基于数据挖掘技术的葡萄酒评价体系研究
- 格式:pdf
- 大小:368.46 KB
- 文档页数:9

葡萄酒的评价摘要本文主要采用数学统计与分析方法,利用EXCEL,MATLAB等工具解决了有关葡萄酒质量评价的一系列问题。
关于问题一,分析判断两组评酒员评价结果有无显著性差异及哪组结果更可信。
首先我们采用t-检验法,根据T值判断差异的显著性,代入数据后求得P T t 双尾=0.00065<0.01,即两组评价结果差异性显著。
然后将第一组10位()评酒员对于酒样品所给评分的方差值与第二组10位评酒员对于酒样品所给评分的方差值做比较,得出第一组的方差较大,所以认为第一组评酒员打分较为严格,即更可信。
关于问题二,在不确定酿酒葡萄的理化指标和葡萄酒的质量之间的关系的情况下,运用主成分分析法粪别根据酿酒葡萄的理化指标和葡萄酒的质量对酿酒葡萄进行了分级,将红葡萄、白葡萄各分成了优质、较好、一般、劣质四个等级,结果详见表5.2.1至表5.2.4。
关于问题三,采用回归分析法,计算出酿酒葡萄与葡萄酒所共有的理化指标之间的相关系数,结果详见表5.3.1和表5.3.2,其相关系数的绝对值越大表示联系程度越紧密。
关于问题四,首先根据问题三的结果可知酿酒葡萄与葡萄酒的理化指标之间的联系,将分析过程简化为只考虑葡萄酒的理化指标对葡萄酒质量的影响。
然后查阅资料结合附表1,总结出口感和外观为葡萄酒质量的决定因素,而总酚、色泽、花色苷这三个理化指标为主要影响葡萄酒质量的因素。
最后结合附件3,发现芳香物质对葡萄酒质量也有影响,否定了用葡萄和葡萄酒的理化指标来评价葡萄酒的质量的可行性。
关键词:葡萄酒质量的评价EXCEL MATLAB、主成分分析相关系数T-检验1.问题重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。
每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。
酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。

基于机器学习算法的红葡萄酒质量评价模型研究红葡萄酒是指采用红葡萄酿制而成的葡萄酒,其酿制过程中需要进行多个环节的控制,如选材、发酵、陈酿等,而其中一个非常重要的环节就是质量评价。
酒类行业一直以来都在探索如何通过科技手段来提高红葡萄酒的质量,机器学习算法作为其中的一个重要工具也开始受到了越来越多的关注。
本文将从机器学习算法的角度,探讨基于机器学习算法的红葡萄酒质量评价模型的研究。
一、机器学习算法简介机器学习是人工智能的一个分支,它的主要任务是通过训练数据集让机器能够自动学习并表现出某种行为或任务的能力。
机器学习算法可以分为监督学习、无监督学习、半监督学习、强化学习等几种,其中监督学习是应用最广泛的算法之一。
监督学习主要是基于已有的有标签数据集进行训练,让机器能够自动学习并对未知数据进行分类或预测等任务。
二、基于机器学习算法的红葡萄酒质量评价模型研究红葡萄酒质量评价是根据各种目标和指标来综合评价葡萄酒的质量,包括外观、香气、口感等各个方面。
传统的评价方法主要是依靠人工鉴定,但是这种方法有很多缺点,例如标准不统一、可靠性差、评价效率低等。
随着科技的发展,基于机器学习算法的红葡萄酒质量评价模型开始逐渐被应用于酒类行业中。
在基于机器学习算法的红葡萄酒质量评价模型中,主要是通过先给出一些红葡萄酒的质量数据集作为训练集,利用监督学习算法进行训练,然后通过训练出来的模型对新的红葡萄酒进行评价。
在数据集的选取上,一般需要考虑到数据的多样性、数量和质量等因素。
如何有效地选取数据集是机器学习中非常重要的一个环节。
在选择机器学习算法的时候,要根据任务的具体需求来进行选择。
例如,如果需要对红葡萄酒的外观进行评价,可以采用基于图像处理的机器学习算法,如卷积神经网络(CNN)等。
如果需要对红葡萄酒的香气进行评价,可以采用基于自然语言处理(NLP)的机器学习算法,如深度学习等。
三、机器学习算法在红葡萄酒质量评价中的应用案例随着机器学习算法的不断发展,它在红葡萄酒质量评价中的应用也越来越广泛。

葡萄酒的评价模型摘要近年来,我国掀起了一场葡萄酒热,对葡萄酒的需求与日俱增。
特别是随着食品科学技术的发展,人们不再满足传统感官评价葡萄酒的水平。
如何运用数据资料定量研究葡萄酒的品质,加快建立葡萄酒市场指标规则成为人们关注的焦点。
本文通过对感官评价分析,结合葡萄酒和酿酒葡萄的理化指标和芳香物质的大量数据,建立了客观可靠的葡萄酒质量综合评价模型。
针对问题一:本题需要检验两组品酒员的评价结果是否存在显著差异,并选出更可靠的一组。
我们将各种葡萄酒的10个二级指标得分,相加得到每种酒的总分。
在判断知每组品酒员的评价总分均服从正态分布后,用t检验分析两组品酒员对各葡萄酒评价的差异性,由此计算得到两组评价的显著性差异率为13.36%,即总体上两组品酒员的评价不存在显著差异。
但由于两组品酒员的评价仍存在部分差异,我们比较两组品酒员对55种葡萄酒评价的方差,发现第二组评分的方差普遍小于第一组,所以第二组的评价结果更可信。
针对问题二:为了对酿酒葡萄进行分级,我们将葡萄的理化指标作为媒介。
先根据国际指标制定适用于本题评分的分级标准,将葡萄酒进行分级,再根据理化指标经标准化之后的数值,利用欧氏距离对酿酒的55种酿酒葡萄进行Q型聚类分析。
聚类得到红白葡萄各六个分类后,再把各类酿酒葡萄对应至相应葡萄酒的等级,将酿酒红葡萄和酿酒白葡萄各分为五级。
针对问题三:由于各种酿酒葡萄的理化指标种类复杂,我们用主成分分析的方法,从酿酒红葡萄和酿酒白葡萄的27个有效指标中各提取出了8个和9个主要成分。
考虑到酿酒葡萄经化学反应酿造成葡萄酒的过程中各项理化指标一般存在线性关系,我们建立多元线性回归模型,得出酿酒葡萄和葡萄酒各项有效理化指标的正负相关关系。
关键词:显著性检验;聚类分析;主成分分析;多元回归。
一、问题的重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评。
每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。

红酒评级的科技与数据分析红酒作为一种具有浓厚文化底蕴和高端品质的酒类,一直以来都备受关注。
而对于红酒爱好者来说,了解不同品牌和产区的红酒评级成为了一种必备的技能。
而现代科技和数据分析的发展,为红酒评级带来了更为准确和便捷的方法。
在本文中,我们将探讨红酒评级的科技与数据分析的重要性和应用。
一、红酒评级科技的发展随着科技的进步和互联网的普及,红酒评级也逐渐与科技相结合,形成了一种新型的评级方式。
通过使用先进的科技手段,如人工智能、大数据分析和区块链技术等,收集和处理大量红酒相关的信息和数据,为红酒爱好者提供全面、准确的评级信息。
二、数据分析在红酒评级中的应用1. 评级指标的建立:数据分析帮助红酒评级建立起一套完整的评级指标体系。
通过分析红酒的各项数据,比如葡萄种植条件、酿造方法、口感特点等,确定不同参数对红酒品质的重要性,并建立起相应的评级体系。
2. 品鉴过程的辅助:传统的品鉴过程需要依赖专业品鉴师的经验和感觉,但这种主观性往往会带来评级的不准确性。
而借助数据分析技术,可以将一系列客观的指标纳入考量,例如颜色、香气、味道等,从而提高红酒评级的客观性和准确性。
