基于数据挖掘的葡萄酒质量识别
- 格式:doc
- 大小:1.05 MB
- 文档页数:22

基于机器学习算法的红葡萄酒质量评价模型研究红葡萄酒是指采用红葡萄酿制而成的葡萄酒,其酿制过程中需要进行多个环节的控制,如选材、发酵、陈酿等,而其中一个非常重要的环节就是质量评价。
酒类行业一直以来都在探索如何通过科技手段来提高红葡萄酒的质量,机器学习算法作为其中的一个重要工具也开始受到了越来越多的关注。
本文将从机器学习算法的角度,探讨基于机器学习算法的红葡萄酒质量评价模型的研究。
一、机器学习算法简介机器学习是人工智能的一个分支,它的主要任务是通过训练数据集让机器能够自动学习并表现出某种行为或任务的能力。
机器学习算法可以分为监督学习、无监督学习、半监督学习、强化学习等几种,其中监督学习是应用最广泛的算法之一。
监督学习主要是基于已有的有标签数据集进行训练,让机器能够自动学习并对未知数据进行分类或预测等任务。
二、基于机器学习算法的红葡萄酒质量评价模型研究红葡萄酒质量评价是根据各种目标和指标来综合评价葡萄酒的质量,包括外观、香气、口感等各个方面。
传统的评价方法主要是依靠人工鉴定,但是这种方法有很多缺点,例如标准不统一、可靠性差、评价效率低等。
随着科技的发展,基于机器学习算法的红葡萄酒质量评价模型开始逐渐被应用于酒类行业中。
在基于机器学习算法的红葡萄酒质量评价模型中,主要是通过先给出一些红葡萄酒的质量数据集作为训练集,利用监督学习算法进行训练,然后通过训练出来的模型对新的红葡萄酒进行评价。
在数据集的选取上,一般需要考虑到数据的多样性、数量和质量等因素。
如何有效地选取数据集是机器学习中非常重要的一个环节。
在选择机器学习算法的时候,要根据任务的具体需求来进行选择。
例如,如果需要对红葡萄酒的外观进行评价,可以采用基于图像处理的机器学习算法,如卷积神经网络(CNN)等。
如果需要对红葡萄酒的香气进行评价,可以采用基于自然语言处理(NLP)的机器学习算法,如深度学习等。
三、机器学习算法在红葡萄酒质量评价中的应用案例随着机器学习算法的不断发展,它在红葡萄酒质量评价中的应用也越来越广泛。

基于机器学习的红酒品质分析技术研究红酒一直是人们选购时的重要饮品之一。
由于红酒品牌、生产年份、产地、等级等因素的复杂性,人们很难在挑选时做出准确的决定。
同时,在红酒的生产、存放和管理过程中,也存在着一系列的问题,如酒质的不稳定、存放环境的不合规、防伪措施的不完善等。
因此,基于机器学习的红酒品质分析技术研究成为当下的重要焦点。
1. 红酒的品质评估方法在传统红酒品质评估中,专业人员通过品尝红酒的香气、清晰度、色泽、口感等指标进行评估。
这种方法需要专业的品鉴师进行,费用昂贵,并且存在主观性的问题。
随着科技的发展,红酒品质评估的方法也在不断创新。
除了传统的口感品鉴外,科学家们开始利用现代化技术对红酒进行分析评估。
这些技术包括光谱分析、气相色谱-质谱联用分析、感官分析和化学感官分析等。
但是,这些方法也同样耗费时间和成本高昂。
2. 机器学习在红酒品质分析中的应用机器学习基于大量数据的处理和分析,可以实现对红酒品质的准确评估。
通过利用机器学习算法,可以处理并纠正口感品鉴的主观偏差,提高评估的准确性。
机器学习算法包括支持向量机、人工神经网络、决策树、朴素贝叶斯等。
这些算法可根据特征提取、样本分类和模型训练等步骤,将来自不同生产酒厂、年份、地区、酿造手法等的储存数据进行匹配分类和预测。
例如,针对红酒的气味、口感和颜色等特征,可以利用机器学习算法提取出不同特征值的影响因素,进而建立数学模型和算法模型,最终得出对待评估红酒的品质评估结果。
