bayes判别分析案例及结果
- 格式:doc
- 大小:670.00 KB
- 文档页数:6

bayes法计算遗传例子(一)Bayes法计算遗传Bayes法是一种常用的概率统计方法,用于计算遗传学中的各种概率问题。
下面列举了一些应用Bayes法计算遗传的例子,并详细讲解每个例子的计算步骤。
例子1: 遗传病携带者概率假设某种遗传病是由一对隐性基因引起的,该基因阻碍了患者体内产生特定的酶。
现在有一对夫妇,二者都没有表现出遗传病的症状,但知道自己的父母中有人患有该病。
他们打算要一个孩子,现在想知道他们的孩子患有该病的概率。
计算步骤: 1. 假设该夫妇都是基因携带者的概率为P(A) = 1/4,其中A代表该夫妇都是基因携带者。
2. 由于该病是由隐性基因引起的,在一对隐性基因携带者夫妇的子女中,每个子女的患病概率为1/4。
3. 因此,该夫妇的孩子患有该病的概率为P(B|A) = 1/4。
例子2: 遗传病与基因检测某种遗传病的表现型只有基因型为Aa或AA的个体才会患病。
现有一家三口,父亲和母亲的基因型均为Aa,他们的孩子患病的概率是多少?计算步骤: 1. 父亲和母亲的基因型为Aa,即每个人都有一个A基因和一个a基因。
2. 孩子患病的概率可以通过计算父亲和母亲之间产生不同基因型子代的概率来得到。
在这种情况下,父亲和母亲之间共有以下四种基因组合:AA、Aa、aA、aa,每种组合的概率均为1/4。
3. 只有基因型为Aa或AA的个体才会患病,因此只有前三种基因组合的孩子有可能患病。
这三种组合中,有两种携带基因A的组合(AA和Aa),因此孩子患病的概率为P(B) = 2/4 = 1/2。
例子3: 利用先验概率计算遗传性状某种遗传性状受一个隐性基因和一个显性基因共同决定。
现有一对夫妇,其中丈夫是显性基因型,妻子是隐性基因型。
他们的孩子有多大概率是显性基因型?计算步骤: 1. 根据题目所给的信息,丈夫的基因型是显性,即AA或Aa;妻子的基因型是隐性,即aa。
2. 在这种情况下,通过计算丈夫和妻子之间产生不同基因型子代的概率,来确定孩子是显性基因型的概率。


贝叶斯判别、费希尔判别法的计算机操作及结果分析一、实验内容、目标及要求(一)实验内容选取140家上市公司作为样本,其中70家为由于“财务状况异常”而被交易所对其股票实行特别处理(Special Treatment,简称ST)的公司,另外70家为财务正常的公司。
为了研究上市公司发生财务困境的可能性,以“是否被ST”为分组变量,选择资产负债率、总资产周转率和总资产利润率几个财务指标作为判别分析变量,这三个指标分别从上市公司的偿债能力、资产管理能力和获利能力三个不同的角度反映了企业的财务状况。
(二)实验目标贝叶斯判别、费希尔判别法的计算机操作及结果分析。
(三)实验要求要求学生能熟练应用计算机软件进行判别分析并对结果进行分析,培养实际应用能力。
二、实验准备(一)运行环境说明电脑操作系统为Windows XP及以上版本,所需软件为SPSS 16.0。
(二)基础数据设置说明将数据正确导入SPSS,设置相应的变量值。
三、实验基本操作流程及说明(一)系统界面及说明同实验一。
(二)操作步骤1. 选择菜单项Analyze→Classify→Discriminate,打开Discriminate Analysis对话框,如图4-1。
将分组变量st移入Grouping V ariable列表框中,将自变量x1-x3选入Independents 列表框中。
选择Enter independents together单选按钮,即使用所有自变量进行判别分析。
若选择了Use stepwise method单选按钮,则可以根据不同自变量对判别贡献的大小进行变量筛选,此时,对话框下方的Method按钮被激活,可以通过点击该按钮设置变量筛选的方法及变量筛选的标准。
图4-1 Discriminate Analysis对话框2. 单击Define Range按钮,在打开的Define Range子对话框中定义分组变量的取值范围。
本例中分类变量的取值范围为0到1,所以在Minimum和Maximum输入框中分别输入0和1。


我们来看一个简单的例子:例:高射炮向敌机发射三发炮弹,每弹击中与否相互独立且每发炮弹击中的概率均为0.3,又知敌机若中一弹,坠毁的概率为0.2,若中两弹,坠毁的概率为0.6,若中三弹,敌机必坠毁。
求敌机坠毁的概率。
