第4章 SOM自组织特征映射神经网络
- 格式:doc
- 大小:1.71 MB
- 文档页数:16


模式识别习题集答案解析1、PCA和LDA的区别?PCA是⼀种⽆监督的映射⽅法,LDA是⼀种有监督的映射⽅法。
PCA只是将整组数据映射到最⽅便表⽰这组数据的坐标轴上,映射时没有利⽤任何数据部的分类信息。
因此,虽然做了PCA后,整组数据在表⽰上更加⽅便(降低了维数并将信息损失降到了最低),但在分类上也许会变得更加困难;LDA在增加了分类信息之后,将输⼊映射到了另外⼀个坐标轴上,有了这样⼀个映射,数据之间就变得更易区分了(在低纬上就可以区分,减少了很⼤的运算量),它的⽬标是使得类别的点距离越近越好,类别间的点越远越好。
2、最⼤似然估计和贝叶斯⽅法的区别?p(x|X)是概率密度函数,X是给定的训练样本的集合,在哪种情况下,贝叶斯估计接近最⼤似然估计?最⼤似然估计把待估的参数看做是确定性的量,只是其取值未知。
利⽤已知的样本结果,反推最有可能(最⼤概率)导致这样结果的参数值(模型已知,参数未知)。
贝叶斯估计则是把待估计的参数看成是符合某种先验概率分布的随机变量。
对样本进⾏观测的过程,把先验概率密度转化为后验概率密度,利⽤样本的信息修正了对参数的初始估计值。
当训练样本数量趋于⽆穷的时候,贝叶斯⽅法将接近最⼤似然估计。
如果有⾮常多的训练样本,使得p(x|X)形成⼀个⾮常显著的尖峰,⽽先验概率p(x)⼜是均匀分布,此时两者的本质是相同的。
3、为什么模拟退⽕能够逃脱局部极⼩值?在解空间随机搜索,遇到较优解就接受,遇到较差解就按⼀定的概率决定是否接受,这个概率随时间的变化⽽降低。
实际上模拟退⽕算法也是贪⼼算法,只不过它在这个基础上增加了随机因素。
这个随机因素就是:以⼀定的概率来接受⼀个⽐单前解要差的解。
通过这个随机因素使得算法有可能跳出这个局部最优解。
4、最⼩错误率和最⼩贝叶斯风险之间的关系?基于最⼩风险的贝叶斯决策就是基于最⼩错误率的贝叶斯决策,换⾔之,可以把基于最⼩错误率决策看做是基于最⼩风险决策的⼀个特例,基于最⼩风险决策本质上就是对基于最⼩错误率公式的加权处理。




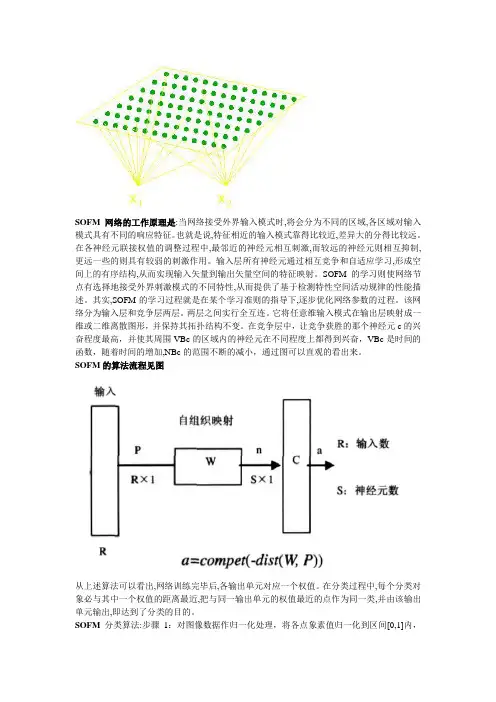
SOFM网络的工作原理是:当网络接受外界输入模式时,将会分为不同的区域,各区域对输入模式具有不同的响应特征。
也就是说,特征相近的输入模式靠得比较近,差异大的分得比较远。
在各神经元联接权值的调整过程中,最邻近的神经元相互刺激,而较远的神经元则相互抑制,更远一些的则具有较弱的刺激作用。
输入层所有神经元通过相互竞争和自适应学习,形成空间上的有序结构,从而实现输入矢量到输出矢量空间的特征映射。
SOFM的学习则使网络节点有选择地接受外界刺激模式的不同特性,从而提供了基于检测特性空间活动规律的性能描述。
其实,SOFM的学习过程就是在某个学习准则的指导下,逐步优化网络参数的过程。
该网络分为输入层和竞争层两层。
两层之间实行全互连。
它将任意维输入模式在输出层映射成一维或二维离散图形,并保持其拓扑结构不变。
在竞争层中,让竞争获胜的那个神经元c的兴奋程度最高,并使其周围VBc的区域内的神经元在不同程度上都得到兴奋,VBc是时间的函数,随着时间的增加,NBc的范围不断的减小,通过图可以直观的看出来。
SOFM的算法流程见图从上述算法可以看出,网络训练完毕后,各输出单元对应一个权值。
在分类过程中,每个分类对象必与其中一个权值的距离最近,把与同一输出单元的权值最近的点作为同一类,并由该输出单元输出,即达到了分类的目的。
SOFM分类算法:步骤1:对图像数据作归一化处理,将各点象素值归一化到区间[0,1]内,由此得到图像X=(x 1,x 2,…x n ),其中x i 为图像一点的归一化后的模式.步骤2:初始化网络连接权值W j ,其中1<=j<=M ,M 对应竞争层神经元向量元素的个数。
