自变量中含有定性变量的回归分析
- 格式:pptx
- 大小:435.53 KB
- 文档页数:26





报告中的变量选择和回归分析方法引言:报告中的变量选择和回归分析方法是数据分析和统计学中的重要内容。
在研究报告和学术论文中,合理选择变量和进行回归分析可以有效地揭示变量之间的关系,提高分析的准确性和可靠性。
本文将从六个方面对报告中的变量选择和回归分析方法进行详细论述。
一、变量选择的意义变量选择是指在进行回归分析时,从众多可能的自变量中选择出最为重要和相关的变量。
合理的变量选择可以减少冗余变量的存在,避免数据过拟合问题,并提高模型的预测能力和可解释性。
变量选择的意义在于提高研究的效率和有效性。
二、变量选择的方法1. 相关系数法:通过计算自变量与因变量之间的相关系数,选择与因变量关系最为密切的自变量。
相关系数法既简单又直观,但在多变量分析中无法考虑到变量之间的相互作用。
2. 正向选择法:从众多可能的自变量中,逐步添加具有显著影响力的变量,并根据模型的显著性检验去除不显著的变量。
正向选择法可以一步步剔除不相关的变量,但可能会错过一些有用的变量。
3. 逆向选择法:从包含所有自变量的模型开始,逐步去除不显著的变量,直到剩下的自变量都显著。
逆向选择法可以保留所有可能有用的变量,但可能出现模型过于复杂的问题。
三、回归分析的基本原理回归分析是通过建立数学模型,分析自变量对因变量的影响程度和方向。
常见的回归分析方法包括线性回归、多元回归、逻辑回归等。
回归分析需要满足一些基本的假设和前提,如线性关系、多元正态分布等。
四、回归分析的评价指标回归分析的结果需要进行评价,以判断模型的拟合程度和可靠性。
常用的评价指标包括判定系数(R平方)、均方根误差(RMSE)、残差等。
这些指标可以帮助研究者判断模型的准确性,并进行模型的改进和优化。
五、回归分析的解读和应用回归分析的结果需要进行解读,以揭示自变量与因变量之间的关系。
解读回归系数可以确定变量之间的正负相关关系,判断自变量对因变量的影响程度。
回归分析的应用广泛,可以用于预测、控制和优化等多个领域。

XX师X学院课程教学大纲应用回归分析教学大纲(试行)课程编号:07160110 适用专业:统计学学时数:54 学分数: 3执笔人:黄建文审核人:赵兴杰系别:数学教研室:统计学教研室编印日期:二〇一三年八月前言一、课程性质与任务1. 课程授课对象本大纲适用于师X院校数学学科统计学专业本科生。
2. 课程的性质与任务《应用回归分析》课程是师X院校数学系统计学专业基础课程。
它是在学生掌握了一定的数学专业理论知识的基础上开设的。
3. 在人才培养过程中的地位及作用本课程是学生掌握统计学的基本思想、理论和方法的主要课程,是培养学生熟练应用计算机软件处理统计数据的能力的基础课程.通过本课程的学习,了解统计知识在相关领域(如社会经济、生物、医学、信息管理、保险金融等)的应用,使学生成为具有综合应用能力的应用型人才。
4. 在思想、知识和能力等方面达到的教学目标(1)从生活中的需要出发,并根据回归分析的内容和知识结构,把回归分析的一些基本问题分别组成若干专题,在内容上适当延伸和充实,在理论、观点和方法上予以提高。
(2)对各专题的教学,都要着重基本思维方法的培养和基本技能技巧的训练。
(3)结合学生生活实践,利用生活中的案例进行分析,培养学生的辩证唯物主义观点。
