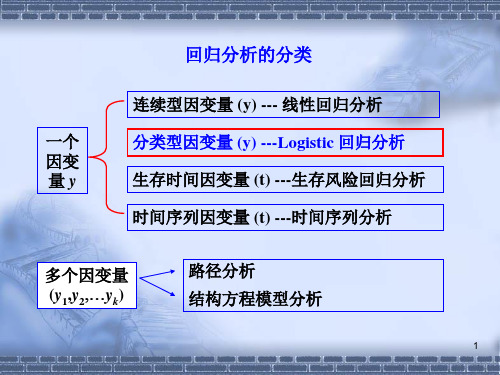
因变量是定性变量的回归分析—Logistic回归分析
- 格式:docx
- 大小:9.62 KB
- 文档页数:3


数据分析知识:数据分析中的Logistic回归分析Logistic回归分析是数据分析中非常重要的一种统计分析方法,它主要用于研究变量之间的关系,并且可以预测某个变量的取值概率。
在实际应用中,Logistic回归分析广泛应用于医学疾病、市场营销、社会科学等领域。
一、Logistic回归分析的原理1、概念Logistic回归分析是一种分类分析方法,可以将一个或多个自变量与一个二分类的因变量进行分析,主要用于分析变量之间的关系,并确定自变量对因变量的影响。
Logistic回归分析使用的是逻辑回归模型,该模型是将自变量与因变量的概率映射到一个范围为0-1之间的变量上,即把一个从负无穷到正无穷的数映射到0-1的范围内。
这样,我们可以用这个数值来表示某个事件发生的概率。
当这个数值大于0.5时,我们就可以判定事件发生的概率比较高,而当这个数值小于0.5时,我们就可以判定事件发生的概率比较小。
2、方法Logistic回归分析的方法有两种:一是全局最优化方法,二是局部最优化方法。
其中全局最优化方法是使用最大似然估计方法,而局部最优化方法则是使用牛顿法或梯度下降算法。
在进行Logistic回归分析之前,我们首先要对数据进行预处理,将数据进行清洗、变量选择和变量转换等操作,以便进行回归分析。
在进行回归分析时,我们需要先建立逻辑回归模型,然后进行参数估计和模型拟合,最后进行模型评估和预测。
在进行参数估计时,我们通常使用最大似然估计方法,即在估计参数时,选择最能解释样本观测数据的参数值。
在进行模型拟合时,我们需要选取一个合适的评价指标,如准确率、召回率、F1得分等。
3、评价指标在Logistic回归分析中,评价指标包括拟合度、准确性、鲁棒性、可解释性等。
其中最常用的指标是拟合度,即模型对已知数据的拟合程度,通常使用准确率、召回率、F1得分等指标进行评价。
此外,还可以使用ROC曲线、AUC值等指标评估模型的性能。
二、Logistic回归分析的应用1、医学疾病预测在医学疾病预测中,Logistic回归分析可以用来预测患某种疾病的概率,如心脏病、肺癌等。

统计学中的Logistic回归分析Logistic回归是一种常用的统计学方法,用于建立并探索自变量与二分类因变量之间的关系。
它在医学、社会科学、市场营销等领域得到广泛应用,能够帮助研究者理解和预测特定事件发生的概率。
本文将介绍Logistic回归的基本原理、应用领域以及模型评估方法。
一、Logistic回归的基本原理Logistic回归是一种广义线性回归模型,通过对数据的处理,将线性回归模型的预测结果转化为概率值。
其基本原理在于将一个线性函数与一个非线性函数进行组合,以适应因变量概率为S形曲线的特性。
该非线性函数被称为logit函数,可以将概率转化为对数几率。
Logistic回归模型的表达式如下:\[P(Y=1|X) = \frac{1}{1+e^{-(\beta_0+\beta_1X_1+...+\beta_pX_p)}}\]其中,P(Y=1|X)表示在给定自变量X的条件下,因变量为1的概率。
而\(\beta_0\)、\(\beta_1\)、...\(\beta_p\)则是待估计的参数。
二、Logistic回归的应用领域1. 医学领域Logistic回归在医学领域中具有重要的应用。
例如,研究者可以使用Logistic回归分析,探索某种疾病与一系列潜在风险因素之间的关系。
