伍德里奇计量经济学第六版答案Chapter-10
- 格式:docx
- 大小:143.28 KB
- 文档页数:13

伍德里奇计量经济学导论第6版笔记和课后答案
第1章计量经济学的性质与经济数据
1.1 复习笔记
考点一:计量经济学及其应用★
1计量经济学
计量经济学是在一定的经济理论基础之上,采用数学与统计学的工具,通过建立计量经济模型对经济变量之间的关系进行定量分析的学科。
进行计量分析的步骤主要有:①利用经济数据对模型中的未知参数进行估计;②对模型进行检验;③通过检验后,可以利用计量模型来进行相关预测。
2经济分析的步骤
经济分析是指利用所搜集的相关数据检验某个理论是否成立或估计某种关系的方法。
经济分析主要包括以下几步,分别是阐述问题、构建经济模型、经济模型转化为计量模型、搜集相关数据、参数估计和假设检验。
考点二:经济数据★★★
1经济数据的结构(见表1-1)
表1-1 经济数据的结构
2面板数据与混合横截面数据的比较(见表1-2)
表1-2 面板数据与混合横截面数据的比较
考点三:因果关系和其他条件不变★★
1因果关系
因果关系是指一个变量的变动将引起另一个变量的变动,这是经济分析中的重要目标之一。
计量分析虽然能发现变量之间的相关关系,但是如果想要解释因果关系,还要排除模型本身存在因果互逆的可能,
否则很难让人信服。
2其他条件不变
其他条件不变是指在经济分析中,保持所有的其他变量不变。
“其他条件不变”这一假设在因果分析中具有重要作用。

第12章时间序列回归中的序列相关和异方差性12.1复习笔记考点一:含序列相关误差时OLS 的性质★★★1.无偏性和一致性当时间序列回归的前3个高斯-马尔可夫假定成立时,OLS 的估计值是无偏的。
把严格外生性假定放松到E(u t |X t )=0,可以证明当数据是弱相关时,∧βj 仍然是一致的,但不一定是无偏的。
2.有效性和推断假定误差存在序列相关,即满足u t =ρu t-1+e t ,t=1,2,…,n,|ρ|<1。
其中,e t 是均值为0方差为σe 2满足经典假定的误差。
对于简单回归模型:y t =β0+β1x t +u t 。
假定x t 的样本均值为零,因此有:1111ˆn x t tt SST x u -==+∑ββ其中:21nx t t SST x ==∑∧β1的方差为:()()122221111ˆ/2/n n n t j xt t x x t t j t t j Var SST Var x u SST SST x x ---+===⎛⎫==+ ⎪⎝⎭∑∑∑βσσρ其中:σ2=Var(u t )。
根据∧β1的方差表达式可知,第一项为经典假定条件下的简单回归模型中参数的方差。
因此,当模型中的误差项存在序列相关时,OLS 估计的方差是有偏的,假设检验的统计量也会出现偏差。
3.拟合优度当时间序列回归模型中的误差存在序列相关时,通常的拟合优度指标R 2和调整R 2便会失效;但只要数据是平稳和弱相关的,拟合优度指标就仍然有效。
4.出现滞后因变量时的序列相关(1)在出现滞后因变量和序列相关的误差时,OLS 不一定是不一致的假设E(y t |y t-1)=β0+β1y t-1。
其中,|β1|<1。
加上误差项把上式写为:y t =β0+β1y t-1+u t ,E(u t |y t-1)=0。
模型满足零条件均值假定,因此OLS 估计量∧β0和∧β1是一致的。
误差{u t }可能序列相关。
虽然E(u t |y t-1)=0保证了u t 与y t-1不相关,但u t-1=y t -1-β0-β1y t-2,u t 和y t-2却可能相关。

第1章计量经济学的性质与经济数据1.1复习笔记考点一:计量经济学★1计量经济学的含义计量经济学,又称经济计量学,是由经济理论、统计学和数学结合而成的一门经济学的分支学科,其研究内容是分析经济现象中客观存在的数量关系。
2计量经济学模型(1)模型分类模型是对现实生活现象的描述和模拟。
根据描述和模拟办法的不同,对模型进行分类,如表1-1所示。
(2)数理经济模型和计量经济学模型的区别①研究内容不同数理经济模型的研究内容是经济现象各因素之间的理论关系,计量经济学模型的研究内容是经济现象各因素之间的定量关系。
②描述和模拟办法不同数理经济模型的描述和模拟办法主要是确定性的数学形式,计量经济学模型的描述和模拟办法主要是随机性的数学形式。
③位置和作用不同数理经济模型可用于对研究对象的初步研究,计量经济学模型可用于对研究对象的深入研究。
考点二:经济数据★★★1经济数据的结构(见表1-3)2面板数据与混合横截面数据的比较(见表1-4)考点三:因果关系和其他条件不变★★1因果关系因果关系是指一个变量的变动将引起另一个变量的变动,这是经济分析中的重要目标之计量分析虽然能发现变量之间的相关关系,但是如果想要解释因果关系,还要排除模型本身存在因果互逆的可能,否则很难让人信服。
2其他条件不变其他条件不变是指在经济分析中,保持所有的其他变量不变。
“其他条件不变”这一假设在因果分析中具有重要作用。
1.2课后习题详解一、习题1.假设让你指挥一项研究,以确定较小的班级规模是否会提高四年级学生的成绩。
(i)如果你能指挥你想做的任何实验,你想做些什么?请具体说明。
(ii)更现实地,假设你能搜集到某个州几千名四年级学生的观测数据。
你能得到它们四年级班级规模和四年级末的标准化考试分数。
你为什么预计班级规模与考试成绩成负相关关系?(iii)负相关关系一定意味着较小的班级规模会导致更好的成绩吗?请解释。
答:(i)假定能够随机的分配学生们去不同规模的班级,也就是说,在不考虑学生诸如能力和家庭背景等特征的前提下,每个学生被随机的分配到不同的班级。

第二篇时间序列数据的回归分析第10章时间序列数据的基本回归分析10.1 复习笔记考点一:时间序列数据★★1.时间序列数据与横截面数据的区别(1)时间序列数据集是按照时间顺序排列。
(2)时间序列数据与横截面数据被视为随机结果的原因不同。
(3)一个时间序列过程的所有可能的实现集,便相当于横截面分析中的总体。
时间序列数据集的样本容量就是所观察变量的时期数。
2.时间序列模型的主要类型(见表10-1)表10-1 时间序列模型的主要类型考点二:经典假设下OLS的有限样本性质★★★★1.高斯-马尔可夫定理假设(见表10-2)表10-2 高斯-马尔可夫定理假设2.OLS估计量的性质与高斯-马尔可夫定理(见表10-3)表10-3 OLS估计量的性质与高斯-马尔可夫定理3.经典线性模型假定下的推断(1)假定TS.6(正态性)假定误差u t独立于X,且具有独立同分布Normal(0,σ2)。
该假定蕴涵了假定TS.3、TS.4和TS.5,但它更强,因为它还假定了独立性和正态性。
(2)定理10.5(正态抽样分布)在时间序列的CLM假定TS.1~TS.6下,以X为条件,OLS估计量遵循正态分布。
而且,在虚拟假设下,每个t统计量服从t分布,F统计量服从F分布,通常构造的置信区间也是确当的。
定理10.5意味着,当假定TS.1~TS.6成立时,横截面回归估计与推断的全部结论都可以直接应用到时间序列回归中。
这样t统计量可以用来检验个别解释变量的统计显著性,F统计量可以用来检验联合显著性。
考点三:时间序列的应用★★★★★1.函数形式、虚拟变量除了常见的线性函数形式,其他函数形式也可以应用于时间序列中。
最重要的是自然对数,在应用研究中经常出现具有恒定百分比效应的时间序列回归。
虚拟变量也可以应用在时间序列的回归中,如某一期的数据出现系统差别时,可以采用虚拟变量的形式。
2.趋势和季节性(1)描述有趋势的时间序列的方法(见表10-4)表10-4 描述有趋势的时间序列的方法(2)回归中的趋势变量由于某些无法观测的趋势因素可能同时影响被解释变量与解释变量,被解释变量与解释变量均随时间变化而变化,容易得到被解释变量与解释变量之间趋势变量的关系,而非真正的相关关系,导致了伪回归。

CHAPTER 11TEACHING NOTESMuch of the material in this chapter is usually postponed, or not covered at all, in an introductory course. However, as Chapter 10 indicates, the set of time series applications that satisfy all of the classical linear model assumptions might be very small. In my experience, spurious time series regressions are the hallmark of many student projects that use time series data. Therefore, students need to be alerted to the dangers of using highly persistent processes in time series regression equations. (Spurious regression problem and the notion of cointegration are covered in detail in Chapter 18.)It is fairly easy to heuristically describe the difference between a weakly dependent process and an integrated process. Using the MA(1) and the stable AR(1) examples is usually sufficient.When the data are weakly dependent and the explanatory variables are contemporaneously exogenous, OLS is consistent. This result has many applications, including the stable AR(1) regression model. When we add the appropriate homoskedasticity and no serial correlation assumptions, the usual test statistics are asymptotically valid.The random walk process is a good example of a unit root (highly persistent) process. In a one-semester course, the issue comes down to whether or not to first difference the data before specifying the linear model. While unit root tests are covered in Chapter 18, just computing the first-order autocorrelation is often sufficient, perhaps after detrending. The examples in Section 11.3 illustrate