2018年春社会统计学期末复习训练题 (4)
- 格式:doc
- 大小:120.00 KB
- 文档页数:21


2018年春社会统计学期末复习题一、单项选择题1.以下关于因变量与自变量的表述不正确的是()A.自变量是引起其他变量变化的变量B.因变量是由于其他变量的变化而导致自身发生变化的变量C.自变量的变化是以因变量的变化为前提D.因变量的变化是以自变量的变化为前提2.在频数分布表中,将各个有序类别或组的百分比逐级累加起来称为( )A.频率B.累积频数C.累积频率D.比率3.离散系数的主要目的是()A.反映一组数据的平均水平B.比较多组数据的平均水平C.反映一组数据的离散程度D.比较多组数据的离散程度4.经验法则表明,当一组数据正态分布时,在平均数加减2个标准差的范围之内大约有()A.50%的数据B.68%的数据C.95%的数据D.99%的数据5.在某市随机抽取10家企业,7月份利润额(单位:万元)分别为72。
0、63.1、20。
0、23.0、54.7、54.3、23。
9、25.0、26。
9、29.0,那么这10家企业7月份利润额均值为()A.39。
19B.28。
90C.19.54D.27.956.用样本统计量的值直接作为总体参数的估计值,这种方法称为()A.点估计B.区间估计C.有效估计D.无偏估计7.在频数分布表中,比率是指()A.各组频数与上一组频数之比B.各组频数与下一组频数之比C.各组频数与总频数之比D.不同小组的频数之比8.下面哪一项不是方差分析中的假定()A.每个总体都服从正态分布B.观察值是相互独立的C.各总体的方差相等D.各总体的方差等于09.判断下列哪一个不可能是相关系数()A.—0。
9B.0C.0。
5D.1。
210.用于说明回归方程中拟合优度的统计量主要是()A.相关系数B.离散系数C.回归系数D.判定系数11.在假设检验中,不拒绝虚无假设意味着()A.虚无假设是肯定正确的B.虚无假设肯定是错误的C.没有证据证明虚无假设是正确的D.没有证据证明虚无假设是错误的12.下列变量属于数值型变量的是( )A.工资收入B.产品等级C.学生对考试改革的态度D.企业的类型13.如果用一个图形描述比较两个或多个样本或总体的结构性问题时,适合选用哪种图形()A.环形图B.饼图C.直方图D.条形图14.在频数分布表中,频率是指()A.各组频数与上一组频数之比B.各组频数与下一组频数之比C.各组频数与总频数之比D.各组频数与最大一组频数之比15.两个定类变量之间的相关分析可以使用()A.λ系数B.ρ系数C.γ系数D.Gamma系数16.根据一个样本均值求出的90%的置信区间表明()A.总体均值一定落入该区间内B.总体均值有90%的概率不会落入该区间内C.总体均值有90%的概率会落入该区间内D.总体均值有10%的概率会落入该区间内17.已知某单位职工平均每月工资为3000元,标准差为500元。

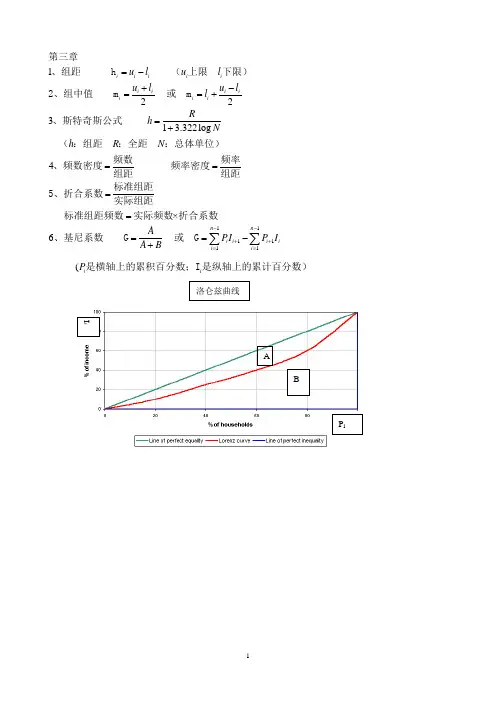
12231 3.322log 4×6i i i i i i i i i i i i u l u l u l u ll Rh N h R N AA B =-+-==+=+=====+第三章、组距 h (上限 下限)2、组中值 m 或 m 、斯特奇斯公式 (:组距 :全距 :总体单位)频数频率、频数密度 频率密度组距组距标准组距5、折合系数实际组距标准组距频数实际频数折合系数、基尼系数 G 111111n n i i i ii i PI P I --++===-∑∑ 或 G(i i P 是横轴上的累积百分数;I 是纵轴上的累计百分数)洛仑兹曲线P iI iAB1(2))(1)1221222d d X X X N fXX fN NN NN F L ==++-=+∑∑∑第四章1、算术平均数()()未分组资料 分组资料 注:对于单项数列分组,X即为变量值,若为组距式分组,则X为组中值 f:各组频数2、中位数(M 未分组资料 若N为奇数,则取第位上的变量值为中位数,若为偶数,则取第 位和第位上的两个变量值的平均数作为中位数()分组资料 M 112h h L : 2m m d m m m m m N F U f f f F F N---⨯=-⨯或 M 中位数所在组的下限: 中位数所在组的频数: 小于中位数所在组的各组频数之和(向上累计) h : 中位数所在组的组距 U: 中位数所在组的上限: 包括中位数所在组的各组频数之和(向上累计) 注: 中位数所在组由确定11111111133333334h :h 34h :N F l f F l f NF l f F l -=+⨯-=+⨯3、四分位数(1)第一四分位数 Q :小于第一四分位数所在组的各组累计频数(向上累计) 第一四分位数所在组的下限 :第一四分位数所在组的组距 :第一四分位数所在组的组距(2)第三四分位数 Q :小于第三四分位数所在组的各组累计频数(向上累计) 第三四分位数所在组的3311212h 1h :h 5o o o oo o f L L ∆=+⨯∆+∆∆∆下限 :第三四分位数所在组的组距 :第三四分位数所在组的组距4、众数(M )()未分组资料 先将所有数据顺序排列,观察某些变量值出现的次数最多,这些变量值就 是众数(2)分组资料 M 众数所在组的下限:众数所在组频数与前一组频数之差 :众数所在组频数与后一组频数之差 :众数所在组的组距、几何平均数11lg lg anti(lg )(2)1lg lg anti(lg )g g g g g gg g g X Nf X NX ========∑∑(M )()简单几何平均数 M 或 M M M 加权几何平均数M 或 M M M 注:若为组距式分组,则为组中值3112316)(1)111111...