3. 用户个性化推荐:通过分析红酒评级数据和用户的喜好,可以为用户提供个性化的红酒推荐。
根据用户的历史品鉴记录和对不同品牌、产区的评分,系统可以通过数据分析准确判断用户的口味偏好,进而为其推荐最符合其口味的红酒产品。
三、红酒评级科技的优势1. 提高评级准确性:传统的评级方式常常受到品鉴师主观意见的干扰,评级结果可能存在一定的主观性和不稳定性。
而采用科技手段进行红酒评级,可以从更多的客观数据中得出评级结果,避免主观因素的影响,提高评级的准确性和可靠性。
2. 提升评级效率:传统的红酒评级需要品鉴师花费大量时间和精力,而采用科技手段进行评级,可以减少人力成本和时间消耗,提升评级效率。
通过大数据分析和自动化技术,可以实现对大量红酒进行快速评级,为红酒爱好者提供更加及时准确的评级信息。


基于数据挖掘技术的红酒质量评价与等级划分研究红酒是一种受到广泛欢迎的酒类,在世界各地都有着众多的酒友和爱好者。
而红酒的品质和等级则成为了关注的重点之一,因为好的红酒能够为人们带来更美好的品尝体验。
然而,传统的红酒评价方式多为人工,时间和成本较高。
近年来,基于数据挖掘技术的红酒质量评价与等级划分研究越来越受到人们的关注。
一、数据挖掘技术与红酒质量评价数据挖掘技术是一种从大量数据中自动发现规律的方法,可以帮助人们快速准确地对红酒进行品质评价。
数据挖掘技术不仅包括了基础的数据统计和分析方法,还包括了人工智能、机器学习和深度学习等高级算法,可以更加准确地对红酒进行评价和分类。
在红酒质量评价中,数据挖掘技术主要通过构建模型实现。
模型的构建包括了特征提取、特征选择、模型训练和模型应用等多个过程。
其中,特征提取是数据挖掘技术的关键。
红酒的特征包括了多种成分和属性,如酒精度、酸度、甜度、色泽、气味等。
在特征提取中,需要选择合适的特征来对红酒进行描述和评价,同时,还需要对特征进行标准化和归一化等预处理操作。
二、基于数据挖掘技术的红酒品质等级划分方法基于数据挖掘技术的红酒品质等级划分方法主要包括了基于聚类的划分和基于分类的划分两种方法。
基于聚类的划分方法是将相似的红酒样本划分在一类中,不同的红酒样本则归为不同的类别。
在聚类过程中,需要选择合适的距离计算方法、聚类算法和聚类评价指标等。
在红酒品质等级划分中,可以选择基于距离的层次聚类或基于密度的DBSCAN聚类等算法来进行。
同时,也需要根据实际情况选择合适的聚类评价指标,如轮廓系数、DB指数等。
基于分类的划分方法是将红酒样本划分到已知的品质等级类别中。
在分类过程中,需要选择合适的分类算法和分类评价指标等。
在红酒品质等级划分中,可以选择k-NN、SVM、决策树等分类算法来进行。
同时,也需要根据实际情况选择合适的分类评价指标,如准确率、召回率、F1值等。
三、基于数据挖掘技术的红酒品质等级划分案例基于数据挖掘技术的红酒品质等级划分已经有一些实际应用案例。

全国大学生数学建模竞赛A题葡萄酒评价分析葡萄酒是一种古老而美妙的饮品,其种类繁多,风味各异。
如何对葡萄酒进行准确的评价和分析成为了葡萄酒爱好者和生产商们共同关注的问题。
在此次全国大学生数学建模竞赛A题中,我们将围绕葡萄酒的评价和分析展开讨论。
1. 引言葡萄酒是一种由葡萄经过发酵而成的酒类饮品。
葡萄酒的风味和品质受到许多因素的影响,如产地、葡萄品种、酿造工艺等。
为了准确评价葡萄酒的质量和特点,我们需要建立相应的评价指标和模型。
2. 数据分析为了进行葡萄酒评价,我们首先需要收集相关的数据。
通过对不同品牌、不同种类的葡萄酒进行采样和测试,我们可以获得葡萄酒的关键指标,如酒精含量、酸度、甜度、单宁含量等。
在数据分析中,我们可以运用统计学方法和数学建模技术,对数据进行整理和处理。
通过计算均值、方差、相关系数等指标,我们可以得到葡萄酒的基本特征和相互之间的关系。
3. 葡萄酒评价指标体系建立基于数据分析的结果,我们可以建立葡萄酒评价指标体系。
这一体系应该包含对葡萄酒各项指标的评价方法和权重。
常见的评价指标包括酒精含量、色泽、香气、口感等。
在指标体系中,我们可以采用层次分析法,通过对各个指标的重要性进行排序和评估。
同时,还可以利用数学模型,将各项指标综合起来,得到最终的评价结果。
4. 葡萄酒评价模型构建在对葡萄酒进行评价时,我们可以利用数学建模方法构建评价模型。
常用的模型包括多元回归模型、灰色关联度模型等。
多元回归模型可以用来分析葡萄酒各项指标之间的关系,进而预测葡萄酒的品质。
灰色关联度模型则可以用来度量葡萄酒各个指标对品质的影响程度。
通过不断地调整模型和参数,我们可以得到更准确的葡萄酒评价结果,并为葡萄酒生产商提供有针对性的改进建议。
5. 葡萄酒评价系统设计为了方便葡萄酒评价和分析的实施,我们可以设计一个葡萄酒评价系统。
该系统可以包括数据输入、数据处理、指标评价、模型计算等功能模块。
数据输入模块用于将葡萄酒相关数据录入系统。

基于机器学习的红酒质量检测研究随着世界科技的不断进步和发展,人工智能技术也逐渐走向成熟。
在各行各业中,人工智能技术已经开始发挥其独特的优势,掀起了一场马不停蹄的技术革命。
其中,基于机器学习的红酒质量检测研究已经成为了该领域中的一个热点话题。
红酒的质量往往是影响消费者购买的一大关键因素。
传统的红酒质量检测方式采用人工品尝鉴定,不仅耗时费力,而且还存在主观的偏差和误判,无法保证判定结果的准确性。
而基于机器学习的红酒质量检测则可以有效地解决上述问题,实现自动化、精确化、快速化检测。
首先,咱们来了解一下机器学习的基本概念。
机器学习是一门人工智能领域的重要分支,它通过计算机程序模拟人类学习的过程,从而使计算机能够进行自主学习和探索数据规律。
在红酒质量检测中,机器学习算法会自动从大量的历史数据中提取特征,建立相应的模型,并对新的红酒质量数据进行预测鉴定。
那么,机器学习如何应用在红酒质量检测中呢?首先,我们需要有一个足够的数据集进行训练。
这些数据集可能包括红酒的产地、葡萄品种、酒精度、pH值等多个方面的信息。
然后,我们需要选择适合的机器学习算法进行训练和预测。
常见的算法包括支持向量机(SVM)、决策树(Decision Tree)、随机森林(Random Forest)等。
这些算法具有不同的特点和适用范围,需要根据具体情况进行选择。
最后,我们需要对模型进行评估和优化,以保证其准确性和稳定性。
随着机器学习技术的不断发展和完善,基于机器学习的红酒质量检测已经取得了一定的研究成果。
例如,澳大利亚南澳大学的研究人员利用机器学习算法,成功分类了超过6000种来自54个国家的红酒。
同时,该研究还通过与人工品鉴比较,证明了机器学习的鉴定结果更为准确可靠。
然而,基于机器学习的红酒质量检测也存在一些挑战和限制。
首先,数据集的质量和数量会直接影响模型的准确性和可靠性。
如果数据集过小或者存在大量的噪声数据,那么模型很难学习到有效的信息,导致鉴定结果不准确。

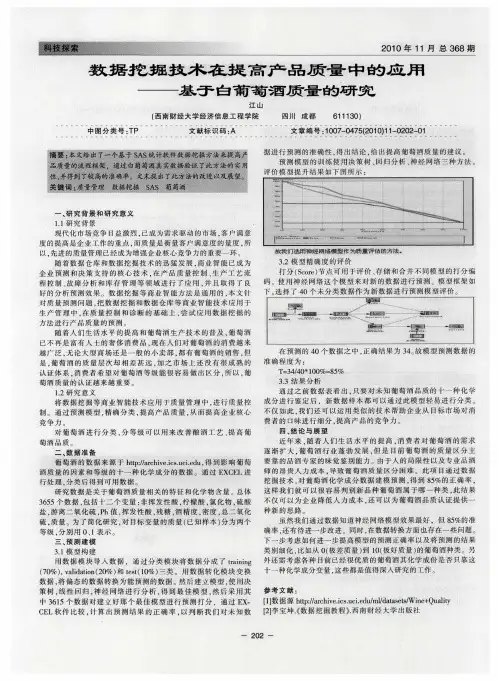
