重差分法运行和示例
- 格式:docx
- 大小:100.37 KB
- 文档页数:4

三重差分法(triple-difference method)是一种常用的计量经济学方法,用于评估政策或事件对特定群体或地区的影响。
而全球价值链(global value chain)则是指跨国企业通过全球分工和合作,将产品和服务的不同环节分别分布在不同国家和地区,形成一个全球性的产业链。
三重差分法在全球价值链研究中常被用来衡量全球价值链对国家、地区或产业的影响。
它通过对比不同地区或国家在全球价值链中的地位和参与程度,以及相应的政策或事件对其产生的影响,来评估全球价值链对经济增长、就业、贸易等方面的影响。
具体而言,三重差分法的步骤如下:
1. 第一重差分:对照组和处理组的比较。
选择两个或多个地区或国家作为对照组和处理组,对于处理组,通常是发生了某种政策或事件,而对照组没有发生相同的政策或事件。
比较这两组的差异,可以初步估计出政策或事件的影响。
2. 第二重差分:时间差分。
通过观察同一地区或国家在政策或事件发生前后的差异,消除了地区或国家固有的差异,以更准确地评估政策或事件的影响。
3. 第三重差分:全球价值链差分。
在第一和第二重差分的基础上,将全球价值链的参与程度视为一个关键变量。
通过对比不同地区或国家在全球价值链中的地位和参与程度的差异,可以更精确地评估全球价值链对经济增长、就业、贸易
等方面的影响。
通过运用三重差分法,研究人员可以更准确地评估全球价值链对国家、地区或产业的影响,并为政策制定者提供有针对性的政策建议。
然而,三重差分法的使用也需要注意数据的可靠性和合理性,以及对其他潜在因素的控制,以确保研究结果的准确性和可靠性。

双重差分法的stata命令-回复双重差分法(Double Difference method)是一种在处理含有面板数据(Panel Data)的实证研究中常用的统计方法。
该方法通过观察同一实体在时间上的变化和不同实体之间的差异,来解决内生性(Endogeneity)的问题。
在Stata软件中,有一些常用的命令可以实施双重差分法分析,包括`xtreg`、`areg`和`reghdfe`等。
本文将一步一步地回答关于Stata命令的使用问题,并介绍其背后的原理。
首先,我们需要了解何时应该使用双重差分法。
双重差分法通常用于面板数据的因果推断分析,特别适用于研究政策决策对实体间变量的影响。
例如,假设我们想研究一项政策改革对不同地区的经济增长率的影响。
我们需要收集每个地区多年的经济增长数据,并观察政策改革前后的变化。
双重差分法将帮助我们控制因其他潜在因素带来的内生性问题,以更准确地评估政策改革的影响。
接下来,我们将介绍如何使用Stata的命令实施双重差分法分析。
首先,我们需要加载面板数据,并确保数据已经按照实体和时间进行排序。
statause "面板数据文件名.dta", clear然后,我们可以使用`xtreg`命令来运行双重差分法。
`xtreg`命令是Stata 中用于拟合面板数据固定效应模型的命令。
stataxtreg 因变量自变量1 自变量2 自变量3, fe vce(cluster 实体标识)在上述命令中,`因变量`代表面板数据中的被解释变量,`自变量1`至`自变量3`代表我们感兴趣的解释变量。
`fe`选项表示拟合固定效应模型,`vce(cluster 实体标识)`选项用于计算异方差稳健的标准误。
另外一种可看作是`xtreg`的替代命令是`areg`。
这两个命令的使用方法非常相似,但是它们处理固定效应模型的原理略有不同。
`areg`命令假设实体固定效应与时间固定效应被完全包含在因变量和解释变量中。

双重差分事件研究法stata命令
双重差分事件研究法是一种常用的计量经济学方法,用于评估政策或干预措施对某个群体或地区的影响。
本文介绍如何在Stata中使用双重差分事件研究法进行数据分析。
双重差分事件研究法的核心思想是对比两个时间点和两个群体之间的差异,以确定政策或干预措施的效果。
具体地,研究者需要分别选择一个实验组和一个对照组,然后在政策实施前后分别测量两组的指标,比较差异来评估政策的影响。
在Stata中,实现双重差分事件研究法需要用到两个命令:diff 和xtreg。
其中,diff用于计算差分值,xtreg用于拟合混合效应模型。
下面是一个基本的Stata代码示例:
