视频摘要技术
- 格式:pdf
- 大小:190.16 KB
- 文档页数:3

基于门控多头注意力机制的视频摘要 基于门控多头注意力机制的视频摘要 摘要: 随着互联网和数字技术的飞速发展,视频成为了人们获取信息和娱乐的主要方式之一。然而,随着视频数据的爆炸式增长,如何快速而准确地从大量的视频中提取出关键信息成为了一项重要的研究课题。视频摘要作为一种重要的视频信息提取方式,在这个背景下变得越来越受人们关注。本文将介绍一种基于门控多头注意力机制的视频摘要方法,该方法能够有效地从视频中提取出关键帧和关键段落,为用户提供更加高效、准确的视频内容概览。 1.引言 随着视频数据的爆炸式增长,从大量的视频中提取出关键信息成为了一项重要的研究课题。传统的视频摘要方法主要基于图像处理和机器学习技术,但往往无法有效地处理视频中的动态内容和语义信息。因此,本文将介绍一种基于门控多头注意力机制的视频摘要方法,该方法能够充分考虑视频中的语义信息,并根据用户的需求提取出关键帧和关键段落。 2.相关工作 在视频摘要领域,研究者们提出了许多不同的方法,包括基于图像处理的方法、基于机器学习的方法和基于深度学习的方法等。然而,这些方法往往忽略了视频中的语义信息,导致提取出的摘要内容不够准确和完整。为了解决这个问题,本文将引入门控多头注意力机制来处理视频的语义信息,从而提高视频摘要的质量。 3.门控多头注意力机制 门控多头注意力机制是一种基于注意力机制的深度学习方法,能够自适应地选择和集中注意力在视频的重要帧和段落上。该方法由多个注意力头组成,每个注意力头负责对不同的视频特征进行注意力加权,然后将加权后的特征进行融合。通过引入门控机制,该方法能够动态地选择不同注意力头的权重,进一步提高视频摘要的质量和性能。 4.基于门控多头注意力机制的视频摘要方法 本文提出的基于门控多头注意力机制的视频摘要方法主要分为三个步骤:关键帧提取、关键段落提取和摘要生成。首先,通过卷积神经网络提取视频的帧级特征,并使用门控多头注意力机制对每一帧进行加权和融合,得到帧级注意力特征。然后,根据帧级注意力特征,识别出关键帧,这些关键帧往往包含了视频中最重要的信息。接下来,通过循环神经网络对每个关键帧进行段落级特征提取,并使用门控多头注意力机制对段落进行加权和融合。最后,根据段落级注意力特征,生成整个视频的摘要。 5.实验与评估 为了验证基于门控多头注意力机制的视频摘要方法的有效性,我们在公开数据集上进行了一系列实验。实验结果表明,与传统方法相比,该方法在视频摘要的准确性和完整性方面具有显著的改进。同时,该方法在不同类型的视频上也都能够取得较好的性能。 6.结论 本文介绍了一种基于门控多头注意力机制的视频摘要方法,该方法能够充分考虑视频中的语义信息,并根据用户的需求提取出关键帧和关键段落。实验结果表明,该方法在视频摘要的准确性和完整性方面具有显著的改进,适用于不同类型的视频。未来,我们将进一步完善该方法,提高视频摘要的效果和性能。


基于深度学习的视频摘要与关键帧提取算法研究摘要:随着互联网的迅猛发展,视频数据成为人们获取信息和娱乐的重要来源。
然而,随着视频数量的不断增加,人们需要更快速和有效地处理和浏览这些视频内容。
