SPSS操作方法:聚类分析
- 格式:doc
- 大小:245.50 KB
- 文档页数:11

第九章SPSS的聚类分析1.引言聚类分析是一种数据分析方法,用于将相似的对象划分到同一组中,同时将不相似的对象划分到不同的组中。
SPSS是一种常用的统计软件,提供了聚类分析的功能。
本章将介绍SPSS中的聚类分析方法及其应用。
2.数据准备在进行聚类分析之前,需要准备好待分析的数据。
数据应该是定量变量或者定性变量,可以包含多个变量。
如果存在缺失值,需要处理之后才能进行聚类分析。
3.SPSS中的聚类分析方法在SPSS中,聚类分析方法有两种:基于距离的聚类和基于密度的聚类。
基于距离的聚类方法将对象划分到不同的组中,使得组内的对象之间的距离最小,组间的对象之间的距离最大。
常见的基于距离的聚类方法包括单链接聚类、完全链接聚类和平均链接聚类。
基于密度的聚类方法则通过考虑对象周围的密度来划分对象所属的组。
在SPSS中,可以使用层次聚类和K均值聚类这两种方法进行聚类分析。
3.1层次聚类层次聚类又称为分级聚类,它将对象分为一个个的层级,直到每个对象都成为一个单独的组为止。
层次聚类分为两种方法:凝聚层次聚类和分化层次聚类。
凝聚层次聚类是从每个对象作为一个单独的组开始,然后根据对象之间的距离逐渐合并组,直到所有的对象都合并到一个组为止。
凝聚层次聚类的最终结果是一个层级的分组结构,可以根据需要确定分组的层数。
分化层次聚类是从所有的对象开始,然后根据对象之间的距离逐渐分离成不同的组,直到每个对象都成为一个单独的组为止。
在SPSS中,可以使用层次聚类方法进行聚类分析。
通过选择合适的距离度量和链接方法,可以得到不同的聚类结果。
3.2K均值聚类K均值聚类是一种基于距离的聚类方法,通过计算对象之间的距离,将对象分为K个组。
K均值聚类的基本思想是:首先随机选择K个对象作为初始的聚类中心,然后将每个对象分配到离它最近的聚类中心,重新计算聚类中心的位置,直到对象不再发生变化为止。
K均值聚类的结果是每个对象所属的聚类,以及聚类的中心。
在SPSS中,可以使用K均值聚类方法进行聚类分析。
六、聚类分析(一)概述1.聚类分析的目的根据已知数据,计算样本或者变量之间亲疏关系的统计量(距离或相关系数)。
根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最初达到的就是将样本或变量分成若干类。
2.聚类分析的分类3.距离与相似性为了对样本或者变量进行分类,就需要研究样本之间的关系,最常用的方法有两个。
(二)系统聚类1.系统聚类的步骤距离的具体定义及计算方式计算n各样本两两之间的距离将距离接近的数据依次合并为一类,再计算,再合并 画聚类图,解释类与类之间的关系2.亲疏程度度量方法3.系统聚类的分类4.SPSS操作及实例SPSS采用的是凝聚法。
案例:根据30个省的23个主要行业的平均工资情况,通过聚类分析来判断哪些地区平均工资水平高。
SPSS操作及结果:打开SPSS上方菜单栏中的分析->分类->系统聚类选择变量->勾选统计量->在绘制里选择树状图和冰柱图勾选方法(通常使用组间联接)->度量区间->选择标准化方式(全距从0到1)下图为近似矩阵表,标注了相关系数,数值越大,距离越接近下图为聚类分析结果表,第一类表示这是聚类分析的第几步,第二三列表示该步中那几个样本或者小类聚成一类,第四列表示距离,第五六列表示本步骤中参与的是个体还是小类(0表示样本,非0表示第n步生成的小类),第七列表示本步骤的聚类结果将在以下第几步中用到。
下面是冰柱图和树状图的结果,根据树状图可以看出,如果分为三类的话,第一类包括北京上海,第二类包括天津、广东、浙江、江苏、西藏,剩下的归为一类。
(三)快速聚类(适合大样本聚类)1.快速聚类的步骤指定聚类数目K确定K个初始类的中心(自定义或者根据数据中心初步确定)根据距离最近的原则进行分类根据新的中心位置,重新计算每一记录距离新的类别中心的的距离,并重新分类重复步骤4,直到达到标准2.SPSS操作及实例打开SPSS上方菜单栏中的分析->分类->K-均值聚类选择变量->勾选统计量->定义变量值选择迭代次数->选项(勾选初始聚类中心、每个个案的聚类信息)->定义变量值->保存(勾选聚类成员、聚类中心距离)下图为输出的初始聚类中心下图为最终距离中心,第一类平均工资最高,第二类次之,第三类最低下图为每个聚类中的案例数和聚类成员。