基于数据分析的葡萄酒评价模型摘要本文就葡萄酒的评价问题进行了分析研究,首先对所有评酒员的评分结果采用逐对比较法()1(2-≥=hn t hns hd ht hdα)和双样本t 假设检验法进行分析,然后对葡萄和葡萄酒的理化指标基本数据进行统计分析及无量纲化处理,再对其用主成分分析法(),,2,1,(),(p j i e x z p l ij i j i ij ===λ)、典型性相关分析法、多元线性规划分析法([][]alpha X Y regress stats r b b ,,int,int,,=,int),(r r rcopht )和TOPSIS 法(n j m i a a b mi ijijij ,,2,1,,,2,1,12===∑=)进行相关性分析,最后针对各个问题建立模型求解.针对问题一,我们首先利用EXCEL 对葡萄酒品尝评分表的分数数据进行处理,然后利用MATLAB 软件绘制出所有葡萄酒样品的分数曲线图,因为样本总体相同,i i y x -服从正态分布,采用逐对比较法得到两组红白葡萄酒综合评价的差值,确定出两组评分无显著性差异.再利用双样本t 假设检验方法判断最终得出第二组评酒员的评分结果更可信.针对问题二,我们首先利用EXCEL 及MATLAB 软件对附件二指标总表中的一、二级指标数据分别进行处理,然后利用主成份分析法,用贡献率(),,2,1(1p i pk ki=∑=λλ)对各主成分加权求和,得到样本总得分,由于我们在问题一中已得出第二组评酒员的评分结果更可信,故设样本总得分与第二组数据符合二八原理,计算得到一组综合分数,最终分析确定红葡萄可分为五个等级,白葡萄可分为六个等级.针对问题三,我们首先对酿酒葡萄和葡萄酒的理化指标数据进行预处理,提取两个有代表性的综合变量,再利用典型性相关分析处理得到两组指标之间的整体相关性联系,呈现出对应相关关系.针对问题四,由于在问题三中已得出酿酒葡萄和葡萄酒的理化指标之间存在着整体相关关系,我们首先对附件二指标总表中的数据进行无量纲化处理,然后采用多元线性回归分析得到酿酒葡萄和葡萄酒的理化指标与葡萄酒质量(分数)的线性相关关系,最后利用TOPSIS 法论证确定出不能用葡萄和葡萄酒的理化指标来评价葡萄酒的质量.关键字 t 假设检验 无量纲化 主成分分析 典型性相关分析 多元线性规划分析一问题提出1.1问题重述确定葡萄酒质量时一般是通过聘请一批有资质的评酒员进行品评.每个评酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量.酿酒葡萄的好坏与所酿葡萄酒的质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量.附件1给出了某一年份一些葡萄酒的评价结果,附件2和附件3分别给出了该年份这些葡萄酒的和酿酒葡萄的成分数据.请尝试建立数学模型讨论下列问题:1. 分析附件1中两组评酒员的评价结果有无显著性差异,哪一组结果更可信?2. 根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒葡萄进行分级.3. 分析酿酒葡萄与葡萄酒的理化指标之间的联系.4.分析酿酒葡萄和葡萄酒的理化指标对葡萄酒质量的影响,并论证能否用葡萄和葡萄酒的理化指标来评价葡萄酒的质量?1.2 问题分析问题要求我们通过研究葡萄酒和酿酒葡萄的理化指标以及葡萄酒的品尝评分,分析评价结果的差异性、可信度,以及酿酒葡萄对葡萄酒质量之间的影响,说明酿酒葡萄与葡萄酒的理化指标之间的关系,确定是否能用葡萄酒和葡萄的理化指标来评价葡萄酒的质量.问题一,根据附件一中两组品酒员对红白两种葡萄酒的评分,利用逐对比较法得出hd,bd,hs,bs,hd,bd,再得出btht,值,在利用双样本均值差t检验法得出两组评价结果有无显著性差异,再对所得数据进行双样本t假设检验方法判断哪组更可信.问题二,根据附件二中酿酒葡萄的理化指标,先对每种含量进行求和再平均,(见附录三表三、表四),然后利用主成分分析法,得出所有成分中的主成分、特征值特征向量以及主成分得分等,最后利用贡献率对主成分得分加权,得出一组得分,将总得分与附件一中二组的数据根据一定的比例进行加权计算,得到总得分,对总得分进行排序,就得到了酿酒葡萄的分级.问题三,针对本问题,先提取两组变量中具有代表性的数据,利用典型性分析,对这些数据建模求解,得到一个整体的相关性.反应酿酒葡萄与葡萄酒理化指标之间的联系.问题四,因为酿酒葡萄和葡萄酒的理化指标之间有联系,所以在考虑他们对葡萄酒质量影响时,可以把它们两个综合起来考虑对葡萄酒质量的影响,即希望能建立一种关系,所以用多元线性回归分析,这样便能得出它们对葡萄酒的质量有否影响.二模型假设1、假设题目所给数据真实可靠.2、假设每组评酒员品的是同一样酒.3、假设附件一中评酒员的评价结果反映了葡萄酒的质量.4、假设葡萄酒样品和葡萄酒一一对应,例如27号红葡萄酒是由27号红葡萄生产而来.5、假设二级指标影响很小,我们可以忽略它的影响.6、不考虑因个人口味、爱好不同对葡萄酒打分的影响,不考虑因环境等不同对葡萄酒和葡萄理化指标的影响.三符号说明x:第一组得分.y:第二组得分.hx:第一组每位品酒师对每个红酒样品各个方面评分的和,即综合评价.bx:第一组每位品酒师对每个白酒样品各个方面评分的和,即综合评价.hy:第二组每位品酒师对每个红酒样品各个方面评分的和,即综合评价.by:第二组每位品酒师对每个白酒样品各个方面评分的和,即综合评价.hd:两组红葡萄酒综合评价的差值.bd:两组白葡萄酒综合评价的差值.hs:hd的标准差.bs:bd的标准差.hd:hd的平均值.bd:bd的平均值.hn:红葡萄酒样品个数,即27.bn:白葡萄酒样品个数,即28.四模型建立与求解问题一1、数据处理利用附件一中的数据,求出每个评酒员对每个酒样评价的综合评分,用MATLAB 对这些数据进行处理,见附录三(表一,表二).2、模型建立我们首先考虑对每个样品的十个综合评分求平均值,用MATLAB作图(见下图),结果不能判断有无显著性差异.然后采用逐对比较法,以红葡萄酒为例:红葡萄酒共有27对相互独立的观察结果:),(,),,(),,(27272211hy hx hy hx hy hx ,令272727222111,,,hy hx hd hy hx hd hy hx hd -=-=-= ,则2721,,,hd hd hd 相互独立,又由于2721,,,hd hd hd 是有统一因素所引起的,可认为他们服从同一分布.今假设i hd ~),(2hd hd N δμ,27,,2,1 =i .这就是说2721,,,hd hd hd 构成正态总体),(2hd hd N δμ的一个样本,其中2,hd hd δμ未知.我们需要基于这一样本检验假设: (1);0:,0:10≠=hd hd H H μμ (2);0:,0:10〉≤hd hd H H μμ (3) ;0:,0:10〈≥hd hd H H μμ分别记2721,,,hd hd hd 的样本均值和样本方差的观察值,hd 2hd s .检验问题(1),(2),(3)的拒绝域分别为(显著性水平为α):)1(2-≥=hn t hns hd ht hdα,)1(-≥=hn t hns hd ht hdα, )1(--≤=hn t hns hd ht hd α.现在回过来讨论本例的检验问题.先做出同一试块分别由y x h h ,测得的结果之差.按题意需检验假设;0:,0:10≠=hd hd H H μμ现在4786.2)26()26(,27005.02===t t h n ε即知拒绝域为4786.2≥=hns hd ht hd.