步骤3:选择获胜单元c,d c =j min ||x i -w j ||.步骤4:进行连接权调整邻域函数一般选用Gaussian 函数:NB(t)=exp{-d j,i (x)2)/2σ2}其中d j,i (x)表示邻域中神经元与获胜神经元间的距离,采用Euclid 距离计算;σ为邻域的有效半径,随离散时间指数衰减σ(t)=σ(0).exp(-t/τ1),t=0,1,2,∀,j=1,2,…m 的初始值,τ1为时间常数,σ(0)是σ(t)的初始值. 步骤5:按照以上步骤,反复训练每一个输入的模式值x i ,直至完成规定的训练次数.经过学习后,再次将x i 输入网络,其输出结果即为分类结果。



神经网络的特点分析神经网络的特点分析(1)神经网络的一般特点作为一种正在兴起的新型技术神经网络有着自己的优势,他的主要特点如下:①由于神经网络模仿人的大脑,采用自适应算法。
使它较之专家系统的固定的推理方式及传统计算机的指令程序方式更能够适应化环境的变化。
总结规律,完成某种运算、推理、识别及控制任务。
因而它具有更高的智能水平,更接近人的大脑。
②较强的容错能力,使神经网络能够和人工视觉系统一样,根据对象的主要特征去识别对象。
③自学习、自组织功能及归纳能力。
以上三个特点是神经网络能够对不确定的、非结构化的信息及图像进行识别处理。
石油勘探中的大量信息就具有这种性质。
因而,人工神经网络是十分适合石油勘探的信息处理的。
(2)自组织神经网络的特点自组织特征映射神经网络作为神经网络的一种,既有神经网络的通用的上面所述的三个主要的特点又有自己的特色。
①自组织神经网络共分两层即输入层和输出层。
②采用竞争学记机制,胜者为王,但是同时近邻也享有特权,可以跟着竞争获胜的神经元一起调整权值,从而使得结果更加光滑,不想前面的那样粗糙。
③这一网络同时考虑拓扑结构的问题,即他不仅仅是对输入数据本身的分析,更考虑到数据的拓扑机构。
权值调整的过程中和最后的结果输出都考虑了这些,使得相似的神经元在相邻的位置,从而实现了与人脑类似的大脑分区响应处理不同类型的信号的功能。
④采用无导师学记机制,不需要教师信号,直接进行分类操作,使得网络的适应性更强,应用更加的广泛,尤其是那些对于现在的人来说结果还是未知的数据的分类。
顽强的生命力使得神经网络的应用范围大大加大。
1.1.3自组织神经网络相对传统方法的优点自组织特征映射神经网络的固有特点决定了神经网络相对传统方法的优点:(1)自组织特性,减少人为的干预,减少人的建模工作,这一点对于数学模型不清楚的物探数据处理尤为重要,减少不精确的甚至存在错误的模型给结果带来的负面影响。
(2)强大的自适应能力大大减少了工作人员的编程工作,使得被解放出来的处理人员有更多的精力去考虑参数的调整对结果的影响。

第4章 SOM自组织特征映射神经网络生物学研究表明,在人脑的感觉通道上,神经元的组织原理是有序排列的。
当外界的特定时空信息输入时,大脑皮层的特定区域兴奋,而且类似的外界信息在对应的区域是连续映像的.生物视网膜中有许多特定的细胞对特定的图形比较敏感,当视网膜中有若干个接收单元同时受特定模式刺激时,就使大脑皮层中的特定神经元开始兴奋,输入模式接近,与之对应的兴奋神经元也接近;在听觉通道上,神经元在结构排列上与频率的关系十分密切,对于某个频率,特定的神经元具有最大的响应,位置相邻的神经元具有相近的频率特征,而远离的神经元具有的频率特征差别也较大。
大脑皮层中神经元的这种响应特点不是先天安排好的,而是通过后天的学习自组织形成的。
据此芬兰Helsinki大学的Kohonen T.教授提出了一种自组织特征映射网络(Self—organizing feature Map,SOM),又称Kohonen网络[1—5].Kohonen认为,一个神经网络接受外界输入模式时,将会分为不同的对应区域,各区域对输入模式有不同的响应特征,而这个过程是自动完成的。
SOM网络正是根据这一看法提出的,其特点与人脑的自组织特性相类似.4.1 竞争学习算法基础[6]4。
1.1 自组织神经网络结构1.定义自组织神经网络是无导师学习网络.它通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构。
2.结构层次型结构,具有竞争层.典型结构:输入层+竞争层。
如图4-1所示。
竞争层输入层图4—1 自组织神经网络结构输入层:接受外界信息,将输入模式向竞争层传递,起“观察”作用。
竞争层:负责对输入模式进行“分析比较”,寻找规律,并归类。
4。