解:设事件B=“敌机坠毁”;Ai=“敌机中弹”;i=0,1,2,3 实际上我们从题目知道应该是A0,A1,A2,A3构成完备事件组,但是敌机坠毁只和A1,A2,A3有关,即则我们可用如下公式则贝叶斯准则例题P(B|A) 在A的情况下B发生的概率P(A|B)在B的情况下A发生的概率贝叶斯公式:贝叶斯定理公式:P(A|B)=P(B|A)*P(A)/P(B)如上公式也可变形为:P(B|A)=P(A|B)*P(B)/P(A)1、例如:一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,在盗贼入侵时狗叫的概率被估计为0.9,问题是:在狗叫的时候发生入侵的概率是多少?我们假设 A 事件为狗在晚上叫,B 为盗贼入侵,则 P(A) = 3 / 7,P(B)=2/(20·365)=2/7300,P(A | B) = 0.9(窃贼入室盗窃狗叫概率),按照公式很容易得出结果:P(B|A)=0.9*(2/7300)*(7/3)=0.000582、另一个例子,现分别有 A,B 两个容器,在容器 A 里分别有 7 个红球和 3 个白球,在容器 B 里有 1 个红球和 9 个白球,现已知从这两个容器里任意抽出了一个球,且是红球,问这个红球是来自容器 A 的概率是多少?假设已经抽出红球为事件 B,从容器 A 里抽出球为事件 A,则有:P(B) = 8 / 20,P(A) = 1 / 2,P(B | A) = 7 / 10(容器A中抽到红球的概率),按照公式,则有:P(A|B)=(7 / 10)*(1 / 2)*(20/8)=7/8。

实验十一Bayes判别实验目的和要求掌握Bayes判别分析的理论与方法、模型的建立与误差率估计;掌握利用判别分析的SAS过程解决有关实际问题.实验要求:编写程序,结果分析.实验内容:5.4 5.5 选一题data examp5_4。
input group $ x1-x7 @@。
cards。
G1 6.6 39 1.0 6.0 6 0.12 20G1 6.6 39 1.0 6.0 12 0.12 20G1 6.1 47 1.0 6.0 6 0.08 12G1 6.1 47 1.0 6.0 12 0.08 12G1 8.4 32 2.0 7.5 19 0.35 75G1 7.2 6 1.0 7.0 28 0.30 30G1 8.4 113 3.5 6.0 18 0.15 75G1 7.5 52 1.0 6.0 12 0.16 40G1 7.5 52 3.5 7.5 6 0.16 40G1 8.3 113 0.0 7.5 35 0.12 180G1 7.8 172 1.0 3.5 14 0.21 45G1 7.8 172 1.5 3.0 15 0.21 45G2 8.4 32 2.0 9.0 10 0.35 75 G2 8.4 32 2.5 4.0 10 0.35 75 G2 6.3 11 4.5 7.5 3 0.20 15 G2 7.0 8 4.5 4.5 9 0.25 30 G2 7.0 8 6.0 7.5 4 0.25 30 G2 7.0 8 1.5 6.0 1 0.25 30 G2 8.3 161 1.5 4.0 4 0.08 70 G2 8.3 161 0.5 2.5 1 0.08 70 G2 7.2 6 3.5 4.0 12 0.30 30 G2 7.2 6 1.0 3.0 3 0.30 30 G2 7.2 6 1.0 6.0 5 0.30 30 G2 5.5 6 2.5 3.0 7 0.18 18 G2 8.4 113 3.5 4.5 6 0.15 75 G2 8.4 113 3.5 4.5 8 0.15 75 G2 7.5 52 1.0 6.0 6 0.16 40 G2 7.5 52 1.0 7.5 8 0.16 40 G2 8.3 97 0.0 6.0 5 0.15 180 G2 8.3 97 2.5 6.0 5 0.15 180 G2 8.3 89 0.0 6.0 10 0.16 180 G2 8.3 56 1.5 6.0 13 0.25 180 G2 7.8 172 1.0 3.5 6 0.21 45run。
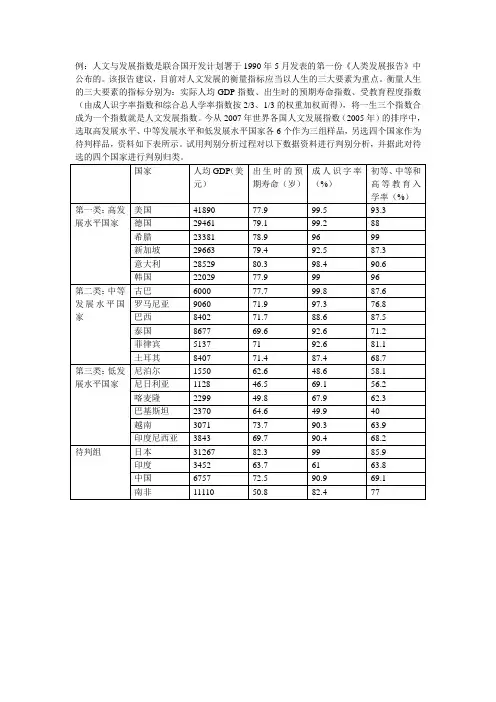
例:人文与发展指数是联合国开发计划署于1990年5月发表的第一份《人类发展报告》中公布的。
该报告建议,目前对人文发展的衡量指标应当以人生的三大要素为重点。
衡量人生的三大要素的指标分别为:实际人均GDP指数、出生时的预期寿命指数、受教育程度指数(由成人识字率指数和综合总人学率指数按2/3、1/3的权重加权而得),将一生三个指数合成为一个指数就是人文发展指数。
今从2007年世界各国人文发展指数(2005年)的排序中,选取高发展水平、中等发展水平和低发展水平国家各6个作为三组样品,另选四个国家作为待判样品,资料如下表所示。
