视频摘要
- 格式:ppt
- 大小:237.50 KB
- 文档页数:14




观李镇西老师讲座《如何转化后进生》摘要一、转化后进生能够成就一个老师。
这里的所谓“成就一个老师”有两个含义:一是让老师享受到教育的幸福;二是让老师获得教育智慧。
多年前我写过这样一段话――面对一个后进生,无论多么聪明的教育者,也无法预料他明天会给自己惹什么祸事。
也正是在这个意义上,我说过:“教育,每天都充满悬念!”这里的“悬念”,主要就是我们通常的所说的“教育的难题”。
期待着每一天的“悬念”,进而研究、解决不期而遇的“悬念”,并享受解开“悬念”后的喜悦,然后又期待着下一个“悬念”……如此周而复始,这便是教育过程的无穷魅力!也是教师的无限幸福!二、“后进生”的产生主要原因:1.家庭方面的原因①教育方法不当:要么是溺爱,让孩子从小就在百依百顺的“温柔”中习惯于“朕即真理”;要么是粗暴,使孩子在呵斥和棍棒中学会仇视一切“教育”;要么就是放任,孩子在“自由”中疏远了棍棒也疏远了感情,养成了懒惰也养成了散漫。
②家长行为不正:“家长是孩子的第一任老师”已是人人都懂的道理,但为数不少的“第一任老师”却不知不觉地以自身并不美好的言行影响着孩子。
胸无大志、工作懒散、趣味低级、生活平庸、言谈粗俗、热衷赌博、沉迷色情……如此等等都是在对孩子进行着负面的“启蒙教育”。
③家庭离异:真诚和睦的家庭,不但是孩子生活的温馨港湾,而且从教育的角度看,更是他们健康成长必不可少的良好环境。
相反,夫妻经常打架、吵架、无疑会在孩子心中投下生活的阴影,扭曲他们的道德是非观念。
由父母离异而造成的家庭破裂,使一些子女失去了应有的家庭温暖和教育,心灵的创伤、感情的失落、畸形的教育,使不少孩子渐渐成为学校中的“后进学生”。
2.学校方面的原因①教师的歧视,冷落,疏远。
这是我在一次对“后进学生”的学生的问卷调查中获得的“惊人”发现。
相当多的“后进生”诉说,他们从小学起就被老师冷落、辱骂、甚至体罚。
这种歧视,不一定是教师的自觉所为,但后果却是不但使这些学生丧失了自信更丧失了自尊,更严重的是在他们心中播下了对教师乃至对教育的敌意。

视频浓缩与摘要技术在监控系统中的应用摘要:监控系统作为现代社会中重要的安全保障手段之一,在保护人民生命财产安全方面发挥着重要作用。
然而,监控系统所产生的海量视频数据给监控人员带来了极大的压力。
视频浓缩与摘要技术的应用在监控系统中,可以有效地缩短监控视频的观看时间,提高监控效率。
本文将重点探讨视频浓缩与摘要技术在监控系统中的应用,并分析其存在的挑战和发展方向。
一、视频浓缩技术的原理与应用视频浓缩是将大容量视频数据进行编码压缩,以减少存储空间和传输带宽的占用。
常用的视频浓缩技术包括基于帧间压缩的动态曲线估计、运动补偿和熵编码等。
在监控系统中,视频浓缩技术可以将原始视频数据压缩成更小的文件,便于存储和传输。
此外,视频浓缩后的视频文件还能够在保证图像质量的前提下,减少监控人员观看视频的时间。
二、视频摘要技术的原理与应用视频摘要是从原始视频中提取出该视频的关键帧序列,快速概括视频内容的过程。
视频摘要技术可以通过算法自动化地选择并呈现重要的视频帧,避免监控人员对整个视频进行观看。
常用的视频摘要技术包括关键帧提取、特征提取和关键帧排序等。
在监控系统中,视频摘要技术能够将长时间的视频浓缩为几个关键帧的摘要,帮助监控人员快速获取视频内容信息,提高工作效率。
三、视频浓缩与摘要技术在监控系统中的应用案例1. 事件检测与回放:视频浓缩与摘要技术可以通过自动检测监控视频中的重要事件,并生成摘要视频供后续回放和分析。
这种应用在公共安全监控、交通监控等领域具有重要意义。
2. 多摄像头监控:在多摄像头监控系统中,视频浓缩与摘要技术可以将多个摄像头所产生的大量视频数据压缩为一个简洁的摘要,方便监控人员同时观看多路视频。