视频摘要和关键帧提取作为视频内容分析和检索的重要技术,能够提供视频的概要信息和代表性帧,帮助用户快速了解和检索视频内容。
本文将基于深度学习的视频摘要与关键帧提取算法进行详细研究和探讨。
首先,我们将介绍视频摘要与关键帧提取的概念和应用领域。
然后,将介绍传统的视频摘要和关键帧提取算法以及其存在的问题和局限性。
接着,我们将详细介绍基于深度学习的视频摘要与关键帧提取算法的原理和方法,并分析其优势和挑战。
最后,将针对该算法进行实验验证,并对未来研究方向进行展望。
关键词:深度学习、视频摘要、关键帧提取、概要信息、代表性帧1. 引言随着数字技术和互联网的高速发展,用户可以方便地拍摄、共享和传播各种视频内容。
然而,海量的视频数据给人们带来了处理和浏览视频内容的难题。
视频摘要和关键帧提取作为视频内容分析和检索的重要技术,为用户提供了更快速和有效获取视频信息的方法。
2. 视频摘要与关键帧提取的概念和应用领域视频摘要是从视频中提取出包含概要信息的视频片段,用于快速浏览和了解视频内容。
关键帧提取是从视频中选择一些代表性的静态图像帧,用于代表整个视频。
视频摘要和关键帧提取在许多应用领域得到了广泛的应用,如视频检索、视频摘要浏览、视频摘要生成等。
3. 传统的视频摘要和关键帧提取算法传统的视频摘要和关键帧提取算法主要基于图像处理和机器学习技术。
常用的算法包括基于视觉特征的聚类算法、基于机器学习的分类算法和基于视觉显著性的算法。
然而,这些传统算法通常需要手工设计特征,并且在处理复杂的视频场景时效果不佳。
4. 基于深度学习的视频摘要与关键帧提取算法深度学习在计算机视觉领域取得了巨大的突破,为视频摘要和关键帧提取算法的发展提供了新的思路。
基于深度学习的视频摘要与关键帧提取算法能够自动学习视频的高级语义特征,并提供更准确和鲁棒的结果。


基于关键帧提取的视频摘要算法研究视频摘要是从长时间视频中提取关键信息的过程,具有重要的应用价值。
基于关键帧提取的视频摘要算法是一种有效的方法,它通过选取一系列具有代表性的关键帧来代表整个视频。
本文将研究不同的基于关键帧提取的视频摘要算法,并对其性能进行评估。
通过对比实验结果,我们将得出结论,并提出改进方法,以进一步提高基于关键帧提取的视频摘要算法在实际应用中的效果。
1. 引言视频是一种重要而复杂的多媒体数据形式,其包含了大量信息。
然而,长时间视频往往包含了大量无用信息或冗余内容,使得用户在观看过程中需要花费大量时间和精力。
因此,从长时间视频中快速准确地获取有价值信息成为了一个重要问题。
2. 相关工作在过去几十年里,研究人员们已经提出了多种不同类型和方法来进行视频摘要。
其中一个常见方法是基于关键帧提取来进行视频摘要。
3. 关键帧选择关键帧选择是基于关键帧提取的视频摘要算法的核心步骤。
关键帧是具有代表性且能够准确描述视频内容的关键图像帧。
在这一步骤中,我们可以使用多种方法来选择关键帧,例如基于图像质量、基于内容相似度和基于动作变化等。
4. 关键帧提取算法4.1 图像质量评估算法图像质量评估算法是一种常见的关键帧选择方法。
这种方法通过对每一帧进行图像质量评估,选取质量最好的几个作为关键帧。
常见的图像质量评估指标包括对比度、清晰度和亮度等。