同时,基于机器学习的红酒品质分析技术还可以辅助红酒生产过程中的质量管理和监控,实现红酒生产质量的稳定和标准化。
3. 基于机器学习的红酒品质分析技术的局限性尽管基于机器学习的红酒品质分析技术具有高效、高准确度的特点和优势,在实际应用时,还存在一些限制和困难。
首先,机器学习需要大量的数据,才能进行比较准确的预测和分析。
而目前,在红酒品质分析方面关于红酒品质的数据还不够充分和精确。
其次,红酒综合品质评估包括多个指标,而且对红酒品质的评估包括感官评估和化学分析两个方面。

数学建模经典案例分析以葡萄酒质量评价为例一、本文概述本文旨在通过深入剖析数学建模在葡萄酒质量评价中的应用,展示数学建模的经典案例。
我们将首先简要介绍数学建模的基本概念及其在各个领域的应用,然后聚焦葡萄酒质量评价这一具体问题,阐述如何通过数学建模对其进行科学、客观的分析。
文章将详细分析数据的收集与处理、模型的建立与求解、模型的验证与优化等关键环节,并探讨不同数学模型在葡萄酒质量评价中的优缺点。
我们将总结数学建模在葡萄酒质量评价中的实际应用效果,展望其在未来葡萄酒产业中的发展前景。
通过阅读本文,读者将能够了解数学建模在葡萄酒质量评价中的重要作用,掌握相关数学建模方法和技术,为类似问题的解决提供有益的参考和借鉴。
本文也将促进数学建模在葡萄酒产业中的应用与发展,推动葡萄酒产业的科技进步和产业升级。
二、数学建模基础数学建模是一种将实际问题抽象化、量化的过程,通过数学工具和方法来求解问题的近似解。
在葡萄酒质量评价这一案例中,数学建模提供了从复杂的实际生产环境中提取关键信息,并建立预测模型的可能。
这需要我们具备一定的数学基础,如统计学、线性代数、微积分等,同时也需要理解并掌握数据处理的基本技术,如数据清洗、特征提取和选择等。
在葡萄酒质量评价问题中,我们首先需要收集大量的葡萄酒样本数据,这些数据可能包括葡萄品种、产地、气候、土壤、酿造工艺、化学成分等多个方面的信息。
然后,我们需要对这些数据进行预处理,如去除缺失值、异常值,进行数据标准化等,以提高模型的稳定性和准确性。
接下来,我们可以选择适合的模型进行训练。
在这个案例中,我们可以选择线性回归、决策树、随机森林、神经网络等模型进行尝试。
我们需要根据数据的特性和问题的需求,选择最合适的模型。
同时,我们还需要进行模型的训练和验证,通过调整模型的参数,提高模型的预测能力。
我们需要对模型进行评估和优化。
这可以通过交叉验证、ROC曲线、AUC值等评估指标来进行。
如果模型的预测能力不足,我们需要对模型进行优化,如改进模型的结构、增加更多的特征等。

基于大数据的红酒品质分类技术研究红酒品质分类一直以来都是酿酒界的研究热点之一、传统的红酒品质分类依赖于专家的感官评价和经验,这种方法不仅需要专业的品酒师,还存在主观性和一致性的问题。
随着大数据技术的快速发展,利用大数据进行红酒品质分类成为可能,并且逐渐得到了广泛的研究和应用。
大数据技术可以应用于红酒的品质分类的各个方面,包括红酒原材料的种植、酒厂的酿造技术、生产过程中的监测与控制、产区环境因素等。
首先,大数据可以用来分析红酒原材料的种植情况,包括葡萄的种类、种植地的土壤条件、气候特点等,通过对这些数据的分析和挖掘,可以找出对红酒品质影响较大的因素。
其次,大数据还可以用于酒厂的酿造技术优化,通过收集和分析酿酒过程中的各种数据,如发酵温度、酒液的酸碱度、酒液中的酒精含量等,可以实现对酿酒过程的监测和控制,从而提高红酒的品质。
另外,在红酒的品质分类中,还可以利用大数据来分析和挖掘消费者的评价数据和消费记录。