how different first-difference results can be from estimating equations in levels. Section 11.4 is novel in an introductory text, and simply points out that, if a model is dynamically complete in a well-defined sense, it should not have serial correlation. Therefore, we need not worry about serial correlation when, say, we test the efficient market hypothesis. Section 11.5 further investigates the homoskedasticity assumption, and, in a time series context, emphasizes that what is contained in the explanatory variables determines what kind of hetero-skedasticity is ruled out by the usual OLS inference. These two sections could be skipped without loss of continuity.129130SOLUTIONS TO PROBLEMS11.1 Because of covariance stationarity, 0γ = Var(x t ) does not depend on t , so sd(x t+hany h ≥ 0. By definition, Corr(x t ,x t +h ) = Cov(x t ,x t+h )/[sd(x t )⋅sd(x t+h)] = 0/.h h γγγ=11.2 (i) E(x t ) = E(e t ) – (1/2)E(e t -1) + (1/2)E(e t -2) = 0 for t = 1,2, Also, because the e t are independent, they are uncorrelated and so Var(x t ) = Var(e t ) + (1/4)Var(e t -1) + (1/4)Var(e t -2) = 1 + (1/4) + (1/4) = 3/2 because Var (e t ) = 1 for all t .(ii) Because x t has zero mean, Cov(x t ,x t +1) = E(x t x t +1) = E[(e t – (1/2)e t -1 + (1/2)e t -2)(e t +1 – (1/2)e t + (1/2)e t -1)] = E(e t e t+1) – (1/2)E(2t e ) + (1/2)E(e t e t -1) – (1/2)E(e t -1e t +1) + (1/4(E(e t-1e t ) – (1/4)E(21t e -) + (1/2)E(e t-2e t+1) – (1/4)E(e t-2e t ) +(1/4)E(e t-2e t-1) = – (1/2)E(2t e ) – (1/4)E(21t e -) = –(1/2) – (1/4) = –3/4; the third to last equality follows because the e t are pairwise uncorrelated and E(2t e ) = 1 for all t . Using Problem 11.1 and the variance calculation from part (i),Corr(x t x t+1) = – (3/4)/(3/2) = –1/2.Computing Cov(x t ,x t+2) is even easier because only one of the nine terms has expectation different from zero: (1/2)E(2t e ) = ½. Therefore, Corr(x t ,x t+2) = (1/2)/(3/2) = 1/3.(iii) Corr(x t ,x t+h ) = 0 for h >2 because, for h > 2, x t+h depends at most on e t+j for j > 0, while x t depends on e t+j , j ≤ 0.(iv) Yes, because terms more than two periods apart are actually uncorrelated, and so it is obvious that Corr(x t ,x t+h ) → 0 as h → ∞.11.3 (i) E(y t ) = E(z + e t ) = E(z ) + E(e t ) = 0. Var(y t ) = Var(z + e t ) = Var(z ) + Var(e t ) + 2Cov(z ,e t ) = 2z σ + 2e σ + 2⋅0 = 2z σ + 2e σ. Neither of these depends on t .(ii) We assume h > 0; when h = 0 we obtain Var(y t ). Then Cov(y t ,y t+h ) = E(y t y t+h ) = E[(z + e t )(z + e t+h )] = E(z 2) + E(ze t+h ) + E(e t z ) + E(e t e t+h ) = E(z 2) = 2z σ because {e t } is an uncorrelated sequence (it is an independent sequence and z is uncorrelated with e t for all t . From part (i) we know that E(y t ) and Var(y t ) do not depend on t and we have shown that Cov(y t ,y t+h ) depends on neither t nor h . Therefore, {y t } is covariance stationary.(iii) From Problem 11.1 and parts (i) and (ii), Corr(y t ,y t+h ) = Cov(y t ,y t+h )/Var(y t ) = 2z σ/(2z σ + 2e σ) > 0.(iv) No. The correlation between y t and y t+h is the same positive value obtained in part (iii) now matter how large is h . In other words, no matter how far apart y t and y t+h are, theircorrelation is always the same. Of course, the persistent correlation across time is due to the presence of the time-constant variable, z .13111.4 Assuming y 0 = 0 is a special case of assuming y 0 nonrandom, and so we can obtain the variances from (11.21): Var(y t ) = 2e σt and Var(y t+h ) = 2e σ(t + h ), h > 0. Because E(y t ) = 0 for all t (since E(y 0) = 0), Cov(y t ,y t+h ) = E(y t y t+h ) and, for h > 0,E(y t y t+h ) = E[(e t + e t-1 + e 1)(e t+h + e t+h -1 + + e 1)]= E(2t e ) + E(21t e -) + + E(21e ) = 2e σt ,where we have used the fact that {e t } is a pairwise uncorrelated sequence. Therefore, Corr(y t ,y t+h ) = Cov(y t ,y t+ht11.5 (i) The following graph gives the estimated lag distribution:wage inflation has its largest effect on price inflation nine months later. The smallest effect is at the twelfth lag, which hopefully indicates (but does not guarantee) that we have accounted for enough lags of gwage in the FLD model.(ii) Lags two, three, and twelve have t statistics less than two. The other lags are statistically significant at the 5% level against a two-sided alternative. (Assuming either that the CLMassumptions hold for exact tests or Assumptions TS.1' through TS.5' hold for asymptotic tests.)132(iii) The estimated LRP is just the sum of the lag coefficients from zero through twelve:1.172. While this is greater than one, it is not much greater, and the difference from unity could be due to sampling error.