SQL Server 2008如何创建分区表
- 格式:doc
- 大小:292.50 KB
- 文档页数:8

创建分区表的sql语句当我们需要在数据库中存储大量数据并且需要对这些数据进行快速访问和管理时,分区表是一个非常有用的工具。
通过创建分区表,我们可以将数据分割成更小的部分,从而提高查询性能、降低维护成本,并且更好地管理数据。
下面是创建分区表的SQL语句示例:sql.CREATE TABLE sales_data.(。
transaction_id INT,。
sales_amount DECIMAL(10, 2),。
sales_date DATE.)。
PARTITION BY RANGE (YEAR(sales_date))。
(。
PARTITION p0 VALUES LESS THAN (2010),。
PARTITION p1 VALUES LESS THAN (2011),。
PARTITION p2 VALUES LESS THAN (2012),。
PARTITION p3 VALUES LESS THAN (2013),。
PARTITION p4 VALUES LESS THAN MAXVALUE.);在上面的SQL语句中,我们创建了一个名为`sales_data`的分区表,其中包括了`transaction_id`、`sales_amount`和`sales_date`三个字段。
我们使用`PARTITION BY RANGE`来指定分区的方式,这里是按照`sales_date`字段的年份进行分区。
然后,我们定义了几个分区,每个分区包含了一个特定的年份范围。
通过这样的分区表设计,我们可以更加高效地存储和管理销售数据,同时在查询时也能够获得更好的性能。
分区表的创建语句可以根据实际需求进行调整,以满足不同的数据存储和查询需求。
创建分区表的SQL语句是数据库管理和优化的重要工具,能够帮助我们更好地利用数据库资源并提高系统性能。
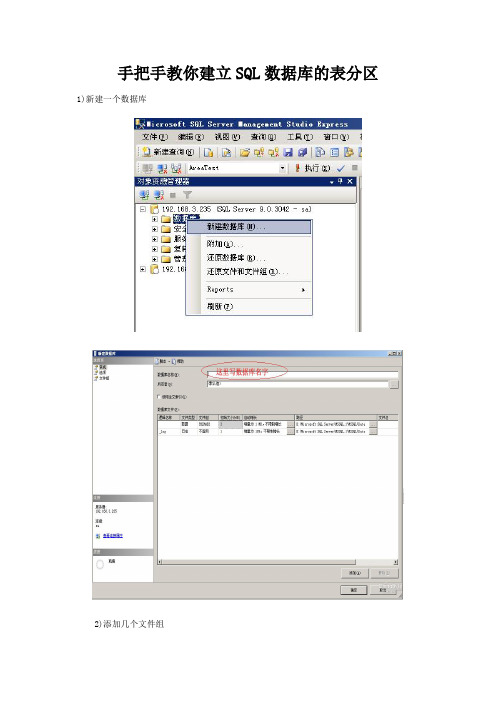
手把手教你建立SQL数据库的表分区1)新建一个数据库2)添加几个文件组3)回到“常规”选项卡,添加数据库文件看到用红色框框起来的地方没?上一步中建立的文件组在这里就用上了。
再看后面的路径,我把每一个文件都单独放在不同的磁盘上,而且最好都是单独的放在不同的物理盘上,这样会大大提高数据的性能。
点击“确定”数据库就算创建完成了。
4)接下来要做的是建立一个分区行数,SQL语句如下:大家学习的时候最好不要直接COPY,动手把它抄一遍也好。
create partition function PartFuncForExample(Datetime) as Range Right for Value('20000101','20010101','20020101','20030101')这里我准备用表中的某个时间字段作为分区的条件,当然你也可以用其他的,比如INT 之类,只要好分段的都可以。
这里注意 Right 关键字,意思就是当记录的时间(在下面会被指到表的某个字段)大于等于20000101的时候,数据会被分到下一个区间,比如2000年1月1号之前的数据会被分到一区,包含2000年1月1号和之后的数据会被分到二区,以此类推。
Right 也可以使用Left替代,意思同上类似。
另外,上面我定义了四个分割点,这四个分割点是根据我们刚刚创建的文件组来决定的。
四个分割点就能产生5个区间段,我们把每个区间段的数据存入一个文件组。
正确执行上述语句后你可以在数据里找到以“PartFuncForExample”命名的分区函数,如下图5)把分区函数建立好以后,我们再来建立分区方案。
目的是为了把分区函数产生的分区映射到文件数据组里。
分区函数是告诉数据库如何分区数据,而分区方案是告诉数据库如何把已分区的数据存到哪个文件组里。
下面我来创建分区方案。
Create Partition Scheme PartSchForExample //创建一个分区方案+分区方案名称 As Partition PartFuncForExample//目的为了分区函数PartFuncForExample To ( PRIMARY,//文件组名 Partition1, //文件组名 Partition2, //文件组名 Partition3, //文件组名Partition4 //文件组名 )正确执行后能在分区方案中看到,如下图6)马上就快要大公告成了,下面我们来建立要分区存储的表,该表的数据理论上应该是非常非常多的,百万级别的记录以上而且基本上是不更新的。

创建数据库和表通过向导方式,在SQL Server Management Studio窗口中使用可视化的界面通过提示来创建数据库和表。
