第九章面板数据模型
- 格式:ppt
- 大小:417.00 KB
- 文档页数:50



面板数据模型面板数据模型(Panel Data Model)是一种经济学和统计学中常用的数据分析方法,它允许研究人员在时间和个体维度上分析数据。
该模型结合了截面数据(Cross-sectional Data)和时间序列数据(Time Series Data),能够捕捉到个体间的异质性和时间的动态变化。
面板数据模型的基本假设是个体间存在固定效应(Fixed Effects)和时间效应(Time Effects),即个体特定的不变因素和时间特定的不变因素会对观测数据产生影响。
通过控制这些效应,面板数据模型可以更准确地估计变量之间的关系。
面板数据模型的普通形式可以表示为:Yit = α + βXit + εit其中,Yit表示第i个个体在第t个时间点的观测值,α是截距项,β是自变量Xit的系数,εit是误差项。
面板数据模型可以通过固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)来估计参数。
固定效应模型假设个体间的差异是固定的,即个体特定的不变因素对观测数据产生影响。
该模型通过引入个体固定效应来控制个体间的差异,估计其他变量对因变量的影响。
随机效应模型假设个体间的差异是随机的,即个体特定的不变因素对观测数据不产生影响。
该模型通过引入个体随机效应来控制个体间的差异,估计其他变量对因变量的影响。
面板数据模型的估计方法包括最小二乘法(Ordinary Least Squares, OLS)、固定效应估计法(Fixed Effects Estimation)和随机效应估计法(Random Effects Estimation)。
最小二乘法是一种常用的估计方法,但在面板数据模型中存在一致性问题。
固定效应估计法通过个体间的差异来估计参数,可以解决一致性问题。
随机效应估计法则通过个体间和时间间的差异来估计参数,可以更全面地捕捉到数据的变化。
面板数据模型在经济学和社会科学研究中具有广泛的应用。

面板数据模型引言概述:面板数据模型是一种经济学和统计学中常用的数据分析方法。
它适用于具有时间和个体维度的数据,可以帮助研究人员更好地理解个体之间的关系以及时间的变化趋势。
本文将详细介绍面板数据模型的概念、应用领域、优势和限制,并提供一些实际案例来说明其实际价值。
正文内容:1. 面板数据模型的概念1.1 面板数据模型的定义面板数据模型是一种同时考虑时间和个体维度的数据分析方法。
它将个体的观察结果按照时间顺序排列,形成一个面板数据集,以便分析个体之间的关系和时间的变化趋势。
1.2 面板数据模型的分类面板数据模型可以分为固定效应模型和随机效应模型。
固定效应模型假设个体之间的差异是固定的,而随机效应模型则允许个体之间的差异是随机的。
2. 面板数据模型的应用领域2.1 经济学领域面板数据模型在经济学领域得到广泛应用。
例如,研究人员可以利用面板数据模型来分析不同国家或地区的经济增长率、失业率和通货膨胀率之间的关系,以及企业的生产效率和市场竞争程度之间的关系。
2.2 社会科学领域面板数据模型也在社会科学领域具有重要意义。
研究人员可以利用面板数据模型来研究教育、健康、就业等社会问题,并分析个体特征对这些问题的影响。
2.3 金融领域面板数据模型在金融领域的应用也非常广泛。
例如,研究人员可以利用面板数据模型来分析不同股票的收益率之间的关系,以及股票市场的波动与宏观经济指标之间的关系。
3. 面板数据模型的优势3.1 控制个体固定效应面板数据模型可以通过固定效应来控制个体固有的差异,从而更准确地分析个体之间的关系。
3.2 利用时间维度的信息面板数据模型可以利用时间维度的信息,分析个体随时间的变化趋势,更好地理解时间的影响。
3.3 提高数据的效率面板数据模型可以利用面板数据集中的交叉个体和时间信息,提高数据的效率,减少估计的方差。
4. 面板数据模型的限制4.1 数据缺失问题面板数据模型在面对数据缺失问题时可能会出现一些困难,需要采取一些特殊的处理方法。