3. 实时监控与告警:视频浓缩与摘要技术可以快速提取监控视频中的异常情况,如行人入侵、车辆违规等,并通过实时告警系统提醒监控人员。
这种应用在安防领域具有重要意义。
四、视频浓缩与摘要技术面临的挑战1. 大规模视频数据处理:监控系统中产生的视频数据量巨大,如何快速高效地处理海量视频数据是视频浓缩与摘要技术需要解决的重要问题。


基于关键帧提取的视频摘要算法研究视频摘要是从长时间视频中提取关键信息的过程,具有重要的应用价值。
基于关键帧提取的视频摘要算法是一种有效的方法,它通过选取一系列具有代表性的关键帧来代表整个视频。
本文将研究不同的基于关键帧提取的视频摘要算法,并对其性能进行评估。
通过对比实验结果,我们将得出结论,并提出改进方法,以进一步提高基于关键帧提取的视频摘要算法在实际应用中的效果。
1. 引言视频是一种重要而复杂的多媒体数据形式,其包含了大量信息。
然而,长时间视频往往包含了大量无用信息或冗余内容,使得用户在观看过程中需要花费大量时间和精力。
因此,从长时间视频中快速准确地获取有价值信息成为了一个重要问题。
2. 相关工作在过去几十年里,研究人员们已经提出了多种不同类型和方法来进行视频摘要。
其中一个常见方法是基于关键帧提取来进行视频摘要。
3. 关键帧选择关键帧选择是基于关键帧提取的视频摘要算法的核心步骤。
关键帧是具有代表性且能够准确描述视频内容的关键图像帧。
在这一步骤中,我们可以使用多种方法来选择关键帧,例如基于图像质量、基于内容相似度和基于动作变化等。
4. 关键帧提取算法4.1 图像质量评估算法图像质量评估算法是一种常见的关键帧选择方法。
这种方法通过对每一帧进行图像质量评估,选取质量最好的几个作为关键帧。
常见的图像质量评估指标包括对比度、清晰度和亮度等。
4.2 内容相似度算法内容相似度算法是另一种常见的关键帧选择方法。
这种方法通过计算每个相邻图像之间的相似性来选取关键帧。
常见的相似性计算方法包括结构相似性指数(SSIM)和峰值信噪比(PSNR)等。
4.3 动作变化检测算法动作变化检测算法是另一种常见的关键帧选择方法。
这种方法通过检测视频中动作变化来选取关键帧。
常见的动作变化检测方法包括光流法和运动矢量法等。
5. 性能评估为了评估基于关键帧提取的视频摘要算法的性能,我们将进行一系列实验。
我们将使用不同类型和长度的视频数据集,并使用不同的评估指标,例如召回率、准确率和F1值等。

avss标准AVSS(Audio Video Scene and Summary)是一种用于视频摘要生成的标准。
它旨在通过自动分析视频内容,提取关键信息,生成视频摘要,以便用户能够快速了解视频的内容和主题。
AVSS标准的应用范围广泛,包括视频搜索、视频推荐、视频监控等领域。
AVSS标准的核心是对视频内容进行分析和理解。
首先,它需要对视频进行语义分割,将视频中的不同物体和场景进行区分。
这可以通过计算机视觉技术实现,如目标检测、图像分割等。
然后,AVSS标准需要对每个物体或场景进行特征提取,以便后续的摘要生成。
在特征提取阶段,AVSS标准可以使用多种技术。
例如,可以使用深度学习模型来提取物体的视觉特征,如卷积神经网络(CNN)或循环神经网络(RNN)。
此外,还可以使用自然语言处理技术来提取文本特征,如词袋模型或词嵌入模型。
一旦完成了特征提取阶段,AVSS标准就可以根据这些特征生成视频摘要。
这可以通过多种方法实现。
例如,可以使用聚类算法将相似的物体或场景分组在一起,然后选择每个组中最具代表性的物体或场景作为摘要。
此外,还可以使用生成模型,如生成对抗网络(GAN),来生成与视频内容相关的图像或文本。
AVSS标准的应用非常广泛。
在视频搜索领域,它可以帮助用户快速找到感兴趣的视频片段。
在视频推荐领域,它可以根据用户的兴趣和偏好生成个性化的视频推荐列表。
在视频监控领域,它可以帮助安保人员快速发现异常事件,并采取相应的措施。
总之,AVSS标准是一种用于视频摘要生成的标准。