(iv) The model underlying and the estimated equation can be written with intercept α0 and lag coefficients δ0, δ1, , δ12. Denote the LRP by θ0 = δ0 + δ1 + + δ12. Now, we can write δ0 = θ0 - δ1 - δ2 - - δ12. If we plug this into the FDL model we obtain (with y t = gprice t and z t = gwage t )y t = α0 + (θ0 - δ1 - δ2 - - δ12)z t + δ1z t -1 + δ2z t -2 + + δ12z t -12 + u t= α0 + θ0z t + δ1(z t -1 – z t ) + δ2(z t -2 – z t ) + + δ12(z t -12 – z t ) + u t .Therefore, we regress y t on z t , (z t -1 – z t ), (z t -2 – z t ), , (z t -12 – z t ) and obtain the coefficient and standard error on z t as the estimated LRP and its standard error.(v) We would add lags 13 through 18 of gwage t to the equation, which leaves 273 – 6 = 267 observations. Now, we are estimating 20 parameters, so the df in the unrestricted model is df ur =267. Let 2ur R be the R -squared from this regression. To obtain the restricted R -squared, 2r R , weneed to reestimate the model reported in the problem but with the same 267 observations used toestimate the unrestricted model. Then F = [(2ur R -2r R )/(1 - 2ur R )](247/6). We would find thecritical value from the F 6,247 distribution.[Instructor’s Note: As a computer exercise, you might have the students test whether all 13 lag coefficients in the population model are equal. The restricted regression is gprice on (gwage + gwage -1 + gwage -2 + gwage -12), and the R -squared form of the F test, with 12 and 259 df , can be used.]11.6 (i) The t statistic for H 0: β1 = 1 is t = (1.104 – 1)/.039 ≈ 2.67. Although we must rely on asymptotic results, we might as well use df = 120 in Table G.2. So the 1% critical value against a two-sided alternative is about 2.62, and so we reject H 0: β1 = 1 against H 1: β1 ≠ 1 at the 1% level. It is hard to know whether the estimate is practically different from one withoutcomparing investment strategies based on the theory (β1 = 1) and the estimate (1ˆβ= 1.104). But the estimate is 10% higher than the theoretical value.(ii) The t statistic for the null in part (i) is now (1.053 – 1)/.039 ≈ 1.36, so H 0: β1 = 1 is no longer rejected against a two-sided alternative unless we are using more than a 10% significance level. But the lagged spread is very significant (contrary to what the expectations hypothesis predicts): t = .480/.109≈ 4.40. Based on the estimated equation, when the lagged spread is positive, the predicted holding yield on six-month T-bills is above the yield on three-month T-bills (even if we impose β1 = 1), and so we should invest in six-month T-bills.(iii) This suggests unit root behavior for {hy3t }, which generally invalidates the usual t -testing procedure.133(iv) We would include three quarterly dummy variables, say Q2t , Q3t , and Q4t , and do an F test for joint significance of these variables. (The F distribution would have 3 and 117 df .)11.7 (i) We plug the first equation into the second to gety t – y t-1 = λ(0γ + 1γx t + e t – y t-1) + a t ,and, rearranging,y t = λ0γ + (1 - λ)y t-1 + λ1γx t + a t + λe t ,≡ β0 + β1y t -1 + β2 x t + u t ,where β0 ≡ λ0γ, β1 ≡ (1 - λ), β2 ≡ λ1γ, and u t ≡ a t + λe t .(ii) An OLS regression of y t on y t-1 and x t produces consistent, asymptotically normal estimators of the βj . Under E(e t |x t ,y t-1,x t-1, ) = E(a t |x t ,y t-1,x t-1, ) = 0 it follows that E(u t |x t ,y t-1,x t-1, ) = 0, which means that the model is dynamically complete [see equation (11.37)]. Therefore, the errors are serially uncorrelated. If the homoskedasticity assumption Var(u t |x t ,y t-1) = σ2 holds, then the usual standard errors, t statistics and F statistics are asymptotically valid.(iii) Because β1 = (1 - λ), if 1ˆβ= .7 then ˆλ= .3. Further, 2ˆβ= 1ˆˆλγ, or 1ˆγ= 2ˆβ/ˆλ= .2/.3 ≈ .67.11.8 (i) Sequential exogeneity does not rule out correlation between, say, 1t u - and tj x for anyregressors j = 1, 2, …, k . The differencing generally induces correlation between the differenced errors and the differenced regressors. To see why, consider a single explanatory variable, x t . Then 1t t t u u u -∆=- and 1t t t x x x -∆=-. Under sequential exogeneity, t u is uncorrelated with t x and 1t x -, and 1t u - is uncorrelated with 1t x -. But 1t u - can be correlated with t x , which means that t u ∆ and t x ∆ are generally correlated. In fact, under sequential exogeneity, it is always true that 1Cov(,)Cov(,)t t t t x u x u -∆∆=-.(ii) Strict exogeneity of the regressors in the original equation is sufficient for OLS on the first-differenced equation to be consistent. Remember, strict exogeneity implies that theregressors in any time period are uncorrelated with the errors in any time period. Of course, we could make the weaker assumption: for any t , u t is uncorrelated with 1,t j x -, t j x , and 1,t j x + for all j = 1, 2, …, k . The strengthening beyond sequential exogeneity is the assumption that u t is uncorrelated w ith all of next period’s outcomes on all regressors. In practice, this is probably similar to just assuming strict exogeneity.(iii) If we assume sequential exogeneity in a static model, the condition can be written as。

第7章含有定性信息的多元回归分析:二值(或虚拟)变量7.1 复习笔记考点一:带有虚拟自变量的回归★★★★★1.对定性信息的描述定性信息是指通常以二值信息(0-1)的形式出现的信息,如性别、是否结婚等。