面板数据模型面板数据模型,又称固定效应模型,是计量经济学中常用的一种数据分析方法。
它适用于时间序列和截面数据的联合分析,具有较高的灵活性和强大的解释能力。
本文将对面板数据模型的基本原理、应用场景以及估计方法进行介绍,并通过实例说明其实际运用。
第一部分:面板数据模型的基本原理面板数据模型基于以下假设:每个个体(又称单位)在不同时间点都有观测值,并且个体之间的观测值具有相关性。
面板数据模型通常由固定效应模型和随机效应模型两种形式。
固定效应模型假设个体特定的不变因素对观测值产生了影响,这些不变因素可能包括个体的性别、年龄、学历等。
固定效应模型可以通过引入个体固定效应变量来捕捉这些影响因素,并以此来解释观测值的变动。
第二部分:面板数据模型的应用场景面板数据模型在经济学、金融学、社会学等领域得到了广泛的应用。
例如,在经济学中,研究人员可以利用面板数据模型来分析不同国家或地区的经济增长情况,探讨政策对经济发展的影响;在金融学领域,研究人员可以运用面板数据模型来研究股票价格的波动和影响因素。
第三部分:面板数据模型的估计方法面板数据模型有多种估计方法,常见的有固定效应模型估计和随机效应模型估计。
固定效应模型估计通常采用最小二乘法,即通过对个体固定效应进行回归分析来求解模型参数。
随机效应模型估计则假设个体固定效应是误差项的一部分,通过对固定效应进行随机化处理得到模型的估计结果。
实例应用:假设我们需要研究不同地区的教育水平对经济增长的影响,我们可以使用面板数据模型来分析这个问题。
我们收集了10个地区在2010年到2020年的经济增长率和教育水平数据。
我们可以利用固定效应模型来探究教育水平对经济增长的影响。
首先,我们创建一个包含个体固定效应的面板数据模型,并使用最小二乘法来估计参数。
然后,我们通过分析模型的显著性水平、参数估计结果以及模型拟合程度来得出结论。
通过面板数据分析,我们可以发现教育水平对经济增长确实存在显著的正向影响。

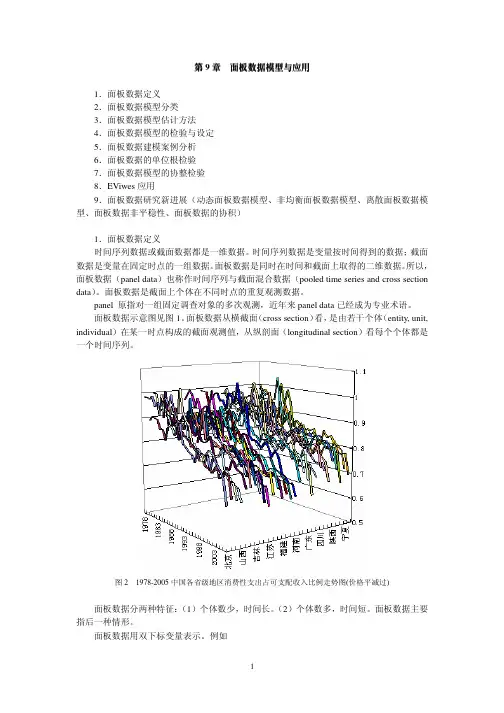


面板数据模型引言概述:面板数据模型是一种经济学和统计学领域常用的数据分析方法,它可以更准确地描述和分析时间序列和横截面数据的关系。
本文将从五个大点来阐述面板数据模型的相关内容。
正文内容:1. 面板数据模型的基本概念1.1 面板数据的定义和特点:面板数据是指在一段时间内对多个个体进行观察得到的数据,包含了时间序列和横截面的特点。
1.2 面板数据的分类:面板数据可以分为平衡面板和非平衡面板,平衡面板是指每一个个体在每一个时间点都有观测值,非平衡面板则相反。
2. 面板数据模型的估计方法2.1 固定效应模型:固定效应模型是面板数据模型中最常用的一种估计方法,它通过引入个体固定效应来控制个体特定的不可观测因素对因变量的影响。
2.2 随机效应模型:随机效应模型则是通过引入个体随机效应来控制个体特定的不可观测因素对因变量的影响,相比于固定效应模型,它更加灵便。
2.3 混合效应模型:混合效应模型是固定效应模型和随机效应模型的结合,既考虑了个体固定效应,又考虑了个体随机效应。
3. 面板数据模型的假设检验3.1 Hausman检验:Hausman检验是用来判断固定效应模型和随机效应模型哪个更适合的一种假设检验方法。
3.2 异方差检验:由于面板数据模型中存在异方差问题,需要进行异方差检验来确保模型的可靠性。
3.3 序列相关检验:面板数据模型中还需要进行序列相关检验,以确保模型的误差项是否存在相关性。
4. 面板数据模型的应用领域4.1 经济学领域:面板数据模型在经济学领域广泛应用,可以用于研究经济增长、劳动经济学、国际贸易等问题。
4.2 社会学领域:面板数据模型也被用于社会学研究中,可以用于分析教育、健康、家庭结构等社会问题。
4.3 金融学领域:面板数据模型在金融学领域的应用也很广泛,可以用于研究股票市场、债券市场等金融问题。
