第九章SPSS的聚类案例
- 格式:ppt
- 大小:274.00 KB
- 文档页数:41


第九章SPSS的聚类分析1.引言聚类分析是一种数据分析方法,用于将相似的对象划分到同一组中,同时将不相似的对象划分到不同的组中。
SPSS是一种常用的统计软件,提供了聚类分析的功能。
本章将介绍SPSS中的聚类分析方法及其应用。
2.数据准备在进行聚类分析之前,需要准备好待分析的数据。
数据应该是定量变量或者定性变量,可以包含多个变量。
如果存在缺失值,需要处理之后才能进行聚类分析。
3.SPSS中的聚类分析方法在SPSS中,聚类分析方法有两种:基于距离的聚类和基于密度的聚类。
基于距离的聚类方法将对象划分到不同的组中,使得组内的对象之间的距离最小,组间的对象之间的距离最大。
常见的基于距离的聚类方法包括单链接聚类、完全链接聚类和平均链接聚类。
基于密度的聚类方法则通过考虑对象周围的密度来划分对象所属的组。
在SPSS中,可以使用层次聚类和K均值聚类这两种方法进行聚类分析。
3.1层次聚类层次聚类又称为分级聚类,它将对象分为一个个的层级,直到每个对象都成为一个单独的组为止。
层次聚类分为两种方法:凝聚层次聚类和分化层次聚类。
凝聚层次聚类是从每个对象作为一个单独的组开始,然后根据对象之间的距离逐渐合并组,直到所有的对象都合并到一个组为止。
凝聚层次聚类的最终结果是一个层级的分组结构,可以根据需要确定分组的层数。
分化层次聚类是从所有的对象开始,然后根据对象之间的距离逐渐分离成不同的组,直到每个对象都成为一个单独的组为止。
在SPSS中,可以使用层次聚类方法进行聚类分析。
通过选择合适的距离度量和链接方法,可以得到不同的聚类结果。
3.2K均值聚类K均值聚类是一种基于距离的聚类方法,通过计算对象之间的距离,将对象分为K个组。
K均值聚类的基本思想是:首先随机选择K个对象作为初始的聚类中心,然后将每个对象分配到离它最近的聚类中心,重新计算聚类中心的位置,直到对象不再发生变化为止。
K均值聚类的结果是每个对象所属的聚类,以及聚类的中心。
在SPSS中,可以使用K均值聚类方法进行聚类分析。
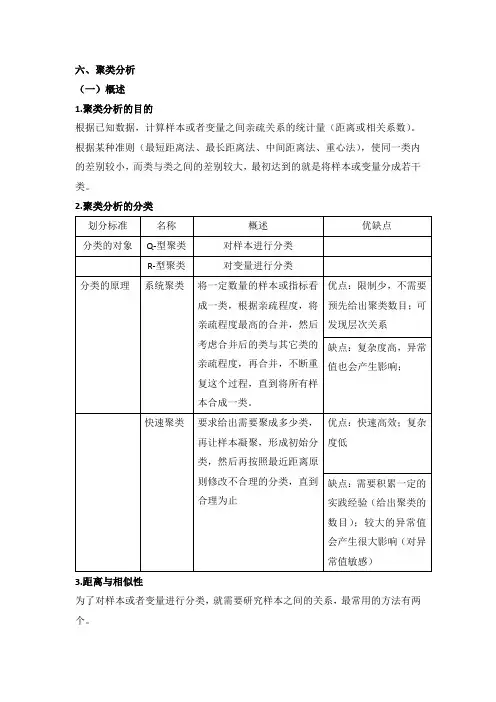
六、聚类分析(一)概述1.聚类分析的目的根据已知数据,计算样本或者变量之间亲疏关系的统计量(距离或相关系数)。
根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最初达到的就是将样本或变量分成若干类。
2.聚类分析的分类3.距离与相似性为了对样本或者变量进行分类,就需要研究样本之间的关系,最常用的方法有两个。
(二)系统聚类1.系统聚类的步骤距离的具体定义及计算方式计算n各样本两两之间的距离将距离接近的数据依次合并为一类,再计算,再合并 画聚类图,解释类与类之间的关系2.亲疏程度度量方法3.系统聚类的分类4.SPSS操作及实例SPSS采用的是凝聚法。
案例:根据30个省的23个主要行业的平均工资情况,通过聚类分析来判断哪些地区平均工资水平高。
SPSS操作及结果:打开SPSS上方菜单栏中的分析->分类->系统聚类选择变量->勾选统计量->在绘制里选择树状图和冰柱图勾选方法(通常使用组间联接)->度量区间->选择标准化方式(全距从0到1)下图为近似矩阵表,标注了相关系数,数值越大,距离越接近下图为聚类分析结果表,第一类表示这是聚类分析的第几步,第二三列表示该步中那几个样本或者小类聚成一类,第四列表示距离,第五六列表示本步骤中参与的是个体还是小类(0表示样本,非0表示第n步生成的小类),第七列表示本步骤的聚类结果将在以下第几步中用到。
下面是冰柱图和树状图的结果,根据树状图可以看出,如果分为三类的话,第一类包括北京上海,第二类包括天津、广东、浙江、江苏、西藏,剩下的归为一类。
