聚类分析的SPSS实现
- 格式:doc
- 大小:485.00 KB
- 文档页数:12



spss聚类分析案例在进行SPSS聚类分析时,我们通常会遵循一系列步骤来确保分析的准确性和有效性。
以下是一个典型的聚类分析案例,展示了如何使用SPSS软件进行数据分析。
首先,我们需要收集数据。
数据可以是定量的,也可以是定性的,但必须与研究问题相关。
例如,如果我们正在研究消费者购买行为,我们可能会收集关于消费者年龄、收入、购买频率和偏好的数据。
接下来,我们将数据导入SPSS。
这可以通过直接输入数据、从Excel文件导入或使用SPSS的数据导入向导来完成。
一旦数据在SPSS中,我们需要检查数据的准确性和完整性,确保没有缺失值或异常值。
在进行聚类分析之前,我们通常需要对数据进行预处理。
这可能包括标准化变量、处理缺失值和异常值,以及可能的变量转换。
标准化是重要的,因为它确保了所有变量在聚类分析中具有相同的权重。
然后,我们选择聚类方法。
SPSS提供了几种聚类方法,包括K-means聚类、层次聚类和双向聚类。
选择哪种方法取决于数据的特性和研究目的。
例如,如果我们有明确的类别数量,K-means聚类可能是合适的;如果我们希望看到数据的层次结构,层次聚类可能更合适。
在选择了聚类方法后,我们需要确定聚类的数量。
这可以通过多种方法来确定,包括肘部方法、轮廓系数或基于信息准则的方法。
确定聚类数量后,我们可以运行聚类算法,并将数据点分配到不同的聚类中。
聚类完成后,我们需要评估聚类的质量。
这可以通过查看聚类的内部一致性和聚类之间的差异来完成。
我们还可以进行统计测试,如ANOVA或卡方检验,来检验聚类是否在统计上显著。
最后,我们解释聚类结果。
这包括识别每个聚类的特征,以及这些特征如何与研究问题相关。
例如,如果我们发现一个聚类主要由高收入、频繁购买的消费者组成,这可能表明这是一个高价值的市场细分。
在整个聚类分析过程中,我们可能会进行多次迭代,调整聚类方法、聚类数量或数据预处理步骤,以获得最佳的聚类结果。
聚类分析是一个动态的过程,需要根据数据和研究目的进行调整。
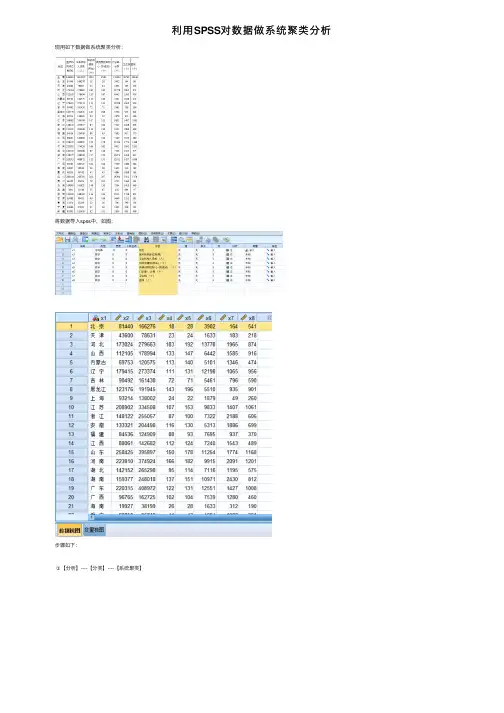
利⽤SPSS对数据做系统聚类分析现⽤如下数据做系统聚类分析:将数据导⼊spss中,如图:步骤如下:①【分析】----【分类】----【系统聚类】⼩技巧:添加变量的时候,可以单击【医疗机构床位数(张)】,然后按住shift键不松,⿏标单击【医院(个)】就可以选择多个变量⼀起添加③点击【统计】勾选【解的范围】,可以根据⾃⼰的需要选择最⼩聚类数和最⼤聚类数(这⾥我设置为2和5),然后点击【继续】④点击【图】,(这⾥我选择的是做系谱图),然后点击【继续】⑤点击【⽅法】,选择⽡尔德(word)⽅法,然后点击【继续】⑥点击【保存】,取消勾选默认项,勾选解的范围,填⼊刚才设置的最⼩、最⼤聚类数,然后点击【继续】【确定】得到结果如下:系谱图为:观察得出的结果图就可以知道当分n类时,把哪些地区是分到⼀类的如果需要进⼀步分析聚类中的均值等特点,可以将数据分组后分析⽐如,以聚3类分析:各类均值的特点步骤:①【数据】-----【拆分⽂件】②勾选【⽐较组】,将Ward Method [CLU3_1]填⼊分组依据,然后确定③然后点击【分析】----【描述性统计】----【描述】④填⼊变量⑤点击【选项】,勾选⾃⼰想要得到的结果(这⾥只勾选均值),然后点击【继续】【确定】可得到结果如图,便可以⽐较各类均值⼤⼩了北京8144016627618283902164541天津436007863123241633183218河北173024279663183192137781965874⼭西11210517899413314764421585916内蒙古6975312057511314051011346474辽宁179415273374111131121981065956吉林9049216143872715461796590⿊龙江1231761919451431965510935901上海932141380022422187949260