5. 面板数据模型的优缺点5.1 优点:面板数据模型可以同时考虑个体特征和时间变化,更准确地描述变量之间的关系。

面板数据模型引言概述:面板数据模型是一种经济学和统计学领域常用的数据分析方法,它能够有效处理时间序列和截面数据的结合。
本文将介绍面板数据模型的概念、应用领域、优势以及常见的面板数据模型方法。
一、面板数据模型的概念1.1 面板数据的定义面板数据是指在一段时间内对多个个体进行观测得到的数据,其中个体可以是个人、公司、国家等。
面板数据包含了时间序列和截面数据的特点,能够提供更全面和准确的信息。
1.2 面板数据模型的基本假设面板数据模型的基本假设包括个体异质性、时间稳定性和无序列相关等。
个体异质性指个体之间存在差异;时间稳定性指个体的特征在时间上保持稳定;无序列相关指个体之间的观测值在时间上不相关。
1.3 面板数据模型的分类面板数据模型可以分为固定效应模型、随机效应模型和混合效应模型。
固定效应模型假设个体间存在固定差异,随机效应模型假设个体间存在随机差异,而混合效应模型同时考虑了固定差异和随机差异。
二、面板数据模型的应用领域2.1 经济学领域面板数据模型在经济学领域广泛应用于宏观经济分析、产业经济分析、金融市场分析等方面。
它能够匡助研究人员更准确地分析经济现象,提供政策制定的依据。
2.2 社会科学领域面板数据模型在社会科学领域中的应用也较为广泛,例如教育领域的学生绩效评估、健康领域的医疗资源分配等。
通过面板数据模型,研究人员可以更好地理解社会问题并提供相应的解决方案。
2.3 管理学领域面板数据模型在管理学领域的应用主要集中在企业绩效评估、市场竞争分析、人力资源管理等方面。
它能够匡助企业决策者更好地了解企业内外部环境对企业绩效的影响。
三、面板数据模型的优势3.1 提供更多信息相比于传统的时间序列或者截面数据分析方法,面板数据模型能够提供更多的信息,更全面地反映个体和时间的差异。
3.2 提高估计效率面板数据模型能够利用个体和时间的交叉信息,提高估计的效率。
通过引入个体固定效应或者随机效应,可以降低估计的方差。

面板数据模型引言概述:面板数据模型是一种统计学中常用的数据分析方法,它适用于研究时间序列数据和横截面数据的结合。
通过面板数据模型,研究者可以更准确地分析数据的动态变化和个体之间的差异。
本文将从面板数据模型的定义、特点、优势、应用和局限性五个方面进行详细介绍。
一、定义1.1 面板数据模型是指同时包含时间序列和横截面数据的一种数据结构。
1.2 面板数据模型将不同时间点上的横截面数据整合在一起,形成一个二维的数据集。
1.3 面板数据模型可以用来研究个体之间的差异以及时间序列数据的动态变化。
二、特点2.1 面板数据模型具有横截面数据和时间序列数据的双重特性。
2.2 面板数据模型可以更准确地捕捉数据的动态变化和个体之间的异质性。
2.3 面板数据模型可以有效解决截面数据和时间序列数据分析中的一些问题。
三、优势3.1 面板数据模型可以提高数据的效率和准确性。
3.2 面板数据模型可以更好地控制个体特征和时间效应。
3.3 面板数据模型可以更准确地估计数据的影响因素和关联关系。
四、应用4.1 面板数据模型在经济学、社会学、医学等领域都有广泛的应用。
4.2 面板数据模型可以用来研究个体行为的变化趋势和影响因素。
4.3 面板数据模型可以用来预测未来的数据变化和趋势。
五、局限性5.1 面板数据模型在数据处理和模型选择上需要更多的技术和经验。
5.2 面板数据模型对数据的要求较高,需要充分考虑数据的质量和可靠性。
5.3 面板数据模型在样本量较小或数据缺失的情况下可能会出现估计偏差和不准确性。
总结:面板数据模型是一种强大的数据分析工具,能够更准确地分析数据的动态变化和个体之间的差异。
研究者在使用面板数据模型时需要充分考虑数据的质量和可靠性,同时也要注意模型的局限性和应用范围。
通过合理使用面板数据模型,可以更好地理解数据的本质和规律,为进一步的研究和决策提供有力支持。
