相关系数,回归模型,自组织竞争神经网络
- 格式:doc
- 大小:389.00 KB
- 文档页数:18


神经网络的模型和算法人工智能领域中最流行的技术之一是神经网络。
神经网络是模拟神经系统对信息进行处理的一种模型。
它由多个相互连接的单元组成,形成图形结构,类似于人类神经系统。
神经网络经常被用于图像识别、语音识别和自然语言处理等应用领域。
本文将讨论神经网络的模型和算法。
神经网络的模型神经网络可以描述为由多个神经元单元组成的图形结构。
图形结构是由神经元单元之间的连接和对输入的响应特征定义的。
神经元单元可以被描述为一组输入和输出之间的特定函数。
神经网络的模型分为前向神经网络和反向神经网络。
前向神经网络根据输入数据的特征通过多个隐藏层传递信息,最终得到一个输出值。
反向神经网络则是通过输入和输出之间的关系来学习网络的参数。
反向传播算法被广泛地应用于训练多层前馈神经网络。
神经网络的算法神经网络的算法与其模型密切相关,下面将介绍几种常用的神经网络算法。
BP算法BP算法是一种反向传播算法,通过反向传播误差更新神经网络的权重和阈值,使得网络输出与期望输出之间的误差最小化。
BP算法分别计算输出层和隐含层的误差,然后反向传播误差,更新网络的权重和阈值。
Hopfield网络算法Hopfield网络算法是一种无监督学习模型,采用回馈结构,可以存储和检索模式。
Hopfield网络将重要的信息编码为状态向量,并选择一些不合法的状态,以期获得一些不同的结果。
Hopfield网络具有较好的容错性和大规模模式的处理能力。
自组织映射算法Kohonen SOM算法是一种无监督学习算法,可以进行数据降维和聚类分析。
该算法是基于映射的,将高维输入数据映射到低维输出层。
自组织映射算法将数据点映射到CRT图中的点,以发现数据库中存在的潜在结构。
总结神经网络作为人工智能工具之一,正在被应用于许多领域。
神经网络的模型和算法是其成功实现的关键。
本文介绍了几种常用的神经网络模型和算法,希望对读者理解神经网络提供一定的帮助。


十大数据分析模型详解数据分析模型是指用于处理和分析数据的一种工具或方法。
下面将详细介绍十大数据分析模型:1.线性回归模型:线性回归模型是一种用于预测数值型数据的常见模型。
它基于变量之间的线性关系建立模型,然后通过拟合这个模型来进行预测。
2.逻辑回归模型:逻辑回归模型与线性回归模型类似,但应用于分类问题。
它通过将线性模型映射到一个S形曲线来进行分类预测。
3.决策树模型:决策树模型是一种基于树结构的分类与回归方法。
它将数据集划分为一系列的决策节点,每个节点代表一个特征变量,根据特征变量的取值选择下一个节点。
4.随机森林模型:随机森林模型是一种集成学习的方法,通过建立多个决策树模型来进行分类与回归分析。
它通过特征的随机选择和取样来增加模型的多样性和准确性。
5.支持向量机模型:支持向量机模型是一种用于分类和回归分析的模型。
其核心思想是通过找到一个最优的分割超平面,使不同类别的数据点之间的间隔最大化。
6.主成分分析:主成分分析是一种常用的数据降维方法,用于减少特征维度和提取最重要的信息。
它通过找到一组新的变量,称为主成分,这些主成分是原始数据中变量的线性组合。
7.聚类分析:聚类分析是一种无监督学习方法,用于对数据进行分类和分组。
它通过度量样本之间的相似性,将相似的样本归到同一类别或簇中。
8.关联规则挖掘:关联规则挖掘是一种挖掘数据集中的频繁项集和关联规则的方法。
