数学建模方法 拟合
- 格式:ppt
- 大小:494.00 KB
- 文档页数:48

数学模型拟合作业引言数学模型是数学与实际问题相结合的产物,通过建立数学模型能够对复杂的实际问题进行简化和抽象,使其更易于分析和求解。
在现实生活中,我们经常会遇到一些问题需要拟合一个数学模型,以便更好地了解问题的本质和规律。
本文将介绍数学模型拟合的基本概念、常用的拟合方法以及实际应用。
数学模型拟合的基本概念1.1 数学模型数学模型是利用数学语言和符号对实际问题进行抽象和描述的工具。
它可以通过一系列的数学方程来描述问题的属性、关系和行为,从而使问题更易于分析和求解。
数学模型通常包括数学模型的定义、变量的定义、约束条件和目标函数等要素。
1.2 拟合问题在实际问题中,我们通常会根据已知的数据或观测到的现象,试图通过建立一个数学模型来描述数据或现象之间的关系。
这个过程称为拟合,也被称为参数估计或函数逼近。
拟合问题的目标是找到一个数学模型,使得该模型与已知的数据或观测结果的残差最小化。
常用的拟合方法2.1 线性回归线性回归是最常用的拟合方法之一,它假设拟合函数与自变量之间存在一个线性关系。
线性回归问题可以通过最小二乘法来求解,即通过最小化残差平方和来确定拟合函数的参数。
2.2 非线性回归在实际问题中,往往存在非线性关系的情况,因此线性回归并不能完全拟合数据。
为了解决这个问题,可以使用非线性回归方法。
非线性回归方法包括多项式拟合、指数拟合、对数拟合等,通过将非线性函数线性化,再利用线性回归方法进行拟合。
2.3 曲线拟合曲线拟合是一种通过将一条曲线与数据点进行拟合的方法。
曲线拟合通常使用的函数包括多项式函数、指数函数、对数函数、幂函数等。
曲线拟合的目标是找到一条曲线,使得曲线与数据点之间的误差最小化。
2.4 插值拟合插值拟合是一种通过已知数据点之间的插值来拟合的方法。
插值拟合可以通过拉格朗日插值法、牛顿插值法等方法进行。
插值拟合的目标是找到一个函数,使得该函数经过已知的数据点。
实际应用3.1 经济学中的拟合问题在经济学中,拟合问题是非常常见的。

摘要冬青是一种寄生在大树上部树枝的药科植物。
本文主要研究每株大树上冬青的数量与大树年龄之间的关系。
本文主要是运用两种方法,一是线性化模型求解,二是非线性模型求解。
1.线性化求解,由于题目中的数据对参数是非线性的,因此要通过两边取对数的方法转化为线性模型,即εln ln ln ++=bx a y模型中的因变量y ln 对新的参数A 、B 是线性的。
运用MATLAB 进行线性拟合因而得到A 、B 的值,从而得到a 、b 的值从而得到回归方程x b e a yˆˆˆ= 2.非线性模型求解,题目中的数据对参数是非线性的,因此可以用非线性回归的方法直接估计模型中的参数。
模型的求解可以用MATLAB 统计工具箱中的命令进行,使用格式为:[beta,R,J]=nlinfit(x,Y,'f1',beta0)Nlinfit 函数可以对给出的数据进行非线性回归,确定出参数的值,从而得到回归方程x b e a yˆˆˆ= 关键词: 线性回归 非线性回归 nlinfit一.问题重述冬青是一种寄生在大树上部树枝的药科植物,它喜欢寄生在年轻的大树上,以模型Y=εbx ae ,ln ε~N(0,2σ)拟合数据,试求曲线回归方程()x b a yˆex p ˆˆ=。
二.基本假设1.每株大树的生长环境是一样;2.影响大树上冬青寄生的株数的环境因素也是一样。
三.符号说明四.问题分析由数据绘制出散点图如下:以大树的年龄x 为自变量、以每株大树上冬青寄生的株数y 为因变量,利用MATLAB 统计工具箱的plot 命令画出散点图如图1,使用程序见附录程序1图1 散点图下面可以用εbx ae y =拟合数据。
其中ε为随机误差。
这个模型是非线性的,因此要通过两边取对数将其变成线性的,即bx a y ++=εln ln ln 。
可以将其看成是一元线性方程:εln ln ++=Bx A y 。
则y ln 对x 是线性的。
输出b 为a ln 和b 的估计值,bint 为b 的置信区间,stats 为回归模型的检验统计量,分别为回归方程的决定系数2R ,统计量值F ,概率值p 。