SPSS聚类分析:用于筛选聚类变量的一套方法聚类分析是常见的数据分析方法之一,主要用于市场细分、用户细分等领域。
利用SPSS进行聚类分析时,用于参与聚类的变量决定了聚类的结果,无关变量有时会引起严重的错分,因此,筛选有效的聚类变量至关重要。
案例数据源:在SPSS自带数据文件plastic.sav中记录了20中塑料的三个特征,分别是tear_res(抗拉力)、gloss(光滑度)、opacity(透明度),相关经验表面这20中塑料可以分为3个种类,如果用这三个变量进行聚类,请判断和筛选有效聚类变量。
一套筛选聚类变量的方法一、盲选将根据经验得到的、现有的备选聚类变量全部纳入模型,暂时不考虑某些变量是否不合适。
本案例采用SPSS系统聚类方法。
对话框如下:统计量选项卡:聚类成员选择单一方案,聚类数输入数字3;绘制选项卡:勾选树状图;方法选项卡:默认选项,不进行标准化;保存选项卡:聚类成员选择单一方案,聚类数输入数字3;二、初步聚类这是盲选得到的初步聚类结果,并且在数据视图我们可以看到已经自动生成了一个聚类结果变量,这个变量非常有用。
三、方差分析是不是每一个纳入模型的聚类变量都对聚类过程有贡献?利用已经生成的初步聚类结果,我们可以用一个单因素方差分析来判断分类结果在三个变量上的差异是否显著,进而判断哪些变量对聚类是没有贡献的。
分析——比较均值——单因素方差分析:选项选项卡:勾选均值图由方差分析我们很明确的得知,纳入模型的三个聚类变量,其中只有“透明度”指标在各个分类上有显著的差异,也就是说分类有效果,让每个分类的差异很大,而两外两个变量则在三个分类上没有显著差异,没有很好的类别区分度,所以,我们可以认为,这两个变量对聚类无作用或者无贡献,可考虑踢出模型。
我们还想从可视化的角度来查看和判断,单因素方差分析为我们提供了均值图,可惜,这三个图却最容易误导我们的判断,因为spss在自动生产均值图时为每一个变量单独制图,而且分配不同的纵轴坐标,导致每个图看起来都有非常大的差异,从视觉上迷惑我们做出错误的判断。

IBM SPSS Modeler 实验一、聚类分析在数据挖掘中,聚类分析关注的内容是一些相似的对象按照不同种类的度量构造成的群体。
聚类分析的目标就是在相似的基础上对数据进行分类。
IBM SPSS Modeler提供了多种聚类分析模型,其中主要包括两种聚类分析,K-Mean 聚类分析和Kohonen聚类分析,下面对各种聚类分析实验步骤进行详解。
1、K-Means聚类分析实验首先进行K-Means聚类实验。
(1)启动SPSS Modeler 14.2。
选择“开始”→“程序”→“IBM SPSS Modeler 14.2”→“IBM SPSS Modeler 14.2”,即可启动SPSS Modeler程序,如图1所示。
图1 启动SPSS Modeler程序(2)打开数据文件。
首先选择窗口底部节点选项板中的“源”选项卡,再点击“可变文件”节点,单击工作区的合适位置,即可将“可变文件”的源添加到流中,如图2所示。
右键单击工作区的“可变文件”,选择“编辑”,打开如图3的编辑窗口,其中有许多选项可供选择,此处均选择默认设定。
点击“文件”右侧的“”按钮,弹出文件选择对话框,选择安装路径下“Demos”文件夹中的“DRUG1n”文件,点击“打开”,如图4所示。
单击“应用”,并点击“确定”按钮关闭编辑窗口。
图2 工作区中的“可变文件”节点图3 “可变文件”节点编辑窗口图4 文件选择对话框图5 工作区中的“表”节点(3)借助“表(Table)”节点查看数据。
选中工作区的“DRUG1n”节点,并双击“输出”选项卡中的“表”节点,则“表”节点出现在工作区中,如图5所示。
运行“表”节点(Ctrl+E或者右键运行),可以看到图6中有关病人用药的数据记录。
该数据包含7个字段(序列、年龄(Age)、性别(Sex)、血压(BP)、胆固醇含量(Cholesterol)、钠含量(Na)、钾含量(K)、药类含量(Drug)),共200条信息记录。


spss聚类分析步骤什么是聚类分析聚类分析是一种通过将相似的样本数据进行分组的方法,以便于研究者可以更好地理解数据中的模式和结构。