二、教学时间安排(总学时54)三、教材及主要参考书建议教材:何晓群.应用回归分析.中国人民大学,2011.四、学生阅读书目及参考文献1. 《数理统计》,胡发胜.宿洁编,XX大学,2004年9月2. 孙荣恒.应用数理统计.:科学,2003五、考核考核形式:本课程为考试课程。
试卷题型:填空、选择(单项)、判断、计算、证明。
小题总量在20~22个之间。
成绩评定:平时成绩(含平时作业、考勤、半期考试)占30%,期末考试占70%。
六、教学基本要求1. 备课:课程应有规X的教案及讲稿,针对不同班级,任课教师应在教案的统一要求下有比较详细的讲稿。
2. 教学方法与手段:根据内容和教学条件,由任课教师选择适当的教学方法与教学手段。
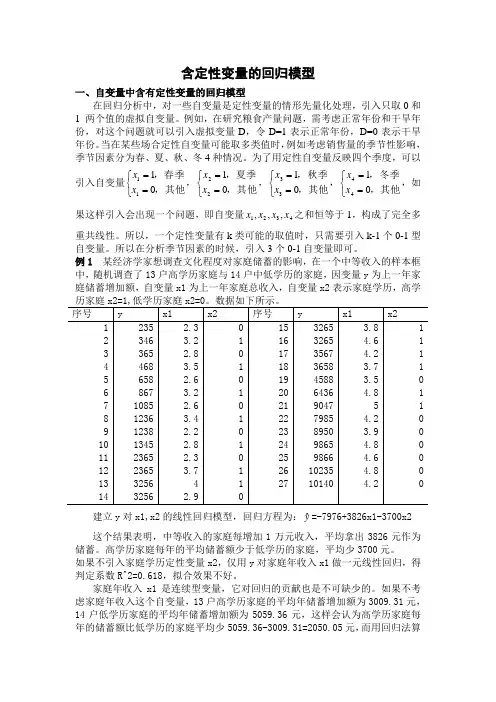
含定性变量的回归模型一、自变量中含有定性变量的回归模型在回归分析中,对一些自变量是定性变量的情形先量化处理,引入只取0和1 两个值的虚拟自变量。
例如,在研究粮食产量问题,需考虑正常年份和干旱年份,对这个问题就可以引入虚拟变量D ,令D=1表示正常年份,D=0表示干旱年份。
当在某些场合定性自变量可能取多类值时,例如考虑销售量的季节性影响,季节因素分为春、夏、秋、冬4种情况。
为了用定性自变量反映四个季度,可以引入自变量⎩⎨⎧==,其他,春季0111x x ,⎩⎨⎧==,其他,夏季0122x x ,⎩⎨⎧==,其他,秋季0133x x ,⎩⎨⎧==,其他,冬季0144x x ,如果这样引入会出现一个问题,即自变量4321,,,x x x x 之和恒等于1,构成了完全多重共线性。
所以,一个定性变量有k 类可能的取值时,只需要引入k-1个0-1型自变量。
所以在分析季节因素的时候,引入3个0-1自变量即可。
例1 某经济学家想调查文化程度对家庭储蓄的影响,在一个中等收入的样本框中,随机调查了13户高学历家庭与14户中低学历的家庭,因变量y 为上一年家庭储蓄增加额,自变量x1为上一年家庭总收入,自变量x2表示家庭学历,高学建立y 对x1,x2的线性回归模型,回归方程为:yˆ=-7976+3826x1-3700x2 这个结果表明,中等收入的家庭每增加1万元收入,平均拿出3826元作为储蓄。
高学历家庭每年的平均储蓄额少于低学历的家庭,平均少3700元。
如果不引入家庭学历定性变量x2,仅用y 对家庭年收入x1做一元线性回归,得判定系数R^2=0.618,拟合效果不好。
家庭年收入x1是连续型变量,它对回归的贡献也是不可缺少的。
如果不考虑家庭年收入这个自变量,13户高学历家庭的平均年储蓄增加额为3009.31元,14户低学历家庭的平均年储蓄增加额为5059.36元,这样会认为高学历家庭每年的储蓄额比低学历的家庭平均少5059.36-3009.31=2050.05元,而用回归法算出的数值是3824元,两者并不相等。
第7章含有定性信息的多元回归分析:二值(或虚拟)变量在前面几章中,我们的多元回归模型中的因变量和自变量都具有定量的含义。
就像小时工资率、受教育年数、大学平均成绩、空气污染量、企业销售水平和被拘捕次数等。
在每种情况下,变量的大小都传递了有用的信息。
在经验研究中,我们还必须在回归模型中考虑定性因素。
一个人的性别或种族、一个企业所属的产业(制造业、零售业等)和一个城市在美国所处的地理位置(南、北、西等)都可以被认为是定性因素。
本章的绝大部分内容都在探讨定性自变量。