(三)快速聚类(适合大样本聚类)1.快速聚类的步骤指定聚类数目K确定K个初始类的中心(自定义或者根据数据中心初步确定)根据距离最近的原则进行分类根据新的中心位置,重新计算每一记录距离新的类别中心的的距离,并重新分类重复步骤4,直到达到标准2.SPSS操作及实例打开SPSS上方菜单栏中的分析->分类->K-均值聚类选择变量->勾选统计量->定义变量值选择迭代次数->选项(勾选初始聚类中心、每个个案的聚类信息)->定义变量值->保存(勾选聚类成员、聚类中心距离)下图为输出的初始聚类中心下图为最终距离中心,第一类平均工资最高,第二类次之,第三类最低下图为每个聚类中的案例数和聚类成员。


SPSS聚类分析实例讲解SPSS是一款功能强大的统计分析软件,可用于数据清洗、描述统计分析、假设检验和聚类分析等。
聚类分析是一种无监督学习方法,其目标是按照数据的相似性度量,将样本数据划分为多个不同的群组。
下面将以一个实例来讲解如何使用SPSS进行聚类分析。
实例描述:假设有一个超市的销售数据,包含了不同商品的销售额、销售量和利润等信息。
我们希望将商品进行聚类分析,找出相似销售特征的商品群组。
步骤一:数据准备首先,将销售数据保存为一个.SP文件,然后打开SPSS软件。
在主界面上选择“文件”-“打开”-“数据库”-“从SPSS文件”,打开数据文件。
步骤二:变量选择在数据文件中,选择出要进行聚类分析的变量。
在“数据视图”中,选择那些代表销售特征的变量,例如“销售额”、“销售量”和“利润”。
在变量列上按住“Ctrl”键,同时点击这些变量名,选中它们。
步骤三:聚类分析点击菜单上的“数据”-“服务”-“聚类分析”进行聚类分析操作。
会弹出“聚类分析”对话框。
在对话框中,将选中的变量移到右侧的“变量”框中,并选择“K均值聚类”作为聚类方法。
K值是指要分成的群组数量,可以根据实际情况设定。
这里假设将商品分成3个群组,因此设置为3步骤四:聚类结果解读点击“确定”按钮,SPSS将自动进行聚类分析。
完成后,SPSS会在数据文件中生成一个新的变量,用于表示每个样本所属的群组。
在下方的“结果视图”中,可以看到聚类结果的统计数据、聚类中心和变量间的距离。
此外,在“分类变量资料”中,还可以看到每个样本所属的群组编号。
步骤五:聚类结果可视化为了更好地理解聚类结果,可以进行可视化展示。
点击菜单上的“图形”-“散点图”,在对话框中依次选择所属群组变量和销售额、销售量这两个变量。
点击“确定”按钮,即可生成散点图。
散点图可以清楚地显示出不同群组之间的差异和相似性。
根据散点图,可以对聚类结果进行解读。
例如,如果不同群组之间的点比较分散,则说明聚类效果较差;而如果不同群组之间的点比较集中,则说明聚类效果较好。

spss聚类分析案例SPSS聚类分析案例。
在统计学中,聚类分析是一种常用的数据分析方法,它可以将数据集中的个体或变量进行分组,使得同一组内的个体或变量之间的相似度较高,而不同组之间的相似度较低。
聚类分析在市场分析、社会学调查、医学研究等领域有着广泛的应用。
而SPSS作为一款专业的统计分析软件,提供了丰富的聚类分析功能,能够帮助研究者对数据进行深入的分析和挖掘。
在本案例中,我们将以一个实际的数据集为例,介绍SPSS中如何进行聚类分析,并对分析结果进行解读和讨论。
首先,我们需要加载数据集,然后选择合适的变量进行聚类分析。
在选择变量时,需要考虑变量之间的相关性,避免出现多重共线性的情况。
在本案例中,我们选择了A、B、C三个变量进行聚类分析。
接下来,我们需要进行聚类分析的设置。
在SPSS软件中,可以选择不同的聚类算法和距离度量方法,以及设置聚类的个数。
在本案例中,我们选择了K均值聚类算法,并设置聚类的个数为3。
同时,我们还可以对聚类结果进行验证和评价,以确保聚类结果的准确性和稳定性。
