text, ®ex, NULL);if (ret!= REG_OK) {printf("Error compiling regex: %s ", regex_error(®ex));return 1;}// 使用regexec 函数进行匹配操作ret = regex_match(text, ®ex, "o", 1);if (ret == REG_OK) {printf("Matched "o"");} else {printf("No match found");}// 使用regfree 函数释放资源regex_free(®ex);return 0;}```这个程序首先定义了一个字符串数组text,然后使用regex_compile 函数初始化regex_t 变量。

regexp对象的方法正则表达式(RegExp)是一种用于匹配字符串模式的工具。
它可以用于搜索、替换和验证字符串,为开发者提供了强大而灵活的文本处理能力。
在JavaScript中,我们可以使用RegExp对象的方法来操作和处理字符串。
1. test()方法:test()方法用于检测一个字符串是否匹配某个模式。
它返回一个布尔值,如果匹配成功则返回true,否则返回false。
例如,我们可以使用test()方法来检测一个字符串是否是一个有效的邮箱地址。
2. exec()方法:exec()方法用于在字符串中搜索指定的模式,并返回找到的第一个匹配结果。
它返回一个数组,包含匹配的子字符串及其相关信息。
我们可以使用exec()方法来提取字符串中的特定部分,或者获取匹配的位置和长度等信息。
3. match()方法:match()方法用于在字符串中搜索指定的模式,并返回所有匹配结果。
它返回一个数组,包含所有匹配的子字符串。
我们可以使用match()方法来提取字符串中的所有匹配部分,或者获取匹配的位置和长度等信息。
4. search()方法:search()方法用于在字符串中搜索指定的模式,并返回第一个匹配的位置。
它返回一个整数,表示匹配的起始位置。
我们可以使用search()方法来查找字符串中是否包含某个模式,以及它的位置。
5. replace()方法:replace()方法用于在字符串中搜索指定的模式,并将匹配的部分替换为指定的字符串。
它返回一个新的字符串,原字符串不会改变。
我们可以使用replace()方法来进行字符串的替换操作,例如将所有的空格替换为逗号。
6. split()方法:split()方法用于将一个字符串分割成多个子字符串,并返回一个数组。
它接受一个分隔符作为参数,用于指定分割的位置。
我们可以使用split()方法来将一个字符串按照指定的分隔符进行拆分,例如将一个以逗号分隔的字符串拆分为多个子字符串。

一、什么是filter和regexp1. filter是一种用于筛选数据的工具,它可以接受一个函数作为参数,对数据进行筛选。
在编程中,filter的常见用法是对数组进行筛选,只保留符合条件的元素。
2. regexp是正则表达式的缩写,它是一种用于匹配字符串的工具。
通过使用特定的模式来描述字符串的规则,可以实现对字符串的匹配和提取。
二、filter和regexp的结合使用1. 当我们需要对一组数据进行筛选,并且筛选条件是基于字符串的规则时,可以使用filter和regexp的结合使用。
这种方式可以实现更灵活、清晰的数据筛选和匹配。
2. 以在JavaScript中的使用为例,我们可以先使用filter方法对数组进行筛选,再利用regexp对字符串进行匹配。
这样可以高效地实现复杂的数据筛选和匹配操作。
三、filterregexp的常见用法1. 在处理文本数据时,我们经常需要对字符串进行筛选和匹配。
使用filterregexp可以简化这一过程,提高代码的可读性和效率。
2. 在处理用户输入时,我们通常需要对输入的内容进行校验,例如验证电流新箱位置区域、通联等。
filterregexp可以帮助我们轻松地实现这些校验逻辑。
3. 在处理日志或文本文件时,我们可能需要筛选出符合特定模式的内容,或者提取出需要的信息。
filterregexp可以帮助我们快速实现这些操作。
四、filterregexp的注意事项1. 在使用filterregexp时,需要注意正则表达式的编写和测试。
由于正则表达式本身具有一定的复杂性,编写和调试时需要谨慎对待,以避免出现意外的匹配结果。
2. 另外,需要注意filterregexp的性能问题。