通过收集和分析消费者对不同红酒的评价和喜好,可以建立起红酒的品质分类模型,将红酒分为不同的等级或种类。
此外,还可以结合消费者的消费记录和购买意向,提供个性化的推荐服务,帮助消费者挑选符合自己口味的红酒。
大数据的应用对于红酒品质分类的研究有着重要的意义。
首先,通过大数据技术的应用,可以减少专家评价的主观性和不一致性,提高红酒品质分类的准确性和一致性。
其次,大数据的应用可以提供更加全面和细致的红酒品质评估,从而帮助酿酒师更好地改进酿造技术,提高红酒的品质。
最后,大数据的应用还可以实现对消费者需求的个性化分析和推荐,为消费者提供更好的购酒体验。
然而,大数据的应用在红酒品质分类研究中也存在一些挑战。
首先,大数据的收集和处理需要消耗大量的时间和资源,需要建立完善的数据采集和处理系统。
其次,红酒的品质分类涉及到多个因素的综合评估,需要建立复杂的数据模型和算法。
最后,红酒的品质分类是一个相对主观的问题,不同的消费者可能有不同的评价标准,这就需要建立适应多样性需求的红酒品质分类系统。

基于数据挖掘的红酒品质评估研究红酒一直以来都是高端美酒的代表,而在品质评估方面,数据挖掘技术的应用为我们提供了更为准确的评估手段。
本文将深入介绍基于数据挖掘的红酒品质评估研究。
第一部分红酒品质评估的现状红酒品质评估一直是一个非常重要且难以解决的课题。
传统方法主要依赖专业品鉴师的经验,但这种方法有时候会出现非常大的误差。
为了提升品质评估的质量,近年来越来越多的研究开始将数据挖掘技术引入到红酒品质评估中。
第二部分数据挖掘在红酒品质评估中的应用数据挖掘在红酒品质评估中有着广泛的应用。
其主要可以通过建立模型等方法,对红酒的生产历史、品种、产地、成分等多方面数据进行分析,从而准确预测其品质。
1. 建立模型数据挖掘中最常用的方法之一就是建立模型。
在红酒品质评估中,建立预测模型可以充分利用大量的历史数据,并通过数据的分析,找出红酒品质的影响因素,从而预测红酒的品质。
当然,建立模型也需要根据不同的数据特点,灵活选择相应的模型算法。
2. 分析历史数据历史数据分析也是数据挖掘在红酒品质评估中的一种常见应用。
通过分析红酒的生产历史,我们可以轻松地获得红酒的品质趋势。
再结合其它的外部因素如作物气候等因素,我们可以更加准确地评估红酒的品质。
3. 红酒成分分析成分分析也是数据挖掘在红酒品质评估中的重要组成部分。
不同的红酒成分会对品质产生巨大的影响,在分析不同成分的数据后,可以制定不同的评估标准,从而更快准确地评估红酒品质。
第三部分数据挖掘在红酒品质评估中的意义数据挖掘在红酒品质评估中的应用具有非常明显的意义。
首先,对于品质评估,数据挖掘可以提供更为准确的评估方法,以消除人为的主观误差。
其次,红酒品质的评估同时也能够反推数据挖掘模型的优化和推广,并为其他领域的数据挖掘研究提供重要经验。
最后,数据挖掘方法还能够通过大量的历史数据,提供有关红酒各种因素的更加准确的分析结果和反馈给酿酒厂,从而更好地优化生产流程。
总结在红酒品质评估方面,数据挖掘技术的应用已经得到广泛的认可。
基于数据挖掘技术的红酒质量评价与等级划分研究红酒是一种受到广泛欢迎的酒类,在世界各地都有着众多的酒友和爱好者。
而红酒的品质和等级则成为了关注的重点之一,因为好的红酒能够为人们带来更美好的品尝体验。
然而,传统的红酒评价方式多为人工,时间和成本较高。
近年来,基于数据挖掘技术的红酒质量评价与等级划分研究越来越受到人们的关注。
一、数据挖掘技术与红酒质量评价数据挖掘技术是一种从大量数据中自动发现规律的方法,可以帮助人们快速准确地对红酒进行品质评价。