(2):312=23h h N h d o g h N Q Q NX X X X XNNf XX f X X -==++++==-≥≥-⋅∑∑、调和平均数(M 简单调和平均数(未分组) M 加权调和平均数(分组)M 注:若为组距式分组,为组中值 各组频数7、各种平均数的关系2M M M M 第五章、全距 R=X X 、四分位差 Q D、平均差=2=::X X Nf X XfX f X f -⋅-⋅∑∑(1)未分组资料 A D ()分组资料 A D 注:若为组距式分组,为组中值 各组频数4、标准差(S)(1)未分组资料(2)分组资料 注:若为组距式分组,为组中值 各组X X S-频数5、标准分 Z=社会统计学复习整理一、变量的测量层次61(2)37=1:83(o o oR R M M M o d o R X X SXN f f NNf X M X M X M S Sαα⋅⋅=-⋅=----==A D 、变异系数()全距系数 V =A D平均差系数 V =()标准差系数 V 、异众比率(非众数的频数与总体单位数的比值) V R 众数的频数、偏态系数())偏态=二、判断变量层次的技巧1.首先所有的变量都是定类变量。

社会统计学复习题答案社会统计学是一门应用广泛的学科,它涉及到数据的收集、处理、分析和解释,以帮助我们更好地理解社会现象。
以下是一些社会统计学的复习题及其答案,供参考:一、选择题1. 社会统计学的主要研究对象是什么?A. 个体行为B. 社会现象C. 经济活动D. 政治事件答案:B2. 以下哪个是描述性统计的主要内容?A. 推断总体参数B. 描述数据分布C. 预测未来趋势D. 建立因果关系答案:B3. 抽样调查与普查的主要区别是什么?A. 抽样调查成本高B. 普查不具有代表性C. 抽样调查结果不可靠D. 普查可以得到全面数据答案:D二、填空题4. 社会统计学中,________是用来衡量数据集中趋势的指标。
答案:均值5. 标准差是衡量数据________的指标。
答案:离散程度6. 相关系数的取值范围在________之间。
答案:-1到1三、简答题7. 简述抽样误差和非抽样误差的区别。
答案:抽样误差是指由于样本不能完美代表总体而产生的误差,它可以通过增大样本量来减少。
非抽样误差则包括测量误差、非响应误差等,这些误差与抽样方法无关,通常与数据收集和处理过程中的偏差有关。
8. 描述统计与推断统计的区别。
答案:描述统计主要关注对数据集的描述,如计算均值、中位数、方差等,它不涉及对总体的推断。
推断统计则是基于样本数据来推断总体特征,如估计总体均值、进行假设检验等。
四、计算题9. 给定一组数据:10, 12, 14, 16, 18, 20,计算其均值和标准差。
答案:均值 = (10+12+14+16+18+20)/6 = 15;标准差 =√[(Σ(xi - 均值)^2) / (n-1)] = √[(10+4+0+4+0+5)/5] ≈ 3.0310. 如果一个总体的均值为50,标准差为10,样本均值为55,样本量为100,进行单样本t检验,假设总体方差未知,计算t值。
答案:首先计算样本标准差,然后使用t检验公式:t = (样本均值 - 总体均值) / (样本标准差/ √样本量)。

社会统计学复习题1.定类变量是指取值只有属性之分,没有大小程度之分。
定序变量是指除类别属性之外,还有等级次序的差别、大小之分。
定距变量是指区别它是连续型变量还是离散型变量。
定比变量是指其取值还可构成一个比率。
2.分布是指概率分布或频次分布。
在一个分布中,变量的取值应注意(1)变量取值必须完备;(2)变量取值必须互斥。
3.根据变量的不同层次,统计图的选择是不同的,定类变量选择圆瓣图和图;定序变量选择条形图;定距变量选择直方图和折线图。
4.圆瓣图是指将资料展示在一个圆平面上,通常用圆形代表现象的总体;条形图是指用长条的高度来表示资料类别的次数或百分数;直方图是指由紧挨着的长度所组成,以长条的面积来表示频次或相对频次;折线图是指用直线连接直方图中条形顶端的中点。
5.频次密度是指直方图的长条面积=频次/组距;相对频次密度是指条形的长度,即纵轴的高度。
6.累计图或累计表是指大于某个变量值的频次是多少或小于某个变量值的频次是多少。
7.左偏态是指偏态图形左边尾巴拖得较长的图形;右偏态是指。
8.反映分布集中值或集中趋势的指标有众值、中位值、均值。
众值适用于定类、定序、定距变量;中位值适用于定距、定序变量;均值适用于定距变量。
9.对于众值、中位值和均值三者的大小关系,对称图形表现为众值、中位值、均值三者位置重叠;右偏态表现为均值变化较快,中位值次之,众值不变;左偏态表现为。
10.反映分布离散趋势的指标有异众比率、极差、四分互差、方差或标准差。
适用于定类变量的有异众比率;适用于定序变量的有异众比率、极差、四分互差;适用于定距变量的有异众比率、极差、四分互差,方差或标准差。
11.当变量值较大而次数较多时,平均数接近于变量值较大的一方,当变量值较小而次数较多时,平均数靠近于变量值较小的一方。
12.某班70%的同学平均成绩为85分,另30%的同学平均成绩为70分,则全班总平均成绩为 80.5 分。
13.统计中的变量数列是以均值为中心而左右波动,所以这个指标反映了总体分布的集中趋势。