在计量经济学中,二值变量又称为虚拟变量。
2.只有一个虚拟自变量(1)只有一个虚拟自变量的简单模型考虑决定小时工资的简单模型:wage=β0+δ0female+β1educ+u。
根据多元回归的解释方式,δ0表示控制educ不变时,female变化1单位给wage带来的变化。
假定零条件均值假定E(u|female,educ)=0成立,那么:δ0=E(wage|female=1,educ)-E(wage|female=0,educ),其中female=1表示女性,female=0表示男性。
可以发现,在任意教育水平下,男性与女性的工资差异是固定的,女性工资比男性工资多δ0。
除了β0之外,模型中只需要引入一个虚拟变量。
因为female+male=1,所以引入两个虚拟变量会导致完全多重共线性,即虚拟变量陷阱。
(2)当因变量为log(y)时,对虚拟解释变量系数的解释当变量中有一个或多个虚拟变量,且因变量以对数的形式存在时,虚拟变量的系数可以理解为百分比的变化。
将虚拟变量的系数乘以100,表示的是在保持所有其他因素不变时y的百分数差异,精确的百分数差异为:100·[exp (β∧1)-1]。
其中β∧1是一个虚拟变量的系数。
3.使用多类别虚拟变量 (1)在方程中包括虚拟变量的一般原则如果回归模型具有g 组或g 类不同截距,一种方法是在模型中包含g -1个虚拟变量和一个截距。
基组的截距是模型的总截距,某一组的虚拟变量系数表示该组与基组在截距上的估计差异。
如果在模型中引入g 个虚拟变量和一个截距,将会导致虚拟变量陷阱。
另一种方法是只包括g 个虚拟变量,而没有总截距。
这种方法存在两个实际的缺陷:①对于相对基组差别的检验变得更繁琐;②在模型不包含总截距时,回归软件通常都会改变R 2的计算方法。

伍德⾥奇《计量经济学导论》(第6版)复习笔记和课后习题详解-多元回归分析:推断【圣才出品】第4章多元回归分析:推断4.1复习笔记考点⼀:OLS估计量的抽样分布★★★1.假定MLR.6(正态性)假定总体误差项u独⽴于所有解释变量,且服从均值为零和⽅差为σ2的正态分布,即:u~Normal(0,σ2)。
对于横截⾯回归中的应⽤来说,假定MLR.1~MLR.6被称为经典线性模型假定。
假定下对应的模型称为经典线性模型(CLM)。
2.⽤中⼼极限定理(CLT)在样本量较⼤时,u近似服从于正态分布。
正态分布的近似效果取决于u中包含多少因素以及因素分布的差异。
但是CLT的前提假定是所有不可观测的因素都以独⽴可加的⽅式影响Y。
当u是关于不可观测因素的⼀个复杂函数时,CLT论证可能并不适⽤。
3.OLS估计量的正态抽样分布定理4.1(正态抽样分布):在CLM假定MLR.1~MLR.6下,以⾃变量的样本值为条件,有:∧βj~Normal(βj,Var(∧βj))。
将正态分布函数标准化可得:(∧βj-βj)/sd(∧βj)~Normal(0,1)。
注:∧β1,∧β2,…,∧βk的任何线性组合也都符合正态分布,且∧βj的任何⼀个⼦集也都具有⼀个联合正态分布。
考点⼆:单个总体参数检验:t检验★★★★1.总体回归函数总体模型的形式为:y=β0+β1x1+…+βk x k+u。
假定该模型满⾜CLM假定,βj的OLS 量是⽆偏的。
2.定理4.2:标准化估计量的t分布在CLM假定MLR.1~MLR.6下,(∧βj-βj)/se(∧βj)~t n-k-1,其中,k+1是总体模型中未知参数的个数(即k个斜率参数和截距β0)。
t统计量服从t分布⽽不是标准正态分布的原因是se(∧βj)中的常数σ已经被随机变量∧σ所取代。
t统计量的计算公式可写成标准正态随机变量(∧βj-βj)/sd(∧βj)与∧σ2/σ2的平⽅根之⽐,可以证明⼆者是独⽴的;⽽且(n-k-1)∧σ2/σ2~χ2n-k-1。
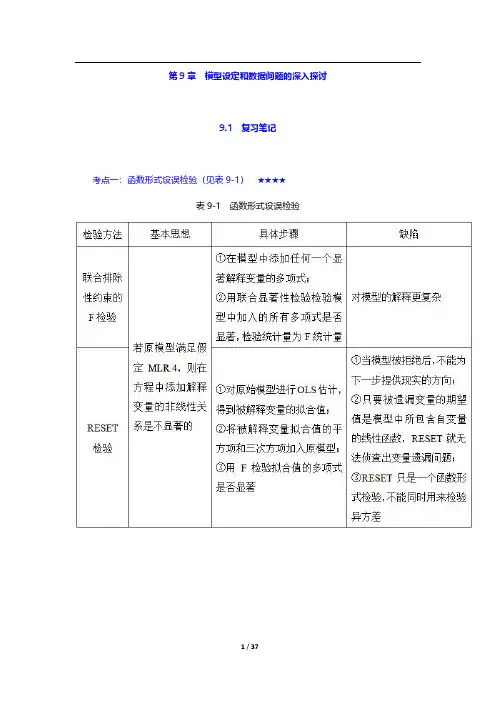
第9章模型设定和数据问题的深入探讨9.1复习笔记考点一:函数形式设误检验(见表9-1)★★★★表9-1函数形式设误检验考点二:对无法观测解释变量使用代理变量★★★1.代理变量代理变量就是某种与分析中试图控制而又无法观测的变量相关的变量。
(1)遗漏变量问题的植入解假设在有3个自变量的模型中,其中有两个自变量是可以观测的,解释变量x3*观测不到:y=β0+β1x1+β2x2+β3x3*+u。
但有x3*的一个代理变量,即x3,有x3*=δ0+δ3x3+v3。
其中,x3*和x3正相关,所以δ3>0;截距δ0容许x3*和x3以不同的尺度来度量。
假设x3就是x3*,做y对x1,x2,x3的回归,从而利用x3得到β1和β2的无偏(或至少是一致)估计量。
在做OLS之前,只是用x3取代了x3*,所以称之为遗漏变量问题的植入解。
代理变量也可以以二值信息的形式出现。
(2)植入解能得到一致估计量所需的假定(见表9-2)表9-2植入解能得到一致估计量所需的假定2.用滞后因变量作为代理变量对于想要控制无法观测的因素,可以选择滞后因变量作为代理变量,这种方法适用于政策分析。
但是现期的差异很难用其他方法解释。
使用滞后被解释变量不是控制遗漏变量的唯一方法,但是这种方法适用于估计政策变量。
考点三:随机斜率模型★★★1.随机斜率模型的定义如果一个变量的偏效应取决于那些随着总体单位的不同而不同的无法观测因素,且只有一个解释变量x,就可以把这个一般模型写成:y i=a i+b i x i。
上式中的模型有时被称为随机系数模型或随机斜率模型。
对于上式模型,记a i=a+c i和b i=β+d i,则有E(c i)=0和E(d i)=0,代入模型得y i=a+βx i+u i,其中,u i=c i+d i x i。
2.保证OLS无偏(一致性)的条件(1)简单回归当u i=c i+d i x i时,无偏的充分条件就是E(c i|x i)=E(c i)=0和E(d i|x i)=E(d i)=0。


伍德里奇计量经济学第六版答案AppendixBAPPENDIX BSOLUTIONS TO PROBLEMSB.1 Before the student takes the SAT exam, we do not know – nor can we predict with certainty – what the score will be. The actual score depends on numerous factors, many of which we cannot even list, let alone know ahead of time. (The student’s innate abil ity, how the student feels on exam day, and which particular questions were asked, are just a few.) The eventual SAT score clearly satisfies the requirements of a random variable.B.2 (i) P(X≤ 6) = P[(X–5)/2 ≤ (6 –5)/2] = P(Z≤ .5) ≈.692, where Z denotes a Normal (0,1) random variable. [We obtain P(Z≤ .5) from Table G.1.](ii) P(X > 4) = P[(X– 5)/2 > (4 – 5)/2] = P(Z > -.5) = P(Z≤ .5) ≈ .692.(iii) P(|X– 5| > 1) = P(X– 5 > 1) + P(X– 5 < –1) = P(X > 6) + P(X < 4) ≈ (1 – .692) + (1 – .692) = .616, where we have used answers from parts (i) and (ii).B.3 (i) Let Y it be the binary variable equal to one if fund i outperforms the market in year t. By assumption, P(Y it = 1) = .5 (a 50-50 chance of outperforming the market for each fund in each year). Now, for any fund, we are also assuming that performance relative to the market is independent across years. But then the probability that fund i outperforms the market in all 10 years, P(Y i1 = 1,Y i2 = 1, , Y i,10 = 1), is just the product of the probabilities: P(Y i1 = 1)?P(Y i2 = 1) P(Y i,10 = 1) = (.5)10 = 1/1024 (which is slightly less than .001). In fact, if we define a binary random variable Y i such that Y i = 1 if and only if fund i outperformed the market in all 10 years, then P(Y i = 1) = 1/1024.(ii) Let X denote the number of funds out of 4,170 that outperform the market in all 10 years. Then X = Y1 + Y2 + + Y4,170. If we assume that performance relative to the market is independent across funds, then X has the Binomial (n,θ) distribution with n = 4,170 and θ =1/1024. We want to compute P(X≥ 1) = 1 – P(X = 0) = 1 –P(Y1 = 0, Y2= 0, …, Y4,170 = 0) = 1 –P(Y1 = 0)? P(Y2 = 0)P(Y4,170 = 0) = 1 –(1023/1024)4170≈.983. This means, if performance relative to the market is random and independent across funds, it is almost certain that at least one fund will outperform the market in all 10 years.