数据挖掘技术不仅包括了基础的数据统计和分析方法,还包括了人工智能、机器学习和深度学习等高级算法,可以更加准确地对红酒进行评价和分类。
在红酒质量评价中,数据挖掘技术主要通过构建模型实现。
模型的构建包括了特征提取、特征选择、模型训练和模型应用等多个过程。
其中,特征提取是数据挖掘技术的关键。
红酒的特征包括了多种成分和属性,如酒精度、酸度、甜度、色泽、气味等。
在特征提取中,需要选择合适的特征来对红酒进行描述和评价,同时,还需要对特征进行标准化和归一化等预处理操作。
二、基于数据挖掘技术的红酒品质等级划分方法基于数据挖掘技术的红酒品质等级划分方法主要包括了基于聚类的划分和基于分类的划分两种方法。
基于聚类的划分方法是将相似的红酒样本划分在一类中,不同的红酒样本则归为不同的类别。
在聚类过程中,需要选择合适的距离计算方法、聚类算法和聚类评价指标等。
在红酒品质等级划分中,可以选择基于距离的层次聚类或基于密度的DBSCAN聚类等算法来进行。
同时,也需要根据实际情况选择合适的聚类评价指标,如轮廓系数、DB指数等。
基于分类的划分方法是将红酒样本划分到已知的品质等级类别中。
在分类过程中,需要选择合适的分类算法和分类评价指标等。
在红酒品质等级划分中,可以选择k-NN、SVM、决策树等分类算法来进行。
同时,也需要根据实际情况选择合适的分类评价指标,如准确率、召回率、F1值等。
三、基于数据挖掘技术的红酒品质等级划分案例基于数据挖掘技术的红酒品质等级划分已经有一些实际应用案例。
基于机器学习的红酒质量评价算法研究一、引言随着红酒消费市场的逐步成熟,消费者对红酒的需求越来越高,同时,对红酒质量的要求也越来越高。
如何对红酒进行准确评价成为了业内重要的研究方向。
机器学习因其在数据分析和模型建立方面的优势,成为红酒质量评价的重要工具。
二、红酒质量评价方法1. 专业评价方法:通常是由专业品鉴师进行,根据气味、口感、颜色、杯底析出物等多个方面进行评价,并给出相关指标;2. 数字化评价方法:借助现代仪器对红酒进行检测和分析,如使用分光光度法分析多酚、使用气相色谱法检测残留农药等指标。
三、机器学习在红酒质量评价中的应用1. 特征提取:通过对红酒的色泽、香气、味道等方面进行数据采集和处理,提取出相关特征;2. 模型建立:根据提取出的特征,构建机器学习模型;3. 模型训练:选择合适的数据集进行模型训练,并进行优化调整;4. 模型预测:对未知红酒进行预测,并给出相应的评价结果。
四、红酒质量评价算法1. 支持向量机算法(SVM): SVM是一种广泛使用的算法,在红酒质量评价中也有较好的应用效果;2. 决策树算法:决策树是一种常用的分类算法,其本质是一种多路判断的方法,根据数据特征进行划分;3. 随机森林算法:随机森林是一种结合多个决策树的算法,能够降低模型过拟合的风险;4. 神经网络算法:神经网络是一种模拟自然神经网络的算法,可以进行非线性建模。
五、机器学习算法在红酒质量评价中的应用实例以葡萄酿酒为例,通过琼瑶浆等多种特征对葡萄酒进行数据采集和处理,利用SVM算法进行建模和训练,并进行模型预测。
结果表明SVM算法在评价葡萄酒质量方面有着较好的效果。
六、未来展望随着机器学习算法的不断发展,红酒质量评价也将得到不断提升,同时红酒质量评价算法的新型研究方向也会不断涌现,如深度学习等。
七、结论基于机器学习算法的红酒质量评价,在特征提取、模型建立、模型训练和预测等方面有着明显的优势,可以有效提升红酒质量评价的准确性和效率。
基于机器学习的红酒质量检测研究随着世界科技的不断进步和发展,人工智能技术也逐渐走向成熟。