在进行聚类分析后,我们需要对聚类结果进行解读和讨论。
首先,我们可以通过聚类中心和聚类图表来直观地展示不同组之间的差异和相似度。
然后,我们可以对每一组的特征进行分析,找出不同组之间的显著性差异和共性特征。
最后,我们可以将聚类结果与实际情况进行比较,验证聚类结果的有效性和可解释性。
通过本案例的介绍,相信读者对SPSS中的聚类分析方法有了更深入的了解。
在实际应用中,聚类分析可以帮助研究者发现数据中潜在的规律和结构,为决策提供科学依据。
同时,SPSS作为一款功能强大的统计分析软件,为用户提供了丰富的数据分析工具和可视化功能,能够满足不同领域的研究需求。
总之,聚类分析是一种重要的数据分析方法,能够帮助研究者理解数据的内在结构和规律。
而SPSS作为一款专业的统计分析软件,为用户提供了便捷的聚类分析工具,能够帮助用户快速准确地进行数据分析和挖掘。


第九章SPSS的聚类分析聚类分析是一种将相似个体或对象归类到同一组中的统计方法,它通过测量个体或对象之间的相似性或距离来确定聚类的结构。
聚类分析在许多领域中都有广泛的应用,如市场分析、社会科学研究和生物学等。
在SPSS中进行聚类分析可以帮助研究人员和分析师更好地理解数据的结构和模式。
SPSS的聚类分析功能位于“分析”菜单下的“分类”子菜单中。
在打开聚类分析对话框后,用户需要选择聚类变量,并可以设置合适的聚类方法和距离度量。
可以使用的聚类方法包括层次聚类和K均值聚类,常用的距离度量有欧氏距离和曼哈顿距离等。
此外,用户还可以选择是否进行标准化处理和设置聚类数目等。
在进行聚类分析之前,用户需要对变量进行适当的数据准备工作,如缺失值处理、异常值处理和变量转换等。
这些数据准备步骤可以在“转换”菜单中的相应功能中完成。
对于聚类分析的结果,SPSS提供了多种显示和解释的方法。
在聚类过程完成后,SPSS会自动生成聚类结果的总结报告,该报告包含了关于聚类数目和每个聚类的统计信息。
用户可以通过“聚类概括”选项卡中的预览按钮查看聚类结果的总结报告。
此外,用户还可以通过“数量聚类输出”选项卡中的可视化按钮来生成聚类结果的可视化图形,如散点图和聚类树等。
在解释聚类分析的结果时,用户应该关注聚类数目和每个聚类的特征。
聚类数目可以根据数据的结构和目标进行选择,一般来说,聚类数目越多,聚类结果更详细,但也更复杂。
每个聚类的特征指的是在该聚类中具有相似特征的个体或对象。
用户可以通过查看每个聚类的平均值和标准差来得到关于每个聚类的特征。
总之,在SPSS中进行聚类分析可以帮助研究人员和分析师更好地理解数据的结构和模式。
通过选择合适的聚类变量、聚类方法和距离度量,以及适当的数据准备和结果解释,用户可以得到有关数据聚类结构的有用信息。


spss软件聚类分析案例案例一:选择那些变量进行聚类?——采用“R型聚类”1、现在我们有4个变量用来对啤酒分类,是否有必要将4个变量都纳入作为分类变量呢?热量、钠含量、酒精含量这3个指标是要通过化验员的辛苦努力来测定,而且还有花费不少成本,如果都纳入分析的话,岂不太麻烦太浪费?所以,有必要对4个变量进行降维处理,这里采用spss R型聚类(变量聚类),对4个变量进行降维处理。
输出“相似性矩阵”有助于我们理解降维的过程。
2、4个分类变量量纲各自不同,这一次我们先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,此时,涉及到相关,4个变量可不用标准化处理,将来的相似性矩阵里的数字为相关系数。
若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
只输出“树状图”就可以了,个人觉得冰柱图很复杂,看起来没有树状图清晰明了。
从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。