社会统计学期末复习训练一、单项选择题(20=2×10)1.为了解IT行业从业者收入水平,某研究机构从全市IT行业从业者随机抽取800人作为样本进行调查,其中44%回答他们的月收入在6000元以上,30%回答他们每月用于娱乐消费在1000元以上。
此处800人是.样本2.某地区政府想了解全市332.1万户家庭年均收入水平,从中抽取3000户家庭进行调查,以推断所有家庭的年均收入水平。
这项研究的总体是 332.1户家庭的年均收入3.学校后勤集团想了解学校22000学生的每月生活费用,从中抽取2200名学生进行调查,以推断所有学生的每月生活费用水平。
这项研究的总体是 22000名学生的每月生活费用4.为了解地区的消费,从该地区随机抽取5000户进行调查,其中30%回答他们的月消费在5000元以上,40%回答他们每月用于通讯、网络的费用在300元以上。
此处5000户是样本5.从变量分类看,下列变量属于定序变量的是产品等级6.下列变量属于数值型变量的是工资收入7.从含有N个元素的总体中,抽取n个元素作为样本,同时保证总体中每个元素都有相同的机会入选样本,这样的抽样方式称为.简单随机抽样8.某班级有60名男生,40名女生,为了了解学生购书支出,从男生中抽取12名学生,从女生中抽取8名学生进行调查。
这种调查方法属于分层抽样9.先将总体按某标志分为不同的类别或层次,然后在各个类别中采用简单随机抽样或系统抽样的方式抽取子样本,这样的抽样方式称为分层抽样10.某班级有100名学生,为了了解学生消费水平,将所有学生按照学习成绩排序后,在前十名学生中随机抽出成绩为第3名的学生,后面依次选出第13、23、33、43、53、63、73、83、93九名同学进行调查。
这种调查方法属于系统抽样11.在频数分布表中,某一小组中数据个数占总数据个数的比例称为频率12.在频数分布表中,将各个有序类别或组的百分比逐级累加起来称为累积频率13.在频数分布表中,频率是指各组频数与总频数之比14.在频数分布表中,比率是指不同小组的频数之比15.如果用一个图形描述比较两个或多个样本或总体的结构性问题时,适合选用环形图16.某地区2001-2010年人口总量(单位:万人)分别为98,102,103,106,108,109,110,111,114,115,下列哪种图形最适合描述这些数据线图17.当我们用图形描述甲乙两地区的人口年龄结构时,适合选用哪种图形环形图18.在某市随机抽取10家企业,7月份利润额(单位:万元)分别为72.0、63.1、20.0、23.0、54.7、54.3、23.9、25.0、26.9、29.0,那么这10家企业7月份利润额均值为 39.1919.某班级10名同学期末统计课考试分数分别为76、93、95、80、92、83、88、90、92、72,那么该班考试成绩的中位数是 8920.某企业职工的月收入水平分为五组:1)1500元及以下;2)1500-2000元;3)2000-2500元;4)2500-3000元;5)3000元及以上,则3000元及以上这一组的组中值为 3250元21.为了解某行业12月份利润状况,随机抽取5家企业,12月份利润额(单位:万元)分别为65、23、54、45、39,那么这5家企业12月份利润额均值为 45.222.某专业共8名同学,他们的统计课成绩分别为86、77、97、94、82、90、83、92,那么该班考试成绩的中位数是8823.某班级学生平均每天上网时间可以分为以下六组:1)1小时及以下;2)1-2小时;3)2-3小时;4)3-4小时;5)4-5小时;6)5小时及以上,则5小时及以上这一组的组中值近似为5.5小时24.对于左偏分布,平均数、中位数和众数之间的关系是众数>中位数>平均数25.对于右偏分布,平均数、中位数和众数之间的关系是平均数>中位数>众数26.离散系数的主要目的是比较多组数据的离散程度27.两组数据的平均数不相等,但是标准差相等。

社会统计学期末复习题与答案整理普查是一种专门的调查,它是为了其中一种特定的目的而对总体中所有的个体进行的一次全面调查。
例如,我们历年进行的人口普查、工业普查、农业普查、第三产业普查、经济普查、统计基本单位普查等。
(2)抽样调查抽样调查是从总体中选取部分个体组成样本进行调查的一种方式,其目的在于根据样本的调查结果推断总体特征。
根据抽取样本的方法不同,抽样调查可以分为:概率抽样和非概率抽样。
5.普查P12普查是一种专门的调查,它是为了其中一种特定的目的而对总体中所有的个体进行的一次全面调查。
例如,我们历年进行的人口普查、工业普查、农业普查、第三产业普查、经济普查、统计基本单位普查等。
6.概率抽样P13概率抽样就是按照随机原则进行的抽样,总体中每个个体都有一定的、非零的概率入选样本,并且入选样本的概率都是已知的或可以计算的。
包括:简单随机抽样、系统抽样、分层抽样、整群抽样、多阶段抽样。
7.众数P681、众数众数是一组数据中出现频数最多的数值,用Mo表示。
例如,一个城市有多种产业,但如果以旅游业为最多,那么旅游业就是众数,这个城市也被称为旅游城市。
8.中位数P732、中位数中位数是中心趋势的一种测量,是将一组数据排序后,处于中间位置的变量值,用Me表示。
中位数处于中间位置,前后每部分均包括50%的数据,而且前面部分小于中位数、后面部分大于中位数。
例如,在职工收入水平差异比较大的单位要了解职工收入的一般水平,用职工收入分布的中位数作为收入水平的代表值要比用算术平均数更恰当,因为它排除了极端数据的影响。
9.均值P784、均值均值是集中趋势最主要的测量值,它是将全部数据进行加总然后除以数据总个数,也称为算数平均数。