在各行各业中,人工智能技术已经开始发挥其独特的优势,掀起了一场马不停蹄的技术革命。
其中,基于机器学习的红酒质量检测研究已经成为了该领域中的一个热点话题。
红酒的质量往往是影响消费者购买的一大关键因素。
传统的红酒质量检测方式采用人工品尝鉴定,不仅耗时费力,而且还存在主观的偏差和误判,无法保证判定结果的准确性。
而基于机器学习的红酒质量检测则可以有效地解决上述问题,实现自动化、精确化、快速化检测。
首先,咱们来了解一下机器学习的基本概念。
机器学习是一门人工智能领域的重要分支,它通过计算机程序模拟人类学习的过程,从而使计算机能够进行自主学习和探索数据规律。
在红酒质量检测中,机器学习算法会自动从大量的历史数据中提取特征,建立相应的模型,并对新的红酒质量数据进行预测鉴定。
那么,机器学习如何应用在红酒质量检测中呢?首先,我们需要有一个足够的数据集进行训练。
这些数据集可能包括红酒的产地、葡萄品种、酒精度、pH值等多个方面的信息。
然后,我们需要选择适合的机器学习算法进行训练和预测。
常见的算法包括支持向量机(SVM)、决策树(Decision Tree)、随机森林(Random Forest)等。
这些算法具有不同的特点和适用范围,需要根据具体情况进行选择。
最后,我们需要对模型进行评估和优化,以保证其准确性和稳定性。
随着机器学习技术的不断发展和完善,基于机器学习的红酒质量检测已经取得了一定的研究成果。
例如,澳大利亚南澳大学的研究人员利用机器学习算法,成功分类了超过6000种来自54个国家的红酒。
同时,该研究还通过与人工品鉴比较,证明了机器学习的鉴定结果更为准确可靠。
然而,基于机器学习的红酒质量检测也存在一些挑战和限制。
首先,数据集的质量和数量会直接影响模型的准确性和可靠性。
如果数据集过小或者存在大量的噪声数据,那么模型很难学习到有效的信息,导致鉴定结果不准确。
上海大学2013-2014学年春季学期硕士研究生课程考试课程名称:数据挖掘与商务智能课程编号: 29SBG9016论文题目:基于C5.0算法的白葡萄酒品质分析研究生姓名(学号):论文评价:论文成绩:任课教师:评阅日期: 2014年6月基于C5.0算法的白葡萄酒品质分析摘要:针对目前消费者对葡萄酒的需求日益强烈,很多大的庄园希望为顾客提供品质优秀的葡萄酒,本文使用测量优先度信息增益率的计算方法,对某庄园现有葡萄酒的客观理性数据进行分析处理,在SPSS Clementine 12.0数据挖掘平台使用C5.0算法模型进行数据挖掘,构造了对葡萄酒品质进行分类的决策树模型,经分析评估正确率为72.71%,从而帮助庄园在大数据环境下利用数据挖掘技术进行葡萄酒品质的判别,有效地减少因品酒师个人因素带来的评级波动。
关键词:葡萄酒;品质;决策树;C5.0算法;Clementine数据挖掘平台1 引言葡萄酒品质测定是葡萄酒行业进行质量管理的一种重要手段,测定葡萄酒品质需要品酒师依靠个人感官和经验来进行判定。
品酒师通过观察葡萄酒的颜色、质感等外观特性以及葡萄酒的香气,并且采用品尝的方式感受葡萄酒的滋味和口感。
然而,人工品酒具有一定的主观性,依赖于品酒师的经验以及当前的状态,所评定出来的葡萄酒级别存在评级不稳定的问题,难以在业内得到共识。
另外,葡萄酒的质量安全与公众身体健康密切相关,其中葡萄酒质量检测技术是保障葡萄酒质量安全的重要手段,采用自动化手段检测葡萄酒质量及安全是提高葡萄酒质量检测手段的一种有效方法。