数学实验与数学建模实验报告学院:南通大学理学院班级:信计111学号:姓名:实验名称:线性拟合与非线性拟合指导教师:填写日期:2013年11月5日实验五线性拟合与非线性拟合一、实验指导解读本实验的主要目的是了解迭代法,研究迭代数列的收敛性,学习线性方程组的求解以学习非线性方程组的求解。
本次实验是通过两个变量的多组记录数据利用最小二乘法寻求两个变量之间的函数关系。
两个变量之间的函数关系主要有两种:一是线性关系(一次函数);二是非线性关系(非一次的其它一元函数)。
因此本实验做两件事:一是线性拟合(习题1);二是非线性拟合(习题2)。
习题2是用多项式函数、指数函数、双曲函数等初等函数以及分段函数拟合。
二、实验基本方法与理论:(习题1)线性拟合修改、补充程序要说明拟合效果,主要从形(大多数散点是否在拟合曲线上或附近)与量(残差是否小)!计算残差的程序:假设对两个变量的多组记录数据已有程序biao={{x1,y1},{x2,y2},…,{xn,yn}}并且通过Fit得到线性拟合函数y=ax+b我们可以先定义函数(程序)f[x_]:=a*x+b再给出计算残差的程序dareta=Sum[(biao[[i ,2]]-f[biao[[i ,1]]])^2,{i ,1, n}]程序说明:biao[[i]]是提取表biao的第i行,即{xi,yi}biao[[i ,1]] 是提取表biao的第i行的第一个数, 即xibiao[[i ,2]] 是提取表biao的第i行的第一个数, 即yibiao[[i ,2]]-f[biao[[i ,1]]] 即yi-(a*xi+b)(习题2)非线性拟合修改、补充程序要说明拟合效果,主要从形(大多数散点是否在拟合曲线上或附近)与量(残差是否小)!计算残差的程序:假设对两个变量的多组记录数据已有程序biao={{x1,y1},{x2,y2},…,{xn,yn}}并且通过Fit得到非线性拟合函数y=f(x)我们可以先定义函数(程序)f[x_]:=再给出计算残差的程序dareta=Sum[(biao[[i ,2]]-f[biao[[i ,1]]])^2,{i ,1, n}]程序说明:biao[[i]]是提取表biao的第i行,即{xi,yi}biao[[i ,1]] 是提取表biao的第i行的第一个数, 即xibiao[[i ,2]] 是提取表biao的第i行的第一个数, 即yibiao[[i ,2]]-f[biao[[i ,1]]] 即yi-f(xi)三、实验的整体思路(1)对数据线性拟合1、先对习题1的十组数据线性拟合,并从形与量看拟合效果;2、对习题1的十组数据中的9组数据线性拟合,并从形与量看拟合效果;3、对习题1的十组数据中的6组数据线性拟合,并从形与量看拟合效果。

数学建模方法大汇总数学建模是数学与实际问题相结合,通过建立数学模型来解决实际问题的一种方法。
在数学建模中,常用的方法有很多种,下面将对常见的数学建模方法进行大汇总。
1.描述性统计法:通过总结、归纳和分析数据来描述现象和问题,常用的统计学方法有平均值、标准差、频率分布等。
2.数据拟合法:通过寻找最佳拟合曲线或函数来描述和预测数据的规律,常用的方法有最小二乘法、非线性优化等。
3.数理统计法:通过样本数据对总体参数进行估计和推断,常用的方法有参数估计、假设检验、方差分析等。
4.线性规划法:建立线性模型,通过线性规划方法求解最优解,常用的方法有单纯形法、对偶理论等。
5.整数规划法:在线性规划的基础上考虑决策变量为整数或约束条件为整数的情况,常用的方法有分支定界法、割平面法等。
6.动态规划法:通过递推关系和最优子结构性质建立动态规划模型,通过计算子问题的最优解来求解原问题的最优解,常用的方法有最短路径算法、最优二叉查找树等。
7.图论方法:通过图的模型来描述和求解问题,常用的方法有最小生成树、最短路径、网络流等。
8.模糊数学法:通过模糊集合和隶属函数来描述问题,常用的方法有模糊综合评价、模糊决策等。
9.随机过程法:通过概率论和随机过程来描述和求解问题,常用的方法有马尔可夫过程、排队论等。
10.模拟仿真法:通过构建系统的数学模型,并使用计算机进行模拟和仿真来分析问题,常用的方法有蒙特卡洛方法、事件驱动仿真等。