复杂的正则表达式可能会对性能产生影响,因此在编写filterregexp时需要慎重考虑其性能开销。
3. 也需要考虑到不同编程语言或评台对filterregexp的支持程度和性能表现。
在选择filterregexp的使用时,需要综合考虑这些因素。
hbuilder中regexp的用法HBuilder中regexp的用法主要用于正则表达式的匹配和替换。
以下是一些常用的regexp方法:1. search: 匹配一个字符串中的第一个符合正则表达式的子串,并返回匹配结果。
例如:var str = "abc123";var result = str.search(/\d+/); // 返回3,表示匹配到的数字子串在字符串中的起始位置2. exec: 匹配一个字符串中的第一个符合正则表达式的子串,并返回一个数组,数组的第0个元素是匹配到的子串,后续元素是该子串的分组捕获内容。
例如:var str = "abc123";var pattern = /(\w+)(\d+)/;var result = pattern.exec(str); // 返回['abc123', 'abc', '123']3. test: 判断一个字符串是否符合正则表达式的匹配规则,返回布尔值。
例如:var pattern = /\d+/;var result = pattern.test("abc123"); // 返回true4. match: 在一个字符串中查找所有符合正则表达式的子串,并返回一个数组,数组的每个元素是一个匹配到的子串。
例如:var str = "abc123def456";var result = str.match(/\d+/g); // 返回['123', '456']5. replace: 在一个字符串中查找符合正则表达式的子串,并用指定的字符串替换找到的子串。
例如:var str = "abc123def456";var result = str.replace(/\d+/g, "666"); // 返回'abc666def666'以上是HBuilder中regexp的一些常用用法,不同的编程语言可能会有一些细微的差别,具体使用时需参考对应语言的文档和API。
正则表达式编写工具
有很多工具可以帮助您编写正则表达式,以下是一些常见的工具:
1.RegexBuddy:这是一个功能强大的正则表达式编辑器,提供了直观的界面
和大量的功能,可以帮助您轻松地编写和测试正则表达式。
2.Expresso:这是另一个流行的正则表达式编辑器,提供了丰富的正则表达
式语法和大量的例子,可以帮助您快速学习如何编写正则表达式。
3.Notepad++:这是一款文本编辑器,它内置了正则表达式支持,可以在编辑
文本时使用正则表达式进行搜索和替换。
4.Sublime Text:这是一款流行的文本编辑器,也支持正则表达式,提供了许
多插件和功能来帮助您更轻松地编写和测试正则表达式。
5.Jupyter Notebook:如果您是一名数据分析师或数据科学家,您可能会发现
Jupyter Notebook是一个很好的工具,它允许您在单元格中编写和测试正则表达式。
这些工具中的每一个都有自己的优点和缺点,您可以根据自己的需求选择最适合您的工具。
深入浅出之正则表达式(一)前言:半年前我对正则表达式产生了兴趣,在网上查找过不少资料,看过不少的教程,最后在使用一个正则表达式工具RegexBuddy时发现他的教程写的非常好,可以说是我目前见过最好的正则表达式教程。
于是一直想把他翻译过来。
这个愿望直到这个五一长假才得以实现,结果就有了这篇文章。
关于本文的名字,使用“深入浅出”似乎已经太俗。
但是通读原文以后,觉得只有用“深入浅出”才能准确的表达出该教程给我的感受,所以也就不能免俗了。
本文是Jan Goyvaerts为RegexBuddy写的教程的译文,版权归原作者所有,欢迎转载。
但是为了尊重原作者和译者的劳动,请注明出处!谢谢!1. 什么是正则表达式基本说来,正则表达式是一种用来描述一定数量文本的模式。
Regex代表Regular Express。
本文将用<<regex>>来表示一段具体的正则表达式。
一段文本就是最基本的模式,简单的匹配相同的文本。
2. 不同的正则表达式引擎正则表达式引擎是一种可以处理正则表达式的软件。
通常,引擎是更大的应用程序的一部分。
在软件世界,不同的正则表达式并不互相兼容。
本教程会集中讨论Perl 5 类型的引擎,因为这种引擎是应用最广泛的引擎。
同时我们也会提到一些和其他引擎的区别。
许多近代的引擎都很类似,但不完全一样。
