Linpack的安装测试与优化
- 格式:ppt
- 大小:181.50 KB
- 文档页数:44

hpl算法流程HPL算法流程概述HPL(High Performance Linpack)是一种用于评估计算机性能的基准测试程序,它是由美国劳伦斯伯克利国家实验室开发的。
该程序主要用于测试并行计算机系统的性能,能够对计算机系统进行全面的测评,包括CPU、内存、存储等方面。
HPL算法流程主要分为以下几个步骤:1.环境配置2.数据预处理3.矩阵分解4.矩阵运算5.结果输出下面将详细介绍每个步骤的具体流程。
一、环境配置在进行HPL测试之前,需要先进行环境配置。
具体步骤如下:1.安装MPI(Message Passing Interface)库。
MPI是一种消息传递接口,用于实现多个进程之间的通信。
在HPL中,MPI库主要用于实现并行计算。
2.安装BLAS(Basic Linear Algebra Subprograms)库。
BLAS库是一个基本线性代数子程序库,包含了大量常用的线性代数运算函数。
3.安装HPL软件包。
HPL软件包是一个高性能线性代数软件包,主要用于求解稠密线性方程组。
二、数据预处理在进行矩阵分解和运算之前,需要对输入的矩阵进行预处理。
具体步骤如下:1.生成随机矩阵。
HPL测试需要一个大型的稠密矩阵作为输入,通常使用随机数生成器来生成这个矩阵。
2.将矩阵分块。
为了实现并行计算,HPL需要将大型的稠密矩阵分成多个小块,并将每个小块分配给不同的处理器进行计算。
3.将数据转换为二进制格式。
HPL使用二进制格式来存储输入数据,因为它比文本格式更快速、更节省空间。
三、矩阵分解在完成数据预处理之后,就可以开始进行矩阵分解了。
具体步骤如下:1.进行LU分解。
LU分解是一种常用的线性代数运算,用于将一个方阵分解成一个下三角矩阵和一个上三角矩阵的乘积。
2.对LU分解结果进行排序。
为了实现高效的并行计算,HPL需要对LU分解结果进行排序,并按顺序存储到内存中。
3.计算逆置指针数组。
逆置指针数组是一种特殊的数据结构,用于保存每个块在内存中的位置信息。
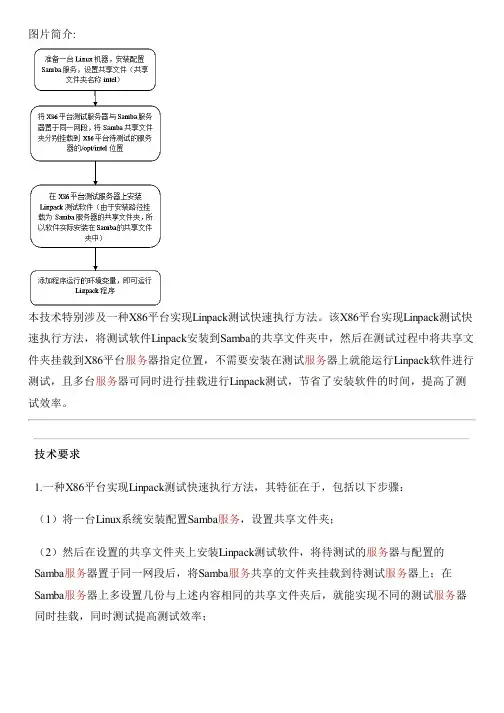
图片简介:本技术特别涉及一种X86平台实现Linpack测试快速执行方法。
该X86平台实现Linpack测试快速执行方法,将测试软件Linpack安装到Samba的共享文件夹中,然后在测试过程中将共享文件夹挂载到X86平台服务器指定位置,不需要安装在测试服务器上就能运行Linpack软件进行测试,且多台服务器可同时进行挂载进行Linpack测试,节省了安装软件的时间,提高了测试效率。
技术要求1.一种X86平台实现Linpack测试快速执行方法,其特征在于,包括以下步骤:(1)将一台Linux系统安装配置Samba服务,设置共享文件夹;(2)然后在设置的共享文件夹上安装Linpack测试软件,将待测试的服务器与配置的Samba服务器置于同一网段后,将Samba服务共享的文件夹挂载到待测试服务器上;在Samba服务器上多设置几份与上述内容相同的共享文件夹后,就能实现不同的测试服务器同时挂载,同时测试提高测试效率;(3)当有X86平台机器需要进行Linpack测试时,将待测的X86平台的服务器连接到与Samba服务器同一网段,然后将Samba服务器共享的文件夹挂载到X86平台服务器的上,添加程序运行的环境变量,即可运行Linpack程序。
2.根据权利要求1所述的X86平台实现Linpack测试快速执行方法,其特征在于,所述Samba服务器配置文件如下:public = yeswritable = yesvalid users = @kanasadmin users = lucas ##用户名create mask = 0777directory mask = 0777force user = nobodyforce group = nogroupavailable = yesbrowseable = yes[intel] ##共享文件夹名comment = l_cprocpath = /linpack/optpublic = yeswritable = yes。




Linpack测试手册(1)千兆以太网:Step1:安装MPICH2将MPICH2安装包放到/hpc目录下,运行:tar –xvf mpich2-1.0.2p1.tarcd mpich2-1.0.2p1创建MPICH2安装目录:mkdir /hpc/mpich2设置MPICH2安装目录:./configure --prefix=/hpc/mpich2配置完成后makemake install安装完成后退出当前目录进入/root目录编辑环境变量文件cd /rootvi .bashrc在文件最后附加一行PATH="$PATH:/hpc/mpich2/bin"关闭并保存文件,执行命令:source .bashrc检查which mpirun返回/hpc/mpich2/bin/mpirun则mpi安装正常。