试用判别分析过程对以下数据资料进行判别分析,并据此对待data develop;input type gdp life rate zhrate@@;cards;1 41890 77.9 99.5 93.31 29461 79.1 99.2 881 23381 78.9 96 991 29663 79.4 92.5 87.31 28529 80.3 98.4 90.61 22029 77.9 99 962 6000 77.7 99.8 87.62 9060 71.9 97.3 76.82 8402 71.7 88.6 87.52 8677 69.6 92.6 71.22 5137 71 92.6 81.12 8407 71.4 87.4 68.73 1550 62.6 48.6 58.13 1128 46.5 69.1 56.23 2299 49.8 67.9 62.33 2370 64.6 49.9 403 3071 73.7 90.3 63.93 3843 69.7 90.4 68.2. 31267 82.3 99 85.9. 3452 63.7 61 63.8. 6757 72.5 90.9 69.1. 11110 50.8 82.4 77;proc discrim simple wcov distance list;/*simple:要求技术各类样品的简单描述统计量;选项WCOV要求计算类内协方差阵;选项DISTANCE要求计算马氏距离;选项LIST要求输出重复替换归类结果。



研究与探讨贝叶斯(B ayes)判别分析理论在安全评价中的应用雷兢 沈斐敏(福州大学环境与资源学院 福州350002) 摘 要 论述了多元统计分析方法中的贝叶斯判别分析方法在安全评价中的应用。
通过对原始数据的分析建立起反映被评价对象安全状况的综合指标函数模型,从而简化后续同类评价目标工作量。
关键词 贝叶斯判别分析 安全评价 模型Application of B ayes Discriminant Analysis in S afety Evalu ationLei Jing Shen Feim in(Institute o f Environment and Resources ,Fuzhou Univer sity Fuzhou 350002)Abstract The paper expounds the application of Bayes discrim inant analysis in safety evaluation.Based on analysis of the original datum ,a m odel of evaluation function that reflects safety condition of evaluated object is constructed s o as to sim plify the process of the same evaluat 2ed target.K eyw ords bayes discrim inant analysis safety evaluation m odel 安全是人类生存和发展的最基本的需要之一,它伴随着人类的诞生而产生,存在于人类的所有活动中,随着科学技术的迅猛发展,人民生活水平及安全意识的提高和中国加入WT O ,人们对安全越来越重视,安全在国家的政治、经济、文化生活中已成为必不可少的角色。
实验十一 Bayes 判别实验目的和要求掌握Bayes 判别分析的理论与方法、模型的建立与误差率估计;掌握利用判别分析的SAS 过程解决有关实际问题.实验要求:编写程序,结果分析.实验内容:1、2题必做,第2-4题可选一题1. 写出两总体Bayes 判别的划分、准则,误判率估计;两总体的Bayes 判别准则为⎩⎨⎧<=∈∈≥=∈∈)}()2|1()()1|2(:{,)}()2|1()()1|2(:{,221122221111x x x x x x x x x x f p c f p c R G f p c f p c R G 如如误判概率的频率估计---回代法和交叉确认法*p ),2|1(),1|2(21R R P p P p +=212112221212112211*ˆn n n n n n n n n n n n n n p++=⋅++⋅+=≈ 回代法估计 21*21*12*ˆn n n n pp c++=≈* 交叉确认法估计2.