它用于发现数据集中的频繁项集,并根据频繁项集生成关联规则。
9.神经网络模型:神经网络模型是一种模拟人脑神经网络结构和功能的机器学习模型。
它通过建立多层的神经元网络来进行预测和分类。
10.贝叶斯网络模型:贝叶斯网络模型是一种基于概率模型的图论模型,用于表示变量之间的条件依赖关系。
它通过计算变量之间的概率关系来进行推理和预测。
以上是十大数据分析模型的详细介绍。
这些模型在实际应用中具有不同的优势和适用范围,可以根据具体的问题和数据情况选择合适的模型进行分析和预测。


竞争型神经网络是基于无监督学习的神经网络的一种重要类型,作为基本的网络形式,构成了其他一些具有组织能力的网络,如学习向量量化网络、自组织映射网络、自适应共振理论网络等。
与其它类型的神经网络和学习规则相比,竞争型神经网络具有结构简单、学习算法简便、运算速度快等特点。
竞争型神经网络模拟生物神经网络系统依靠神经元之间的兴奋、协调与抑制、竞争的方式进行信息处理。
一个竞争神经网络可以解释为:在这个神经网络中,当一个神经元兴奋后,会通过它的分支对其他神经元产生抑制,从而使神经元之间出现竞争。
当多个神经元受到抑制,兴奋最强的神经细胞“战胜”了其它神经元的抑制作用脱颖而出,成为竞争的胜利者,这时兴奋最强的神经元的净输入被设定为 1,所有其他的神经元的净输入被设定为 0,也就是所谓的“成者为王,败者为寇”。
一般说来,竞争神经网络包含两类状态变量:短期记忆变元(STM)和长期记忆变元(LTM)。
STM 描述了快速变化的神经元动力学行为,而 LTM 描述了无监督的神经细胞突触的缓慢行为。
因为人类的记忆有长期记忆(LTM)和短期记忆(STM)之分,因此包含长时和短时记忆的竞争神经网络在理论研究和工程应用中受到广泛关注。
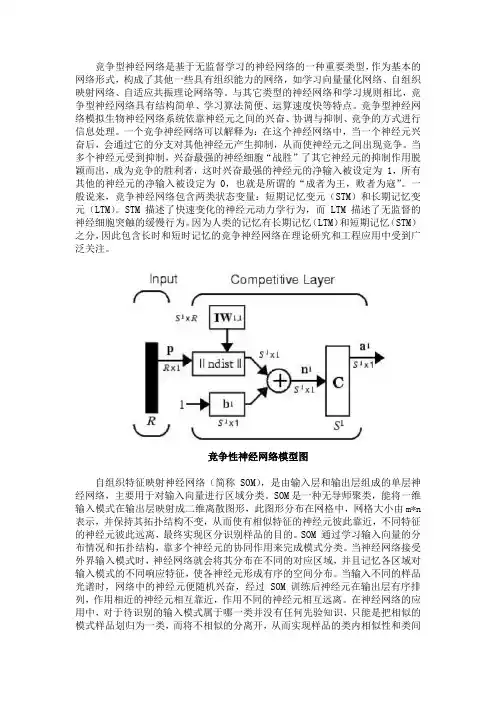
竞争性神经网络模型图自组织特征映射神经网络(简称SOM),是由输入层和输出层组成的单层神经网络,主要用于对输入向量进行区域分类。
SOM是一种无导师聚类,能将一维输入模式在输出层映射成二维离散图形,此图形分布在网格中,网格大小由m*n 表示,并保持其拓扑结构不变,从而使有相似特征的神经元彼此靠近,不同特征的神经元彼此远离,最终实现区分识别样品的目的。
SOM 通过学习输入向量的分布情况和拓扑结构,靠多个神经元的协同作用来完成模式分类。
当神经网络接受外界输入模式时,神经网络就会将其分布在不同的对应区域,并且记忆各区域对输入模式的不同响应特征,使各神经元形成有序的空间分布。
当输入不同的样品光谱时,网络中的神经元便随机兴奋,经过SOM 训练后神经元在输出层有序排列,作用相近的神经元相互靠近,作用不同的神经元相互远离。

⼤数据的常⽤算法(分类、回归分析、聚类、关联规则、神经⽹络⽅法、web数据挖掘)在⼤数据时代,数据挖掘是最关键的⼯作。
⼤数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的⼤型数据库中发现隐含在其中有价值的、潜在有⽤的信息和知识的过程,也是⼀种决策⽀持过程。
其主要基于,,模式学习,统计学等。
通过对⼤数据⾼度⾃动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、⽤户调整市场政策、减少风险、理性⾯对市场,并做出正确的决策。
⽬前,在很多领域尤其是在商业领域如、电信、电商等,数据挖掘可以解决很多问题,包括市场营销策略制定、背景分析、危机等。