若4786.2〈ht ,则t 的值不落在拒绝域内,故接受0H ,认为两组对红葡萄酒的评分无显著性差异,反之则反. 3、 模型求解利用逐对比较法(程序见附录二附件一),求出ht 与bt (见图1),在α=0.01下进行t 分布的显著性分析,得出两组评酒员的评价结果无显著性差异,再对数据进行双样本均值差t 检验法(见图二),结果得出二组更可信.问题二1、 数据分析首先对附件二酿酒葡萄的理化指标进行数据处理(见附录三表三、表四) 2、 模型建立1)计算相关系数矩阵⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=pp p p p p r r r r r r r r r R 212222111211... (1) ij r (p j i ,...2,1,=)为原变量的i x 与j x 之间的相关系数,其计算公式为∑∑∑===----=nk nk j kj i kij j k nk i ik j i x x x xx x x xr 11221)()()()( (2)因为R 是是对称矩阵(即i j j i r r =),所以只需计算上三角元素或下三角元素即可. 2)计算特征值与特征向量首先解特征方程0=-R I λ,通常可用雅可比法(Jacobi )求出特征值),,2,1(p i i =λ,并使其按顺序大小排列,即0...,321≥≥≥≥p λλλλ;然后分别求出对应于特征值i λ的特征向量),,2,1(p i e i =.这里要求,1=即∑==pj ij e 121,其中ij e 表示向量i e 的第j 个分量.3)计算主成分贡献率及累计贡献率 主成分i z 的贡献率i α为),,2,1(1p i pk ki=∑=λλ累计贡献率为),,2,1(11p i pk kik k=∑∑==λλ一般取累计贡献率达85-95%的特征值m λλλλ,,,,321 所对应的第一、第二、第)(p m m ≤个主成分. 4)计算主成分载荷量 其计算公式为),,2,1,(),(p j i e x z p l ij i j i ij ===λ (3)得到各主成分的载荷后,利用特征向量,得到各主成分的得分⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=nm n n m m z z z z z z z z z Z 212222111211 (4)5)主成分分析用于系统评估利用主成分p z z z ,,,21 做线性组合,并以每一个主成分i z 的方差贡献率i α作为权数,构造一个综合评价函数p p z z z y ⋅++⋅+⋅=ααα 2211 (5) 也称y 为评估指数,依据对每个样品得出的y 值进行分级. 3、 模型求解利用MATLAB 编写程序,得出y 的值.(程序见附录二附件二) 得出的y 值越大说明酿酒葡萄的质量越高,葡萄酒质量的衡量用附件一中二组的数据(由题一知二组比一组更可靠),利用二八原理得出葡萄酒和酿酒葡萄的综合得分(见附录三表五),找出最大值max ,最小值min ,组距6min)(max -=d ,红葡萄酒得出5个小区间,划分为5个等级,白葡萄酒得出6个小区间,划分为6个等级,划分等1、 数据分析在两组变量中提取有代表性的两个综合变量,对综合变量进行标准化处理(见附录二附件三),利用这两个综合变量之间的相关关系来反映两组指标之间的整体相关性.2、 模型建立本模型对两组指标酿酒葡萄和葡萄酒的理化指标作典型相关分析.其中, 酿酒葡萄指标:211,,A A葡萄酒的理化指标:3022,,A A第一步,计算相关系数阵3030)(⨯=ij r R ,具体结果见附录表1A 2A … 29A 30A⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡--------0000.13113.02401.03680.03113.00000.13486.01073.02401.03486.00000.11097.03680.01073.01097.00000.1302921A A A A 第二步,典型相关系数及其检验,将酿酒葡萄指标和葡萄酒的理化指标数据经过整理利用 MATLAB 软件的canoncorr 函数进行处理,得出如表1所示结果:由表1可知,前6个典型相关系数均较高,表明相应典型变量之间密切相关.进行相关系数的2χ统计量检验确定典型变量相关性的显著程度,比较统计量2χ计算值从上表得知这9对典型变量均通过统计量检验,表明相应典型变量之间相关关系显著,酿酒葡萄与葡萄酒的理化指标之间有相关联系.第三步:典型相关模型由于原始变量的计量单位不同,不宜直接比较,本文采用标准化的典型系数,给出典型相关模型,如公式⑴~⑹所示⎪⎪⎪⎩⎪⎪⎪⎨⎧+++++=++++++++++++-=302928272625242322121201918171615141312111098765432110.1859A -0.1243A 0.8060A0.9033A - 0.1438A 0.7253A 1.1161A -0.5222A 0.9882A V0.2576A - 0.6898A 0.6145A 0.3881A 0.8054A -0.9221A -0.0797A 0.8424A 0.1035A-0.1112A 0.6588A 0.5552A - 0.6333A - 0.8875A 2.1858 -0.53080.07880.53010.0333- 0.14192666.0 A A A A A A A U ⑴ ⎪⎪⎪⎩⎪⎪⎪⎨⎧++++++=++++++++=302928272625242322221201918171615141312111098765432120.3811A 1.0582A 1.9635A0.7222A 0.6133A - 1.1626A -2.8979A 1.2812A - 0.5658A V0.2346A 0.2256A -0.1844A 0.1093A 0.0087A -1.4993A 0.1513A 0.7407A - 0.6954A-0.6504A - 0.3317A - 0.1804A - 0.0854A - 0.6617A -0.7315 0.2775 0.4173- 0.0114 0.0908- 0.8853-0.1777 A A A A A A A U ⑵ ⎪⎪⎪⎩⎪⎪⎪⎨⎧+-+++=+++++-+++++=302928272625242322321201918171615141312111098765432130.6108A 1.1652A -0.2270A0.2647A 0.5229A 0.4005A 1.3208A -0.3465A -0.0115A V0.7740A 0.0768A 0.1494A - 0.5894A 0.7736A 0.8003A 0.0571A 0.0390A -0.1631A - 0.1316A 0.3281A - 0.3523A - 0.5051A 0.7135A -1.9691 1.6219-0.6603 1.1176-0.4611- 0.0626 -0.1341A A A A A A A U ⑶ ⎪⎪⎪⎩⎪⎪⎪⎨⎧-++++=++++++++++++=302928272625242322421201918171615141312111098765432140.8632A - 0.6128A -2.1413A0.3405A 0.1296A 0.1725A 1.7119A -1.1137A 2.7421A - V0.4821A 0.2111A -0.0337A - -0.4764A 0.8511A - 3.8525A -0.4394A -0.8279A 0.7593A 1.6148A 1.4068A 0.0829A 0.4232A -1.5406A 2.0668 -0.90220.17060.2461-0.5411 0.1621-0.0964A A A A A A A U ⑷ ⎪⎪⎪⎩⎪⎪⎪⎨⎧-+++=+++++++++++=302928272625242322521201918171615141312111098765432150.9032A -0.5843A -1.5873A0.0911A - 0.1586A 0.1056A 1.3940A 1.8497A -1.4755A - VA 0.2073 0.0210A 0.6044A - 0.1196A - 0.8591A 0.2084A 0.2593A -0.1736A - 0.7033A - -0.3871A - 0.0474A 0.1275A - 0.3342A 0.0629A - 1.6602 -1.22400.1262 0.3456- 0.4287- 0.2810 -0.0774A A A A A A A U ⑸ ⎪⎪⎪⎩⎪⎪⎪⎨⎧-++=+++++++++++++=302928272625242322621201918171615141312111098765432160.0113A - 0.2930A -1.2336A 0.5983A 0.6340A 1.1863A -1.1943A -0.1001A -0.1006A V1.1199A 1.6234A -0.5710A - 0.4459A 1.2038A 1.1480A -1.0176A -0.2293A 0.1792A0.1712A 0.4702A 0.3912A 0.8888A 0.0378A - 1.1037 2.3197-0.59180.4889-0.2723 0.3094 0.3201- A A A A A A A U ⑹ 3、结果分析由公式⑴典型相关方程可知,酿酒葡萄的主要指标是7A ,8A ,14A ,16A ,17A ,说明酿酒葡萄中影响葡萄酒理化指标的主要因素是总酚(7A )、单宁(8A )、PH(14A )、干物质含量(16A )、果穗质量(17A ),葡萄酒的第一典型变量1V 与22A ,24A ,27A ,28A 呈高度相关;根据公式⑵典型相关方程,2A (花色苷)是酿酒葡萄的主要因素,葡萄酒的第二典型变量2V 与23A ,24A ,25A ,28A ,29A 呈高度相关;公式⑶中酿酒葡萄的主要指标是6A ,7A ,16A ,葡萄酒的第三典型变量3V 与24A ,29A 呈高度相关;公式⑷酿酒葡萄的主要指标是6A ,7A ,8A ,11A ,12A ,14A ,17A ,葡萄酒的第四典型变量4V 与22A ,23A ,24A ,28A 呈高度相关;公式⑸酿酒葡萄的主要指标是6A ,7A ,葡萄酒的第五典型变量5V 与22A ,23A ,24A ,28A 呈高度相关;公式⑹酿酒葡萄的主要指标是15A ,16A ,17A ,20A ,21A ,葡萄酒的第六典型变量6V 与24A ,25A ,28A 呈高度相关.由于第一组典型变量信息比重较大,所以总体上酿酒葡萄与葡萄酒主要理化高度相关的主要指标是7A ,6A ,16A ,17A ,8A ,14A ,2A ,11A ,12A ,14A ,15A ,20A ,21A ,反映葡萄酒的理化指标与酿酒葡萄高度相关的指标为22A ,23A ,24A ,25A ,27A ,28A ,29A .问题四1、模型建立[][]alpha X Y regress stats r b b ,,int,int,,= int),(r r rcophtn j m i aa b mi ijijij ,,2,1,,,2,1,12 ===∑=程序见附表二附件,残差图见附录一图三、图四. 2、结果分析 以红葡萄酒为例 2997.5;5148.7010==ββ y =70.5148+5.29971x ,9842.02=r ;(越接近于1,回归效果越显著) 05.00255.0≤=p ,回归模型成立.从残差图可以看出,除第8,11,20三个数据外,其余数据的残差离零点均较近,且残差的置信区间均包含零点,这说明回归模型y =70.5148+5.29971x ,能较好的符合原始数据,而这三个个数据可视为异常点. 同理,白葡萄的多元线性回归成立. 用TOPSIS 法,对能否用葡萄酒和葡萄酒的理化指标来评价葡萄酒的质量进行分析, (1)用向量规划化的方法求得规范决策矩阵。
上海大学2013-2014学年春季学期硕士研究生课程考试课程名称:数据挖掘与商务智能课程编号: 29SBG9016论文题目:基于C5.0算法的白葡萄酒品质分析研究生姓名(学号):论文评价:论文成绩:任课教师:评阅日期: 2014年6月基于C5.0算法的白葡萄酒品质分析摘要:针对目前消费者对葡萄酒的需求日益强烈,很多大的庄园希望为顾客提供品质优秀的葡萄酒,本文使用测量优先度信息增益率的计算方法,对某庄园现有葡萄酒的客观理性数据进行分析处理,在SPSS Clementine 12.0数据挖掘平台使用C5.0算法模型进行数据挖掘,构造了对葡萄酒品质进行分类的决策树模型,经分析评估正确率为72.71%,从而帮助庄园在大数据环境下利用数据挖掘技术进行葡萄酒品质的判别,有效地减少因品酒师个人因素带来的评级波动。
关键词:葡萄酒;品质;决策树;C5.0算法;Clementine数据挖掘平台1 引言葡萄酒品质测定是葡萄酒行业进行质量管理的一种重要手段,测定葡萄酒品质需要品酒师依靠个人感官和经验来进行判定。
品酒师通过观察葡萄酒的颜色、质感等外观特性以及葡萄酒的香气,并且采用品尝的方式感受葡萄酒的滋味和口感。
然而,人工品酒具有一定的主观性,依赖于品酒师的经验以及当前的状态,所评定出来的葡萄酒级别存在评级不稳定的问题,难以在业内得到共识。
另外,葡萄酒的质量安全与公众身体健康密切相关,其中葡萄酒质量检测技术是保障葡萄酒质量安全的重要手段,采用自动化手段检测葡萄酒质量及安全是提高葡萄酒质量检测手段的一种有效方法。
针对这个问题,采用数据挖掘算法中的C5.0算法进行葡萄酒品质预测,该方法具有准确率高、算法简单和高效的优点,尤其适合对大量数据信息分析挖掘,在葡萄酒行业中品质预测应用中,能够有效地减少因品酒师个人因素带来的评级波动。
2 算法概述2.1 C5.0算法概述C5.0是决策树模型中的算法,最早的算法是亨特CLS(Concept Learning System)提出,后经发展由Quinlan.J.R在1979年提出了著名的ID3算法,主要针对离散型属性数据。
红酒评级的科技应用与大数据分析红酒作为一种高品质的饮品,一直以来都备受人们的喜爱。
然而,红酒品质的评判一直是一个相对主观的过程。
随着科技的不断进步与大数据分析的广泛运用,红酒评级也得以更加客观、准确和科学化。
本文将介绍红酒评级的科技应用以及大数据分析对红酒评级的影响。
一、红酒评级科技应用的发展随着科技的进步和人们对红酒品质要求的提高,红酒评级的科技应用得到了加强。
现在,许多红酒评级机构和专家利用各种科技手段进行红酒品质的评判,其中最为常见的有以下几种:1. 科学仪器分析法:红酒品质的评判往往需要借助于一系列科学仪器来进行。