针对这个问题,采用数据挖掘算法中的C5.0算法进行葡萄酒品质预测,该方法具有准确率高、算法简单和高效的优点,尤其适合对大量数据信息分析挖掘,在葡萄酒行业中品质预测应用中,能够有效地减少因品酒师个人因素带来的评级波动。
2 算法概述2.1 C5.0算法概述C5.0是决策树模型中的算法,最早的算法是亨特CLS(Concept Learning System)提出,后经发展由Quinlan.J.R在1979年提出了著名的ID3算法,主要针对离散型属性数据。
承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。
我们参赛选择的题号是(从A/B/C/D中选择一项填写): A我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):装甲兵工程学院参赛队员(打印并签名) :1. 刘戎翔2. 罗辉3. 谭立冬指导教师或指导教师组负责人(打印并签名):陈建华日期: 2012 年 9 月 9 日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):基于数据挖掘的葡萄酒质量识别摘要随着我国葡萄酒业的逐步发展,葡萄酒生产企业的规模和数量不断扩大。
但中国的葡萄酒业仍面临着进口酒的激烈竞争以及质量检测体系不明确带来的市场紊乱。
针对这些问题,本文分析了葡萄酒质量人工品尝存在的不足,并提出了如何提高基于数据挖掘技术的葡萄酒质量等级的识别率,对中国葡萄酒市场的稳定发展以及更好地酿造出高质量的葡萄酒有着实际的应用价值。
在数据挖掘中,经常会遇到不平衡数据的分析。
相对于多数类来说,少数类样本对准确率的影响力小,这意味着对所有样本进行分类,可以在不识别出任何少数类样本的情况下得到很高的正确率,识别少数类的分类规则也就被忽略了。
本文的创新点在于从不平衡样本中提取平衡样本进行建模并对测试样本预测,进行多次的循环,得到多次的预测结果,选择次数出现最多的预测结果作为最终的预测结果,大大提高了低质量葡萄酒的识别率。
基于此抽样建模方法,本文首先对判别分析、支持向量机、分类回归树以及随机森林在葡萄酒质量识别能力进行了比较分析,其中随机森林的预测效果最好,整体识别率以及低质量葡萄酒识别率最高,且模型较为稳定;其次,采用随机森林确定变量重要性,变量重要性排序结果发现,硫酸钾和酒精的重要性最高,硫酸钾和酒精的含量增加,更容易使得此种葡萄酒质量的提升,为酿造师酿造出更好的葡萄酒提供重要的信息;最后,本文将异常点的检测方法应用于进口酒的低质量葡萄酒的检测,遗憾的是,低质量葡萄酒的识别程度有限,仅识别出30%左右的低质量葡萄酒样本,只能辅助低质量葡萄酒的识别,实证结果表明,基于异常样本的低质量葡萄酒的识别率提高了。
本文的主要内容及创新点:本文的主要工作及创新点如下:1.研究分析了传统葡萄酒质量品鉴方法存在的不足,提出了进行智能识别葡萄酒质量的必要性;2.将多种数据挖掘分类方法应用于葡萄酒质量识别,比较各方法的差异及优势。
3.对实证研究中出现少数类样本识别率低的情况,提出通过多次特定随机采样,建立多个模型预测样本类别,对每类样本的预测结果进行统计,以最大的样本类别预测结果作为此样本的预测结果,大大提高了模型的稳定性和预测的局部优化功能,解决了葡萄酒质量识别出现的尴尬问题,即非平衡样本中,少数类样本未被识别。
4.异常点的检测方法应用于检测低质量葡萄酒的检测,辅助和完善低质量葡萄酒的识别结果。
5.本文是通过结合先进的统计软件R语言和数学计算软件matlab对数据进行分析处理,继而建立模型对样本进行预测,特别是R语言,在计算的性能上更优于matlab,更节省时间和计算空间。