至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。
(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。
)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
案例二:20中啤酒能分为几类?——采用“Q型聚类”现在开始对20中啤酒进行聚类。
开始不确定应该分为几类,暂时用一个3-5类范围来试探。
Q型聚类要求量纲相同,所以我们需要对数据标准化,这一回用欧式距离平方进行测度。
2、主要通过树状图和冰柱图来理解类别。
最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。
我这里试着确定分为4类。
选择“保存”,则在数据区域内会自动生成聚类结果。
案例三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”1、聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
![9.1.3 分层聚类的应用举例_例说SPSS统计分析_[共7页]](https://uimg.taocdn.com/1808c55571fe910ef02df83d.webp)
9.1.3 分层聚类的应用举例表9-2 2006年各地区交通事故情况表地区发生数(起)死亡人数(人)受伤人数(人)损失折款(万元)地区发生数(起)死亡人数(人)受伤人数(人)损失折款(万元)北京 5 808 1 373 6 681 2 772 湖北9 590 2 304 11 976 4 750天津 4 913 878 5 865 3 319.2湖南12 202 3 563 16 493 5 745.5河北8 631 3 486 9 580 5 846 广东56 2178 828 67 637 16 384.9山西10 981 3 413 12 340 5 422.9广西8 895 3 016 11 337 2 803.6内蒙古 6 481 1 874 7 058 1 879.3海南 1 398427 1 960 603.1 …… …… …… …… …… ……………… …… …… 福建21 924 3 871 25 097 8 742.3青海939 662 1199 374.8 江西8 867 2 190 10 079 6 073.1宁夏 2 985666 3 434 748山东30 056 6 309 28 945 9 511.2新疆7 428 2 608 8 848 1 662.8河南18 402 4 046 19 193 6 849.2数据来源:中国发展门户网。
根据表9-2建立数据文件“2006年各地区交通事故情况.sav”,因聚类变量的数量级别不同,应先对其做标准化处理,即执行〖Analyze〗/〖Descriptives Statistics〗/〖Descriptives〗命令,打开“Descriptives”(描述性统计分析)对话框,如图9-2所示。
从左侧的变量列表框里选择变量“发生数”、“死亡人数”、“受伤人数”和“损失折款”,单击右向箭头按钮,将其移到“Variable(s)”(变量框)中;勾选“Savestandardized values as variables”对聚类变量进行标准化处理;单击“OK”按钮。
第九章作业问题:P235 9-4数据方法:聚类分析Q型聚类计算步骤:1.在“分析”菜单中的“分类”子菜单中选择“系统聚类”命令。
2.在“系统聚类”对话框中,从左侧变量列表中选择“tear_res,gloss,opacity”变量添加到因变量列表,“品种” 变量添加到标注个案列表。