例如,在配置好的SQL Server服务器Y AO上进行操作,创建一个名称为的数据库Storage,然后在Storage数据库中创建一个名为LoginInFrm的表,该表包含userId、userName、passWord个字段。
操作步骤:(1)单击【开始】菜单,并执行【所有程序】|【Microsoft SQL Server 2008 R2】|【配置工具】|【SQL Server 配置管理器】命令,打开SQL Server Management Studio窗口。
(2)在【连接到服务器】对话框中,选择服务器类型为“数据库引擎”;服务器名称为“Y AO”,设置身份验证为SQL Server身份验证并输入登录名和密码,启用【记住密码】复选框后单击【连接】按钮,如图1-12所示。
图1-12 连接服务器启用【记住密码】复选框选项,在以后连接服务器时可以不用再输入服务器名称、登陆名和密码,直接单击【连接】按钮即可。
(3)右击【数据库】节点,执行【新建数据库】命令,如图1-13所示。
图1-13 执行【新建数据库】命令(4)在弹出的【新建数据库】对话框中,输入【数据库名称】为“Storage”,单击【确定】按钮,完成Storage数据库创建,如图1-14所示。
图1-14 【新建数据库】对话框在SQL Server 2008不强制这2种类型文件必须使用带mdf和ldf扩展名,但使用它们指出文件类型是个良好的文件命名习惯。
(5)在“对象资源管理器”中展开Storage数据库节点,右击【表】节点,执行【新建表】命令。
(6)在弹出的【新建表】窗口中,分别输入userId、userName、passWord字段,并设置其属性,并单击【保存】按钮。
然后,在弹出对话框中,输入LoginInFrm数据表名,再保存当前所创建的表,如图1-15所示。
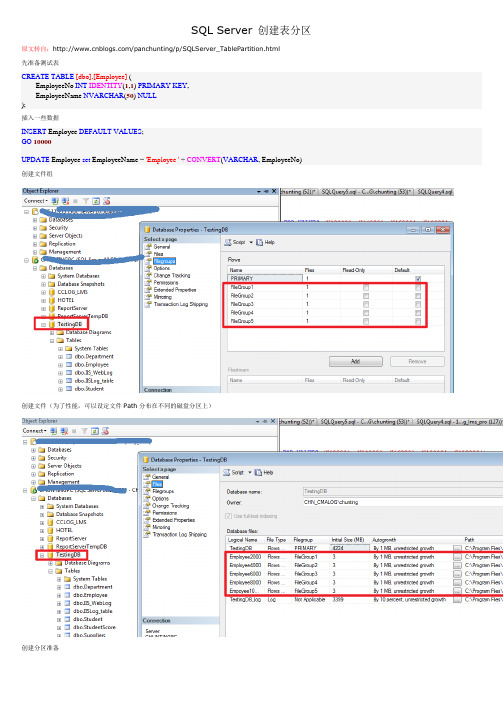
SQL Server 创建表分区原文转自:/panchunting/p/SQLServer_TablePartition.html先准备测试表CREATETABLE[dbo].[Employee] (EmployeeNo INT IDENTITY(1,1) PRIMARYKEY,EmployeeName NVARCHAR(50) NULL);插入一些数据INSERT Employee DEFAULTVALUES;GO10000UPDATE Employee set EmployeeName='Employee '+CONVERT(VARCHAR, EmployeeNo)创建文件组创建文件(为了性能,可以设定文件Path分布在不同的磁盘分区上)创建分区准备选择分区列创建分区函数创建分区框架定义边界值,分区,因为有5个边界值,所以需6个分区产生的脚本文件(换句话说上面的步骤等同于下面的语句)USE[TestingDB]GOBEGINTRANSACTIONCREATE PARTITION FUNCTION[EmpFunction](int) AS RANGE RIGHT FORVALUES (N'2000', N'4000', N'6000', N'8000', N'10000')CREATE PARTITION SCHEME [FunScheme]AS PARTITION [EmpFunction]TO ([FileGroup1], [FileGroup2], [FileGroup3], [FileGroup4], [FileGroup5], [PRIMARY])ALTERTABLE[dbo].[Employee]DROPCONSTRAINT[PK__Employee__7AD0F1B633D4B598]ALTERTABLE[dbo].[Employee]ADDPRIMARYKEYCLUSTERED([EmployeeNo]ASC)WITH (PAD_INDEX =OFF, STATISTICS_NORECOMPUTE =OFF, SORT_IN_TEMPDB =OFF, IGNORE_DUP_KEY =OFF, ONLINE =OFF, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) ON[FunScheme]([EmployeeNo])COMMITTRANSACTION执行上面的SQL语句其中语句ON [FunScheme]([EmployeeNo])是关键,表明了表Employee依赖分区框架FunScheme来进行分区,分区的列为EmployeeNo而分区框架有依赖于分区函数,即分区表依赖分区框架,分区框架又依赖于分区函数查看表分区结果作者:舍长出处:/本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.。