diff y, t(1) i(group) // 计算差分值
xtreg ydiff t i.group, fe // 拟合混合效应模型其中,y代表被观测变量,t代表时间,group代表实验组和对照组的二元变量。
diff命令会计算每个群体在两个时间点之间的差分值,存储在ydiff变量中。
然后,xtreg命令会拟合混合效应模型,其中t和group作为固定效应,ydiff作为因变量。
除了基本的命令,研究者还可以使用其他Stata命令进行进一步的分析,例如xtsum、xtline、xtgraph等。
这些命令可以帮助研究者更好地理解数据,并进行可视化展示。
总之,双重差分事件研究法是一种有效的计量经济学方法,可以用于评估政策或干预措施的效果。
在Stata中,研究者可以使用diff
和xtreg命令进行数据分析,同时结合其他命令进行进一步的分析和可视化展示。

二重差分法具体实例二重差分法是一种常用的数据挖掘和机器学习方法,它通过对原始数据进行多次差分,来提取数据中的特征信息。
二重差分法具体实例如下:假设我们有一组电子表格数据,其中每行代表一个学生,每列代表一个科目。
每个学生每门科目都有一個成绩。
我们的目标是根据学生的成绩,寻找不同成绩之间的差异。
首先,我们使用二重差分法,计算学生成绩的平均值和标准差。
我们发现,不同成绩之间的平均值有很大的差异,而标准差则相对较小。
这是因为在成绩较高和较低的学生中,平均成绩较高,而标准差则相对较小,说明这些学生的成绩更加离散。
接下来,我们使用二重差分法,计算不同成绩之间的差异。
我们发现,成绩差异主要体现在80分到100分之间的学生较多,而60分到80分之间的学生较少。
这是由于,在成绩较高和较低的学生中,80分到100分之间的学生数量较多,而60分到80分之间的学生数量较少。
然后,我们使用二重差分法,计算不同科目之间的差异。
我们发现,不同科目之间的平均成绩差异不大,而标准差则相对较小。
这是由于,在学生成绩中,不同科目之间的成绩差异相对较小,而平均成绩则相对较大。
通过以上三个方面的分析,我们得出了一些结论。
首先,成绩较高的学生,成绩更加离散;其次,不同科目之间的平均成绩相对较小,而标准差则相对较大;最后,不同科目之间的成绩差异相对较小。
基于以上分析,我们可以提出一个二重差分法的应用场景:根据学生成绩,为学生推荐更适合的科目。
我们可以根据学生的平均成绩和标准差,为学生推荐一些相对较为合适的科目。
这样,学生可以选择自己擅长的科目,提高学习效果和兴趣。
此外,我们还可以根据不同科目之间的差异,为学生推荐一些具有较大学习难度的科目。
这样,学生可以在学习过程中,感受到一定的挑战,提高自己的学习积极性和动力。
总之,二重差分法是一种非常有用的数据挖掘和机器学习方法。
通过它可以提取数据中的特征信息,为我们提供有价值的信息和启示。
在实际应用中,我们可以根据需要选择不同的特征,以达到更好的数据挖掘和机器学习效果。

DID双重差分法的原理和方法双重差分法(DID)是一种在计量经济学中常用的估计因果效应的方法。
它能够在实证研究中有效地处理因果推断中的内生性问题,尤其在面板数据的分析中得到广泛应用。
本文将详细介绍DID方法的原理和应用方法。
一、DID方法的原理DID方法的核心原理是利用面板数据的时间和处理组别维度,通过比较处理组和对照组的差异来估计因果效应。
简而言之,DID方法通过比较处理组在政策干预前后的变化,和同期对照组的变化差异,来估计政策对处理组的因果效应。
为了更好地理解DID方法的原理,我们以一个实际案例为例进行说明。
假设地区实施了一项新的政策措施(如教育),我们想要评估这项政策对学生学习成绩的影响。
我们需要一个对照组和一个处理组,对照组是未接受教育的地区,处理组是接受教育的地区。
在DID方法中,我们同时比较了政策干预前后两个组别的差异。
具体地,我们比较了两个时间点的学生成绩差异:政策实施前的学生成绩差异(处理组与对照组),以及政策实施后的学生成绩差异(处理组与对照组)。
通过比较这两个时间点的差异,我们可以估计政策对学生成绩的因果效应。
二、DID方法的应用方法在实际应用中,DID方法的步骤可以总结如下:1.确定处理组和对照组:根据研究问题和数据可用性,选择合适的处理组和对照组。
处理组是接受政策的群体,对照组是未接受政策的群体。
2.选择合适的时期:确定政策实施的时间点,并选择合适的时间段进行分析。
