数学建模之数据拟合
- 格式:ppt
- 大小:1.10 MB
- 文档页数:60

京师微课JINGSHIWEIKE
(上接第17页)
立安排自己的学习时间,才能彻底激发学生的学习热情,使其主动地进行学习。
还要培养学生独立走上讲台的能力,给学生更广阔的舞台,促进学生的交流沟通,有助于培养学生良好的分析能力和表达能力,为学生的全面发展奠定基础。
(三)加快体育教学的内容改革
我国的高校体育教学仍然停留在传统的教学阶段,改革力度较低,不能挖掘潜在的教学能力。
在这次教学变革中应该积极推进体育线上教学的改革,向深层次和多元化角度进行全面发展,利用互联网技术的优势,培养更多的全面体育人才。
体育线上教学的目标就是培养更多符合社会发展的人才,实现体育的宗旨。
开展体育教学的过程中必须融入更多线上教育技术,才能取得体育的丰硕成果,培养更多的体育合格人才。
三、结语
高校线上教学模式的发展为培养体育人才提供支撑,引领高校教学发展的新模式,特别是使用网络教学授课,改变了传统高校体育教学的不足,打破了教学形式的限制,为高校改革提供了更多的支持。
教育工作者应该运用更多的教学模式,为培养更多的合格体育人才做出贡献。
参考文献
[1]任鹏.关于“互联网+”背景下高校体育信息化教学改革的研究[J].当代体育科技,2020(30).
[2]丁铮锴,许水生.体育教学模式、组织形式和教学方法创新[J].中外企业家,2020(17).
·
3
5
·。
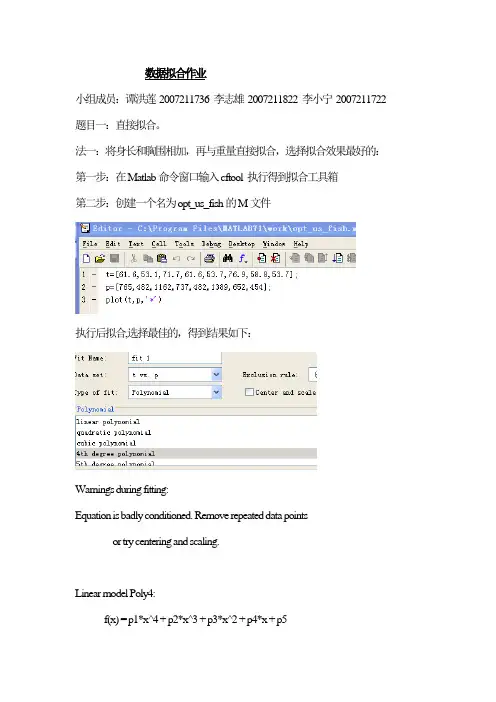
数据拟合作业小组成员:谭洪莲 2007211736 李志雄 2007211822 李小宁 2007211722 题目一:直接拟合。
法一:将身长和胸围相加,再与重量直接拟合,选择拟合效果最好的:第一步:在Matlab命令窗口输入cftool 执行得到拟合工具箱第二步:创建一个名为opt_us_fish的M文件执行后拟合,选择最佳的,得到结果如下:Warnings during fitting:Equation is badly conditioned. Remove repeated data pointsor try centering and scaling.Linear model Poly4:f(x) = p1*x^4 + p2*x^3 + p3*x^2 + p4*x + p5Coefficients (with 95% confidence bounds):p1 = 6.9e-011 (-2.238e-010, 3.618e-010) p2 = -2.549e-007 (-1.344e-006, 8.346e-007) p3 = 0.0003309 (-0.001117, 0.001778) p4 = -0.151 (-0.9579, 0.6559)p5 = 74.47 (-84.11, 233.1)Goodness of fit:SSE: 1.161R-square: 0.9979Adjusted R-square: 0.995RMSE: 0.6221拟合结果:法二:将身长与胸围相乘,再与重量直接拟合,选择拟合效果最好的,结果如下:(步骤同上)Warnings during fitting:Equation is badly conditioned. Remove repeated data pointsor try centering and scaling.Linear model Poly4:f(x) = p1*x^4 + p2*x^3 + p3*x^2 + p4*x + p5Coefficients (with 95% confidence bounds):p1 = 3.195e-009 (-4.077e-009, 1.047e-008)p2 = -1.164e-005 (-3.87e-005, 1.542e-005) p3 = 0.01518 (-0.02077, 0.05113)p4 = -7.549 (-27.59, 12.49)p5 = 1935 (-2004, 5874)Goodness of fit:SSE: 716.1R-square: 0.9986Adjusted R-square: 0.9968RMSE: 15.45拟合效果:题目二:首先利用机理分析建立模型。

数学建模方法大汇总数学建模是数学与实际问题相结合,通过建立数学模型来解决实际问题的一种方法。