下面进行通用作业启动机制配置:修改/root/.mpd.conf文件,内容为secretword=mywordcd /root#vi .mpd.conf文件内容如下SECRETWORD=123456设置文件读取权限和修改时间#touch /root/.mpd.conf#chmod 600 /root/.mpd.confcp ./.mpd.conf /etc/mpd.conf创建主机名称集合文件/root/mpd.hosts#vi mpd.hosts文件内容如下:cn01cn02cn03。
启动MPD进程:命令如下mpd & (单节点启动)或者通过mpdboot启动,命令如下mpdboot –n 16 –f /root/mpd.hosts (16为起动的机器的个数)观看启动机器:mpdtrace (看到所有启动机器的列表则正常)退出用命令:mpdallexitStep2:安装数学库(GotoBLAS)将数学库安装包GotoBLAS-1.26.tar.gz放到/hpc目录下,运行:tar –zxvf GotoBLAS-1.26.tar.gzcd GotoBLAS32 bit安裝:./quickbuild.32bit64 bit安裝:./quickbuild.64bit安裝完成后,在当前目录下会生成3个文件,系統根据你的CPU型式來取名,例如:libgoto.alibgoto_core2p-r1.14.a 系統根据你的CPU型式來取名libgoto_core2p-r1.14.so其中libgoto.a即为使用的数学库函数,记下该路径Step3:安装linpack测试包(hpl.tgz)将linpack测试包hpl.tgz放到/hpc目录下,运行tar –xvf hpl.tgzcd hplcd setupcp ./Make.Linux_PII_FBLAS /hpc/hpl/Make.testcd ..pwd目录为/hpc/hpl/vi Make.test编辑该文件如下地方需要更改:ARCH = testTOPdir = /hpc/hplINCdir = $(TOPdir)/includeBINdir = $(TOPdir)/bin/$(ARCH)LIBdir = $(TOPdir)/lib/$(ARCH)MPdir = /hpc/mpich2MPinc = -I$(MPdir)/includeMPlib = $(MPdir)/lib/libmpich.aLAdir = /hpc/GotoBLASLAlib = $(LAdir)/libgoto.aCC = $(MPdir)/bin/mpiccLINKER = $(MPdir)/bin/mpif77更改完毕保存后进行编译make arch=test完成后会在/hpc/hpl/bin下生成test目录,进入cd bin/test会看到2个文件HPL.dat 和xhpl编辑HPL.dat,设置如下:P值,Q值,NB值,Ns值可根据情况调整,不能超过sqrt((单个计算节点内存*计算节点个数)/8 )*0.8,否则可能导致测试中使用swap分区或者内存耗尽而导致的死机,P*Q=进程数=核数,16台计算节点,内存8G,每节点8核心数,共128核心例子如下:HPLinpack benchmark input fileInnovative Computing Laboratory, University of TennesseeHPL.out output file name (if any)6 device out (6=stdout,7=stderr,file)1 # of problems sizes (N)100000 Ns1 # of NBs192 NBs0 PMAP process mapping (0=Row-,1=Column-major)1 # of process grids (P x Q)8 Ps16 Qs16.0 threshold1 # of panel fact0 PFACTs (0=left, 1=Crout, 2=Right)1 # of recursive stopping criterium2 NBMINs (>= 1)1 # of panels in recursion2 NDIVs1 # of recursive panel fact.0 RFACTs (0=left, 1=Crout, 2=Right)1 # of broadcast0 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)1 # of lookahead depth0 DEPTHs (>=0)2 SWAP (0=bin-exch,1=long,2=mix)64 swapping threshold0 L1 in (0=transposed,1=no-transposed) form0 U in (0=transposed,1=no-transposed) form1 Equilibration (0=no,1=yes)8 memory alignment in double (> 0)编辑完成后创建运行节点的列表hostlist文件,每个核心对应一行节点名。