江苏208902334508107153983314071061浙江1481222550578710073222188606安徽13332120449811613053131886699福建8453612490988937695937370江西8806114268211212472401543489⼭东2584253958971501781125417741168河南223810374924166182991520911201湖北1421522652989511471161195575湖南159377248018137151109712430812⼴东2203154089721221311255114271008⼴西9676516272510210475391280460海南199273819926281633312190重庆6825096742414348841088361四川2003442857852022071629450121178贵州66152956547910537151460394云南10989514562114815072041410649西藏749610746558143266697陕西11094316819011612481111748851⽢肃65988994319910696491351381青海15470235092256790399136宁夏182602785221261022238131新疆83303121400922115856861699。

SPSS聚类分析实验报告一、实验目的本实验旨在通过SPSS软件对样本数据进行聚类分析,找出样本数据中的相似性,并将样本划分为不同的群体。
二、实验步骤1.数据准备:在SPSS软件中导入样本数据,并对数据进行处理,包括数据清洗、异常值处理等。
2.聚类分析设置:在SPSS软件中选择聚类分析方法,并设置分析参数,如距离度量方法、聚类方法、群体数量等。
3.聚类分析结果:根据分析结果,对样本数据进行聚类,并生成聚类结果。
4.结果解释:分析聚类结果,确定每个群体的特征,观察不同群体之间的差异性。
三、实验数据本实验使用了一个包含1000个样本的数据集,每个样本包含了5个变量,分别为年龄、性别、收入、教育水平和消费偏好。
下表展示了部分样本数据:样本编号,年龄,性别,收入,教育水平,消费偏好---------,------,------,------,---------,---------1,30,男,5000,大专,电子产品2,25,女,3000,本科,服装鞋包3,35,男,7000,硕士,食品饮料...,...,...,...,...,...四、实验结果1. 聚类分析设置:在SPSS软件中,我们选择了K-means聚类方法,并设置群体数量为3,距离度量方法为欧氏距离。
2.聚类结果:经过聚类分析后,我们将样本分为了3个群体,分别为群体1、群体2和群体3、每个群体的特征如下:-群体1:年龄偏年轻,女性居多,收入较低,教育水平集中在本科,消费偏好为服装鞋包。
-群体2:年龄跨度较大,男女比例均衡,收入中等,教育水平较高,消费偏好为电子产品。
-群体3:年龄偏高,男性居多,收入较高,教育水平较高,消费偏好为食品饮料。
3.结果解释:根据聚类结果,我们可以看到不同群体之间的差异性较大,每个群体都有明显的特征。
这些结果可以帮助企业更好地了解不同群体的消费习惯,为市场营销活动提供参考。
五、实验结论通过本次实验,我们成功地对样本数据进行了聚类分析,并得出了3个不同的群体。
作业2:城镇居民消费结构的K-means聚类模型
本次作业为基于IBM SPSS Statistics 24的K-means聚类运算
一、第一步:导入数据,点击文件下方的图标,选中”案例2-城镇居民消费结构“,点击打开,
二、分析数据
1、点击Spss界面的“分析”,然后依次点击“分类”、“K-均值聚类”,如下图
2、在弹出的界面中点击“选项”,勾选“ANOVA表”,如下图,再点击“继续”
3、在弹出的界面中点击“保存”,勾选“聚类成员”、“与聚类中心距离”,如下图所示,点击“继续”