写出两总体正态分布的Bayes 判别准则,给出样品;两个正态总体的Bayes 判别212221212||)2()},(21exp{)}()(21exp{||)2(1)(j p j j j T j j p j G d f Σx μx Σμx Σx ππ-=---=- )}()(21||ln )2ln(2)(ln 1j j j j j p f μx Σμx Σx -----=-π =)(2x j d )()(1j j T j μx Σμx ---)|(ln 2-ln 2-||ln j i c p j j Σ+---广义平方距离2,1,)(2exp()(2exp()(21exp()|(22212=-+--=j d d d G P j j x x x x ----后验概率最优划分 ⎩⎨⎧>=≤=)}()(:{)}()(:{2221222211x x x x x x d d R d d R两正态总体一般判别准则⎩⎨⎧><∈≤≥∈)()()|()|(,)()()|()|(,22212122221211x x x x x x x x x x d d G P G P G d d G P G P G 或当或当3.书上5.4、5.5选一题 5.4 (1) 结果如下:data examp5_4;input group $ x1-x7 @@; cards ;G1 6.6 39 1.0 6.0 6 0.12 20 G1 6.6 39 1.0 6.0 12 0.12 20 G1 6.1 47 1.0 6.0 6 0.08 12 G1 6.1 47 1.0 6.0 12 0.08 12 G1 8.4 32 2.0 7.5 19 0.35 75 G1 7.2 6 1.0 7.0 28 0.30 30 G1 8.4 113 3.5 6.0 18 0.15 75 G1 7.5 52 1.0 6.0 12 0.16 40 G1 7.5 52 3.5 7.5 6 0.16 40 G1 8.3 113 0.0 7.5 35 0.12 180 G1 7.8 172 1.0 3.5 14 0.21 45 G1 7.8 172 1.5 3.0 15 0.21 45 G2 8.4 32 1.0 5.0 4 0.35 75 G2 8.4 32 2.0 9.0 10 0.35 75 G2 8.4 32 2.5 4.0 10 0.35 75 G2 6.3 11 4.5 7.5 3 0.20 15 G2 7.0 8 4.5 4.5 9 0.25 30 G2 7.0 8 6.0 7.5 4 0.25 30 G2 7.0 8 1.5 6.0 1 0.25 30 G2 8.3 161 1.5 4.0 4 0.08 70 G2 8.3 161 0.5 2.5 1 0.08 70 G2 7.2 6 3.5 4.0 12 0.30 30 G2 7.2 6 1.0 3.0 3 0.30 30 G2 7.2 6 1.0 6.0 5 0.30 30 G2 5.5 6 2.5 3.0 7 0.18 18 G2 8.4 113 3.5 4.5 6 0.15 75 G2 8.4 113 3.5 4.5 8 0.15 75 G2 7.5 52 1.0 6.0 6 0.16 40 G2 7.5 52 1.0 7.5 8 0.16 40G2 8.3 97 0.0 6.0 5 0.15 180G2 8.3 97 2.5 6.0 5 0.15 180G2 8.3 89 0.0 6.0 10 0.16 180G2 8.3 56 1.5 6.0 13 0.25 180G2 7.8 172 1.0 3.5 6 0.21 45G2 7.8 233 1.0 4.5 6 0.18 45;run;proc discrim data=examp5_4 wcov outstat=aa method=normal pool=no list crosslist;class group;priors proportional; /* 总体的先验概率与各总体的训练样本容量成比例 */ run;proc print data=aa; /* 数据集aa中有各总体的均值向量、标准差、相关系数等*/ run;结果如下:计算广义平方距离函数和后验概率2,1,))(ˆ5.0exp(/))(ˆ5.0exp()|(ˆ2122=--=∑=j d d G P k kj j x x x由此可见,误判率的回代估计为0ˆ* r p .误判率的交叉确认法估计交叉确认法的广义平方距离函数及后验概率计算公式2,1,ln 2||ln (()(~)()()1()()(2=-+--=-j p d j x j x x j x j jj S )x x )S x x x2,1,))(ˆ5.0exp(/))(ˆ5.0exp()|(ˆ2122=--=∑=j d d G P k kj j x x x交叉确认法分类小结4.针对波士顿房价问题(1) 利用Bayes 判别对住房状况做判别分析,并给出5、100、400号样品判别结果。