在数学建模中,常用的方法有很多种,下面将对常见的数学建模方法进行大汇总。
1.描述性统计法:通过总结、归纳和分析数据来描述现象和问题,常用的统计学方法有平均值、标准差、频率分布等。
2.数据拟合法:通过寻找最佳拟合曲线或函数来描述和预测数据的规律,常用的方法有最小二乘法、非线性优化等。
3.数理统计法:通过样本数据对总体参数进行估计和推断,常用的方法有参数估计、假设检验、方差分析等。
4.线性规划法:建立线性模型,通过线性规划方法求解最优解,常用的方法有单纯形法、对偶理论等。
5.整数规划法:在线性规划的基础上考虑决策变量为整数或约束条件为整数的情况,常用的方法有分支定界法、割平面法等。
6.动态规划法:通过递推关系和最优子结构性质建立动态规划模型,通过计算子问题的最优解来求解原问题的最优解,常用的方法有最短路径算法、最优二叉查找树等。
7.图论方法:通过图的模型来描述和求解问题,常用的方法有最小生成树、最短路径、网络流等。
8.模糊数学法:通过模糊集合和隶属函数来描述问题,常用的方法有模糊综合评价、模糊决策等。
9.随机过程法:通过概率论和随机过程来描述和求解问题,常用的方法有马尔可夫过程、排队论等。
10.模拟仿真法:通过构建系统的数学模型,并使用计算机进行模拟和仿真来分析问题,常用的方法有蒙特卡洛方法、事件驱动仿真等。
11.统计回归分析法:通过建立自变量与因变量之间的关系来分析问题,常用的方法有线性回归、非线性回归等。
12.优化方法:通过求解函数的最大值或最小值来求解问题,常用的方法有迭代法、梯度下降法、遗传算法等。
13.系统动力学方法:通过建立动力学模型来分析系统的演化过程,常用的方法有积分方程、差分方程等。
14.图像处理方法:通过数学模型和算法来处理和分析图像,常用的方法有小波变换、边缘检测等。
15.知识图谱方法:通过构建知识图谱来描述和分析知识之间的关系,常用的方法有图论、语义分析等。



数学建模中的参数拟合方法数学建模是研究实际问题时运用数学方法建立模型,分析和预测问题的一种方法。
在建立模型的过程中,参数拟合是非常重要的一环。
所谓参数拟合,就是通过已知数据来推算模型中的未知参数,使模型更加精准地描述现实情况。
本文将介绍数学建模中常用的参数拟合方法。
一、最小二乘法最小二乘法是一种常用的线性和非线性回归方法。
该方法通过最小化误差的平方和来估计模型参数。
同时该方法的优点在于可以使用简单的数学公式解决问题。
最小二乘法的基本思想可以简单地表示如下:对于给定的数据集合,设其对应的观测值集合为y,$y_1,y_2,...,y_n$,对应的自变量集合为x,$x_1,x_2,...,x_n$,则目标是找到一组系数使得拟合曲线最接近实际数据点。
通常拟合曲线可以用如下所示的线性方程表示:$$f(x)=a_0+a_1x+a_2x^2+...+a_kx^k$$其中,k为拟合曲线的阶数,$a_i$表示第i个系数。
最小二乘法的目标即为找到一组系数${a_0,a_1,...,a_k}$,使得曲线拟合残差平方和最小:$$S=\sum_{i=1}^{n}(y_i-f(x_i))^2$$则称此时求得的拟合数学模型为最小二乘拟合模型。
最小二乘法在实际问题中应用广泛,如线性回归分析、非线性回归分析、多项式拟合、模拟建模等领域。
对于非线性模型,最小二乘法的数学公式比较复杂,需要使用计算机编程实现。
二、梯度下降法梯度下降法是一种优化算法,通过求解函数的导数,从而找到函数的最小值点。
在数学建模中,梯度下降法可以用于非线性回归分析,最小化误差函数。
梯度下降法的基本思想为:在小区间范围内,将函数$f(x)$视为线性的,取其一阶泰勒展开式,在此基础上进行优化。
由于$f(x)$的导数表示$f(x)$函数值增大最快的方向,因此梯度下降法可以通过调整参数的值,逐渐朝向函数的最小值点移动。
具体地,对于给定的数据集合,设其对应的观测值集合为y,$y_1,y_2,...,y_n$,对应的自变量集合为x,$x_1,x_2,...,x_n$,则目标是找到一组系数使得拟合曲线最接近实际数据点。

数学建模数据拟合例题解析近年来,数学建模在各个领域得到了广泛的应用,其中数据拟合作为数学建模中重要的一环,更是被广泛应用于实际问题中。
本文将以一个例题为例,通过建模和代码的方法,解析数据拟合的过程,帮助读者更好地理解和应用数据拟合的方法。
1. 问题描述假设我们有一组实验数据,数据中包含了一个变量x和一个变量y,我们想通过这组实验数据,建立一个数学模型来描述x和y之间的关系,并且用这个模型来预测其他x对应的y值。