均值包含一组数据中所有数值,它是先将所有数值进行加总,然后进行平均,在均值中所有数值都有所体现。
因而,我们说均值是集中趋势最主要的测量值。
10.方差与标准差P956、方差方差是各数值与均值离差平方的平均数,它是数值型数据离散趋势最主要的测量值。

社会统计学期末复习题社会统计学课程期末复习题一、名词解释1、社会统计学:社会统计学就是运用统计的一般原理,对社会各种静态结构与动态趋势进行定量描述或推断的一种专门方法与技术。
也就是对社会现象的资料进行收集、整理和分析,以便对社会学的假设、理论进行求证的一门方法论学科。
4、点估计:所谓点估计,就是根据样本数据算出一个单一的估计值,用它来估计总体的参数值。
5、区间估计:所谓区间估计,就是计算抽样平均误差,指出估计的可信程度,进而在点估计的基础上,确定总体参数的所在范围或区间。
6、置信区间:置信区间就是我们为了增加参数被估计到的信心而在点估计两边设置的估计区间。
7、消减误差比例:变量间的相关程度,可以用不知Y与X有关系时预测Y的误差E,减去知道Y与X有关系时预测Y的误差1E,再将其化为比例来度量。
将削减误差比例记为PRE。
8、因果关系:变量之间的关系满足三个条件,才能断定是因果关系。
1)连个变量有共变关系,即一个变量的变化会伴随着另一个变量的变化;2)两个变量之间的关系不是由其他因素形成的,即因变量的变化是由自变量的变化引起的;3)两个变量的产生和变化有明确的时间顺序,即一个在前,另一个在后,前者称为自变量,后者称为因变量。
9、正相关与负相关:正相关是指一个变量的值增加时,另一变量的值也增加;负相关是指一个变量的值增加时,另一变量的值却减少。
13、大数定理:当我们的观察次数n趋向无限时,随机事件可能转换为不可能事件或必然事件。
即,在大量观察的前提下,观察结果具有稳定性。
多次重复试验,随机变量的平均值接近数学期望(即总体均值)。
7.描述性统计就是讨论范围仅以搜索的资料本身为限,而不予以扩大。
早期的统计都是描述统计。
8.推论性统计,主要是依据概率论,研究如何依据有限资料对总体性质作推断,从而使统计的功能大为扩充。
是在树立统计学派之后发展起来的,属于比较现代的统计分析方法。
9.样本或样本总体,是通过抽样得到的用以推断总体特征的那个“部分”。

社会统计学期末复习训练一、单项选择题(20=2×10)1.为了解IT行业从业者收入水平,某研究机构从全市IT行业从业者随机抽取800人作为样本进行调查,其中44%回答他们的月收入在6000元以上,30%回答他们每月用于娱乐消费在1000元以上。
此处800人是.样本2.某地区政府想了解全市332.1万户家庭年均收入水平,从中抽取3000户家庭进行调查,以推断所有家庭的年均收入水平。
这项研究的总体是 332.1户家庭的年均收入3.学校后勤集团想了解学校22000学生的每月生活费用,从中抽取2200名学生进行调查,以推断所有学生的每月生活费用水平。
这项研究的总体是 22000名学生的每月生活费用4.为了解地区的消费,从该地区随机抽取5000户进行调查,其中30%回答他们的月消费在5000元以上,40%回答他们每月用于通讯、网络的费用在300元以上。
此处5000户是样本5.从变量分类看,下列变量属于定序变量的是产品等级6.下列变量属于数值型变量的是工资收入7.从含有N个元素的总体中,抽取n个元素作为样本,同时保证总体中每个元素都有相同的机会入选样本,这样的抽样方式称为.简单随机抽样8.某班级有60名男生,40名女生,为了了解学生购书支出,从男生中抽取12名学生,从女生中抽取8名学生进行调查。
这种调查方法属于分层抽样9.先将总体按某标志分为不同的类别或层次,然后在各个类别中采用简单随机抽样或系统抽样的方式抽取子样本,这样的抽样方式称为分层抽样10.某班级有100名学生,为了了解学生消费水平,将所有学生按照学习成绩排序后,在前十名学生中随机抽出成绩为第3名的学生,后面依次选出第13、23、33、43、53、63、73、83、93九名同学进行调查。
这种调查方法属于系统抽样11.在频数分布表中,某一小组中数据个数占总数据个数的比例称为频率12.在频数分布表中,将各个有序类别或组的百分比逐级累加起来称为累积频率13.在频数分布表中,频率是指各组频数与总频数之比14.在频数分布表中,比率是指不同小组的频数之比15.如果用一个图形描述比较两个或多个样本或总体的结构性问题时,适合选用环形图16.某地区2001-2010年人口总量(单位:万人)分别为98,102,103,106,108,109,110,111,114,115,下列哪种图形最适合描述这些数据线图17.当我们用图形描述甲乙两地区的人口年龄结构时,适合选用哪种图形环形图18.在某市随机抽取10家企业,7月份利润额(单位:万元)分别为72.0、63.1、20.0、23.0、54.7、54.3、23.9、25.0、26.9、29.0,那么这10家企业7月份利润额均值为 39.19 19.某班级10名同学期末统计课考试分数分别为76、93、95、80、92、83、88、90、92、72,那么该班考试成绩的中位数是 8920.某企业职工的月收入水平分为五组:1)1500元及以下;2)1500-2000元;3)2000-2500元;4)2500-3000元;5)3000元及以上,则3000元及以上这一组的组中值为 3250元21.为了解某行业12月份利润状况,随机抽取5家企业,12月份利润额(单位:万元)分别为65、23、54、45、39,那么这5家企业12月份利润额均值为 45.222.某专业共8名同学,他们的统计课成绩分别为86、77、97、94、82、90、83、92,那么该班考试成绩的中位数是8823.某班级学生平均每天上网时间可以分为以下六组:1)1小时及以下;2)1-2小时;3)2-3小时;4)3-4小时;5)4-5小时;6)5小时及以上,则5小时及以上这一组的组中值近似为5.5小时24.对于左偏分布,平均数、中位数和众数之间的关系是众数>中位数>平均数25.对于右偏分布,平均数、中位数和众数之间的关系是平均数>中位数>众数26.离散系数的主要目的是比较多组数据的离散程度27.两组数据的平均数不相等,但是标准差相等。

