第10章 典型相关分析
- 格式:ppt
- 大小:171.00 KB
- 文档页数:35


大数据解析与应用导论知到章节测试答案智慧树2023年最新浙江大学第一章测试1.下列属于多元统计方法的为()参考答案:回归分析;主元分析2.多元统计分析的图表示法有()参考答案:散布图矩阵;调和曲线图;轮廓图;雷达图3.完整的数据分析过程,包括数据采集、数据清洗和数据分析。
()参考答案:对4.下列场景适用于回归分析的是 ( )参考答案:天气预报5.下面哪一句体现了主元分析的思想()参考答案:牵牛要牵牛鼻子第二章测试1.一般常见的缺失值处理的方法有()参考答案:回归填充法;最近邻插补填充法;插值填充;替换填充法2.一般常见的数据归一化的方法有()参考答案:最小最大规范化;零均值规范化3.少量的异常值完全不会影响数据分析。
()参考答案:错4.下列哪种方法不是数据填补的手段 ( )参考答案:均值标准化5.主成分分析的英文名是()。
参考答案:Principal Component Analysis第三章测试1.下面哪个是SVM在实际生活中的应用()参考答案:图片分类;邮件分类2.以下说法正确的有哪些()参考答案:SVM是一种线性方法;软间隔的引入可以解决轻度线性不可分问题3.拉格朗日乘子法可用于线性可分SVM的模型求解。
()参考答案:对4.SVM的中文全称叫什么?()参考答案:支持向量机5.SVM算法的最小时间复杂度是O(n²),基于此,以下哪种规格的数据集并不适该算法?()参考答案:大数据集第四章测试1.一元线性回归有哪些基本假定?()参考答案:解释变量X是确定性变量,Y是随机变量;;随机误差项和解释变量X不相关;;随机误差项服从零均值、同方差的正态分布。
;随机误差项具有零均值、同方差和序列不相关的性质;2.最典型的两种拟合不佳的情况是()。
参考答案:欠拟合;过拟合3.岭回归适用于样本很少,但变量很多的回归问题。
()参考答案:对4.最小二乘方法的拟合程度衡量指标是()。
参考答案:残差平方和5.关于最小二乘法,下列说法正确的是。