11.统计回归分析法:通过建立自变量与因变量之间的关系来分析问题,常用的方法有线性回归、非线性回归等。
12.优化方法:通过求解函数的最大值或最小值来求解问题,常用的方法有迭代法、梯度下降法、遗传算法等。
13.系统动力学方法:通过建立动力学模型来分析系统的演化过程,常用的方法有积分方程、差分方程等。
14.图像处理方法:通过数学模型和算法来处理和分析图像,常用的方法有小波变换、边缘检测等。
15.知识图谱方法:通过构建知识图谱来描述和分析知识之间的关系,常用的方法有图论、语义分析等。


数学建模中的参数拟合方法数学建模是研究实际问题时运用数学方法建立模型,分析和预测问题的一种方法。
在建立模型的过程中,参数拟合是非常重要的一环。
所谓参数拟合,就是通过已知数据来推算模型中的未知参数,使模型更加精准地描述现实情况。
本文将介绍数学建模中常用的参数拟合方法。
一、最小二乘法最小二乘法是一种常用的线性和非线性回归方法。
该方法通过最小化误差的平方和来估计模型参数。
同时该方法的优点在于可以使用简单的数学公式解决问题。
最小二乘法的基本思想可以简单地表示如下:对于给定的数据集合,设其对应的观测值集合为y,$y_1,y_2,...,y_n$,对应的自变量集合为x,$x_1,x_2,...,x_n$,则目标是找到一组系数使得拟合曲线最接近实际数据点。
通常拟合曲线可以用如下所示的线性方程表示:$$f(x)=a_0+a_1x+a_2x^2+...+a_kx^k$$其中,k为拟合曲线的阶数,$a_i$表示第i个系数。
最小二乘法的目标即为找到一组系数${a_0,a_1,...,a_k}$,使得曲线拟合残差平方和最小:$$S=\sum_{i=1}^{n}(y_i-f(x_i))^2$$则称此时求得的拟合数学模型为最小二乘拟合模型。
最小二乘法在实际问题中应用广泛,如线性回归分析、非线性回归分析、多项式拟合、模拟建模等领域。
对于非线性模型,最小二乘法的数学公式比较复杂,需要使用计算机编程实现。
二、梯度下降法梯度下降法是一种优化算法,通过求解函数的导数,从而找到函数的最小值点。
在数学建模中,梯度下降法可以用于非线性回归分析,最小化误差函数。
梯度下降法的基本思想为:在小区间范围内,将函数$f(x)$视为线性的,取其一阶泰勒展开式,在此基础上进行优化。
由于$f(x)$的导数表示$f(x)$函数值增大最快的方向,因此梯度下降法可以通过调整参数的值,逐渐朝向函数的最小值点移动。
具体地,对于给定的数据集合,设其对应的观测值集合为y,$y_1,y_2,...,y_n$,对应的自变量集合为x,$x_1,x_2,...,x_n$,则目标是找到一组系数使得拟合曲线最接近实际数据点。

数学建模数据拟合例题解析近年来,数学建模在各个领域得到了广泛的应用,其中数据拟合作为数学建模中重要的一环,更是被广泛应用于实际问题中。
本文将以一个例题为例,通过建模和代码的方法,解析数据拟合的过程,帮助读者更好地理解和应用数据拟合的方法。
1. 问题描述假设我们有一组实验数据,数据中包含了一个变量x和一个变量y,我们想通过这组实验数据,建立一个数学模型来描述x和y之间的关系,并且用这个模型来预测其他x对应的y值。
2. 数据分析我们需要对实验数据进行分析,观察数据的分布规律以及x和y之间的关系。
通常情况下,我们可以通过绘制散点图的方式来直观地观察数据的分布情况。
3. 数据拟合模型的选择在观察了实验数据的分布规律之后,我们需要选择一个适合的数据拟合模型来描述x和y之间的关系。
常用的数据拟合模型包括线性回归模型、多项式拟合模型、指数拟合模型、对数拟合模型等。
在选择模型时,需要考虑模型的复杂程度、拟合效果以及实际问题的需求。
4. 模型建立选择了数据拟合模型之后,我们需要利用实验数据来建立模型,通常可以通过最小二乘法或者最大似然估计的方法来确定模型的参数。
以线性回归模型为例,假设模型为y=ax+b,我们需要通过最小二乘法来确定参数a和b的取值,使得模型能够最好地拟合实验数据。
5. 模型评估建立模型之后,我们需要对模型进行评估,以确定模型的拟合效果。
常用的评估指标包括决定系数R^2、均方误差MSE等。
通过这些评估指标,我们可以了解模型的拟合效果如何,并且对模型进行优化和改进。