关键词:葡萄酒质量识别,判别分析,支持向量机,分类回归树,随机森林,异常点检测。
一、问题重述伟大的科学家伽利略说过:“.一切推理都必须从观察与实验得来”。
以往的葡萄酒一直靠感官品尝来判定其质量的好坏,并且要求品尝者是训练有素的品酒专家。
但是,感官品尝结果受到多种因素的影响,如品酒专家的职业水平、个人喜好以及葡萄酒的温度等等都会影响到葡萄酒评价的结果。
葡萄酒品尝在国内尚不普遍,训练有素的专家品酒师也有限。
况且酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,而且葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
根据题意及所给数据,本文需要解决的问题有:(1) 两组评酒员的评价结果有无显著性差异,哪一组结果更可信?(2) 根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级。
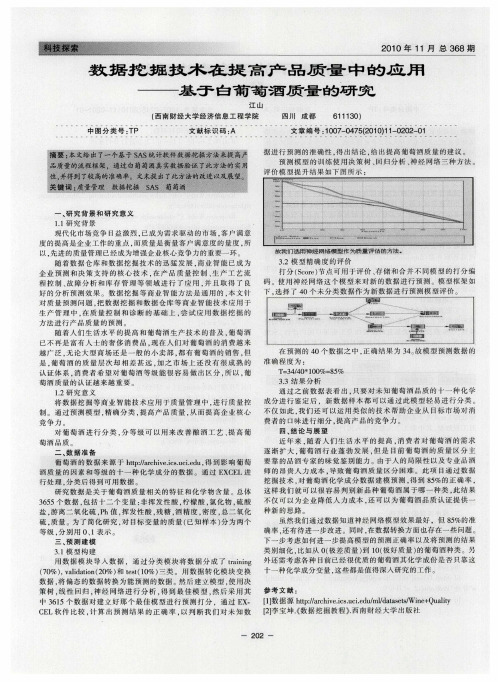
(3) 分析酿酒葡萄与葡萄酒的理化指标之间有哪些联系? (4) 分析酿酒葡萄和葡萄酒的理化指标对葡萄酒质量的影响,并论证能否用葡萄和葡萄酒的理化指标来评价葡萄酒的质量?二、模型假设⑴不考虑元素间的相互作用的影响⑵短期内重金属元素的物理、化学变化及迁移对周围环境影响不大 ⑶假设附录中所给8种重金属元素的背景值真实 ⑷不考虑历史沉积的重金属的影响三、符号说明i x 第i 种元素在第j 个采样点的浓度(8,...2,1=i ); x 第i 种元素浓度的平均值(8,...2,1=i );i x ' 第i 种元素在第j 个采样点无量纲化后的数值(5,...2,1=j ); i P 第j 个功能区重金属i 的单项污染指数(5,...2,1=j ); i C 第j 个功能区重金属i 含量的实测值(5,...2,1=j ); D 污染距离积;h 污染源位置与已知采样点的距离;()()()i y i x , 给定采样点的坐标;四、数据处理与基本分析4.1数据说明及预处理葡萄酒数据来源于网站 http://archive.ies.uei.edml/datasets/Wine+Quality,包含1599个样本记录、n个表示成分及含量的自变量和含量以及一个关于葡萄酒质量好坏的因变量。
本文数据分析所使用的工具主要有MATLAB和R语言[32,,7]。
首先将葡萄酒质量等级分为低等、中等以及高等三类,对应样本量分别为63、1319、217。
具体的十一个自变量如表4一1所示。
其中体现葡萄酒的酸、甜、咸、苦的成分归纳如下:酸:酒石酸、醋酸、柠檬酸甜:糖分、酒精咸:氯化钠苦:游离二氧化硫、总二氧化硫、硫酸钾由于自变量单位不全相同,为了消除量纲对模型的影响,进行回归时需对数据进行标准化处理。
4.1.2数据基本分析4.1.2,l相关胜分析首先对自变量之间进相关性分析,图4-1给出了部分相关性相对较大的变量两两之间的散点图。
透过散点图我们可以观察到酸度与密度,酸度与PH值之间的相关性程度较高。
其他各个变量之间的相关系数详见表4-2。
从表4一2可以观察到,除了酒石酸与密度、游离SO:与总S仇含量之间的相关系数在0.68并不高。
其中,酒石酸与PH、醋酸与酒石酸、酒石酸与柠檬酸、酒石酸与PH、左右,其他变量之间的相关程度。
4.1 对重元素的分析城市工业“三废”排放,金属采矿和冶炼,家庭燃煤,生活垃圾,汽车尾气排放都增加了城市土壤重金属的负荷。
重金属污染环境的主要有汞、铅、铬、锌镉、铜等。
