伍德里奇---计量经济学第6章部分计算机习题详解(STATA)
- 格式:pdf
- 大小:808.44 KB
- 文档页数:11

第六章自相关二、问答题1、那些原因可以造成自相关;2、存在自相关时,参数的OLS估计具有哪些性质;3、如何检验是否存在自相关;4、当存在自相关时,如何利用广义差分法进行参数估计;5、当存在自相关时,如何利用广义最小平方估计法进行参数估计;6、异方差与自相关有什么异同;三、计算题1、证明:当样本个数较大时,)d。
≈-1(2ρα2、通过D-W检验,判断下列模型中是否存在自相关,显著性水平%5=(1)样本大小:20;解释变量个数(包括常数项):2;d=0.73;(2)样本大小:35;解释变量个数(包括常数项):3;d=3.56;(3)样本大小:50;解释变量个数(包括常数项):3;d=1.87;(4)样本大小:80;解释变量个数(包括常数项):6;d=1.62;(5)样本大小:100;解释变量个数(包括常数项):5;d=2.41;3、假定存在下表所示的时间序列数据:请回答下列问题:(1)利用表中数据估计模型:t t t x y εββ++=10;(2)利用D-W 检验是否存在自相关?如果存在请用d 值计算估计自相关系数ρ;(3)利用广义差分法重新估计模型:'''1011(1)()t t tt t y y x x ρβρβρε---=-+-+。
第三部分 参考答案二、问答题1、那些原因可以造成自相关?答:造成自相关的原因大致包括以下六个方面:(1)经济变量的变化具有一定的倾向性。
在实际的经济现象中,许多经济变量的现值依赖于他的前期值。
也就是说,许多经济时间序列都有一个明显的相依性特点,这种现象称作经济变量所具有的惯性。
(2)缺乏应有变量的设定偏差。
(3)不正确的函数形式的设定错误。
(4)蛛网现象和滞后效应。
(5)随机误差项的特征。
(6)数据拟合方法造成的影响。
2、存在自相关时,参数的OLS 估计具有哪些性质?答:当存在自相关,即I D ≠ΩΩ=,)(2σε时,OLS 估计的性质有:(1)βˆ是观察值Y 和X 的线性函数;(2)βˆ是β的无偏估计;(3)βˆ的协方差矩阵为112)()()ˆ(--'Ω''=X X X X X X D σβ;(4)βˆ不是β的最小方差线性无偏估计;(5)如果nX X n Ω'∞→lim存在,那么βˆ是β的一致估计;(6)2σ 不是2σ的无偏估计;(7)2σ不是2σ的一致估计。

伍德里奇计量经济学第6章计算机习题详解 STATA引言本文档旨在对伍德里奇计量经济学第6章的计算机习题进行详解和解答,使用计量经济学软件STATA进行操作和分析。
本文档将逐步解答各个习题,并给出相应的STATA代码和结果展示。
习题1假设我们有一个数据集data.dta,其中包含了变量y和x。
现在我们想要估计下列回归模型的系数:$$y = \\beta_0 + \\beta_1 x + \\beta_2 x^2 + u$$使用STATA进行分析,首先加载数据集:use data.dta然后我们可以采用如下代码进行回归分析:reg y x c.x#c.x这里的c.x#c.x表示将变量x进行平方。
执行上述代码后,STATA将输出回归结果。
习题2在第6章的习题2中,我们需要进行假设检验。
假设我们想要检验系数$\\beta_1=0$和$\\beta_2=0$的原假设。
我们可以使用STATA进行对应的假设检验。
首先,我们需要执行回归分析,并保存回归结果:reg y x c.x#c.xestimates store reg1然后,我们可以使用如下代码进行假设检验:test x#c.x=0执行上述代码后,STATA将输出相应的假设检验结果。
习题3在第6章的习题3中,我们需要计算残差的平方和(Sum of Squared Residuals)。
我们可以使用STATA来计算残差的平方和。
首先,我们需要执行回归分析,并保存回归结果:reg y x c.x#c.xestimates store reg1然后,我们可以使用以下代码计算残差的平方和:predict u, residegen ssr = sum(u^2)scalar ssr_sum = r(ssr)执行上述代码后,STATA将输出残差的平方和。
习题4在第6章的习题4中,我们需要计算拟合度(Goodness of Fit)度量指标,如R2,调整后R2等。
我们可以使用STATA计算拟合度指标。

文章主题:探寻计量经济学伍德里奇第六版stata代码的应用与意义1. 引言计量经济学作为经济学的一个重要分支,旨在运用数学、统计学和计算机科学的方法来分析经济问题和经济现象,从而为实证经济研究提供理论和方法。
而伍德里奇的《计量经济学》第六版,作为该领域的经典教材,常常被用来进行实证研究和教学。
在本文中,我们将深入探讨这本教材中的stata代码部分,分析其应用与意义。