通过对患病和非患病个体的数据进行回归分析,可以估计各个风险因素对疾病患病的影响程度,进而预测某个个体患病的概率。
2. 社会科学领域在社会科学研究中,研究者常常使用Logistic回归来探索特定变量对于某种行为、态度或事件发生的影响程度。
例如,研究者可能想要了解不同性别、教育程度、收入水平对于选民投票行为的影响。
通过Logistic回归分析,可以对不同自变量对于投票行为的作用进行量化,进而预测某个选民投票候选人的概率。
3. 市场营销领域在市场营销中,Logistic回归也被广泛应用于客户分类、市场细分以及产品销量预测等方面。
通过分析客户的个人特征、购买习惯和消费行为等因素,可以建立Logistic回归模型,预测不同客户购买某一产品的概率,以便制定个性化的市场营销策略。

因变量是定性变量的回归分析—L o g i s t i c回归分析内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)因变量是定性变量的回归分析—Logistic回归分析一、从多元线性回归到Logistic 回归例这是200个不同年龄和性别的人对某项服务产品的认可的数据(logi.sav).其中:年龄是连续变量,性别是有男和女(分别用1和0表示)两个水平的定性变量,而变量“观点”则为包含认可(用1表示)和不认可(用0表示)两个水平的定性变量。
从这张图可以看出什么呢从这张图又可以看出什么呢这里观点是因变量, 只有两个值;所以可以把它看作成功概率为p的Bernoulli试验的结果.但是和单纯的Bernoulli试验不同,这里的概率p为年龄和性别的函数. 必须应用Logistic回归。
二、多元线性回归不能应用于定性因变量的原因首先,多元线性回归中使用定性因变量严重违反本身假设条件,即:因变量只能取两个值时,对于任何给定的自变量值,e本身也只能取两个值。
这必然会违背线性回归中关于误差项e的假设条件。
其次,线性概率概型及其问题:由于因变量只有两个值;所以可以把它看作成功概率p,取值范围必然限制在0—1的区间中,然而线性回归方程不能做到。
另外概率发生的情况也不是线性的。
三、 Logistic 函数Logistic 的概率函数定义为:我们将多元线性组合表示为:于是,Logistic 概率函数表示为:经过变形,可得到线性函数:这里, 事件发生概率=P (y=1)事件不发生概率=1-P (y=0) 发生比:Ω=-=pp odds 1)( 对数发生比:)(log )1(ln )log(p it p p odds =⎥⎦⎤⎢⎣⎡-= 这样,就可将logistic 曲线线性化为:从P 到logit P 经历了两个步骤变换过程:第一步:将p 转换成发生比,其值域为0到无穷第二步:将发生比换成对数发生比,其值域科为[]∞+∞-经过转换, 将P →logit P,在将其作为回归因变量来解释就不再有任何值域方面的限制了,即可线性化!四、 Logistic 回归系数的意义以logit P 方程的线性表达式来解释回归系数,即:在logistic 回归的实际研究中,通常不是报告自变量对P 的作用,而是报告自变量对logit P 的作用。

搞懂Logistic回归之前,你得需要先把这个问题搞清楚!⼀个⼈需要隐藏多少秘密才能巧妙地度过⼀⽣。
有⽼师咨询有关Logisitic的知识,其实我们之前也做过相关的资讯,⼤家可以先去看看之前的资讯。
随便说⼀说:logistic回归分析Logistic回归有啥⽤?因变量是定性变量的回归分析—Logistic回归分析案例分析 | 有序多分类logistic回归及SPSS操作SPSS教程 | ⼆分类logistic回归及SPSS操作我们都知道,医学研究中常碰到因变量(y)的可能取值仅有两个(即⼆分类变量),如发病与未发病、阳性与阴性、死亡与⽣存、治愈与未治愈、暴露与未暴露等,显然这类资料不满⾜多重回归的条件。