Bayes 判别分析及应用班级:计算B101姓名:孔维文 学号201009014119指导老师:谭立云教授【摘 要】判别分析是根据所研究个体的某些指标的观测值来推断该个体所属类型的一种统计方法,在社会生产和科学研究上应用十分广泛。
在判别分析之前,我们往往已对各总体有一定了解,样品的先验概率也对其预测起到一定作用,因此进行判别时应考虑到各个总体出现的先验概率;由于在实际问题中,样品错判后会造成一定损失,故判别时还要考虑到预报的先验概率及错判造成的损失,Bayes 判别就具有这些优点;然而当样品容量大时计算较复杂,故而常借助统计软件来实现。
本文着重于Bayes 判别分析的应用以及SPSS 的实现。
【关键词 】 判别分析 Bayes 判别 Spss 实现 判别函数 判别准则Class: calculation B101 name: KongWeiWen registration number 201009014119Teacher: TanLiYun professor.【Abstract 】Discriminant analysis is based on the study of certain indicators of individual observations to infer that the individual belongs as a type of statistical methods in social production and scientific research is widely used. In discriminant analysis, we often have a certain understanding of the overall sample of the a priori probability of its prediction play a role, it should be taken into account to determine the overall emergence of various prior probability; because of practical problems, samples will result in some loss of miscarriage of justice, so identification must be considered when the prior probability and wrongly predicted loss, Bayes discriminant to have these advantages; However, when the sample is large computing capacity of more complex, often using statistical software Guer to achieve. This article focuses on the application of Bayes discriminant analysis, and implementation of SPSS.【Key words 】 Discriminant analysis; Bayes discriminant; Spss achieve; Discriminantfunction; Criteria;1.1.1 判别分析的概念在科学研究中,经常会遇到这样的问题:某研究对象以某种方式(如先前的结果或经验)已划分成若干类型,而每一种类型都是用一些指标T p X X X X ),,(21 来表征的,即不同类型的X 的观测值在某种意义上有一定的差异。
第三节Bayes判别本节内容贝叶斯公式最大后验概率准则最小平均误判代价准则Bayes判别的基本方法案例分析距离判别法的缺点第一,把总体等同看待,没有考虑到总体会以1不同的概率出现,认为判别方法与总体各自出现的概率的大小无关。
2第二,判别方法与错判之后所造成的损失无关,没有考虑误判之后所造成的损失差异。
贝叶斯(Bayes)公式贝叶斯统计的基本思想:假定对研究的对象已有一定的认识,常用先验概率分布来描述这种认识,然后我们取得一个样本,用样本来修正已有的认识(先验概率分布),得到后验概率分布,各种统计推断都通过后验概率分布进行,将贝叶斯思想用于判别分析,就得到贝叶斯判别。
某公司新入职雇员小王,小王是好员工还是坏员工大家都在猜测。
按人们先验的主观猜测,新人是好员工或坏员工的概率均为0.5。
坏员工总是无法按时完成工作,偶尔也可以顺利完成;好员工一般都能按时完成任务,但偶尔也会出现工作失误:一般好员工按时完成工作的概率为0.9,坏员工按时完成工作的概率为0.2。