⼤数据的挖掘常⽤的⽅法有分类、回归分析、聚类、关联规则、⽅法、Web 数据挖掘等。
这些⽅法从不同的⾓度对数据进⾏挖掘。
数据准备的重要性:没有⾼质量的挖掘结果,数据准备⼯作占⽤的时间往往在60%以上。
(1)分类分类是找出数据库中的⼀组数据对象的共同特点并按照分类模式将其划分为不同的类,其⽬的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。
可以应⽤到涉及到应⽤分类、趋势预测中,如淘宝商铺将⽤户在⼀段时间内的购买情况划分成不同的类,根据情况向⽤户推荐关联类的商品,从⽽增加商铺的销售量。
分类的⽅法:决策树——是最流⾏的分类⽅法特点:a、它的每次划分都是基于最显著的特征的;b、所分析的数据样本被称作树根,算法从所有特征中选出⼀个最重要的,⽤这个特征把样本分割成若⼲⼦集;c、重复这个过程,直到所有的分⽀下⾯的实例都是“纯”的,即⼦集中各个实例都属于同⼀个类别,这样的分⽀即可确定为⼀个叶⼦节点。
在所有⼦集变成“纯”的之后,树就停⽌⽣长了。
决策树的剪枝:a、如果决策树建的过深,容易导致过度拟合问题(即所有的分类结果数量基本⼀样,没有代表性);b、剪枝通常采⽤⾃上⽽下的⽅式。
每次找出训练数据中对预测精度贡献最⼩的那个分⽀,剪掉它;c、简⾔之,先让决策树疯狂⽣长,然后再慢慢往回收缩。

竞争性神经网络的原理及应用竞争性神经网络是一类典型的无监督学习算法,它在人类的神经系统中有着广泛的应用。
竞争性神经网络作为一种较新的技术,其目标在于模拟人类神经系统的行为,实现自主学习和不断变化的能力。
本文将介绍竞争性神经网络的原理及其应用。
一、竞争性神经网络的原理竞争性神经网络是通过模拟人类神经系统的行为来进行学习的。
它的基本原理是,将一组数据输入系统中,每个神经元之间相互竞争,最终经过竞争得出“优胜者”。
竞争性神经网络中最常用的模型是Kohonen自组织映射网络。
在Kohonen自组织映射网络中,每个神经元都与一个向量相关联,称为权重向量。
每次输入向量并给出一个胜出神经元,胜出神经元的权重向量通过调整来接近输入向量,而其他神经元的权重向量则保持不变。
Kohonen自组织映射网络的工作过程如下:(1)初始化每个神经元的权重向量;(2)给定输入向量;(3)计算每个神经元与输入向量的距离;(4)选择距离最近的神经元作为胜出神经元;(5)调整胜出神经元及其周围神经元的权重向量。
上述过程重复多次,神经元的位置会不断调整,最终形成一个由许多神经元构成的二维网格。
这个过程中,神经元的权重向量会不断调整,使得相似的输入向量聚集在相邻的神经元上。
二、竞争性神经网络的应用竞争性神经网络的应用十分广泛,在模式分类、数据挖掘、机器人控制、图像处理等领域中都有着重要的应用。
1. 模式分类竞争性神经网络可以通过自组织学习的方式进行模式分类。
在输入向量空间中聚集在一起的向量归为同一类别,从而对其它向量进行分类。
例如,通过对由红色和蓝色像素组成的图像进行训练,可以将红色像素和蓝色像素分别归类,并将其它颜色的像素归类到与其最接近的类别中。
2. 数据挖掘竞争性神经网络可以在数据挖掘领域中用来确定数据的特征。
这种网络可以在输入向量空间中分离出各种特征,并将其归为不同的类别。
例如,在一个由客户购买历史、性别、年龄等组成的数据集中使用竞争性神经网络,将各种特征分离出来,并将客户划分为不同的类别。

神经网络数学模型神经网络数学模型是机器学习基础中最重要和最有用的部分。
它是一种用来模拟大脑和神经系统复杂行为的数学模型。