2. 计量经济学伍德里奇第六版stata代码的意义在《计量经济学》第六版中,作者伍德里奇通过stata代码来展示实证分析的方法和过程。
这些代码不仅仅是为了教学目的,更重要的是为了让读者能够学会如何用计量经济学的方法来研究实际经济问题。
通过学习这些stata代码,读者可以掌握实证分析的基本技能,了解如何处理实际数据、构建模型、进行估计和推断,从而在实际研究中能够灵活运用计量经济学的方法。
3. 深入理解计量经济学伍德里奇第六版stata代码在伍德里奇的《计量经济学》第六版中,stata代码涵盖了从简单的OLS回归分析到复杂的面板数据模型的估计方法,涉及了各种实证问题和分析工具。
通过深入学习这些代码,读者可以逐步理解和掌握计量经济学的核心内容,包括数据的处理与清洗、模型的构建与估计、假设检验与推断等方面的知识和技能。
这样的深入理解将使读者能够更好地应用计量经济学的方法来解决实际经济问题,并且能够进行批判性思考和创新性研究。
4. 个人观点和理解作为一名计量经济学的研究者和教学者,我深切理解学习和掌握计量经济学伍德里奇第六版stata代码的重要性。
这些代码不仅仅是一种工具,更是一种思维方式和方法论,是我们用来研究经济现象和问题的利器。
通过不断地学习和实践,我相信我们能够更好地理解和应用计量经济学的方法,为经济学研究和实践带来更多的启发和进步。
5. 总结通过本文的探讨,我们深入了解了《计量经济学》第六版中stata代码的应用与意义。
这些代码的存在不仅仅是为了让我们学会如何进行实证分析,更重要的是让我们深刻理解和掌握计量经济学的思想和方法。

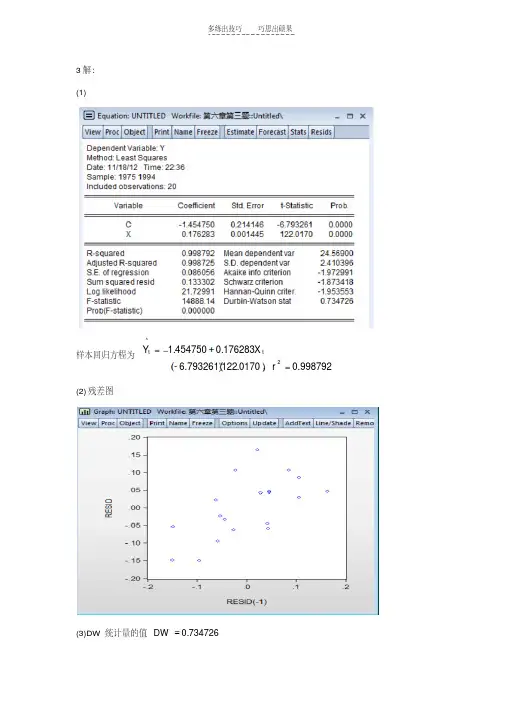
3解:(1)样本回归方程为998792.00170.1226.793261-176283.0454750.12^t r X Y t,(2)残差图(3)DW 统计量的值734726.0DW(4)BG LM 自相关检验辅助回归式估计结果是t t t tX e e 000420.0060923.0638831.01因为84.3998223.7,84.31205.0LM ,所以LM 检验量也说明样本回归方程的误差项存在一阶正自相关。
首先估计自相关系数^,得632637.02734726.0121^DW 对原变量做广义差分变换。
令1t 632637.0t t Y Y GDY ,1t 632637.0t t X X GDX 以年1994~1975,,t t GDX GDY 为样本再次回归,得tGDX GDY 173740.0391490.0t 回归方程拟合的效果仍然比较好,651914.1DW 对于给定05.0,查表得,。
43.1,24.1U L d d 因为75.243.11651914.1DW ,依据判别规则,误差项已消除自相关。
由391490.0^*0,得06568.1632637.01/391490.01/^^*0^0则原模型的广义最小二乘估计结果是t X Y 173470.006568.1^t 。
4解:(1)样本回归方程为tGDP Y 694454.0674.2816^t(2)残差图(3)3397.0DW(4)BG LM 自相关检验辅助回归式估计结果是t t t tGDP e e 029062.07871.334985257.01因为84.309615.30,84.31205.0LM ,所以LM 检验量也说明样本回归方程的误差项存在一阶正自相关。
首先估计自相关系数^,得83015.023397.0121^DW对原变量做广义差分变换。
令1t 83015.0t t Y Y GDY ,183015.0t t tGDGDP GDP GDGDP ,以年1994~1975,,t t GDGDP GDY 为样本再次回归,得。

第1章计量经济学的性质与经济数据1.1复习笔记考点一:计量经济学★1计量经济学的含义计量经济学,又称经济计量学,是由经济理论、统计学和数学结合而成的一门经济学的分支学科,其研究内容是分析经济现象中客观存在的数量关系。
2计量经济学模型(1)模型分类模型是对现实生活现象的描述和模拟。
根据描述和模拟办法的不同,对模型进行分类,如表1-1所示。
(2)数理经济模型和计量经济学模型的区别①研究内容不同数理经济模型的研究内容是经济现象各因素之间的理论关系,计量经济学模型的研究内容是经济现象各因素之间的定量关系。
②描述和模拟办法不同数理经济模型的描述和模拟办法主要是确定性的数学形式,计量经济学模型的描述和模拟办法主要是随机性的数学形式。
③位置和作用不同数理经济模型可用于对研究对象的初步研究,计量经济学模型可用于对研究对象的深入研究。
考点二:经济数据★★★1经济数据的结构(见表1-3)2面板数据与混合横截面数据的比较(见表1-4)考点三:因果关系和其他条件不变★★1因果关系因果关系是指一个变量的变动将引起另一个变量的变动,这是经济分析中的重要目标之计量分析虽然能发现变量之间的相关关系,但是如果想要解释因果关系,还要排除模型本身存在因果互逆的可能,否则很难让人信服。