3.在“绘制”中选择树形图,“统计量”中选择单一方案聚类数填3。
3.点击“OK”按钮。
结果及结论:表格 1 个案统计表格1说明20个样本都进入了聚类分析。
表格 2 聚类表阶数群集组合系数首次出现阶群集下一阶群集 1 群集 2 群集 1 群集 21 3 11 .100 0 0 42 5 16 .350 0 0 103 12 14 .360 0 0 114 3 7 .390 1 0 115 6 18 .590 0 0 146 1 9 .750 0 0 107 15 19 .980 0 0 128 2 10 1.100 0 0 99 2 8 1.320 8 0 1410 1 5 1.615 6 2 1311 3 12 1.927 4 3 1612 4 15 2.030 0 7 1513 1 17 2.315 10 0 1714 2 6 2.355 9 5 1515 2 4 3.087 14 12 1616 2 3 4.816 15 11 1817 1 13 6.706 13 0 1818 1 2 16.094 17 16 0表格2是各样本的距离矩阵,第一行表示先将第3份样本和第12份样本聚类,样本间距离为0.100,其他行以此类推。
表格 3 群集成员案例:成员 3 群集1: 2 12: 3 23: 4 24: 5 25: 6 16: 7 27: 8 28: 9 29: 10 110: 11 211: 12 212: 13 213: 14 314: 15 215: 16 216: 17 117: 18 118: 19 219: 20 2表格3说明样本2,6,10,17,18属于第一类,样本3,4,5,7,8,9,11,12,13,15,16,19,20属于第二类,样本14属于第三类。
spss聚类分析案例在进行SPSS聚类分析时,我们通常会遵循一系列步骤来确保分析的准确性和有效性。
以下是一个典型的聚类分析案例,展示了如何使用SPSS软件进行数据分析。
首先,我们需要收集数据。
数据可以是定量的,也可以是定性的,但必须与研究问题相关。
例如,如果我们正在研究消费者购买行为,我们可能会收集关于消费者年龄、收入、购买频率和偏好的数据。
接下来,我们将数据导入SPSS。
这可以通过直接输入数据、从Excel文件导入或使用SPSS的数据导入向导来完成。
一旦数据在SPSS中,我们需要检查数据的准确性和完整性,确保没有缺失值或异常值。
在进行聚类分析之前,我们通常需要对数据进行预处理。
这可能包括标准化变量、处理缺失值和异常值,以及可能的变量转换。
标准化是重要的,因为它确保了所有变量在聚类分析中具有相同的权重。
然后,我们选择聚类方法。
SPSS提供了几种聚类方法,包括K-means聚类、层次聚类和双向聚类。
选择哪种方法取决于数据的特性和研究目的。
例如,如果我们有明确的类别数量,K-means聚类可能是合适的;如果我们希望看到数据的层次结构,层次聚类可能更合适。
在选择了聚类方法后,我们需要确定聚类的数量。
这可以通过多种方法来确定,包括肘部方法、轮廓系数或基于信息准则的方法。
确定聚类数量后,我们可以运行聚类算法,并将数据点分配到不同的聚类中。
聚类完成后,我们需要评估聚类的质量。
这可以通过查看聚类的内部一致性和聚类之间的差异来完成。
我们还可以进行统计测试,如ANOVA或卡方检验,来检验聚类是否在统计上显著。
最后,我们解释聚类结果。
这包括识别每个聚类的特征,以及这些特征如何与研究问题相关。
例如,如果我们发现一个聚类主要由高收入、频繁购买的消费者组成,这可能表明这是一个高价值的市场细分。
在整个聚类分析过程中,我们可能会进行多次迭代,调整聚类方法、聚类数量或数据预处理步骤,以获得最佳的聚类结果。
聚类分析是一个动态的过程,需要根据数据和研究目的进行调整。