这种模型可以帮助我们理解神经网络的运作和功能,以及它们如何应用于现实世界中复杂的任务。
这些模型包括呈指数下降的逻辑回归,梯度下降的广义线性模型,并行自适应的反向传播神经网络,强化学习等等。
神经网络模型被用来模拟人类大脑的功能,使机器能够完成任务,如识别图像和语音,或从实时数据流中提取有用信息。
神经网络由多个层组成,每一层由多个神经元连接而成。
神经元通过权重来连接到前一层,以及下一层。
每个神经元通过算术运算(如累加和非线性激活函数)将输入转换为输出。
可以通过调整神经网络模型中各层之间的参数来更新这些模型,以更好地拟合数据。
神经网络模型的应用可以追溯到1940年代,当时科学家们开始使用它们来模拟神经元之间的连接。
随着计算机科学的发展,研究人员不断改进这些模型,以更好地模拟神经网络。
随着人工智能技术的兴起,神经网络模型现在成为机器学习中最重要的一部分。
神经网络模型的最新发展之一,是深度学习模型。
这些模型在数据量很大的情况下,可以获得更好的训练性能,比如图像分类任务。
深度学习模型包括卷积神经网络、循环神经网络和强化学习等。
深度学习研究人员还开发出了各种新颖的结构和算法,例如注意力机制、受限玻尔兹曼机以及特征学习等等。
神经网络数学模型对于机器学习研究来说是非常重要的,它们可以帮助我们更好地理解机器学习中的各种复杂的情况,并且可以应用于实际的领域。
它们的用途可以很大程度上拓展了机器学习的可能性,并将帮助人类更好地把握未来的机会和挑战。
回归分析与神经网络方法的比较研究数据分析领域中,回归分析和神经网络方法都是常用的预测和建模工具。
虽然它们在实际应用中都有各自的优势和局限性,但对于不同问题的解决和数据的处理,它们的比较还是有一定的意义。
回归分析是一种传统的统计方法,主要用于建立变量之间的函数关系。
它的基本思想是依靠线性或非线性的回归方程来表达自变量与因变量之间的关系,并通过参数估计来确定回归方程的具体形式。
回归分析的优点在于其简单易懂、参数估计可解释性强,适用于大部分数据场景,特别是小样本情况下。
然而,回归分析也存在一些局限性。
首先,它对于非线性关系的建模能力相对较弱。
在数据包含复杂关系的情况下,回归分析可能无法准确描述变量之间的实际影响机制。
其次,回归分析对异常值敏感,当数据中存在异常点时,回归模型的效果会受到明显的影响。
此外,回归分析假设了变量之间的线性或非线性关系是确定性的,而在现实场景中,很多因素可能是随机的,这导致回归分析对其建模存在一定的限制。
与回归分析相比,神经网络方法则以其强大的非线性建模能力而著称。
神经网络模型由大量的人工神经元组成,可以通过调整连接权重和偏置项来学习和逼近复杂的非线性关系。
神经网络的优势在于其灵活性和容错性,可以处理大量的、高维度的数据,并且对于异常值和不完整数据也具有一定的鲁棒性。
然而,神经网络方法也存在一些问题。
首先,神经网络模型需要大量的数据来调整网络参数,因此在数据较为稀缺的情况下,其表现可能不如回归分析。
其次,神经网络的黑箱特性使得模型的结果可解释性较差,很难通过参数来判断各个输入变量之间的重要性。
此外,神经网络模型的训练过程相对复杂,需要较长的训练时间和计算资源。
对于回归分析和神经网络方法的比较,根据具体的数据特征和问题需求来选择合适的方法。
如果数据关系较为简单,变量间的影响较为明显,且需要清晰的参数估计和解释能力,回归分析是一个较好的选择。
而当数据关系复杂,变量间存在非线性且随机的关联,或者需要高维度数据的建模时,神经网络方法能够更好地适应和处理。