2其他条件不变其他条件不变是指在经济分析中,保持所有的其他变量不变。
“其他条件不变”这一假设在因果分析中具有重要作用。
1.2课后习题详解一、习题1.假设让你指挥一项研究,以确定较小的班级规模是否会提高四年级学生的成绩。
(i)如果你能指挥你想做的任何实验,你想做些什么?请具体说明。
(ii)更现实地,假设你能搜集到某个州几千名四年级学生的观测数据。
你能得到它们四年级班级规模和四年级末的标准化考试分数。
你为什么预计班级规模与考试成绩成负相关关系?(iii)负相关关系一定意味着较小的班级规模会导致更好的成绩吗?请解释。
答:(i)假定能够随机的分配学生们去不同规模的班级,也就是说,在不考虑学生诸如能力和家庭背景等特征的前提下,每个学生被随机的分配到不同的班级。

第六章 经典联立方程计量经济学模型:理论与方法一、内容提要联立方程计量经济学模型是相对于单一方程模型提出来的,旨在在讨论多个经济变量相互影响的错综复杂的运行规律,或者说讨论多个内生变量被联立决定的问题。
本章学习内容的一个重点是关于联立方程计量经济学模型区别于单方程模型的若干基本概念,包括内生变量、外生变量、前定变量的概念;结构式模型、简化式模型的概念;随机方程、恒等方程的概念;行为方程、技术方程、制度方程、统计方程、定义方程、平衡方程等相关概念。
本章学习的另一个重点是联立模型的识别问题。
需掌握模型识别的基本概念、模型识别的类型(不可识别、恰好识别、过渡识别)、模型的结构式识别条件、模型的简化式识别条件以及实际应用中的经验识别方法。
本章学习的第三个重点是联立模型的估计问题。
首先明确联立模型估计时会遇到的三个方面的问题。
一是随机解释变量问题,即模型中的某些解释变量也能是与随机扰动项相关的随机解释变量;二是损失变量信息的问题,即以单方程方法估计模型时会损失其他方程变量所提供的信息;三是损失方程之间的相关性信息问题,即以单方程方法估计模型时会损失不同方程随机扰动项间的相关性方面的一些信息。
其次,需要掌握联立模型两大类估计方法中的主要估计方法,如单方程估计方法中的狭义工具变量法(IV )、间接最小二乘法(ILS )、二阶段最小二乘法(2SLS ),系统估计方法中的三阶段最小二乘法(3SLS )等。
本章学习中不容忽视的还有联立方程计量经济学模型估计方法的比较,以及联立方程模型的检验问题。
前者需要考察大样本估计量特性与小样本估计量的特性;后者包括拟合效果检验、预测性检验、方程间误差传递检验等方面的内容。
二、典型例题分析1、如果我们将“供给”1Y 与“需求”2Y 写成如下的联立方程的形式:222221111211u Z Y Y u Z Y Y ++=++=βαβα其中,1Z 、2Z 为外生变量。
(1)若01=α或02=α,解释为什么存在1Y 的简化式?若01≠α、02=α,写出2Y 的简化式。

伍德里奇计量经济学导论第6版考研笔记和课后习题详解伍德里奇《计量经济学导论》(第6版)笔记和课后习题详解内容简介伍德里奇所著的《计量经济学导论》(第6版)是我国许多高校采用的计量经济学优秀教材,也被部分高校指定为“经济类”专业考研考博参考书目。
本书遵循伍德里奇《计量经济学导论》(第6版)教材的章目编排,共分3篇19章,每章由两部分组成:第一部分为复习笔记,总结本章的重难点内容;第二部分为课(章)后习题详解,对第6版的所有课(章)后习题都进行了详细的分析和解答。
作为该教材的学习辅导书,本书具有以下几个方面的特点:(1)整理名校笔记,浓缩内容精华。
每章的复习笔记以伍德里奇所著的《计量经济学导论》(第6版)为主,并结合国内外其他计量经济学经典教材对各章的重难点进行了整理,因此,本书的内容几乎浓缩了经典教材的知识精华。
(2)解析课后习题,提供详尽答案。
本书参考大量经济学相关资料对伍德里奇所著的《计量经济学导论》(第6版)的课(章)后习题进行了详细的分析和解答,并对相关重要知识点进行了延伸和归纳。
(3)补充相关要点,强化专业知识。
一般来说,国外英文教材的中译本不太符合中国学生的思维习惯,有些语言的表述不清或条理性不强而给学习带来了不便,因此,对每章复习笔记的一些重要知识点和一些习题的解答,我们在不违背原书原意的基础上结合其他相关经典教材进行了必要的整理和分析。
•试看部分内容第1章计量经济学的性质与经济数据1.1复习笔记考点一:计量经济学及其应用★1计量经济学计量经济学是在一定的经济理论基础之上,采用数学与统计学的工具,通过建立计量经济模型对经济变量之间的关系进行定量分析的学科。
进行计量分析的步骤主要有:①利用经济数据对模型中的未知参数进行估计;②对模型进行检验;③通过检验后,可以利用计量模型来进行相关预测。
2经济分析的步骤经济分析是指利用所搜集的相关数据检验某个理论是否成立或估计某种关系的方法。
经济分析主要包括以下几步,分别是阐述问题、构建经济模型、经济模型转化为计量模型、搜集相关数据、参数估计和假设检验。