通常我们需要在政策实施前后收集足够的数据,以便比较两个时期的差异。
3. 建立DID回归模型:为了估计因果效应,我们需要建立DID回归模型。
基本的DID模型可以表示为:Y_it = α + β*T_t + γ*D_i +δ*(T_t * D_i) + ε_i t。
其中,Y_it是观测单位i在时间t的因变量;T_t是时间指标,取1表示政策实施后,取0表示政策实施前;D_i是处理组指标,取1表示处理组,取0表示对照组;α是截距项;β、γ、δ分别是政策效应、处理组效应和DID效应的系数;ε_it是误差项。

双重差分法(DID)是一种常见的计量经济学方法,用于评估政策或其他干预措施对目标变量的影响。
下面是一个使用DID方法的例子和代码:假设我们想研究某项政策对企业生产力的影响。
我们可以选择两个时间点,分别代表政策实施前后的状态。
然后,我们可以找到在这两个时间点都存在的企业,并将它们分为实验组和对照组。
对于实验组,我们将该政策应用于企业;对于对照组,我们不应用该政策。
最后,我们比较实验组和对照组在政策实施前后生产力的变化,以评估该政策的影响。
以下是使用Stata实现DID方法的代码示例:```do filesysuse "data.dta", clear// 定义时间变量timevar t// 定义处理变量(虚拟变量)egen did = 0replace did = 1 if policy == 1// 定义因变量egen productivity = log(sales)// 进行 DID 分析DID productivity did time, absorb(time)```在上述代码中,我们首先使用`sysuse`命令加载数据集。
然后,我们定义了时间变量`t`和处理变量`did`,其中`did`表示是否应用了政策。
接着,我们定义了因变量`productivity`,它是企业生产力的对数。
最后,我们使用`DID`命令进行双重差分分析,其中`productivity`是因变量,`did`是处理变量,`time`是时间变量,`absorb(time)`表示时间变量被吸收到模型中。
请注意,这只是一个简单的示例,实际应用中可能需要根据具体情况进行调整。
如果你有其他问题,请随时提问。

DID双重差分法的原理和方法
DID (Difference-in-Differences)双重差分法是一种常用的计量经
济学方法,用于评估政策、项目或者干预措施对于个体、群体或者地区的
影响。
双重差分法的原理:
双重差分法的核心原理是通过比较干预的组群的差异与未干预的组群
的差异,来分析干预的效果。
在具体实践中,双重差分法一般利用带有两
个时间点的数据,将被干预组群和未干预组群的差异以及两个时间点的差
异相减,从而得到干预效果的估计。
方法步骤:
二、选择对照组:在使用双重差分法时,我们需要找到一个对照组,
也就是未受到干预的组群。
这个对照组需要与被干预组群具有相似的特征,以确保比较的准确性。
三、进行前后测量:在实施干预之前和之后,对被干预组群和对照组
的相关变量进行测量。
这些变量可能包括人口统计学数据、经济指标等。
四、计算双重差分:双重差分的计算是通过以下公式进行的:
DID=(被干预组群后测量-被干预组群前测量)-(对照组群后测量-对照
组群前测量)
五、进行统计分析:使用双重差分方法得到的差异值作为干预效果的
估计量,然后进行假设检验或者置信区间估计,以确定差异是否显著。
六、进行结果诠释:对结果进行诠释时,需要考虑其他可能的干扰因素,例如外部环境变化或者样本选择偏差等。
在结果诠释中,需要准确理解干预效果的大小和统计显著性水平。
优点:
1.双重差分法可以有效控制时间固定效应和个体固定效应,减少内生性问题。
2.双重差分法不需要对个体特征进行匹配,更加简单易行。
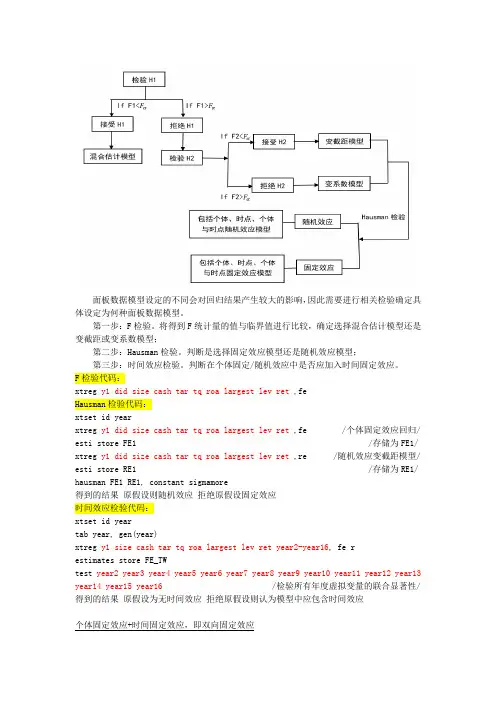
面板数据模型设定的不同会对回归结果产生较大的影响,因此需要进行相关检验确定具体设定为何种面板数据模型。
第一步:F检验。
将得到F统计量的值与临界值进行比较,确定选择混合估计模型还是变截距或变系数模型;第二步:Hausman检验。
判断是选择固定效应模型还是随机效应模型;第三步:时间效应检验。
判断在个体固定/随机效应中是否应加入时间固定效应。