4、最后在弹出的界面中,把“地区”放入“个案标注依据”,其余的放入“变量”中,如下图所示,点击“确定”。
三、结果展示
ANOVA。

spss聚类分析步骤什么是聚类分析聚类分析是一种通过将相似的样本数据进行分组的方法,以便于研究者可以更好地理解数据中的模式和结构。
在聚类分析中,研究者希望将数据样本划分为若干个互不重叠的群体,每个群体内的样本相似度较高,而不同群体之间的样本相似度较低。
spss的聚类分析功能spss是一种功能强大的统计分析软件,它提供了丰富的数据分析功能。
在spss中,可以使用聚类分析功能来进行数据样本的分组和分类。
聚类分析功能可以帮助研究者发现数据中的模式、规律和群体。
使用spss的聚类分析功能,可以根据变量之间的相似性将样本分成若干个组,从而更好地理解数据。
spss聚类分析步骤以下是使用spss进行聚类分析的基本步骤:1.打开数据文件:首先,需要打开包含要进行聚类分析的数据的spss数据文件。
可以通过点击菜单栏的“文件”选项打开数据文件,或者通过键盘快捷键“Ctrl + O”。
2.转换变量类型:在进行聚类分析之前,需要将数据中的所有变量转换为合适的类型。
例如,如果有一些分类变量,需要将其转换为因子变量。
可以通过点击菜单栏的“数据”选项,然后选择“转换变量类型”来进行变量类型的转换。
3.选择变量:在进行聚类分析之前,需要确定要使用的变量。
可以选择所有的变量,也可以只选择特定的变量。
选择变量可以通过点击菜单栏的“数据”选项,然后选择“选择变量”来进行。
4.进行聚类分析:选择好变量之后,可以进行聚类分析。
可以通过点击菜单栏的“分析”选项,然后选择“聚类”来进行聚类分析。
5.配置聚类分析参数:在进行聚类分析之前,需要配置一些参数。
例如,确定要使用的聚类方法和相似性测度。
可以根据具体的研究目的和数据特点来选择合适的参数。
6.运行聚类分析:配置好参数之后,可以点击“确定”按钮来运行聚类分析。
spss会根据选择的变量和参数,对样本数据进行聚类,并生成相应的结果。
7.分析聚类结果:在进行聚类分析之后,可以对聚类结果进行进一步的分析。
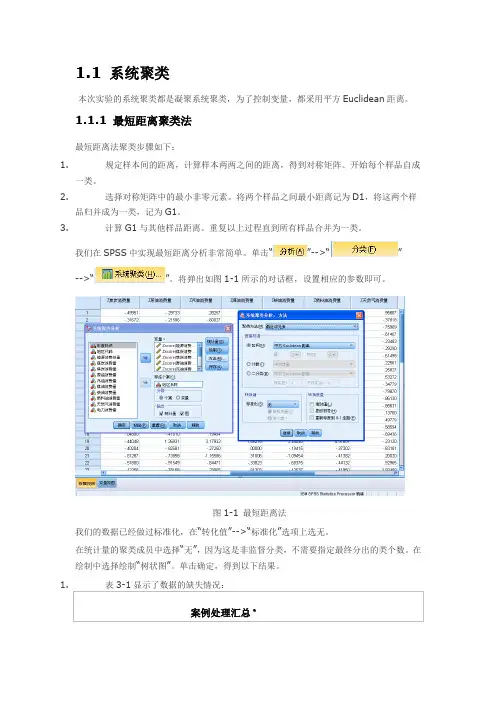
1.1 系统聚类本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。
1.1.1 最短距离聚类法最短距离法聚类步骤如下:1.规定样本间的距离,计算样本两两之间的距离,得到对称矩阵。
开始每个样品自成一类。
2.选择对称矩阵中的最小非零元素。
将两个样品之间最小距离记为D1,将这两个样品归并成为一类,记为G1。
3.计算G1与其他样品距离。
重复以上过程直到所有样品合并为一类。
我们在SPSS中实现最短距离分析非常简单。
单击“”-->“”-->“”。
将弹出如图1-1所示的对话框,设置相应的参数即可。
图1-1 最短距离法我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。
在绘制中选择绘制“树状图”。
单击确定,得到以下结果。
聚类表阶群集组合系数首次出现阶群集下一阶群集1 群集 2 群集 1 群集 21 21 28 .211 0 0 102 12 24 .465 0 0 63 2 27 .491 0 0 54 13 20 .585 0 0 95 2 14 .645 3 0 66 2 12 .678 5 2 77 2 7 .702 6 0 88 2 25 .773 7 0 99 2 13 .916 8 4 1110 21 29 1.085 1 0 1211 2 18 1.106 9 0 12表1-2 聚类过程我们可以通过更加形象直观的树状图来观察整个聚类过程和聚类效果。
如图1-2所示,最短距离法组内距离小,但组间距离也较小。
分类特征不够明显,无法凸显各个省份的能源消耗的特点。
但是我们可以看到广东省能源消耗组成和其他省份特别不同,在其他方法中也显现出来。