比如,通过质谱仪、气相色谱仪等分析仪器可以对红酒中的化学成分进行精确分析,从而评估其香气、酸度、单宁含量等参数。
2. 电子鼻技术:电子鼻是一种模拟人类嗅觉系统的仪器,可以模拟人类嗅觉的感知能力。
通过培训电子鼻识别红酒的特定香气,可以高效地评价红酒的香气特征。
3. 数字图像处理技术:数字图像处理技术可以被应用于红酒的颜色分析。
通过采集红酒的彩色图像,利用图像处理算法计算红酒的色调、饱和度和明度,从而对红酒的颜色进行评估。
二、大数据分析在红酒评级中的应用大数据分析作为一种强大的技术工具,也为红酒评级提供了新的方法和视角。
通过收集和分析红酒相关的海量数据,可以发现一些关联规律和趋势,从而更加准确地评价红酒的品质。
大数据分析在红酒评级中的应用主要有以下几个方面:1. 市场趋势分析:通过大数据分析,可以了解红酒市场的供需关系、价格变动趋势、消费者偏好等信息。
这可以帮助红酒评级机构和生产商做出更加合理的品质评判和市场定位。
2. 消费者反馈分析:大数据分析可以对消费者在社交媒体、网上评论等渠道中的评价进行搜集和分析。
通过分析消费者的反馈,可以了解红酒的市场口碑和受欢迎程度,为红酒评级提供更多参考依据。
3. 品质与价格的关联分析:大数据分析可以挖掘出红酒品质和价格之间的关联规律。
通过分析大数据,可以找到红酒品质与价格之间的最佳平衡点,使消费者能够获得尽可能高品质的红酒,同时又能以合理的价格购买。
基于数据挖掘技术的红酒评分预测模型的设计与分析作者:王柏来源:《现代商贸工业》2019年第07期摘要:随着现代社会的快速发展,红酒行业已慢慢走向全球化与大众化,更多的红酒品牌和品种也逐渐被世人所知。
然而,红酒品质也分三六九等,如何判断一款红酒是优是劣?利用SPSS,Excel等软件,使用回归、决策树、聚类等经典机器学习算法,对红酒的价格、评分、产地等因素进行统计与分析。
最终得出红酒的原产国,省份以及品种基本可以决定红酒的优劣。
关键词:红酒;数据挖掘;机器学习中图分类号:TB文献标识码:Adoi:10.19311/ki.1672-3198.2019.07.1001前言红酒,是一种有着漫长历史的饮品。
早在公元前1000年,红酒就在地中海沿岸大部分地区繁衍传播,并逐漸发展成为高档饮品。
在全世界的基督教信徒的眼中,红酒被视为耶稣的血液,这一点也促进了红酒的平民化。
红酒不仅仅给人以高雅和浪漫的感觉,在很多女性心中还有美容驻颜的功效,随着时间的推移,社会也在快速发展,人们生活水平逐步提升,红酒市场目前拥有着巨大的发展潜力和良好的发展前景,红酒也将逐渐走向全球化与大众化,让越来越多的人有机会去品尝。
近年来,越来越多的人更加讲究红酒的品质,传统红酒的品鉴,要考虑红酒的香气、口感、结构、酿造工艺、风土和价格等综合因素。
但这些复杂的品鉴技术需要积年累月的品酒经验,对于大多数普通人来说,学习这门技术并不容易。
因此,人们对于红酒的品质界定十分地模糊,并不清楚哪些红酒档次较高,而哪些红酒档次相对较低。
为了帮助人们通过更简单直接的方法去了解红酒的品质,本文根据Kaggle网站上Wine Reviews专题提供的129970组数据,使用决策树,聚类等经典机器学习算法,分析数据规律,建立了根据红酒产地、品种、制造商等因素预测红酒品质的模型;并探索了影响红酒档次的最主要因素。
该模型可以为喜欢红酒的人们提供参考,从而使他们对于红酒品质有着更加清晰的认识。
基于数据挖掘的葡萄酒质量识别我们知道,传统的葡萄酒鉴别靠感觉器官的品尝来判断其质量的好坏,这就必须要求品尝者是训练有素的品酒专家。
但感官品尝结果容易受各种因素的影响。
随着科学技术的发展,葡萄酒质量品鉴成了一项可以替代性的工作,不在局限于酿酒工作者的工作才能完成。
因此,将数据挖掘方法用于葡萄酒评级早已被各国所采用。
下面主要基于数据挖掘的分类和回归方法对葡萄酒质量的鉴别做一个简单的分析与判断。
1.数据挖掘理论方法论述1.1主成分回归在数据处理中,经常会遇到高维数据组,由于数据维数高,变量多,而且变量间往往存在相关关系,因此很难抓住他们的相关关系信息。
在实际问题中,研究多变量问题是经常遇到的,再加上变量指标之间有一定的相关性,这势必增加了问题的复杂性,主成分分析就是设法将原来指标重新组合成一组新的互相无关的较少的综合指标来代替原来的指标,同时根据实际需要从中可取几个较少的综合指标尽可能多的反映原来指标的信息。
这种将多个变量化为少数互相无关的综合指标的统计方法称为主成分分析。
主成分分析就是设法将原来众多具有一定相关性的变量重新组合成一组新的相互无关的综合指标来代替,通常数学上的处理就是将原来个变量作线性组合,作为新的综合指标,但是这种线性组合,需要加以限制。
假设第一个综合指标记为,自然希望尽可能多的反映原来指标的信息,这里最经典的方法是用的方差来表达,即越大,表示包含的信息越。
因此所有线性组合中所选取的应该是方差最大的,故将称为第一主成分,如果不足以代表原来个指标的信息,在满足的条件下,再考虑选取作为第二个主成分,同理可以构造第三,四,.....,第个主成分。
要求:(1)(2)求得的主成分为协房阵的特征向量为系数的线性组合。
得到主成分,提取所需要的前几个主要成分后,回归的过程与线性回归是一致的。
只是自变量变成了选取的主成分,因变量不变。
1.2 分类回归树1.2.1分类回归树的构建分类回归树的构建是通过学习给定的训练样本,寻找最佳的分支规则。
承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。
我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。
我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。
如有违反竞赛规则的行为,我们将受到严肃处理。
我们授权全国大学生数学建模竞赛组委会,可将我们的论文以任何形式进行公开展示(包括进行网上公示,在书籍、期刊和其他媒体进行正式或非正式发表等)。
我们参赛选择的题号是(从A/B/C/D中选择一项填写): A我们的参赛报名号为(如果赛区设置报名号的话):所属学校(请填写完整的全名):装甲兵工程学院参赛队员(打印并签名) :1. 刘戎翔2. 罗辉3. 谭立冬指导教师或指导教师组负责人(打印并签名):陈建华日期: 2012 年 9 月 9 日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):基于数据挖掘的葡萄酒质量识别摘要随着我国葡萄酒业的逐步发展,葡萄酒生产企业的规模和数量不断扩大。
但中国的葡萄酒业仍面临着进口酒的激烈竞争以及质量检测体系不明确带来的市场紊乱。
针对这些问题,本文分析了葡萄酒质量人工品尝存在的不足,并提出了如何提高基于数据挖掘技术的葡萄酒质量等级的识别率,对中国葡萄酒市场的稳定发展以及更好地酿造出高质量的葡萄酒有着实际的应用价值。
在数据挖掘中,经常会遇到不平衡数据的分析。
相对于多数类来说,少数类样本对准确率的影响力小,这意味着对所有样本进行分类,可以在不识别出任何少数类样本的情况下得到很高的正确率,识别少数类的分类规则也就被忽略了。
红酒评级的科技与数据分析红酒评级在选购红酒时起到了重要的作用,帮助消费者了解红酒的品质、口感和适宜搭配的食物。
而在现代科技的进步下,通过数据分析和技术手段,红酒评级的准确性和客观性得到了极大的提升。