其实,Logistic回归的⽬的是:作出以多个⾃变量(危险因素)估计因变量(结果因素)的logistic回归⽅程。
(属于概率型⾮线性回归)对所要分析资料的条件:①因变量为反映某现象发⽣与不发⽣的⼆值变量;②⾃变量宜全部或⼤部分为分类变量,可有少数数值变量。
分类变量要数量化。
logistic回归的⽤途:研究某种疾病或现象发⽣和多个危险因素(或保护因⼦)的数量关系。
(⽤检验(或u检验)的局限性:只能研究1个危险因素)logistic回归的种类:①成组(⾮条件)logistic回归⽅程。
②配对(条件)logistic回归⽅程。
以上是有关 logistic回归的基本介绍,在正式采⽤案例讲解 logistic回归之前,我们需要先回顾⼀下队列研究和病例对照研究的基本原理。
队列研究队列研究(cohort study):对“因”分类上的⼈群作追踪随访,观察其“果”,然后对资料进⾏⽐较分析,从⽽判断“因”与“果”之间有⽆关联及关联的强度。
(见下图)病例对照研究(case-control study):是对“果”分类上的⼈群作回顾性调查,观察其“因”,然后对资料进⾏⽐较分析,从⽽判断“果”与“因”间关联有⽆统计学意义及关联的强度。
第十章 logitic 回归本章导读:Logitic 回归模型是离散选择模型之一,属于多重变数分析范畴,是社会学、生物统计学、临床、数量心理学、市场营销、会计与财务等实证分析的常用方法。
10.1 logit 模型和原理Logistic 回归分析是对因变量为定性变量的回归分析。
它是一种非线性模型。
其基本特点是:因变量必须是二分类变量,若令因变量为y ,则常用y=1表示“yes ”,y=0表示“no ”。
[在发放股利与不发放股利的研究中,分别表示发放和不发放股利的公司]。
自变量可以为虚拟变量也可以为连续变量。
从模型的角度出发,不妨把事件发生的情况定义为y=1,事件未发生的情况定义为0,这样取值为0、1的因变量可以写作:⎩⎨⎧===事情未发生事情发生01y 我们可以采用多种方法对取值为0、1的因变量进行分析。
通常以P 表示事件发生的概率(事件未发生的概率为1-P ),并把P 看作自变量x 的线性函数。
由于y 是0-1型Bernoulli 分布,因此有如下分布:P=P (y=1|x ):自变量为x 时y=1的概率,即发放现金股利公司的概率1-P=P (y=0|x ):自变量为x 时y=0的概率,即不发放现金股利公司的概率 事件发生和不发生的概率比成为发生比,即相对风险,表现为PP odds -=1.因为是以 对数形式出现的,故该发生比为对数发生比(log odds ),表现为)1ln(P P odds -=。
对数发生比也是事件发生概率P 的一个特定函数,通过logistic 转换,该函数可以写成logistic 回归的logit 模型:)1(log )(log PP P it e -= Logit 一方面表达出它是事件发生概率P 的转换单位;另一方面,它作为回归的因变量就可以自己与自变量之间的依存关系保持传统回归模式。
根据离散型随即变量期望值的定义,可得:E(y)=1(P)+0(1-P)=P进而得到x P y E 10)(ββ+==因此,从以上分析可以看出,当因变量的取值为0、1时,均值x y E 10)(ββ+=总是代表给定自变量时y=1的概率。
Logistic 回归分析Logistic 回归分析是与线性回归分析方法非常相似的一种多元统计方法。