标准LinPack测试详细指南云计算系统的一个重要作用是向用户提供计算力,评价一个系统的总体计算力的方法就是采用一个统一的测试标准作为评判,现在评判一个系统计算力的方法中最为知名的就是LinPack测试,世界最快500台巨型机系统的排名采用的就是这一标准。
掌握LinPack测试技术对于在云计算时代评判一个云系统的计算力也有着重要意义。
本附录将对LinPack测试技术作详细的介绍。
1.LinPack安装在安装之前,我们需要做一些软件准备,相关的软件及下载地址如下。
(1)Linux平台,最新稳定内核的Linux发行版最佳,可以选择Red hat, Centos等。
(2)MPICH2,这是并行计算的软件,可以点击下面链接下载最新的源码包:/research/projects/mp ich2/downloads/index.php?s=downloads (3)Gotoblas,BLAS库(Basic Linear Algebra Subprograms)是执行向量和矩阵运算的子程序集合,这里我们选择公认性能最好的Gotoblas,最新版可点击下面链接下载(需要注册):/tacc- projects(4)HPL,LinPack测试的软件,可在点击下面链接下载最新版本:/benchmark/hpl/安装方法和步骤如下。
(1)安装MPICH2,并配置好环境变量,本书前面已作介绍。
(2)进入Linux系统,建议使用root用户,在/root下建立LinPack文件夹,解压下载的Gotoblas和HPL文件到LinPack文件夹下,改名为Gotoblas和hpl。
#tar xvf GotoBLAS-*.tar.gz#mv GotoBLAS-* ~/linpack/Gotoblas#tar xvf hpl-*.tar.gz#mv hpl-* ~/linpack/hpl(3)安装Gotoblas。
进入Gotoblas文件夹,在终端下执行./ quickbuild.64bit(如果你是32位系统,则执行./ quickbuild.31bit)进行快速安装,当然,你也可以依据README里的介绍自定义安装。

Linpack是国际上最流行的用于测试高性能计算机系统浮点性能的benchmark。
通过对高性能计算机采用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算机的浮点性能。
测试包括三类,Linpack100、Linpack1000和HPL 。
HPL即High Performance Linpack,也叫高度并行计算基准测试。
至目前为止,LINPACK 还是广泛地应用于解各种数学和工程问题。
也由于它高效率的运算,使得其它几种数学软件例如IMSL、MA TLAB 纷纷加以引用来处理矩阵问题,所以足见其在科学计算上有举足轻重的地位。
如何运行linpack:1.编译器的选择Gcc免费,通用,功能强大这里使用全安装方式下RedHat操作系统自带的GNU编译器。
2.mpi的选择Openmpi-1.2.4支持mpi2.0,功能强大,灵活,支持infiniband,效率高使用rsh或ssh可以自由切换,路径可以自己标志,编译器也可以改,一个版本支持多种通讯方式Openmpi安装过程因为默认的openmpi编译出来的库为动态库,所有要设置LD_LIBRARY_PA TH变量,如果想要不设,在编译openmpi时加上--disable-shared --enable-static 选项编辑/etc/profile,在文件的最后面加上蓝线区域内的内容,然后source一下,使更改生效。
输入which mpirun 出现如下信息,则说明环境已搭建成功。
库的安装库的选择一般认为gotoblas库(基本线性代数子方程)比较好,所以在这里我们就选用gotoblas 库。
当前所用机器为amd平台的机器,所以我们就直接选用gotoblas-1.26下面是具体的安装过程:修改make.rule文件。
将下面的蓝色行前面的#去掉,保存,退出。
Make生成库文件也可以直接运行gotoblas目录下的quickbuild.64bit文件来生成库文件。

hpc的常用测试基准
HPC(高性能计算)的常用测试基准包括以下几种:
1. LINPACK:用于衡量计算机系统的浮点运算性能,通过解线性方程组来评估计算机系统的性能。