(iii) Using the Stata command Binomial(4170,5,1/1024), the answer is about .385. So there is a nontrivial chance that at least five funds will outperform the market in all 10 years.B.4 We want P(X ≥.6). Because X is continuous, this is the same as P(X > .6) = 1 –P(X≤ .6) =F(.6) = 3(.6)2– 2(.6)3 = .648. One way to interpret this is that almost 65% of all counties havean elderly employment rate of .6 or higher.B.5 (i) As stated in the hint, if X is the number of jurors convinced of Simpson’s innocence, then X ~ Binomial(12,.20). We want P(X≥ 1) = 1 – P(X = 0) = 1 –(.8)12≈ .931.263264 (ii) Above, we computed P(X = 0) as about .069. We need P(X = 1), which we obtain from(B.14) with n = 12, θ = .2, and x = 1: P(X = 1) = 12? (.2)(.8)11 ≈ .206. Therefore, P(X ≥ 2) ≈ 1 – (.069 + .206) = .725, so there is almost a three in four chance that the jury had at least two members convinced of Simpson’s innocence prior to the trial.B.6 E(X ) = 30()xf x dx ? = 320[(1/9)] x x dx ? = (1/9) 330x dx ?.But 330x dx ? = (1/4)x 430| = 81/4. Therefore, E(X ) = (1/9)(81/4) = 9/4, or 2.25 years.B.7 In eight attempts the expected number of free throws is 8(.74) = 5.92, or about six free throws.B.8 The weights for the two-, three-, and four-credit courses are 2/9, 3/9, and 4/9, respectively. Let Y j be the grade in the j th course, j = 1, 2, and 3, and let X be the overall grade point average. Then X = (2/9)Y 1 + (3/9)Y 2 + (4/9)Y 3 and the expected value is E(X ) = (2/9)E(Y 1) + (3/9)E(Y 2) + (4/9)E(Y 3) = (2/9)(3.5) + (3/9)(3.0) + (4/9)(3.0) = (7 + 9 + 12)/9 ≈ 3.11.B.9 If Y is salary in dollars then Y = 1000?X , and so the expected value of Y is 1,000 times the expected value of X , and the standard deviation of Y is 1,000 times the standard deviation of X . Therefore, the expected value and standard deviation of salary, measured in dollars, are $52,300 and $14,600, respectively.B.10 (i) E(GPA |SAT = 800) = .70 + .002(800) = 2.3. Similarly, E(GPA |SAT =1,400) = .70 + .002(1400) = 3.5. The difference in expected GPAs is substantial, but the difference in SAT scores is also rather large.(ii) Following the hint, we use the law of iterated expectations. SinceE(GPA |SAT ) = .70 + .002 SAT , the (unconditional) expected value of GPA is .70 + .002 E(SAT ) = .70 + .002(1100) = 2.9.。

第十章一、名词解释1、结构式模型:根据经济理论和行为规律建立的描述经济变量之间直接关系结构的计量经济学方程系统称为结构式模型。
结构式模型中的每一个方程都是结构方程,将一个内生变量表示为其它内生变量、先决变量和随机误差项的函数形式,被称为结构方程的正规形式。
2、先决变量:模型中的外生变量和滞后内生变量被统称为先决变量,其含义是在模型求解时,这些变量已有所赋的值。
3、不可识别:如果联立方程计量经济学模型中某个结构方程不具有确定的统计形式,则称该方程为不可识别。
或者说如果从参数关系体系无法求出其结构方程的参数,则称该方程为不可识别。
如果一个模型系统中存在一个不可识别的随机方程,则认为该联立方程系统是不可识别的。
4、间接最小二乘法:先对关于内生解释变量的简化式方程采用普通最小二乘法估计简化式参数,得到简化式参数估计量,然后通过参数关系体系,计算得到的结构式参数的估计量,这种方法称为间接最小二乘法。
二、判断题1、√2、×3、√4、√5、√6、×7、×8、×三、单项选择题1、C2、B3、A4、 C5、 C6、 B7、B8、B9、B 10、B11、A 12、C 13、C 14、A15、D 16、C 17、C 18、D 19、B 20、B21、B 22、D 23、C 24、A四、多项选择题1、ADF2、ABCDE3、ABE4、ABCE五、简答题1、联立方程计量经济学模型的结构式BΓNY X+=中的第i个方程中包含gi个内生变量和ki 个先决变量,模型系统中内生变量和先决变量的数目用g和k表示,矩阵()BΓ00表示第i个方程中未包含的变量在其它g-1个方程中对应系数所组成的矩阵。
于是,判断第i个结构方程识别状态的结构式条件为:如果R g()BΓ001<-,则第i个结构方程不可识别;如果R g()BΓ001=-,则第i个结构方程可以识别,并且如果k k gi i-=-1,则第i个结构方程恰好识别,如果k k gi i->-1,则第i个结构方程过度识别。
2.10(iii) From (2.57), Var(1ˆβ) = σ2/21()n i i x x =⎛⎫- ⎪⎝⎭∑. 由提示:: 21n ii x =∑ ≥ 21()n i i x x =-∑, and so Var(1β) ≤ Var(1ˆβ). A more direct way to see this is to write(一个更直接的方式看到这是编写) 21()ni i x x =-∑ = 221()n i i x n x =-∑, which is less than21n i i x=∑unless x = 0.(iv)给定的c 2i x 但随着x 的增加, 1ˆβ的方差与Var(1β)的相关性也增加.0β小时1β的偏差也小.因此, 在均方误差的基础上不管我们选择0β还是1β要取决于0β,x ,和n 的大小 (除了 21n i i x=∑的大小).3.7We can use Table 3.2. By definition, 2β > 0, and by assumption, Corr(x 1,x 2) < 0. Therefore, there is a negative bias in 1β: E(1β) < 1β. This means that, on average across different random samples, the simpleregression estimator underestimates the effect of the training program. It is even possible that E(1β) isnegative even though 1β > 0. 我们可以使用表3.2。
根据定义,> 0,由假设,科尔(X1,X2)<0。
因此,有一个负偏压为:E ()<。
这意味着,平均在不同的随机抽样,简单的回归估计低估的培训计划的效果。
第11章OLS用于时间序列数据的其他问题11.1复习笔记考点一:平稳和弱相关时间序列★★★★1.时间序列的相关概念(见表11-1)表11-1时间序列的相关概念2.弱相关时间序列(1)弱相关对于一个平稳时间序列过程{x t:t=1,2,…},随着h的无限增大,若x t和x t+h“近乎独立”,则称为弱相关。
对于协方差平稳序列,如果x t和x t+h之间的相关系数随h的增大而趋近于0,则协方差平稳随机序列就是弱相关的。
本质上,弱相关时间序列取代了能使大数定律(LLN)和中心极限定理(CLT)成立的随机抽样假定。
(2)弱相关时间序列的例子(见表11-2)表11-2弱相关时间序列的例子考点二:OLS的渐近性质★★★★1.OLS的渐近性假设(见表11-3)表11-3OLS的渐近性假设2.OLS的渐近性质(见表11-4)表11-4OLS的渐进性质考点三:回归分析中使用高度持续性时间序列★★★★1.高度持续性时间序列(1)随机游走(见表11-5)表11-5随机游走(2)带漂移的随机游走带漂移的随机游走的形式为:y t=α0+y t-1+e t,t=1,2,…。
其中,e t(t=1,2,…)和y0满足随机游走模型的同样性质;参数α0被称为漂移项。
通过反复迭代,发现y t的期望值具有一种线性时间趋势:y t=α0t+e t+e t-1+…+e1+y0。
当y0=0时,E(y t)=α0t。
若α0>0,y t的期望值随时间而递增;若α0<0,则随时间而下降。
在t时期,对y t+h的最佳预测值等于y t加漂移项α0h。
y t的方差与纯粹随机游走情况下的方差完全相同。
带漂移随机游走是单位根过程的另一个例子,因为它是含截距的AR(1)模型中ρ1=1的特例:y t=α0+ρ1y t-1+e t。
2.高度持续性时间序列的变换(1)差分平稳过程I(1)弱相关过程,也被称为0阶单整或I(0),这种序列的均值已经满足标准的极限定理,在回归分析中使用时无须进行任何处理。
第三篇高级专题第13章跨时横截面的混合:简单面板数据方法13.1复习笔记考点一:跨时独立横截面的混合★★★★★1.独立混合横截面数据的定义独立混合横截面数据是指在不同时点从一个大总体中随机抽样得到的随机样本。
这种数据的重要特征在于:都是由独立抽取的观测所构成的。
在保持其他条件不变时,该数据排除了不同观测误差项的相关性。
区别于单独的随机样本,当在不同时点上进行抽样时,样本的性质可能与时间相关,从而导致观测点不再是同分布的。
2.使用独立混合横截面的理由(见表13-1)表13-1使用独立混合横截面的理由3.对跨时结构性变化的邹至庄检验(1)用邹至庄检验来检验多元回归函数在两组数据之间是否存在差别(见表13-2)表13-2用邹至庄检验来检验多元回归函数在两组数据之间是否存在差别(2)对多个时期计算邹至庄检验统计量的办法①使用所有时期虚拟变量与一个(或几个、所有)解释变量的交互项,并检验这些交互项的联合显著性,一般总能检验斜率系数的恒定性。