2. 数据分析我们需要对实验数据进行分析,观察数据的分布规律以及x和y之间的关系。
通常情况下,我们可以通过绘制散点图的方式来直观地观察数据的分布情况。
3. 数据拟合模型的选择在观察了实验数据的分布规律之后,我们需要选择一个适合的数据拟合模型来描述x和y之间的关系。
常用的数据拟合模型包括线性回归模型、多项式拟合模型、指数拟合模型、对数拟合模型等。
在选择模型时,需要考虑模型的复杂程度、拟合效果以及实际问题的需求。
4. 模型建立选择了数据拟合模型之后,我们需要利用实验数据来建立模型,通常可以通过最小二乘法或者最大似然估计的方法来确定模型的参数。
以线性回归模型为例,假设模型为y=ax+b,我们需要通过最小二乘法来确定参数a和b的取值,使得模型能够最好地拟合实验数据。
5. 模型评估建立模型之后,我们需要对模型进行评估,以确定模型的拟合效果。
常用的评估指标包括决定系数R^2、均方误差MSE等。
通过这些评估指标,我们可以了解模型的拟合效果如何,并且对模型进行优化和改进。
6. 模型预测我们可以利用建立的模型来进行预测,预测其他x对应的y值。
通过模型预测,我们可以更好地理解实验数据中x和y之间的关系,从而为实际问题的决策提供支持。
通过以上的解析,我们可以清楚地了解了数据拟合的整个过程,包括数据分析、模型选择、模型建立、模型评估以及模型预测等环节。
通过这些方法和步骤,我们可以更好地理解和应用数据拟合的方法,在实际问题中更好地解决实际问题。

数学建模常见的⼀些⽅法【04拟合算法】@⽬录数学建模常见的⼀些⽅法1. 拟合算法与插值问题不同,在拟合问题中不需要曲线⼀定经过给定的点。
拟合问题的⽬标是寻求⼀个函数(曲线),使得该曲线在某种准则下与所有的数据点最为接近,即曲线拟合的最好(最⼩化损失函数)。
1.1 插值和拟合的区别 插值算法中,得到的多项式f(x)要经过所有样本点。
但是如果样本点太多,那么这个多项式次数过⾼,会造成。
尽管我们可以选择分段的⽅法避免这种现象,但是更多时候我们更倾向于得到⼀个确定的曲线,尽管这条曲线不能经过每⼀个样本点,但只要保证误差⾜够⼩即可,这就是拟合的思想。
(拟合的结果是得到⼀个确定的曲线)1.2 求解最⼩⼆乘法1.3 Matlab求解最⼩⼆乘测试数据:x =4.20005.90002.70003.80003.80005.60006.90003.50003.60002.90004.20006.10005.50006.60002.90003.30005.90006.00005.6000>> yy =8.400011.70004.20006.10007.900010.200013.20006.60006.00004.60008.400012.000010.300013.30004.60006.700010.800011.50009.9000计算代码:>> plot(x,y,'o')>> % 给x和y轴加上标签>> xlabel('x的值')>> ylabel('y的值')>> n = size(x,1);>> k = (n*sum(x.*y)-sum(x)*sum(y))/(n*sum(x.*x)-sum(x)*sum(x))>> b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/(n*sum(x.*x)-sum(x)*sum(x))>> hold on % 继续在之前的图形上来画图形>> grid on % 显⽰⽹格线>> f=@(x) k*x+b; % 函数线>> fplot(f,[2.5,7]); % 设置显⽰范围>> legend('样本数据','拟合函数','location','SouthEast')计算过程:>> plot(x,y,'o')>> % 给x和y轴加上标签>> xlabel('x的值')>> ylabel('y的值')>> n = size(x,1);>> n*sum(x.*y)-sum(x)*sum(y)ans = 1.3710e+03>> n*sum(x.*x)-sum(x)*sum(x)ans = 654.4600>> k = (n*sum(x.*y)-sum(x)*sum(y))/(n*sum(x.*x)-sum(x)*sum(x))k = 2.0948>> b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/(n*sum(x.*x)-sum(x)*sum(x))b = -1.0548>> hold on>> grid on>> f=@(x) k*x+b;>> fplot(f,[2.5,7]);>> legend('样本数据','拟合函数','location','SouthEast')1.4 如何评价拟合的好坏线性函数是指对参数为线性(线性于参数)在函数中,参数仅以⼀次⽅出现,且不能乘以或除以其他任何的参数,并不能出现参数的复合函数形式。