2. SPEC(Standard Performance Evaluation Corporation):SPEC提供了一系列基准测试,包括SPEC CPU、SPECint、SPECfp等,用于评估计算机系统的整体性能。
3. HPL(High-Performance Linpack):是一种基于LINPACK的测试基准,用于评估计算机系统在大规模并行计算方面的性能。
4. HPC Challenge:包含一系列测试,包括HPL、PTRANS(并行通信带宽和延迟测试)、RandomAccess(随机访问测试)等,用于评估计算机系统在高性能计算方面的综合性能。
5. STREAM:用于评估计算机系统的内存带宽性能,通过进行一系列内存访问操作来测量系统的内存传输速率。
6. IO500:用于评估计算机系统在输入/输出(IO)操作方面的性能,包括文件读写速度、并行文件系统性能等。
这些测试基准可以帮助用户评估和比较不同计算机系统的性能,选择适合自己需求的HPC系统。

LINPACK算法及其测试方法改进优秀doc资料CN43—1258/TP ISSN 1007—130X计算机工程与科学COMPUTER ENGINEERING&SCIENCE2021年第30卷第A1期 V01.30。
No.A1,2021文章编号:1007—130X(2021A1—0032’04LINPACK LINPACK and the 算法及其测试方法Improvement of Its改进’。
乃st Method司照凯。
濮晨Sl Zhao-kai。
PU Chen(江南计算技术研究所,江苏无锡214083(Jiangnan Institute of Computing Technology.Wuxi 214083,China摘要:HPL(High Performance LINPACK是一种用来测试计算机浮点性能的基准测试程序,通过求解稠密线性方程组来评估计算机的浮点性能。
本文分析了HPL的核心算法,并对HPL的计时系统进行改进,提出了一种新的基于计时系统的测试方法,以达到快速完成LINPACK测试的目的,实验证明这种新的测试方法很有效。
experiment shows that this new way is helpful.关键词:高性能;LINPACK;BLAS;MPl;L,U factorizationKey words:high performance LINPACK;BLAS;M[Pl;LU factorization中图分类号:TP309文献标识码:A1引言LINPACK是当前评测计算机浮点性能的基准测试程序,TOP500a是根据计算机的LINPACK性能来进行排名。
LINPACK根据矩阵规模可以分为100×100,1000×1000和N×N三种[“,本文分析的High Pedormanee LIN-PACK(HPL属于N×N这一类。

Linpack安装过程Linpack安装在安装之前,我们需要做一些软件准备,相关的软件及下载地址如下。
(1)Linux平台,最新稳定内核的Linux发行版最佳,可以选择Red hat, Centos等。
(2)MPICH2,这是个并行计算的软件,可以到/research/projects/mp ich2/downloads/index.php?s=downloads 下载最新的源码包。
(3)Gotoblas,BLAS库(Basic Linear Algebra Subprograms)是执行向量和矩阵运算的子程序集合,这里我们选择公认性能最好的Gotoblas,最新版可到/tacc- projects/下载,需要注册。
(4)HPL,linpack测试的软件,可在/benchmark/hpl/下载最新版本。
一、Mpich2的安装过程1、解压软件包tarzxvf mpich2-1.1.1p1.tar.gz cd mpich2-1.1.1p1指定目录编译./configure --prefix=/root/linpack/mpi --with-pm=smpd --enable-f77makemake install2、配置环境变量vim ~/.bashrcPATH="$PATH:/usr/local/mpi/bin"source .bashrc 3、测试环境变量whichsmpdwhichmpiccwhichmpiexecwhichmpirun下面这两部据说在测试时需要输入密码,但是不知道为什么这个密码没有生效。