它通过自动分析视频内容,提取关键信息,并生成视频摘要,以便用户能够快速了解视频的内容和主题。
AVSS标准在多个领域有着广泛的应用前景,并为我们提供了更加智能化和高效率的视频处理和分析方法。

视频摘要与关键帧提取第一章:引言1.1 背景介绍随着互联网媒体技术的迅猛发展,视频成为人们获取信息和娱乐的重要途径。
然而,随着视频数量的爆发式增长,人们很难从海量的视频中快速准确地找到自己感兴趣的内容。
因此,如何对大规模视频进行高效摘要和关键帧提取成为了一个重要研究领域。
1.2 研究意义在信息爆炸时代,快速准确地获取所需信息对于个人用户和企业来说至关重要。
通过对大规模视频进行摘要与关键帧提取可以极大地节省用户搜索时间,并且能够更好地满足用户需求。
第二章:相关技术介绍2.1 视频摘要技术传统方法主要依靠手动编辑或者基于规则定义来生成摘录片段。
然而这种方法效率低下且需要耗费大量人力物力,并且很难适应海量数据处理需求。
近年来出现了基于机器学习、深度学习等方法实现自动化生成精确高质量视觉摘要的技术。
2.2 关键帧提取技术关键帧提取是指从视频序列中选择最具代表性的关键帧,以便在有限的时间内传达出视频内容。
传统方法主要基于图像处理和特征提取算法,但这些方法往往无法准确地捕捉到视频中最重要的信息。
近年来,随着深度学习等技术的发展,基于卷积神经网络(CNN)和循环神经网络(RNN)等方法实现了更加准确和高效的关键帧提取。
第三章:视频摘要与关键帧提取算法3.1 视频摘要算法3.1.1 基于机器学习方法采用机器学习方法进行视觉摘录片段生成是目前主流研究方向之一。
该类算法通过训练模型来识别并选择出与用户需求相关性较高且具有代表性特点的片段。
3.1.2 基于深度学习方法近年来深度学习在计算机视觉领域获得了巨大成功,并且被广泛应用于视频摘录片段生成任务中。
通过使用卷积神经网络(CNN)进行图像特征抽取,并结合循环神经网络(RNN)进行时间序列建模,可以更准确地捕捉到视频中的关键信息。
3.2 关键帧提取算法3.2.1 基于图像处理方法传统的关键帧提取方法主要基于图像处理技术,通过计算图像间的相似度来选择具有代表性的关键帧。

使用AI技术进行视频摘要的技巧一级标题:AI技术在视频摘要中的应用二级标题1:视频摘要的定义及意义视频摘要是对长时间的视频内容进行概括和提炼,以便节省时间和精力。
随着互联网和移动设备的普及,产生了大量的视频内容,但很多用户没有足够的时间或兴趣观看完整的视频。
因此,使用AI技术进行视频摘要成为了一种解决方案。
视频摘要可以帮助用户快速了解整个视频的主题、关键信息和重要细节。
它对于新闻报道、教育培训、产品演示等领域都具有重要意义。
利用AI技术可以自动识别并抽取出关键信息,从而帮助用户更高效地获取所需知识。
二级标题2:AI技术在视频摘要中的优势1. 自动化处理:传统上,手工制作一个视频摘要需要人工观看整个视频,并选择合适的片段进行编辑。
而借助AI技术,可以实现自动化处理,在不需要人工干预的情况下生成高质量且准确可靠的摘要结果。
2. 高效率:由于人们无法同时处理大量的视听信息,使用AI技术进行视频摘要可以大大减少时间和精力的消耗。
AI算法能够快速处理庞大的数据,快速提取出关键信息,为用户节省了大量时间。
3. 智能化选择:AI技术可以根据预设的摘要目标自动选择关键片段,并利用语音识别、图像处理等技术进行内容分析和抽取,从而生成更加符合用户需求的视频摘要结果。
4. 多样化功能:除了基本的文字摘要外,AI技术还可以实现其他附加功能,如转录语音、人物识别、情感分析等。
这些功能可以进一步丰富视频摘要的形式和内容,提高用户体验。
二级标题3:使用AI技术进行视频摘要的技巧1. 视频分割与关键帧提取:首先需要将整个视频拆分为多个较短的片段或帧,并从中选择代表性的关键帧。
这一过程可以借助AI图像处理算法来自动完成,例如通过颜色直方图、边缘检测等方法对关键帧进行提取。