sqlserver2008使用教程SQL Server 2008是由微软公司开发的一款关系型数据库管理系统(RDBMS),用于存储和管理大量结构化数据。
本教程将向您介绍SQL Server 2008的基本功能和使用方法。
首先,您需要安装SQL Server 2008软件。
您可以从微软官方网站下载并安装免费的Express版本,或者购买商业版本以获取更多高级功能。
安装完成后,您可以启动SQL Server Management Studio (SSMS),这是一个图形化界面工具,可用于管理和操作SQL Server数据库。
在SSMS中,您可以连接到本地或远程的SQL Server实例。
一旦连接成功,您将能够创建新的数据库,更改数据库设置,执行SQL查询和管理用户权限等。
要创建新的数据库,您可以右键单击数据库节点并选择“新建数据库”。
在弹出的对话框中,输入数据库名称和其他选项,然后单击“确定”。
新的数据库将出现在对象资源管理器窗口中。
要执行SQL查询,您可以在查询编辑器中编写SQL语句。
例如,要创建一个新的表,您可以使用“CREATE TABLE”语句,并在括号中定义表的列和数据类型。
将查询复制到查询窗口中,并单击“执行”按钮来执行查询。
除了执行基本的SQL查询外,SQL Server 2008还提供了许多高级功能,如存储过程、触发器、视图和索引等。
这些功能可以提高数据库的性能和安全性。
存储过程是预编译的SQL代码块,可以按需执行。
您可以使用存储过程来处理复杂的业务逻辑或执行重复的任务。
要创建存储过程,您可以使用“CREATE PROCEDURE”语句,并在大括号中定义存储过程的内容。
触发器是与表相关联的特殊存储过程,可以在表中插入、更新或删除数据时自动触发。
通过使用触发器,您可以实现数据的约束和验证。
视图是虚拟表,是对一个或多个基本表的查询结果进行封装。
视图可以简化复杂的查询,并提供安全性和数据隐藏。

sql server分区表的实现我们知道很多事情都存在一个分治的思想,同样的道理我们也可以用到数据表上,当一个表很大很大的时候,我们就会想到将表拆分成很多小表,查询的时候就到各个小表去查,最后进行汇总返回给调用方来加速我们的查询速度,当然切分可以使用横向切分,纵向切分,比如我们最熟悉的订单表,通常会将三个月以外的订单放到历史订单表中,这里的三个月就是将订单表进行切分的依据。
好了,分区表的好处我想大家都很清楚了,下面我们看看如何实现。
一:分区表这里我们做个例子,创建一个test数据库,表名为shop,以createtime作为分区依据。
1:确定分区依据怎么分区的话,这个要看具体业务逻辑了,你可以按照时间,地区,求模等等都可以。
2:创建文件组既然是文件组,肯定是对文件进行分类管理的,默认情况下就一个mdf和ldf文件,当所有的数据都挤压在mdf上,确实不是一个很好的事情,降低我们的查询速度,当用到文件组的时候就可以创建多个ndf来分摊mdf 中的数据,甚至还可以将ndf分摊到几个磁盘上,充分利用服务器多核处理能力,说了这么多,我们看看sql语句咋搞,这里我创建四个文件组,分别存放2013之前,2013,2014和2014年之后的数据。
1 alter database Test add filegroup Before20132 alter database Test add filegroup T20133 alter database Test add filegroup T20144 alter database Test add filegroup After20143:创建文件根据上面在文件组上的概述,文件的作用大家都知道了,这里我们要做的是,将次文件.ndf附加到文件组上,因为我创建了4个文件组,所以我也创建4个文件分别存放在这4个文件组中。
1 alter database Test add file2 (Name=N'Before2013',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\Before20131.ndf',size=5mb,maxsize=100Mb,filegr owth=5mb)3 to filegroup Before20134 alter database Test add file5 (Name=N'T2013',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\T20131.ndf',size=5mb,maxsize=100Mb,filegrowth =5mb)6 to filegroup T20137 alter database Test add file8 (Name=N'T2014',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\T20141.ndf',size=5mb,maxsize=100Mb,filegrowth =5mb)9 to filegroup T201410 alter database Test add file11 (Name=N'After2014',filename='D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\After20141.ndf',size=5mb,maxsize=100Mb,filegro wth=5mb)12 to filegroup After20144:编写分区函数刚才也说了,我们是按照时间进行切分的,将数据表数据分成:① 2013年之前② 2013-2014③ 2014-2015④ 2015之后既然都知道依据了,我们分区函数也方便写了。
SQL-Server-2008数据库—创建、建表、查询语句SQL Server 2008数据库—创建、建表、查询语句一、创建数据库1、利用对象资源管理器创建用户数据库:(1)选择“开始”—“程序”—Microsoft SQL Server 2008—SQL Server Management Studio命令,打开SQL Server Management Studio。
(2)使用“Windows身份验证”连接到SQL Server 2008数据库实例。
(3)展开SQL Server 实例,右击“数据库”,然后人弹出的快捷菜单中选择“新建数据库存”命令,打开“新建数据库”对话框。
(4)在“新建数据库”对话框中,可以定义数据库的名称、数据库的所有者、是否使用全文索引、数据文件和日志文件的逻辑名称和路径、文件组、初始大小和增长方式等。
输入数据库名称student。
2、利用T-SQL语句创建用户数据库:在SQL Server Management Studio中,单击标准工具栏的“新建查询”按钮,启动SQL编辑器窗口,在光标处输入T-SQL语句,单击“执行”按钮。
SQL编辑器就提交用户输入的T-SQL语句,然后发送到服务器执行,并返回执行结果。
创建数据库student的T-SQL语句如下:Create data base studentOn primary(name=student_data,filename='E:\SQL Server2008 SQLFULL_CHS\student_data.mdf',size=3,maxsize=unlimited,filegrowth=1)Log on(name=student_log,filename='E:\SQL Server2008 SQLFULL_CHS\student_log.ldf',size=1,maxsize=20,filegrowth=10%)二、创建数据表1、利用表设计器创建数据表:(1)启动SQL Server Management Studio,连接到SQL Server 2008数据库实例。
分区表创建语句1. 嘿,你想知道分区表咋创建吗?就像盖房子得先规划房间一样,分区表创建也有它的门道。
比如说,在MySQL里创建按日期分区的销售数据表,那语句就像魔法咒语。
“CREATE TABLE sales (id INT, sale_date DATE, amount DECIMAL(10,2)) PARTITION BY RANGE (YEAR(sale_date)) (PARTITION p2020 VALUES LESS THAN (2021), PARTITION p2021 VALUES L ESS THAN (2022));”这样一弄,数据就像被好好归类的小物件,整整齐齐。
2. 分区表创建语句简直是数据管理的神器呢!想象你有一堆乱七八糟的衣服,分区表创建语句就是那能把衣服按季节分类的魔法棒。
拿Oracle来说,如果要创建一个按地区分区的客户表,语句可能是“CREATE TABLE customers (id NUMBER, name VARCHAR2(50), region VARCHAR2(20)) PARTITION BY LIST (region) (PARTITION north V ALUES ('North Region'), PARTITION south VALUES ('South Region'));”是不是很神奇,数据一下就井井有条啦。
3. 你要是还不懂分区表创建语句,那可有点out啦!这就好比给一群小动物建不同的窝,让它们各得其所。