本文将探讨红酒评级背后的科技和数据分析的应用。
一、科技手段在红酒评级中的应用随着科技的不断进步,红酒评级中的科技手段也得到了广泛应用。
首先,利用先进的仪器设备,可以对红酒进行精确的化学成分分析。
通过检测红酒中的酒精含量、酸碱度、单宁含量、挥发性酸等指标,可以客观地评估红酒的品质和口感。
其次,在红酒评级中,科技手段还包括了利用人工智能技术和大数据分析。
通过对海量的红酒品鉴数据进行深度学习和模式识别,可以建立起准确的红酒评级模型,提供科学的评级指标。
二、数据分析在红酒评级中的重要性数据分析在红酒评级中扮演着至关重要的角色。
首先,数据分析可以提供全面的红酒信息,为红酒评级提供依据。
通过对红酒产地、葡萄品种、酿造工艺等数据进行分析,可以了解红酒的特点和风味,帮助评级专家做出准确的评价。
其次,数据分析可以帮助建立红酒评级模型。
通过对历史评级数据的挖掘和分析,可以找到影响红酒品质和口感的关键指标,并据此建立评级模型,提高评级的准确性和客观性。
三、红酒评级科技与数据分析的优势红酒评级的科技与数据分析具有许多优势。
首先,科技手段可以提高评级的准确性和客观性。
传统的红酒评级往往依赖于评级人员的主观判断,容易受到个人偏好和主观因素的影响。
而科技手段可以通过客观的数据和指标进行评级,降低了主观性的影响。
其次,数据分析可以帮助消费者做出更明智的购买决策。
通过对红酒评级数据和市场价格的对比分析,消费者可以选择性价比更高的红酒,提高购买的满意度。
此外,科技与数据分析还可以促进红酒行业的发展,为红酒生产商提供改进产品质量和推广营销策略的参考依据。
四、红酒评级科技与数据分析的挑战与展望虽然红酒评级的科技与数据分析带来了许多优势,但也面临一些挑战。
基于大数据的红酒品质分类技术研究红酒品质分类一直以来都是酿酒界的研究热点之一、传统的红酒品质分类依赖于专家的感官评价和经验,这种方法不仅需要专业的品酒师,还存在主观性和一致性的问题。
随着大数据技术的快速发展,利用大数据进行红酒品质分类成为可能,并且逐渐得到了广泛的研究和应用。
大数据技术可以应用于红酒的品质分类的各个方面,包括红酒原材料的种植、酒厂的酿造技术、生产过程中的监测与控制、产区环境因素等。
首先,大数据可以用来分析红酒原材料的种植情况,包括葡萄的种类、种植地的土壤条件、气候特点等,通过对这些数据的分析和挖掘,可以找出对红酒品质影响较大的因素。
其次,大数据还可以用于酒厂的酿造技术优化,通过收集和分析酿酒过程中的各种数据,如发酵温度、酒液的酸碱度、酒液中的酒精含量等,可以实现对酿酒过程的监测和控制,从而提高红酒的品质。
另外,在红酒的品质分类中,还可以利用大数据来分析和挖掘消费者的评价数据和消费记录。
通过收集和分析消费者对不同红酒的评价和喜好,可以建立起红酒的品质分类模型,将红酒分为不同的等级或种类。
此外,还可以结合消费者的消费记录和购买意向,提供个性化的推荐服务,帮助消费者挑选符合自己口味的红酒。
大数据的应用对于红酒品质分类的研究有着重要的意义。
首先,通过大数据技术的应用,可以减少专家评价的主观性和不一致性,提高红酒品质分类的准确性和一致性。
其次,大数据的应用可以提供更加全面和细致的红酒品质评估,从而帮助酿酒师更好地改进酿造技术,提高红酒的品质。
最后,大数据的应用还可以实现对消费者需求的个性化分析和推荐,为消费者提供更好的购酒体验。
然而,大数据的应用在红酒品质分类研究中也存在一些挑战。
首先,大数据的收集和处理需要消耗大量的时间和资源,需要建立完善的数据采集和处理系统。
其次,红酒的品质分类涉及到多个因素的综合评估,需要建立复杂的数据模型和算法。
最后,红酒的品质分类是一个相对主观的问题,不同的消费者可能有不同的评价标准,这就需要建立适应多样性需求的红酒品质分类系统。
Advances in Applied Mathematics 应用数学进展, 2015, 4(4), 376-384Published Online November 2015 in Hans. /journal/aam/10.12677/aam.2015.44047The Study on Evaluation System of WineBased on Data MiningSizhe Wang1, Zhigang Wang2*, Yong He21Automation Professional Class 1301, School of Information Science and Engineering, Central South University, Changsha Hunan2College of Information Science and Technology, Hainan University, Haikou HainanReceived: Nov. 8th, 2015; accepted: Nov. 23rd, 2015; published: Nov. 30th, 2015Copyright © 2015 by authors and Hans Publishers Inc.This work is licensed under the Creative Commons Attribution International License (CC BY)./licenses/by/4.0/AbstractBased on Question A of Mathematical Contest in Modeling for college students in 2012, the empha-sis in this paper is mainly on the establishment of evaluation system of wine based on data mining technology. The wine quality is determined by the score of the wine tasting. We analyze the credi-bility of the liquor score by one-way ANOVA. We classify the wine grape by extracting common factors of some physical and chemical indicators from the wine grape, and by clustering the factor score and wine score. The stepwise regression model is established through the correlation be-tween the physical and chemical indicators and the physical and chemical indicators of wine grapes. By the regression model between the aroma substances and the score of the wine, the key physical and chemical indicators of wine quality will be found. In the end, some shortcomings of current rating system of wine will be pointed out.KeywordsEvaluation System of the Wine, Data Mining Technology, One-Way ANOVA, Cluster Analysis,Regression Analysis基于数据挖掘技术的葡萄酒评价体系研究王思哲1,王志刚2*,何勇21中南大学信息科学与工程学院自动化专业1301班,湖南长沙2海南大学信息科学技术学院,海南海口*通讯作者。