6. 模型预测我们可以利用建立的模型来进行预测,预测其他x对应的y值。
通过模型预测,我们可以更好地理解实验数据中x和y之间的关系,从而为实际问题的决策提供支持。
通过以上的解析,我们可以清楚地了解了数据拟合的整个过程,包括数据分析、模型选择、模型建立、模型评估以及模型预测等环节。
通过这些方法和步骤,我们可以更好地理解和应用数据拟合的方法,在实际问题中更好地解决实际问题。

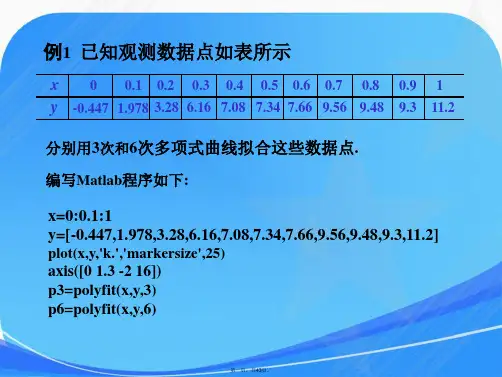
数学建模常见的⼀些⽅法【04拟合算法】@⽬录数学建模常见的⼀些⽅法1. 拟合算法与插值问题不同,在拟合问题中不需要曲线⼀定经过给定的点。
拟合问题的⽬标是寻求⼀个函数(曲线),使得该曲线在某种准则下与所有的数据点最为接近,即曲线拟合的最好(最⼩化损失函数)。
1.1 插值和拟合的区别 插值算法中,得到的多项式f(x)要经过所有样本点。
但是如果样本点太多,那么这个多项式次数过⾼,会造成。
尽管我们可以选择分段的⽅法避免这种现象,但是更多时候我们更倾向于得到⼀个确定的曲线,尽管这条曲线不能经过每⼀个样本点,但只要保证误差⾜够⼩即可,这就是拟合的思想。
(拟合的结果是得到⼀个确定的曲线)1.2 求解最⼩⼆乘法1.3 Matlab求解最⼩⼆乘测试数据:x =4.20005.90002.70003.80003.80005.60006.90003.50003.60002.90004.20006.10005.50006.60002.90003.30005.90006.00005.6000>> yy =8.400011.70004.20006.10007.900010.200013.20006.60006.00004.60008.400012.000010.300013.30004.60006.700010.800011.50009.9000计算代码:>> plot(x,y,'o')>> % 给x和y轴加上标签>> xlabel('x的值')>> ylabel('y的值')>> n = size(x,1);>> k = (n*sum(x.*y)-sum(x)*sum(y))/(n*sum(x.*x)-sum(x)*sum(x))>> b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/(n*sum(x.*x)-sum(x)*sum(x))>> hold on % 继续在之前的图形上来画图形>> grid on % 显⽰⽹格线>> f=@(x) k*x+b; % 函数线>> fplot(f,[2.5,7]); % 设置显⽰范围>> legend('样本数据','拟合函数','location','SouthEast')计算过程:>> plot(x,y,'o')>> % 给x和y轴加上标签>> xlabel('x的值')>> ylabel('y的值')>> n = size(x,1);>> n*sum(x.*y)-sum(x)*sum(y)ans = 1.3710e+03>> n*sum(x.*x)-sum(x)*sum(x)ans = 654.4600>> k = (n*sum(x.*y)-sum(x)*sum(y))/(n*sum(x.*x)-sum(x)*sum(x))k = 2.0948>> b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/(n*sum(x.*x)-sum(x)*sum(x))b = -1.0548>> hold on>> grid on>> f=@(x) k*x+b;>> fplot(f,[2.5,7]);>> legend('样本数据','拟合函数','location','SouthEast')1.4 如何评价拟合的好坏线性函数是指对参数为线性(线性于参数)在函数中,参数仅以⼀次⽅出现,且不能乘以或除以其他任何的参数,并不能出现参数的复合函数形式。

mathcad指数拟合
指数拟合是一种常见的数学建模方法,用于拟合具有指数函数
关系的数据。
Mathcad是一种流行的工程计算软件,它提供了强大