F检验代码:xtreg y1 did size cash tar tq roa largest lev ret ,feHausman检验代码:xtset id yearxtreg y1 did size cash tar tq roa largest lev ret ,fe /个体固定效应回归/ esti store FE1 /存储为FE1/ xtreg y1 did size cash tar tq roa largest lev ret ,re /随机效应变截距模型/ esti store RE1 /存储为RE1/ hausman FE1 RE1, constant sigmamore得到的结果原假设则随机效应拒绝原假设固定效应时间效应检验代码:xtset id yeartab year, gen(year)xtreg y1 size cash tar tq roa largest lev ret year2-year16, fe restimates store FE_TWtest year2 year3 year4 year5 year6 year7 year8 year9 year10 year11 year12 year13 year14 year15 year16 /检验所有年度虚拟变量的联合显著性/ 得到的结果原假设为无时间效应拒绝原假设则认为模型中应包含时间效应个体固定效应+时间固定效应,即双向固定效应一、常用的两种双重差分模型:(一)传统DIDy it=α0+α1treated i+α2time t+α3treated i×time t+γx it+εit(1)treated i为实验组和控制组的分组变量。


双重差分法原理及其应用双重差分法原理及其应用双重差分法(Double Difference Method)是一种常用的估计处理方法,用于处理面板数据。
它的原理是同时控制因素的内生性和异质性,以达到更准确的估计结果。
在本文中,我们将详细介绍其原理及应用。
一、原理在经济学中,我们常常遇到面板数据,即同时包含时间和交叉部门或地区的数据。
这种数据结构下,因素的内生性和异质性很容易引起估计结果的偏差。
而双重差分法正是为了应对这种情况而出现的。
具体来说,双重差分法的原理是通过对面板数据进行差分操作,去除掉因素的内生性和异质性,从而得到更准确的估计结果。
其中,双重差分法的“双重”指的是两次差分操作,分别针对时间和交叉部门或地区的差异进行。
例如,我们用y表示某一经济变量,t表示时间,i表示部门或地区,则双重差分法公式如下:(1)ΔΔy(i,t) = ΔΔy(i,t) - ΔΔy(i,t-1) - ΔΔy(i-1,t) +ΔΔy(i-1,t-1)其中,Δ和ΔΔ表示一阶和二阶差分,即y的变化量。
这个公式的意思是用第i个单位时间和部门或地区的变化量减去相邻单位时间和部门或地区的变化量,两组数据之间还要再进行差分操作,最终得到去除掉内生性和异质性后的估计值。
二、应用双重差分法广泛应用于经济学、金融学、社会学等领域,常用于研究经济政策变化或自然事件对于经济变量的影响。
例如,假设某国政府在某一年度实行了一项减税政策,我们想要研究这项政策对于国内生产总值(GDP)的影响。
这时,我们可以采用双重差分法来排除其他因素的影响,得到减税政策对于GDP的实际影响。
具体来说,我们可以先对减税政策前后的GDP进行一阶差分,得到GDP 的变化量。
然后再对减税政策前后的不同地区或部门的GDP进行一阶差分,得到GDP变化量的交叉差分值。
最后,再对这两组数据进行一阶差分,得到去除掉内生性和异质性后的减税政策实际影响值。
双重差分法能够排除内生性和异质性的影响,从而得到更准确的估计结果,但也存在一些限制。

双重差分法的平行趋势假定双重差分法是估计处理效应的常见方法,但也有被滥用的倾向,因为有些应用者对于双重差分法的优点与局限缺乏了解,特别是其潜在的平行趋势(parallel trend)假定……差分法的局限经济学家常关心某政策实施后的效应,比如对于收入(y )的作用。
最简单(天真)的做法是比较处理组(即受政策影响的地区或个体)的前后差异,比如这称为“差分估计量”(difference estimator),即将处理组(treatment group)政策实施后的样本均值,减去政策实施前的样本均值。
然而,由于宏观经济环境也随时间而变(时间效应),故政策实施地区的前后差异未必就是处理效应(treatment effects)。