12 2 21 1.115 11 10 13 13 2 17 1.360 12 0 14 14 2 26 1.564 13 0 15 15 2 22 1.627 14 0 16 16 2 5 1.649 15 0 17 17 2 8 1.877 16 0 18 18 2 16 3.027 17 0 19 19 2 30 3.543 18 0 20 20 2 11 4.930 19 0 21 21 2 4 5.024 20 0 22 22 2 10 6.445 21 0 24 23 1 9 8.262 0 0 26 24 2 15 10.093 22 0 25 25 2 23 10.096 24 0 26 26 1 2 10.189 23 25 27 27 1 6 11.387 26 0 28 28 1 3 13.153 27 0 29 2911932.36728图1-2 最短距离法聚类图1.1.2 组间联接聚类组间联接聚类法定义为两类之间的平均平方距离,即。

使用SPSS软件进行因子分析和聚类分析的方法随着统计分析软件的进步,SPSS(Statistical Package for the Social Sciences)软件作为一款功能强大、易于使用的统计分析工具受到广泛欢迎。
它能援助探究人员进行各种统计分析,其中包括因子分析和聚类分析。
本文将介绍如何使用SPSS软件进行因子分析和聚类分析,并针对每个分析方法提供详尽步骤和操作示例。
一、因子分析因子分析是一种常用的统计方法,在数据维度缩减和相关变量结构分析方面具有广泛的应用。
以下是使用SPSS软件进行因子分析的步骤:1. 数据筹办起首,需要将原始数据导入SPSS软件中。
可以通过选择“文件”>“打开”>“数据”,然后选择合适的数据文件进行导入。
确保数据是以矩阵的形式存储,每个变量占据一列,每个观察单位占据一行。
2. 因子分析设置在SPSS软件中,选择“分析”>“数据筹办”>“特殊分析”>“因子”。
在弹出的对话框中,选择需要进行因子分析的变量,将它们挪动到“因子”框中。
然后,选择所需的因子提取方法(如主成分分析或因子分析),并指定所需的因子个数。
可以选择默认值,也可以依据实际需求进行调整。
3. 统计输出完成因子分析设置后,点击“确定”按钮开始分析。
SPSS软件将生成一个因子分析结果报告。
报告中将包含因子载荷矩阵、特征值、诠释的方差比例等统计指标。
通过这些指标,可以对变量和因子之间的干系、每个因子的诠释能力进行分析。
4. 结果解读对于因子载荷矩阵,可以依据因子载荷的大小来裁定变量与因子之间的干系。
一般来说,载荷肯定值大于0.3的变量与因子之间具有显著关联。
诠释的方差比例表示每个因子能够诠释变量总方差的比例,一般来说,越大越好。
在解读结果时,需要综合思量因子载荷和诠释的方差比例。
二、聚类分析聚类分析是一种用于数据分类的统计方法。
它依据观测值之间的相似性将数据对象分组到不同的类别中。

IBM SPSS Modeler 实验一、聚类分析在数据挖掘中,聚类分析关注的内容是一些相似的对象按照不同种类的度量构造成的群体。
聚类分析的目标就是在相似的基础上对数据进行分类。
IBM SPSS Modeler提供了多种聚类分析模型,其中主要包括两种聚类分析,K-Mean 聚类分析和Kohonen聚类分析,下面对各种聚类分析实验步骤进行详解。
1、K-Means聚类分析实验首先进行K-Means聚类实验。
(1)启动SPSS Modeler 14.2。
选择“开始”→“程序”→“IBM SPSS Modeler 14.2”→“IBM SPSS Modeler 14.2”,即可启动SPSS Modeler程序,如图1所示。
图1 启动SPSS Modeler程序(2)打开数据文件。
首先选择窗口底部节点选项板中的“源”选项卡,再点击“可变文件”节点,单击工作区的合适位置,即可将“可变文件”的源添加到流中,如图2所示。
右键单击工作区的“可变文件”,选择“编辑”,打开如图3的编辑窗口,其中有许多选项可供选择,此处均选择默认设定。
点击“文件”右侧的“”按钮,弹出文件选择对话框,选择安装路径下“Demos”文件夹中的“DRUG1n”文件,点击“打开”,如图4所示。
单击“应用”,并点击“确定”按钮关闭编辑窗口。