适用于因变量的取值仅有两个(即二分类变量,一般用1和0表示)的情况,如发病与未发病、阳性与阴性、死亡与生存、治愈与未治愈、暴露与未暴露等,对于这类数据如果采用线性回归方法则效果很不理想,此时用Logistic 回归分析则可以很好的解决问题。
一、Logistic 回归模型设Y 是一个二分类变量,取值只可能为1和0,另外有影响Y 取值的n 个自变量12,,...,n X X X ,记12(1|,,...,)n P P Y X X X ==表示在n 个自变量的作用下Y 取值为1的概率,则Logistic 回归模型为:[]0112211exp (...)n n P X X X ββββ=+-++++它可以化成如下的线性形式:01122ln ...1n n P X X X P ββββ⎛⎫=++++ ⎪-⎝⎭通常用最大似然估计法估计模型中的参数。
二、Logistic 回归模型的检验与变量筛选根据R Square 的值评价模型的拟合效果。
变量筛选的原理与普通的回归分析方法是一样的,不再重复。
三、Logistic 回归的应用(1)可以进行危险因素分析计算结果各关于各变量系数的Wald 统计量和Sig 水平就直接反映了因素i X 对因变量Y 的危险性或重要性的大小。
(2)预测与判别Logistic回归是一个概率模型,可以利用它预测某事件发生的概率。
当然也可以进行判别分析,而且可以给出概率,并且对数据的要求不是很高。
四、SPSS操作方法1.选择菜单2.概率预测值和分类预测结果作为变量保存其它使用默认选项即可。
例:试对临床422名病人的资料进行分析,研究急性肾衰竭患者死亡的危险因素和统计规律。
Logistic回归分析.sav解:在SPSS中采用Logistic回归全变量方式分析得到:(1)模型的拟合优度为0.755。
logit定序回归模型
Logit定序回归模型是一种用于分析有序分类因变量的统计模型。
在这种模型中,因变量被分为有序的类别,例如低、中、高。
Logit定序回归模型基于Logistic函数,它可以用来估计因变量落
入每个类别的概率。
这种模型的核心假设是因变量的类别之间存在
顺序关系,并且不同类别之间的距离是相等的。
在Logit定序回归模型中,自变量的系数被用来解释因变量类
别的变化。
这些系数可以告诉我们自变量的变化如何影响向更高类
别转变的概率。
通过估计这些系数,我们可以了解自变量对于因变
量的影响程度。
在实际应用中,Logit定序回归模型常常用于分析教育水平、
收入水平等有序分类变量的影响因素。
这种模型可以帮助研究者了
解不同自变量对于因变量类别的影响,从而进行政策制定或者其他
决策的支持。
需要注意的是,使用Logit定序回归模型时需要满足一些假设,比如因变量的类别之间应该是有序的,自变量与因变量之间应该是
线性关系等。
同时,在解释结果时,应该注意避免因果解释,因为
回归分析本身不能证明因果关系。
因此,在使用Logit定序回归模型时,需要仔细考虑模型的假设和结果的解释。
因变量是定性变量的回归分析一Logistic回归分析
一、从多元线性回归到Logistic回归
例这是200个不同年龄和性别的人对某项服务产品的认可的数据(logi.sav).
其中:年龄是连续变量,性别是有男和女(分别用1和0表示)两个水平的定性变量,而变量“观点”则为包含认可(用1表示)和不认可(用0表示)两个水平的定性变量。
从这张图可以看出什么呢?
从这张图又可以看出什么呢?
这里观点是因变量,只有两个值;所以可以把它看作成功概率为p的Bernoulli试验的结果. 但是和单纯的Bernoulli试验不同,这里的概率p为年龄和性别的函数.