②做一个容许不同时期有不同截距的混合回归来估计约束模型,得到SSR r。
然后,对T个时期都分别做一个回归,并得到相应的残差平方和,有:SSR ur=SSR1+SSR2+…+SSR T。
若有k个解释变量(不包括截距和时期虚拟变量)和T个时期,则需检验(T-1)k个约束。
而无约束模型中有T+Tk个待估计参数。
所以,F检验的df为(T-1)k和n-T-Tk,其中n为总观测次数。
F统计量计算公式为:[(SSR r-SSR ur)/SSR ur][(n-T-Tk)/(Tk-k)]。
但该检验不能对异方差性保持稳健,为了得到异方差-稳健的检验,必须构造交互项并做一个混合回归。
4.利用混合横截面作政策分析(1)自然实验与真实实验当某些外生事件改变了个人、家庭、企业或城市运行的环境时,便产生了自然实验(准实验)。
一个自然实验总有一个不受政策变化影响的对照组和一个受政策变化影响的处理组。
自然实验中,政策发生后才能确定处理组和对照组。
伍德里奇计量经济学英文版各章总结(word版可编辑修改)编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望(伍德里奇计量经济学英文版各章总结(word版可编辑修改))的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为伍德里奇计量经济学英文版各章总结(word版可编辑修改)的全部内容。
CHAPTER 1TEACHING NOTESYou have substantial latitude about what to emphasize in Chapter 1。
I find it useful to talk about the economics of crime example (Example 1.1) and the wage example (Example 1.2) so that students see, at the outset,that econometrics is linked to economic reasoning, even if the economics is not complicated theory.I like to familiarize students with the important data structures that empirical economists use, focusing primarily on cross—sectional and time series data sets, as these are what I cover in a first—semester course. It is probably a good idea to mention the growing importance of data sets that have both a cross—sectional and time dimension。
CHAPTER 10TEACHING NOTESBecause of its realism and its care in stating assumptions, this chapter puts a somewhat heavier burden on the instructor and student than traditional treatments of time series regression. Nevertheless, I think it is worth it. It is important that students learn that there are potential pitfalls inherent in using regression with time series data that are not present for cross-sectional applications. Trends, seasonality, and high persistence are ubiquitous in time series data. By this time, students should have a firm grasp of multiple regression mechanics and inference, and so you can focus on those features that make time series applications different from cross-sectional ones.I think it is useful to discuss static and finite distributed lag models at the same time, as these at least have a shot at satisfying the Gauss-Markov assumptions. Many interesting examples have distributed lag dynamics. In discussing the time series versions of the CLM assumptions, I rely mostly on intuition. The notion of strict exogeneity is easy to discuss in terms of feedback. It is also pretty apparent that, in many applications, there are likely to be some explanatory variables that are not strictly exogenous. What the student should know is that, to conclude that OLS is unbiased – as opposed to consistent – we need to assume a very strong form of exogeneity of the regressors. Chapter 11 shows that only contemporaneous exogeneity is needed for consistency. Although the text is careful in stating the assumptions, in class, after discussing strict exogeneity, I leave the conditioning on X implicit, especially when I discuss the no serial correlation assumption. As the absence of serial correlation is a new assumption I spend a fair amount of time on it. (I also discuss why we did not need it for random sampling.)Once the unbiasedness of OLS, the Gauss-Markov theorem, and the sampling distributions under the classical linear model assumptions have been covered – which can be done rather quickly – I focus on applications. Fortunately, the students already know about logarithms and dummy variables. I treat index numbers in this chapter because they arise in many time series examples.A novel feature of the text is the discussion of how to compute goodness-of-fit measures with a trending or seasonal dependent variable. While detrending or deseasonalizing y is hardly perfect (and does not work with integrated processes), it is better than simply reporting the very high R-squareds that often come with time series regressions with trending variables.117118SOLUTIONS TO PROBLEMS10.1 (i) Disagree. Most time series processes are correlated over time, and many of themstrongly correlated. This means they cannot be independent across observations, which simply represent different time periods. Even series that do appear to be roughly uncorrelated – such as stock returns – do not appear to be independently distributed, as you will see in Chapter 12 under dynamic forms of heteroskedasticity.(ii) Agree. This follows immediately from Theorem 10.1. In particular, we do not need the homoskedasticity and no serial correlation assumptions.(iii) Disagree. Trending variables are used all the time as dependent variables in a regression model. We do need to be careful in interpreting the results because we may simply find a spurious association between y t and trending explanatory variables. Including a trend in the regression is a good idea with trending dependent or independent variables. As discussed in Section 10.5, the usual R -squared can be misleading when the dependent variable is trending.