引言在一元统计分析中,用相关系数来衡量两个随机变量之间的线性相关关系;用复相关系数研究一个随机变量和多个随机变量的线性相关关系。
然而,这些统计方法在研究两组变量之间的相关关系时却无能为力。
比如要研究生理指标与训练指标的关系,居民生活环境与健康状况的关系,人口统计变量与消费变量(之间是否具有相关关系。
阅读能力变量(阅读速度、阅读才能)与数学运算能力变量(数学运算速度、数学运算才能)是否相关。
典型相关分析(Canonical Correlation )是研究两组变量之间相关关系的一种多元统计方法。
它能够揭示出两组变量之间的内在联系。
1936年霍特林(Hotelling )最早就“大学表现”和“入学前成绩”的关系、政府政策变量与经济目标变量的关系等问题进行了研究,提出了典型相关分析技术。
之后,Cooley 和Hohnes (1971),Tatsuoka (1971)及Mardia ,Kent 和Bibby (1979)等人对典型相关分析的应用进行了讨论,Kshirsagar (1972)则从理论上给出了最好的分析。
典型相关分析的目的是识别并量化两组变量之间的联系,将两组变量相关关系的分析,转化为一组变量的线性组合与另一组变量线性组合之间的相关关系分析。
目前,典型相关分析已被应用于心理学、市场营销等领域。
如用于研究个人性格与职业兴趣的关系,市场促销活动与消费者响应之间的关系等问题的分析研究。
第一章、典型相关的基本理论 1.1 典型相关分析的基本概念典型相关分析由Hotelling 提出,其基本思想和主成分分析非常相似。
首先在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。
然后选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此继续下去,直到两组变量之间的相关性被提取完毕为此。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
典型相关系数度量了这两组变量之间联系的强度。
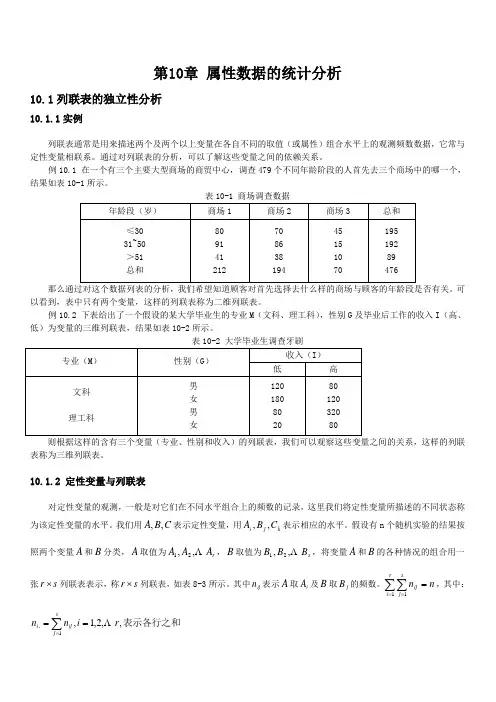
第10章 属性数据的统计分析10.1列联表的独立性分析10.1.1实例列联表通常是用来描述两个及两个以上变量在各自不同的取值(或属性)组合水平上的观测频数数据,它常与定性变量相联系。
通过对列联表的分析,可以了解这些变量之间的依赖关系。
例10.1 在一个有三个主要大型商场的商贸中心,调查479个不同年龄阶段的人首先去三个商场中的哪一个,结果如表10-1所示。
表10-1 商场调查数据那么通过对这个数据列表的分析,我们希望知道顾客对首先选择去什么样的商场与顾客的年龄段是否有关。
可以看到,表中只有两个变量,这样的列联表称为二维列联表。
例10.2 下表给出了一个假设的某大学毕业生的专业M (文科、理工科),性别G 及毕业后工作的收入I (高、低)为变量的三维列联表,结果如表10-2所示。
表10-2 大学毕业生调查牙刷则根据这样的含有三个变量(专业、性别和收入)的列联表,我们可以观察这些变量之间的关系,这样的列联表称为三维列联表。
10.1.2 定性变量与列联表对定性变量的观测,一般是对它们在不同水平组合上的频数的记录,这里我们将定性变量所描述的不同状态称为该定性变量的水平。
我们用C B A ,,表示定性变量,用k j i C B A ,,表示相应的水平。
假设有n 个随机实验的结果按照两个变量A 和B 分类,A 取值为r A A A ,,21,B 取值为s B B B ,,21,将变量A 和B 的各种情况的组合用一张s r 列联表表示,称s r 列联表,如表8-3所示。
其中ij n 表示A 取i A 及B 取j B 的频数。
r i sj ijn n11,其中:表示各行之和,,2,1,1.r i n n sj ij iri i sj j ri ij j n n n s j n n 1.1.1...,,,2,1,表示各列之和表10-3 变量频数表体表,但这样通常用起来不方便,所以一般是采用象例10.2的方式把三维列联表给出。

第十章市场营销组合策略4C策略的基本概念14Ps向4Cs的转变24C策略的相关分析3案例分析4随着市场竞争日趋激烈,媒介传播速度越来越快,4Ps理论越来越受到挑战。
1990年,美国学者罗伯特·劳特朋(Robert Lauterborn)教授在其《4P退休4C登场》(New Marketing Litany: Four Ps Passé: C-Words Take Over)专文中提出了与传统营销的4P 相对应的4Cs营销理论。
4C(Customer、Cost、Convenience、Communication)营销理论以消费者需求为导向,重新设定了市场营销组合的四个基本要素:瞄准消费者的需求和期望(Customer)。
基本概述:1970年,美国著名未来学家AlvinToHler在其著名的Futureshock中曾预言:“未来的社会将要提供的并不是有限的、标准化的商品,而是有史以来最大多样化的、非标准化的商品和服务。
”大规模定制作为一种现代生产和管理的模式,将大规模生产和定制生产两种生产模式结合起来,以低成本向多元化细分市场生产和销售满足客户个性化要求的产品和服务,最终形成“销售—生产—服务”一体化模式。
为了实现向客户提供低成本、高质量的个性化定制产品和服务的目标,必须迅速发现和准确捕捉细分市场中个性化客户需求信息,与客户直接进行交流。
传统的以推销为中心的市场营销方式已经不再适应大规模定制生产模式的要求。
大规模定制作为一种崭新的生产和管理模式必然要求有一种新的市场营销方式与之对应。
大规模定制营销需要以市场为起点,发现和挖掘客户的个性化需求,以此制定综合的市场营销组合策略,以实现顾客价值和企业效益的双赢。
4Cs :指代Customer(顾客,主要指顾客的需求)、Cost(成本)、Convenience(便利)和Communication(沟通)。
Customer(顾客):主要指顾客的需求。