1。
2 自组织神经网络的原理1.分类与输入模式的相似性分类是在类别知识等导师信号的指导下,将待识别的输入模式分配到各自的模式类中,无导师指导的分类称为聚类,聚类的目的是将相似的模式样本划归一类,而将不相似的分离开来,实现模式样本的类内相似性和类间分离性。
Kohonen算法实现自组织特征映射神经网络Kohonen算法实现自组织特征映射神经网络2010-12-23 14:28设有现有一个样本数据集,含有4个模式类,,,,各个类别含有5个数据,每个数据是一个二维向量[x,y]。
则需要设定4个输出层神经元来构建SOM网络,由于输入数据是二维的向量,所以输入层神经元有2个。
为了使SOM网络的设计和实行过程在作图中清晰可见,对输入的样本数据集均进行归一化处理。
:A =0.8776 0.47940.8525 0.52270.8253 0.56460.7961 0.60520.7648 0.6442:B=-0.6663 0.7457-0.7027 0.7115-0.7374 0.6755-0.7702 0.6378-0.8011 0.5985:C=-0.5748 -0.8183-0.5332 -0.8460-0.4903 -0.8716-0.4461 -0.8950-0.4008 -0.9162:D=0.9602 -0.27940.9729 -0.23110.9833 -0.18220.9911 -0.13280.9965 -0.0831 第一步:设定初始初始权值w,暂时设定为位于极坐标0°,90°,180°,270°角处的四个单位向量;设定初始学习率rate1max和学习率最小值rate1min;设定初始领域半径r1max和领域半径截止值r1min;设定输出层神经元个数为4。
第二步:输入新的模式向量X,即输入以上四类数据样本集A,B,C,D为X。
接着开始Kohonen算法的迭代运算过程,求解最佳权值w即聚类中心第三步:每次计算输入模式到输出神经元之间的距离之前,对学习率和领域半径均进行自适应修改。
随机抽取一个输入模式x,计算x与神经元之间的欧氏距离。
第四步:选取距离最小的神经元节点为最优神经元。
第五步:在规定的领域范围类对神经元的权值w按照公式进行修改。
第4章 SOM自组织特征映射神经网络生物学研究表明,在人脑的感觉通道上,神经元的组织原理是有序排列的。
当外界的特定时空信息输入时,大脑皮层的特定区域兴奋,而且类似的外界信息在对应的区域是连续映像的。
生物视网膜中有许多特定的细胞对特定的图形比较敏感,当视网膜中有若干个接收单元同时受特定模式刺激时,就使大脑皮层中的特定神经元开始兴奋,输入模式接近,与之对应的兴奋神经元也接近;在听觉通道上,神经元在结构排列上与频率的关系十分密切,对于某个频率,特定的神经元具有最大的响应,位置相邻的神经元具有相近的频率特征,而远离的神经元具有的频率特征差别也较大。
大脑皮层中神经元的这种响应特点不是先天安排好的,而是通过后天的学习自组织形成的。
据此芬兰Helsinki大学的Kohonen T.教授提出了一种自组织特征映射网络(Self-organizing feature Map,SOM),又称Kohonen网络[1-5]。
Kohonen认为,一个神经网络接受外界输入模式时,将会分为不同的对应区域,各区域对输入模式有不同的响应特征,而这个过程是自动完成的。
SOM网络正是根据这一看法提出的,其特点与人脑的自组织特性相类似。
4.1 竞争学习算法基础[6]4.1.1 自组织神经网络结构1.定义自组织神经网络是无导师学习网络。
它通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构。
2.结构层次型结构,具有竞争层。
典型结构:输入层+竞争层。
如图4-1所示。
竞争层图4-1 自组织神经网络结构输入层:接受外界信息,将输入模式向竞争层传递,起“观察”作用。
竞争层:负责对输入模式进行“分析比较”,寻找规律,并归类。
4.1.2 自组织神经网络的原理1.分类与输入模式的相似性分类是在类别知识等导师信号的指导下,将待识别的输入模式分配到各自的模式类中,无导师指导的分类称为聚类,聚类的目的是将相似的模式样本划归一类,而将不相似的分离开来,实现模式样本的类内相似性和类间分离性。