4、修改/root/.mpd.confsecretword=mywordchmod 600 /root/.mpd.conf5、修改/etc/mpd.confsecretword=mywordchmod 600 /etc/mpd.conf6、测试mpich2的进程smpd是否启动[root@LG01 linpack]# whichsmpd/root/linpack/mpi/bin/smpd[root@LG01 linpack]# smpd –s[root@LG01 linpack]# ps -ef | grepsmpd测试mpi是否启动[root@LG01 linpack]#mpiexec -n 1 hostname二、Gotoblas,BLAS库(Basic Linear Algebra Subprograms)是执行向量和矩阵运算的子程序集合,这里我们选择公认性能最好的Gotoblas GotoBLAS2-1.13_bsd.tar.gz#tar -xzvf GotoBLAS2-1.13_bsd.tar.gz#cd GotoBLAS2#viMakefile.rule改四个地方,标注为(# modified)的行:## Beginning of user configuration## This library's versionVERSION = 1.13# You can specify the target architecture, otherwise it's# automatically detected.TARGET = PENRYN NEHALEM# If you want to support multiple architecture in one binary# DYNAMIC_ARCH = 1# C compiler including binary type(32bit / 64bit). Default is gcc.# Don't use Intel Compiler or PGI, it won't generate right codes as I expect.CC = gcc # modified (设置C编译器)# Fortran compiler. Default is g77.FC = gfortran # modified (设置fortran编译器)# Even you can specify cross compiler# CC = x86_64-w64-mingw32-gcc# FC = x86_64-w64-mingw32-gfortran# If you need 32bit binary, define BINARY=32, otherwise define BINARY=64 BINARY=64 # modified (64为linux操作系统)# About threaded BLAS. It will be automatically detected if you don't# specify it.# For force setting for single threaded, specify USE_THREAD = 0# For force setting for multi threaded, specify USE_THREAD = 1# USE_THREAD = 0# If you're going to use this library with OpenMP, please comment it in.# USE_OPENMP = 1# You can define maximum number of threads. Basically it should be# less than actual number of cores. If you don't specify one, it's# automatically detected by the the script.NUM_THREADS = 1 # modified (单线程运行,可以根据需要配成多线程)# If you don't need CBLAS interface, please comment it in.# NO_CBLAS = 1# If you want to use legacy threaded Level 3 implementation.# USE_SIMPLE_THREADED_LEVEL3 = 1# If you want to drive whole 64bit region by BLAS. Not all Fortran# compiler supports this. It's safe to keep comment it out if you# are not sure(equivalent to "-i8" option).# INTERFACE64 = 1# Unfortunately most of kernel won't give us high quality buffer.# BLAS tries to find the best region before entering main function,# but it will consume time. If you don't like it, you can disable one.