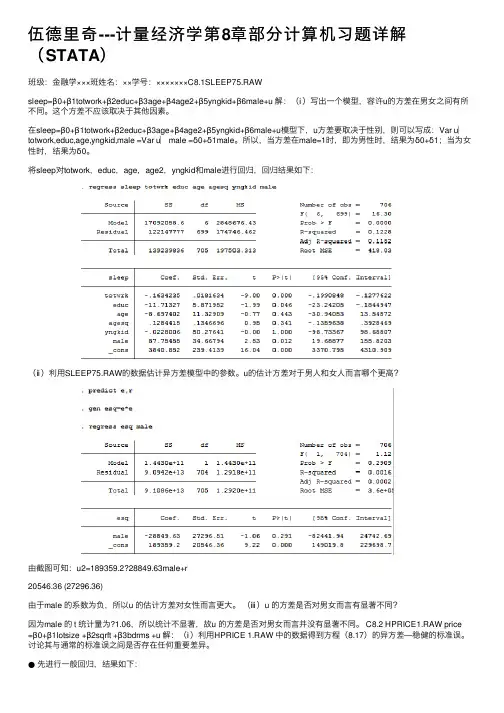
伍德⾥奇---计量经济学第8章部分计算机习题详解(STATA)班级:⾦融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAWsleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出⼀个模型,容许u的⽅差在男⼥之间有所不同。
这个⽅差不应该取决于其他因素。
在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u⽅差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。
所以,当⽅差在male=1时,即为男性时,结果为δ0+δ1;当为⼥性时,结果为δ0。
将sleep对totwork,educ,age,age2,yngkid和male进⾏回归,回归结果如下:(ⅱ)利⽤SLEEP75.RAW的数据估计异⽅差模型中的参数。
u的估计⽅差对于男⼈和⼥⼈⽽⾔哪个更⾼?由截图可知:u2=189359.2?28849.63male+r20546.36 (27296.36)由于male 的系数为负,所以u 的估计⽅差对⼥性⽽⾔更⼤。
(ⅲ)u 的⽅差是否对男⼥⽽⾔有显著不同?因为male 的 t 统计量为?1.06,所以统计不显著,故u 的⽅差是否对男⼥⽽⾔并没有显著不同。
C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利⽤HPRICE 1.RAW 中的数据得到⽅程(8.17)的异⽅差—稳健的标准误。
讨论其与通常的标准误之间是否存在任何重要差异。
●先进⾏⼀般回归,结果如下:●再进⾏稳健回归,结果如下:由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms29.48 0.00064 0.013 (9.01)37.13 0.00122 0.018 [8.48]n =88,R 2=0.672⽐较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较⼤。

(完整版)计量经济学(伍德里奇第五版中文版)答案第1章解决问题的办法1.1(一)理想的情况下,我们可以随机分配学生到不同尺寸的类。
也就是说,每个学生被分配一个不同的类的大小,而不考虑任何学生的特点,能力和家庭背景。
对于原因,我们将看到在第2章中,我们想的巨大变化,班级规模(主题,当然,伦理方面的考虑和资源约束)。
(二)呈负相关关系意味着,较大的一类大小是与较低的性能。
因为班级规模较大的性能实际上伤害,我们可能会发现呈负相关。
然而,随着观测数据,还有其他的原因,我们可能会发现负相关关系。
例如,来自较富裕家庭的儿童可能更有可能参加班级规模较小的学校,和富裕的孩子一般在标准化考试中成绩更好。
另一种可能性是,在学校,校长可能分配更好的学生,以小班授课。
或者,有些家长可能会坚持他们的孩子都在较小的类,这些家长往往是更多地参与子女的教育。
(三)鉴于潜在的混杂因素- 其中一些是第(ii)上市- 寻找负相关关系不会是有力的证据,缩小班级规模,实际上带来更好的性能。
在某种方式的混杂因素的控制是必要的,这是多元回归分析的主题。
1.2(一)这里是构成问题的一种方法:如果两家公司,说A和B,相同的在各方面比B公司à用品工作培训之一小时每名工人,坚定除外,多少会坚定的输出从B公司的不同?(二)公司很可能取决于工人的特点选择在职培训。
一些观察到的特点是多年的教育,多年的劳动力,在一个特定的工作经验。
企业甚至可能歧视根据年龄,性别或种族。
也许企业选择提供培训,工人或多或少能力,其中,“能力”可能是难以量化,但其中一个经理的相对能力不同的员工有一些想法。
此外,不同种类的工人可能被吸引到企业,提供更多的就业培训,平均,这可能不是很明显,向雇主。
(iii)该金额的资金和技术工人也将影响输出。
所以,两家公司具有完全相同的各类员工一般都会有不同的输出,如果他们使用不同数额的资金或技术。
管理者的素质也有效果。
(iv)无,除非训练量是随机分配。
第六章1、答:给定显著水平α,依据样本容量n 和解释变量个数k’,查D.W.表得d 统计量的上界du 和下界dL ,当0<d<dL 时,表明存在一阶正自相关,而且正自相关的程度随d 向0的靠近而增强。
当dL<d<du 时,表明为不能确定存在自相关。
当du<d<4-du 时,表明不存在一阶自相关。
当4-du<d<4-dL 时,表明不能确定存在自相关。
当4-dL<d<4时,表明存在一阶负自相关,而且负自相关的程度随d 向4的靠近而增强。
前提条件:DW 检验的前提条件:(1)回归模型中含有截距项;(2)解释变量是非随机的(因此与随机扰动项不相关)(3)随机扰动项是一阶线性自相关。