插值和数据拟合一、 插值方法问题:已知n+1个节点(x j ,y j )(j=0,1,…,n),a=x 0<x 1<…< x n =b ,求任一插值点x*处的插值y*方法:构造一个相对简单的函数y=f(x),使得f 通过所有节点,即f(x j )= y j ,再用y=f(x)计算x*的值。
1. 拉格朗日多项式插值设f(x)是n 次多项式,记作1110()n n n n n L x a x a x a x a --=++++要求对于节点(,)j j x y 有(),0,1,,n j j L x y j n ==将n+1个条件带入多项式,就可以解出多项式的n+1个系数。
实际上,我们有n 次多项式011011()()()()()()()()()i i n i i i i i i i n x x x x x x x x l x x x x x x x x x -+-+----=----满足1,()0,,,0,1,,i j i jl x i j i j n =⎧=⎨≠=⎩则0()()nn i i i L x y l x ==∑就是所要的n 次多项式,称为拉格朗日多项式。
由拉格朗日多项式计算的插值称为拉格朗日插值。
一般来讲,并不是多项式的阶数越高就越精确,一般采用三阶、二阶或一阶(线性)多项式,对相邻点进行分段插值。
2. 样条插值在分段插值时,会造成分段点处不光滑,如果要求在分段点处光滑,即不仅函数值相同,还要一阶导数和二阶导数相同,则构成三阶样条插值。
一般用于曲线绘制,数据估计等。
例 对21,[5,5](1)y x x =∈-+,用n=11个等分节点做插值运算,用m=21个等分插值点作图比较结果。
见inter.m 程序二、 曲线拟合 三、 给药方案 1. 问题一种新药用于临床必须设计给药方案,在快速静脉注射的给药方式下,就是要确定每次注射剂量多大,间隔时间多长.我们考虑最简单的一室模型,即整个机体看作一个房室,称为中心室,室内血液浓度是均匀的.注射后浓度上升,然后逐渐下降,要求有一个最小浓度1c 和一个最大浓度2c .设计给药浓度时,要使血药浓度保持在1c ~2c 之间.2. 假设(1)药物排向体外的速度与中心室的血药浓度成正比,比例系数是k(>0),称为排出速度.(2)中心室血液容积为常数V ,t=0的瞬间注入药物的剂量为d ,血药浓度立即为dV. 3. 建模设中心室血药浓度为c(t),满足微分方程(0)dckc dtd c V=-=用分离变量法解微分方程,有()ktd c te V-=(*) 4. 方案设计每隔一段时间τ,重复注入固定剂量D ,使血药浓度c(t)呈周期变化,并保持在1c ~2c 之间.如图:设初次剂量加大到D 0,易知0221,D Vc D Vc Vc ==-,2121()11ln[],()()ln c Vc t t t c t c k d k c τ=-=-= 那么,当12,c c 确定后,要确定给药方案0{,,}D D τ,就要知道参数V 和k .5. 由实验数据做曲线拟合确定参数值已知1210,25(/)c c g ml μ==,一次注入300mg 药物后,间隔一定ln lndc kt V=- 记12ln ,,lndy c a k a V==-=,则有 12y a t a =+求解过程见medicine_1.m得120.2347, 2.9943a a =-=,由d=300(mg)代入算出k=0.2347,V=15.02(L) 从而有0375.5(),225.3(), 3.9()D mg D mg τ===小时四、 口服给药方案 1. 问题口服给药相当于先有一个将药物从肠胃吸收入血液的过程,可简化为一个吸收室,一个中心室,记t 时刻,中心室和吸收室的血液浓度分别是1()()c t c t 和,容积分别是V ,V1,中心室的排除速度为k ,吸收速度为k1,且k,k1分别是中心室和吸收室血液浓度变化率与浓度的比例系数,t=0口服药物的剂量为d ,则有11111,(0)dc dk c c dt V =-= (1) 111,(0)0V dckc k c c dt V=-+= (2) 解方程(1)有111()k td c te V -=代入方程(2)有111()()k t kt k d c t e e V k k--=--其中三个参数1,,dk k b V=,可由下列数据拟合得到:(非线性拟合)。