的数学建模和数据分析工具,包括指数拟合功能。
在Mathcad中进行指数拟合,可以按照以下步骤进行:
1. 输入数据,首先,将需要进行指数拟合的数据输入到Mathcad工作表中。
这些数据可以是实验测量得到的,或者是需要
进行拟合的现有数据。
2. 选择拟合函数,在Mathcad中,选择“Curve Fitting”工具,然后选择指数函数作为拟合函数类型。
指数函数通常表示为y
= a exp(b x),其中a和b是拟合参数,x是自变量,y是因变量。
3. 进行拟合,在Mathcad中,选择拟合函数后,可以使用拟合
工具对数据进行拟合。
Mathcad会自动计算最优的拟合参数a和b,
以最小化实际数据与拟合曲线之间的残差。
4. 分析拟合结果,完成拟合后,可以对拟合结果进行进一步分
析。
Mathcad通常会提供拟合参数的置信区间、拟合曲线与实际数
据的对比图等信息,以帮助用户评估拟合的质量和可靠性。
5. 应用拟合结果,最后,根据拟合结果可以进行进一步的预测、分析或者其他应用。
拟合结果可以用于预测未来的数据趋势,或者
用于分析数据之间的相关性等。
总之,Mathcad提供了方便易用的指数拟合工具,可以帮助工
程师和科学家对实验数据进行指数函数拟合,并进行进一步的数据
分析和应用。

插值和拟合实验目的:了解数值分析建模的方法,掌握用Matlab进行曲线拟合的方法,理解用插值法建模的思想,运用Matlab一些命令及编程实现插值建模。
实验要求:理解曲线拟合和插值方法的思想,熟悉Matlab相关的命令,完成相应的练习,并将操作过程、程序及结果记录下来。
实验内容:一、插值1.插值的基本思想·已知有n +1个节点(xj,yj),j = 0,1,…, n,其中xj互不相同,节点(xj, yj)可看成由某个函数y= f (x)产生;·构造一个相对简单的函数y=P(x);·使P通过全部节点,即P (xk) = yk,k=0,1,…, n ;·用P (x)作为函数f ( x )的近似。
2.用MA TLAB作一维插值计算yi=interp1(x,y,xi,'method')注:yi—xi处的插值结果;x,y—插值节点;xi—被插值点;method—插值方法(‘nearest’:最邻近插值;‘linear’:线性插值;‘spline’:三次样条插值;‘cubic’:立方插值;缺省时:线性插值)。
注意:所有的插值方法都要求x是单调的,并且xi不能够超过x的范围。
练习1:机床加工问题每一刀只能沿x方向和y方向走非常小的一步。
表3-1给出了下轮廓线上的部分数据但工艺要求铣床沿x方向每次只能移动0.1单位.这时需求出当x坐标每改变0.1单位时的y坐标。
试完成加工所需的数据,画出曲线.步骤1:用x0,y0两向量表示插值节点;步骤2:被插值点x=0:0.1:15; y=y=interp1(x0,y0,x,'spline');步骤3:plot(x0,y0,'k+',x,y,'r')grid on答:x0=[0 3 5 7 9 11 12 13 14 15 ];y0=[0 1.2 1.7 2.0 2.1 2.0 1.8 1.2 1.0 1.6 ];x=0:0.1:15;y=interp1(x0,y0,x,'spline');plot(x0,y0,'k+',x,y,'r')grid on3.用MA TLAB作网格节点数据的插值(二维) z=inte rp2(x0,y0,z0,x,y,’method’)注:z—被插点值的函数值;x0,y0,z0—插值节点;x,y—被插值点;method—插值方法(‘nearest’:最邻近插值;‘linear’:双线性插值;‘cubic’:双三次插值;缺省时:双线性插值)。
Matlab数学建模学习笔记——插值与拟合⽬录插值与拟合插值和拟合的区别图⽚取⾃知乎⽤户yang元祐的回答插值:函数⼀定经过原始数据点。
假设f(x)在某区间[a,b]上⼀系列点上的值y_i=f(x_i),i=0,1,\dots,n。
插值就是⽤较简单、满⾜⼀定条件的函数\varphi(x)去代替f(x)。
插值函数满⾜条件\varphi(x_i)=y_i,i=0,1,\dots,n拟合:⽤⼀个函数去近似原函数,不要求过已知数据点,只要求在某种意义下它在这些点上的总偏差最⼩。