王思哲等收稿日期:2015年11月8日;录用日期:2015年11月23日;发布日期:2015年11月30日摘要本文以2012年高教社杯全国大学生数学建模竞赛A题为例,利用数据挖掘技术建立葡萄酒评价体系。
葡萄酒质量一般是通过聘请有资质的品酒员进行品尝评分,由于品酒员主观因素导致对酒样品的评分差异悬殊,我们通过方差分析对品酒员评分进行可信性研究;通过提取酿酒葡萄多个理化指标的公共因子,对因子得分和葡萄酒评分进行聚类,将酿酒葡萄进行分级研究;通过对葡萄酒理化指标和酿酒葡萄理化的数据进行相关性分析,利用逐步回归分析模型建立它们之间的依赖关系;利用葡萄酒芳香物质与葡萄酒评分之间的回归模型,找出决定葡萄酒质量的关键理化指标,最后指出现行葡萄酒评分体系的不足。
关键词葡萄酒评价,数据挖掘技术,方差分析,聚类分析,回归分析1. 引言在当今大数据时代,从数据库的挖掘出隐含的、先前未知的并有潜在价值的信息显得十分重要,多元统计方法是数据挖掘技术的关键要素。
多元统计分析是处理多维同体观测数据的数学方法,是数理统计学近几十年迅速发展的一个分支,计算机技术的发展为多元统计的方法应用提供了便利的计算工具。
多元统计的内容十分丰富,主要包括判别分析、聚类分析、主成分分析、因子分析、回归分析预测方法、方差分析、典型相关分析、时间序列等[1]-[11]。
多元统计方法在工业、农业、医学、气象、环境以及经济管理等诸多领域中有着十分广泛的应用。
本文以2012年高教社杯全国大学生数学建模竞赛A题为例,用多元统计序列方法建立葡萄酒评价体系。
确定葡萄酒质量时一般是通过聘请一批有资质的品酒员进行品评,每个品酒员在对葡萄酒进行品尝后对其分类指标打分,然后求和得到其总分,从而确定葡萄酒的质量。
酿酒葡萄的好坏与所酿葡萄酒质量有直接的关系,葡萄酒和酿酒葡萄检测的理化指标会在一定程度上反映葡萄酒和葡萄的质量。
附件1(见竞赛试题中的附件,本文略,下同)给出了某一年份两组品酒员对两组红葡萄酒和白葡萄酒的评分结果,附件2和附件3分别给出了该年份这些葡萄酒的和酿酒葡萄的成分数据,包括各种理化指标和芳香物质指标数据。
由于品酒员主观因素导致对酒样品的评分差异,我们分别构造以品酒员和酒样品为组别数据序列进行方差分析,通过比较F统计量值评价两组品酒员是否有显著性差异,对品酒员评分进行可信性研究;通过对酿酒葡萄的多个理化指标进行筛选,提取公共因子,并计算因子得分,然后将这些因子得分和葡萄酒评分进行聚类分析,将酿酒葡萄进行分级研究;通过对葡萄酒理化指标和酿酒葡萄理化指标相关性分析,利用逐步回归模型建立它们之间的线性关系;通过葡萄酒理化指标与葡萄酒评分之间的回归模型,建立酿酒葡萄理化指标与葡萄酒质量之间关系,给出决定葡萄酒质量的关键理化指标。
2. 葡萄酒评分的可信性研究考虑到品酒员之间可能存在个人评酒风格等主观差异因素,导致不同品酒员对同一葡萄酒的评分悬殊,影响葡萄酒质量鉴定,因此,必须对品酒员的评分主观因素进行检验。
附件1给出了两组红葡萄酒王思哲等品酒员对27个酒样品的评价得分和两组白葡萄酒品酒员对28组酒样品的评价得分。
对于评酒得分的偏差性检验和影响因素的数据挖掘技术,可以通过方差分析来实现。
方差分析主要是检验两组品酒员评价结果有无显著性差异,进而判断出哪组评价结果更为可信。
评价得分之间的差异可以分为两个部分,一部分是由于各葡萄酒样品之间的差异,称为条件误差,另一部分是各品酒员评酒风格之间的差异,称为试验误差,我们主要目的是分析得分差异是由于葡萄酒样品之间差异,还是由于品酒员主观差异造成的。
通过对两组红葡萄酒和两组白葡萄酒评价得分进行正态性检验可以看出都近似服从正态分布,我们分别构造以品酒员和酒样品为组别的数据序列进行方差分析(见表1)。
分析表1数据,基于品酒员和酒样品的显著性差异检验中,除第二组白葡萄酒酒样品差异不显著外,另七组的F统计量都大于基于显著性水平0.01的临界值,表明品酒员评酒风格和酒样品之间的差异都很显著。
进一步比较F统计量数值大小,第一组红葡萄酒评分差异主要来源于酒样品之间的差异,第二组红葡萄酒评分差异主要来源于品酒员评分差异;白葡萄酒评分差异主要来源于品酒员评分差异,酒样品之间的差异不很显著。
初步可以看出,对于红葡萄酒,第一组品酒员评分更为可信,两组白葡萄酒品酒员评分都不可信,品酒员间的差异过大将导致酒样质量差异的显著性被掩盖,结合实际分析,酒样评价中应尽可能缩小由于品酒员个人风格的原因而导致对同一酒样评价差异较大的情况,应尽可能将酒样之间质量的差异通过评价扩大,提高酒样的可识别度。
为此,将原始数据进行处理,原始数据进行处理方法有很多,如标准化处理、聚类处理、收敛区间处理等,我们采用数据标准化处理,降低品酒员之间的主观差异性(见表2)。
Table 1. Wine score variance analysis based on the raw data表1. 基于原始数据的葡萄酒评分方差分析表差异源总平方和自由度均方差F统计量F临界值第一组红葡萄酒品酒员3084.952 9 342.772 3.543 2.484 酒样品14,090.119 26 541.928 9.308 1.837第二组红葡萄酒品酒员3228.681 9 358.742 9.999 2.484 酒样品4186.830 26 161.032 4.675 1.837第一组白葡萄酒品酒员17,034.122 9 1892.68 26.830 2.481 酒样品6253.086 27 231.596 1.957 1.818第二组白葡萄酒品酒员6714.442 9 746.049 19.910 2.481 酒样品2714.811 27 100.549 1.795 1.818Table 2. Wine score variance analysis based on data standardization表2.基于数据标准化处理的葡萄酒评分方差分析表差异源总平方和自由度均方差F统计量F临界值第一组红葡萄酒品酒员0 9 0 0 2.484 酒样品152.698 26 5.873 13.300 1.837第二组红葡萄酒品酒员0 9 0 0 2.484 酒样品119.148 26 4.583 7.906 1.837第一组白葡萄酒品酒员0.196 9 0.022 0.022 2.481 酒样品93.467 27 3.462 4.942 1.818第二组白葡萄酒品酒员0.006 9 0.001 0.001 2.481 酒样品76.147 27 2.820 3.666 1.818王思哲等分析表2数据,对于四组品酒员评价数据序列,用于检验的F统计量值都接近于0,远低于基于显著性水平0.01的F临界值,四组酒样品数据序列的F统计量都大于基于显著性水平0.01的F临界值。