双重差分法的反事实逻辑为了解决差分法的局限性,常用方法是寻找适当的控制组(control group),即未实施政策的地区(或未参加项目的个体),作为处理组的反事实(counterfactual)参照系。
具体来说,可将未受政策影响的控制组之前后变化视为纯粹的时间效应,即综合以上两个差分,即将处理组的前后变化减去控制组的前后变化,可得到对于政策处理效应更为可靠的估计:(1)这就是所谓的双重差分估计量(Difference in Differences,简记DD或DID),因为它是处理组差分与控制组差分之差。
该法最早由Ashenfelter(1978)引入经济学,而国内最早的应用或为周黎安、陈烨(2005)。
从以上推理可知,DID的反事实逻辑能够成立,其基本前提是,处理组如果未受到政策干预,其时间效应或趋势应与控制组一样(故可以后者来控制时间效应),这就是所谓的“平行趋势”(parallel trend)或“共同趋势”(common trend)假定。
下图直观地展示了DID的思想与平行趋势假定。
其中,t = 1 表示政策实施前(before),而t = 2 表示政策实施后(after)。
三重差分法平行趋势检验概述说明以及解释1. 引言1.1 概述在经济学和统计学领域中,平行趋势检验是一种常用的方法,用于评估某个政策、干预措施或其他因素对数据的影响。
然而,在实践中,由于被评估的因素往往与其他变量存在内在关联性,直接进行趋势分析可能会导致结果出现偏差。
为了解决这个问题,引入了三重差分法作为一种有效的统计工具。
通过使用三重差分法,研究人员可以排除不相关的变量对结果产生的干扰,并更准确地评估因果关系。
1.2 文章结构本文将以以下结构来介绍和解释三重差分法和平行趋势检验的概念、原理、应用和结果解释:第二部分将详细介绍三重差分法的定义和原理。
我们将解释为什么需要使用三重差分法以及其基本概念和核心思想。
第三部分将着重讨论平行趋势检验。
我们将介绍该方法的概念、判断标准和应用场景,并通过具体案例进行深入分析。
第四部分将对结果进行解释和讨论。
我们将探讨如何准确评估结果的可靠性和准确性,以及如何对不同结果进行比较和评估其在研究领域中的意义和影响。
最后,在第五部分我们将总结研究的发现和重要性,并探讨进一步研究该领域的方向以及未来可能的发展。
1.3 目的本文的目的是提供关于三重差分法和平行趋势检验的综合概述。
我们将通过清晰地介绍相关概念、原理和应用,帮助读者深入理解这些方法,并为进一步研究或实践提供指导。
此外,本文还旨在强调使用三重差分法进行平行趋势检验时需要注意的问题,以及正确解读和解释结果的方法。
2. 三重差分法:2.1 定义与原理:三重差分法是一种用于处理时间序列数据中存在的趋势性关系的统计分析方法。
它通过连续对时间序列数据进行三次差分,以消除数据中的线性趋势和季节性影响。
在三重差分法中,首先进行一次差分以去除线性趋势。
然后,进行二次差分以去除存在的季节性变化。
最后,进行三次差分以消除任何残留的趋势。
这种方法有效地减少了时间序列数据中的趋势效应,并使得数据在某种程度上是平稳的,从而方便进一步的统计分析和建模。
双重差分法使用案例
想象一下啊,有个减肥公司推出了一款超神奇的减肥药丸。
他们想知道这药丸到底有没有效果呢。
他们找了两组人。
一组是实验组,这组人呢,每天都会吃这个减肥药丸。
另一组是对照组,这组人就像平常一样生活,啥特别的药丸都不吃。
这两组人啊,在最开始的时候都称了体重,发现平均体重差不多呢,比如说都是70公斤。
这就相当于找到了一个比较公平的起点,就像两个人站在同一条起跑线上准备比赛。
然后呢,过了一段时间,比如说三个月后,再去称体重。
这时候就发现实验组的人平均体重变成了60公斤,而对照组的人平均体重变成了68公斤。
这里面的差别可就有讲究啦。
双重差分法就是这么来分析的。
先看第一重差,就是实验组自己在吃药前后的体重差,那就是70 60 = 10公斤。
这说明实验组在吃了药丸之后体重下降了不少。
但是呢,光看这个还不行,因为也许在这三个月里,不吃药丸的人也会因为其他原因瘦一点呢。
这时候对照组就派上用场了。
对照组的体重差是70 68 = 2公斤。
这2公斤可能就是因为其他因素,像有的人可能自己在这三个月里多运动了一点或者少吃了一点。
然后呢,双重差分法就做第二重差,就是用实验组的体重差减去对照组的体重差,也就是10 2 = 8公斤。
这个8公斤就是我们认为是这个减肥药丸真正起到的减肥效果。