在SQL Server里创建按产品类型分区的库存表,语句可以是“CREATE TABLE inventory (product_id INT, product_type VARCHAR(30), quantity INT) PARTITION BY RANGE (product_type) (PARTITION electronics VALUES LESS THAN ('Furniture'), PARTITION furniture VALUES LESS THAN('Toys'));”看,这样数据就不会乱成一团了。
-本文演示了SQL Server 2008 分区表实例:--1. 创建测试数据库;--2. 创建分区函数;--3. 创建分区架构;--4. 创建分区表;--5. 创建分区索引;--6. 分区切换;--7. 查询哪些表使用了分区表;-- 创建测试数据库USE masterGOIF OBJECT_ID(N'PartitionDataBase') IS NOT NULLDROP DATABASE PartitionDataBaseGOCREATE DATABASE PartitionDataBaseON PRIMARY(NAME = N'File_A_H',FILENAME ='D:\Data\PartitionDataBase_AH.mdf'),FILEGROUP FileGroup_I_N(NAME = N'File_I_N',FILENAME ='D:\Data\PartitionDataBase_IN.mdf'),FILEGROUP FileGroup_M_Z(NAME = N'File_M_Z',FILENAME ='D:\Data\PartitionDataBase_MZ.mdf')GO-- 创建分区函数USE PartitionDataBase;GOCREATE PARTITION FUNCTION StaffNameRangePFN(varchar(100)) ASRANGE LEFT FOR VALUES ('H','M')GO-- 创建分区架构CREATE PARTITION SCHEME StaffNamePSchemeASPARTITION StaffNameRangePFNTO ([PRIMARY], FileGroup_I_N, FileGroup_M_Z)GO-- 创建分区表CREATE TABLE [dbo].[Staff]([StaffName] [varchar](100) NOT NULL)ON StaffNamePScheme ([StaffName])GO-- 插入测试数据1INSERT INTO [dbo].[Staff]SELECT FirstName FROM AdventureWorks.Person.Contact-- 查看结果SELECT$partition.StaffNameRangePFN(StaffName) AS [Partition Number],MIN(StaffName) AS [Min StaffName],MAX(StaffName) AS [Max StaffName],COUNT(StaffName) AS [Rows In Partition]FROM dbo.staff AS oGROUP BY $partition.StaffNameRangePFN(StaffName)ORDER BY [Partition Number]-- 插入测试数据2INSERT INTO [dbo].[Staff]SELECT AddressLine1 FROM AdventureWorks.Person.Address-- 查看结果SELECT$partition.StaffNameRangePFN(StaffName) AS [Partition Number],MIN(StaffName) AS [Min StaffName],MAX(StaffName) AS [Max StaffName],COUNT(StaffName) AS [Rows In Partition]FROM dbo.staff AS oGROUP BY $partition.StaffNameRangePFN(StaffName)ORDER BY [Partition Number]-- 从结果看出,已经重新分区过了-- 重新改变布局Use masterGOALTER DATABASE PartitionDataBase ADD FILEGROUP FileGroup_0_9 GOALTER DATABASE PartitionDataBaseADD FILE(NAME = N'File_0_9',FileName = 'D:\Data\PartitionDataBase.mdf')TO FILEGROUP FileGroup_0_9GOUse PartitionDataBaseGOALTER PARTITION SCHEME StaffNamePSchemeNEXT USED FileGroup_0_9;GOALTER