由于无导师学习的训练样本中不含期望输出,因此对于某一输入模式样本应属于哪一类并没有任何先验知识。
对于一组输入模式,只能根据它们之间的相似程度来分为若干类,因此,相似性是输入模式的聚类依据。
2.相似性测量神经网络的输入模式向量的相似性测量可用向量之间的距离来衡量。
常用的方法有欧氏距离法和余弦法两种。
(1)欧式距离法设i X X ,为两向量,其间的欧式距离T i i i X X X X X X d ))((--=-= (4-1)d 越小,X 与i X 越接近,两者越相似,当0=d 时,i X X =;以T d =(常数)为判据,可对输入向量模式进行聚类分析:由于312312,,d d d 均小于T ,465645,,d d d 均小于T ,而)6,5,4(1=>i T d i , )6,5,4(2=>i T d i , )6,5,4(3=>i T d i ,故将输入模式654321,,,,,X X X X X X 分为类1和类2两大类,如图4-2所示。
(2)余弦法设i X X ,为两向量,其间的夹角余弦iTX X XX =ϕcos (4-2)ϕ越小,X 与i X 越接近,两者越相似;当ϕ=0时,ϕcos =1,i X X =;同样以0ϕϕ=为判据可进行聚类分析。
类1类2图4-2 基于欧式距离法的模式分类3.竞争学习原理竞争学习规则的生理学基础是神经细胞的侧抑制现象:当一个神经细胞兴奋后,会对其周围的神经细胞产生抑制作用。
最强的抑制作用是竞争获胜的“唯我独兴”,这种做法称为“胜者为王”(Winner-Take-All ,WTA )。
竞争学习规则就是从神经细胞的侧抑制现象获得的。
它的学习步骤为:(1)向量归一化对自组织网络中的当前输入模式向量X 、竞争层中各神经元对应的内星权向量j w (m j ,,2,1 =),全部进行归一化处理,如图4-3所示,得到X ˆ和jW ˆ: XX X=ˆ, j j j W W W =ˆ (4-3)X 1X i图4-3 向量归一化(2)寻找获胜神经元将X ˆ与竞争层所有神经元对应的内星权向量),,2,1(ˆm j W j=进行相似性比较。
最相似的神经元获胜,权向量为*ˆjW : {}jn j j WX W X ˆˆmin},,2,1{*-=-∈T j j T j T T j j j W W X W X X W X W X W X ******ˆˆˆˆ2ˆˆ)ˆ)(ˆ(ˆˆ+-=--=-⇒)ˆˆ1(2*T jX W -= )ˆˆ(max ˆˆ*T j jT jX W X W =⇒ (4-4) (3)网络输出与权调整按WTA 学习法则,获胜神经元输出为“1”,其余为0。
即:⎪⎩⎪⎨⎧≠==+**01)1(jj j j t y j (4-5)只有获胜神经元才有权调整其权向量*j W 。
其权向量学习调整如下:⎪⎩⎪⎨⎧≠=+-+=∆+=+*)(ˆ)1()ˆˆ()(ˆ)(ˆ)1(*****j j t W t W W X t W W t W t W j j j j j j j α (4-6) 10≤<α为学习率,α一般随着学习的进展而减小,即调整的程度越来越小,趋于聚类中心。
(4)重新归一化处理归一化后的权向量经过调整后,得到的新向量不再是单位向量,因此要对学习调整后的向量重新进行归一化,循环运算,直到学习率α衰减到0。
为了更好地说明竞争学习算法的聚类分析效果,下面以一具体实例进行计算[6]。
【例4-1】用竞争学习算法将下列各模式分为两类)6.0,8.0(1=X ,)9848.0,1736.0(2-=X , )707.0,707.0(3=X , )9397.0,342.0(4-=X , )8.0,6.0(5=X ,学习率α=0.5。
【解】 将上述输入模式转换为极坐标形式: 89.3611∠=X , 8012-∠=X , 4513∠=X , 7014-∠=X , 13.5315∠=X 。
如图4-4所示。
2图4-4 模式向量图要求将各模式分为两类,则竞争层为两个神经元,设两个权向量,随机初始化为单元向量: 01)0,1()0(1∠==W , 1801)0,1()0(2-∠=-=W ,其竞争学习过程如下:(1)1X=1d 89.361)0(11∠=-W X ,=2d 89.2161)0(21∠=-W X 21d d <,神经元1获胜,1W 调整。