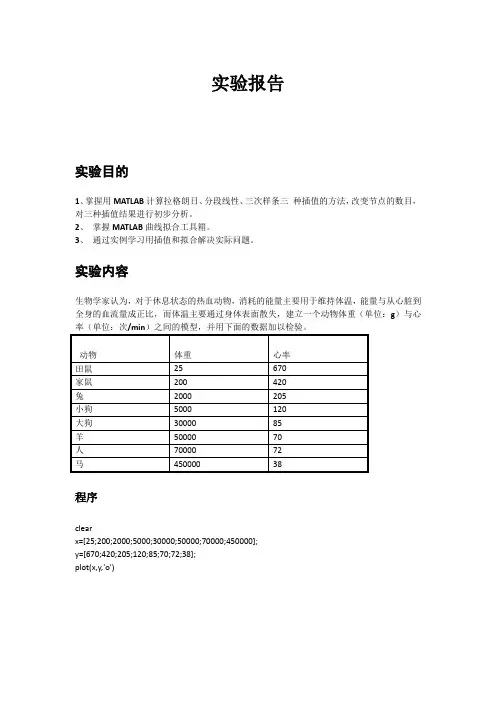
插值和拟合实验目的:了解数值分析建模的方法,掌握用Matlab进行曲线拟合的方法,理解用插值法建模的思想,运用Matlab一些命令及编程实现插值建模。
实验要求:理解曲线拟合和插值方法的思想,熟悉Matlab相关的命令,完成相应的练习,并将操作过程、程序及结果记录下来。
实验内容:一、插值1.插值的基本思想·已知有n +1个节点(xj,yj),j = 0,1,…, n,其中xj互不相同,节点(xj, yj)可看成由某个函数y= f (x)产生;·构造一个相对简单的函数y=P(x);·使P通过全部节点,即P (xk) = yk,k=0,1,…, n ;·用P (x)作为函数f ( x )的近似。
2.用MA TLAB作一维插值计算yi=interp1(x,y,xi,'method')注:yi—xi处的插值结果;x,y—插值节点;xi—被插值点;method—插值方法(‘nearest’:最邻近插值;‘linear’:线性插值;‘spline’:三次样条插值;‘cubic’:立方插值;缺省时:线性插值)。
注意:所有的插值方法都要求x是单调的,并且xi不能够超过x的范围。
练习1:机床加工问题每一刀只能沿x方向和y方向走非常小的一步。
表3-1给出了下轮廓线上的部分数据但工艺要求铣床沿x方向每次只能移动0.1单位.这时需求出当x坐标每改变0.1单位时的y坐标。
试完成加工所需的数据,画出曲线.步骤1:用x0,y0两向量表示插值节点;步骤2:被插值点x=0:0.1:15; y=y=interp1(x0,y0,x,'spline');步骤3:plot(x0,y0,'k+',x,y,'r')grid on答:x0=[0 3 5 7 9 11 12 13 14 15 ];y0=[0 1.2 1.7 2.0 2.1 2.0 1.8 1.2 1.0 1.6 ];x=0:0.1:15;y=interp1(x0,y0,x,'spline');plot(x0,y0,'k+',x,y,'r')grid on3.用MA TLAB作网格节点数据的插值(二维) z=inte rp2(x0,y0,z0,x,y,’method’)注:z—被插点值的函数值;x0,y0,z0—插值节点;x,y—被插值点;method—插值方法(‘nearest’:最邻近插值;‘linear’:双线性插值;‘cubic’:双三次插值;缺省时:双线性插值)。
数据拟合求解方程参数
数据拟合是一种常见的数学建模方法,它可以通过拟合给定数据点的函数形式,来求解方程中的参数。
本文将介绍数据拟合的基本原理和常用方法。
首先,我们需要明确问题的背景和目标。
假设我们有一组离散的数据点,我们希望找到一个函数,使得这个函数与这些数据点的拟合程度最好。
通过拟合得到的函数,我们可以进一步预测或分析相关的问题。
在数据拟合中,常用的函数形式包括线性函数、多项式函数、指数函数、对数函数等。
选择合适的函数形式是数据拟合的第一步。
通常情况下,我们可以根据数据的特点和问题的要求来选择合适的函数形式。
接下来,我们需要确定拟合的准则。
常见的拟合准则包括最小二乘法、最大似然估计等。
最小二乘法是一种常见且简单的拟合准则,它通过最小化实际观测值与拟合值之间的误差平方和来确定参数的
值。
最大似然估计则是一种统计方法,它通过最大化观测数据出现的概率来确定参数的值。
确定了函数形式和拟合准则后,我们可以通过数值计算的方法来求解方程中的参数。
常见的求解方法包括最小二乘法、非线性最小二乘法、最大似然估计等。
这些方法可以通过迭代的方式逐渐逼近最优解。
在实际的数据拟合过程中,我们还需要考虑数据的质量和噪声的影响。
如果数据存在较大的噪声或异常值,我们可以通过加权最小二乘法等方法来降低它们对拟合结果的影响。
总之,数据拟合求解方程参数是一种常见且重要的数学建模方法。
通过选择合适的函数形式、拟合准则和求解方法,我们可以得到与给定数据点拟合程度较好的函数,并进一步应用于相关问题的预测和分析中。