近日,小王按时完成了一项工作任务,请问小王此时是好员工的概率有多大?“先验概率”是一种权重(比例),所谓“先验”,是指我们在抽样以前,就已经知道的 ;贝叶斯判别需要研究的“后验概率”,就是当样本X 已知时,它属于G i 的概率。
()i P G ()i P G X 由此,使用“最大后验概率准则”得到的贝叶斯判别规则为:1,()max ()≤≤∈=l l i i kX G P G X P G X 如果最大后验概率准则没有涉及误判的代价,因此,在各种误判代价明显不同的场合,该准则就失效了。
设有k 个总体 ,其各自的分布密度函数 互不相同,假设k 个总体各自出现的概率分别为 (先验概率), , 。
假设若将本来属于G i 总体的样品错判到总体G j 时造成的损失为, 。
在这样的情形下,对于新的样品X 判断其来自哪个总体。
问题12,,,k G G G ⋅⋅⋅()()()12,,,k f X f X f X ⋅⋅⋅12,,,k q q q ⋅⋅⋅0≥i q 11ki i q ==∑(|)C j i , 1.2,,=⋅⋅⋅i j k显然 、,对于任意的 成立。
例:研究某年全国各地区农民家庭收支的分布规律,根据抽样调查资料进行分类,共抽取28个省、市、自治区的六个指标数据。
先采用聚类分析,将28个省、市、自治区分为三组。
北京、上海、广州3个城市属于待判样本。
(家庭收支.sav)
1.选中判别分析,
2.选择Fisher 即bayes判别分析方法,易混!!!
3.确定组别
4. 选择保存结果
5. 模型检验(即判别准确率)
重要结果
分类函数系数
类别
1 2 3
食品.480 .473 .429 衣着 1.612 1.354 .933 燃料 2.421 2.189 .777 住房.555 .335 .052 用品及其它 1.032 .580 .847 文化支出 5.387 5.446 4.317
(常量) -117.620 -89.052 -53.616
Fisher 的线性判别式函数
按照案例顺序的统计量
案例
数目
实
际
组
最高组第二最高组判别式得分
预
测
组
P(D>d |
G=g)
P(G=g
| D=d)
到质心的平
方
Mahalanobis
距离组
P(G=g
| D=d)
到质心的平
方
Mahalanobis
距离
函数
1
函数
2 p df
初始 1 1 1 .320 2 1.000 2.282 2 .000 22.754 3.163 -2.717
2 1 1 .799 2 1.000 .449 2 .000 17.611 3.559 -1.659
3 1 2**.095 2 .688 4.705 1 .312 6.283 2.737 1.275
4 1 1 .797 2 .984 .453 2 .016 8.670 2.85
5 -.569
5 1 1 .504 2 1.000 1.372 2 .000 20.770 4.205 -1.461
6 1 1 .313 2 .996 2.321 2 .004 13.305 1.84
7 -2.131
7 2 2 .788 2 .986 .476 1 .011 9.482 .566 .595
8 2 2 .405 2 .992 1.806 1 .008 11.456 1.756 1.913
9 2 2 .532 2 .987 1.263 1 .013 9.942 1.645 1.607
10 2 2 .451 2 .999 1.593 1 .001 15.008 1.358 2.269
11 2 2 .826 2 .984 .383 1 .015 8.758 .816 .718
12 2 2 .769 2 .994 .524 1 .006 10.742 1.252 1.523
13 2 2 .378 2 .861 1.945 3 .139 5.594 -.611 .539
14 2 2 .219 2 .639 3.034 3 .361 4.179 -1.036 .605
15 2 2 .304 2 .941 2.379 3 .059 7.903 -.943 1.596
16 2 2 .935 2 .997 .134 1 .003 12.046 .874 1.485
17 3 3 .387 2 .994 1.899 2 .006 12.039 -1.570 -1.448
18 3 3 .801 2 1.000 .443 2 .000 19.449 -3.157 -1.076
19 3 3 .413 2 .991 1.767 2 .009 11.104 -1.531 -1.303