例如.NET正则库,JDK正则包。
3. 文字符号最基本的正则表达式由单个文字符号组成。
如<<a>>,它将匹配字符串中第一次出现的字符“a”。
如对字符串“Jack is a boy”。
“J”后的“a”将被匹配。
而第二个“a”将不会被匹配。
正则表达式也可以匹配第二个“a”,这必须是你告诉正则表达式引擎从第一次匹配的地方开始搜索。
在文本编辑器中,你可以使用“查找下一个”。
在编程语言中,会有一个函数可以使你从前一次匹配的位置开始继续向后搜索。
类似的,<<cat>>会匹配“About cats and dogs”中的“cat”。
深入浅出之正则表达式(一)前言:半年前我对正则表达式产生了兴趣,在网上查找过不少资料,看过不少的教程,最后在使用一个正则表达式工具RegexBuddy时发现他的教程写的非常好,可以说是我目前见过最好的正则表达式教程。
于是一直想把他翻译过来。
这个愿望直到这个五一长假才得以实现,结果就有了这篇文章。
关于本文的名字,使用“深入浅出”似乎已经太俗。
但是通读原文以后,觉得只有用“深入浅出”才能准确的表达出该教程给我的感受,所以也就不能免俗了。
本文是Jan Goyvaerts为RegexBuddy写的教程的译文,版权归原作者所有,欢迎转载。
但是为了尊重原作者和译者的劳动,请注明出处!谢谢!1. 什么是正则表达式基本说来,正则表达式是一种用来描述一定数量文本的模式。
Regex代表Regular Express。
本文将用<<regex>>来表示一段具体的正则表达式。
一段文本就是最基本的模式,简单的匹配相同的文本。
2. 不同的正则表达式引擎正则表达式引擎是一种可以处理正则表达式的软件。
通常,引擎是更大的应用程序的一部分。
在软件世界,不同的正则表达式并不互相兼容。
本教程会集中讨论Perl 5 类型的引擎,因为这种引擎是应用最广泛的引擎。
同时我们也会提到一些和其他引擎的区别。
许多近代的引擎都很类似,但不完全一样。
例如.NET正则库,JDK正则包。
3. 文字符号最基本的正则表达式由单个文字符号组成。
如<<a>>,它将匹配字符串中第一次出现的字符“a”。
如对字符串“Jack is a boy”。
“J”后的“a”将被匹配。
而第二个“a”将不会被匹配。
正则表达式也可以匹配第二个“a”,这必须是你告诉正则表达式引擎从第一次匹配的地方开始搜索。
在文本编辑器中,你可以使用“查找下一个”。
在编程语言中,会有一个函数可以使你从前一次匹配的位置开始继续向后搜索。
类似的,<<cat>>会匹配“About cats and dogs”中的“cat”。
regexp方法标题:regexp方法(创建与此标题相符的正文并拓展)正文:regexp(regsub)方法是计算机科学中常用的字符串匹配方法之一。
它允许您在字符串中查找指定的模式,并返回匹配的行或字符。
regexp方法通常用于字符串处理、文本搜索和文件操作等领域。
在本文中,我们将介绍regexp方法的基本用法以及如何对其进行扩展。
首先,让我们了解regexp方法的基本原理。
regexp方法使用一个正则表达式来匹配字符串。
正则表达式是一个包含一系列字符和符号的组合,用于描述要匹配的字符串模式。
在匹配过程中,regexp方法会使用一个函数来解析正则表达式,并返回匹配的行或字符。
下面是一个使用regexp方法进行字符串匹配的示例:```pythonimport retext = "The quick brown fox jumps over the lazy dog."match = re.search(r"bbrownb", text)if match:print("Match found: ", match.group(0))else:print("No match found.")```在这个示例中,我们使用`re.search()`函数来查找字符串中的“brown”字符。
如果匹配成功,我们将得到“match found”的提示消息,并且匹配的行或字符将被打印出来。
如果匹配失败,我们将得到“No match found”的提示消息。
下面是一些可以扩展regexp方法的功能:1. 反向匹配:可以使用`re.search()`函数的`re.RSTART`和`re.REND`参数来反向查找匹配。
例如,`re.search()`函数的第一个参数是模式,第二个参数是模式的起点和终点,第三个参数是模式的起点和终点的反向索引。