你看,通过这样的双重差分,就好像把那些可能干扰结果的因素都给排除掉了,就能比较准确地知道这个减肥药丸到底有没有效果啦。
这就是双重差分法在这个减肥产品效果评估中的简单应用。
分位数双重差分法的stata命令分位数双重差分法是一种常用的回归分析方法,可用于研究政策改变对个体或群体行为的影响。
这种方法的优势在于可以控制个体固定效应和时间固定效应,消除了可能存在的内生性问题,提高了研究的可信度。
为了使用分位数双重差分法,我们可以借助Stata软件提供的命令进行实施。
首先,我们需要使用"xtset"命令设置数据集的面板结构,以便正确地识别个体和时间。
然后,利用"areg"命令进行分位数双重差分估计。
下面我们以一个实际例子来解释分位数双重差分法的应用。
假设我们想研究教育政策改变对学生成绩的影响。
我们有一个包含学生个体信息和学校年度数据的面板数据集。
我们的目标是估计政策改变对学生成绩的效应。
首先,我们使用"xtset"命令设置数据集的面板结构。
假设个体变量为"student_id",时间变量为"year",则命令为:xtset student_id year接下来,我们将使用"areg"命令进行分位数双重差分估计。
假设我们想估计教育政策改变对学生成绩的影响,并将注意力放在学生成绩分布的中位数水平。
我们可以使用"areg"命令的"qreg"选项来实现。
具体命令如下:areg score policy_change, absorb(individual school)qreg(0.5)在这个命令中,"score"是学生成绩的因变量,"policy_change"是政策变量。
"absorb(individual school)"表示我们将控制个体和学校的固定效应。
"qreg(0.5)"表示我们将对学生成绩分布的中位数水平进行估计。
分位数双重差分估计的结果将提供政策变化对学生成绩的影响估计量以及对应的置信区间。
双重差分法的平行趋势假定双重差分法是估计处理效应的常见方法,但也有被滥用的倾向,因为有些应用者对于双重差分法的优 点与局限缺乏了解,特别是其潜在的平行趋势( parallel trend )假定 ....差分法的局限经济学家常关心某政策实施后的效应,比如对于收入(y )的作用。
最简单(天真)的做法是比较处理组(即受政策影响的地区或个体)的前后差异,比如 这称为 差分估计量"(difference estimator ),即将处理组(treatment group )政策实施后的样本均值, 减去政策实施前的样本均值。
然而,由于宏观经济环境也随时间而变(时间效应),故政策实施地区的前 后差异未必就是处理效应(treatment effects )。
双重差分法的反事实逻辑为了解决差分法的局限性, 常用方法是寻找适当的控制组 (cont ⑹group ),即未实施政策的地区(或 未参加项目的个体),作为处理组的反事实( counterfactual )参照系。
具体来说,可将未受政策影响的控 制组之前后变化视为纯粹的时间效应,即V control — ^ctwiirof, before综合以上两个差分,即将处理组的前后变化减去控制组的前后变化,可得到对于政策处理效应更为可 靠的估计:这就是所谓的双重差分估计量( Difference in Differences ,简记DD 或DID ),因为它是处理组差分与控制组差分之差。
该法最早由Ashenfelter (1978 )引入经济学,而国内最早的应用或为周黎安、陈烨(2005 ) 从以上推理可知,DID 的反事实逻辑能够成立,其基本前提是,处理组如果未受到政策干预,其时间效应或趋势应与控制组一样(故可以后者来控制时间效应),这就是所谓的或 共同趋势”(common trend )假定。
下图直观地展示了 DID 的思想与平行趋势假定。
平行趋势"(parallel trend )E 伽G = = 1) = a + d其中,t = 1表示政策实施前(before ),而t = 2表示政策实施后(after )。
双重差分法 python双重差分法:理解和 Python 实现简介双重差分法 (DID) 是一种计量经济学技术,用于评估干预措施的因果效应。
它通过比较处理组和对照组在干预前后差异的差异,来消除固有偏见和时间固有趋势的影响。