社会统计学课程期末复习题一、填空题(计算结果一般保留两位小数)1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。
2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。
3、在回归分析中,各实际观测值y 与估计值y ˆ的离差平方和称为 剩余 变差。
4、平均增长速度= 平均发展速度 —1(或100%)。
5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。
6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。
7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。
8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为100%7%A 100% 1.06%100%6%-=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为100%10%100% 4.76%100%5%+=-=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。
10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值);四个部分组成。
11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。
社会统计分析方法 --复习资料一、单项选择题1、根据同一资料计算的数值平均数通常是各不相同的,三者之间的关系是()。
A. 算术平均数≥几何平均数≥调和平均数B. 几何平均数≥调和平均数≥算术平均数C. 调和平均数≥算术平均数≥几何平均数D. 没有确定的关系参考答案: A2、结构相对指标用来反映总体内容的( )。
A. 质量关系B. 密度关系C. 各部分占总体的比重D. 计划关系E. 互为因果关系参考答案: C3、增长速度的计算方法为()。
A. 数列发展水平之差B. 数列发展水平之比C. 绝对增长量和发展速度之比D. 绝对增长量同基期水平之比参考答案: D4、平均增长量等于()。
A. 逐期增长量之和/逐期增长量的个数B. 增长量/报告期水平C. 各期水平与上一期水平之比D. 以上都不对参考答案: A5、区别重点调查和典型调查的标志是()。
A. 调查单位数目不同统计学试题库及答案B. 收集资料方法不同C. 确定调查单位标准不同D. 确定调查单位目的不同参考答案: C二、多项选择题1、参数估计就是根据样本统计量确定总体参数,一般说来,参数估计方法有()。
A. 点估计B. 区间估计C. 最大似然估计D. 矩估计参考答案: A B2、一般来说,样本平均数与总体平均数数值之间的差异和样本平均误差的关系是()。
A. 完全相等B. 可能高于样本平均误差C. 可能低于样本平均误差D. 完全没有关系参考答案: B C3、经常转移有多种存在形式,以下属于经常转移的有()。
A. 所得、财产等经常税B. 社会缴款和社会福利C. 其他经常转移D. 劳动者报酬参考答案: A B C4、整群抽样的优点包括( )。
A. 调查单位比较集中B. 实施比较方便C. 便于设计和组织抽样D. 抽样精度一般低于单纯随机抽样参考答案: A B C5、统计分组( )。
A. 是一种统计方法B. 对总体而言是“合”C. 对总体而言是“分”D. 对个体而言是“合”E. 对个体而言是“分”参考答案: A C D三、判断题1、社会经济现象中,大多数统计总体的次数分布都服从正态分布。
《社会统计学》作业一、单项选择题1、从历史上看,在社会经济统计学的形成过程中,首先使用“统计学”这一术语的是()0A.政治算术学派B.国势学派C,数理统计学派 D.社会经济统计学派2、社会统计的研究对象是()。
A.抽象的数量关系B.社会现象的规律性C.社会现象的数理特征和数量关系D.社会统计认识过程的规律和方法3、对某城市社区居民收入情况进行调查,统计总体是()。
A,每个社区B,该城市全部社区C,每个社区的全部居民D,该城市全部社区的全部居民4、社会统计调查分为一次性调查和经常性调查,是根据()oA.是否定期进行B,组织方式不同C.是否调查全部单位D,时间是否连续5、对学校的教师进行身体普查,调查单位是()。
A.学校全部教师B.学校每一位教师C.每所学校的教师D.学校6、某地区的社会扶贫投入2009年比2004年增长了58.6%,则该地区2004—2009年间扶贫投入的平均发展速度为(A. ^58.6%B.边58.6%C. 058.6%D. §158.6%7、如果采用三项移动平均修匀时间数列,那么所得修匀数列比原数列首尾各少()。