图2 工作区中的“可变文件”节点图3 “可变文件”节点编辑窗口图4 文件选择对话框图5 工作区中的“表”节点(3)借助“表(Table)”节点查看数据。
选中工作区的“DRUG1n”节点,并双击“输出”选项卡中的“表”节点,则“表”节点出现在工作区中,如图5所示。
运行“表”节点(Ctrl+E或者右键运行),可以看到图6中有关病人用药的数据记录。
该数据包含7个字段(序列、年龄(Age)、性别(Sex)、血压(BP)、胆固醇含量(Cholesterol)、钠含量(Na)、钾含量(K)、药类含量(Drug)),共200条信息记录。

spss软件聚类分析案例案例一:选择那些变量进行聚类?——采用“R型聚类”1、现在我们有4个变量用来对啤酒分类,是否有必要将4个变量都纳入作为分类变量呢?热量、钠含量、酒精含量这3个指标是要通过化验员的辛苦努力来测定,而且还有花费不少成本,如果都纳入分析的话,岂不太麻烦太浪费?所以,有必要对4个变量进行降维处理,这里采用spss R型聚类(变量聚类),对4个变量进行降维处理。
输出“相似性矩阵”有助于我们理解降维的过程。
2、4个分类变量量纲各自不同,这一次我们先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,此时,涉及到相关,4个变量可不用标准化处理,将来的相似性矩阵里的数字为相关系数。
若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
只输出“树状图”就可以了,个人觉得冰柱图很复杂,看起来没有树状图清晰明了。
从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。
至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。
(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。
)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
案例二:20中啤酒能分为几类?——采用“Q型聚类”现在开始对20中啤酒进行聚类。
开始不确定应该分为几类,暂时用一个3-5类范围来试探。
Q型聚类要求量纲相同,所以我们需要对数据标准化,这一回用欧式距离平方进行测度。
2、主要通过树状图和冰柱图来理解类别。
最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。
我这里试着确定分为4类。
选择“保存”,则在数据区域内会自动生成聚类结果。
案例三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”1、聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
使用SPSS软件进行因子分析和聚类分析的方法因子分析和聚类分析是一种常用的数据分析方法,可以用于数据降维和分组。
SPSS是一款常用的统计软件,提供了丰富的分析工具和函数,可以方便地进行因子分析和聚类分析。
一、因子分析:因子分析是一种多变量分析方法,可以将一组相关的变量转化为少数几个互相独立的综合变量,称为因子。
因子分析可以用于降低数据的维度,提取主要的因素,并分析因素之间的关系。
以下是使用SPSS软件进行因子分析的步骤:1.打开SPSS软件,并导入要进行因子分析的数据集。
2.菜单栏选择“分析”-“降维”-“因子”。
3.在弹出的因子分析对话框中,选择要进行因子分析的变量,将其添加到“因子”框中。
4.在“提取”选项中,选择提取的因子个数。
可以根据实际需求和经验进行选择。
5. 在“旋转”选项中,选择旋转方法。
常用的旋转方法有方差最大旋转(Varimax),斜交旋转(Oblique)等。
6.点击“确定”按钮,进行因子分析。
7.SPSS会生成因子载荷矩阵、解释方差表、因子得分等结果。
可以根据因子载荷矩阵和解释方差表来解释因子的含义和解释度。
8.根据具体需求和分析目的,可以进行因子得分的计算和因子分组的分析。