4.2 内容相似度算法内容相似度算法是另一种常见的关键帧选择方法。
这种方法通过计算每个相邻图像之间的相似性来选取关键帧。
常见的相似性计算方法包括结构相似性指数(SSIM)和峰值信噪比(PSNR)等。
4.3 动作变化检测算法动作变化检测算法是另一种常见的关键帧选择方法。
这种方法通过检测视频中动作变化来选取关键帧。
常见的动作变化检测方法包括光流法和运动矢量法等。
5. 性能评估为了评估基于关键帧提取的视频摘要算法的性能,我们将进行一系列实验。
我们将使用不同类型和长度的视频数据集,并使用不同的评估指标,例如召回率、准确率和F1值等。

avss标准AVSS(Audio Video Scene and Summary)是一种用于视频摘要生成的标准。
它旨在通过自动分析视频内容,提取关键信息,生成视频摘要,以便用户能够快速了解视频的内容和主题。
AVSS标准的应用范围广泛,包括视频搜索、视频推荐、视频监控等领域。
AVSS标准的核心是对视频内容进行分析和理解。
首先,它需要对视频进行语义分割,将视频中的不同物体和场景进行区分。
这可以通过计算机视觉技术实现,如目标检测、图像分割等。
然后,AVSS标准需要对每个物体或场景进行特征提取,以便后续的摘要生成。
在特征提取阶段,AVSS标准可以使用多种技术。
例如,可以使用深度学习模型来提取物体的视觉特征,如卷积神经网络(CNN)或循环神经网络(RNN)。
此外,还可以使用自然语言处理技术来提取文本特征,如词袋模型或词嵌入模型。
一旦完成了特征提取阶段,AVSS标准就可以根据这些特征生成视频摘要。
这可以通过多种方法实现。
例如,可以使用聚类算法将相似的物体或场景分组在一起,然后选择每个组中最具代表性的物体或场景作为摘要。
此外,还可以使用生成模型,如生成对抗网络(GAN),来生成与视频内容相关的图像或文本。
AVSS标准的应用非常广泛。
在视频搜索领域,它可以帮助用户快速找到感兴趣的视频片段。
在视频推荐领域,它可以根据用户的兴趣和偏好生成个性化的视频推荐列表。
在视频监控领域,它可以帮助安保人员快速发现异常事件,并采取相应的措施。
总之,AVSS标准是一种用于视频摘要生成的标准。
它通过自动分析视频内容,提取关键信息,并生成视频摘要,以便用户能够快速了解视频的内容和主题。
AVSS标准在多个领域有着广泛的应用前景,并为我们提供了更加智能化和高效率的视频处理和分析方法。

视频检索中的场景摘要技术研究的开题报告一、选题背景随着网络环境的不断发展,大量的视频资料被上传至互联网上。
面对如此庞大的数据量,如何快速、准确地获取所需信息成为重要问题。
在视频检索领域中,场景摘要技术是一种常用的方法。
该技术能够通过对视频中的关键帧进行自动抽取,提取视频内容的主要特征,从而方便用户快速了解视频内容。
二、选题意义场景摘要技术具有很高的应用价值。
例如,可以应用于视频搜索、广告投放等场景。
此外,随着视频内容的不断增多,如何自动提取视频内容的主要信息,进一步提升视频检索效率,也是目前该领域的研究热点。
三、研究目标和内容本文旨在研究视频检索中的场景摘要技术。
具体内容包括以下几点:1.探究视频场景摘要的基本概念和技术原理。
2.分析场景摘要技术的优缺点。