A.一项数值B.二项数值C,三项数值 D.四项数值8、在社会统计指数的计算中,可变权数是指在一个指数数列中,各个指数的()o A,同度量因素是变动的 B.基期是变动的C,指数化因数是变动的 D.时期是变动的9、某企业的职工工资水平比上年提高5%,职工人数增加2%,则企业工资总额增长()。
A.10%B. 7. 1%C. 7%D. 11%10、2009年某市下岗职工已安置了13. 7万人,安置率达80. 6%,安置率是()。
B.变异指标 D,相对指标A. 总量指标 C.平均指标13、 重点调查的重点单位是( )。
A. 这些单位的单位总量占总体单位总量的比重很大B. 标志值很大C. 这些单位的标志总量占总体标志总量的比重很大D. 在社会中的重点单位或部门14、 某村企业职工最高工资为852元,最低工资为540元,据此分为六个组,形成闭口式等距数列,则组距应为( )oA. 142B. 52C. 312D. 26415、某领导小组成员的年龄分别为29, 45, 35, 43, 45, 58,他们年龄的中位数为()A. 45B. 40C. 44D. 43 16、 采用几何平均法计算平均发展速度的依据是( )oA, 各年环比发展速度之积等于总速度 B, 各年环比发展速度之和等于总速度 C, 各年环比增长速度之积等于总速度 D, 各年环比增长速度之和等于总速度17、 某商品报告期与基期相比,商品销售额增长10%,商品销售量增长10%,则商品价格( )oA 、 增长20%B 、 增长10%C 、 增长1%D 、 不增不减 18、 社会统计指数划分为个体指数和总指数的依据是( )=A,反映的对象范围不同 B.指标性质不同 C.采用的基期不同D.编制指数的方法不同19、 对某市1999-2009年教育投资支出(万元)的时间数列配合方程为y = 500 + 52?,这意味着该市教育投资支出每年平均( )。
《社会统计学》课程期末复习题一、填空题1、总体单位除了必须具备同质性外,还必须具备1、差异性(或变异性)性,否则就没有必要对总体进行统计分析研究了,即该性质是对总体进行统计研究的前提条件。
2、抽样调查所遵循的基本原则是2、随机原则,必须保证总体中的每一个单位都有同等的机会被抽中。
3、四分位差数值越小,说明3、中位数;代表性高;异众比率越小,说明众数的代表性越高。
4、在两个变量x与y中,如果y是由x独一无二地确定,这种关系称为4、函数关系;;如果y不是由x独一无二地确定,这种关系称为相关关系。
5、在统计误差中,由于抽样的偶然因素而产生的5、随机(或抽样)误差是不可避免的,但可以通过科学计算加以控制。
6、统计分组按所选择分组标志的多少不同可以分为6、简单分组;和复合分组。
7、某农贸市场,芹菜的价格分别为:早市每斤1.60元,中市每斤1.00元,晚市每斤0.80元。
若甲顾客在早、中、晚三市各买1元芹菜,则应采用7、简单调和;平均数计算该顾客所购买芹菜的平均价格;而乙顾客在早、中、晚三市各买了12元、10元和5元的芹菜,则应采用加权调和平均数计算该顾客所购买芹菜的平均价格。
8、在变量数列编制过程中,组距可以通过8、全距除以组数;来确定。
因此,组距的大小和组数的多少成反比关系。
9、判定系数值越小,则估计标准误差值越,从而在简单线性回归分析中一元直线回归方程的精确性越;反之,判定系数值越大,则估计标准误差值越,从而在简单线性回归分析中一元直线回归方程的精确性越。
9、大;低;小;高10、某商场计划今年4月份销售成本比3月份降低2%,实际却降低了3%,则该商场销售成本计划完成程度为。
10、98.98%11、某福利企业职工先按姓氏笔画排列,再按照排列顺序每隔10人抽取一名职工进行调查,这样的抽样组织方式被称为。
11、等距抽样(系统抽样或机械抽样);12、强度相对指标的数值表现形式是或。
12、无名数;有名数13、从我国指数编制的实践来看,数量指标综合指数的同度量因素固定在,质量指标综合指数的同度量因素固定在。
社会统计学课程期末复习题一、填空题(计算结果一般保留两位小数)1、第五次人口普查南京市和上海市的人口总数之比为 比较 相对指标;某企业男女职工人数之比为 比例 相对指标;某产品的废品率为 结构 相对指标;某地区福利机构网点密度为 强度 相对指标。
2、各变量值与其算术平均数离差之和为 零 ;各变量值与其算术平均数离差的平方和为 最小值 。
3、在回归分析中,各实际观测值y 与估计值y ˆ的离差平方和称为 剩余 变差。
4、平均增长速度= 平均发展速度 —1(或100%)。
5、 正J 形 反J 形 曲线的特征是变量值分布的次数随变量值的增大而逐步增多; 曲线的特征是变量值分布的次数随变量值的增大而逐步减少。
6、调查宝钢、鞍钢等几家主要钢铁企业来了解我国钢铁生产的基本情况,这种调查方式属于 重点 调查。
7、要了解某市大学多媒体教学设备情况,则总体是 该市大学中的全部多媒体教学设备 ;总体单位是 该市大学中的每一套多媒体教学设备; 。
8、若某厂计划规定A 产品单位成本较上年降低6%,实际降低了7%,则A 产品单位成本计划超额完成程度为100%7%A 100%1.06%100%6%-=-=-产品单位成本计划超额完成程度 ;若某厂计划规定B产品产量较上年增长5%,实际增长了10%,则B 产品产量计划超额完成程度为100%10%100%4.76%100%5%+=-=+B 产品产量计划超额完成程度 。
9、按照标志表现划分,学生的民族、性别、籍贯属于 品质 标志;学生的体重、年龄、成绩属于 数量 标志。