在聚类分析中,研究者希望将数据样本划分为若干个互不重叠的群体,每个群体内的样本相似度较高,而不同群体之间的样本相似度较低。
spss的聚类分析功能spss是一种功能强大的统计分析软件,它提供了丰富的数据分析功能。
在spss中,可以使用聚类分析功能来进行数据样本的分组和分类。
聚类分析功能可以帮助研究者发现数据中的模式、规律和群体。
使用spss的聚类分析功能,可以根据变量之间的相似性将样本分成若干个组,从而更好地理解数据。
spss聚类分析步骤以下是使用spss进行聚类分析的基本步骤:1.打开数据文件:首先,需要打开包含要进行聚类分析的数据的spss数据文件。
可以通过点击菜单栏的“文件”选项打开数据文件,或者通过键盘快捷键“Ctrl + O”。
2.转换变量类型:在进行聚类分析之前,需要将数据中的所有变量转换为合适的类型。
例如,如果有一些分类变量,需要将其转换为因子变量。
可以通过点击菜单栏的“数据”选项,然后选择“转换变量类型”来进行变量类型的转换。
3.选择变量:在进行聚类分析之前,需要确定要使用的变量。
可以选择所有的变量,也可以只选择特定的变量。
选择变量可以通过点击菜单栏的“数据”选项,然后选择“选择变量”来进行。
4.进行聚类分析:选择好变量之后,可以进行聚类分析。
可以通过点击菜单栏的“分析”选项,然后选择“聚类”来进行聚类分析。
5.配置聚类分析参数:在进行聚类分析之前,需要配置一些参数。
例如,确定要使用的聚类方法和相似性测度。
可以根据具体的研究目的和数据特点来选择合适的参数。
6.运行聚类分析:配置好参数之后,可以点击“确定”按钮来运行聚类分析。
spss会根据选择的变量和参数,对样本数据进行聚类,并生成相应的结果。
7.分析聚类结果:在进行聚类分析之后,可以对聚类结果进行进一步的分析。


IBM SPSS Modeler 实验一、聚类分析在数据挖掘中,聚类分析关注的内容是一些相似的对象按照不同种类的度量构造成的群体。
聚类分析的目标就是在相似的基础上对数据进行分类。
IBM SPSS Modeler提供了多种聚类分析模型,其中主要包括两种聚类分析,K-Mean 聚类分析和Kohonen聚类分析,下面对各种聚类分析实验步骤进行详解。
1、K-Means聚类分析实验首先进行K-Means聚类实验。
(1)启动SPSS Modeler 14.2。
选择“开始”→“程序”→“IBM SPSS Modeler 14.2”→“IBM SPSS Modeler 14.2”,即可启动SPSS Modeler程序,如图1所示。
图1 启动SPSS Modeler程序(2)打开数据文件。
首先选择窗口底部节点选项板中的“源”选项卡,再点击“可变文件”节点,单击工作区的合适位置,即可将“可变文件”的源添加到流中,如图2所示。
右键单击工作区的“可变文件”,选择“编辑”,打开如图3的编辑窗口,其中有许多选项可供选择,此处均选择默认设定。
点击“文件”右侧的“”按钮,弹出文件选择对话框,选择安装路径下“Demos”文件夹中的“DRUG1n”文件,点击“打开”,如图4所示。
单击“应用”,并点击“确定”按钮关闭编辑窗口。
图2 工作区中的“可变文件”节点图3 “可变文件”节点编辑窗口图4 文件选择对话框图5 工作区中的“表”节点(3)借助“表(Table)”节点查看数据。
选中工作区的“DRUG1n”节点,并双击“输出”选项卡中的“表”节点,则“表”节点出现在工作区中,如图5所示。
运行“表”节点(Ctrl+E或者右键运行),可以看到图6中有关病人用药的数据记录。
该数据包含7个字段(序列、年龄(Age)、性别(Sex)、血压(BP)、胆固醇含量(Cholesterol)、钠含量(Na)、钾含量(K)、药类含量(Drug)),共200条信息记录。
1.1 系统聚类本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。
1.1.1 最短距离聚类法最短距离法聚类步骤如下:1.规定样本间的距离,计算样本两两之间的距离,得到对称矩阵。
开始每个样品自成一类。
2.选择对称矩阵中的最小非零元素。
将两个样品之间最小距离记为D1,将这两个样品归并成为一类,记为G1。