;(4)回归模型中不把滞后内生变量(前定内生变量)做为解释变量。
(5)没有缺失数据,样本比较大。
DW 检验的局限性:(1)DW 检验有两个不能确定的区域,一旦DW 值落在这两个区域,就无法判断。
这时,只有增大样本容量或选取其他方法(2)DW 统计量的上、下界表要求n ≥15, 这是因为样本如果再小,利用残差就很难对自相关的存在性做出比较正确的诊断(3) DW 检验不适应随机误差项具有高阶序列相关的检验.(4) 只适用于有常数项的回归模型并且解释变量中不能含滞后的被解释变量2、答:(1)当回归模型随机误差项有自相关时,普通最小二乘估计量是有偏误的和非有效的。
判断:错误。
当回归模型随机误差项有自相关时,普通最小二乘估计量是无偏误的和非有效的。
(2)DW 检验假定随机误差项u i 的方差是同方差。
判断:错误。
DW 统计量的构造中并没有要求误差项的方差是同方差 。
(3)用一阶差分法消除自相关是假定自相关系数为-1。
判断:错误。
用一阶差分法消除自相关是假定自相关系数为1,即原原模型存在完全一阶正自相关。
(4)当回归模型随机误差项有自相关时,普通最小二乘估计的预测值的方差和标准误差不再是有效的。
第三篇高级专题第13章跨时横截面的混合:简单面板数据方法13.1复习笔记考点一:跨时独立横截面的混合★★★★★1.独立混合横截面数据的定义独立混合横截面数据是指在不同时点从一个大总体中随机抽样得到的随机样本。
这种数据的重要特征在于:都是由独立抽取的观测所构成的。
在保持其他条件不变时,该数据排除了不同观测误差项的相关性。
区别于单独的随机样本,当在不同时点上进行抽样时,样本的性质可能与时间相关,从而导致观测点不再是同分布的。
2.使用独立混合横截面的理由(见表13-1)表13-1使用独立混合横截面的理由3.对跨时结构性变化的邹至庄检验(1)用邹至庄检验来检验多元回归函数在两组数据之间是否存在差别(见表13-2)表13-2用邹至庄检验来检验多元回归函数在两组数据之间是否存在差别(2)对多个时期计算邹至庄检验统计量的办法①使用所有时期虚拟变量与一个(或几个、所有)解释变量的交互项,并检验这些交互项的联合显著性,一般总能检验斜率系数的恒定性。
②做一个容许不同时期有不同截距的混合回归来估计约束模型,得到SSR r。
然后,对T个时期都分别做一个回归,并得到相应的残差平方和,有:SSR ur=SSR1+SSR2+…+SSR T。
若有k个解释变量(不包括截距和时期虚拟变量)和T个时期,则需检验(T-1)k个约束。
而无约束模型中有T+Tk个待估计参数。
所以,F检验的df为(T-1)k和n-T-Tk,其中n为总观测次数。
F统计量计算公式为:[(SSR r-SSR ur)/SSR ur][(n-T-Tk)/(Tk-k)]。
但该检验不能对异方差性保持稳健,为了得到异方差-稳健的检验,必须构造交互项并做一个混合回归。
4.利用混合横截面作政策分析(1)自然实验与真实实验当某些外生事件改变了个人、家庭、企业或城市运行的环境时,便产生了自然实验(准实验)。
一个自然实验总有一个不受政策变化影响的对照组和一个受政策变化影响的处理组。
自然实验中,政策发生后才能确定处理组和对照组。
clear,clc;% c6.13 by% 打开文字文件和数据文件importdata('meap00_01.des');data=xlsread('meap00_01');% 检验所用数据是否为非空Isnan=isnan(data(:,[3,5,8,9]));a=sum(Isnan')';b=find(a==0);data1=data(b,:);% 变量命名math4=data1(:,3);lunch=data1(:,5);lenroll=data1(:,8);lexppp=data1(:,9);% OLS估计result1=ols(math4,[ones(length(math4),1),lunch,lenroll,lexppp]);vnames=char('math4','constant','lunch','lenroll','lexppp');prt(result1,vnames)% 回归结果% Ordinary Least-squares Estimates% Dependent Variable = math4% R-squared = 0.3729% Rbar-squared = 0.3718% sigma^2 = 234.1638% Durbin-Watson = 1.7006% Nobs, Nvars = 1692, 4% ***************************************************************% Variable Coefficient t-statistic t-probability% constant 91.932484 4.605444 0.000004% lunch -0.448743 -30.647631 0.000000% lenroll -5.399153 -5.741265 0.000000% lexppp 3.524742 1.680172 0.093109% 由回归结果中的p值发现lunch,lenroll是在5%的水平上显著的,而lexppp在5%水平上不显著,% 但在10%的显著水平上是显著的.