3.调研现有视频检索中的场景摘要技术,分析其应用与局限性。
4.设计场景摘要的具体实现方案。
5.对实现方案进行实验评估和性能分析,以验证其实用性和效果。
四、预期结果通过对视频检索中的场景摘要技术研究,预计可以取得如下研究成果:1.深入了解场景摘要技术的优势和局限性,为未来该领域的研究提供参考。
2.设计和实现一种高效、准确的场景摘要技术,提高视频检索效率。
3.对提出的实现方案进行测试和评估,验证其实用性和效果。
五、预期难点与解决方案本文预计需要解决的难点如下:1.场景摘要技术需要对视频关键帧进行自动抽取和分类,如何确保分类准确性是需要解决的难点。
2.不同视频之间的场景内容差别很大,如何针对不同的视频提取准确的摘要信息也需要解决。
为解决这些难点,采取以下策略:1.使用深度学习等相关技术对视频关键帧进行准确分类。
2.通过分析视频特征,设计不同视频类型的场景摘要技术。
六、研究方法和步骤本文主要采用文献调研和实验研究相结合的方法进行研究。
具体步骤如下:1.收集相关文献,学习场景摘要技术的相关理论,深入了解该技术的应用前景及实现难点。
2.对现有的场景摘要技术进行分析,总结优缺点。

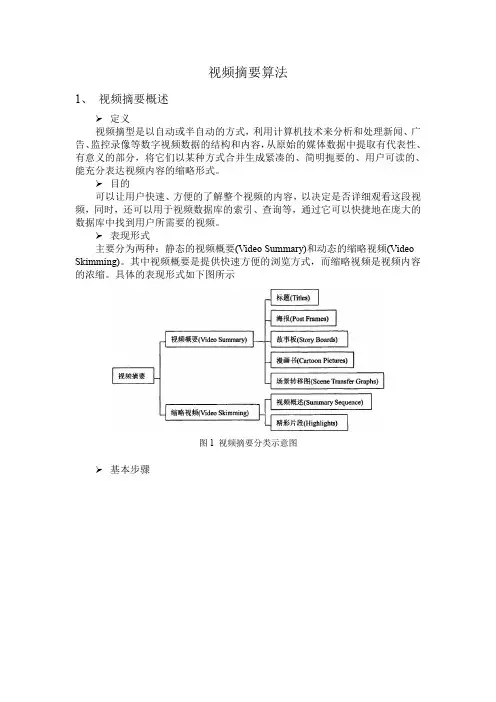
视频摘要视频摘要、视频检索和⼈脸识别成千上万的监控摄像头昼夜不停地录像,制造出海量的视频⽂件。
从如此巨⼤的视频⽂件集中发现重要事件是⾮常困难的,即使是⼀段已知有事件发⽣的视频录像。
如今有三种⽅法解决这⼀问题:1、⽣成⼀个简短的视频概要,例如将单个摄像头摄制24 ⼩时的视频压缩成⼏分钟,同时保留活动细节,以⽅便⽤户快速浏览。
久凌视觉已经开发出⼀个基于⽬标跟踪技术的视频摘要系统。
“视频摘要”是指从原始视频中提取感兴趣的⽬标的活动信息,和背景视频缝合剪辑⽽成的较短视频⽚断,可以⽤短⼩精悍,信息全⾯来描述它。
视频摘要可以采⽤原始视频分辨率,也可以根据存储要求降低分辨率;2、通过摄像头⽹络或视频⽂件集进⾏嫌疑⽬标或事件的跟踪查询。
此项⽬也是久凌视觉研究范围之⼀;3、⼈脸识别技术,进⾏重要场所视频监控⽬标筛查。
1 视频摘要如今,越来越多的监控摄像头安装在我们⾝边。
随着电脑速度的提升,磁盘容量的增⼤和因特⽹的⼴泛使⽤,这些设备每天⽣成了成千上万的数据。
因此,从这些海量的数据中找到重要事件就变得异常困难。
所以,找出⼀种⽅法去压缩视频,甚⾄⾃动地搜索整个⽂件集就尤为紧迫。
由于视频浏览和检索很耗时,⼤多数取得的视频并不会观看和检查。
视频摘要就成了⼀种浏览检索视频的有效⼯具。
它将⽣成⼀个简短的视频,其中包含了原视频中所有重要的活动。
视频通过同时播放多个事件,哪怕是在原视频中不同时间发⽣的,将整个视频被压缩成⼀个简短的事件摘要。
这个摘要同时也是原视频⽂件的⼀个索引,可以找到每⼀个事件发⽣的真实时间。
这⼀技术主要通过对视频重排序来摘要和检索,对监控摄像头和⽹络摄像机是很有益处的。
上述视频摘要技术可以⽤于单个摄像头拍摄的视频。
对于跨摄像机⽹络,由于存在每⼀个摄像机视⾓的不同,光线变化,⽬标姿态的变化以及可能存在遮挡的情况,对于跨摄像机视频对象的跟踪,查找甚⾄重新确认定位,具有很⼤的挑战。
在后⾯的章节,我们将介绍跨摄像机⽬标跟踪的⽅法。