3.计算G1与其他样品距离。
重复以上过程直到所有样品合并为一类。
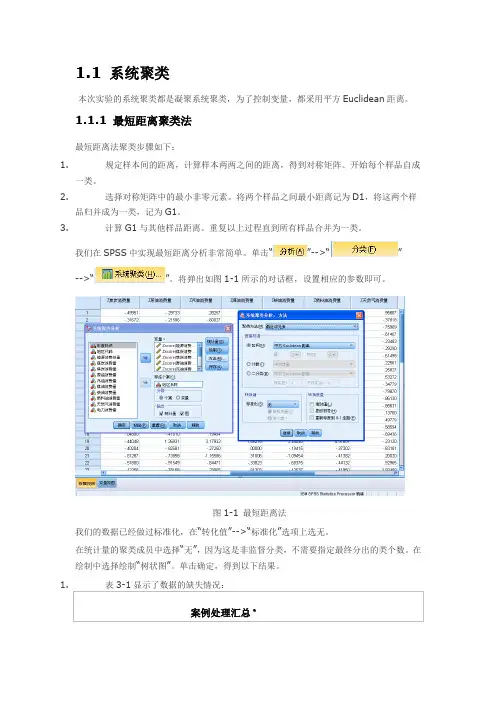
我们在SPSS中实现最短距离分析非常简单。
单击“”-->“”-->“”。
将弹出如图1-1所示的对话框,设置相应的参数即可。
图1-1 最短距离法我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。
在绘制中选择绘制“树状图”。
单击确定,得到以下结果。
聚类表阶群集组合系数首次出现阶群集下一阶群集1 群集 2 群集 1 群集 21 21 28 .211 0 0 102 12 24 .465 0 0 63 2 27 .491 0 0 54 13 20 .585 0 0 95 2 14 .645 3 0 66 2 12 .678 5 2 77 2 7 .702 6 0 88 2 25 .773 7 0 99 2 13 .916 8 4 1110 21 29 1.085 1 0 1211 2 18 1.106 9 0 12表1-2 聚类过程我们可以通过更加形象直观的树状图来观察整个聚类过程和聚类效果。
如图1-2所示,最短距离法组内距离小,但组间距离也较小。
分类特征不够明显,无法凸显各个省份的能源消耗的特点。
但是我们可以看到广东省能源消耗组成和其他省份特别不同,在其他方法中也显现出来。
12 2 21 1.115 11 10 13 13 2 17 1.360 12 0 14 14 2 26 1.564 13 0 15 15 2 22 1.627 14 0 16 16 2 5 1.649 15 0 17 17 2 8 1.877 16 0 18 18 2 16 3.027 17 0 19 19 2 30 3.543 18 0 20 20 2 11 4.930 19 0 21 21 2 4 5.024 20 0 22 22 2 10 6.445 21 0 24 23 1 9 8.262 0 0 26 24 2 15 10.093 22 0 25 25 2 23 10.096 24 0 26 26 1 2 10.189 23 25 27 27 1 6 11.387 26 0 28 28 1 3 13.153 27 0 29 2911932.36728图1-2 最短距离法聚类图1.1.2 组间联接聚类组间联接聚类法定义为两类之间的平均平方距离,即。
聚类分析为了研究全国各地的城镇家庭收支的分布规律,共抽取28个省、市、自治区的农民生活消费支出的6个有关指标的数据资料。
用表中的数据做谱系聚类,画出谱系图,确定消费支出类型。
地区食品支出住房支出衣着支出其他支出北京190 43 60 49天津135 36 44 36河北95 22 22 22山西104 25 9 18内蒙128 27 12 23辽宁145 32 27 39吉林159 33 11 25黑龙江116 29 13 21上海221 38 115 50江苏144 29 42 27浙江169 32 47 34安徽153 23 23 18福建144 21 19 21江西140 21 19 15山东115 30 33 33河南101 23 20 20湖北140 28 18 20湖南164 24 22 18广东182 20 42 36江西139 18 13 20四川137 20 17 16贵州121 21 14 12云南124 19 14 15陕西106 20 10 18甘肃95 16 6 12青海107 16 5 8宁夏113 24 9 22新疆123 38 4 17【结果与分析】一、欧氏距离平方、组间平均距离连接法Case Processing Summary(a)CasesValid Missing Total N Percent N Percent N Percent28 100.0 0 .0 28 100.0a Average Linkage (Between Groups)上表表示进行聚类分析的有效样品是28个,无缺失值。