# NO_WARMUP = 1# If you want to disable CPU/Memory affinity on Linux.# NO_AFFINITY = 1# If you would like to know minute performance report of GotoBLAS.# FUNCTION_PROFILE = 1# Support for IEEE quad precision(it's *real* REAL*16)( under testing)# QUAD_PRECISION = 1# Theads are still working for a while after finishing BLAS operation# to reduce thread activate/deactivate overhead. You can determine# time out to improve performance. This number should be from 4 to 30 # which corresponds to (1 << n) cycles. For example, if you set to 26,# thread will be running for (1 << 26) cycles(about 25ms on 3.0GHz# system). Also you can control this mumber by GOTO_THREAD_TIMEOUT# CCOMMON_OPT += -DTHREAD_TIMEOUT=26# Using special device driver for mapping physically contigous memory# to the user space. If bigphysarea is enabled, it will use it.# DEVICEDRIVER_ALLOCATION = 1# If you need to synchronize FP CSR between threads (for x86/x86_64 only).# CONSISTENT_FPCSR = 1# If you need santy check by comparing reference BLAS. It'll be very# slow (Not implemented yet).# SANITY_CHECK = 1# Common Optimization Flag; -O2 is enough.COMMON_OPT += -O2# Profiling flagsCOMMON_PROF = -pg## End of user configuration#进入目录执行:./quickbuild.64bit若出现如下:../kernel/x86_64/gemm_ncopy_4.S:192: Error: undefined symbol `RPREFETCHSIZE' in operation ../kernel/x86_64/gemm_ncopy_4.S:193: Error: undefined symbol `RPREFETCHSIZE' in operation ../kernel/x86_64/gemm_ncopy_4.S:194: Error: undefined symbol `RPREFETCHSIZE' in operation ../kernel/x86_64/gemm_ncopy_4.S:195: Error: undefined symbol `RPREFETCHSIZE' in operation则执行:gmake cleanmake BINARY=64 TARGET=NEHALEM出现以上错误的原因为,cpu太新,配置文件不识别,需要重新指定一下CPU类型三、安装HPL。
Linpack的安装调试、优化目录一.Linpack的安装与调试 (2)1.编译器的安装 (2)2.并行环境MPI的安装 (2)3.数学库的安装 (3)4.HPL的安装 (3)二.Linpack的优化与运行 (5)1.HPL.dat中参数的优化 (5)2.xhpl运行的方式 (5)3.查看分析结果 (6)一.Linpack的安装与调试Linpack是国际上最流行的用于测试高性能计算机系统浮点性能的benchmark。
通过对高性能计算机采用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算机的浮点性能,Linpack测试包括三类,Linpack100、Linpack1000和HPLHPL是针对现代并行计算机提出的测试方式。