必须应用Logistic回归。
二、多元线性回归不能应用于定性因变量的原因
首先,多元线性回归中使用定性因变量严重违反本身假设条件,即:
因变量只能取两个值时,对于任何给定的自变量值,e本身也只能取两个值。
这必然会违
背线性回归中关于误差项e的假设条件。
其次,线性概率概型及其问题:
由于因变量只有两个值;所以可以把它看作成功概率p,取值范围必然限制在0—1的区间
中,然而线性回归方程不能做到。
另外概率发生的情况也不是线性的。
三、Logistic函数
Logistic的概率函数定义为:
我们将多元线性组合表示为:
于是,Logistic概率函数表示为:
经过变形,可得到线性函数:
这里,事件发生概率=P (y=1)
事件不发生概率=1-P (y=0)
发生比:(odds)—-门
1 -P
对数发生
比:log(odds)刑1_p)「ogit(p)
这样,就可将logistic曲线线性化为:
从P到logit P经历了两个步骤变换过程:
第一步:将p转换成发生比,其值域为0到无穷
第二步:将发生比换成对数发生比,其值域科为1- ::•二I 经过转换,将P^logit P,在将其作为回归因变量来解释就不再有任何值域方面的限制
了,即可线性化!
四、Logistic回归系数的意义
以logit P方程的线性表达式来解释回归系数,即:
在logistic回归的实际研究中,通常不是报告自变量对P的作用,而是报告自变量对logit P
的作用。
以发生比Q的指数表达式来解释回归系数
与logit P不同,发生比Q具有一定的实际意义,代表一种相对风险。
因此对logistic回归系数的解释通常是从发生比的指数表达式出发的。
例如:在取得了logistic回归系数的各bi的解以后,将其带入Q函数,
如果分析x变化一个单位对于Q的影响幅度,可以用(x +1)表示,并将其代入上式,得到新的发生比
将两个发生比集中在一起有:
将此称为发生比率,它可测量自变量一个单位的增加给原来的发生比所带来的变化,
一般表达式为:0 /0=exo(b)
说明在其他情况不变的情况下,x 一个单位的变化使原来的发生比扩大 exp(bJ倍。
比如,原来的Q为6:4(比值为1.5),如果一个自变量变化一个单位导致的发生比率为exp (0.693)=2,即表示这一变化将会导致新发生比值Q *为原来的2倍,即新发生比将是12:4(比值为3)。
我们也可用发生比率减1的差来表示发生比的增长率,如发生比率为2.3,就可以说自变量一个单位的变化会使原发生比增加 1.3倍(2.3-仁1.3).
当logistic回归系数为负数时,发生比率小于1。
这时的表达要特别小心。
比如发生比率为0.8时,表示新发生比只有原来的80%,那么下降的倍数则是(1-0.8=)02
五、Logistic回归应用
以上例为例,说明logistic回归分析
SPSS 选项:An alyze —Regressi on—Bi nary logistic
Logistic回归的SPSS输出结果
六、Logistic模型的检验与评价
1.对于整体模型的检验
Logistic回归方程求解参数是采用最大似然估计方法,因此其回归方程的整体检验通过似然函数值,表示为:
-2 Log Likelihood
该值越大,意味着回归方程的似然值越小,模型的拟和程度越差。
反之,拟和程度越好。
在评价或检验一个含有自变量的Logistic回归模型时,通常是将其含有自变量的Logistic 的-2 Log Likelihood与截距模型的相比较。
两者之差服从卡方分布,进行卡方检验。
所谓截距模型,就是将所有自变量删除后只剩一个截距系数的模型。
2.对于回归系数的检验
Logistic回归系数的检验是用Wald统计量进行的七、L ogistic 回归的标准化回归系数
SPSS进行Logistic回归时不提供标准化回归系数,但是其手工计算公式很简单: Age和Sex的标准
化回归系数分别约为:
八、L ogistic 回归的偏回归系数通过比较两个自变量的标准化回归系数,我们发现对于是否同意该观点来说,年龄的负作用要比性别的负作用要大一些。