Agglomeration ScheduleStageCluster CombinedCoefficientsStage Cluster FirstAppearsNext Stage Cluster 1 Cluster 2 Cluster 1 Cluster 21 14 21 15.000 0 0 62 22 23 22.000 0 0 123 4 24 30.000 0 0 104 3 16 45.000 0 0 155 8 27 51.000 0 0 106 14 20 55.500 1 0 87 13 17 67.000 0 0 88 13 14 82.167 7 6 169 12 18 123.000 0 0 1410 4 8 141.000 3 5 1511 25 26 161.000 0 0 1812 5 22 179.000 0 2 1613 2 10 215.000 0 0 1914 7 12 302.500 0 9 2215 3 4 310.750 4 10 1816 5 13 333.600 12 8 2017 11 19 342.000 0 0 2318 3 25 386.000 15 11 2519 2 6 396.500 13 0 2120 5 28 617.250 16 0 2221 2 15 833.667 19 0 2422 5 7 915.222 20 14 2423 1 11 1021.000 0 17 2624 2 5 1225.875 21 22 2525 2 3 1757.844 24 18 2626 1 2 5112.264 23 25 2727 1 9 18396.630 26 0 0上表表示聚类过程,从中可知,聚类共进行27步;第一步首先合并距离最近的14号和21号样品,形成类G1;因为next stage=6,所以在第6步G1和20号进行复聚类,因此,在Stage Cluster First Appears里列的Cluster 1=1,Cluster 2=0;第二步,合并22号和23号样品,形成类G2;因为next stage=12,所以在第12步,G2和第5号样品进行复聚类,且Cluster 1=0,Cluster 2=2;第一次出现类类的合并在第8步,Cluster 1=7,Cluster 2=6,表示第7步和第6步合并形成的类在第8步合并;其余的类似,不再详细叙述。
实验指导之一聚类分析的SPSS操作方法系统聚类法实验例城镇居民消费水平通常用下表中的八项指标来描述。
八项指标间存在一定的线性相关。
为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。
实验数据表 2001年30个省。
市,自治区城镇居民月平均消费数据x1人均粮食支出(元/人) x5人均衣着商品支出(元/人)x2人均副食支出(元/人) x6人均日用品支出(元/人)x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人)x4人均其他副食支出(元/人) x8人均非商品支出(元/人)x1x2x3x4x5x6x7x8北京天津河北山西内蒙古辽宁吉林黑龙江上海江苏浙江安徽福建江西山东河南湖北湖南13.23广东广西海南四川贵州云南西藏陕西甘肃青海宁夏新疆系统聚类法的SPSS操作:1. 从数据编辑窗口点击Analyze →Classify →Hierachical Cluster , (见图1)图1 系统聚类法打开层次聚类法对话如图2。
图2 系统聚类法对话框选择需要进行聚类分析的变量进入Variable框内后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法:Cases 对样品聚类(Q型;系统默认),Variable 对指标变量聚类(R型),本例选择。
在Display栏中选择默认的输出项。
2. 点击Statistics按钮,打开对话框如图3.图3 Statistics对话框Agglomeration schedule输出凝聚状态表(聚类进度表);本例选择。
Ploximity matrix 输出个体间的距离矩阵,本例选择。
Cluster Membership栏中显示每个观测量被分派到的类。
None 不输出。
本例选择。
Simple solution 指定分类数,并输出样本所属类,单一解。