用户在不修改任意测试程序的基础上,可以调节问题规模大小(矩阵大小)、使用CPU数目、使用各种优化方法等等来执行该测试程序,以获取最佳的性能1.编译器的安装常用的编译器有:GNU PGI Intel编译器如果CPU是Intel的产品,最好使用Intel的编译器,它针对自己的产品做了一些优化,可能效果要好一些。
这里使用全安装方式下CentOS6.2操作系统自带的GNU编译器。
2.并行环境MPI的安装常用的MPI并行环境有:MPICH OpenMPI Intel的MPI等。
如果CPU是Intel的产品,提议使用Intel的MPI。
这里使用OpenMPI 。
安装步骤:本例中各软件安装在/home/richard目录下下载openmpi‐1.4.5.tar.gz#tar zxvf openmpi‐1.4.5.tar.gz#mv openmpi‐1.4.5 openmpi#cd openmpi#./configure –prefix=/home/ ichard/openmpi#make all install安装过程比较长,请耐心等待……安装完成后,#export PATH=/home/ ichard/openmpi/bin:$PATH#export LD_LIBRARY_PATH=/home/ ichard/openmpi/lib:$LD_LIBRARY_PATH#source在命令行输入mpi加两次Tab键,如果下面能正常显示mpirun,mpicc…就说明变量添加成功,但在每次重启都会消失,需重新添加,可在~/.bashrc中永久添加3.数学库的安装采用BLAS库的性能对最终测得的Linpack性能有密切的关系,常用的BLAS库有GOTO、Atlas、ACML、MKL等,测试经验是GOTO库性能最优。
Linpack简要说明文档LINPACK是线性系统软件包(Linear system package)的缩写,主要开始于1974年4月,美国Argonne国家实验室应用数学所主任Jim Pool,在一系列非正式的讨论会中评估,建立一套专门解线性系统问题之数学软件的可能性。
后来便提出了LINPACK。
LINPACK主要的特色是:●率先开创了力学(Mechanics)分析软件的制作。
●建立了将来数学软件比较的标准。
●提供软件链接库,允许使用者加以修正以便处理特殊问题,(当然程序名称必须改写,并应注明修改之处,以尊重原作者,并避免他人误用。
)●兼顾了对各计算机系统的通用性,并提供高效率的运算。
至目前为止,LINPACK还是广泛地应用于解各种数学和工程问题。
也由于它高效率的运算,使得其它几种数学软件例如IMSL、MATLAB纷纷加以引用来处理矩阵问题,所以足见其在科学计算上有举足轻重的地位。
LINPACK性能测试基准:Linpack现在在国际上已经成为最流行的用于测试高性能计算机系统浮点性能的benchmark。
通过利用高性能计算机,用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算机的浮点性能。
Linpack测试包括三类,Linpack100、Linpack1000和HPL。
Linpack100求解规模为100阶的稠密线性代数方程组,它只允许采用编译优化选项进行优化,不得更改代码,甚至代码中的注释也不得修改。
Linpack1000要求求解规模为1000阶的线性代数方程组,达到指定的精度要求,可以在不改变计算量的前提下做算法和代码上做优化。
HPL即High Performance Linpack,也叫高度并行计算基准测试,它对数组大小N没有限制,求解问题的规模可以改变,除基本算法(计算量)不可改变外,可以采用其它任何优化方法。
前两种测试运行规模较小,已不是很适合现代计算机的发展,因此现在使用较多的测试标准为HPL,而且阶次N也是linpack测试必须指明的参数。
LinPACKLinpack 是当前国际上流行的性能测试基准,通过对高性能计算机求解稠密线性代数方程组能力的测试,评价高性能计算机系统的浮点性能,由Jack Dongarra 在1979 年首次提出,多为Fortran 版本。
它提供多种程序并在其它函数库的支持下解决线性方程问题,包括求解稠密矩阵运算,带状的线性方程,求解最小平方问题以及其它各种矩阵运算,但它们都是基于高斯消去法的原理。
Linpack 根据问题规模与优化选择的不同分为100×100,1000×1000,n×n 三种测试[1]。
HPL[2] (High performance linpack) 是第一个标准的公开版本并行Linpack 测试软件包,是n×n 测试的MPI 实现,可适应多体系移植,目前广泛用于top500 测试[3]。
这一测试主要针对分布式存储大规模并行计算系统而设计,它的要求也是Linpack 标准中最为宽松的,用户可以对任意大小的问题规模,使用任意个数的CPU,使用基于高斯消去法的各种优化方法来执行该测试程序,寻求最佳的测试结果。