PARTITION FUNCTION StaffNameRangePFN()SPLIT RANGE ('A');GO-- 查看结果SELECT$partition.StaffNameRangePFN(StaffName) AS [Partition Number],MIN(StaffName) AS [Min StaffName],MAX(StaffName) AS [Max StaffName],COUNT(StaffName) AS [Rows In Partition]FROM dbo.staff AS oGROUP BY $partition.StaffNameRangePFN(StaffName)ORDER BY [Partition Number]-- 创建聚集分区索引CREATE CLUSTERED index IXC_Staff_StaffName on dbo.Staff ( StaffName )go--- 分区切换-- 6.1切换分区表的一个分区到普通数据表中:Partition to Table--首先建立普通数据表dbo.StaffName_Num ,该用来存放表StaffName 数字STAFF的数据-- 创建表if OBJECT_ID('dbo.StaffName_Num') is not nulldrop table dbo.StaffName_Numgocreate table dbo.StaffName_Num(StaffName varchar ( 100 ) not null)on [FileGroup_0_9]go--注意这里建表不能为空或primary,因为我们建的分区表不在primary文件组--如果这样会出现--消息4939,级别16,状态1,第1 行--ALTER TABLE SWITCH 语句失败。
1.1数据库1.1.1创建CREATE DATABASE name[ [ WITH ][ OWNER [=]user_name ][ TEMPLATE [=]template ][ ENCODING [=]encoding ][ LC_COLLATE [=]lc_collate ][ LC_CTYPE [=]lc_ctype ][ TABLESPACE [=]tablespace_name ][ CONNECTION LIMIT [=]connlimit ] ]1.1.2删除DROP DATABASE db_name011.1.3修改1.1.3.1查看当前的存放位置select database_id,name,physical_name AS CurrentLocation,state_desc,size from sys.master_files where database_id=db_id(N'数据库名');1.1.3.2修改默认的数据库文件存放位置(即时生效)EXEC xp_instance_regwrite@rootkey='HKEY_LOCAL_MACHINE',@key='Software\Microsoft\MSSQLServer\MSSQLServer',@value_name='DefaultData',@type=REG_SZ,@value='E:\MSSQL_MDF\data'GO1.1.3.3修改默认的日志文件存放位置(即时生效)EXEC master..xp_instance_regwrite@rootkey='HKEY_LOCAL_MACHINE',@key='Software\Microsoft\MSSQLServer\MSSQLServer',@value_name='DefaultLog',@type=REG_SZ,@value='E:\MSSQL_MDF\log'GO1.1.3.4修改数据库文件自动增长ALTER DATABASE db_003MODIFY FILE (NAME=N'db_003a',FILEGROWTH= 10%)ALTER DATABASE db_016MODIFY FILE (NAME=N'db_016',maxsize= UNLIMITED)1.1.3.5重命名数据库EXEC sp_dboption'OldDbName','Single User','TRUE'EXEC sp_renamedb'OldDbName','NewDbName'EXEC sp_dboption'NewDbName','Single User','FALSE'1.1.3.6向数据库添加数据文件或日志文件USE masterGOALTER DATABASE db_testADD FILEGROUP Test1FG1;GOALTER DATABASE db_testADD FILE(NAME=test1dat3,FILENAME='d:\MSSQLSERVER\DATA\t1dat3.ndf',SIZE= 