插值⽅法分段线段插值分线段插值就是将每两个相邻的节点⽤直线连起来,如此形成的⼀条折线就是就是分段线性插值函数,记作I_n(x),它满⾜I_n(x_i)=y_i,且I_n(x)在每个⼩区间[x_i,x_{i+1}]上是线性函数(i=0,1\dots,n-1)。
I_n(x)可以表⽰为I_n(x)=\sum_{i=0}^n y_il_i(x),其中l_i(x)= \begin{cases} \frac{x-x_{i-1}}{x_i-x_{i-1}},&x\in [x_{i-1},x_i],i \neq 0,\\ \frac{x-x_{i+1}}{x_i-x_{i+1}},&x\in [x_i,x_{i+1}],i \neq n,\\ 0,&其他 \end{cases}I_n(x)有良好的收敛性,即对x\in [a,b],有\lim _{n \rightarrow \infin}I_n(x)=f(x)⽤I_n(x)计算x点的插值的时候,只⽤到x左右的两个点,计算量与节点个数n⽆关。
但是n越⼤,分段越多,插值误差越⼩。
拉格朗⽇插值多项式朗格朗⽇(Lagrange)插值的基函数为\begin{aligned} l_i(x)&=\frac{(x-x_0)\cdots(x-x_{i-1})(x-x_{i+1})\cdots(x-x_n)}{(x_i-x_0)\cdots(x_i-x_{i-1})(x_i-x_{i+1})\cdots(x_i-x_n)}\\ &= \prod_{j=0\\j\neq i}^{n} \frac{x-x_j}{x_i -x_j},i=0,1,\cdots,n。
一组适合初三教学的数学建模案例——数据拟合模型数学建模案例之数据拟合模型数学建模是一门研究建立数学模型以及利用模型去研究问题的学科,它可以用来解决许多实际问题,为这些问题提供更好的解决方案,有效地提高工作效率。
数学建模作为一门新兴的学科已经成为初中生学习数学的重要组成部分,而对于初中生来说,学习数学建模将有助于培养他们的分析问题和解决问题的能力。
其中,数据拟合模型是建模学科中的一种重要的建模方式,也是初中生学习的一种重要内容。
数据拟合模型的基本思想是:通过对一定数据资料的分析,将其用规律曲线图形表示,以拟合这些数据,使之更接近实际运行情况。
在实际应用中,数据拟合是一种建模技术,它可以用来分析特定系统或指标的多种变化趋势,因此可以更好地预测未来的变化趋势和结果。
下面以一个实际的例子来介绍数据拟合模型在初三数学教学中的应用,具体如下:一家企业的一周的产品销售情况如下表所示:星期一-2500,星期二-3000,星期三-4000,星期四-3500,星期五-4500,星期六-5100,星期日-6000,请根据这些数据建立数据拟合模型,了解这家企业每周的产品销售情况。
首先,在构建数据拟合模型之前,需要根据上述数据分析出其变化趋势,它可以通过观察上述数据来判断:这些数据显示出了一个以上下缓冲为特征的曲线变化趋势。
其次,根据上述分析,可以利用它的特征,构建一个拟合函数来模拟上述变化趋势,具体的拟合函数可设为y=A·sin(k·x+b)+c,其中A、k、b、c是拟合模型的参数,它们的值可通过给定的数据点的拟合来进行计算。
同时,可以利用Excel等绘图工具,建立数据拟合模型,进行实际分析模型,从而更好地分析这家企业每周的产品销售情况,并进行有效的预测。
从上述案例可以看出,数据拟合模型中的介绍可以帮助初三学生更加系统的理解数据拟合的基本原理以及建模的具体方法,从而更好地应用到实践中。
总之,在初中数学教学中,引入数据拟合模型可以使学生更系统地掌握建模技术,也可以让学生更加实践性地学习数学,从而更有效地学习数学。
数学建模曲线拟合模型在数据分析与预测中,曲线拟合是一个重要的步骤。
它可以帮助我们找到数据之间的潜在关系,并为未来的趋势和行为提供有价值的洞察。
本篇文章将深入探讨数学建模曲线拟合模型的各个方面,包括数据预处理、特征选择、模型选择、参数估计、模型评估、模型优化、模型部署、错误分析和调整等。
一、数据预处理数据预处理是任何数据分析过程的第一步,对于曲线拟合尤为重要。
这一阶段的目标是清理和准备数据,以便更好地进行后续分析。