% 求出回归的拟合值及其取值范围yhat=result1.yhat;std_yhat=std(yhat);mean_yhat=mean(yhat);yhat_qujian=[mean_yhat-2*std_yhat,mean_yhat+2*std_yhat]% yhat的取值范围是(49.1090 ,96.2665)% 求出math4的实际取值范围math4_qujian=[min(math4),max(math4)]% math4的实际取值范围是(0 ,100),可见拟合值的取值范围要比实际范围窄% 求出回归残差resid=result1.resid;max_resid=max(resid);row=find(resid==max_resid)school_code=data1(row,2)% 学校类型是school_code=1141,说明该学校的实际数学考试通过率要比估计的数学考试通% 过率高很多,也就这所学校的数学教学质量较高% 求取解释变量数据的平方项lenroll2=lenroll.^2;lexppp2=lexppp.^2;lunch2=lunch.^2;%在方程中加入所有解释变量的平方项进行回归result2=ols(math4,[ones(length(math4),1),lunch,lenroll,lexppp,lunch2,lenroll2,lexppp2]); vnames=char('math4','constant','lunch','lenroll','lexppp','lunch2','lenroll2','lexppp2');prt(result2,vnames)% 检验联合显著性rsqr1=result1.rsqr;rsqr2=result2.rsqr;F=((rsqr2-rsqr1)/3)/((1-rsqr2)/(1692-6-1))p=1-fcdf(F,3,1685)% F =0.5180% p =0.6699% 所以这几个解释变量的平方项是联合不显著的,所以不应该把他们放到模型中% 求所用数据值除以其标准差lenroll_new=lenroll/std(lenroll);lunch_new=lunch/std(lunch);lexppp_new=lexppp/std(lexppp);math4_new=math4/std(math4);% 重新进行回归result3=ols(math4_new,[ones(length(math4_new),1),lunch_new,lenroll_new,lexppp_new]); vnames=char('math4_new','constant','lunch_new','lenroll_new','lexppp_new');prt(result3,vnames)% 回归结果% Ordinary Least-squares Estimates% Dependent Variable = math4_new% R-squared = 0.3729% Rbar-squared = 0.3718% sigma^2 = 0.6282% Durbin-Watson = 1.7006% Nobs, Nvars = 1692, 4% ***************************************************************% Variable Coefficient t-statistic t-probability% constant 4.761759 4.605444 0.000004% lunch_new -0.612853 -30.647631 0.000000% lenroll_new -0.114620 -5.741265 0.000000% lexppp_new 0.034743 1.680172 0.093109% 由结果lunch,lenroll和lexppp分别提高一倍,会使数学通过率分别变化0.613,0.115和% 0.035个标准差,所以lunch对数学考试通过率影响最大。
班级:金融学×××班姓名:××学号:×××××××C6.9 NBASAL.RAW points=β0+β1exper+β2exper2+β3age+β4coll+u 解:(ⅰ)按照通常的格式报告结果。
由上图可知:points=35.22+2.364exper−0.077exper2−1.074age−1.286coll6.9870.4050.02350.295 (0.451)n=269,R2=0.1412,R2=0.1282。