5MB,MAXSIZE= 100MB,FILEGROWTH= 5MB),(NAME=test1dat4,FILENAME='d:\MSSQLSERVER\DATA\t1dat4.ndf',SIZE= 5MB,MAXSIZE= 100MB,FILEGROWTH= 5MB)TO FILEGROUP Test1FG1;GO1.1.3.7数据库规划和分区技术(新建)第一步:首先建立我们要使用的数据库,最重要的是建立多个文件组我们先新建立四个目录,来组成文件组,一个用来存放主文件的目录:Primary三个数据文件目录:FG1、FG2、FG3建立库:create database Sales on primary(name=N'Sales',filename=N'C:\data\Primary\Sales.mdf',size=3MB,maxsize=100MB,filegrowth=10%),filegroup FG1(NAME=N'File1',FILENAME=N'C:\data\FG1\File1.ndf',SIZE= 1MB,MAXSIZE= 100MB,FILEGROWTH= 10%),FILEGROUP FG2(NAME=N'File2',FILENAME=N'C:\data\FG2\File2.ndf',SIZE= 1MB,MAXSIZE= 100MB,FILEGROWTH= 10%),FILEGROUP FG3(NAME=N'File3',FILENAME=N'C:\data\FG3\File3.ndf',SIZE= 1MB,MAXSIZE= 100MB,FILEGROWTH= 10%)LOG ON(NAME=N'Sales_Log',FILENAME=N'C:\data\Primary\Sales_Log.ldf',SIZE= 1MB,MAXSIZE= 100MB,FILEGROWTH= 10%)GO第二步:建立分区函数目的是用来规范不同数据存放到不同目录的标准,简单讲就是如何分区。
SQL Server 2008中的分区表
如果你的数据库中某一个表中的数据满足以下几个条件,那么你就要考虑创建分区表了。
1、数据库中某个表中的数据很多。
很多是什么概念?一万条?两万条?还是十万条、一百万条?这个,我觉得是仁者见仁、智者见智的问题。
当然数据表中的数据多到查询时明显感觉到数据很慢了,那么,你就可以考虑使用分区表了。
如果非要我说一个数值的话,我认为是100万条。
2、但是,数据多了并不是创建分区表的惟一条件,哪怕你有一千万条记录,但是这一千万条记录都是常用的记录,那么最好也不要使用分区表,说不定会得不偿失。
只有你的数据是分段的数据,那么才要考虑到是否需要使用分区表。
3、什么叫数据是分段的?这个说法虽然很不专业,但很好理解。
比如说,你的数据是以年为分隔的,对于今年的数据而言,你常进行的操作是添加、修改、删除和查询,而对于往年的数据而言,你几乎不需要操作,或者你的操作往往只限于查询,那么恭喜你,你可以使用分区表。
换名话说,你对数据的操作往往只涉及到一部分数据而不是所有数据的话,那么你就可以考虑什么分区表了。
那么,什么是分区表呢?
简单一点说,分区表就是将一个大表分成若干个小表。
假设,你有一个销售记录表,记录着每个每个商场的销售情况,那么你就可以把这个销售记录表按时间分成几个小表,例如说5个小表吧。
2009年以前的记录使用一个表,2010年的记录使用一个表,2011年的记录使用一个表,2012年的记录使用一个表,2012年以后的记录使用一个表。
那么,你想查询哪个年份的记录,就可以去相对应的表里查询,由于每个表中的记录数少了,查询起来时间自然也会减少。
但将一个大表分成几个小表的处理方式,会给程序员增加编程上的难度。
以添加记录为例,以上5个表是独立的5个表,在不同时间添加记录的时候,程序员要使用不同的SQL 语句,例如在2011年添加记录时,程序员要将记录添加到2011年那个表里;在2012年添
加记录时,程序员要将记录添加到2012年的那个表里。
这样,程序员的工作量会增加,出错的可能性也会增加。
使用分区表就可以很好的解决以上问题。
分区表可以从物理上将一个大表分成几个小表,但是从逻辑上来看,还是一个大表。
接着上面的例子,分区表可以将一个销售记录表分成五个物理上的小表,但是对于程序员而言,他所面对的依然是一个大表,无论是2010年添加记录还是2012年添加记录,对于程序员而言是不需要考虑的,他只要将记录插入到销售记录表——这个逻辑中的大表里就行了。
SQL Server会自动地将它放在它应该呆在的那个物理上的小表里。
同样,对于查询而言,程序员也只需要设置好查询条件,OK,SQL Server会自动将去相应的表里查询,不用管太多事了。
这一切是不是很诱人?