第一讲面板数据模型相关概念面板数据定义面板数据特点面板数据模型介绍一、面板数据的定义☐在经济学研究和实际应用中,我们经常需要同时分析和比较横截面观察值和时间序列观察值结合起来的数据,即:数据集中的变量同时含有横截面和时间序列的信息。
☐这种数据被称为面板数据(panel data),它与我们以前分析过的纯粹的横截面数据和时间序列数据有着不同的特点。
0112233,1,2,,;1,2,,it it it it it Y X X X i N t Tββββμ=++++==☐对于面板数据模型☐一般为了分析每个个体的特殊效应,对随机扰动项的设定是itμ=it i itμαε+☐其中代表个体的特殊效应,它反映了不同个体之间的差别。
是服从经典假定的扰动项。
it εi α☐最常见的两种面板数据模型是建立在的不同假设基础之上的。
☐一种假设是固定的常数,这种模型被称为固定效应模型(fixed effect model );☐另一种假设假定不是固定的,这种模型被称为随机效应模型(random effect model )。
i αi αi α在固定效应模型中假定it i it εαμ+= 其中i α是对每一个个体是固定的常数,代表个体的特殊效应,也反映了个体间的差异。
it it i it x y εβα++= 整个固定效应模型可以用矩阵形式表示为:⎪⎪⎪⎪⎪⎭⎫ ⎝⎛+⎪⎪⎪⎪⎪⎭⎫ ⎝⎛+⎪⎪⎪⎪⎪⎭⎫ ⎝⎛⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=⎪⎪⎪⎪⎪⎭⎫ ⎝⎛N N N N x x x i i i y y y εεεβααα 21212121000000 其中i 为1⨯T 的单位向量。
☐OLS估计量:有偏的,非一致的。
☐本质问题:个体效应的内生性。
☐其常用的方法是最小二乘虚拟变量(LSDV)法。
基本思想:通过虚拟变量把个体效应从误差项中分离出来,使分离后剩余的误差项与解释变量不相关,以便进行OLS 估计。
01it it itY X ββμ=++it i itμαε=+N i ,,2,1 =Tt ,,2,1 =二、固定效应模型估计引入虚拟变量,。
面板数据模型引言概述:面板数据模型是一种经济学和统计学领域常用的数据分析方法,它能够有效地处理时间序列和横截面数据的结合。
本文将介绍面板数据模型的概念、应用领域以及其在实证研究中的优势。
一、概述面板数据模型1.1 面板数据模型的定义面板数据模型是一种将时间序列和横截面数据结合起来的统计模型。
它包含了多个个体(cross-section)在多个时间点(time period)上的观测数据。
面板数据模型可以分为固定效应模型和随机效应模型两种类型。
1.2 面板数据模型的应用领域面板数据模型广泛应用于经济学、金融学、社会科学等领域的实证研究中。
它可以用于分析个体间的差异、时间变化以及两者之间的相互作用。
面板数据模型可以帮助研究者更准确地捕捉数据的动态特征,从而提高研究的可信度和准确性。
1.3 面板数据模型的优势面板数据模型相比于传统的时间序列或横截面数据模型具有以下优势:(1)更多的信息:面板数据模型结合了时间序列和横截面数据,可以提供更多的信息,从而增加了研究的可靠性。
(2)更强的效率:面板数据模型可以利用个体间和时间间的差异,提高模型的效率和准确性。
(3)更广泛的应用:面板数据模型可以适用于各种数据类型,包括面板数据、平衡面板数据和非平衡面板数据等。
二、固定效应模型2.1 固定效应模型的基本原理固定效应模型假设个体间存在不可观测的个体固定效应,即个体特征对因变量的影响在模型中是固定的。
通过控制个体固定效应,固定效应模型可以更准确地估计其他变量对因变量的影响。
2.2 固定效应模型的估计方法固定效应模型的估计方法包括最小二乘法(OLS)和差分法(Difference-in-Differences)。
最小二乘法可以通过控制个体固定效应来估计其他变量的系数。
差分法则通过个体间的差异来估计因果效应。
2.3 固定效应模型的应用案例固定效应模型可以应用于许多实证研究中,例如研究个体间的收入差距、教育对收入的影响等。