2. 语音识别与文本生成:使用自然语言处理及深度学习技术对视频中出现的语音进行转换和识别,并将其转化为文字文本。
这样可以便于后续处理和生成摘要。
3. 内容分析与信息抽取:利用语义分析和机器学习算法,对视频内容进行深度理解和分析。
基于深度学习的自动化视频摘要生成在当今数字化的时代,视频已经成为信息传播的重要载体。
然而,随着视频数量的急剧增长,如何快速有效地获取视频中的关键信息成为了一个亟待解决的问题。
基于深度学习的自动化视频摘要生成技术应运而生,为我们提供了一种高效的解决方案。
想象一下,你面对海量的视频数据,无论是教育讲座、电影、新闻报道还是个人拍摄的视频,想要在短时间内了解其核心内容,这几乎是一项不可能完成的任务。
传统的方式可能需要我们花费大量的时间去观看整个视频,这不仅效率低下,还可能让我们错过重要的信息。
而自动化视频摘要生成技术就像是一位智能的助手,能够快速为我们提取出视频的关键要点,以简洁明了的形式呈现给我们。
那么,什么是基于深度学习的自动化视频摘要生成呢?简单来说,它是利用深度学习算法和模型,对输入的视频进行分析和理解,然后自动生成能够概括视频主要内容的摘要。
这个过程涉及到对视频中的图像、音频、文字等多种信息的处理和融合。
深度学习在这个过程中发挥着关键作用。
深度学习模型,例如卷积神经网络(CNN)和循环神经网络(RNN),能够从视频中学习到复杂的特征和模式。
CNN 擅长处理图像信息,能够提取视频中的视觉特征,比如人物的动作、场景的变化等。
而 RNN 则对序列数据有着良好的处理能力,可以处理音频信息以及视频中随时间变化的特征。
在实际的应用中,自动化视频摘要生成技术有着广泛的用途。
对于新闻行业来说,能够快速生成新闻视频的摘要,帮助观众更快地了解新闻要点,提高新闻传播的效率。
在教育领域,它可以将冗长的教学视频精简为重点突出的摘要,方便学生复习和掌握关键知识。
对于企业而言,能够对大量的培训视频、会议视频进行摘要提取,节省员工的时间,提高工作效率。
为了实现高质量的视频摘要生成,需要解决一系列的技术挑战。
首先是如何准确地理解视频的内容。
视频包含了丰富的信息,不仅有图像和音频,还有可能存在文字、字幕等。
如何将这些多模态的信息有效地融合起来,准确理解视频的主题、情节和关键事件,是一个难题。
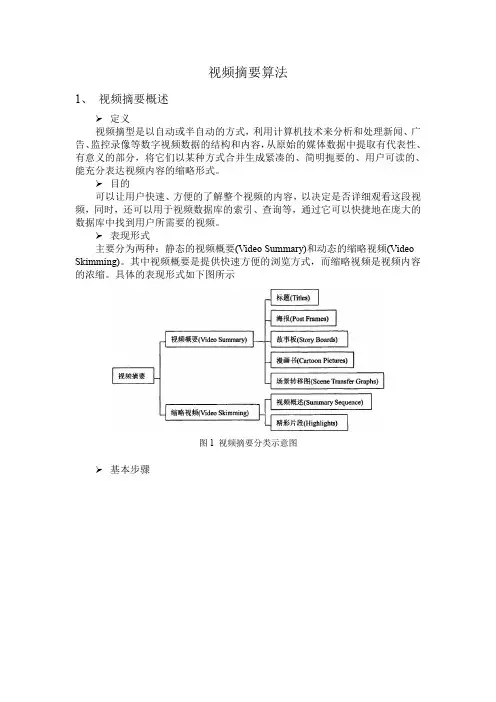
视频作品摘要例子
视频概要往往为静态视频摘要模式,即通过一系列关键帧(对象)组成相应的语义单元,概括表示镜头内容,并支持视频快速导航。
特点:静态视频摘要只考虑其关键帧(对象),忽略了音频信息,生成摘要的速度比动态的快;
缩略视频为动态视频摘要模式,即保持了视频内容随时间动态变化的视频固有特征,一般是智能选择能够刻画原视频内容的小片段加以编辑合成。
特点:动态视频摘要表现的内容比静态视频摘要丰富,通常以镜头的方式表示,融合了图像、声音和文字等信息。
视频略览:
关键帧表示
目前在基于MPEG-1/2 的数字视频索引与检索模型中,主要是基于关键帧(代表帧)表示视频序列的概略信息。
关键帧是从视频中抽取的一些静态图像,用于表示镜头的内容,以此实现视频内容的快速浏览,并能够与视频索引技术等相结合,进行基于内容的视频检索与分析,其浏览方式包括故事板、场景转移图等。
(基于故事板的浏览方式为将提取后的关键帧以缩略图的形式按照时间顺序显示和浏览。
缩略图的周围还伴随关键帧相关属性,包括该镜头持续时间和摄像机运动等。
)
方法:
基于采样的方法,即首先通过镜头分割技术将视频转换为镜头的集合,然后选取镜头的第一帧为关键帧。
该方法实现最简单,运算量小,但是对摄像机快速运动的镜头表现能力有限。
当前的关键帧表示主要为基于聚类的方法。
其原理为对当前帧,计算其与已知的聚类中心的距离,若大于预设的阈值,则为新类中心,否则加入距离最近的类,并重新计算该类中心。