高等教育学费标准的研究摘要本文从搜集有关普通高等学校学费数据开始,从学生个人支付能力和学校办学利益获得能力两个主要方面出发,分别通过对这两个方面的深入研究从而制定出各自有关高等教育学费的标准,最后再综合考虑这两个主要因素,进一步深入并细化,从而求得最优解。
模块Ⅰ中,我们将焦点锁定在从学生个人支付能力角度制定合理的学费标准。
我们从选取的数据和相关资料出发,发现1996年《高等学校收费管理暂行办法》规定高等学校学费占生均教育培养的成本比例最高不得超过25%,而由数据得到图形可知,从2002年开始学费占教育经费的比例超过了25%,并且生均学费和人均GDP 的比例要远远超过美国的10%到15%。
由此可见,我国的学费的收取过高。
紧接着,我们从个人支付能力角度出发,研究GDP 和学费的关系。
并因此制定了修正参数,由此来获取生均学费的修正指标。
随后,我们分析了高校专业的相关系数,从个人支付能力角度,探讨高校收费与专业的关系,进一步得到了高校收费标准1i i y G R Q =Q R G y ig g i =1 在模块Ⅱ中,我们从学校办学利益获得能力出发,利用回归分析对学生应交的学杂费与教育经费总计、国家预算内教育经费、社会团体和公民个人办学经验、社会捐投资和其他费用的关系,发现学杂费与教育经费总计成正相关,与其他几项费用成负相关。
对此产生的数据验证分析符合标准。
然后,再根据专业相关系数来确定学校收取学费的标准。
从而,得到了学校办学利益的收费标准2i i i y y R = 。
在模块Ⅲ中,为了获取最优解,我们综合了前面两个模块所制定的收费指标,并分别给予不同权系数,得到最终学费的表达式12i i C ay by =+。
然后,我们从学校收费指标的权系数b 考虑,利用神经网络得到的区域划分,根据不同区域而计算出的权系数b 的范围。
最终得到的表达式]12345**(1)(1.0502 1.1959 1.3108 1.36360.7929)**b i i C R G Q b x x x x x R =-+----;由此便可得到综合学费标准C 的取值范围。
然后,我们随机选取了同一区域不同专业,并根据表达式计算这些专业的学费,结果发现对社会收益大,个人收益小的专业如地质学的学费范围为:3469.8~3506.3元之间;对社会收益小,个人收益大的专业如广告设计的学费范围为:7931.0~8014.5元之间。
与通常高校实现的一刀切政策有了明显的优点。
最后,我们从本论文研究方向考虑,为优化高校费用标准的制定提出参考意见,如建立反馈制度和特殊生补贴制度的建议。
【关键字】相关系数 回归模型 自组织竞争神经网络一、问题提出高等教育事关高素质人才培养、国家创新能力增强、和谐社会建设的大局,因此受到党和政府及社会各方面的高度重视和广泛关注。
高等教育的一个核心指标是培养质量,不同的学科、专业在设定不同的培养目标后,都需要有相应的经费来保证其质量。
高等教育属于非义务教育,在世界各地其经费都是由政府财政拨款、学校自筹、社会捐赠和学费收入等几部份组成的。
世纪之交和“十五”期间,对我国高等教育制度进行改革与发展,我国高等教育面临着大有作为的重要战略机遇期,也面临着新的挑战。
随着改革的进行,学费问题也面临着严重的矛盾。
学费问题涉及每一个大学生及其家庭,是一个敏感而又复杂的问题:由于中国的经济限制,中国的人均收入并不是太高,特别是一些偏远山区和西北部地区,若学费过高会是许多学生因为无力支付学费而辍学;若学费太低,会导致学校的财力不足以致无法保障教学质量。