2. 零宽断言:可以使用`re.match()`函数的`re.DOTALL`参数来匹配除了模式本身之外的任何字符。
RegexBuddy工具的使用教程(图文)12009-10-14 12:14一、什么是RegexBuddy使用了几天,个人感觉RegexBuddy 是学习正则表达式时的比较好的帮手。
它可以容易地建立你想要的正确的正则表达式。
清晰地推断他人所写的复杂的正则表达式。
它还可以用给出的实例字符串或文件快速地进行测试匹配,从而防止了在实际应用中出现错误。
RegexBuddy会在你的源代码中根据你所应用的特殊编程语言,自动生成带有正则表达式的代码段。
同时你也可以收集正则表达式到库中,以在未来重新使用。
二、获得RegexBuddy目前最新的版本是3.2.1(图2-1),于2008年12月9日发布的。
可以在/(RegexBuddy的官网)进行最新版本的下载和正版的购买。
图2-1 RegexBuddy的3.2.1版三、初步认识RegexBuddy安装比较简单(略过)首先,我们先对RegexBuddyg 产生一个整体的初步的认识,而不是设法解释所有的东西。
RegexBuddyg是相当易懂的容易的,所以我想经过简单大家应该能够基本正确地使用它。
默认情况下,RegexBuddy会在顶部显示正则表达式和上一次使用的历史,如图2-1。
图3-1 RegexBuddy的顶部底部会显示7个选项卡,分别是“Create”、“Test”、“Debug”、“Use”、“Library”、“GREP”、“Forum”(需要注册才能使用此功能),如图2-2。
图3-2 RegexBuddy的底部如果你的显示器较大,也可以分成两块平铺,你可以单击窗口最右上方工具栏上的“View”按键,在菜单中选择“Side by Side Layout”,这样你可以最大限度的同时查看两个窗口(图3-4)。
图3-3 Side by Side 样式四、开始建立第一个正则表达式接下来我们来用RegexBuddy来建立一个简单的正则表达式,以进一步加深对它的了解。
我们在文本域中直接输入:“^[0-9]*$”,也就是只允许有数字的正则表达式,然后在Test中输入下列测试文本: 90909、uiuiu、56464、787b、001、a65b (每输入一个换一行,文本内容任意更换)并选择“Line by line”,在此时界面如图4-1:图4-1 Example会发现匹配的字符串会被高亮显示,十分方便查找与正则表达式匹配的部分!RegexBuddy中“Create”与“Test”选项卡是你新建正则表达式时最有用的,一般我会按照之前选择的“Side by Side Layout”样式,这样就可以同时看见这两个面板。
在“Create”选项卡中,可以看到对这个正则表达式的解释的一个树状展示,其中的每一个节点对照着表达式中的一个元素块,在RegexBuddy中被称为一个“token”,我们点击其中的一个节点,就会在我们所输入的表达式的相应部分进行着重显示。
在分析他人所写的复杂的表达式的时候在这里查看会十分方便。
此选项卡中包含四个按键:1.“Explain Token”按键,打开RegexBuddy所自带的正则表达式指南,而且指向的正是你所选择的节点的正则表达式的语法规则的解释,十分方便!!2.“Insert Token”按键,会弹出一个下拉菜单(这个菜单会在以后介绍),其中包含了正则表达式里涉及的所有语法符号,可以进行选择,当然对于语法十分熟悉后,就可以不用这个菜单,直接在上面的文本输入区键入表达式了。
3.“Export”按键,可以将当前的表达式导出到文本文件、HTML文件或放入到剪贴板中。
4.“打印”按键,可以将当前的表达示打印出来。
俗话说,工欲善其事,必先利其器。
关于windows下的正则表达式工具,这里推荐的是:RegexBuddy和PowerGREP。
在linux下,也有好用的正则表达式工具,例如grep的兄弟们,只不过是都是基于命令行的。
而这两款windows下的小工具,其突出特点是可视化,允许尝试和预览,极大地方便了使用者。
RegexBuddy:网址是。
在编写正则式时,它提供可视化的支持、提示、调试方面的便利;在使用正则表达式时,它无私地将正则式转换为多种语言的字串,还提供了代码输出功能。
正则式助手,该称号名副其实。
基本界面正则式的基本功能无外乎搜索和替换。