Renge of solution 指定输出从m到n类的各样本所属类。
多个解。
选好后返回主对话框。
3. 单击Method按钮,打开对话框如图4-1.Cluster Method:选择聚类方法:SPSS中提供7种聚类方法,分别是:类间平均,类内平均,最短距离,最长距离,重心法,中值法,最小平方和法。
本例选择类间平均。
Measure栏:对距离的测度方法选择SPSS中提供了三种类型:Interval等间距度量的变量(连续型), Counts 计数型变量(离散型)和Binary二值变量。
Interval等间隔测度的变量方法包括:Euclidean distance欧氏距离;Squared Euclidean distance欧氏平方距离;Cosine夹角余弦(R 型聚类);Pearson Correlation皮尔逊相关系数距离(R 型聚类),本例选择此项。
Chebychev契比雪夫距离;block距离;Minkowski明氏距离;Customized用户自定义距离--即变量绝对值的第p 次幂之和的第r 次根。
p与r 由用户指定。
图4-1 Method对话框Transform Values栏,选择消除数量级差的方法(见图4-2),依次是:None不作处理(系统默认);本例选择此项。
Z scores标准化处理;Range -1 to 1 各变量值除全距;Range 0 to 1各变量值减最小值后除全距;Maximum magnitude of 1各变量值除最大值;Mean of 1各变量值除以均值;Standard deviation of 1各变量值除以标准差。
图4-2 Method对话框4. 单击Plots按钮,打开对话框如图5.图5 Plots对话框Dendrogram 表示输出树形图,本例选择此项。
Icicle表示输出冰柱图。
其中,All clusters表示输出聚类分析每个阶段的冰柱图;本例选择此项。
Specified range of cluster 表示只输出某个阶段的冰柱图,输入从第几步开始到第几步结束,中间间隔几步。
Orientationk 栏中指定如何显示冰挂图:Vertical纵向显示,本例选择此项。
Horizontal 横向显示。
图6 Save New Variables对话框5. 单击Save按钮,打开Save New Variables对话框,如图6所示。
选择是否将聚类的结果以变量形式保存在数据文件中。
变量名为:clun_m,其中n表示类数,m表示第m次分析。
Cluster Membership栏None 不输出Simple solution 指定分类数,并输出样本所属类。
单一变量。
Renge of solution 指定输出从m到n类的各样本所属类。
多个变量。
当选择结束后,在主对话框中点击OK,可得下面的输出表和图。
Proximity Matrix两两变量间距离矩阵(相关系数矩阵)Average Linkage (Between Groups) 类间平均凝聚状态进度表:第一列(Stage)表示聚类的进度顺序;第二、三列(Cluster combine)表示每一步将哪两类合并;第四列(Cofficients)表示被合并的两类之间的距离;第五、六列(Stage Cluster First Appares)表示被合并的两类上一次合并分别是在哪一步形成的。
0表示被合并的类为单个样品。
最后一列(Next Stage)表示每一步形成的新类将在哪一步参与下一次合并。
Vertical Icicle 冰柱图Number of clustersCase人均衣着商品支出(元/人)人均其他副食支出(元/人)人均烟、酒、茶支出(元/人)人均燃料支出(元/人)人均日用品支出(元/人)人均非商品支出(元/人)人均副食支出(元/人)人均粮食支出(元/人)1X X X X X X X X X X X X X X X 2X X X X X X X X X X X X X X 3X X X X X X X X X X X X X 4X X X X X X X X X X X X 5X X X X X X X X X X X 6X X X X X X X X X X 7X X X X X X X X