面板数据模型一、概述面板数据模型是一种统计分析方法,用于研究面板数据(也称为纵向数据或者长期数据)。
面板数据由多个个体(如个人、家庭或者公司)在不同时间点上的观测数据组成。
该模型可以匡助我们理解个体之间的差异、时间的变化以及个体与时间的交互作用。
二、面板数据模型的基本假设1. 独立性假设:面板数据中的个体之间是相互独立的,即个体之间的观测结果不会相互影响。
2. 同质性假设:个体之间的差异是固定的,即个体的特征在观测期间内保持不变。
3. 随机性假设:个体的观测结果是随机的,不受其他未观测到的因素影响。
4. 稳定性假设:个体之间的关系在观测期间内是稳定的,不受外部因素的影响。
三、面板数据模型的常见形式1. 固定效应模型(Fixed Effects Model):该模型假设个体之间的差异是固定的,并通过引入个体固定效应来控制个体特征的影响。
2. 随机效应模型(Random Effects Model):该模型假设个体之间的差异是随机的,并通过引入个体随机效应来控制个体特征的影响。
3. 混合效应模型(Mixed Effects Model):该模型结合了固定效应模型和随机效应模型的优点,既考虑了个体固定效应,又考虑了个体随机效应。
四、面板数据模型的优势1. 利用面板数据可以更准确地估计个体之间的差异和时间的变化,相比于横截面数据或者时间序列数据,面板数据更具有信息量。
2. 面板数据模型可以控制个体特征的影响,从而更准确地研究个体与时间的交互作用。
3. 面板数据模型可以提高估计的效率,减少参数估计的方差。
五、面板数据模型的应用领域1. 经济学研究:面板数据模型在经济学中广泛应用,例如研究个体消费行为、企业投资决策等。
2. 社会学研究:面板数据模型可以用于研究个体的社会行为、社会关系等。
3. 教育研究:面板数据模型可以用于研究学生的学业发展、教育政策的效果等。
六、面板数据模型的实施步骤1. 数据准备:采集面板数据,并进行数据清洗和整理。
经济统计学中的面板数据模型面板数据模型是经济统计学中一种重要的分析方法,它能够综合考虑横截面和时间序列的特征,为研究人员提供了更为全面和准确的数据分析工具。
本文将探讨面板数据模型的基本概念、应用领域以及一些常见的方法和技巧。
一、面板数据模型的基本概念面板数据模型又称为纵横数据模型,它是将多个横截面单位(如个人、家庭、企业等)在一定时间段内的观测数据组合起来进行分析的一种统计模型。
面板数据模型可以分为固定效应模型和随机效应模型两种类型。
固定效应模型假设每个横截面单位的个体效应是固定的,不随时间变化。
这种模型常用于分析不同个体之间的差异,例如研究不同企业的经营绩效。
而随机效应模型则假设个体效应是随机的,可以通过随机变量来表示。
这种模型适用于研究同一横截面单位在不同时间点的变化,例如分析个人收入的变化趋势。
二、面板数据模型的应用领域面板数据模型在经济学和社会科学的研究中得到了广泛的应用。
首先,它可以用于研究个体行为的动态变化。
例如,通过分析个人消费行为的面板数据,可以了解到个人在不同时间段内的消费习惯和消费水平的变化趋势,为制定宏观经济政策和个人理财提供依据。
其次,面板数据模型也可以用于评估政策效果和经济政策的影响。
通过对政策实施前后的面板数据进行比较,可以分析政策对经济发展、就业情况等方面的影响,并为政策制定者提供决策参考。
另外,面板数据模型还可以用于研究跨国公司的经营策略和市场竞争。
通过对不同国家或地区的面板数据进行分析,可以了解到跨国公司在不同市场的表现和竞争优势,为企业决策提供参考。
三、面板数据模型的方法和技巧在面板数据模型的分析中,有一些常见的方法和技巧可以帮助研究人员更好地利用数据进行分析。
首先,面板数据模型中的异质性问题需要引起注意。
由于不同个体之间存在差异,研究人员需要通过引入个体固定效应或随机效应来控制这种差异,以确保模型的准确性。
其次,面板数据模型中的内生性问题也需要关注。
内生性问题指的是模型中的解释变量与误差项之间存在相关性,可能导致估计结果的偏误。