28中学数学研究2021年第1期(下)数学建模在高中数学课堂教学中的实践——“数据拟合”的课例及反思江苏省无锡市第一中学(214031) 何晨良刘峰摘要从一个具体的数据拟合实例岀发,探索数据拟合的一般流程.一个完整的数据拟合过程至少要包括作图、选择函数模型、求解函数模型、检验这4个步骤.从解决的实际问题来看,数据拟合既可以在基础学科中起到辅助作用,又 可以对对生产生活进行预测或控制.关键词 数学建模; 数据拟合; 校本课程《普通高中数学课程标准(2017版)》(以下简称“课标”) 指岀“数学是研究数量关系和空间形式的一门科学.数学源 于对现实世界的抽象,基于抽象结构,通过符号运算、形式推理、模型构建等,理解和表达现实世界中事物的本质、关系和 规律.数学与人类生活和社会发展紧密关联.数学不仅是运算和推理的工具,还是表达和交流的语言.数学承载着思想和文化,是人类文明的重要组成部分.数学是自然科学的重要基础,并且在社会科学中发挥越来越大的作用,数学的应 用已渗透到现代社会及人们日常生活的各个方面.随着现代科学技术特别是计算机科学、人工智能的迅猛发展,人们获 取数据和处理数据的能力都得到很大的提升,伴随着大数据时代的到来,人们常常需要对网络、文本、声音、图像等反映 的信息进行数字化处理,这使数学的研究领域与应用领域得到极大拓展.数学直接为社会创造价值,推动社会生产力的 发展m ”2019年11月29-30日,"全国第12届数学方法论与数学教育学术研讨会暨MM 课题实施30年纪念活动”在江苏省无锡市第一中学举行,笔者展示了一节“数据拟合”的观摩 课,荣获课堂观摩一等奖,受到了与会专家和老师的好评,现 将课堂教学实录分享给大家,望请指正.本文中所用图形计算器型号为HP Prime,以下简称图形 计算器.1课堂实录1.1引入教师: 现实世界中的实物都是相互联系、相互影响的, 反 映事物变化的变量之间就存在着一定的关系. 这些关系的发 现,通常是通过试验或实验测定得到一批数据,在经过分析 处理得到的.数据拟合就是研究变量之间这种关系,并给岀近似的数学表达式的一种方法.我们不妨从具体问题体验一下数据拟合的过程,首先我 们来看下例1.1.2例题示范与探究例1下表给岀了八大行星离太阳的距离和他们运行的周期,试建立这两组数据之间的关系.水星金星地球火星土星木星天王星海王星距离/1066km 57.9108.2149.6227.9778.3142728704497周期/d882253656874329107533066060150教师:你能否用数学的语言将问题翻译一下?学生1:如果把距离看成横坐标,周期看成纵坐标,这8组数据就是8个点的坐标,题目就是问这8个点满足的函数 解析式.教师:到目前为止,我们已经学习过哪些函数模型?学生2:我们目前学习过的函数模型有:一次函数模型:ky = kx + b(k = 0);反比例型函数模型:y =孑+ b(k = 0);二次函数模型:y = ax 2 + bx + c(a = 0);三次函数模 型:y = ax 3 + bx 2 + cx + d(a = 0);指数型函数模型:y = b • a x + c(b = 0,a > 0且a = 1);对数型函数模型: y = mlog a x + n(b = 0,a > 0且a = 1);幕函数型函数模型: y = ax ” + b(a = 0, n = 1).'基金项目:江苏省教育科学“十三五”规划课题“以高中数学为主导的跨学科教学研究”(B-a/2020/02/47)参考文献45-47.[3]王蔷.核心素养背景下英语阅读教学:问题、原则、目标和路径[J].[1] 朱昌宝.基于“ADDIE ”模型的数学单元教学设计的实践与思考[J].初中数学教与学,2019(9) : 35-37.[2] 朱昌宝.提升数学阅读能力的命题与教学[J].江苏教育,2017(10):英语学习,2017(2): 16-18.[4]朱林.透析教材中“阅读材料”内容分布渗入数学文化教育功能[J].初中数学教与学,2017(2) : 28-30.2021年第1期(下)中学数学研究29教师:在图形计算器中按Apps键进入主菜单,在主菜单中点击双变量统计,按Mun键,在C1中输入距离的前7个值,再依次在C2中输入周期中的前7个值(图1),点击Plot 键,得到了散点图(图2).图1图2教师:由这7个点的趋势,我们可以尝试选择哪个或哪些函数模型来拟合?老师示范操作时只输入了7个点的坐标,第8组数据并没有输入,为什么?