二、聚类分析:聚类分析是一种无监督学习方法,可以将一组样本数据自动分成若干互不相交的群组,称为簇。
聚类分析可以用于数据的分组和群体特征的分析。
以下是使用SPSS软件进行聚类分析的步骤:1.打开SPSS软件,并导入要进行聚类分析的数据集。
2.菜单栏选择“分析”-“分类”-“聚类”。
3.在弹出的聚类分析对话框中,选择要进行聚类分析的变量,将其添加到“变量”框中。
可以选择多个变量进行分析。
4.在“距离”选项中,选择计算样本间距离的方法。
常用的方法有欧几里得距离、曼哈顿距离等。
5. 在“聚类方法”选项中,选择聚类算法的方法。
常用的方法有层次聚类(Hierarchical Clustering)、K均值聚类(K-means)等。
聚类分析实验报告SPSS一、实验目的:1.掌握聚类分析的基本原理和方法;2.了解SPSS软件的使用;3.通过实际数据分析,探索样本数据的聚类结构。
二、实验步骤:1.数据预处理:a.收集并导入样本数据;b.对数据进行初步探索和了解,包括数据描述统计、缺失值处理等;2.聚类分析:a.选择合适的变量进行聚类分析;b.选择聚类算法和相似性度量方法;c.进行聚类分析,得到聚类结果;d.检验聚类结果的稳定性和合理性;3.结果解释:a.对聚类结果进行解释和描述,给出每个聚类的特点和含义;b.使用图表展示聚类结果,以便更直观地理解;c.对聚类结果进行验证和评估,如通过交叉验证等方法;4.结论:a.总结分析结果,给出对样本数据的聚类结构的总体认识;b.提出有关样本数据的进一步探索方向和建议。
三、实验结果与分析:1.数据预处理:样本数据包括了多个变量,我们首先对这些变量进行初步的探索和分析,了解它们的分布情况和特点。
同时,对于缺失值的处理,我们采取了删除或插补的方法,以保证后续分析的准确性和完整性。
2.聚类分析:在选择变量时,我们考虑到了变量之间的相关性,以及对聚类结果的解释性。
通过SPSS软件,我们选择了合适的聚类算法和相似性度量方法,进行了聚类分析。
3.结果解释:根据聚类结果,我们将样本数据划分为多个聚类群组。
对于每个聚类群组,我们进行了详细的解释和描述,给出了其特点和含义。
通过图表的展示,我们能更直观地理解每个聚类群组的分布情况和区别。
4.结论:综合分析结果,我们得出了对样本数据聚类结构的总体认识。
同时,我们提出了进一步探索的方向和建议,以获取更多的知识和信息。
四、实验总结:通过这次实验,我们掌握了聚类分析的基本原理和方法,了解了SPSS软件的使用。
通过实际数据的分析,我们能够更深入地理解样本数据的聚类结构,为进一步的研究和应用提供了基础。
在实验过程中,我们也遇到了一些问题和困难,但通过团队合作和专业指导,我们得以顺利完成实验,并取得了较好的结果。
§7.5聚类分析的SPSS实现一、系统聚类法的SPSS实现例7.5.1利用全国30个省市自治区经济发展基本情况的八项指标数据(见数据集wyzb6_5.),用系统聚类法对这30个省市自治区作一初步的分类,并说明各类地区经济发展的特点。
操作分析(Analyze)⇒分类(Classify)⇒系统聚类(Hierarchical Cluster)打开系统聚类分析(Hierarchical Cluster Analysis)对话框1.变量(Variable(s))列表框设置分析变量。
2.标志个案(Label Cases by)框设置分析对象的标志变量。
3.分群(Cluster)单选择框设置聚类分析的类型。
4.输出(Display)复选择框设置聚类分析的输出结果,统计量和图都是默认选项。
5.统计量(Statistics)按钮设置输出的统计量。
合并进程表(Agglomeration schedule)默认选项,输出聚类分析的凝聚状态表;相似性矩阵(Proximitymatrix)为复选项,输出各样品的距离矩阵。
聚类成员(Cluster Menbership)选择框:无(None)选项:不显示类的样品构成;单一方案(Single solution)选项:选择此项,并输入一个确定的分类数n,并输出聚成n个类时各个类的样品构成情况。