20 3 3 .570 2 .984 1.124 2 .016 9.398 -1.635 -.847
21 3 3 .880 2 .997 .255 2 .003 11.791 -2.562 -.128
22 3 3 .826 2 .993 .383 2 .007 10.155 -2.282 -.140
23 3 3 .130 2 1.000 4.077 2 .000 29.305 -4.643 -.183
24 3 3 .078 2 .995 5.095 2 .005 15.558 -3.369 1.526
25 3 3 .323 2 1.000 2.260 2 .000 25.638 -3.294 -1.989
26 未
分
组
的
1 .000
2 1.000 20.22
3 2 .000 62.899 7.05
4 -3.278
27 未
分
组
的
1 .000
2 1.000 82.160 2 .000 150.236 11.796 -3.630
28 未
分
组
的
1 .005
2 1.000 10.431 2 .000 25.808 5.621 .759
交叉验证a 1 1 1 .349 6 1.000 6.707 2 .000 27.301
2 1 1 .025 6 .999 14.400 2 .001 29.412
3 1 2**.087 6 1.000 11.051 1 .000 37.740
4 1 1 .233 6 .900 8.064 2 .100 12.459
5 1 1 .13
6 6 1.000 9.738 2 .000 28.718
6 1 1 .182 6 .975 8.851 2 .025 16.179
7 2 2 .249 6 .945 7.850 1 .043 14.042
8 2 2 .734 6 .984 3.575 1 .016 11.807
9 2 2 .039 6 .880 13.285 1 .120 17.268
10 2 2 .078 6 .996 11.349 1 .004 22.465
11 2 2 .701 6 .967 3.819 1 .031 10.683
12 2 2 .461 6 .984 5.669 1 .016 13.903
13 2 3**.129 6 .703 9.898 2 .297 11.622
14 2 3**.444 6 .684 5.820 2 .316 7.368
15 2 2 .123 6 .635 10.047 3 .365 11.151
16 2 2 .000 6 .878 35.006 1 .121 38.973
17 3 3 .114 6 .955 10.252 2 .044 16.407
18 3 3 .925 6 1.000 1.939 2 .000 20.371
19 3 3 .288 6 .959 7.373 2 .041 13.678
20 3 3 .652 6 .963 4.186 2 .037 10.707
21 3 3 .526 6 .991 5.139 2 .009 14.634
22 3 3 .834 6 .986 2.792 2 .014 11.302
23 3 3 .101 6 1.000 10.616 2 .000 39.411
24 3 3 .018 6 .917 15.261 2 .083 20.057
25 3 3 .268 6 1.000 7.611 2 .000 32.555
对初始数据来说,平方Mahalanobis 距离基于典则函数。
对交叉验证数据来说,平方Mahalanobis 距离基于观察值。
**. 错误分类的案例
a. 仅对分析中的案例进行交叉验证。
在交叉验证中,每个案例都是按照从该案例以外的所有其他案例派生的函数来分类的。
分类结果b,c
类别预测组成员
合计
1 2 3
初始计数 1 5 1 0 6
2 0 10 0 10
3 0 0 9 9
未分组的案例 3 0 0 3
% 1 83.3 16.7 .0 100.0
2 .0 100.0 .0 100.0
3 .0 .0 100.0 100.0
未分组的案例100.0 .0 .0 100.0
交叉验证a计数 1 5 1 0 6
2 0 8 2 10
3 0 0 9 9
% 1 83.3 16.7 .0 100.0
2 .0 80.0 20.0 100.0
3 .0 .0 100.0 100.0
a. 仅对分析中的案例进行交叉验证。
在交叉验证中,每个案例都是按照从该案例以外的所
有其他案例派生的函数来分类的。
b. 已对初始分组案例中的96.0% 个进行了正确分类。
c. 已对交叉验证分组案例中的88.0% 个进行了正确分类。