学生:可选择二次函数、三次函数、指数型函数、幂函数型函数拟合.教师:点击Symb键,从图形计算器拟合的图像上看(图3-图11),除指数型函数模型明显不符外,其他函数模型都用可能,那到底哪个函数模型更合适呢?现在大家知道老师留着第8组数据的用途了吗?图3图4图5图7图8图9图10学生:(齐答)检验.教师:我们用第8组海王星的数据去验证,按CAS键,按1双变量统计,按2PredY键,输入4497,用二次函数拟合得到64292.2,用三次函数模型拟合得到54719.9,用幂函数模型拟合得到60108.0(图11),由这些数据,你能找到最为合适的函数模型了吗?题中两组数据的关系如何表达?学生4:很明显用幂函数模型模拟计算海王星的周期值60108与60150最为接近,也就是说用幂函数模型模拟岀的结果最好,用幂函数模拟岀的解析式为y—0.20019066x i-49948i°4a0.2x i-5.也就是说题中所给两组数据近似满足周期a0.2x x i'B(x表示距离).1.3归纳数据拟合的步骤教师:对于实际问题,我们首先要对问题中变化过程进行分析,收集相关数据,结合例1,我们可以小结岀数据拟合的一般步骤:(1)收集数据;⑵作图:根据已知数据,画岀散点图;(3)选择函数模型:一般是根据散点图的特征,联想哪些函数具有类似的图像特征,找岀几个比较接近的函数模型尝试;⑷求岀函数模型:求岀⑶中找到的几个函数模型的解析式;(5)检验:将⑷中找到的几个函数模型进行比较、验证,得到相对合适的函数模型;(6)应用:利用所求岀的函数模型解决问题.1.4知识链接函数y—0.2x i'5,这其实就是天文学、物理学中非常重要的开普勒第三定律的数学表达式,它揭示了“公转时间的平方与平均距离的立方成正比”这一天体运动规律.开普勒(Johannes Kepler,1571年-1630年),德国杰岀的天文学家、物理学家、数学家.他以数学的和谐性探索宇宙,在天文学方面做岀了巨大成就.开普勒在《宇宙谐和论》上的原始表述:绕以太阳为焦点的椭圆轨道运行的所有行星,其各自椭圆轨道半长轴的立方与周期的平方之比是一个常量.常见表述:绕同一中心天体的所有行星的轨道的半长轴的三次方(R3)跟它的公转周期的二次方(T2)的比值都相等,即R2—k,k为开普勒常数,这是一个只与被绕星体有30中学数学研究2021年第1期(下)关的常量.3开普勒在整理数据时发现,把R2作为横坐标,把T作为纵坐标,这些坐标所表示的各点大致连成一条直3线,因此他认为行星的运行周期T和R2成正比(其中2nR为轨道半径),并计算岀该直线的斜率为器M,即32n—莓R2,其中G为引力常量,其2006年国际推GM荐数值为G=6.67428x10-ii N-m2/kg2,M为中心天体质量.T其中开普勒求直线斜率的放法是最小二乘法,最小二乘法也是数据拟合的最基础的方法,用最小二乘法解决线性回归方程是我们高二将要学习的内容.1.5小组探究、展示问题:今年11月12日凌晨,当阿里巴巴集团宣布2019年11月11日天猫双十一购物节全天销售额为2684亿时,11 月12日当天有很多媒体质疑天猫双十一数据造假,老师收集了2009年至2018年这10年里天猫双十一的销售数据,数据如下:年份2009201020112012201320142015201620172018销售额/亿0.59.3652191350571912120716822135请同学们用以上数据建立适当的拟合模型,试说明天猫双十一数据是否有造假嫌疑.学生5:我们组将2009年至2018年这10年的销售数据作为10个点的坐标,用图形计算计算器分别尝试拟合了二次、三次函数、幂函数、指数函数模型,其中用二次函数模型拟合的解析式为y Q30.09x2-94.15x+70.36,用此解析式计算的2019年的销售额为2675.6亿,用三次函数模型拟合的解析式为y Q0.1562x3+27.513x2-82.266x+56.963,用此解析式计算的2019年的销售额为2688.9亿,2675.6亿、2688.9亿都比较接近天猫公布的销售额2684亿,我们小组认为部分媒体的怀疑有一定道理.教师:从数据上看部分媒体的怀疑确实有一定道理,但若天猫的数据没有造假,根据大家拟合的函数,我们还能做些什么?学生6:用拟合所得到的二次函数计算2020年的销售额为3273.5亿,用拟合得到的三次函数计算2020年的销售额为3301.5亿,我们可以预估2020年天猫的销售额将在3270至3300亿之间.1.6课堂小结这节课我们从一个具体的数据拟合实例岀发,探索数据拟合的一般流程.