因此,学费问题在近年来的各种媒体上都引起了热烈的讨论。
从中国的国情出发,收集诸如近几年来关于我国教育经费方面的及家庭收入等数据[1-4],并通过分析数据建立数学模型,就几类学校或专业的费用标准进行定量分析,并从中得出明确、有说服力的结论。
二、问题分析(一)我国教育收费的现状通过国家统计局相关资料检索得到2000年到2005年我国普通高等学校教育经费统计[5]如表2. 1所示:表2. 1 表2. 1 表2. 1 表2. 1 表2. 1 表2. 1 表2. 1表2. 1 2002~2005年我国普通高校教育经费情况(单位:万元)年份2000 2001 2002 2003 2004 2005 项目合计9133504 11665762 14878590 17543468 21297613 25502371国家财政性教育经5311854 6328004 7521463 8405779 9697909 10908369 费预算内教育经费5044173 6060683 7243459 8074148 9309882 10463734社会团体和公民个65941 181993 331363 603015 1121982 1801315 人办学经费社会捐资和集资办151828 172775 278253 256375 215440 210796 学经费学费和杂费1926109 2824417 3906526 5057307 6476921 7919249 其他教育经费1677772 2158574 2840985 3220992 3785362 4662641学费占教育经费的0.21 0.24 0.26 0.29 0.30 0.31比例以表2. 1所示数据中的年份为横坐标,学费占教育经费的比例为纵坐标,利用MATLAB作图得到图2. 1 各年度学费占教育经费的比例的情况图2. 1 各年度学费占教育经费的比例的情况1996年12月16日颁布的《高等学校收费管理暂行办法》规定在现阶段,高等学校学费占年生均教育培养成本的比例最高不得超过25%。
[6]鉴于用于计算生均培养成本的相关数据的搜集工作难度系数较大,我们借用全国高校总的学费收入和总的教育经费的比值来表示高校学费占年生均教育培养成本的比例。
正如图2. 1 各年度学费占教育经费的比例的情况(二)影响我国普通高校学费标准制定的因素我们若想要具体确定学费标准,首先必须要搞清楚到底有哪些因素会影响学费标准的制定。
影响高等教育学费的因素是很多的,包括政治因素、历史文化传统因素、思想观念因素、国际因素、经济因素等。
前四种因素主观性都比较强,很难量化,因此本文暂不多加考虑。
经济方面的影响因素当然也包括很多,不过本文中主要涉及四种,即各方面的承受能力、高等教育个人收益率、生均培养成本以及地区差异。
(三)我国普通高校学费标准制定的原则至于学费标准制定的原则,研究者已有不少,如王善迈认为教育投资负担的基本依据是收益原则和能力原则,学费制定则应坚持教育成本的一部分原则和多数居民可以承受原则,其实这二者是一致的,如多数居民可以承受原则也就是能力原则。
全国政协常委辜胜阻对此谈得比较全面。
他认为,合理的成本分担机制建设应坚持一下八条原则:第一,成本合理分担原则;第二、承受能力原则;第三,收费标准差别性原则;第四,办学投入多元化原则;第五,办学主体多元化原则;第六,高等学校成本核算管理原则;第七,政府投入到为原则;第八,保障教育公平性原则。