数据预处理包括检查缺失值、异常值和重复值,以及可能的规范化或归一化步骤,以确保数据在相同的尺度上。
二、特征选择特征选择是选择与预测变量最相关和最有信息量的特征的过程。
在曲线拟合中,特征选择至关重要,因为它可以帮助我们确定哪些变量对预测结果有显著影响,并简化模型。
有多种特征选择方法,如基于统计的方法、基于模型的方法和集成方法。
三、模型选择在完成数据预处理和特征选择后,我们需要选择最适合数据的模型。
有许多不同的曲线拟合模型可供选择,包括多项式回归、指数模型、对数模型等。
在选择模型时,我们应考虑模型的预测能力、解释性以及复杂性。
为了选择最佳模型,可以使用诸如交叉验证和网格搜索等技术。
四、参数估计在选择了一个合适的模型后,我们需要估计其参数。
参数估计的目标是最小化模型的预测误差。
有多种参数估计方法,包括最大似然估计和最小二乘法。
在实践中,最小二乘法是最常用的方法之一,因为它可以提供最佳线性无偏估计。
五、模型评估在参数估计完成后,我们需要评估模型的性能。
这可以通过使用诸如均方误差(MSE)、均方根误差(RMSE)和决定系数(R²)等指标来完成。
我们还可以使用诸如交叉验证等技术来评估模型的泛化能力。
此外,可视化工具(如残差图)也可以帮助我们更好地理解模型的性能。
六、模型优化如果模型的性能不理想,我们需要对其进行优化。
这可以通过多种方法实现,包括增加或减少特征、更改模型类型或调整模型参数等。
数据拟合作业小组成员:谭洪莲 2007211736 李志雄 2007211822 李小宁 2007211722 题目一:直接拟合。
法一:将身长和胸围相加,再与重量直接拟合,选择拟合效果最好的:第一步:在Matlab命令窗口输入cftool 执行得到拟合工具箱第二步:创建一个名为opt_us_fish的M文件执行后拟合,选择最佳的,得到结果如下:Warnings during fitting:Equation is badly conditioned. Remove repeated data pointsor try centering and scaling.Linear model Poly4:f(x) = p1*x^4 + p2*x^3 + p3*x^2 + p4*x + p5Coefficients (with 95% confidence bounds):p1 = 6.9e-011 (-2.238e-010, 3.618e-010) p2 = -2.549e-007 (-1.344e-006, 8.346e-007) p3 = 0.0003309 (-0.001117, 0.001778) p4 = -0.151 (-0.9579, 0.6559)p5 = 74.47 (-84.11, 233.1)Goodness of fit:SSE: 1.161R-square: 0.9979Adjusted R-square: 0.995RMSE: 0.6221拟合结果:法二:将身长与胸围相乘,再与重量直接拟合,选择拟合效果最好的,结果如下:(步骤同上)Warnings during fitting:Equation is badly conditioned. Remove repeated data pointsor try centering and scaling.Linear model Poly4:f(x) = p1*x^4 + p2*x^3 + p3*x^2 + p4*x + p5Coefficients (with 95% confidence bounds):p1 = 3.195e-009 (-4.077e-009, 1.047e-008)p2 = -1.164e-005 (-3.87e-005, 1.542e-005) p3 = 0.01518 (-0.02077, 0.05113)p4 = -7.549 (-27.59, 12.49)p5 = 1935 (-2004, 5874)Goodness of fit:SSE: 716.1R-square: 0.9986Adjusted R-square: 0.9968RMSE: 15.45拟合效果:题目二:首先利用机理分析建立模型。