性能测试实际就是要计算浮点运算率。
美国Tennessee大学的Jack J.Dongarra 博士开发的计算测量电脑性能(基准)的程序。
在著名的超级电脑性能比较项目[TOP500 Supercomputer Sites]中作为标准被采用。
是寻求连立一次方程式的解的程序,主要可以测量浮点运算能力。
在TOP500目录单中使用的基准是把LINPACK高度并行化的项目「HPL」(High-Performance Linpack)。
LINPACK本身并不是专门用来做超级计算机的,也可以运行个人计算机和UNIX workstation等。
LINPACK标准是近年来很有名的一种进行浮点性能测试的标准。
它由Jack Dongarra 最早提出。
LINPACK的名字也是来自于利用高斯消去法求解稠密矩阵线性方程的线性代数包。
linux linpack的用法-回复Linux Linpack是一个常用的基准测试工具,用于评估Linux系统的性能和性能相关问题。
通过执行高性能计算任务,并测量计算机的计算能力、内存带宽和高速缓存性能等指标,Linpack可以帮助用户分析系统的弱点和进行性能调优。
本文将详细介绍Linux Linpack的用法,包括安装、配置和执行测试等步骤。
第一步:安装Linux Linpack1. 打开终端,并使用管理员权限登录系统。
2. 在终端中运行以下命令,安装Linpack:sudo apt-get install linpack第二步:配置测试环境1. 在安装完成后,可以通过编辑Linpack的配置文件来配置测试环境。
该配置文件位于/etc/linpack/linpack.conf。
2. 使用文本编辑器打开配置文件,并按需求修改以下参数:a. N:设置进行测试的向量维度大小。
较大的N值可以使测试更加准确,但同时也会增加测试时间。
b. NB:设置每个计算线程的数据块大小。
c. P:设置用于测试的CPU核心数。
建议设置为系统的物理核心数减一。
d. Q:设置每个核心的线程数。
e. VERBOSE:设置是否打印详细的测试信息。
f. OUTPUT:设置测试结果的输出文件。
3. 保存并关闭配置文件。
第三步:执行Linpack测试1. 打开终端,并使用管理员权限登录系统。
2. 在终端中,运行以下命令以执行Linpack测试:sudo linpack3. Linpack将开始执行计算任务,并显示实时计算性能和测试进度等信息。
4. 测试完成后,结果将会保存在指定的输出文件中。
第四步:分析测试结果1. 使用文本编辑器打开Linpack测试结果的输出文件。
2. 分析结果中的各项指标,包括计算能力、内存带宽和高速缓存性能等。
3. 根据测试结果,可以评估系统的性能和确定可能存在的性能瓶颈。
4. 针对性能瓶颈,可以采取相应的优化措施,如增加系统的内存、优化计算任务的调度算法等。
Linux环境下Lapack软件包的编译和使用自行下载编译过程1. 从 netlab 下载最新版本的源代码2. 将源代码解压缩3. 编辑 make.inc 文件,进行一些系统相关的编译参数设置一些编译参数,PLAT 表示使用的平台,会接在生成lib库的名字中,原本是 _LINUX。
FORTRAN 表示你使用的fortran编译器,根据自己安装的编译器来设置,我用的是 gfo rtran。
OPTS 表示编译时的优化程度,设置为 -O2即可。
LOADER 设置成和FORTRAN 基本一样就可以了。
确定生成目标如下,BLASLIB = /libblas$(PLAT).aLAPACKLIB = liblapack$(PLAT).aTMGLIB = libtmglib$(PLAT).aEIGSRCLIB = libeigsrc$(PLAT).aLINSRCLIB = liblinsrc$(PLAT).a原来的这些库文件的名字前面没有lib的,这里加上。
因为linux上库文件一般有前缀lib的,在链接的时候-l后面带的是库的名字,那个时候是不加lib的。
如果已经编译生成了这些库,可以重命名,而不用重新编译。
PLAT :设置生成的库函数的后缀,比如 SUN, LINUX之类的,当然也可以不设置;FORTRAN :设置编译器,比如 g77, gfortran, ifort, g95 等等;(我设置为FORTRAN = ifort -g)OPT:设置编译选项,根据具体的编译器和优化要求进行设置;LOADER :设置成和FORTRAN 一样就可以了;4. 编辑 Makefile找到 lib:选项。
然后设置需要编译的库函数如下#lib: lapacklib tmgliblib: blaslib lapacklib tmglib默认的情况是不编译 blas 库的。
(除非事先编译好了blas库,否则应一起编译。
)5. 编译和测试 Lapack.在源代码的根目录下输入 make 回车。