第一章测试1.四组均数比较的方差分析,其备择假设H1应为()。
A:至少有两个样本均数不等B:C:D:各总体均数不全相等E:任两个总体均数间有差别答案:D2.随机区组设计的方差分析中,ν配伍等于()。
A:ν总-ν处理-ν误差B:ν总-ν处理+ν误差C:ν总-ν误差D:ν总+ν处理+ν误差E:ν总-ν处理答案:A3.当自由度(ν1, ν2)及检验水准α都相同时,方差分析的界值比方差齐性检验的界值()。
A:小B:不一定C:大D:相等答案:A4.完全随机设计方差分析的检验假设是()。
A:各处理组样本均数相等B:各处理组样本均数不相等C:各处理组总体均数相等D:各处理组总体均数不相等答案:C5.关于方差分析,下列说法正确的是()。
A:只要是定量资料,均能选用方差分析B:方差分析只能用于多组定量资料均数的比较C:只要各组例数相等,定量资料均数的比较可采用随机区组设计方差分析D:方差分析的基本思想是将数据均方与自由度进行分解E:方差分析可适用于多组正态且等方差的定量资料均数比较答案:E6.当组数等于2时,对于同一资料,方差分析结果与t检验结果相比()。
A:方差分析结果更为准确B:t检验结果更为准确C:两者结果可能出现矛盾D:完全等价且答案:D7.完全随机设计、随机区组设计的SS和及自由度各分解为几部分()。
A:2,2B:2,3C:2,4D:3,3答案:B8.完全随机设计方差分析中,组间均方主要反映()。
A:处理因素的作用B:系统误差的影响C:抽样误差大小D:n个数据的离散程度E:随机误差的影响答案:A9.三组以上某实验室指标观测数据服从正态分布且满足参数检验的应用条件。
任两组分别进行多次t检验代替方差分析,将会()。
A:使均数相差更为显著B:明显增大犯I型错误的概率C:使结论更加具体D:明显增大犯II型错误的概率E:使均数的代表性更好答案:B10.在完全随机设计的方差分析中,必然有()。
A:MS组间> MS组内B:MS总 = MS组间 + MS组内C:SS总= SS组间 + SS组内D:MS组间< MS组内E:SS组内< SS组间答案:C第二章测试1.2×2析因试验设计表述正确的是()。

多元统计分析智慧树知到课后章节答案2023年下浙江工商大学浙江工商大学第一章测试1.在采用多元统计分析技术进行数据处理、建立宏观或微观系统模型时,可以解决下面哪几方面的问题。
()A:简化系统结构、探讨系统内核 B:进行数值分类,构造分类模型 C:变量之间的相依性分析 D:构造预测模型,进行预报控制答案:简化系统结构、探讨系统内核;进行数值分类,构造分类模型;变量之间的相依性分析;构造预测模型,进行预报控制2.只有调查来的才是数据。
()A:对 B:错答案:错3.以下都属于大数据范畴。
()A:行车轨迹 B:交易记录 C:问卷调查 D:访谈文本答案:行车轨迹;交易记录;问卷调查;访谈文本4.只要是数据,就一定有价值。
()A:对 B:错答案:错5.统计是研究如何搜集数据,如何分析数据的学问,它既是科学,也是艺术.()A:错 B:对答案:对第二章测试1.考虑了量纲影响的距离测度方法有()。
A:欧氏距离 B:Minkowski距离 C:马氏距离 D:切比雪夫距离答案:马氏距离2.不具有单调性的系统聚类方法有()。
A:离差平方和法 B:最短距离法 C:中间距离法 D:重心法 E:类平均距离法答案:中间距离法;重心法3.聚类分析是研究分类问题的一种多元统计分析方法。
()A:对 B:错答案:对4.聚类分析是有监督学习。
()A:错 B:对答案:错5.动态聚类法的凝聚点可以人为主观判别。
()A:对 B:错答案:对第三章测试1.判别分析是通过对已知类别的样本数据的学习、构建判别函数来最大程度区分各类,Fisher判别的准则要求()。
A:各类之间各个类内部变异尽可能大B:各类之间和各类内部变异尽可能小 C:各类之间变异尽可能大、各类内部变异尽可能小D:各类之间变异尽可能小、各类内部变异尽可能大答案:各类之间变异尽可能大、各类内部变异尽可能小2.常用判别分析的方法有()。
A:逐步判别法 B:贝叶斯判别法 C:费舍尔判别法 D:距离判别法答案:逐步判别法;贝叶斯判别法;费舍尔判别法;距离判别法3.较聚类分析,判别分析是根据已知类别的样本信息,对新样品进行分类。