其中汞的毒性最大,铬、铅、锌等也有相当大毒性。
此外还有砷,砷虽不属于金属.但它的毒性与重金属相似,因此归于重金属一类阐述,称为类金属。
目前对我国土壤污染比较普遍的重金属有汞、铬、砷。
根据该城区重金属污染的情况,下面对重金属在土壤污染中的来源及传播途径作简要介绍。
4.1.1砷元素该元素毒性很低,水体中含砷污染物主要来自砷和含砷金属矿的开采、冶炼,以及和砷化物为原料的玻璃、颜料、药物、纸张的生产都可产生含砷的废水,造成水体的砷污染。
砷及砷化物在水中会在水生物体内累积,但累积程度比其他重金属要低。
砷和砷化物,一般可通过水、大气和食物进入人体。
4.1.2镉元素当环境受到镉污染后,镉可在生物体内富集,通过食物链进入人体引起慢性中毒。
镉的主要污染源是电镀、采矿、冶炼、染料、电池和化学工业等排放的废水。
相当数量的镉通过废气、废水、废渣排入环境,造成污染。
镉对土壤的污染主要有气型和水型两种。
气型污染主要来自工业废气。
镉随废气扩散到工厂周围并自然沉降,蓄积于工厂周围的土壤中,可使土壤中的镉浓度达到40ppm。
水型污染主要是铅锌矿的选矿废水和有关工业(电镀、碱性电池等)废水排入地面水或渗入地下水引起。
4.1.3铬元素对水体污染的铬主要来源于电镀、制革、铝盐生产以及铬矿石开采所排放的废水。
是我国水体中一种普遍的污染物。
水体中铬污染主要是三价铬和六价铬,它们在水体中的迁移转化有一定的规律性。
4.1.4铜元素铜(Cu)及其化合物在环境中所造成的污染称为铜污染。
主要污染来源是铜锌矿的开采和冶炼、金属加工、机械制造、钢铁生产等。
冶炼排放的烟尘是大气铜污染的主要来源。
世界铜的年迁移量为:岩石风化20万吨,河流输送11万吨4.1.5汞元素汞是在常温下唯一呈液态的金属元素。
人类活动造成水体汞污染,主要来自氯碱、塑料、电池、电子等工业排放的废水。
由于天然本底情况下汞在大气、土壤和水体中均有分布,所以汞的迁移转化也在陆、水、空之间发生。
4.1.6镍元素镍污染是由镍及其化合物所引起的环境污染。
大部分煤含有微量镍,通过燃烧过程被释放出来,这是大气中镍的主要来源。
镍可以在土壤中富集。
土壤中的镍主要来源于岩石风化,大气降尘,灌溉用水(包括含镍废水),农田施肥,植物和动物残体的腐烂等。
全世界每年镍的迁移状况是:岩石风化量为320 000吨,河流输送量为19 000吨,开采量为560 000吨,矿物燃料燃烧排放5 600吨。
4.1.7铅元素铅对环境的污染,一是由冶炼、制造和使用铅制品的工矿企业,尤其是来自有色金属冶炼过程中所排出的含铅废水、废气和废渣造成的。
二是由汽车排出的含铅废气造成的,汽油中用四乙基铅作为抗爆剂(每公斤汽油用1~3克),在汽油燃烧过程中,铅便随汽车排出的废气进入大气,成为大气的主要铅污染源4.1.8锌元素锌在土壤中富集,会使植物体中也富集而导致食用这种植物的人和动物受害。
金属锌本身无毒,但在焙烧硫化锌矿石、熔锌、冶炼其他含有锌杂质的金属的过程中,以及在铸铜过程中产生的大量氧化锌等金属烟尘,对人有直接的危害。
其他如橡胶轮胎的磨损以及煤的燃烧也是大气锌污染的原因。
各种工业废水的排放是引起水体锌污染的主要原因。
4.2 对基本数据的分析用 EXCELL 软件和 SPSS 统计软件处理数据如表1所示:4.3 元素浓度的无量纲化处理在利用SPSS 统计软件数据进行聚类分析的时候,因为单位不统一需要进行无量纲化处理,我们采用均值化方法,即每一个变量除以该变量的平均值,即xx x ii =', (1) 标准化以后各变量的平均值都为1,标准差为原始变量的变异系数。