(iv) Agree. With annual data, each time period represents a year and is not associated with any season.10.2 We follow the hint and writegGDP t -1 = α0 + δ0int t -1 + δ1int t -2 + u t -1,and plug this into the right-hand-side of the int t equation:int t = γ0 + γ1(α0 + δ0int t-1 + δ1int t-2 + u t-1 – 3) + v t= (γ0 + γ1α0 – 3γ1) + γ1δ0int t-1 + γ1δ1int t-2 + γ1u t-1 + v t .Now by assumption, u t -1 has zero mean and is uncorrelated with all right-hand-side variables in the previous equation, except itself of course. SoCov(int ,u t -1) = E(int t ⋅u t-1) = γ1E(21t u -) > 0because γ1 > 0. If 2u σ= E(2t u ) for all t then Cov(int,u t-1) = γ12u σ. This violates the strictexogeneity assumption, TS.2. While u t is uncorrelated with int t , int t-1, and so on, u t is correlated with int t+1.10.3 Writey* = α0 + (δ0 + δ1 + δ2)z* = α0 + LRP ⋅z *,and take the change: ∆y * = LRP ⋅∆z *.11910.4 We use the R -squared form of the F statistic (and ignore the information on 2R ). The 10% critical value with 3 and 124 degrees of freedom is about 2.13 (using 120 denominator df in Table G.3a). The F statistic isF = [(.305 - .281)/(1 - .305)](124/3) ≈ 1.43,which is well below the 10% cv . Therefore, the event indicators are jointly insignificant at the 10% level. This is another example of how the (marginal) significance of one variable (afdec6) can be masked by testing it jointly with two very insignificant variables.10.5 The functional form was not specified, but a reasonable one islog(hsestrts t ) = α0 + α1t + δ1Q2t + δ2Q3t + δ3Q3t + β1int t +β2log(pcinc t ) + u t ,Where Q2t , Q3t , and Q4t are quarterly dummy variables (the omitted quarter is the first) and the other variables are self-explanatory. This inclusion of the linear time trend allows the dependent variable and log(pcinc t ) to trend over time (int t probably does not contain a trend), and the quarterly dummies allow all variables to display seasonality. The parameter β2 is an elasticity and 100⋅β1 is a semi-elasticity.10.6 (i) Given δj = γ0 + γ1 j + γ2 j 2 for j = 0,1, ,4, we can writey t = α0 + γ0z t + (γ0 + γ1 + γ2)z t -1 + (γ0 + 2γ1 + 4γ2)z t -2 + (γ0 + 3γ1 + 9γ2)z t -3+ (γ0 + 4γ1 + 16γ2)z t -4 + u t = α0 + γ0(z t + z t -1 + z t -2 + z t -3 + z t -4) + γ1(z t -1 + 2z t -2 + 3z t -3 + 4z t -4)+ γ2(z t-1 + 4z t -2 + 9z t -3 + 16z t -4) + u t .(ii) This is suggested in part (i). For clarity, define three new variables: z t 0 = (z t + z t -1 + z t -2 + z t -3 + z t -4), z t 1 = (z t -1 + 2z t -2 + 3z t -3 + 4z t -4), and z t 2 = (z t -1 + 4z t -2 + 9z t -3 + 16z t -4). Then, α0, γ0, γ1, and γ2 are obtained from the OLS regression of y t on z t 0, z t 1, and z t 2, t = 1, 2, , n . (Following our convention, we let t = 1 denote the first time period where we have a full set of regressors.) The ˆj δ can be obtained from ˆj δ= 0ˆγ+ 1ˆγj + 2ˆγj 2.(iii) The unrestricted model is the original equation, which has six parameters (α0 and the five δj ). The PDL model has four parameters. Therefore, there are two restrictions imposed in moving from the general model to the PDL model. (Note how we do not have to actually write out what the restrictions are.) The df in the unrestricted model is n – 6. Therefore, we wouldobtain the unrestricted R -squared, 2ur R from the regression of y t on z t , z t -1, , z t -4 and therestricted R -squared from the regression in part (ii), 2r R . The F statistic is120222()(6).(1)2ur r ur R R n F R --=⋅-Under H 0 and the CLM assumptions, F ~ F 2,n -6.10.7 (i) pe t -1 and pe t -2 must be increasing by the same amount as pe t .(ii) The long-run effect, by definition, should be the change in gfr when pe increasespermanently. But a permanent increase means the level of pe increases and stays at the new level, and this is achieved by increasing pe t -2, pe t -1, and pe t by the same amount.10.8 It is easiest to discuss this question in the context of correlations, rather than conditional means. The solution here does both.(i) Strict exogeneity implies that the error at time t , u t , is uncorrelated with the regressors in every time period: current, past, and future. Sequential exogeneity states that u t is uncorrelated with current and past regressors, so it is implied by strict exogeneity. In terms of conditional means, strict exogeneity is 11E(|...,,,,...)0t t t t u -+=x x x , and so u t conditional on any subset of 11(...,,,,...)t t t -+x x x , including 1(,,...)t t -x x , also has a zero conditional mean. But the lattercondition is the definition of sequential exogeneity.(ii) Sequential exogeneity implies that u t is uncorrelated with x t , x t -1, …, which, of course, implies that u t is uncorrelated with x t (which is contemporaneous exogeneity stated in terms of zero correlation). In terms of conditional means, 1E(|,,...)0t t t u -=x x implies that u t has zero mean conditional on any subset of variables in 1(,,...)t t -x x . In particular, E(|)0t t u =x .