方案范围(Range of solutions):选择此项,并输入两个数n1,n2,将显示指定聚成n1类到n2类时各个类的样品构成情况。
6.Plots按钮设置输出图形:树状图冰状图7.Method按钮设置聚类分析的具体方法。
聚类方法:组间连接:类间平均法组内连接:类内平均法最近临元素:最短距离法最远临元素:最长距离法质心聚类法:重心法中位数聚类法:中位数法Ward法:离差平方和法度量方法选择框:选择计算样品距离的方法转换值选择框:选择原始数据标准化的方法Z得分,最常用的方法8.Save按钮设置需要保存的分析结果。
第十讲聚类分析SPSS操作聚类分析是一种数据挖掘的方法,用于将样本数据按照相似性进行分组。
SPSS是一款功能强大的数据分析软件,提供了丰富的聚类分析功能,下面将介绍如何使用SPSS进行聚类分析。
首先,打开SPSS软件,并导入要进行聚类分析的数据文件。
可以通过点击“文件”菜单中的“打开”选项,选择相应的数据文件进行导入,或者直接将数据拖拽到SPSS软件界面上。
导入数据之后,在SPSS软件的数据视图中,可以查看数据的各个变量和观察值(样本)。
接下来,点击“分析”菜单中的“分类”选项,然后选择“聚类”。
在聚类分析对话框中,首先需要选择要进行聚类分析的变量。
可以将所有要分析的变量移动到“变量”列表中,或者点击“添加全部”按钮,将所有变量添加到“变量”列表中。
在聚类分析对话框中,还有一些其他的配置选项,如“距离测度”、“规范化方法”、“分散度”等,可以根据实际需求进行设置。
其中,距离测度指的是计算样本间相似性的方法,常用的有欧几里得距离、曼哈顿距离等;规范化方法用于对变量进行标准化;分散度用于定义聚类的紧密度。
配置好相关选项之后,可以点击“聚类”按钮开始进行聚类分析。
SPSS会根据所选的变量和配置选项,对样本进行聚类,并在输出视图中呈现聚类结果。
聚类分析的输出结果包括聚类分布表、聚类变量表、聚类映射表等。
聚类分布表显示了每个聚类中的样本数量;聚类变量表显示了每个聚类中各个变量的均值;聚类映射表显示了每个观察值所属的聚类。
分析完毕后,可以根据聚类的结果对样本进行分类。
可以基于聚类分布表和聚类映射表,将样本分为不同的类别,并对每个类别进行描述和解释。
此外,可以对每个类别的特点进行进一步的分析,比如对不同类别的平均值进行比较,以了解不同类别之间的差异。
聚类分析还可以进行一些其他的操作,比如对聚类结果进行可视化展示。
可以使用SPSS的图形功能,绘制散点图或热力图,将样本点按照聚类分组进行呈现,以便更直观地了解聚类结果。
§7.5聚类分析的SPSS实现
一、系统聚类法的SPSS实现
例7.5.1利用全国30个省市自治区经济发展基本情况的八项指标数据(见数据集wyzb6_5.),用系统聚类法对这30个省市自治区作一初步的分类,并说明各类地区经济发展的特点。
操作
分析(Analyze)⇒分类(Classify)⇒系统聚类(Hierarchical Cluster)打开系统聚类分析(Hierarchical Cluster Analysis)对话框
1.变量(V ariable(s))列表框设置分析变量。
2.标志个案(Label Cases by)框设置分析对象的标志变量。
3.分群(Cluster)单选择框设置聚类分析的类型。
4.输出(Display)复选择框设置聚类分析的输出结果,统计量和图都是默认选项。
5.统计量(Statistics)按钮设置输出的统计量。
合并进程表(Agglomeration schedule)默认选项,输出聚类分析的凝聚状态表;
相似性矩阵(Proximitymatrix)为复选项,输出各样品的距离矩阵。
聚类成员(Cluster Menbership)选择框:
无(None)选项:不显示类的样品构成;
单一方案(Single solution)选项:选择此项,并输入一个确定的分类数n,并输出聚成n个类时各个类的样品构成
情况。
方案范围(Range of solutions):选择此项,并输入两个数n1,n2,将显示指定聚成n1类到n2类时各个类的样品构成
情况。