的确,那么我们就可以开始动手创建分区表了。
第一、创建分区表的第一步,先创建数据库文件组,但这一步可以省略,因为你可以直接使用PRIMARY文件。
但我个人认为,为了方便管理,还是可以先创建几个文件组,这样可以将不同的小表放在不同的文件组里,既便于理解又可以提高运行速度。
创建文件组的方法很简单,打开SQL Server Management Studio,找到分区表所在数据库,右键单击,在弹出的菜单里选择“属性”。
然后选择“文件组”选项,再单击下面的“添加”按钮,如下图所示:
第二,创建了文件组之后,还要再创建几个数据库文件。
为什么要创建数据库文件,这很好理解,因为分区的小表必须要放在硬盘上,而放在硬盘上的什么地方呢?当然是文件里啦。
再说了,文件组中没有文件,文件组还要来有啥用呢?还是在上图的那个界面,选择“文件”选项,然后添加几个文件。
在添加文件的时候要注意以下几点:
1、不要忘记将不同的文件放在文件组中。
当然一个文件组中也可以包含多个不同的文件。
2、如果可以的话,将不同的文件放在不同的硬盘分区里,最好是放在不同的独立硬盘里。
要知道IQ的速度往往是影响SQL Server运行速度的重要条件之一。
将不同的文件放在不同的硬盘上,可以加快SQL Server的运行速度。
在本例中,为了方便起见,将所有数据库文件都放在了同一个硬盘下,并且每个文件组
中只有一个文件。
如下图所示。
第三、创建一个分区函数。
这一步是必须的了,创建分区函数的目的是告诉SQL Server 以什么方式对分区表进行分区。
这一步必须要什么SQL脚本来完成。
以上面的例子,我们要将销售表按时间分成5个小表。
假设划分的时间为:
第1个小表:2010-1-1以前的数据(不包含2010-1-1)。
第2个小表:2010-1-1(包含2010-1-1)到2010-12-31之间的数据。
第3个小表:2011-1-1(包含2011-1-1)到2011-12-31之间的数据。
第4个小表:2012-1-1(包含2012-1-1)到2012-12-31之间的数据。
第5个小表:2013-1-1(包含2013-1-1)之后的数据。
那么分区函数的代码如下所示:
CREATE PARTITION FUNCTION partfunSale (datetime)
AS RANGE RIGHT FOR VALUES ('20100101','20110101','20120101','20130101')
其中:
CREATE PARTITION FUNCTION意思是创建一个分区函数。
partfunSale为分区函数名称。
AS RANGE RIGHT为设置分区范围的方式为Right,也就是右置方式。
FOR VALUES ('20100101','20110101','20120101','20130101')为按这几个值来分区。
这里需要说明的一下,在Values中,'20100101'、'20110101'、'20120101'、'20130101',这些都是分区的条件。
“ 20100101”代表2010年1月1日,在小于这个值的记录,都会分成一个小表中,如表1;而小于或等于'20100101'并且小于'20110101'的值,会放在另一个表中,如表2。
以此类推,到最后,所有大小或等于'20130101'的值会放在另一个表中,如表5。
也许有人会问,为什么值“ 20100101”会放在表2中,而不是表1中呢?这是由AS RANGE RIGHT中的RIGHT所决定的,RIGHT的意思是将等于这个值的数据放在右边的那个表里,也就是表2中。
如果您的SQL语句中使用的是Left而不是RIGHT,那么就会放在左边的表中,也就是表1中。
第四、创建一个分区方案。
分区方案的作用是将分区函数生成的分区映射到文件组中去。
分区函数的作用是告诉SQL Server,如何将数据进行分区,而分区方案的作用则是告诉SQL Server将已分区的数据放在哪个文件组中。
分区方案的代码如下所示:
CREATE PARTITION SCHEME partschSale
AS PARTITION partfunSale
TO (
Sale2009,
Sale2010,
Sale2011,
Sale2012,
Sale2013)
其中:
CREATE PARTITION SCHEME意思是创建一个分区方案。
partschSale为分区方案名称。
AS PARTITION partfunSale说明该分区方案所使用的数据划分条件(也就是所使用的分区函数)为partfunSale。
TO后面的内容是指partfunSale分区函数划分出来的数据对应存放的文件组。
到此为止,分区函数和分区方案就创建完毕了。
创建后的分区函数和分区方案在数据库的“存储”中可以看到,如下图所示:
最后,创建分区表,创建方式和创建普遍表类似,如下所示:
CREATE TABLE Sale(
[Id] [int] IDENTITY(1,1) NOT NULL,
[Name] [varchar](16) NOT NULL,
[SaleTime][datetime] NOT NULL
) ON partschSale([SaleTime])
其中:
CREATE TABLE 意思是创建一个数据表。
Sale为数据表名。
()中为表中的字段,这里的内容和创建普通数据表没有什么区别,惟一需要注意的是不能再创建聚集索引了。
道理很简单,聚集索引可以将记录在物理上顺序存储的,而分区表是将数据分别存储在不同的表中,这两个概念是冲突的,所以,在创建分区表的时候就不能再创建聚集索引了。
ON partschSale()说明使用名为partschSale的分区方案。
partschSale()括号中为用于分区条件的字段是SaleTime。
OK,一个物理上是分离的,逻辑上是一体的分区表就创建完毕了。
查看该表的属性,可以看到该表已经属于分区表了。