10、从内容上看,统计表由 主词 和 宾词 两个部分组成;从格式上看,统计表由总标题 、 横行标题 、 纵栏标题 和 指标数值(或统计数值);四个部分组成。
11、从变量间的变化方向来看,企业广告费支出与销售额的相关关系,单位产品成本与单位产品原材料消耗量的相关关系属于 正 相关;而市场价格与消费者需求数量的相关关系,单位产品成本与产品产量的相关关系属于 负 相关。
2018年春社会统计学期末复习题一、单项选择题1.以下关于因变量与自变量的表述不正确的是()A.自变量是引起其他变量变化的变量B.因变量是由于其他变量的变化而导致自身发生变化的变量C.自变量的变化是以因变量的变化为前提D.因变量的变化是以自变量的变化为前提2.在频数分布表中,将各个有序类别或组的百分比逐级累加起来称为()A.频率B.累积频数C.累积频率D.比率3.离散系数的主要目的是()A.反映一组数据的平均水平B.比较多组数据的平均水平C.反映一组数据的离散程度D.比较多组数据的离散程度4.经验法则表明,当一组数据正态分布时,在平均数加减2个标准差的范围之内大约有()A.50%的数据B.68%的数据C.95%的数据D.99%的数据5.在某市随机抽取10家企业,7月份利润额(单位:万元)分别为72.0、63.1、20.0、23.0、54.7、54.3、23.9、25.0、26.9、29.0,那么这10家企业7月份利润额均值为()A.39.19B.28.90C.19.54D.27.956.用样本统计量的值直接作为总体参数的估计值,这种方法称为()A.点估计B.区间估计C.有效估计D.无偏估计7.在频数分布表中,比率是指()A.各组频数与上一组频数之比B.各组频数与下一组频数之比C.各组频数与总频数之比D.不同小组的频数之比8.下面哪一项不是方差分析中的假定()A.每个总体都服从正态分布B.观察值是相互独立的C.各总体的方差相等D.各总体的方差等于09.判断下列哪一个不可能是相关系数()A.-0.9B.0C.0.5D.1.210.用于说明回归方程中拟合优度的统计量主要是()A.相关系数B.离散系数C.回归系数D.判定系数11.在假设检验中,不拒绝虚无假设意味着()A.虚无假设是肯定正确的B.虚无假设肯定是错误的C.没有证据证明虚无假设是正确的D.没有证据证明虚无假设是错误的12.下列变量属于数值型变量的是()A.工资收入B.产品等级C.学生对考试改革的态度D.企业的类型13.如果用一个图形描述比较两个或多个样本或总体的结构性问题时,适合选用哪种图形()A.环形图B.饼图C.直方图D.条形图14.在频数分布表中,频率是指()A.各组频数与上一组频数之比B.各组频数与下一组频数之比C.各组频数与总频数之比D.各组频数与最大一组频数之比15.两个定类变量之间的相关分析可以使用()A.λ系数B.ρ系数C.γ系数D.Gamma系数16.根据一个样本均值求出的90%的置信区间表明()A.总体均值一定落入该区间内B.总体均值有90%的概率不会落入该区间内C.总体均值有90%的概率会落入该区间内D.总体均值有10%的概率会落入该区间内17.已知某单位职工平均每月工资为3000元,标准差为500元。
如果职工的月收入是正态分布,可以判断月收入在2500元—3500元之间的职工人数大约占总体的()A.95%B.68%C.89%D.90%18.方差分析的目的是()A.比较不同总体的方差是否相等B.判断总体是否存在方差C.分析各样本数据之间是否存在显著差异D.研究各分类自变量对数值型因变量的影响是否显著19.对于线性回归,在因变量的总离差平方和中,如果回归平方和所占比例越大,那么两个变量之间()A.相关程度越大B.相关程度越小C.完全相关D.完全不相关20.正态分布中,当均值μ相等时,σ值越大,则()A.离散趋势越小B.峰值越大C.曲线越低平D.变量值越集中21.从含有N个元素的总体中,抽取n个元素作为样本,同时保证总体中每个元素都有相同的机会入选样本,这样的抽样方式称为()A.简单随机抽样B.系统抽样C.整群抽样D.分层抽样22.某地区2001-2010年人口总量(单位:万人)分别为98,102,103,106,108,109,110,111,114,115,下列哪种图形最适合描述这些数据()A.茎叶图B.环形图C.饼图D.线图23.如果一组数据中某一个数值的标准分值为-1.5,这表明该数值()A.是平均数的-1.5倍B.比平均数少1.5C.等于-1.5倍标准差D.比平均数低1.5个标准差24.某班级10名同学期末统计课考试分数分别为76、93、95、80、92、83、88、90、92、72,那么该班考试成绩的中位数和众数分别是()A.89,92B.72,83C.83,90D.92,9225.某班级学生期末英语考试平均成绩为75分,标准差为10分。
如果已知这个班学生的考试分数服从正态分布,可以判断成绩在65-85之间的学生大约占全班学生的()A.68%B.89%C.90%D.95%26.已知某单位平均月收入为3500元,离散系数为0.2,那么他们月收入的标准差为()A.700B.0.2C.3500D.17500027.在回归方程中,若回归系数等于0,这表明()A.因变量y对自变量x的影响是不显著的B.自变量x对因变量y的影响是不显著的C.因变量y对自变量x的影响是显著的D.自变量x对因变量y的影响是显著的28.某班级有60名男生,40名女生,为了了解学生购书支出,从男生中抽取12名学生,从女生中抽取8名学生进行调查。