假设DID 法的有效性依赖于以下假设:平行趋势假设:处理组和对照组在干预措施实施前表现出相似的趋势。
样本外推假设:对照组的变化代表了处理组在没有干预情况下可能发生的趋势。
共同趋势假设:处理组和对照组暴露于相同的未观察到的因素,这些因素在干预前后都不会发生变化。
计算DID 法的计算过程涉及以下步骤:1. 计算处理组和对照组在干预前后差异:- 处理组差异:处理组干预前后观测值的差值。
- 对照组差异:对照组干预前后观测值的差值。
2. 计算处理组和对照组差异的差异:- DID 估计量:处理组差异减去对照组差异。
Python 实现使用 Python 实现 DID 法的步骤如下:1. 导入必需的库:- Pandas:用于数据操作- Statsmodels:用于回归分析2. 加载数据:- 将数据加载到 Pandas 数据框中。
3. 创建处理组和对照组:- 根据处理变量将数据框分成处理组和对照组。
4. 计算干预前后差异:- 使用 Pandas 的 `diff()` 函数计算每个处理组和对照组观测值的干预前后差异。
5. 计算 DID 估计量:- 计算处理组差异和对照组差异的差值。
6. 估计 DID 回归:- 使用 Statsmodels OLS 回归器估计 DID 回归模型。
7. 评估结果:- 检查 DID 估计量的显著性,以确定干预措施的因果效应。
举例考虑一个评估教育计划对学生考试成绩影响的示例。
数据包括干预前后的学生成绩。
1. 加载数据:```pythonimport pandas as pddata = pd.read_csv('student_scores.csv')```2. 创建处理组和对照组:```pythontreatment_group = data[data['treatment'] == 1]control_group = data[data['treatment'] == 0]```3. 计算干预前后差异:```pythontreatment_diff = treatment_group['score_post'] - treatment_group['score_pre']control_diff = control_group['score_post'] - control_group['score_pre']```4. 计算 DID 估计量:```pythondid_est = treatment_diff.mean() - control_diff.mean() ```5. 估计 DID 回归:```pythonimport statsmodels.api as smmodel = sm.OLS(treatment_diff, control_diff)results = model.fit()```6. 评估结果:```pythonprint(results.summary())```如果 DID 估计量在统计学上显著,则表明教育计划对学生考试成绩产生了因果效应。
双重差分法stata命令双重差分法(DoubleDifference)是一种常用的计量经济学方法,它可以帮助我们解决因果推断问题。
在实际应用中,我们经常使用Stata软件来实现双重差分法。
本文将介绍Stata中的双重差分法命令,并从理论和实践两个方面进行讲解。
一、双重差分法的基本概念双重差分法是一种自然实验法,它的基本思想是通过比较实验组和对照组在时间上和空间上的差异,来估计政策或者治疗对于实验组的影响。
它的优点在于可以控制一些固定的不可观测因素,从而减少了因果效应的内生性问题。
在双重差分法中,我们通常使用一个二元模型来估计因果效应。
假设y表示我们感兴趣的结果变量,x表示政策或者治疗,t表示时间,i表示个体,那么我们的模型可以写成:y_it = α + βx_it + γt + δ(x_it * t) + ε_it 其中,α是常数项,β是政策或者治疗的系数,γ是时间的系数,δ是政策或者治疗与时间的交互项系数,ε是误差项。
这个模型的意义是,我们将y_it视为一个个体i在时间t的结果变量,x_it表示政策或者治疗对于个体i在时间t的影响,γ和δ分别表示时间和政策或者治疗与时间的交互项对于y_it的影响。
二、Stata中双重差分法的实现在Stata中,我们可以使用diff命令来实现双重差分法。
diff 命令的基本语法如下:diff y x, group(i) time(t)其中,y表示结果变量,x表示政策或者治疗,group(i)表示按照个体i进行分组,time(t)表示按照时间t进行分组。