(ⅱ)保持大学打球年数和年龄不变,从加盟的第几个年份开始,在NBA打球的经历实际上将降低每场得分?这讲得通吗?由上述估计方程可知,转折点是exper的系数与exper2系数的两倍之比:exper∗= β12β2= 2.364[2×−0.077]=15.35,即从加盟的第15个到第16个年份之间,球员在NBA打球的经历实际上将降低每场得分。
实际上,在模型所用的数据中,269名球员中只有2位的打球年数超过了15年,数据代表性不大,所以这个结果讲不通。
(ⅲ)为什么coll具有负系数,而且统计显著?一般情况下,NBA运动员的球员都会在读完大学之前被选拔出,甚至从高中选出,所以这些球员在大学打球的时间少,但每场得分却很高,所以coll具有负系数。
同时,coll的t统计量为-2.85,所以coll统计显著。
(ⅳ)有必要在方程中增加age的二次项吗?控制exper和coll之后,这对年龄效应意味着什么?增加age的二次项后,原估计模型变成:points=73.59+2.864exper−0.128exper2−3.984age+0.054age2−1.313coll35.930.610.05 2.690.05 (0.45)n=269,R2=0.1451,R2=0.1288。
由方程可知:age的t统计量为−1.48,age2的t统计量为1.09,所以age和age的二次项统计都不显著,而当不增加age2时,age的t统计量为−3.64,统计显著,因此完全没有必要在方程中增加age的二次项。
当控制了exper和coll之后,年龄对points的负效应将会增大。
(ⅴ)现在将log(wage)对points,exper,exper2,age和coll回归。
以通常的格式报告结论。
所以,log wage=6.78+0.078points+0.218exper−0.0071exper2−0.048age−0.040coll0.850.0070.0500.00280.035 (0.053)n=269,R2=0.4878,R2=0.4781。
(ⅵ)在第(ⅴ)部分的回归中检验age和coll是否联合显著。
一旦控制了生产力和资历,这对考察年龄和受教育程度是否对工资具有单独影响这个问题有何含义?F统计量为1.19,F的p值为0.3061,所以检验age和coll不是联合显著的。
因此,一旦控制了生产力和资历,当考察年龄和受教育程度是否对工资具有单独影响这个问题时,不能说明其对工资差异有明显的效应。
C6.9 BWGHT2.RAW log bwght=β0+β1npvis+β2npvis2+u 解:(ⅰ)按照通常的格式报告结果,二次项显著吗?由上图可知:log(bwg t)=7.958+0.0189npvis−0.00043npvis20.0270.00370.00012n=1764,R2=0.0213,R2=0.0201。
因为npvis2的t统计量为−3.57,所以二次项显著。
(ⅱ)基于(ⅰ)中的方程,证明:最大化log(bwg t)的产前检查次数为22。
样本中有多少妇女至少接受过22次产前检查?由上述估计方程可知,转折点是npvis的系数与npvis2系数的两倍之比:npvis∗= β12β2= 0.0189[2×−0.00043]=21.98,所以最大化log(bwg t)的产前检查次数为22。
由截图可知,样本中有89位妇女至少接受过22次产前检查。
(ⅲ)在22次产前检查之后,预计婴儿出生体重实际上会下降,这有意义吗?请解释。
有意义,因为如果产前检查次数太多,表明生育过程可能有困难,所以婴儿的体重可能会下降。
(ⅳ)在方程增加母亲年龄,并使用二次函数形式。
保持npvis不变,目前在什么年龄,孩子的出生体重最大?样本中有多大比率的妇女年龄大于这个“最优”生育年龄?所以,log bwg t=7.584+0.0180npvis−0.00041npvis2+0.0254mage−0.00041mage20.1370.00370.000120.0093 (0.00015)n=1764,R2=0.0256,R2=0.0234。
当孩子的出生体重最大时,对应的年龄为mage∗= β12β2=0.0254[2×−0.00041]= 30.96,即保持npvis不变的情况下,在31岁时孩子的出生体重最大。
由左图可得:样本中有605位妇女年龄大于这个“最优”生育年龄,而有746位妇女年龄大于等于这个“最优”生育年龄。
(ⅴ)你认为母亲年龄和产前检查次数解释了log bwg t中的大部分变异吗?由(ⅳ)中方程可知,母亲年龄和产前检查次数只解释了log bwg t的2.56%的变异,所以解释程度十分小,并没有解释大部分变异。
(ⅵ)确定用bwg t的自然对数或水平值来预测bwg t孰优孰劣?用bwg t的水平值作为因变量时,回归结果如下所示:其对应的R2=0.0192,用bwg t的水平值来预测bwg t更好。