这种调查方法属于()A.简单随机抽样B.整群抽样C.分层抽样D.系统抽样29.某企业职工的月收入水平分为以下五组:1)1500元及以下;2)1500-2000元;3)2000-2500元;4)2500-3000元;5)3000元及以上,则3000元及以上这一组的组中值近似为()A.3000元B.3500元C.2500元D.3250元30.对于右偏分布,平均数、中位数和众数之间的关系是()A.平均数>中位数>众数B.中位数>平均数>众数C.众数>中位数>平均数D.众数>平均数>中位数31.两组数据的平均数不相等,但是标准差相等。
那么()A.平均数小的,离散程度小B.平均数大的,离散程度大C.平均数大的,离散程度小32.如果物价与销售量之间的线性相关系数为-0.87,而且二者之间具有统计显著性,那么二者之间存在着()A.高度相关B.中度相关C.低度相关D.极弱相关33.回归平方和(SSR)反映了y的总变差中()A.由于x与y之间的线性关系引起的y的变化部分B.除了x对y的现有影响之外的其他因素对y变差的影响C.由于x与y之间的非线性关系引起的y的变化部分D.由于x与y之间的函数关系引起的y的变化部分34.在假设检验中,虚无假设和备择假设()A.都有可能成立B.都不可能成立C.有且只有一个成立D.备择假设一定成立,虚无假设不一定成立35.学校后勤集团想了解学校22000学生的每月生活费用,从中抽取2200名学生进行调查,以推断所有学生的每月生活费用水平。
这项研究的总体是()A.22000名学生B.2200名学生C.22000名学生的每月生活费用D.2200名学生的每月生活费用36.中心极限定理认为不论总体分布是否服从正态分布,从均值为μ、方差为σ2的总体中,抽取容量为n的随机样本,当n充分大时(通常要求n≥30),样本均值的抽样分布近似服从均值为()、方差为()的正态分布。
A.μ,σ2B. μ/n ,σ2/nC. μ ,σ2/nD.μ/n ,σ237.某校期末考试,全校语文平均成绩为80分,标准差为3分,数学平均成绩为87分,标准差为5分。
某学生语文得了83分,数学得了97分,从相对名次的角度看,该生()的成绩考得更好。
A.数学B.语文C.两门课程一样D.无法判断38.判断下列哪一个不可能是相关系数()A.-0.89B.0.34C.1.32D.039.对消费的回归分析中,学历、年龄、户口、性别、收入都是自变量,其中收入的回归系数为0.8,这表明()A.收入每增加1元,消费增加0.8元B.消费每增加1元,收入增加0.8元C.收入与消费的相关系数为0.8D.收入对消费影响的显著性为0.840.先将总体按某标志分为不同的类别或层次,然后在各个类别中采用简单随机抽样或系统抽样的方式抽取子样本,最后将所有子样本合起来作为总样本,这样的抽样方式称为()A.简单随机抽样B.系统抽样C.整群抽样D.分层抽样41.某专业共8名同学,他们的统计课成绩分别为86、77、97、94、82、90、83、92,那么该班考试成绩的中位数是()A.86B.77C.90D.8842.经验法则表明,当一组数据正太分布时,在平均数加减2个标准差的范围之内大约有()A.50%的数据B.68%的数据C.95%的数据D.99%的数据43.残差平方和(SSE)反映了y的总变差中()A.由于x与y之间的线性关系引起的y的变化部分B.除了x对y的现有影响之外的其他因素对y变差的影响C.由于x与y之间的非线性关系引起的y的变化部分D.由于x与y之间的函数关系引起的y的变化部分44.某项研究中欲分析受教育年限每增长一年,收入如何变化,下列哪种方法最合适()A.回归分析B.方差分析C.卡方检验D.列联表分析45.用样本统计量的值构造一个置信区间,作为总体参数的估计,这种方法称为()A.点估计B.区间估计C.有效估计D.无偏估计46.为了解某地区的消费,从该地区随机抽取5000户进行调查,其中30%回答他们的月消费在5000元以上,40%回答他们每月用于通讯、网络的费用在300元以上。
此处5000户是()A.变量B.总体C.样本D.统计量47.如果一组数据中某一个数值的标准分值为1.8,这表明该数值()A.是平均数的1.8倍B.比平均数多1.8C.等于标准差的1.8倍D.比平均数高出1.8个标准差48.某次社会统计学考试中学生平均成绩82,标准差为6,某同学考试成绩为80,将这个分数转化为Z值为()A.-0.33B.0.33C.-3D.349.根据一个具体的样本求出的总体均值95%的置信区间()A.以95%的概率包含总体均值B.5%的可能性包含总体均值C.绝对包含总体均值D.绝对不包含总体均值50.在因变量的总离差平方和中,如果回归平方和所占的比例越小,则自变量和因变量之间()A.相关程度越高B.相关程度越低C.完全相关D.没有任何关系51.从两个总体中共选取了8个观察值,得到组间平方和为432,组内平方和为426,则组间均方和组内均方分别为()A.432,71B.216,71C.432,426D.216,42652.某班级有100名学生,为了了解学生消费水平,将所有学生按照学习成绩排序后,在前十名学生中随机抽出成绩为第3名的学生,后面依次选出第13、23、33、43、53、63、73、83、93九名同学进行调查。
这种调查方法属于()A.简单随机抽样B.整群抽样C.分层抽样D.系统抽样53.某班级学生平均每天上网时间可以分为以下六组:1)1小时及以下;2)1-2小时;3)2-3小时;4)3-4小时;5)4-5小时;6)5小时及以上,则5小时及以上这一组的组中值近似为()A.5小时B.6小时C.5.5小时D.6.5小时54.一班学生的平均体重均为55千克,二班学生的平均体重为52千克,两个班级学生体重的标准差均为5千克。