(iii) No, OLS is not generally unbiased under sequential exogeneity. To show unbiasedness, we need to condition on the entire matrix of explanatory variables, X , and use E(|)0t u =X for all t . But this condition is strict exogeneity, and it is not implied by sequential exogeneity.(iv) The model and assumption imply1E(|,,...)0t t t u pccon pccon -=,which means that pccon t is sequentially exogenous. (One can debate whether three lags isenough to capture the distributed lag dynamics, but the problem asks you to assume this.) But pccon t may very well fail to be strictly exogenous because of feedback effects. For example, a shock to the HIV rate this year – manifested as u t > 0 – could lead to increased condom usage in the future. Such a scenario would result in positive correlation between u t and pccon t +h for h > 0. OLS would still be consistent, but not unbiased.SOLUTIONS TO COMPUTER EXERCISESC10.1 Let post79 be a dummy variable equal to one for years after 1979, and zero otherwise. Adding post79 to equation 10.15) gives3t i= 1.30 + .608 inf t+ .363 def t+ 1.56 post79t(0.43) (.076) (.120) (0.51)n = 56, R2 = .664, 2R = .644.The coefficient on post79 is statistically significant (t statistic≈ 3.06) and economically large: accounting for inflation and deficits, i3 was about 1.56 points higher on average in years after 1979. The coefficient on def falls once post79 is included in the regression.C10.2 (i) Adding a linear time trend to (10.22) giveslog()chnimp= -2.37 -.686 log(chempi) + .466 log(gas) + .078 log(rtwex)(20.78) (1.240) (.876) (.472)+ .090 befile6+ .097 affile6- .351 afdec6+ .013 t(.251) (.257) (.282) (.004) n = 131, R2 = .362, 2R = .325.Only the trend is statistically significant. In fact, in addition to the time trend, which has a t statistic over three, only afdec6 has a t statistic bigger than one in absolute value. Accounting for a linear trend has important effects on the estimates.(ii) The F statistic for joint significance of all variables except the trend and intercept, of course) is about .54. The df in the F distribution are 6 and 123. The p-value is about .78, and so the explanatory variables other than the time trend are jointly very insignificant. We would have to conclude that once a positive linear trend is allowed for, nothing else helps to explainlog(chnimp). This is a problem for the original event study analysis.(iii) Nothing of importance changes. In fact, the p-value for the test of joint significance of all variables except the trend and monthly dummies is about .79. The 11 monthly dummies themselves are not jointly significant: p-value≈ .59.121C10.3 Adding log(prgnp) to equation (10.38) givesprepop= -6.66 - .212 log(mincov t) + .486 log(usgnp t) + .285 log(prgnp t)log()t(1.26) (.040) (.222) (.080)-.027 t(.005)n = 38, R2 = .889, 2R = .876.The coefficient on log(prgnp t) is very statistically significant (t statistic≈ 3.56). Because the dependent and independent variable are in logs, the estimated elasticity of prepop with respect to prgnp is .285. Including log(prgnp) actually increases the size of the minimum wage effect: the estimated elasticity of prepop with respect to mincov is now -.212, as compared with -.169 in equation (10.38).C10.4 If we run the regression of gfr t on pe t, (pe t-1–pe t), (pe t-2–pe t), ww2t, and pill t, the coefficient and standard error on pe t are, rounded to four decimal places, .1007 and .0298, respectively. When rounded to three decimal places we obtain .101 and .030, as reported in the text.C10.5 (i) The coefficient on the time trend in the regression of log(uclms) on a linear time trend and 11 monthly dummy variables is about -.0139 (se≈ .0012), which implies that monthly unemployment claims fell by about 1.4% per month on average. The trend is very significant. There is also very strong seasonality in unemployment claims, with 6 of the 11 monthly dummy variables having absolute t statistics above 2. The F statistic for joint significance of the 11 monthly dummies yields p-value≈ .0009.(ii) When ez is added to the regression, its coefficient is about -.508 (se≈ .146). Because this estimate is so large in magnitude, we use equation (7.10): unemployment claims are estimated to fall 100[1 – exp(-.508)] ≈ 39.8% after enterprise zone designation.(iii) We must assume that around the time of EZ designation there were not other external factors that caused a shift down in the trend of log(uclms). We have controlled for a time trend and seasonality, but this may not be enough.C10.6 (i) The regression of gfr t on a quadratic in time givesˆgfr= 107.06 + .072 t- .0080 t2t(6.05) (.382) (.0051)n = 72, R2 = .314.Although t and t2 are individually insignificant, they are jointly very significant (p-value≈ .0000).122。