C6.11 APPLE.RAW ecolbs=β0+β1ecoprc+β2regprc+u 解:(ⅰ)以通常的格式报告结论,包括R2和R2。
解释价格变量的系数,并评论他们的符号和大小。
由上图可知:ecolbs=1.97−2.93ecoprc+3.03regprc0.380.590.71n=660,R2=0.0364,R2=0.0335。
ecoprc的系数表示当regprc不变时,ecoprc提高10%,生态标记的苹果的需求数量将会降低0.293lbs;regprc的系数表示当ecoprc固定不变时,regprc提高10%,生态标记苹果的需求数量将会增加0.303lbs。
由上面分析可知,ecoprc和regprc对生态标记苹果需求变化量的标记效应大小差不多,但是系数符号相反。
(ⅱ)价格变量统计显著吗?报告个别t检验的p值。
由于ecoprc和regprc对应的t统计量分别为−4.98和4.26,所以两个价格变量都统计显著,p值全部为0。
(ⅲ)ecolbs拟合值的范围是多少?样本报告ecolbs=0比例是多少?请评论。
所以,ecolbs拟合值的范围是[0.855,2.087],样本报告ecolbs =0的数据有248个,当ecolbs =0时,需求量为0,说明这些观测值在模型中没有被很好地解释。
(ⅳ)你认为价格变量很好地解释了ecolbs 中的变异吗?请解释。
两个价格变量(ecoprc 和regprc )只解释了ecolbs 中变异的3.6%,解释程度很小,所以价格变量并没有很好地解释了ecolbs 中的变异。
(ⅴ)增加变量faminc , size 家庭规模 ,educ 和age 。
求它们联合显著的p 值。
你得到什么结论?C6.12 401KSUBS .RAW nettfa =β0+β1inc +β2age +β3age2+u解:(ⅰ)样本中最年轻的人多少岁?这个年龄的有多少人?所以,样本中最年轻的人有25岁,并且处于这个年龄的人有99人。
由截图可得:联合显著的p 值为0.6286,所以变量faminc , size 家庭规模 ,educ 和age 联合不显著,不应该放入同一个回归模型中。
(ⅱ)β2的字面解释是什么?它本身有什么意义吗?=β2+2β3age,所以β2的字面解释是从age=0到age=1的近似斜率。
它本身并由于ðnettfaðage没有意义,因为样本中最年轻的人都有25岁,所以从age=0开始考察偏效应,完全没有意义。
(ⅲ)估计第(ⅱ)部分的模型,并以标准形式报告结果。
你关心age的系数为负吗?请解释。
由上图可知:nettfa=−1.20+0.825inc−1.322age+0.0256age215.280.0600.767 (0.0090)n=2017,R2=0.1229,R2=0.1216。
由上述估计方程可知:转折点为age的系数与age2系数的两倍之比:age∗= β12β2= (−1.322)(2×0.0256)=25.82,即年龄从26岁起,净总金融资产会随着年龄的增长增加。
而样本中被调查的人群最低年龄都为25岁,所以结果符合预期猜想,没有必要在意age的系数为负。
(ⅳ)若认为给定收入水平下,25岁时净总金融资产的平均量最低,这有意义吗?记得age对nettfa的偏效应为β2+2β3age,所以在25岁时的偏效应为β2+2β325=β2+50β3;称之为θ2。
求θ2并得到检验H0:θ2=0的双侧p值。
你应该得到θ2很小且在统计上也不显著的结论。
定义一个新的变量age0sq并进行回归,结果如下:由上图可知:nettfa=−17.18+0.825inc−0.0437age+0.0256(age−25)29.970.0600.325 (0.0090)n =2017,R 2=0.1229,R2=0.1216。
由(ⅲ)估计方程可知,θ2=β2+2β3 25 =β2+50β3=−0.042,和方程中−0.0437差不多。
同时,检验H 0:θ2=0的双侧p 值为0.893,θ 2的t 统计量为-0.13,所以θ 2很小且在统计上也不显著。
(ⅴ)估计模型nettfa =α0+β1inc +β3(age −25)2+u ,根据拟合优度,这个模型比第(ⅱ)部分中的模型拟合的更好吗?由上图可知:nettfa =−18.49+0.824inc +0.0244(age −25)22.18 0.060 (0.0025)n =2017,R 2=0.1229,R2=0.1220。
因为age 统计不显著,当把age 从模型中删除后,调整的R 2稍微提高了一点,所以这个模型比第(ⅱ)部分中的模型拟合的更好,解释效果更好。
(ⅵ)对第(ⅴ)部分中估计的方程,令inc =30(大致为平均值),画图给出nettfa 和age 的关系,但仅限于age ≥25。
描述你所看到的情况。
nettfa 和age 的关系如左图所示。