在本文中,我们使用匹配Email的正则式,代码如下:view plaincopy to clipboardprint1.\b[A-Z0-9._%-]+@[A-Z0-9.-]+\.[A-Z]{2,4}\b\b[A-Z0-9._%-]+@[A-Z0-9.-]+\.[A-Z]{2,4}\b此时,RegexBuddy的界面如图:在点击“Explain Token”时,能对当前的正则式片断的作用作出详细解释,例如当你把光标移动到\b上再点击Explain Token,就会激活帮助文档,自动定位到Word Boundaries这一段。
如果想对刚才编写的这条正则式进行测试和验证,可以点击“Test”进行测试。
这时,在下边的文本框输入所需要匹配测试的文字,例如dog@,匹配结果就以黄色背景色标出。
在本例中,你或许没有得到正确的匹配,呵呵,那是正常的。
为什么?答案见文章结尾。
拷贝粘贴RegexBuddy能把正则式以多种字符串格式拷贝出来。
还是刚才那条正则式,根据需要,它可以被拷贝为:view plaincopy to clipboardprint1.'\\b[A-Z0-9._%-]+@[A-Z0-9.-]+\\.[A-Z]{2,4}\\b'2."\\b[A-Z0-9._%-]+@[A-Z0-9.-]+\\.[A-Z]{2,4}\\b"3.'/\\b[A-Z0-9._%-]+@[A-Z0-9.-]+\\.[A-Z]{2,4}\\b/i''\\b[A-Z0-9._%-]+@[A-Z0-9.-]+\\.[A-Z]{2,4}\\b' --editorbr--"\\b[A-Z0-9._%-]+@[A-Z0-9.-]+\\.[A-Z]{2,4}\\b" --editorbr--'/\\b[A-Z0-9._%-]+@[A-Z0-9.-]+\\.[A-Z]{2,4}\\b/i'具体的选项在copy菜单里,如下图所示。
你不必为单双引号、正反斜线操心了。
在paste菜单项中也有类似应用,不赘述。
正则式->代码如果你想把刚才编写好的正则式应用在程序中,这里还有一个选项:Use,界面见下图:在上面的match和replace之间点击,其代码也相应自动调整;当选取不同的language时,代码也会相应调整。
它支持的语言格式为:C# 、Delphi(NET/Win32) 、Java/JavaScript/ECMAScript、PCRE、PHP、Perl、Python、RealBasic、Ruby、VB另外,它还有function选项,分别用以实现下述功能:If/else branch whethe the regex matches (part of) a string. If/else验证正则式是否匹配字串(的一部分)。
最常用的功能。
If/else branch whethe the regex matches a string entirely. If/else验证正则式是否匹配整条字串。
Get the part of a string matched by the regex. 取得字串中与正则式匹配的部分。
Get the part of a string matched by a capturing group. 取得字串中所匹配的捕获组。
这一条我也是刚刚知道,很有用哟。
Get an array of all regex matches in a string.将字串中所有的匹配保存到数组中。
Iterate over all matches in a string。
列出字串中所有的匹配项。
(例如,在使用正则式’\w’来匹配字串’abc’时,本function列出的内容为’a',’b',’c’.)。
单词iterate的含义是重复。
Comment with RegexBuddy’s regex tree. RegexBuddy的正则树的注释。
文本分割split如果需要处理的文本是以某种分隔符隔开的,而该种分隔符恰好又能使用正则式描述,(例如html标签),此时regexbuddy的split功能就可以大显身手了。
我随便打开了一个饭否网页,对其源代码中的消息部分(<divid=“stream”>与</div>之内)的文本进行了处理,使用如下正则式删除了所有的尖括号内容,只留下普通文本。
使用的正则式为:view plaincopy to clipboardprint1.<[^>]+><[^>]+>软件界面以及运行结果请见下图。
结尾:关于本文开头提出的小问题,细心的你或许一下子就能看出答案了!见下图:只要选中Case insensitive选项中OK啦!如果你没有找到,或许是因为该软件是英文的,一时间您没有注意到该选项;或者您对正则式还不太熟悉。