XDendrogram表示输出树形图(谱分析图)* * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * *Dendrogram using Average Linkage (Between Groups类间平均)Rescaled Distance Cluster CombineC A S E 0 5 10 15 20 25Label Num +---------+---------+---------+---------+---------+X2 2X8 8X6 6X7 7X1 1X4 4X5 5X3 3二: K-聚类法的具体操作以例为例,说明快速聚类法的操作过程。
1. 在数据窗口单击Analyze→Classify→K-Mean Cluster打开对话框(见图7)图7 K-Means Cluster Analysis 对话框将变量选入Variables 栏;将标识变量选入 Label Cases 栏(可省略)将分类数输入Number of 框(系统默认为2),本例中选择4.Method 栏聚类方法栏Iterate and classify (按K-means 算法)叠代分类(系统默认)。
Classify only 仅按初始类别中心点分类(不叠代)。
Centers类中心数据的输入与输出(可省略)Read initial from 使用指定数据文件中的数据作为初始类中心(文件格式参考Write final as 文件格式)选择Write final as 把聚类结果中的各类中心数据保存到指定的文件。
本例中选择系统默认项。
2. 单击Iterate按钮,打开Iterate对话框如图8所示:Maximum Iterations 限定K-Means 算法的迭代次数,系统默认值10Convergence Criterion-指定限定收敛标准,系统默认值为0 。
Use running means 限定在每个观测量被分配到一类后即刻计算新的类中心,不选此项表示只有当全部样本的类分配完后再计算类中心,可以节省运算时间,所以一般情况下不选择此项。
本例中选择默认项。
图8 Iterate对话框3. 单出Save按钮,打开Save对话框见图9.Cluster Member 在原数据文件中保存分类结果(本例选择)。
Distance from cluster center在原数据文件中保存各观测量距所属类中心间的欧氏距离。
图9 Save对话框4. 单击Options 按钮,打开Options对话框见图10。
Statistics栏Initial cluster centers 输出初始类中心。
ANOVA table 输出方差分析表Cluster information for each case每个观测量的分类信息(分类结果和该观测量距所属类中心的距离等)图10 Options对话框Missing Values 栏Exclude cases listwise 将出现在Variables 变量表中变量带有缺失值得观测量从分析中剔除(系统默认)Exclude cases pairwise 只有当一个观测量的全部聚类变量值均缺失时才将其从分析中剔除,否则根据所有其他非缺失变量值把它分配到最近的一类中去。
全部选择完成后得到输出结果。
Initial Cluster Centers初始类中心Cluster1234x1 人均粮食支出(元/人)x2 人均副食支出(元/人)x3 人均烟、酒、饮料支出(元/人)x4 人均其他副食支出(元/人)x5 人均衣着支出(元/人)x6 人均日用杂品支出(元/人)x7 人均水电燃料支出(元/人)x8 人均其他非商品支出(元/人)Cluster Membership(聚类结果)聚类结果中的第四列显示的是各样本与其所属类的中心之间的距离。
上述结果可通过“save”按钮设置,保存至原始数据文件中。
ANOVA方差分析表由输出结果知,8个变量指标中除了第一个变量外,其它指标对分类的贡献是显著的。
Distances between Final Cluster Centers最终各类中心之间的距离矩阵Cluster12341234Number of Cases in each Cluster最终每类的样品个数。