6.Plots按钮设置输出图形:树状图冰状图
7.Method按钮设置聚类分析的具体方法。
聚类方法:
组间连接:类间平均法
组内连接:类内平均法
最近临元素:最短距离法
最远临元素:最长距离法
质心聚类法:重心法
中位数聚类法:中位数法
Ward法:离差平方和法
度量方法选择框:选择计算样品距离的方法转换值选择框:选择原始数据标准化的方法Z得分,最常用的方法
8.Save按钮设置需要保存的分析结果。
输出结果的统计分析
凝聚状态表
第1列:步骤号,一共进行了29聚类
第2和3列:表示某步聚类时的哪两个样品或类进行了合并,合并后的类号为第2列的样品或类号
第4列:聚类时的两个样品或类间的距离
第5和6列:表示某步聚类时是样品还是类参与合并
第7列:表示本步所聚成的类,再下面的第几步聚类时用到。
成员表
⏹水平冰柱图
⏹树状图
Dendrogram using Ward Method
Rescaled Distance Cluster Combine
C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+
山西 4 -+
江西 14 -+-+
内蒙 5 -+ +-------+
吉林 7 -+ | |
黑龙江 8 -+-+ |
安徽 12 -+ +---------------+
湖北 17 -+ | |
湖南 18 -+-----+ | |
四川 22 -+ +---+ |
河北 3 -+-+ | +---------------------+ 河南 16 -+ +---+ | | 辽宁 6 ---+ | | 青海 28 -+ | | 宁夏 29 -+-----+ | | 西藏 25 -+ +-------------------+ | 贵州 23 -+ | | 云南 24 -+-----+ | 广西 20 -+ | 陕西 26 -+ | 甘肃 27 -+ | 新疆 30 -+ | 江苏 10 -+-----+ | 山东 15 -+ +-----------------+ | 广东 19 -------+ | | 天津 2 -+---+ +-----------------------+ 海南 21 -+ +---------+ |
浙江 11 -+-+ | | |
福建 13 -+ +-+ +---------+
北京 1 ---+ |
上海 9 ---------------+
结果分析:
二、动态聚类法的SPSS 实现
在SPSS 中,凝聚点的指定不是必须的,系统会自动根据分类数目,结合样品情况来选取凝聚点。
形成初始分类的方法通常有两种,一是直接将每个样品按与其距离最近的凝聚点并类,二是先让每个凝聚点自成一类,将样品依此并入与其距离最近的凝聚点的一类,并计算该类的重心,以这个重心代替原来的凝聚点,再考虑下一个样品的并类,直至所有样品都归类为止。
操作: 分析(Analyze )⇒ 分类(Classify )⇒k-均值聚类(K –Means Cluster )打开k-均值聚类分析(K –Means Cluster Analysis )对话框 变量列表框 :
聚类数(Number of Clusters )输入框 输入指定的聚类数目。
1.迭代(Iterate )按钮 设置快速聚类的迭代终止条件。
2.保存(Save)按钮设置需要保存的分析结果。
3.选项(Options)按钮选择快速聚类的输出结果,并指定对缺失数据的处理方法。
输出结果的统计分析
⏹类间距离表
习题
1土壤样品聚类.sav记录了20个土壤样品的有关指标的数据,5项指标分别是:含沙量X1,淤泥含量X2,粘土含量X3,有机物X4,PH值X5。
利用系统聚类法完成样品分类,选取合适的分类数目,并通过分析各类中所含样品各指标值的统计性质,说明各类土壤的特点。
2森林及草资源.sav记录了世界18个国家的森林及草原资源的分布情况。
共有4项指标,分别是:森林面积X1,森林覆盖率X2,林木蓄积量X3,草原面积X4。
利用快速聚类法完成样品分类,选取合适的分类数目,并通过分析各类中所含样品各指标值的统计性质,说明各类国家的森林及草原资源的分布的情况。