例如,我们想要估计一个政策对于个体收入的影响,我们可以使用以下命令:diff income policy, group(id) time(year)其中,income表示收入,policy表示政策,id表示个体ID,year 表示年份。
三、双重差分法的实践应用在实践中,双重差分法可以应用于很多领域,例如劳动力市场、医疗卫生、教育等。
重差分法运行和示例 TTA standardization office【TTA 5AB- TTAK 08- TTA 2C】
三重差分法及运行
双重差分法的关键假设是实验组与对照组的时间效应一样。
这个假设只有通过足够长的时间序列数据才能检验。
需要指出的一点是,即使干预发生之前两组时间序列一致,也不能保证干预发生后两组时间序列是一致的。
有可能在干预发生的同时在实验组或者对照组中又发生了其他影响产出的事件,则干预发生后两组的时间趋势是不一致的。
简单的双重差分估计是有偏的。
如图3所示,如果对照组是虚线所示,则双重差分估计是无偏的。
但如果对照组是上方的实线,则双重差分估计法是有偏的,偏差部分是在时刻,该实线与虚线之间的距离。
解决这个问题有两个思路:第一个是寻找更多的对照组,把多个对照组加权构造成一个虚拟的对照组,使得虽然每个对照组都与实验组的时间趋势不一样,但加权后的虚拟对照组的时间趋势与实验组的一样。
这个方法被称作综合控制法(Synthetic Control Method)。
Abadie & Gardeazabal(2003)(14)用这个方法研究了恐怖冲突对经济发展的影响。
解决这个问题的第二个思路是估算出这个因为时间趋势不同而带来的偏差,然后从双重差分结果中减去这个偏差即可。
这被称作三重差分法(Difference-in-differences-in-differences, DDD)。
三重差分法的思路是,既然两个地区(分别指实验组和对照组)的时间趋势不一样,那么我们可以分别在两个地区寻找一个没有受到干预影响的人群/行业,通过对这两组的双重差分估算出时间趋势的差异,然后再从原来实验组和对照组的双重差分估算值中减去这个时间趋势差异。
Gruber(15)就使用了这种方法。
图3 时间趋势差异造成的估计偏差
三重差分法例证:
三重差分法回归及运行命令
正如上面的二重差分法实际上运用的是OLS做的回归,我们之前说过,倍差法是相当于two-way fixed effect model,里面包括个体效应时间效应,而对于一个这样的panel data,我们可以运用LSDV通过添加个体和时间虚拟变量来回归,或者运用demeaned variables回归来消除个体和时间效应,再加上那些交互效应后就可以像其他fixed effect回归一样。
二重差分法一般是在同一个省(地区)区分treatment 和control组的,而三重差分法则包括另一个未受到政策冲击的省(地区),来区分treatment和control组的,当然三重差分法要稳健得多。
Empirical Methods in Applied Economics Lecture
Jorn-Steffen Pischke
接下来,我们来区分一下二重差分和三重差分在Stata的运行过程
1992年,美国新泽西州通过法律将最低工资从每小时美元提高到美元,但在相邻的宾夕法尼亚州最低工资却保持不变。
Card and Krueger收集了两个州的快餐店在实施新法前后雇佣人数的数据,并使用双重差分法进行估计。
注:fte:full time employment人数; treated=1,表示快餐店在新泽西州,否则在宾夕法尼亚州;t=1,表示时间为1992年11月,否则为1992年2月;bk=1,表示
Burger King快餐品牌;kfc=1,表示肯德基快餐品牌;roys=1,表示Roy Rogers快餐品牌; wendys=1,表示Wendy's快餐品牌。
以下黑色字体的code可以直接在Stata上执行
1.读取数据:
userepec/bocode/c/"
2.简单的二重差分:
diff fte, t(treated) p(t)
*这里DD10%水平下显着
3.简单的三重差分(快餐品牌bk作为第二个处理组):
diff fte, t(treated) p(t) ddd(bk)
*这里DDD表不显着。