一个完整的数据拟合过程至少要包括作图、选择函数模型、求解函数模型、检验这4个步骤.从我们解决的实际问题来看,数据拟合既可以在基础学科中起到辅助作用,又可以对对生产生活进行预测或控制.希望通过这节课的学习,我们可以学会用数学的眼光观察世界,用数学的思维思考世界,用数学的语言表达世界,将数据拟合应用到更广阔的的学习、生活中去.2教学反思2.1核心素养不应停留在口号上“课标”指岀“数学学科核心素养包括:数学抽象、逻辑推理、数学建模、直观想象、数学运算和数据分析.”随着信息技术的飞速发展,数学辅助工具在教学中的运用逐渐受到重视,尤其在目前大数据时代背景下,在重视数学建模的基础上,在教学中借助数学辅助工具将为学生探索数学提供新的机会.核心素养不是教师教岀来的,而是在问题情境中借助问题解决的实践培育起来的闵整节课,师问生答,从例题的教师示范,学生模仿,再到练习的完全由学生小组探究,课堂逐步由“牵着学生走”变为“放开手让学生自己走”,由“教师主导”向“以学生为中心”转变,实现学生的自主学习,这也是课堂教学迈向核心素养的关键一步〔3〕.2.2对数学建模课程的思考与建议新课标对数学建模的要求,表明下一级段将在高中阶段全面推进数学建模的教学,但对于全国绝大部分高中而言,数学课程任然处于起步阶,很多一线教师将“应用题的练习”等价于“数学建模”,不能理解数学建模的内涵.另一方面,很多参与数学建模的教师普遍感觉可用的数学建模资源不够,使他们在教学中有“巧妇难为无米之炊”之感⑷针对以上思考,笔者给岀以下两点建议:第一,各高中学校加强对数学建模校本课程的开发,教师在平时的教学过程中重视适合高中生的数学建模素材的积累与案例的开发;第二,加强图形计算器等数字工具在数学建模中的运用,促使其对学生的学习产生积极的影响.参考文献[1]中华人民共和国教育部.普通高中数学课程标准(2017年版)[M].北京:人民教育出版社,2018:1-1;[2]钟启泉.基于核心素养的课程发展:挑战与课题[J].全球教育展望,2016(1):3-25;[3]吕增锋.牵着走,还是让学生自己走?一基于核心素养的数学课堂教学的思考[J].中学数学参考(上旬),2019(11):34-36;[4]黄英芬,颜宝瓶,龙红兰.从应用题到建模问题的回译——种开发数学建模素材的新思路[J].数学通报,2019,58(9):34-37.。
一组适合初三教学的数学建模案例——数据拟合模型数学建模案例之数据拟合模型数学建模是一门研究建立数学模型以及利用模型去研究问题的学科,它可以用来解决许多实际问题,为这些问题提供更好的解决方案,有效地提高工作效率。
数学建模作为一门新兴的学科已经成为初中生学习数学的重要组成部分,而对于初中生来说,学习数学建模将有助于培养他们的分析问题和解决问题的能力。
其中,数据拟合模型是建模学科中的一种重要的建模方式,也是初中生学习的一种重要内容。
数据拟合模型的基本思想是:通过对一定数据资料的分析,将其用规律曲线图形表示,以拟合这些数据,使之更接近实际运行情况。
在实际应用中,数据拟合是一种建模技术,它可以用来分析特定系统或指标的多种变化趋势,因此可以更好地预测未来的变化趋势和结果。
下面以一个实际的例子来介绍数据拟合模型在初三数学教学中的应用,具体如下:一家企业的一周的产品销售情况如下表所示:星期一-2500,星期二-3000,星期三-4000,星期四-3500,星期五-4500,星期六-5100,星期日-6000,请根据这些数据建立数据拟合模型,了解这家企业每周的产品销售情况。
首先,在构建数据拟合模型之前,需要根据上述数据分析出其变化趋势,它可以通过观察上述数据来判断:这些数据显示出了一个以上下缓冲为特征的曲线变化趋势。
其次,根据上述分析,可以利用它的特征,构建一个拟合函数来模拟上述变化趋势,具体的拟合函数可设为y=A·sin(k·x+b)+c,其中A、k、b、c是拟合模型的参数,它们的值可通过给定的数据点的拟合来进行计算。
同时,可以利用Excel等绘图工具,建立数据拟合模型,进行实际分析模型,从而更好地分析这家企业每周的产品销售情况,并进行有效的预测。
从上述案例可以看出,数据拟合模型中的介绍可以帮助初三学生更加系统的理解数据拟合的基本原理以及建模的具体方法,从而更好地应用到实践中。
总之,在初中数学教学中,引入数据拟合模型可以使学生更系统地掌握建模技术,也可以让学生更加实践性地学习数学,从而更有效地学习数学。