我们在第7.1节介绍了描述定性信息之后,又在第7.2、7.3和7.4节中说明了,如何在多元回归模型中很容易地包含定性的解释变量。
这几节几乎涵盖了定性自变量用于横截面数据回归分析的所有流行方法。
我们在第7.5节讨论了定性因变量的一种特殊情况,即二值因变量。
这种情形下的多元回归模型具有一个有趣的含义,并被称为线性概率模型。
尽管有些计量经济学家对线性概率模型多有中伤,但其简洁性还是使之在许多经验研究中有用武之地。
虽然我们在第7.5节将指出其缺陷,但在经验研究中,这些缺陷常常都是次要的。
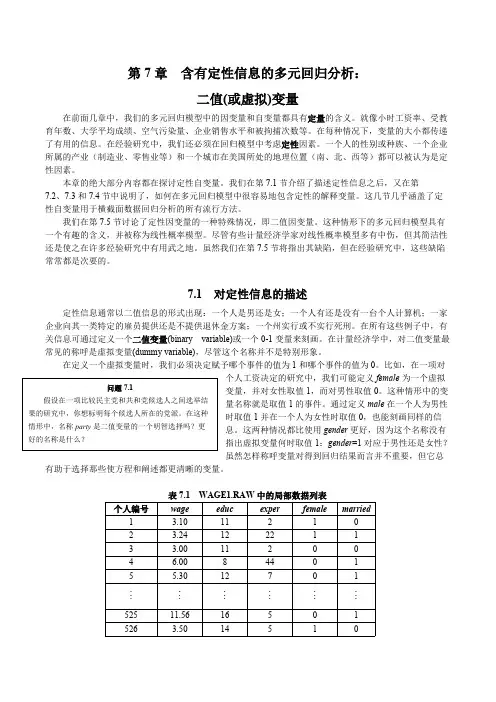
7.1 对定性信息的描述定性信息通常以二值信息的形式出现:一个人是男还是女;一个人有还是没有一台个人计算机;一家企业向其一类特定的雇员提供还是不提供退休金方案;一个州实行或不实行死刑。
在所有这些例子中,有关信息可通过定义一个二值变量(binary variable)或一个0-1变量来刻画。
在计量经济学中,对二值变量最常见的称呼是虚拟变量(dummy variable),尽管这个名称并不是特别形象。
在定义一个虚拟变量时,我们必须决定赋予哪个事件的值为1和哪个事件的值为0。
比如,在一项对个人工资决定的研究中,我们可能定义female 为一个虚拟变量,并对女性取值1,而对男性取值0。
这种情形中的变量名称就是取值1的事件。
通过定义male 在一个人为男性时取值1并在一个人为女性时取值0,也能刻画同样的信息。


常用回归方法回归分析是一种统计学方法,它着重于研究因变量和自变量之间的关系。
它还能够分析因变量的变化,预测未知的因变量,检验某些假设和评估影响因变量的因素。
归分析可以帮助研究人员分析特定的因素,如年龄、教育水平和收入,如何影响某种行为。
另外,它也可以用来模拟实际情况,以便更好地解释相关性。
除了回归分析之外,还有许多不同的回归方法可供选择。
本文将介绍其中常用的回归方法,并分析它们在实际应用中的优势和劣势。
一、最小二乘法最小二乘法是一种最常见的回归方法,它能够捕捉因变量与自变量之间的线性关系。
它的基本原理是,计算出一组参数量,使给定的观测数据和预期的值之间的差异最小。
最小二乘法具有计算简单、结果易于解释和可以拟合非线性关系等优点,但是,当数据有多重共线性或异常值时,它的效果将会受到负面影响。
二、多项式回归多项式回归是一种可以拟合多项式关系的回归方法。
它可以在自变量和因变量之间拟合更复杂的关系。
它的优势在于可以适用于各种复杂的函数关系,而缺点在于它可能会出现欠拟合或过拟合的情况。
三、岭回归岭回归是一种可以避免多重共线性问题的回归方法。
它比最小二乘法更加稳健,可以减少回归系数的估计误差。
它也可以用于处理大数据集。
但是,它需要更多的运算,并且可能会因模型过度拟合而失效。
四、主成分回归主成分回归是一种结合最小二乘法和主成分分析的回归方法。
它可以用来消除主成分之间的共线性,提高模型的预测准确性。
然而,它也有一些缺点,如只能处理线性模型,并且结果不太好理解。
五、逐步回归逐步回归是一种确定回归系数的方法,它可以自动添加有用的自变量来拟合模型,并自动删除不必要的自变量。
它的优势在于可以自动处理大量自变量,缺点在于可能会出现欠拟合或过拟合的情况。
六、多元逻辑回归多元逻辑回归是一种用于定量变量和定性变量之间的回归分析的方法,它用于对自变量的影响程度进行排序。
它的优势在于可以识别重要的自变量,缺点在于它不适用于非线性关系。