43.18189.365.00))0(()0()1(1111∠=⨯+=-+=W X W W α 1801)0()1(22-∠==W W(2)2X=1d 43.981)1(12∠=-W X ,=2d 1001)1(22∠=-W X 21d d <,神经元1获胜,1W 调整。
8.301)43.1880(5.043.18))1(()1()2(1211-∠=--⨯+=-+=W X W W α 1801)1()2(22-∠==W W(3)3X=1d 8.751)2(13∠=-W X ,=2d 2251)2(23∠=-W X 21d d <,神经元1获胜,1W 调整。
71)8.3045(5.08.30))2(()2()3(1311∠=+⨯+-=-+=W X W W α1801)2()3(22-∠==W W(4)4X=1d 771)3(14∠=-W X ,=2d 1101)3(24∠=-W X 21d d <,神经元1获胜,1W 调整。
5.311)770(5.07))3(()3()4(1411-∠=--⨯+=-+=W X W W α 1801)3()4(22-∠==W W(5)5X=1d 63.841)4(15∠=-W X ,=2d 87.1261)4(25∠=-W X 21d d <,神经元1获胜,1W 调整。
111)5.3113.53(5.05.31))4(()4()5(1511∠≈+⨯+-=-+=W X W W α 1801)4()5(22-∠==W W(6)1X=1d 89.251)5(11∠=-W X ,=2d 89.2161)5(21∠=-W X 21d d <,神经元1获胜,1W 调整。
24189.255.011))5(()5()6(1111∠≈⨯+=-+=W X W W α 1801)5()6(22-∠==W W(7)2X=1d 1041)6(12∠=-W X ,=2d 1001)6(22∠=-W X 12d d <,神经元2获胜,2W 调整。
1301)18080(5.0180))6(()6()7(2222-∠=+-⨯+-=-+=W X W W α 241)6()7(11∠==W W(8)3X=1d 211)7(13∠=-W X ,=2d 1751)7(23∠=-W X 21d d <,神经元1获胜,1W 调整。
341)2445(5.024))7(()7()8(1311∠≈-⨯+=-+=W X W W α 1301)7()8(22-∠==W W(9)4X=1d 1041)8(14∠=-W X ,=2d 601)8(24∠=-W X 12d d <,神经元2获胜,2W 调整。
1001)13070(5.0130))8(()8()9(2422-∠=+-⨯+-=-+=W X W W α 341)8()9(11∠==W W(10)5X=1d 13.191)9(15∠=-W X ,=2d 13.1531)9(25∠=-W X 21d d <,神经元1获胜,1W 调整。
441)3413.53(5.034))9(()9()10(1511∠≈-⨯+=-+=W X W W α 1001)9()10(22-∠==W W一直循环运算下去,其前20次学习结果如表4-1所示。
表4-1 竞争学习结果学习次数W 1W 2学习次数 W 1W 21 18.43° -180° 11 40.5° -100°2 -30.8° -180° 12 40.5° -90°3 7° -180° 13 43° -90°4 -32° -180° 14 43° -81° 511°-180°1547.5°-81°(续表)学习次数W 1W 2学习次数 W 1W 26 24° -180° 16 42° -81°7 24° -130° 17 42° -80.5°8 34° -130° 18 43.5° -80.5°9 34° -100° 19 43.5° -75° 1044°-100°2048.5°-75°从表4-1可见,在运算学习20次后,网络权值1W ,2W 趋于稳定: 75,4521-→→W W 。