也有很多学者有一些其他的观点,不过绝大多数学者还是认为要以能力支付原则和利益获得这两个最基本的原则来制定学费。
接下来我们就是要根据这两个基本原则来制定我国普通高校学费标准。
所谓能力支付原则,是根据利益获得者的付款能力来确定负担主体及负担程度。
教育成本支出最终来源于国民收入,国民收入通过初次分配和再分配被各社会群体所占有。
从理论上说,谁占有国民收入,谁就应当担负教育成本。
但是由于国民收入在分配上存在着不均等的现象,各群体的付款能力不同,教育成本的负担应该根据付款能力不同确定负担的程度与比例。
所谓利益获得原则,简言之,谁受益谁负担,获益多者多负担。
用于教育的成本支出就其性质而言是一种可获得预期收益的投资。
由于教育具有经济功能,用于教育的成本是可以获得预期的经济和非经济收益的一种投资。
由于教育的公共物品或准公共物品的特性,教育投资可以产生外部效益,不仅受教育者可以获益,全社会都可以从中获益。
因而社会各成员应根据其所获得的利益,分摊教育成本的负担。
三、 模型假设1、 假设收集的数据均真实有效。
2、 假设不考虑第三批本科国家不给予补助;3、 因为《中国统计年鉴》公布有关高等教育数据的滞后性,我们假设选取2005年的数据对本论文不构成影响。
四、 定义与符号说明G —— 人均GDPQ —— 人均GDP 的权重系数i R —— 各专业的权重系数i y —— 各专业学费的收费标准1x —— 国家财政性教育经费2x —— 预算内教育经费3x —— 社会团体和公民个人办学经费4x —— 社会捐款和集资办学经费5x —— 其他教育经费i b —— i x 相对应的系数C —— 学费制定标准1i y —— 学生期望的各专业学费标准y——学校期望的各专业学费标准2ia——y的权重系数1iy的权重系数b——2i五、模型的建立与求解(一)基于学生个人支付能力能力制定的学费标准——模块Ⅰ1、模型的分析首先,就学生家庭的经济承受能力这个角度来看,基于能力支付和利益获得这两个基本原则,我们从影响普通高校学费能力的众多因素中选取全国人均GDP和学生就读的专业这两个基本因素进行研究,通过建立相关模型确定这两个因素的权重系数,2、模型的准备根据查询国家统计局显示的数据资料[7],我们搜集到从1995年到2004年间我国普通高校生均学费和人均GDP的值如错误!未找到引用源。
表2. 1 表5. 1(1)人均GDP的权重系数Q我们根据国内和国外的高校学费占人均GDP的比例各自所占的权重系数,求出我国高校学费占人均GDP的一般比例,从而根据我国的人均GDP算出我国所有普通高校专业的平均学费。
根据错误!未找到引用源。
所列的数据,以各个年份为横坐标,普通高校生均学费和人均GDP的比值为纵坐标作图如图2. 1各年度学费占教育经费的比例的情况错误!未找到引用源。
图5. 1 各年度高校生均学费与人均GDP比值的变化情况很显然,由表2. 1可以看出,我国普通高校生均学费与人均GDP的比值总体上呈不断上升的趋势,1995年~1998年增长幅度较小(范围在0.20~0.30之内),1998年以后出现猛烈增长,两年之内从0.28突增至0.50,之后两年基本稳定,2002到2004年内又有小范围的滑落,但整体上一直处于高水平状态,保持再0.45以上。
1999年6月24日,教育部和国家计委联合宣布,1999年普通高校招生从上年的108万人扩大到156万人,增幅高达44.44﹪,中国高校大规模的扩招从此拉开了帷幕。
然而这个政策的推行却给民众带来了极大的困扰,扩招后学费高得离谱,令人难以接受。